Cliente
Spanner admite consultas de SQL. A continuación, hay una consulta de muestra:
SELECT s.SingerId, s.FirstName, s.LastName, s.SingerInfo
FROM Singers AS s
WHERE s.FirstName = @firstName;
La construcción @firstName es una referencia a un parámetro de consulta. Puedes usar un parámetro de consulta en cualquier lugar donde se pueda usar un valor literal. Se recomienda usar parámetros en las API programáticas. Usar parámetros de consulta ayuda a evitar los ataques de inyección de SQL y es más probable que las consultas resultantes se beneficien de varias memorias caché del servidor. Consulta Almacenamiento en caché a continuación.
Los parámetros de consulta deben vincularse a un valor cuando se ejecuta la consulta. Por ejemplo:
Statement statement =
Statement.newBuilder("SELECT s.SingerId...").bind("firstName").to("Jimi").build();
try (ResultSet resultSet = dbClient.singleUse().executeQuery(statement)) {
while (resultSet.next()) {
...
}
}
Una vez que Spanner recibe una llamada a la API, analiza la consulta y los parámetros de vinculación para determinar qué nodo del servidor de Spanner debe procesar la consulta. El servidor devuelve una transmisión de filas de resultados que consumen las llamadas a ResultSet.next().
Ejecución de las consultas
La ejecución de las consultas comienza con la llegada de una solicitud de “ejecutar la consulta” en algún servidor de Spanner. El servidor realiza los pasos siguientes:
- Validar la solicitud
- Analizar el texto de la consulta
- Generar un álgebra de consulta inicial
- Generar un álgebra de consulta optimizada
- Generar un plan de consultas ejecutable
- Ejecutar el plan (verificar permisos, leer datos, codificar resultados, etcétera)
Análisis
El analizador de SQL analiza el texto de la consulta y lo convierte en un árbol de sintaxis abstracta. Extrae la estructura de consulta básica (SELECT …
FROM … WHERE …) y realiza verificaciones sintácticas.
Álgebra
El sistema de tipos de Spanner puede representar escalas, arreglos, estructuras, etcétera. El álgebra de las consultas define operadores para análisis de tablas, filtrado, ordenamiento o agrupación, todo tipo de uniones, agregación, entre otros. El álgebra de consulta inicial se crea a partir del resultado del analizador. Las referencias de nombres de campo en el árbol de análisis se resuelven con el esquema de la base de datos. Este código también verifica si hay errores semánticos (p. ej., una cantidad incorrecta de parámetros, tipos que no coinciden, etcétera).
En el siguiente paso (“optimización de consultas”), se toma el álgebra inicial y se genera un álgebra óptima. Esto podría ser más simple, más eficiente o más adecuado para las capacidades del motor de ejecución. Por ejemplo, el álgebra inicial puede especificar solo una “unión”, mientras que el álgebra optimizada especifica una “unión de hash”.
Ejecución
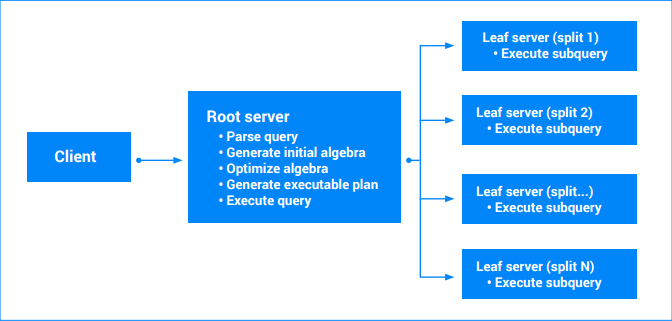
El plan de consultas ejecutable final se crea a partir del álgebra que se escribió de nuevo. En esencia, el plan ejecutable es un gráfico acíclico dirigido de “iteradores”. Con cada iterador, se expone una secuencia de valores. Los iteradores pueden consumir entradas para producir resultados (p. ej., el iterador de ordenación). Un solo servidor (el que contiene los datos) puede ejecutar las consultas que involucran una división única. El servidor analizará los rangos de varias tablas, ejecutará uniones, realizará la agregación y todas las otras operaciones que defina el álgebra de la consulta.
Las consultas que involucran varias divisiones se tendrán en cuenta en varias partes. Parte de la consulta seguirá en ejecución en el servidor principal (raíz). Otras subconsultas parciales se transferirán a nodos de hoja (los que poseen las divisiones que se intentan leer). Esta transferencia se puede aplicar de forma recurrente para las consultas complejas, lo que genera un árbol de ejecuciones de servidor. Todos los servidores acuerdan una marca de tiempo para que los resultados de la consulta sean una instantánea coherente de los datos. Cada servidor de hoja devuelve una transmisión de resultados parciales. En el caso de las consultas que incluyen agregación, podrían ser resultados agregados de forma parcial. El servidor raíz de consultas procesa los resultados de los servidores de hoja y ejecuta el resto del plan de consultas. Para obtener más información, consulta Planes de ejecución de consultas.
Cuando una consulta involucra varias divisiones, Spanner puede ejecutarla en paralelo en todas las divisiones. El grado de paralelismo depende del rango de datos que analiza la consulta, el plan de ejecución de la consulta y la distribución de los datos entre las divisiones. Spanner establece automáticamente el grado máximo de paralelismo para una consulta según su tamaño de instancia y su configuración (regional o multirregión) para lograr un rendimiento óptimo de las consultas y evitar sobrecargar la CPU.
Almacenamiento en caché
Muchos de los artefactos del procesamiento de consultas se almacenan en caché de manera automática y se vuelven a usar para consultas posteriores. Esto incluye álgebras de consulta, planes de consultas ejecutables, etcétera. El almacenamiento en caché se basa en el texto de la consulta, los nombres y los tipos de parámetros vinculados, entre otros. Por eso, es mejor usar parámetros vinculados (como @firstName en el ejemplo anterior) que usar valores literales en el texto de la consulta. El primero se puede almacenar en caché una vez y volverse a usar, sin importar el valor vinculado real. Consulta Cómo optimizar el rendimiento de las consultas de Spanner para obtener más información.
Manejo de errores
El flujo de filas de resultados del método executeQuery se puede interrumpir por
cualquier motivo: errores de red transitorios, transferencia de una división
de un servidor a otro (p.ej., balanceo de cargas), reinicios del servidor (p.ej.,
actualización a una versión nueva), etcétera. Para ayudar a recuperarse de estos errores,
Spanner envía “tokens de reanudación” opacos junto con lotes de datos de resultados parciales. Estos tokens de reanudación se pueden usar cuando se reintenta realizar la consulta para continuar donde se interrumpió. Si usas las bibliotecas cliente de Spanner, esto se hace de manera automática, por lo que los usuarios de la biblioteca cliente no necesitan preocuparse por este tipo de falla transitoria.