Artikel ini adalah bagian dari rangkaian yang membahas pemulihan bencana (DR) di Google Cloud. Bagian ini membahas proses untuk merancang workload menggunakan Google Cloud dan elemen penyusun yang tahan terhadap pemadaman layanan infrastruktur cloud.
Rangkaian ini terdiri dari bagian-bagian berikut:
- Panduan perencanaan pemulihan dari bencana
- Elemen penyusun pemulihan dari bencana
- Skenario pemulihan dari bencana untuk data
- Skenario pemulihan dari bencana untuk aplikasi
- Merancang pemulihan dari bencana untuk workload yang dibatasi lokalitas
- Kasus penggunaan pemulihan dari bencana: aplikasi analisis data yang dibatasi lokalitas
- Merancang pemulihan dari bencana untuk pemadaman layanan infrastruktur cloud (dokumen ini)
Pengantar
Saat perusahaan memindahkan workload ke cloud publik, mereka perlu menerjemahkan pemahaman mereka tentang membangun sistem lokal yang tangguh ke infrastruktur hyperscale penyedia cloud seperti Google Cloud. Artikel ini memetakan konsep standar industri seputar pemulihan dari bencana seperti RTO (Batas Waktu Pemulihan) dan RPO (Batas Titik Pemulihan) ke infrastruktur Google Cloud.
Panduan dalam dokumen ini mengikuti salah satu prinsip utama Google untuk mencapai ketersediaan layanan yang sangat tinggi, yaitu rencana untuk kegagalan. Meskipun Google Cloud menyediakan layanan yang sangat andal, bencana akan terjadi - bencana alam, gangguan koneksi fiber, dan kegagalan infrastruktur yang kompleks dan tidak dapat diprediksi - dan bencana ini menyebabkan pemadaman layanan. Dengan perencanaan pemadaman layanan,Google Cloud pelanggan dapat membangun aplikasi yang performanya dapat diprediksi melalui peristiwa yang tidak dapat dihindari ini, dengan memanfaatkan Google Cloud produk dengan mekanisme DR "bawaan".
Pemulihan dari bencana adalah topik luas yang mencakup lebih dari sekadar kegagalan infrastruktur, seperti bug software atau kerusakan data, dan Anda harus memiliki rencana end-to-end yang komprehensif. Namun, artikel ini berfokus pada satu bagian dari rencana DR secara keseluruhan: cara mendesain aplikasi yang tahan terhadap pemadaman layanan infrastruktur cloud. Secara khusus, artikel ini membahas:
- Infrastruktur Google Cloud , bagaimana peristiwa bencana termanifestasi sebagai Google Cloud pemadaman layanan, dan bagaimana Google Cloud dirancang untuk meminimalkan frekuensi dan cakupan pemadaman layanan.
- Panduan perencanaan arsitektur yang menyediakan framework untuk mengategorikan dan mendesain aplikasi berdasarkan hasil keandalan yang diinginkan.
- Daftar mendetail produk Google Cloud tertentu yang menawarkan kemampuan DR bawaan yang dapat digunakan di aplikasi Anda.
Untuk mengetahui detail lebih lanjut tentang perencanaan DR umum dan penggunaan Google Cloud sebagai komponen dalam strategi DR lokal Anda, lihat panduan perencanaan pemulihan dari bencana. Selain itu, meskipun Ketersediaan Tinggi adalah konsep yang terkait erat dengan pemulihan dari bencana, konsep ini tidak dibahas dalam artikel ini. Untuk mengetahui detail lebih lanjut tentang merancang untuk ketersediaan tinggi, lihat Framework yang Dirancang dengan Baik.
Catatan tentang terminologi: artikel ini merujuk pada ketersediaan ketika membahas kemampuan agar produk dapat diakses dan digunakan secara bermakna dari waktu ke waktu, sedangkan keandalan merujuk pada sekumpulan atribut termasuk ketersediaan, tetapi juga hal-hal seperti ketahanan dan ketepatan.
Cara Google Cloud dirancang untuk ketahanan
Pusat data Google
Pusat data tradisional mengandalkan pemaksimalan ketersediaan masing-masing komponen. Di cloud, skala memungkinkan operator seperti Google menyebarkan layanan di banyak komponen menggunakan teknologi virtualisasi, sehingga melampaui keandalan komponen tradisional. Ini berarti Anda dapat mengubah pola pikir arsitektur keandalan Anda dari berbagai detail yang sebelumnya Anda khawatirkan tentang infrastruktur lokal. Daripada khawatir tentang berbagai mode kegagalan komponen, seperti pendinginan dan pengiriman daya, Anda dapat membuat perencanaan seputar Google Cloud produk dan metrik keandalan yang dinyatakan. Metrik ini mencerminkan risiko pemadaman agregat dari seluruh infrastruktur yang mendasarinya. Hal ini membuat Anda dapat lebih berfokus pada desain, deployment, dan operasi aplikasi, bukan pada pengelolaan infrastruktur.
Google mendesain infrastrukturnya untuk memenuhi target ketersediaan yang agresif berdasarkan pengalaman kami yang luas dalam membangun dan menjalankan pusat data modern. Google adalah pemimpin dunia dalam desain pusat data. Mulai dari daya, pendinginan, hingga jaringan, setiap teknologi pusat data memiliki redundansi dan mitigasinya sendiri, termasuk rencana FMEA. Pusat data Google dibangun dengan cara yang menyeimbangkan berbagai risiko ini dan memberikan tingkat ketersediaan yang diharapkan secara konsisten untuk produk Google Cloud kepada pelanggan. Google menggunakan pengalamannya untuk membuat model ketersediaan keseluruhan arsitektur sistem fisik dan logis guna memastikan bahwa desain pusat data memenuhi ekspektasi. Engineer Google berupaya keras secara operasional untuk membantu memastikan harapan tersebut terpenuhi. Ketersediaan terukur yang sebenarnya biasanya melebihi target desain dengan margin yang nyaman.
Dengan mengurai semua risiko dan mitigasi pusat data ini menjadi produk yang ditampilkan kepada pengguna, Google Cloud membebaskan Anda dari tanggung jawab desain dan operasional tersebut. Sebagai gantinya, Anda dapat berfokus pada keandalan yang didesain ke dalam region dan zonaGoogle Cloud .
Region dan zona
Region adalah area geografis independen yang terdiri dari beberapa zona. Zona dan region adalah abstraksi logis dari resource fisik dasar. Untuk mengetahui informasi selengkapnya tentang pertimbangan khusus wilayah, lihat Geografi dan wilayah.
Google Cloud dibagi menjadi resource zona, resource regional, atau resource multi-regional.
Resource zona dihosting dalam satu zona. Gangguan layanan di zona tersebut dapat memengaruhi semua resource di zona tersebut. Misalnya, instance Compute Engine berjalan di satu zona tertentu; jika kegagalan hardware mengganggu layanan di zona tersebut, instance Compute Engine tersebut tidak akan tersedia selama durasi gangguan.
Resource regional di-deploy secara redundan di beberapa zona dalam satu region. Hal ini memberi mereka keandalan yang lebih tinggi dibandingkan dengan resource zona.
Resource multiregional didistribusikan di dalam dan di seluruh region. Secara umum, resource multi-regional memiliki keandalan yang lebih tinggi daripada resource regional. Namun, pada tingkat ini, produk harus mengoptimalkan ketersediaan, performa, dan efisiensi resource. Oleh karena itu, penting untuk memahami konsekuensi yang dilakukan oleh setiap produk multi-regional yang Anda putuskan untuk digunakan. Konsekuensi ini didokumentasikan berdasarkan produk tertentu di bagian selanjutnya dalam dokumen ini.
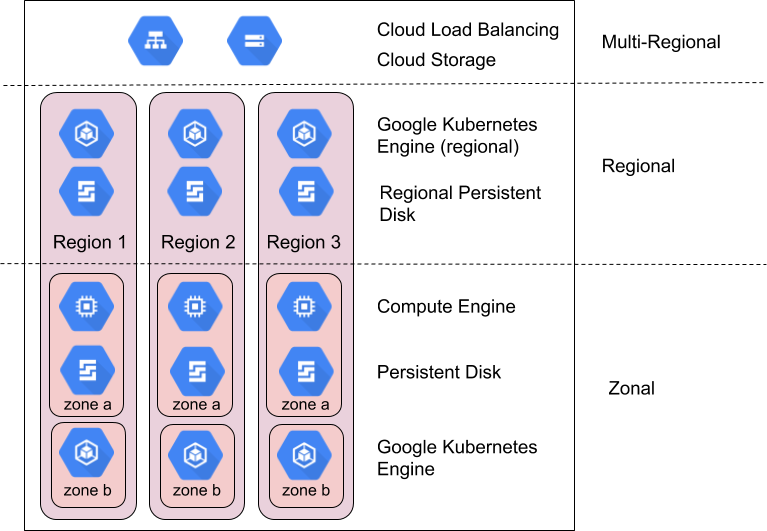
Cara memanfaatkan zona dan region untuk mencapai keandalan
Google SRE mengelola dan menskalakan produk pengguna global yang sangat andal seperti Gmail dan Penelusuran melalui berbagai teknik dan teknologi yang memanfaatkan infrastruktur komputasi di seluruh dunia dengan lancar. Hal ini termasuk mengalihkan traffic dari lokasi yang tidak tersedia menggunakan load balancing global, menjalankan beberapa replika di banyak lokasi di seluruh dunia, dan mereplikasi data di seluruh lokasi. Kemampuan yang sama ini tersedia bagi pelanggan Google Cloud melalui produk seperti Cloud Load Balancing, Google Kubernetes Engine (GKE), dan Spanner.
Google Cloud umumnya mendesain produk agar memberikan tingkat ketersediaan berikut untuk zona dan region:
| Resource | Contoh | Sasaran desain ketersediaan | Periode nonaktif tersirat |
|---|---|---|---|
| Zonal | Compute Engine, Persistent Disk | 99,9% | 8,75 jam/tahun |
| Regional | Cloud Storage Regional, Persistent Disk Replika, GKE Regional | 99,99% | 52 menit/tahun |
Bandingkan Google Cloud sasaran desain ketersediaan dengan tingkat periode nonaktif yang dapat diterima untuk mengidentifikasi Google Cloud resource yang sesuai. Sementara desain tradisional berfokus pada peningkatan ketersediaan tingkat komponen untuk meningkatkan ketersediaan aplikasi yang dihasilkan, model cloud berfokus pada komposisi komponen untuk mencapai sasaran ini. Banyak produk dalam Google Cloud menggunakan teknik ini. Misalnya, Spanner menawarkan database multi-region yang menyusun beberapa region untuk memberikan ketersediaan 99,999%.
Komposisi penting karena tanpanya, ketersediaan aplikasi Anda tidak akan dapat melebihi ketersediaan Google Cloud produk yang Anda gunakan; bahkan, kecuali aplikasi Anda tidak pernah gagal, aplikasi tersebut akan memiliki ketersediaan yang lebih rendah daripada produkGoogle Cloud yang mendasarinya. Bagian selanjutnya dari bagian ini menunjukkan secara umum cara menggunakan komposisi produk zona dan regional untuk mencapai ketersediaan aplikasi yang lebih tinggi daripada yang diberikan oleh satu zona atau region. Bagian berikutnya memberikan panduan praktis untuk menerapkan prinsip-prinsip ini pada aplikasi Anda.
Perencanaan cakupan pemadaman layanan zona
Kegagalan infrastruktur biasanya menyebabkan pemadaman layanan di satu zona. Dalam satu region, zona dirancang untuk meminimalkan risiko kegagalan berkorelasi dengan zona lain, dan gangguan layanan di satu zona biasanya tidak akan memengaruhi layanan dari zona lain di region yang sama. Pemadaman layanan yang mencakup suatu zona bukan berarti seluruh zona tidak tersedia, tetapi hanya menentukan batas insiden. Pemadaman layanan zona mungkin tidak memiliki efek nyata pada resource khusus Anda di zona tersebut.
Ini merupakan kejadian yang lebih jarang terjadi, tetapi penting juga untuk diperhatikan bahwa beberapa zona pada akhirnya masih akan mengalami pemadaman layanan berkorelasi pada waktu tertentu dalam satu region. Saat dua zona atau lebih mengalami pemadaman layanan, strategi cakupan pemadaman layanan regional di bawah ini berlaku.
Resource regional dirancang agar tahan terhadap pemadaman layanan zona dengan memberikan layanan dari komposisi beberapa zona. Jika salah satu zona yang mendukung resource regional terganggu, resource tersebut akan secara otomatis menyediakannya dari zona lain. Periksa deskripsi kemampuan produk dengan cermat di lampiran untuk mengetahui detail lebih lanjut.
Google Cloud hanya menawarkan beberapa resource zona, yaitu virtual machine (VM) dan Persistent Disk Compute Engine. Jika berencana menggunakan resource zona, Anda harus melakukan komposisi resource sendiri dengan mendesain, membangun, dan menguji failover dan pemulihan antara resource zona yang terletak di beberapa zona. Beberapa strategi termasuk:
- Mengarahkan traffic Anda dengan cepat ke virtual machine di zona lain menggunakan Cloud Load Balancing saat health check menentukan bahwa suatu zona mengalami masalah.
- Gunakan template instance Compute Engine dan/atau grup instance terkelola untuk menjalankan dan menskalakan instance VM yang identik di beberapa zona.
- Gunakan Persistent Disk regional untuk mereplikasi data secara sinkron ke zona lain di suatu region. Lihat Opsi ketersediaan tinggi yang menggunakan PD regional untuk mengetahui detail selengkapnya.
Perencanaan cakupan pemadaman layanan regional
Pemadaman layanan regional adalah gangguan layanan yang memengaruhi lebih dari satu zona di satu region. Ini adalah pemadaman layanan berskala lebih besar dan lebih jarang terjadi, serta dapat disebabkan oleh bencana alam atau kegagalan infrastruktur berskala besar.
Untuk produk regional yang dirancang untuk memberikan ketersediaan 99,99%, gangguan masih dapat mengakibatkan periode nonaktif mendekati satu jam untuk produk tertentu setiap tahunnya. Oleh karena itu, aplikasi penting Anda mungkin perlu memiliki rencana DR multi-region jika durasi pemadaman layanan ini tidak dapat diterima.
Resource multi-regional dirancang agar tahan terhadap pemadaman layanan region dengan memberikan layanan dari beberapa region. Seperti yang dijelaskan di atas, produk multi-region mengompromikan keseimbangan antara latensi, konsistensi, dan biaya. Konsekuensi yang paling umum adalah antara replikasi data sinkron dan asinkron. Replikas asinkron menawarkan latensi yang lebih rendah dengan mengorbankan risiko kehilangan data selama pemadaman layanan. Jadi, penting untuk memeriksa deskripsi kapabilitas produk dalam lampiran untuk mengetahui detail lebih lanjut.
Jika Anda ingin menggunakan resource regional serta tetap tangguh terhadap gangguan regional, Anda harus melakukan komposisi resource sendiri dengan mendesain, membangun, dan menguji failover dan pemulihannya di antara resource regional yang terletak di beberapa region. Selain strategi zona di atas, yang juga dapat Anda terapkan di seluruh region, pertimbangkan:
- Resource regional harus mereplikasi data ke region sekunder, ke opsi penyimpanan multi-regional seperti Cloud Storage, atau opsi hybrid cloud seperti GKE Enterprise.
- Setelah Anda menerapkan mitigasi pemadaman layanan regional, uji secara rutin. Ada beberapa hal yang lebih buruk daripada berpikir Anda tahan terhadap pemadaman layanan di satu region, tetapi ternyata hal ini tidak terjadi padahal hal tersebut benar-benar terjadi.
Pendekatan ketahanan dan ketersediaanGoogle Cloud
Google Cloud secara teratur mengalahkan target desain ketersediaannya, tetapi Anda tidak boleh berasumsi bahwa performa masa lalu yang kuat ini adalah ketersediaan minimum yang dapat Anda desain. Sebagai gantinya, Anda harus memilih dependensi Google Cloud yang targetnya dirancang untuk melampaui keandalan aplikasi Anda yang dimaksudkan, sehingga periode nonaktif aplikasi ditambah periode nonaktif Google Cloud memberikan hasil yang Anda cari. Google Cloud
Sistem yang dirancang dengan baik dapat menjawab pertanyaan: "Apa yang terjadi saat zona atau region mengalami pemadaman layanan selama 1, 5, 10, atau 30 menit?" Hal ini harus dipertimbangkan di banyak lapisan, termasuk:
- Apa yang akan dialami pelanggan saya selama pemadaman layanan?
- Bagaimana cara mendeteksi terjadinya pemadaman layanan?
- Apa yang terjadi pada aplikasi saya selama pemadaman layanan?
- Apa yang terjadi pada data saya selama pemadaman layanan?
- Apa yang terjadi pada aplikasi saya yang lain karena pemadaman layanan (akibat lintas dependensi)?
- Apa yang harus saya lakukan untuk melakukan pemulihan setelah pemadaman layanan teratasi? Siapa yang melakukannya?
- Siapa yang harus saya beri tahu tentang pemadaman layanan, dalam jangka waktu berapa?
Panduan langkah demi langkah untuk mendesain pemulihan dari bencana untuk aplikasi di Google Cloud
Bagian sebelumnya membahas cara Google membangun infrastruktur cloud, dan beberapa pendekatan untuk menangani pemadaman layanan zona dan regional.
Bagian ini membantu Anda mengembangkan framework untuk menerapkan prinsip komposisi ke aplikasi berdasarkan hasil keandalan yang Anda inginkan.
Aplikasi pelanggan yang menargetkan tujuan pemulihan dari bencana seperti RTO dan RPO harus dirancang sedemikian rupa sehingga operasi penting bisnis, yang tunduk pada RTO/RPO, hanya memiliki dependensi pada komponen bidang data yang bertanggung jawab atas pemrosesan operasi berkelanjutan untuk layanan. Google Cloud Dengan kata lain, operasi bisnis pelanggan yang penting tersebut tidak boleh bergantung pada operasi bidang pengelolaan, yang mengelola status konfigurasi dan mendorong konfigurasi ke bidang kontrol dan bidang data.
Misalnya, Google Cloud pelanggan yang ingin mencapai RTO untuk operasi yang penting bagi bisnis tidak boleh bergantung pada API pembuatan VM atau update izin IAM.
Langkah 1: Kumpulkan persyaratan yang ada
Langkah pertama adalah menentukan persyaratan ketersediaan untuk aplikasi Anda. Sebagian besar perusahaan sudah memiliki panduan desain tingkat tertentu dalam bidang ini, yang dapat dikembangkan secara internal atau berasal dari peraturan atau persyaratan hukum lainnya. Panduan desain ini biasanya dikodifikasi dalam dua metrik utama: Batas Waktu Pemulihan (RTO) dan Batas Titik Pemulihan (RPO). Dalam istilah bisnis, RTO diterjemahkan sebagai "Berapa lama setelah bencana, saya baru dapat beroperasi." RPO diterjemahkan sebagai "Berapa banyak data yang bisa saya tanggung jika terjadi bencana."

Secara historis, perusahaan telah menentukan persyaratan RTO dan RPO untuk berbagai peristiwa bencana, mulai dari kegagalan komponen hingga gempa bumi. Hal ini masuk akal di dunia lokal, karena perencana harus memetakan persyaratan RTO/RPO melalui seluruh stack software dan hardware. Di cloud, Anda tidak perlu lagi menentukan persyaratan dengan detail seperti itu karena penyedia akan menanganinya. Sebagai gantinya, Anda dapat menentukan persyaratan RTO dan RPO dalam cakupan kerugian (seluruh zona atau region) tanpa harus spesifik tentang alasan yang mendasarinya. Untuk Google Cloud , hal ini menyederhanakan pengumpulan persyaratan Anda menjadi 3 skenario: pemadaman layanan zona, pemadaman layanan regional, atau gangguan yang sangat jarang terjadi pada beberapa region.
Menyadari bahwa tidak semua aplikasi memiliki kritis yang sama, sebagian besar pelanggan mengategorikan aplikasi ke dalam tingkat kekritisan yang dapat digunakan untuk menerapkan persyaratan RTO/RPO tertentu. Saat digunakan bersamaan, RTO/RPO dan kekritisan aplikasi menyederhanakan proses perancangan aplikasi tertentu dengan menjawab:
- Apakah aplikasi perlu berjalan di beberapa zona di region yang sama, atau di beberapa zona di beberapa region?
- Pada produk Google Cloud mana aplikasi dapat bergantung?
Berikut adalah contoh output dari latihan pengumpulan persyaratan:
RTO dan RPO menurut Kekritisan Aplikasi untuk Contoh Organisasi Co:
| Kekritisan aplikasi | % dari Aplikasi | Aplikasi contoh | Pemadaman layanan zona | Pemadaman layanan region |
|---|---|---|---|---|
| Paket 1
(paling penting) |
5% | Biasanya berupa aplikasi yang ditujukan untuk pelanggan global atau eksternal, seperti pembayaran real-time dan etalase e-commerce. | RTO Nol
RPO Nol |
RTO Nol
RPO Nol |
| Paket 2 | 35% | Biasanya, aplikasi regional atau aplikasi internal penting, seperti CRM atau ERP. | RTO 15 mnt
RPO 15 mnt |
RTO 1 jam
RPO 1 jam |
| Tingkat 3
(paling tidak penting) |
60% | Biasanya, aplikasi departemen atau tim, seperti back office, pemesanan cuti, perjalanan internal, akuntansi, dan HR. | RTO 1 jam
RPO 1 jam |
RTO 12 jam
RPO 12 jam |
Langkah 2: Pemetaan kemampuan ke produk yang tersedia
Langkah kedua adalah memahami kemampuan ketahanan produk Google Cloud yang akan digunakan aplikasi Anda. Sebagian besar perusahaan meninjau informasi produk yang relevan, lalu menambahkan panduan tentang cara memodifikasi arsitektur untuk mengakomodasi kesenjangan antara kemampuan produk dan persyaratan ketahanan mereka. Bagian ini membahas beberapa area umum dan rekomendasi seputar data dan batasan aplikasi di ruang ini.
Seperti yang disebutkan sebelumnya, produk Google dengan DR tersedia secara luas untuk dua jenis cakupan pemadaman layanan: regional dan zona. Pemadaman layanan sebagian harus direncanakan dengan cara yang sama seperti pemadaman layanan total ketika berhubungan dengan DR. Tindakan ini akan memberikan matriks tingkat tinggi awal yang berisi produk yang cocok untuk setiap skenario secara default:
Google Cloud Kemampuan Umum Produk
(lihat Lampiran untuk mengetahui kemampuan produk tertentu)
| Semua Google Cloud produk | Produk regional dengan replikasi otomatis di seluruh zona Google Cloud | Produk Google Cloud multi-regional atau global dengan replikasi otomatis di berbagai region | |
|---|---|---|---|
| Terjadi kegagalan komponen dalam suatu zona | Tercakup* | Tercakup | Tercakup |
| Pemadaman layanan zona | Tidak dicakup | Tercakup | Tercakup |
| Pemadaman layanan region | Tidak dicakup | Tidak dicakup | Tercakup |
* Semua Google Cloud produk tahan terhadap kegagalan komponen, kecuali dalam kasus tertentu yang disebutkan dalam dokumentasi produk. Hal ini biasanya merupakan skenario saat produk menawarkan akses langsung atau pemetaan statis ke hardware khusus seperti memori atau Solid State Disk (SSD).
Cara RPO membatasi pilihan produk
Dalam sebagian besar deployment cloud, integritas data adalah aspek arsitektur yang paling signifikan yang harus dipertimbangkan untuk suatu layanan. Setidaknya beberapa aplikasi memiliki persyaratan RPO nol, yang berarti tidak boleh ada kehilangan data jika terjadi pemadaman layanan. Hal ini biasanya mengharuskan data direplikasi secara sinkron ke zona atau region lain. Replikasi sinkron memiliki konsekuensi biaya dan latensi. Jadi, meskipun banyak produk Google Cloud menyediakan replikasi sinkron di seluruh zona, hanya beberapa yang menyediakannya di seluruh region. Harga dan kompleksitas ini berarti bahwa tidak biasa jika berbagai jenis data dalam aplikasi memiliki nilai RPO yang berbeda.
Untuk data dengan RPO lebih besar dari nol, aplikasi dapat memanfaatkan replikasi asinkron. Replikasi asinkron dapat diterima jika data yang hilang dapat dibuat ulang dengan mudah, atau dapat dipulihkan dari sumber data emas jika diperlukan. Hal ini juga bisa menjadi pilihan yang wajar jika sejumlah kecil kehilangan data merupakan kompromi yang dapat diterima dalam konteks durasi pemadaman layanan yang diperkirakan zona dan regional. Perlu juga diperhatikan bahwa selama pemadaman layanan sementara, data yang ditulis ke lokasi yang terpengaruh tetapi belum direplikasi ke lokasi lain umumnya akan tersedia setelah pemadaman layanan teratasi. Artinya, risiko kehilangan data permanen lebih rendah daripada risiko kehilangan akses data selama pemadaman layanan.
Tindakan penting: Tentukan apakah Anda benar-benar memerlukan RPO zero, dan jika ya, apakah Anda dapat melakukan hal ini untuk subset data atau tidak - hal ini secara drastis meningkatkan rentang layanan diaktifkan DR yang tersedia kepada Anda. Di Google Cloud, mencapai RPO nol berarti menggunakan sebagian besar produk regional untuk aplikasi Anda, yang secara default tahan terhadap pemadaman layanan berskala zona, tetapi tidak berskala region.
Cara RTO membatasi pilihan produk
Salah satu manfaat utama cloud computing adalah kemampuan untuk men-deploy infrastruktur sesuai permintaan; namun, ini tidak sama dengan deployment langsung. Nilai RTO untuk aplikasi Anda harus mengakomodasi RTO gabungan produk Google Cloud yang digunakan aplikasi Anda dan tindakan apa pun yang harus dilakukan engineer atau SRE untuk memulai ulang VM atau komponen aplikasi Anda. RTO yang diukur dalam menit berarti mendesain aplikasi yang memulihkan secara otomatis dari bencana tanpa campur tangan manusia, atau dengan langkah-langkah minimal seperti menekan tombol ke failover. Biaya dan kompleksitas sistem semacam ini secara historis sangat tinggi, tetapi produk Google Cloud seperti load balancer dan grup instance membuat desain ini jauh lebih terjangkau dan sederhana. Oleh karena itu, Anda harus mempertimbangkan failover dan pemulihan otomatis untuk sebagian besar aplikasi. Perlu diketahui bahwa mendesain sistem untuk hot failover semacam ini di seluruh region terkadang rumit dan mahal; hanya sebagian kecil layanan penting yang dapat menjamin kemampuan ini.
Sebagian besar aplikasi akan memiliki RTO antara satu jam dan sehari, yang memungkinkan failover yang hangat dalam skenario bencana, dengan beberapa komponen aplikasi berjalan setiap saat dalam mode standby--seperti database --sementara yang lain akan diskalakan jika terjadi bencana yang sebenarnya, seperti server web. Untuk aplikasi ini, Anda harus mempertimbangkan otomatisasi untuk peristiwa penyebaran skala. Layanan dengan RTO selama satu hari adalah hal penting terendah dan sering kali dapat dipulihkan dari cadangan atau dibuat ulang dari awal.
Tindakan utama: Tentukan apakah Anda benar-benar memerlukan RTO (hampir) nol untuk failover regional, dan jika ya, apakah Anda dapat melakukannya untuk subset layanan Anda atau tidak. Ini mengubah biaya menjalankan dan memelihara layanan Anda.
Langkah 3: Kembangkan arsitektur dan panduan referensi Anda sendiri
Langkah terakhir yang direkomendasikan adalah membangun pola arsitektur spesifik per perusahaan Anda sendiri untuk membantu tim Anda menstandarkan pendekatan mereka terhadap pemulihan dari bencana. Sebagian besar Google Cloud pelanggan membuat panduan bagi tim pengembangan mereka yang sesuai dengan ekspektasi ketahanan masing-masing bisnis mereka dengan dua kategori utama skenario pemadaman layanan di Google Cloud. Hal ini memungkinkan tim dengan mudah mengategorikan produk diaktifkan DR yang sesuai untuk setiap tingkat kekritisan.
Buat panduan produk
Dengan melihat kembali contoh tabel RTO/RPO di atas, Anda memiliki panduan hipotetis yang mencantumkan produk mana yang akan diizinkan secara default untuk setiap tingkat kritis. Perhatikan bahwa jika produk tertentu telah diidentifikasi sebagai tidak cocok secara default, Anda selalu dapat menambahkan replikasi dan mekanisme failover sendiri untuk mengaktifkan sinkronisasi lintas zona atau lintas-region, tetapi latihan ini di luar cakupan artikel ini. Tabel ini juga memberikan link ke informasi lebih lanjut tentang setiap produk untuk membantu Anda memahami kemampuannya dalam mengelola pemadaman layanan zona atau region.
Contoh Pola Arsitektur untuk Contoh Organisasi Co -- Ketahanan Pemadaman Layanan Zona
| Google Cloud Produk | Apakah produk memenuhi persyaratan pemadaman layanan zona untuk Contoh Organisasi (dengan konfigurasi produk yang sesuai) | ||
|---|---|---|---|
| Paket 1 | Tingkat 2 | Tingkat 3 | |
| Compute Engine | Tidak | Tidak | Tidak |
| Dataflow | Tidak | Tidak | Tidak |
| BigQuery | Tidak | Tidak | Ya |
| GKE | Ya | Ya | Ya |
| Cloud Storage | Ya | Ya | Ya |
| Cloud SQL | Tidak | Ya | Ya |
| Spanner | Ya | Ya | Ya |
| Cloud Load Balancing | Ya | Ya | Ya |
Tabel ini hanyalah contoh yang hanya didasarkan pada tingkatan hipotetis yang ditampilkan di atas.
Contoh Pola Arsitektur untuk Contoh Organisasi Co -- Ketahanan Pemadaman Layanan Region
| Google Cloud Produk | Apakah produk memenuhi persyaratan pemadaman layanan untuk Contoh Organisasi (dengan konfigurasi produk yang sesuai) | ||
|---|---|---|---|
| Paket 1 | Tingkat 2 | Tingkat 3 | |
| Compute Engine | Ya | Ya | Ya |
| Dataflow | Tidak | Tidak | Tidak |
| BigQuery | Tidak | Tidak | Ya |
| GKE | Ya | Ya | Ya |
| Cloud Storage | Tidak | Tidak | Tidak |
| Cloud SQL | Tidak | Ya | Ya |
| Spanner | Ya | Ya | Ya |
| Cloud Load Balancing | Ya | Ya | Ya |
Tabel ini hanyalah contoh yang hanya didasarkan pada tingkatan hipotetis yang ditampilkan di atas.
Untuk menunjukkan cara produk ini akan digunakan, bagian berikut akan membahas beberapa arsitektur referensi untuk setiap tingkat kekritisan aplikasi hipotesis. Deskripsi ini sengaja dibuat untuk menggambarkan keputusan arsitektur utama, dan tidak mewakili desain solusi yang lengkap.
Contoh arsitektur tingkat 3
| Kekritisan aplikasi | Pemadaman layanan zona | Pemadaman layanan region |
|---|---|---|
| Tingkat 3 (paling tidak penting) |
RTO 12 jam RPO 24 jam |
RTO 28 hari RPO 24 jam |
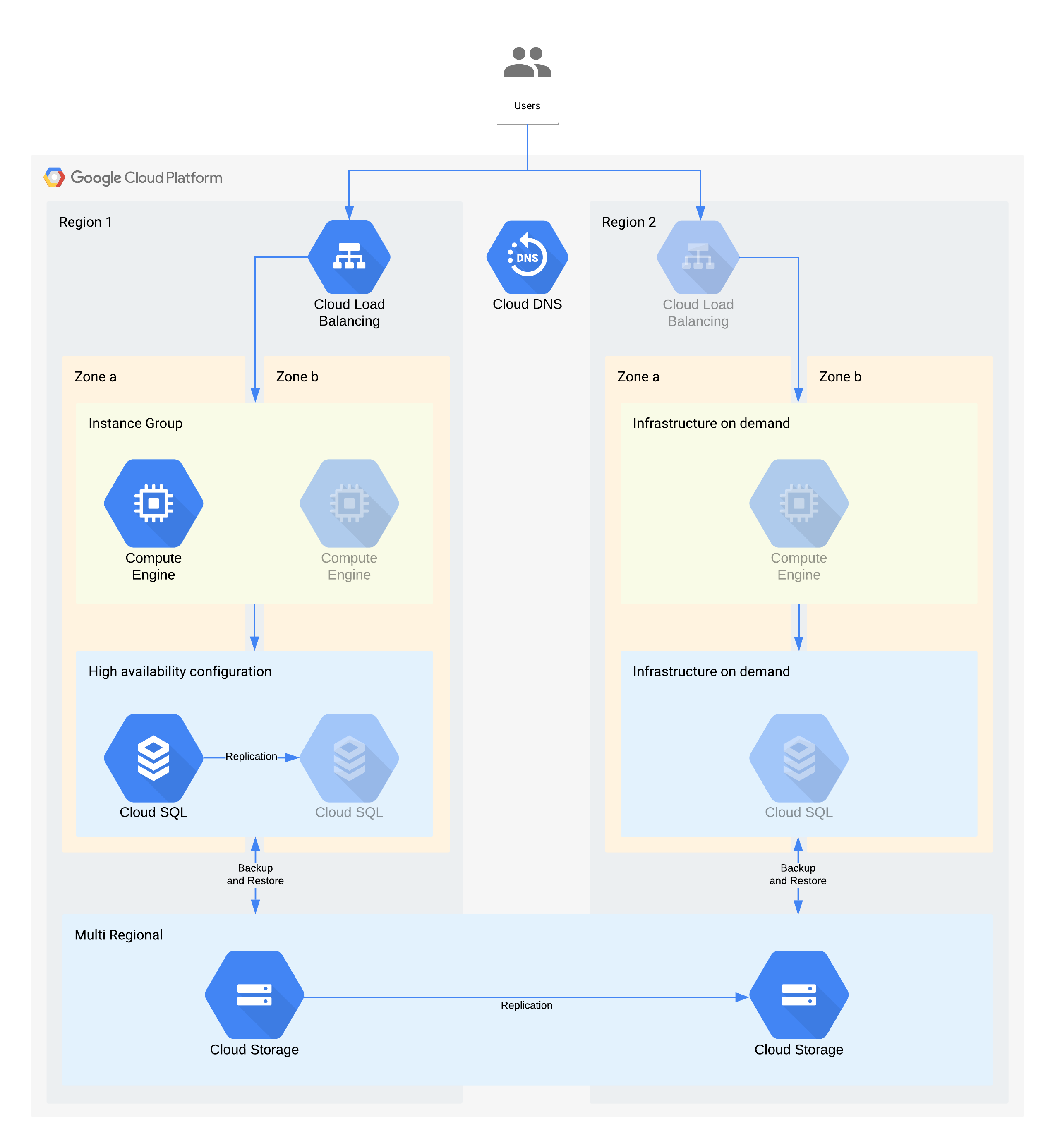
(Ikon berwarna abu-abu menunjukkan infrastruktur yang akan diaktifkan untuk pemulihan)
Arsitektur ini menjelaskan aplikasi klien/server tradisional: pengguna internal terhubung ke aplikasi yang berjalan pada instance komputasi yang didukung oleh database untuk penyimpanan persisten.
Penting untuk diperhatikan bahwa arsitektur ini mendukung nilai RTO dan RPO yang lebih baik daripada yang diperlukan. Namun, Anda juga harus mempertimbangkan untuk menghilangkan langkah-langkah manual tambahan jika langkah-langkah tersebut dapat menghasilkan biaya yang mahal atau tidak dapat diandalkan. Misalnya, pemulihan database dari pencadangan setiap malam dapat mendukung RPO selama 24 jam, tetapi hal ini biasanya memerlukan individu terampil seperti administrator database yang mungkin tidak tersedia, terutama jika ada beberapa layanan pada waktu yang sama. Dengan infrastruktur on demand Google Cloud, Anda dapat membangun kemampuan ini tanpa menimbulkan kompromi biaya yang besar, sehingga arsitektur ini menggunakan HA Cloud SQL, bukan pencadangan/pemulihan manual untuk pemadaman layanan zona.
Keputusan arsitektur penting untuk pemadaman layanan zona - RTO 12 jam dan RPO 24 jam:
- Load balancer internal digunakan untuk menyediakan titik akses yang skalabel bagi pengguna, yang memungkinkan failover otomatis ke zona lain. Meskipun RTO memerlukan waktu 12 jam, perubahan manual pada alamat IP atau bahkan update DNS dapat memerlukan waktu lebih lama dari yang diperkirakan.
- Grup instance terkelola regional dikonfigurasi dengan beberapa zona, tetapi dengan resource minimal. Hal ini mengoptimalkan biaya, tetapi masih memungkinkan virtual machine diskalakan dengan cepat di zona pencadangan.
- Konfigurasi Cloud SQL ketersediaan tinggi menyediakan failover otomatis ke zona lain. Database jauh lebih sulit untuk dibuat ulang dan dipulihkan dibandingkan dengan mesin virtual Compute Engine.
Keputusan arsitektur penting untuk pemadaman layanan region - RTO 28 Hari dan RPO 24 jam:
- Load balancer hanya akan dibuat di region 2 jika terjadi pemadaman layanan regional. Cloud DNS digunakan untuk menyediakan kemampuan failover regional yang terstruktur tetapi manual, karena infrastruktur di region 2 hanya akan tersedia jika terjadi pemadaman layanan region.
- Grup instance terkelola baru hanya akan dibuat jika terjadi pemadaman layanan region. Hal ini mengoptimalkan biaya dan kemungkinan tidak akan dipanggil mengingat sebagian besar pemadaman layanan regional yang singkat. Perlu diperhatikan bahwa agar lebih mudah, diagram tidak menampilkan alat terkait yang diperlukan untuk men-deploy ulang, atau penyalinan image Compute Engine yang diperlukan.
- Instance Cloud SQL baru akan dibuat ulang dan data dipulihkan dari cadangan. Sekali lagi, risiko pemadaman layanan yang berkepanjangan di suatu region sangat rendah, sehingga ini adalah salah satu kompromi pengoptimalan biaya.
- Cloud Storage multi-regional digunakan untuk menyimpan cadangan ini. Hal ini memberikan ketahanan regional dan zona otomatis dalam RTO dan RPO.
Contoh arsitektur tingkat 2
| Kekritisan aplikasi | Pemadaman layanan zona | Pemadaman layanan region |
|---|---|---|
| Paket 2 | RTO 4 jam RPO nol |
RTO 24 jam RPO 4 jam |
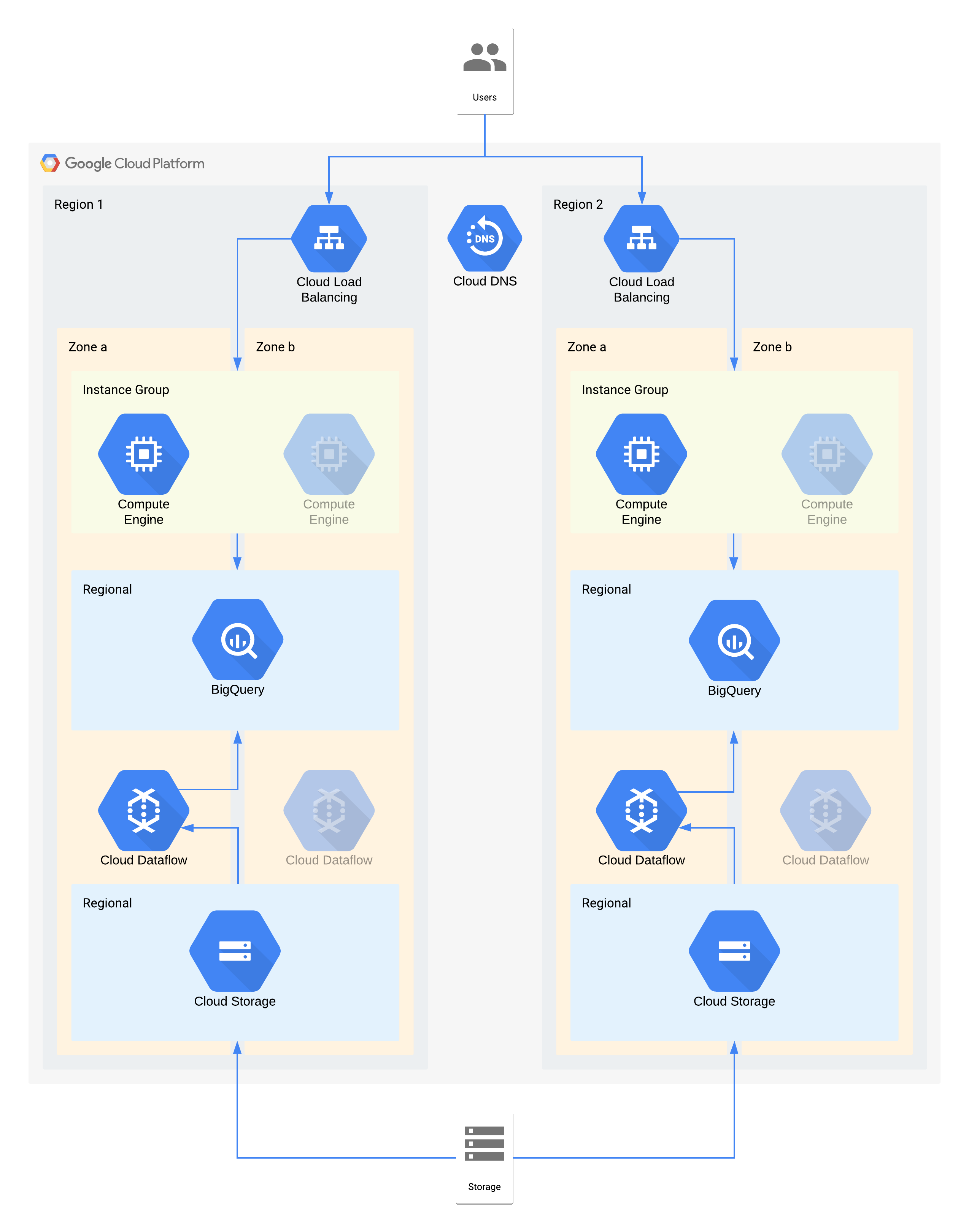
Arsitektur ini menjelaskan data warehouse dengan pengguna internal yang terhubung ke lapisan visualisasi instance komputasi, serta lapisan penyerapan dan transformasi data yang mengisi data warehouse backend.
Beberapa komponen individual arsitektur ini tidak secara langsung mendukung RPO yang diperlukan untuk tingkatnya. Namun, karena cara keduanya digunakan bersama, layanan secara keseluruhan memenuhi RPO. Dalam hal ini, karena Dataflow adalah produk zona, ikuti rekomendasi desain ketersediaan tinggi untuk membantu mencegah kehilangan data selama pemadaman layanan. Namun, lapisan Cloud Storage adalah sumber emas dari data ini dan mendukung RPO nol. Hasilnya, Anda dapat menyerap ulang data yang hilang ke BigQuery dengan menggunakan zona b jika terjadi pemadaman layanan di zona a.
Keputusan arsitektur penting untuk pemadaman layanan zona - RTO 4 jam dan RPO nol:
- Load balancer digunakan untuk menyediakan titik akses yang skalabel bagi pengguna, sehingga memungkinkan failover otomatis ke zona lain. Meskipun RTO memerlukan waktu 4 jam, perubahan manual pada alamat IP atau bahkan update DNS dapat memerlukan waktu lebih lama dari yang diperkirakan.
- Grup instance terkelola regional untuk lapisan komputasi visualisasi data dikonfigurasi dengan beberapa zona, tetapi dengan resource minimal. Hal ini mengoptimalkan biaya, tetapi masih memungkinkan virtual machine diskalakan dengan cepat.
- Cloud Storage regional digunakan sebagai lapisan staging untuk penyerapan awal data, sehingga memberikan ketahanan zona otomatis.
- Dataflow digunakan untuk mengekstrak data dari Cloud Storage dan mengubahnya sebelum memuatnya ke BigQuery. Jika terjadi pemadaman layanan zona, ini adalah proses stateless yang dapat dimulai ulang di zona lain.
- BigQuery menyediakan backend data warehouse untuk front end visualisasi data. Jika terjadi pemadaman layanan zona, data apa pun yang hilang akan diserap kembali dari Cloud Storage.
Keputusan arsitektur penting untuk pemadaman layanan region - RTO 24 jam dan RPO 4 jam:
- Load balancer di setiap region digunakan untuk menyediakan titik akses yang skalabel bagi pengguna. Cloud DNS digunakan untuk menyediakan kemampuan failover regional yang terstruktur tetapi manual, karena infrastruktur di region 2 hanya akan tersedia jika terjadi pemadaman layanan region.
- Grup instance terkelola regional untuk lapisan komputasi visualisasi data dikonfigurasi dengan beberapa zona, tetapi dengan resource minimal. Opsi ini tidak dapat diakses hingga load balancer dikonfigurasi ulang, tetapi sebaliknya tidak memerlukan intervensi manual.
- Cloud Storage regional digunakan sebagai lapisan staging untuk penyerapan awal data. Ini dimuat secara bersamaan ke kedua region untuk memenuhi persyaratan RPO.
- Dataflow digunakan untuk mengekstrak data dari Cloud Storage dan mengubahnya sebelum memuatnya ke BigQuery. Jika terjadi pemadaman layanan region, BigQuery akan mengisi BigQuery dengan data terbaru dari Cloud Storage.
- BigQuery menyediakan backend data warehouse. Dalam operasi normal, pembaruan ini akan diperbarui sesekali. Jika terjadi pemadaman layanan region, data terbaru akan diserap ulang melalui Dataflow dari Cloud Storage.
Contoh arsitektur tingkat 1
| Kekritisan aplikasi | Pemadaman layanan zona | Pemadaman layanan region |
|---|---|---|
| Tingkat 1 (paling penting) |
RTO nol RPO nol |
RTO 4 jam RPO 1 jam |
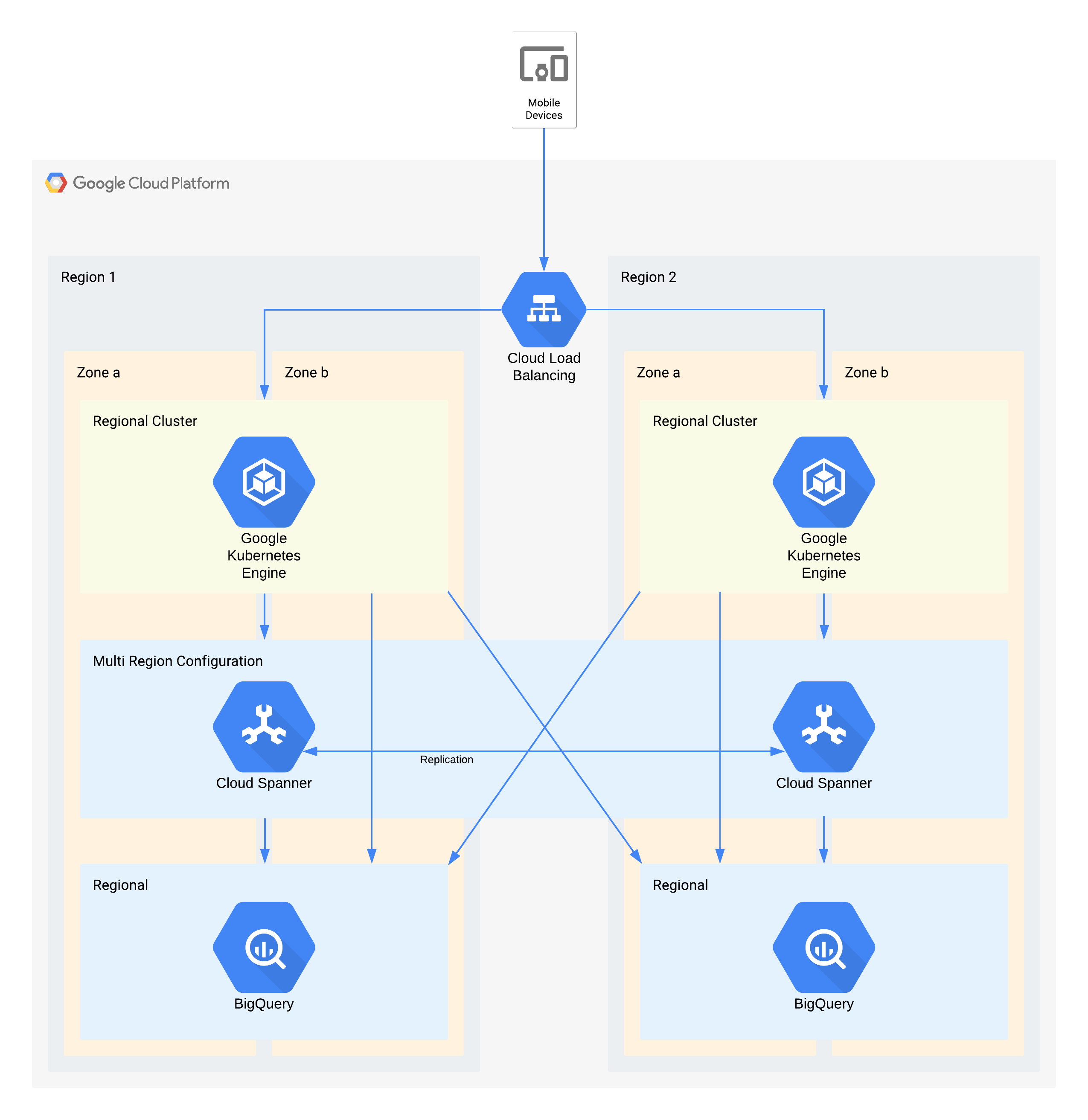
Arsitektur ini menjelaskan infrastruktur backend aplikasi seluler dengan pengguna eksternal yang terhubung ke serangkaian microservice yang berjalan di GKE. Spanner menyediakan lapisan penyimpanan data backend untuk data real time, dan data historis di-streaming ke data lake BigQuery di setiap region.
Sekali lagi, beberapa komponen individual dari arsitektur ini tidak secara langsung mendukung RPO yang diperlukan untuk tingkatnya, tetapi karena cara mereka digunakan bersama, layanan secara keseluruhan dapat mendukungnya. Dalam hal ini, BigQuery digunakan untuk kueri analitik. Setiap region disalurkan secara bersamaan dari Spanner.
Keputusan arsitektur penting untuk pemadaman layanan zona - RTO nol dan RPO nol:
- Load balancer digunakan untuk menyediakan titik akses yang skalabel bagi pengguna, sehingga memungkinkan failover otomatis ke zona lain.
- Cluster GKE regional digunakan untuk lapisan aplikasi yang dikonfigurasi dengan beberapa zona. Cara ini menghasilkan RTO nol dalam setiap wilayah.
- Spanner multi-region digunakan sebagai lapisan persistensi data, yang memberikan ketahanan data zona otomatis dan konsistensi transaksi.
- BigQuery memberikan kemampuan analisis untuk aplikasi. Setiap region menerima data secara independen dari Spanner, dan diakses secara independen oleh aplikasi.
Keputusan arsitektur penting untuk pemadaman layanan region - RTO 4 jam dan RPO 1 jam:
- Load balancer digunakan untuk menyediakan titik akses yang skalabel bagi pengguna, sehingga memungkinkan failover otomatis ke region lain.
- Cluster GKE regional digunakan untuk lapisan aplikasi yang dikonfigurasi dengan beberapa zona. Jika terjadi pemadaman layanan region, cluster di region alternatif akan otomatis diskalakan untuk menerima beban pemrosesan tambahan.
- Spanner multi-region digunakan sebagai lapisan persistensi data, yang memberikan ketahanan data regional dan konsistensi transaksi secara otomatis. Ini adalah komponen kunci dalam mencapai RPO lintas region selama 1 jam.
- BigQuery memberikan kemampuan analisis untuk aplikasi. Setiap region menerima data secara independen dari Spanner, dan diakses secara independen oleh aplikasi. Arsitektur ini mengompensasi komponen BigQuery yang membuatnya cocok dengan persyaratan aplikasi secara keseluruhan.
Lampiran: Referensi produk
Bagian ini menjelaskan arsitektur dan kemampuan DR produk Google Cloud yang paling umum digunakan dalam aplikasi pelanggan dan yang dapat dimanfaatkan dengan mudah untuk mencapai persyaratan DR Anda.
Tema umum
Banyak Google Cloud produk menawarkan konfigurasi regional atau multi-regional. Produk regional tahan terhadap pemadaman layanan zona, dan produk multi-region serta global tahan terhadap pemadaman layanan region. Secara umum, hal ini berarti selama pemadaman layanan, aplikasi Anda akan mengalami sedikit gangguan. Google mencapai hasil ini melalui beberapa pendekatan arsitektur umum, yang mencerminkan panduan arsitektur di atas.
Deployment redundan: Backend aplikasi dan penyimpanan data di-deploy di beberapa zona dalam satu region dan beberapa region dalam lokasi multi-region. Untuk mengetahui informasi selengkapnya tentang pertimbangan khusus wilayah, lihat Geografi dan wilayah.
Replikasi data: Produk menggunakan replikasi sinkron atau asinkron di lokasi redundan.
Replikasi sinkron berarti ketika aplikasi Anda melakukan panggilan API untuk membuat atau mengubah data yang disimpan oleh produk, aplikasi tersebut hanya menerima respons yang berhasil setelah produk menulis data ke beberapa lokasi. Replikasi sinkron memastikan Anda tidak kehilangan akses ke data mana pun selama pemadaman layanan infrastruktur Google Cloud karena semua data Anda tersedia di salah satu lokasi backend yang tersedia.
Meskipun memberikan perlindungan data maksimum, teknik ini memiliki konsekuensi dalam hal latensi dan performa. Produk multi-region yang menggunakan replikasi sinkron mengalami kompromi yang paling signifikan -- biasanya dalam urutan 10 atau 100 milidetik latensi tambahan.
Replikasi asinkron berarti ketika aplikasi Anda melakukan panggilan API untuk membuat atau mengubah data yang disimpan oleh produk, aplikasi tersebut akan menerima respons yang berhasil setelah produk menulis data ke satu lokasi. Setelah permintaan tulis Anda, produk akan mereplikasi data Anda ke lokasi tambahan.
Teknik ini memberikan latensi yang lebih rendah dan throughput yang lebih tinggi di API daripada replikasi sinkron, tetapi dengan mengorbankan perlindungan data. Jika lokasi tempat Anda memiliki data tertulis mengalami pemadaman layanan sebelum replikasi selesai, Anda akan kehilangan akses ke data tersebut hingga pemadaman layanan lokasi teratasi.
Menangani pemadaman layanan dengan load balancing: Google Cloud menggunakan load balancing software untuk merutekan permintaan ke backend aplikasi yang sesuai. Dibandingkan dengan pendekatan lain seperti load balancing DNS, pendekatan ini mengurangi waktu respons sistem terhadap pemadaman layanan. Saat terjadi Google Cloud pemadaman layanan lokasi Google Cloud, load balancer langsung mendeteksi bahwa backend yang di-deploy di lokasi tersebut menjadi "tidak responsif" dan mengarahkan semua permintaan ke backend di lokasi alternatif. Hal ini memungkinkan produk untuk terus melayani permintaan aplikasi Anda selama pemadaman layanan lokasi terjadi. Saat pemadaman layanan lokasi teratasi, load balancer mendeteksi ketersediaan backend produk di lokasi tersebut, dan melanjutkan pengiriman traffic ke sana.
Access Context Manager
Access Context Manager dapat digunakan perusahaan untuk mengonfigurasi tingkat akses yang dipetakan ke kebijakan yang ditentukan berdasarkan atribut permintaan. Kebijakan dicerminkan secara regional.
Jika terjadi pemadaman layanan zona, permintaan ke zona yang tidak tersedia akan secara otomatis dan transparan disalurkan dari zona lain yang tersedia di region tersebut.
Jika terjadi pemadaman layanan regional, penghitungan kebijakan dari region yang terpengaruh tidak akan tersedia hingga region tersebut tersedia kembali.
Transparansi Akses
Transparansi Akses memungkinkan administrator organisasi menentukan kontrol akses berbasis atribut yang terperinci untuk project dan resource di Google Cloud. Google Cloud Terkadang, Google harus mengakses data pelanggan untuk tujuan administratif. Saat kami mengakses data pelanggan, Transparansi Akses memberikan log akses kepada pelanggan yang terpengaruh. Google CloudLog Transparansi Akses ini membantu memastikan komitmen Google terhadap transparansi dan keamanan data dalam penanganan data.
Transparansi Akses tahan terhadap pemadaman layanan di level zona dan regional. Jika terjadi pemadaman layanan zona atau regional, Transparansi Akses akan terus memproses log akses administratif di zona atau region lain.
AlloyDB untuk PostgreSQL
AlloyDB untuk PostgreSQL adalah layanan database yang kompatibel dengan PostgreSQL dan terkelola sepenuhnya. AlloyDB untuk PostgreSQL menawarkan ketersediaan tinggi di suatu region melalui node redundan instance utamanya yang terletak di dua zona region yang berbeda. Instance utama mempertahankan ketersediaan regional dengan memicu failover otomatis ke zona standby jika zona aktif mengalami masalah. Penyimpanan regional menjamin ketahanan data jika terjadi kehilangan zona tunggal.
Sebagai metode pemulihan dari bencana lebih lanjut, AlloyDB for PostgreSQL menggunakan replikasi lintas-region untuk memberikan kemampuan pemulihan dari bencana dengan mereplikasi data cluster utama Anda secara asinkron ke dalam cluster sekunder yang terletak di region Google Cloud terpisah.
pemadaman layanan zona: Selama operasi normal, hanya satu dari dua node instance utama dengan ketersediaan tinggi yang aktif, dan menyalurkan semua penulisan data. Node aktif ini menyimpan data di lapisan penyimpanan regional cluster yang terpisah.
AlloyDB untuk PostgreSQL secara otomatis mendeteksi kegagalan tingkat zona dan memicu failover untuk memulihkan ketersediaan database. Selama failover, AlloyDB untuk PostgreSQL memulai database di node standby, yang sudah disediakan di zona berbeda. Koneksi database baru secara otomatis diarahkan ke zona ini.
Dari perspektif aplikasi klien, pemadaman layanan menurut zona menyerupai gangguan konektivitas jaringan sementara. Setelah failover selesai, klien dapat terhubung kembali ke instance di alamat yang sama, menggunakan kredensial yang sama, tanpa kehilangan data.
pemadaman layanan Regional: Replikasi lintas-region menggunakan replikasi asinkron, yang memungkinkan instance utama meng-commit transaksi sebelum di-commit pada replika. Perbedaan waktu antara saat transaksi di-commit pada instance utama dan saat di-commit pada replika dikenal sebagai keterlambatan replikasi. Perbedaan waktu antara saat email utama menghasilkan write-ahead log (WAL) dan saat WAL mencapai replika dikenal sebagai jeda pengosongan. Jeda replikasi dan jeda flush bergantung pada konfigurasi instance database dan beban kerja yang dihasilkan pengguna.
Jika terjadi pemadaman layanan regional, Anda dapat mempromosikan cluster sekunder di region berbeda ke cluster utama mandiri yang dapat ditulis. Cluster yang dipromosikan ini tidak lagi mereplikasi data dari cluster primer asli yang sebelumnya terkait. Karena adanya jeda pengosongan, sejumlah kehilangan data mungkin terjadi karena mungkin ada transaksi pada data primer asli yang tidak disebarkan ke cluster sekunder.
RPO replikasi lintas-region dipengaruhi oleh penggunaan CPU cluster primer, dan jarak fisik antara region cluster utama dan region cluster sekunder. Untuk mengoptimalkan RPO, sebaiknya uji beban kerja Anda dengan konfigurasi yang menyertakan replika untuk menetapkan batas transaksi per detik (TPS) yang aman, yang merupakan TPS berkelanjutan tertinggi yang tidak mengakumulasi jeda flush. Jika beban kerja Anda melebihi batas TPS yang aman, jeda flush akan terakumulasi, yang dapat memengaruhi RPO. Untuk membatasi jeda jaringan, pilih pasangan region dalam benua yang sama.
Untuk mengetahui informasi selengkapnya tentang pemantauan jeda jaringan dan metrik AlloyDB untuk PostgreSQL lainnya, lihat Memantau instance.
Anti Money Laundering AI
Anti Money Laundering AI (AML AI) menyediakan API untuk membantu institusi keuangan global mendeteksi pencucian uang secara lebih efektif dan efisien. Anti Money Laundering AI adalah penawaran regional, yang berarti pelanggan dapat memilih region, tetapi bukan zona yang membentuk suatu wilayah. Data dan traffic akan otomatis di-load balanced di seluruh zona dalam satu region. Operasi (misalnya, untuk membuat pipeline atau menjalankan prediksi) secara otomatis diskalakan di latar belakang dan di-load balanced di seluruh zona sesuai kebutuhan.
pemadaman layanan zona: AML AI menyimpan data untuk resource-nya secara regional, yang direplikasi secara sinkron. Saat operasi yang berjalan lama berhasil diselesaikan, resource dapat diandalkan, apa pun kegagalan zonanya. Pemrosesan juga direplikasi di seluruh zona, tetapi replikasi ini bertujuan untuk load balancing dan bukan ketersediaan tinggi, sehingga kegagalan zona selama operasi dapat mengakibatkan kegagalan operasi. Jika itu terjadi, mencoba kembali operasi dapat mengatasi masalah tersebut. Selama pemadaman layanan zona, waktu pemrosesan mungkin akan terpengaruh.
Pemadaman layanan regional: Pelanggan memilih region Google Cloud yang diinginkan untuk membuat resource AML AI. Data tidak pernah direplikasi di seluruh region. Traffic pelanggan tidak pernah dirutekan ke region berbeda oleh AML AI. Jika terjadi kegagalan regional, AML AI akan tersedia lagi segera setelah pemadaman layanan teratasi.
Kunci API
Kunci API menyediakan pengelolaan resource kunci API yang skalabel untuk sebuah project. Kunci API adalah layanan global, artinya kunci dapat dilihat dan diakses dari lokasi Google Cloud mana pun. Data dan metadatanya disimpan secara redundan di beberapa zona dan region.
Kunci API tahan terhadap pemadaman layanan zona dan regional. Jika terjadi pemadaman layanan zona atau pemadaman layanan regional, kunci API akan terus melayani permintaan dari zona lain di region yang sama atau berbeda.
Untuk mengetahui informasi selengkapnya tentang kunci API, lihat Ringkasan API kunci API.
Apigee
Apigee menyediakan platform yang aman, skalabel, dan andal untuk mengembangkan dan mengelola API. Apigee menawarkan deployment region tunggal dan multi-region.
Pemadaman layanan zona: Data runtime pelanggan direplikasi di berbagai zona ketersediaan. Oleh karena itu, pemadaman layanan zona tunggal tidak memengaruhi Apigee.
Pemadaman Layanan Regional: Untuk instance Apigee satu region, jika suatu region mengalami penurunan, instance Apigee tidak akan tersedia di region tersebut dan tidak dapat dipulihkan ke region lain. Untuk instance Apigee multi-region, data direplikasi di semua region secara asinkron. Oleh karena itu, kegagalan satu region tidak mengurangi traffic sepenuhnya. Namun, Anda mungkin tidak dapat mengakses data yang tidak di-commit di region yang gagal. Anda dapat mengalihkan traffic dari wilayah yang tidak sehat. Untuk mencapai failover traffic otomatis, Anda dapat mengonfigurasi perutean jaringan menggunakan grup instance terkelola (MIG).
AutoML Translation
AutoML Translation adalah layanan terjemahan mesin yang memungkinkan Anda mengimpor data sendiri (pasangan kalimat) untuk melatih model kustom sesuai kebutuhan khusus domain Anda.
Pemadaman layanan zona: AutoML Translation memiliki server komputasi aktif di beberapa zona dan region. Ini juga mendukung replikasi data sinkron di seluruh zona dalam region. Fitur ini membantu AutoML Translation mencapai failover seketika tanpa kehilangan data akibat kegagalan zona, dan tanpa memerlukan input atau penyesuaian dari pelanggan.
Pemadaman layanan regional: Jika terjadi kegagalan regional, AutoML Translation tidak tersedia.
AutoML Vision
AutoML Vision adalah bagian dari Vertex AI. Framework ini menawarkan framework terpadu untuk membuat set data, mengimpor data, melatih model, dan menayangkan model untuk prediksi online dan prediksi batch.
AutoML Vision adalah penawaran regional. Pelanggan dapat memilih region tempat mereka ingin meluncurkan tugas, tetapi mereka tidak dapat memilih zona tertentu dalam region tersebut. Layanan ini otomatis melakukan load balance beban kerja di berbagai zona dalam region.
Pemadaman layanan zona: AutoML Vision menyimpan metadata untuk tugas secara regional, dan menulis secara sinkron di seluruh zona dalam region. Tugas diluncurkan di zona tertentu, seperti yang dipilih oleh Cloud Load Balancing.
Tugas pelatihan AutoML Vision: Pemadaman layanan zona menyebabkan semua tugas yang sedang berjalan gagal, dan status tugas diperbarui menjadi gagal. Jika tugas gagal, coba lagi segera. Tugas baru dirutekan ke zona yang tersedia.
Tugas prediksi batch AutoML Vision: Prediksi batch dibuat di atas prediksi batch Vertex AI. Saat terjadi pemadaman layanan zona, layanan akan otomatis mencoba kembali tugas dengan merutekannya ke zona yang tersedia. Jika beberapa percobaan ulang gagal, status tugas akan diperbarui menjadi gagal. Permintaan pengguna berikutnya untuk menjalankan tugas akan dirutekan ke zona yang tersedia.
Pemadaman layanan regional: Pelanggan memilih Google Cloud region tempat mereka ingin menjalankan tugas. Data tidak pernah direplikasi di seluruh region. Jika terjadi kegagalan regional, layanan AutoML Vision tidak tersedia di region tersebut. Layanan ini akan tersedia kembali saat pemadaman layanan teratasi. Untuk menjalankan tugasnya, sebaiknya pelanggan menggunakan beberapa region. Jika terjadi pemadaman layanan regional, arahkan tugas ke region lain yang tersedia.
Batch
Batch adalah layanan terkelola sepenuhnya untuk mengantrekan, menjadwalkan, dan menjalankan tugas batch di Google Cloud. Setelan batch ditentukan pada tingkat region. Pelanggan harus memilih region untuk mengirimkan tugas batch mereka, bukan zona di region. Saat tugas dikirim, Batch akan menulis data pelanggan secara sinkron ke beberapa zona. Namun, pelanggan dapat menentukan zona tempat VM Batch menjalankan tugas.
Kegagalan Zona Waktu: Jika satu zona gagal, tugas yang berjalan di zona tersebut juga akan gagal. Jika tugas memiliki setelan percobaan ulang, Batch akan otomatis gagal mengirimkan tugas tersebut ke zona aktif lainnya di region yang sama. Failover otomatis bergantung pada ketersediaan resource di zona aktif di region yang sama. Tugas yang memerlukan resource zona (seperti VM, GPU, atau persistent disk zona) yang hanya tersedia di zona gagal akan dimasukkan ke dalam antrean sampai zona gagal dipulihkan atau hingga waktu tunggu antrean tugas tercapai. Jika memungkinkan, sebaiknya pelanggan mengizinkan Batch memilih resource zona untuk menjalankan tugasnya. Hal ini membantu memastikan bahwa tugas tahan terhadap pemadaman layanan zona.
Kegagalan Regional: Jika terjadi kegagalan regional, bidang kontrol layanan tidak tersedia di region tersebut. Layanan ini tidak mereplikasi data atau mengalihkan permintaan lintas region. Sebaiknya pelanggan menggunakan beberapa region untuk menjalankan tugasnya dan mengalihkan tugas ke region lain jika region gagal.
Perlindungan data dan perlindungan terhadap ancaman Chrome Enterprise Premium
Perlindungan terhadap ancaman dan perlindungan data Chrome Enterprise Premium adalah bagian dari solusi Chrome Enterprise Premium. Fitur ini memperluas Chrome dengan berbagai fitur keamanan, termasuk perlindungan terhadap malware dan phishing, Pencegahan Kebocoran Data (DLP), aturan pemfilteran URL, dan pelaporan keamanan.
Admin Chrome Enterprise Premium dapat memilih untuk menyimpan konten inti pelanggan yang melanggar kebijakan DLP atau malware ke dalam peristiwa log aturan Google Workspace dan/atau ke Cloud Storage untuk penyelidikan di masa mendatang. Peristiwa log aturan Google Workspace didukung oleh database Spanner multi-region. Chrome Enterprise Premium dapat memerlukan waktu hingga beberapa jam untuk mendeteksi pelanggaran kebijakan. Selama waktu ini, data yang belum diproses dapat mengalami kehilangan data akibat pemadaman zona atau regional. Setelah pelanggaran terdeteksi, konten yang melanggar kebijakan Anda akan ditulis ke peristiwa log aturan Google Workspace dan/atau ke Cloud Storage.
Pemadaman layanan Zonal dan Regional: Karena perlindungan data dan perlindungan terhadap ancaman Chrome Enterprise Premium bersifat multi-zona dan multi-regional, layanan ini dapat bertahan dari kehilangan zona atau region yang tidak direncanakan dan lengkap tanpa kehilangan ketersediaan. Load balancer ini memberikan tingkat keandalan ini dengan mengalihkan traffic ke layanannya di zona atau region aktif lainnya. Namun, karena perlindungan data dan perlindungan terhadap ancaman Chrome Enterprise Premium dapat memerlukan waktu beberapa jam untuk mendeteksi pelanggaran DLP dan malware, setiap data yang belum diproses di zona atau wilayah tertentu dapat hilang akibat gangguan zona atau wilayah.
BigQuery
BigQuery adalah cloud data warehouse serverless, sangat skalabel, dan hemat biaya yang dirancang untuk ketangkasan bisnis. BigQuery mendukung jenis lokasi berikut untuk set data pengguna:
- Wilayah: lokasi geografis tertentu, seperti Iowa (
us-central1) atau Montréal (northamerica-northeast1). - Multi-region: area geografis luas yang berisi dua atau beberapa tempat
geografis, seperti Amerika Serikat (
US) atau Eropa (EU).
Dalam kedua kasus tersebut, data disimpan secara redundan di dua zona dalam satu region dalam lokasi yang dipilih. Data yang ditulis ke BigQuery ditulis secara sinkron ke zona primer dan sekunder. Hal ini melindungi dari ketidaktersediaan zona tunggal dalam region, tetapi tidak terhadap pemadaman layanan regional.
Otorisasi Biner
Otorisasi Biner adalah produk keamanan supply chain software untuk GKE dan Cloud Run.
Semua kebijakan Otorisasi Biner direplikasi di beberapa zona dalam setiap region. Replikasi membantu kebijakan Otorisasi Biner memulihkan operasi baca dari kegagalan region lain. Replikasi juga membuat operasi baca menjadi toleran terhadap kegagalan zona dalam setiap region.
Operasi penerapan Otorisasi Biner tahan terhadap pemadaman layanan zona, tetapi tidak tahan terhadap pemadaman layanan regional. Operasi penerapan berjalan di region yang sama dengan cluster GKE atau tugas Cloud Run yang membuat permintaan. Oleh karena itu, jika terjadi pemadaman layanan regional, tidak akan ada yang berjalan untuk membuat permintaan penerapan Otorisasi Biner.
Certificate Manager
Dengan Certificate Manager, Anda dapat memperoleh dan mengelola sertifikat Transport Layer Security (TLS) untuk digunakan dengan berbagai jenis Cloud Load Balancing.
Jika terjadi pemadaman layanan zona, Certificate Manager regional dan global tahan terhadap kegagalan di level zona karena tugas dan database bersifat redundan di beberapa zona dalam satu region. Dalam kasus pemadaman layanan regional, Certificate Manager global tahan terhadap kegagalan regional karena tugas dan database berlebihan di beberapa region. Certificate Manager Regional adalah produk regional, sehingga tidak dapat menahan kegagalan regional.
Cloud Intrusion Detection System
Cloud Intrusion Detection System (Cloud IDS) adalah layanan zonal yang menyediakan Endpoint IDS dengan cakupan per zona, yang memproses traffic VM di satu zona tertentu, dan dengan demikian tidak toleran terhadap gangguan zonal atau regional.
Pemadaman layanan zona: Cloud IDS terikat dengan instance VM. Jika pelanggan berencana memitigasi pemadaman layanan zona dengan men-deploy VM di beberapa zona (secara manual atau melalui Grup Instance Terkelola Regional), mereka juga harus men-deploy Endpoint Cloud IDS di zona tersebut.
Pemadaman Layanan Regional: Cloud IDS adalah produk regional. Layanan ini tidak menyediakan fungsi lintas-region apa pun. Kegagalan regional akan menonaktifkan semua fungsi Cloud IDS di semua zona di region tersebut.
Google Security Operations SIEM
SIEM Google Security Operations (yang merupakan bagian dari Google Security Operations) adalah layanan terkelola sepenuhnya yang membantu tim keamanan mendeteksi, menyelidiki, dan merespons ancaman.
SIEM Google Security Operations memiliki penawaran regional dan multi-regional.
Dalam penawaran regional, data dan traffic akan otomatis di-load balanced di seluruh zona dalam region yang dipilih, dan data disimpan secara redundan di seluruh zona ketersediaan dalam region tersebut.
Multi-region bersifat geo-redundan. Redundansi tersebut memberikan serangkaian perlindungan yang lebih luas daripada penyimpanan regional. Hal ini juga membantu memastikan bahwa layanan terus berfungsi meskipun seluruh wilayah hilang.
Sebagian besar jalur penyerapan data mereplikasi data pelanggan secara sinkron di beberapa lokasi. Saat data direplikasi secara asinkron, ada jangka waktu (batas titik pemulihan, atau RPO) saat data belum direplikasi ke beberapa lokasi. Hal ini terjadi saat melakukan penyerapan dengan feed dalam deployment multi-regional. Setelah RPO, data tersedia di beberapa lokasi.
Pemadaman layanan zona:
Deployment regional: Permintaan dikirimkan dari zona mana pun dalam region. Data direplikasi secara sinkron di beberapa zona. Jika terjadi pemadaman layanan zona penuh, zona lainnya akan terus menyalurkan traffic dan terus memproses data. Penyediaan redundan dan penskalaan otomatis untuk SIEM Google Security Operations membantu memastikan bahwa layanan tetap beroperasi di zona yang tersisa selama perpindahan beban ini.
Deployment multi-regional: Pemadaman layanan zona setara dengan pemadaman layanan regional.
Pemadaman layanan regional:
Deployment regional: Google Security Operations SIEM menyimpan semua data pelanggan dalam satu region dan traffic tidak pernah dirutekan ke berbagai region. Jika terjadi pemadaman layanan regional, Google Security Operations SIEM tidak akan tersedia di region tersebut hingga pemadaman layanan teratasi.
Deployment multi-regional (tanpa feed): Permintaan ditayangkan dari region mana pun dalam deployment multi-regional. Data direplikasi secara sinkron di beberapa region. Jika terjadi pemadaman layanan regional penuh, region yang tersisa akan terus menyalurkan traffic dan terus memproses data. Penyediaan redundan dan penskalaan otomatis untuk Google Security Operations SIEM membantu memastikan bahwa layanan tetap beroperasi di wilayah yang tersisa selama perpindahan beban ini.
Deployment multi-regional (dengan feed): Permintaan ditayangkan dari region mana pun dalam deployment multi-regional. Data direplikasi secara asinkron di beberapa region dengan RPO yang diberikan. Jika terjadi pemadaman layanan di seluruh region, hanya data yang disimpan setelah RPO yang tersedia di region yang tersisa. Data dalam periode RPO mungkin tidak direplikasi.
Inventaris Aset Cloud
Inventaris Aset Cloud adalah layanan global berperforma tinggi, tangguh, dan memiliki performa tinggi yang mengelola repositori metadata resource dan kebijakan. Google Cloud Inventaris Aset Cloud menyediakan alat penelusuran dan analisis yang membantu Anda melacak aset yang di-deploy di seluruh organisasi, folder, dan project.
Jika terjadi pemadaman layanan zona, Inventaris Aset Cloud akan terus melayani permintaan dari zona lain di region yang sama atau berbeda.
Jika terjadi pemadaman layanan regional, Inventaris Aset Cloud akan terus melayani permintaan dari region lain.
Bigtable
Bigtable adalah layanan database NoSQL berperforma tinggi yang terkelola sepenuhnya untuk workload analisis dan operasional yang besar.
Ringkasan replikasi Bigtable
Bigtable menawarkan fitur replikasi yang fleksibel dan dapat dikonfigurasi sepenuhnya. Fitur ini dapat Anda gunakan untuk meningkatkan ketersediaan dan ketahanan data dengan menyalinnya ke cluster di beberapa region. atau beberapa zona dalam region yang sama. Bigtable juga dapat menyediakan failover otomatis untuk permintaan Anda saat menggunakan replikasi.
Saat menggunakan konfigurasi multi-zona atau multi-regional dengan pemilihan rute multi-cluster, jika terjadi pemadaman layanan zona atau regional, Bigtable secara otomatis mengubah rute traffic dan melayani permintaan dari ke klaster terdekat yang tersedia. Karena replikasi Bigtable bersifat asinkron dan konsisten tertunda, perubahan terbaru pada data di lokasi pemadaman layanan mungkin menjadi tidak tersedia jika belum direplikasi ke lokasi lain.
Pertimbangan performa
Saat permintaan resource CPU melebihi kapasitas node yang tersedia, Bigtable selalu memprioritaskan penyaluran permintaan masuk sebelum traffic replikasi.
Untuk mengetahui informasi selengkapnya tentang cara menggunakan replikasi Bigtable dengan beban kerja Anda, lihat Ringkasan replikasi Cloud Bigtable dan contoh setelan replikasi.
Node Bigtable digunakan untuk menyalurkan permintaan masuk dan melakukan replikasi data dari cluster lain. Selain mempertahankan jumlah node yang memadai per cluster, Anda juga harus memastikan bahwa aplikasi menggunakan desain skema yang tepat untuk menghindari hotspot, yang dapat menyebabkan penggunaan CPU yang berlebihan atau tidak seimbang dan peningkatan latensi replikasi.
Untuk mengetahui informasi selengkapnya tentang mendesain skema aplikasi guna memaksimalkan performa dan efisiensi Bigtable, lihat Praktik terbaik desain skema.
Pemantauan
Bigtable menyediakan beberapa cara untuk memantau latensi replikasi instance dan cluster Anda secara visual menggunakan diagram untuk replikasi yang tersedia di Google Cloud console.
Anda juga dapat memantau metrik replikasi Bigtable secara terprogram menggunakan Cloud Monitoring API.
Certificate Authority Service
Certificate Authority Service (CA Service) memungkinkan pelanggan menyederhanakan, mengotomatiskan, dan menyesuaikan deployment, pengelolaan, dan keamanan certificate authority (CA) pribadi serta menerbitkan sertifikat secara andal dalam skala besar.
Pemadaman layanan zona: Layanan CA tahan terhadap kegagalan zona karena bidang kontrolnya redundan di beberapa zona dalam satu region. Jika terjadi pemadaman layanan zona, Layanan CA akan terus menyajikan permintaan dari zona lain di region yang sama tanpa gangguan. Karena data direplikasi secara sinkron, tidak ada data yang hilang atau rusak.
Pemadaman layanan regional: CA Service adalah produk regional, sehingga tidak dapat menahan kegagalan regional. Jika Anda memerlukan ketahanan terhadap kegagalan regional, buat CA penerbit di dua region yang berbeda. Buat CA penerbit utama di region tempat Anda memerlukan sertifikat. Buat CA pengganti di region yang berbeda. Gunakan penggantian saat region CA subordinat utama mengalami pemadaman layanan. Jika diperlukan, kedua CA dapat membentuk rantai hingga CA root yang sama.
Penagihan Cloud
Cloud Billing API memungkinkan developer mengelola penagihan untukGoogle Cloud project mereka secara terprogram. Cloud Billing API dirancang sebagai sistem global dengan update yang ditulis secara sinkron ke beberapa zona dan region.
Kegagalan zona atau regional: Cloud Billing API akan otomatis melakukan failover ke zona atau region lain. Permintaan individual mungkin gagal, tetapi kebijakan coba lagi akan memungkinkan upaya berikutnya berhasil.
Cloud Build
Cloud Build adalah layanan yang menjalankan build Anda di Google Cloud.
Cloud Build terdiri dari instance yang terisolasi secara regional yang mereplikasi data secara sinkron di seluruh zona dalam region tersebut. Sebaiknya gunakan region Google Cloud tertentu, bukan region global, dan pastikan resource yang digunakan build Anda (termasuk bucket log, repositori Artifact Registry, dan sebagainya) selaras dengan region tempat build Anda berjalan.
Jika terjadi pemadaman layanan zona, operasi bidang kontrol tidak akan terpengaruh. Namun, eksekusi saat ini dalam zona yang gagal akan tertunda atau hilang secara permanen. Build yang baru dipicu akan otomatis didistribusikan ke zona fungsi yang tersisa.
Jika terjadi kegagalan regional, bidang kontrol akan offline, dan build yang sedang dijalankan akan tertunda atau hilang secara permanen. Pemicu, kumpulan worker, dan data build tidak pernah direplikasi di seluruh region. Sebaiknya Anda menyiapkan pemicu dan kumpulan worker di beberapa region untuk mempermudah mitigasi pemadaman layanan.
Cloud CDN
Cloud CDN mendistribusikan dan menyimpan konten dalam cache di banyak lokasi di jaringan Google untuk mengurangi latensi penyajian untuk klien. Konten dalam cache disajikan berdasarkan upaya terbaik -- ketika permintaan tidak dapat dilayani oleh cache Cloud CDN, permintaan tersebut diteruskan ke server asal, seperti VM backend atau bucket Cloud Storage, tempat konten asli disimpan.
Jika satu zona atau wilayah gagal, cache di lokasi yang terpengaruh tidak tersedia. Permintaan masuk dirutekan ke cache dan lokasi edge Google yang tersedia. Jika cache alternatif ini tidak dapat menyalurkan permintaan, cache tersebut akan meneruskan permintaan ke server origin yang tersedia. Selama server dapat menyalurkan permintaan dengan data terbaru, konten tidak akan hilang. Peningkatan tingkat cache tidak ditemukan akan menyebabkan server asal mengalami volume traffic yang lebih tinggi dari biasanya saat cache diisi. Permintaan berikutnya akan disajikan dari cache yang tidak terpengaruh oleh pemadaman layanan zona atau region.
Untuk mengetahui informasi selengkapnya tentang Cloud CDN dan perilaku cache, lihat dokumentasi Cloud CDN.
Cloud Composer
Cloud Composer adalah layanan orkestrasi alur kerja terkelola yang dapat Anda gunakan untuk membuat, menjadwalkan, memantau, dan mengelola alur kerja yang tersebar di seluruh cloud dan pusat data lokal. Lingkungan Cloud Composer dibuat berdasarkan project open source Apache Airflow.
Ketersediaan Cloud Composer API tidak terpengaruh oleh tidak tersedianya zona. Selama pemadaman layanan zona, Anda tetap memiliki akses ke Cloud Composer API, termasuk kemampuan untuk membuat lingkungan Cloud Composer baru.
Lingkungan Cloud Composer memiliki cluster GKE sebagai bagian dari arsitekturnya. Selama pemadaman layanan zona, alur kerja di cluster mungkin akan terganggu:
- Di Cloud Composer 1, cluster lingkungan merupakan resource zona. Oleh karena itu, pemadaman layanan zona dapat membuat cluster tidak tersedia. Alur kerja yang sedang dijalankan pada saat pemadaman layanan mungkin akan dihentikan sebelum selesai.
- Di Cloud Composer 2, cluster lingkungan adalah resource regional. Namun, alur kerja yang dijalankan di node di zona yang terpengaruh oleh pemadaman layanan zona dapat dihentikan sebelum selesai.
Di kedua versi Cloud Composer, pemadaman layanan zona dapat mengakibatkan alur kerja yang dijalankan sebagian berhenti dijalankan, termasuk tindakan eksternal apa pun yang sesuai dengan alur kerja Anda yang dikonfigurasi oleh Anda. Bergantung pada alur kerja, hal ini dapat menyebabkan inkonsistensi secara eksternal, seperti jika alur kerja berhenti di tengah eksekusi multi-langkah untuk mengubah penyimpanan data eksternal. Oleh karena itu, Anda harus mempertimbangkan proses pemulihan saat mendesain alur kerja Airflow, termasuk cara mendeteksi status alur kerja yang belum dijalankan sebagian dan memperbaiki setiap perubahan data parsial.
Di Cloud Composer 1, selama pemadaman layanan zona, Anda dapat memilih untuk memulai lingkungan Cloud Composer baru di zona lain. Karena Airflow mempertahankan status alur kerja Anda dalam database metadatanya, mentransfer informasi ini ke lingkungan Cloud Composer baru dapat memerlukan langkah dan persiapan tambahan.
Di Cloud Composer 2, Anda dapat mengatasi pemadaman layanan di zona dengan menyiapkan pemulihan bencana dengan snapshot lingkungan terlebih dahulu. Selama pemadaman layanan zona, Anda dapat beralih ke lingkungan lain dengan mentransfer status alur kerja menggunakan snapshot lingkungan. Hanya Cloud Composer 2 yang mendukung pemulihan dari bencana dengan snapshot lingkungan.
Cloud Data Fusion
Cloud Data Fusion adalah layanan integrasi data perusahaan yang terkelola sepenuhnya untuk membangun dan mengelola pipeline data dengan cepat. Edisi ini menyediakan tiga edisi.
Pemadaman layanan zona memengaruhi instance edisi Developer.
Penonaktifan regional memengaruhi instance edisi Basic dan Enterprise.
Untuk mengontrol akses ke resource, Anda dapat mendesain dan menjalankan pipeline di lingkungan yang terpisah. Pemisahan ini memungkinkan Anda mendesain pipeline sekali, lalu menjalankannya di beberapa lingkungan. Anda dapat memulihkan pipeline di kedua lingkungan. Untuk mengetahui informasi selengkapnya, baca Mencadangkan dan memulihkan data instance.
Saran berikut berlaku untuk pemadaman layanan regional dan zona.
Pemadaman layanan di lingkungan desain pipeline
Di lingkungan desain, simpan draf pipeline jika terjadi pemadaman layanan. Bergantung pada persyaratan RTO dan RPO tertentu, Anda dapat menggunakan draf yang disimpan untuk memulihkan pipeline pada instance Cloud Data Fusion yang berbeda selama pemadaman layanan.
Pemadaman layanan di lingkungan eksekusi pipeline
Di lingkungan eksekusi, Anda memulai pipeline secara internal dengan pemicu atau jadwal Cloud Data Fusion, atau secara eksternal dengan alat orkestrasi, seperti Cloud Composer. Agar dapat memulihkan konfigurasi runtime pipeline, cadangkan pipeline dan konfigurasi, seperti plugin dan jadwal. Saat terjadi pemadaman layanan, Anda dapat menggunakan cadangan untuk mereplikasi instance di region atau zona yang tidak terpengaruh.
Cara lain untuk mempersiapkan pemadaman layanan adalah dengan memiliki beberapa instance di seluruh region dengan konfigurasi dan kumpulan pipeline yang sama. Jika Anda menggunakan orkestrasi eksternal, pipeline yang berjalan dapat di-load balanced secara otomatis di antara instance. Berhati-hatilah agar tidak ada resource (seperti sumber data atau alat orkestrasi) yang terikat ke satu region dan digunakan oleh semua instance, karena ini bisa menjadi titik utama kegagalan jika terjadi pemadaman layanan. Misalnya, Anda dapat memiliki beberapa instance di region yang berbeda dan menggunakan Cloud Load Balancing serta Cloud DNS untuk mengarahkan permintaan operasi pipeline ke instance yang tidak terpengaruh oleh pemadaman layanan (lihat contoh arsitektur tingkat satu dan tingkat tiga).
Pemadaman layanan untuk Google Cloud layanan data lainnya dalam pipeline
Instance Anda mungkin menggunakan layanan Google Cloud lain sebagai sumber data atau lingkungan eksekusi pipeline, seperti Dataproc, Cloud Storage, atau BigQuery. Layanan tersebut dapat berada di wilayah yang berbeda. Jika eksekusi lintas region diperlukan, kegagalan di salah satu region akan menyebabkan pemadaman layanan. Dalam skenario ini, Anda mengikuti langkah-langkah pemulihan dari bencana standar, dengan mengingat bahwa penyiapan lintas regional dengan layanan penting di berbagai wilayah kurang tangguh.
Cloud Deploy
Cloud Deploy menyediakan continuous delivery workload ke dalam layanan runtime seperti GKE dan Cloud Run. Layanan ini terdiri dari instance regional yang mereplikasi data secara sinkron di seluruh zona dalam region tersebut.
Pemadaman layanan zona: Operasi bidang kontrol tidak terpengaruh. Namun, build Cloud Build (misalnya, operasi render atau deploy) yang berjalan saat zona gagal akan tertunda atau hilang secara permanen. Selama pemadaman layanan, resource Cloud Deploy yang memicu build (rilis atau peluncuran) menampilkan status kegagalan yang menunjukkan operasi yang mendasarinya gagal. Anda dapat membuat ulang resource untuk memulai build baru di zona berfungsi yang tersisa. Misalnya, buat peluncuran baru dengan men-deploy ulang rilis ke target.
Pemadaman layanan regional: Operasi bidang kontrol tidak tersedia, begitu juga data dari Cloud Deploy, hingga region dipulihkan. Untuk membantu mempermudah pemulihan layanan jika terjadi pemadaman layanan regional, sebaiknya simpan pipeline pengiriman dan definisi target di kontrol sumber. Anda dapat menggunakan file konfigurasi ini untuk membuat ulang pipeline Cloud Deploy di region yang berfungsi. Selama pemadaman layanan, data tentang rilis yang sudah ada akan hilang. Buat rilis baru untuk terus men-deploy software ke target Anda.
Cloud DNS
Cloud DNS adalah layanan Domain Name System (DNS) global berperforma tinggi, tangguh, dan global yang memublikasikan nama domain Anda ke DNS global dengan cara yang hemat biaya.
Jika terjadi pemadaman layanan zona, Cloud DNS akan terus melayani permintaan dari zona lain di region yang sama atau berbeda tanpa adanya gangguan. Update pada data Cloud DNS direplikasi secara sinkron di seluruh zona dalam region tempat data tersebut diterima. Oleh karena itu, tidak ada data yang hilang.
Jika terjadi pemadaman layanan regional, Cloud DNS akan terus melayani permintaan dari region lain. Ada kemungkinan bahwa update terbaru pada data Cloud DNS tidak akan tersedia karena update akan diproses terlebih dahulu di satu region sebelum direplikasi secara asinkron ke region lain.
Cloud Healthcare API
Cloud Healthcare API, layanan untuk menyimpan dan mengelola data layanan kesehatan, dibuat untuk memberikan ketersediaan tinggi dan menawarkan perlindungan dari kegagalan zona dan regional, bergantung pada konfigurasi yang dipilih.
Konfigurasi regional: dalam konfigurasi default-nya, Cloud Healthcare API menawarkan perlindungan dari kegagalan zona. Layanan di-deploy di tiga zona di satu region, dan data juga di-deploy tiga kali lipat di berbagai zona dalam satu region. Jika terjadi kegagalan zona, yang memengaruhi lapisan layanan atau lapisan data, zona lainnya akan mengambil alih tanpa gangguan. Dengan konfigurasi regional, jika seluruh wilayah tempat layanan berada mengalami pemadaman, layanan tidak akan tersedia hingga wilayah tersebut kembali online. Jika terjadi penghancuran fisik di seluruh wilayah yang tidak terduga, data yang disimpan di wilayah tersebut akan hilang.
Konfigurasi multi-regional: dalam konfigurasi multiregional, Cloud Healthcare API di-deploy di tiga zona yang termasuk dalam tiga region yang berbeda. Data juga direplikasi di tiga region. Hal ini melindungi dari hilangnya layanan jika terjadi pemadaman layanan di seluruh region, karena region yang tersisa akan otomatis mengambil alih. Data terstruktur, seperti FHIR, direplikasi secara sinkron di beberapa region, sehingga dilindungi dari kehilangan data jika terjadi gangguan di seluruh region. Data yang disimpan di bucket Cloud Storage, seperti objek DICOM dan Dictation atau HL7v2/FHIR berukuran besar, direplikasi secara asinkron di beberapa region.
Cloud Identity
Layanan Cloud Identity didistribusikan di beberapa region dan menggunakan load balancing dinamis. Cloud Identity tidak mengizinkan pengguna memilih cakupan resource. Jika zona atau region tertentu mengalami pemadaman layanan, traffic akan otomatis didistribusikan ke zona atau region lain.
Data persisten dicerminkan di beberapa region dengan replikasi sinkron dalam sebagian besar kasus. Untuk alasan performa, beberapa sistem, seperti cache atau perubahan yang memengaruhi sejumlah besar entity, direplikasi secara asinkron di seluruh region. Jika region utama tempat data terbaru disimpan mengalami pemadaman layanan, Cloud Identity akan menyalurkan data yang tidak berlaku dari lokasi lain hingga region utama tersedia.
Cloud Interconnect
Cloud Interconnect menawarkan akses RFC 1918 ke jaringan Google Cloud dari pusat data lokal mereka, melalui kabel fisik yang terhubung ke edge peering Google.
Cloud Interconnect memberi pelanggan SLA 99,9% jika mereka menyediakan koneksi ke dua EAD (Edge Availability Domains) di area metropolitan. SLA 99,99% tersedia jika pelanggan menyediakan koneksi di dua EAD di dua area metropolitan ke dua region dengan Pemilihan Rute Global. Lihat Ringkasan topologi untuk aplikasi non-kritis dan Ringkasan topologi untuk aplikasi level produksi guna mengetahui informasi selengkapnya.
Cloud Interconnect tidak bergantung pada zona komputasi dan memberikan ketersediaan tinggi dalam bentuk EAD. Jika terjadi kegagalan EAD, sesi BGP ke EAD tersebut terputus dan traffic akan gagal terhubung ke EAD lainnya.
Jika terjadi kegagalan regional, sesi BGP ke region tersebut akan berhenti dan traffic akan gagal mengarah ke resource di region kerja. Ini berlaku jika Pemilihan Rute Global diaktifkan.
Cloud Key Management Service
Cloud Key Management Service (Cloud KMS) menyediakan pengelolaan resource kunci kriptografis yang skalabel dan sangat tahan lama. Cloud KMS menyimpan semua data dan metadatanya di database Spanner yang memberikan ketahanan dan ketersediaan data yang tinggi dengan replikasi sinkron.
Resource Cloud KMS dapat dibuat di satu region, beberapa region, atau secara global.
Dalam kasus pemadaman layanan zona, Cloud KMS akan terus menyalurkan permintaan dari zona lain di region yang sama atau berbeda tanpa gangguan. Karena data direplikasi secara sinkron, tidak ada data yang hilang atau rusak. Setelah gangguan zona teratasi, redundansi penuh akan dipulihkan.
Jika terjadi pemadaman layanan regional, resource regional di region tersebut akan offline hingga region tersebut tersedia kembali. Perlu diperhatikan bahwa meskipun dalam suatu region, setidaknya 3 replika dikelola di zona terpisah. Jika ketersediaan yang lebih tinggi diperlukan, resource harus disimpan dalam konfigurasi multi-region atau global. Konfigurasi multi-region dan global didesain untuk tetap tersedia selama pemadaman layanan regional dengan menyimpan dan menyalurkan data secara geo-redundan di lebih dari satu region.
Cloud External Key Manager (Cloud EKM)
Cloud External Key Manager terintegrasi dengan Cloud Key Management Service agar Anda dapat mengontrol dan mengakses kunci eksternal melalui partner pihak ketiga yang didukung. Anda dapat menggunakan kunci eksternal ini untuk mengenkripsi data dalam penyimpanan untuk digunakan oleh layanan Google Cloud lainnya yang mendukung integrasi kunci enkripsi yang dikelola pelanggan (CMEK).
Pemadaman layanan zona: Cloud External Key Manager tahan terhadap pemadaman layanan zona karena redundansi yang disediakan oleh beberapa zona dalam suatu region. Jika terjadi pemadaman layanan zona, traffic akan dialihkan ke zona lain dalam region tersebut. Saat lalu lintas dipilih ulang, Anda mungkin melihat peningkatan error, tetapi layanan masih tersedia.
Pemadaman layanan regional: Cloud External Key Manager tidak tersedia selama pemadaman layanan regional di region yang terpengaruh. Tidak ada mekanisme failover yang mengalihkan permintaan lintas region. Sebaiknya pelanggan menggunakan beberapa region untuk menjalankan tugas mereka.
Cloud External Key Manager tidak menyimpan data pelanggan apa pun secara persisten. Dengan demikian, tidak ada data yang hilang selama pemadaman layanan regional dalam sistem Cloud External Key Manager. Namun, Cloud External Key Manager bergantung pada ketersediaan layanan lain, seperti Cloud Key Management Service dan vendor pihak ketiga eksternal. Jika sistem tersebut gagal selama pemadaman layanan regional, Anda dapat kehilangan data. RPO/RTO sistem ini berada di luar cakupan komitmen Cloud External Key Manager.
Cloud Load Balancing
Cloud Load Balancing adalah layanan terkelola yang terdistribusi sepenuhnya, serta software-defined. Dengan Cloud Load Balancing, satu alamat IP anycast dapat berfungsi sebagai frontend untuk backend di region di seluruh dunia. Layanan ini tidak berbasis hardware, sehingga Anda tidak perlu mengelola infrastruktur load balancing fisik. Penyeimbang beban adalah komponen penting dari sebagian besar aplikasi yang sangat tersedia.
Cloud Load Balancing menawarkan load balancer regional dan global. Platform ini juga menyediakan load balancing lintas region, termasuk failover multi-region otomatis, yang memindahkan traffic ke backend failover jika backend utama Anda tidak responsif.
Load balancer global tahan terhadap pemadaman layanan zona dan regional. Load balancer regional tahan terhadap pemadaman layanan di zona, tetapi terpengaruh oleh pemadaman layanan di region-nya. Namun, dalam kedua kasus tersebut, penting untuk dipahami bahwa ketahanan aplikasi secara keseluruhan tidak hanya bergantung pada jenis load balancer yang Anda deploy, tetapi juga pada redundansi backend.
Untuk mengetahui informasi selengkapnya tentang Cloud Load Balancing dan fitur-fiturnya, lihat Ringkasan Cloud Load Balancing.
Cloud Logging
Cloud Logging terdiri atas dua bagian utama: Router Log dan penyimpanan Cloud Logging.
Router Log menangani peristiwa log streaming dan mengarahkan log ke penyimpanan Cloud Storage, Pub/Sub, BigQuery, atau Cloud Logging.
Penyimpanan Cloud Logging adalah layanan untuk menyimpan, membuat kueri, dan mengelola kepatuhan untuk log. Solusi ini mendukung banyak pengguna dan alur kerja termasuk pengembangan, kepatuhan, pemecahan masalah, dan pemberitahuan proaktif.
Router Log & log masuk: Selama pemadaman layanan zona, Cloud Logging API akan merutekan log ke zona lain di region tersebut. Biasanya, log yang dirutekan oleh Router Log ke Cloud Logging, BigQuery, atau Pub/Sub ditulis ke tujuan akhirnya sesegera mungkin, sementara log yang dikirim ke Cloud Storage di-buffer dan ditulis dalam batch per jam.
Entri Log: Jika terjadi pemadaman layanan di zona atau regional, entri log yang telah di-buffer di zona atau region yang terpengaruh dan tidak ditulis ke tujuan ekspor tidak akan dapat diakses. Metrik berbasis log juga dihitung di Router Log dan tunduk pada batasan yang sama. Setelah dikirim ke lokasi ekspor log yang dipilih, log direplikasi sesuai dengan layanan tujuan. Log yang diekspor ke penyimpanan Cloud Logging direplikasi secara sinkron di dua zona dalam satu region. Untuk perilaku replikasi jenis tujuan lainnya, lihat bagian yang relevan dalam artikel ini. Perhatikan bahwa log yang diekspor ke Cloud Storage dikelompokkan dan ditulis setiap jam. Oleh karena itu, sebaiknya gunakan penyimpanan Cloud Logging, BigQuery, atau Pub/Sub untuk meminimalkan jumlah data yang terpengaruh oleh pemadaman layanan.
Metadata Log: Metadata seperti konfigurasi sink dan pengecualian disimpan secara global, tetapi disimpan dalam cache secara regional, sehingga jika terjadi pemadaman layanan, instance Router Log regional akan beroperasi. Pemadaman layanan satu region tidak berdampak pada luar region.
Cloud Monitoring
Cloud Monitoring terdiri dari berbagai fitur yang saling terhubung, seperti dasbor (bawaan dan buatan pengguna), pemberitahuan, dan pemantauan waktu beroperasi.
Semua konfigurasi Cloud Monitoring, termasuk dasbor, cek uptime, dan kebijakan pemberitahuan, ditentukan secara global. Semua perubahan padanya direplikasi secara sinkron ke beberapa region. Oleh karena itu, selama gangguan zona dan regional, perubahan konfigurasi yang sukses dapat bertahan lama. Selain itu, meskipun kegagalan baca dan tulis sementara dapat terjadi saat sebuah zona atau region gagal pada awalnya, Cloud Monitoring akan mengubah rute permintaan ke zona dan region yang tersedia. Dalam situasi ini, Anda dapat mencoba lagi perubahan konfigurasi dengan backoff eksponensial.
Saat menulis metrik untuk resource tertentu, Cloud Monitoring terlebih dahulu mengidentifikasi region tempat resource berada. Kemudian, API ini akan menulis tiga replika independen dari data metrik dalam region tersebut. Keseluruhan operasi tulis metrik regional akan berhasil segera setelah salah satu dari tiga operasi tulis berhasil. Ketiga replika tersebut tidak dijamin berada di zona berbeda dalam region.
Zonal: Selama pemadaman layanan zona, operasi tulis dan baca metrik sama sekali tidak tersedia untuk resource di zona yang terpengaruh. Secara efektif, Cloud Monitoring bertindak seolah-olah tidak ada zona yang terpengaruh.
Regional: Selama pemadaman layanan regional, operasi tulis dan baca metrik sama sekali tidak tersedia untuk resource di region yang terpengaruh. Secara efektif, Cloud Monitoring bertindak seolah-olah region yang terpengaruh tidak ada.
Cloud NAT
Cloud NAT (penafsiran alamat jaringan) adalah layanan terkelola yang terdistribusi dan ditentukan software yang memungkinkan resource tertentu tanpa alamat IP eksternal membuat koneksi keluar ke internet. Layanan ini tidak didasarkan pada VM atau peralatan proxy. Sebagai gantinya, Cloud NAT akan mengonfigurasi software Andromeda yang mendukung jaringan Virtual Private Cloud Anda sehingga menyediakan terjemahan alamat jaringan sumber (NAT sumber atau SNAT) untuk VM tanpa alamat IP eksternal. Cloud NAT juga menyediakan terjemahan alamat jaringan tujuan (NAT atau DNAT tujuan) untuk paket respons masuk yang telah ditetapkan.
Untuk mengetahui informasi selengkapnya tentang fungsi Cloud NAT, lihat dokumentasi.
Pemadaman layanan zona: Cloud NAT tahan terhadap kegagalan zona karena bidang kontrol dan bidang data jaringan redundan di beberapa zona dalam satu region.
Pemadaman layanan regional: Cloud NAT adalah produk regional, sehingga tidak dapat menahan kegagalan regional.
Cloud Router
Cloud Router adalah layanan yang terdistribusi sepenuhnya dan terkelola Google Cloud yang menggunakan Border Gateway Protocol (BGP) untuk mengiklankan rentang alamat IP. Ini memprogram rute dinamis berdasarkan pemberitahuan BGP yang diterima dari peer. Setiap Cloud Router, bukan perangkat atau alat fisik, terdiri dari tugas software yang bertindak sebagai speaker dan responden BGP.
Jika terjadi pemadaman layanan zona, Cloud Router dengan konfigurasi ketersediaan tinggi (HA) tahan terhadap kegagalan di level zona. Dalam hal ini, satu antarmuka mungkin kehilangan konektivitas, tetapi traffic dialihkan ke antarmuka lain melalui perutean dinamis menggunakan BGP.
Dalam kasus pemadaman layanan regional, Cloud Router adalah produk regional, sehingga tidak dapat menahan kegagalan regional. Jika pelanggan telah mengaktifkan mode pemilihan rute global, pemilihan rute antara region yang gagal dan region lain mungkin akan terpengaruh.
Cloud Run
Cloud Run adalah lingkungan komputasi stateless tempat pelanggan dapat menjalankan kode dalam container mereka di infrastruktur Google. Cloud Run adalah penawaran regional, yang berarti pelanggan dapat memilih region, tetapi tidak zona yang membentuk suatu region. Data dan traffic akan otomatis di-load balanced di seluruh zona dalam satu region. Instance container secara otomatis diskalakan untuk memenuhi traffic masuk dan di-load balanced ke berbagai zona sesuai kebutuhan. Setiap zona mempertahankan penjadwal yang menyediakan penskalaan otomatis ini per zona. Server juga mengetahui beban yang diterima zona lain dan akan menyediakan kapasitas ekstra dalam zona untuk memungkinkan kegagalan zona.
Jika Anda menggunakan GPU Cloud Run, Anda memiliki opsi untuk menonaktifkan redundansi zona untuk layanan, dan sebagai gantinya menggunakan keandalan upaya terbaik jika terjadi gangguan zona, dengan biaya yang lebih rendah. Untuk mengetahui detailnya, lihat Opsi redundansi zona GPU.
Pemadaman layanan zona: Cloud Run menyimpan metadata serta container yang di-deploy. Data ini disimpan secara regional dan ditulis secara sinkron. Cloud Run Admin API hanya menampilkan panggilan API setelah data di-commit ke kuorum dalam suatu region. Karena data disimpan secara regional, operasi bidang data juga tidak terpengaruh oleh kegagalan zona. Traffic akan dirutekan ke zona lain jika terjadi kegagalan zona.
Pemadaman layanan regional: Pelanggan memilih Google Cloud region yang diinginkan untuk membuat layanan Cloud Run. Data tidak pernah direplikasi di seluruh region. Traffic pelanggan tidak akan pernah dirutekan ke region lain oleh Cloud Run. Jika terjadi kegagalan regional, Cloud Run akan tersedia lagi segera setelah pemadaman layanan teratasi. Pelanggan dianjurkan untuk men-deploy ke beberapa region dan menggunakan Cloud Load Balancing untuk mencapai ketersediaan yang lebih tinggi jika diinginkan.
Cloud Shell
Cloud Shell memberi pengguna akses ke instance Compute Engine satu pengguna yang telah dikonfigurasi sebelumnya untuk orientasi, edukasi, pengembangan, dan tugas operator. Google Cloud
Cloud Shell tidak cocok untuk menjalankan beban kerja aplikasi dan justru ditujukan untuk kasus penggunaan pengembangan dan edukatif yang interaktif. Instance ini memiliki batas kuota runtime per pengguna, dan akan otomatis dihentikan setelah tidak aktif beberapa saat, dan instance hanya dapat diakses oleh pengguna yang ditetapkan.
Instance Compute Engine yang mendukung layanan adalah resource zona. Jadi, jika terjadi pemadaman layanan zona, Cloud Shell pengguna tidak akan tersedia.
Cloud Source Repositories
Dengan Cloud Source Repositories, pengguna dapat membuat dan mengelola repositori kode sumber pribadi. Produk ini dirancang dengan model global, sehingga Anda tidak perlu mengonfigurasinya untuk ketahanan regional atau zona.
Sebagai gantinya, operasi git push terhadap Cloud Source Repositories secara sinkron
mereplikasi update repositori sumber ke beberapa zona di beberapa
region. Artinya, layanan tahan terhadap pemadaman di satu region mana pun.
Jika zona atau region tertentu mengalami pemadaman layanan, traffic akan otomatis didistribusikan ke zona atau region lain.
Fitur untuk mencerminkan repositori dari GitHub atau Bitbucket secara otomatis dapat terpengaruh oleh masalah di produk tersebut. Misalnya, pencerminan terpengaruh jika GitHub atau Bitbucket tidak dapat memberi tahu Cloud Source Repositories tentang commit baru, atau jika Cloud Source Repositories tidak dapat mengambil konten dari repositori yang diupdate.
Spanner
Spanner adalah database yang skalabel, sangat tersedia, multi-versi, direplikasi secara sinkron, dan sangat konsisten dengan semantik relasional.
Instance Spanner regional mereplikasi data secara sinkron di tiga zona dalam satu region. Penulisan ke instance Spanner regional dikirim secara sinkron ke 3 replika dan dikonfirmasi ke klien setelah minimal 2 replika (kuorum mayoritas 2 dari 3) telah meng-commit penulisan. Hal ini membuat Spanner tahan terhadap kegagalan zona dengan memberikan akses ke semua data. Hal ini karena penulisan terbaru telah dipertahankan dan kuorum mayoritas untuk penulisan masih dapat dicapai dengan 2 replika.
Instance multi-regional Spanner mencakup write-quorum yang mereplikasi data secara sinkron di 5 zona yang terletak di tiga region (dua replika baca-tulis masing-masing di region paling dominan default dan region lain; dan satu replika di region saksi). Penulisan ke instance Spanner multi-regional dikonfirmasi setelah setidaknya 3 replika (kuorum mayoritas 3 dari 5) telah meng-commit penulisan. Jika terjadi kegagalan zona atau region, Spanner memiliki akses ke semua data (termasuk penulisan terbaru) dan melayani permintaan baca/tulis karena data disimpan di setidaknya 3 zona di 2 region pada saat penulisan dikonfirmasi ke klien.
Lihat dokumentasi instance Spanner untuk mengetahui informasi selengkapnya tentang konfigurasi ini, dan dokumentasi replikasi untuk mengetahui informasi selengkapnya tentang cara kerja replikasi Spanner.
Cloud SQL
Cloud SQL adalah layanan database relasional yang terkelola sepenuhnya untuk MySQL, PostgreSQL, dan SQL Server. Cloud SQL menggunakan virtual machine Compute Engine terkelola untuk menjalankan software database. Fungsi ini menawarkan konfigurasi ketersediaan tinggi untuk redundansi regional, yang melindungi database dari pemadaman layanan zona. Replika lintas region dapat disediakan untuk melindungi database dari pemadaman layanan region. Karena produk juga menawarkan opsi zona, yang tidak tahan terhadap pemadaman layanan zona atau region, Anda harus berhati-hati dalam memilih konfigurasi ketersediaan tinggi, replika lintas-region, atau keduanya.
Pemadaman layanan zona: Opsi ketersediaan tinggi membuat instance VM utama dan standby di dua zona terpisah dalam satu region. Selama operasi normal, instance VM utama akan menyajikan semua permintaan, menulis file database ke Persistent Disk Regional, yang direplikasi secara sinkron ke zona utama dan standby. Jika pemadaman layanan zona memengaruhi instance utama, Cloud SQL akan memulai failover saat Persistent Disk dipasang ke VM standby dan traffic akan diubah rutenya.
Selama proses ini, database harus diinisialisasi, yang mencakup pemrosesan transaksi apa pun yang ditulis ke log transaksi, tetapi tidak diterapkan ke database. Jumlah dan jenis transaksi yang belum diproses dapat meningkatkan waktu RTO. Operasi tulis yang tinggi baru-baru ini dapat menyebabkan tumpukan transaksi yang belum diproses. Waktu RTO paling banyak terpengaruh oleh (a) aktivitas tulis terbaru yang tinggi dan (b) perubahan terbaru pada skema database.
Terakhir, saat pemadaman layanan zona terselesaikan, Anda dapat memicu operasi failover secara manual untuk melanjutkan penyajian di zona utama.
Untuk mengetahui detail selengkapnya tentang opsi ketersediaan tinggi, lihat dokumentasi ketersediaan tinggi Cloud SQL.
Pemadaman layanan regional: Opsi replika lintas region melindungi database Anda dari pemadaman layanan regional dengan membuat replika baca instance utama Anda di region lain. Replikasi lintas-region menggunakan replikasi asinkron, yang memungkinkan instance utama meng-commit transaksi sebelum di-commit pada replika. Perbedaan waktu antara saat transaksi di-commit pada instance utama dan saat di-commit di replika dikenal sebagai "jeda replikasi" (yang dapat dipantau). Metrik ini mencerminkan transaksi yang belum dikirim dari yang utama ke replika, serta transaksi yang telah diterima, tetapi belum diproses oleh replika. Transaksi yang tidak dikirim ke replika tidak akan tersedia selama pemadaman layanan regional. Transaksi yang diterima, tetapi tidak diproses oleh replika akan memengaruhi waktu pemulihan, seperti yang dijelaskan di bawah.
Cloud SQL merekomendasikan pengujian beban kerja Anda dengan konfigurasi yang menyertakan replika untuk menetapkan batas "transaksi aman per detik (TPS)", yaitu TPS berkelanjutan tertinggi yang tidak mengakumulasi jeda replikasi. Jika beban kerja Anda melebihi batas TPS yang aman, jeda replikasi akan terakumulasi, sehingga berdampak negatif pada nilai RPO dan RTO. Sebagai panduan umum, hindari penggunaan konfigurasi instance kecil (<2 core vCPU, disk <100 GB, atau PD-HDD), yang rentan terhadap jeda replikasi.
Jika terjadi pemadaman layanan regional, Anda harus memutuskan apakah akan mempromosikan replika baca secara manual atau tidak. Ini adalah operasi manual karena promosi dapat menyebabkan skenario split brain di mana replika yang dipromosikan menerima transaksi baru meskipun instance utama mengalami jeda pada saat promosi. Hal ini dapat menyebabkan masalah saat pemadaman layanan regional diselesaikan dan Anda harus merekonsiliasi transaksi yang tidak pernah disebarkan dari instance utama ke replika. Jika hal ini bermasalah untuk kebutuhan Anda, Anda dapat mempertimbangkan produk database replikasi sinkron lintas region seperti Spanner.
Setelah dipicu oleh pengguna, proses promosi akan mengikuti langkah-langkah yang mirip dengan aktivasi instance standby dalam konfigurasi ketersediaan tinggi. Dalam proses tersebut, replika baca harus memproses log transaksi yang mendorong total waktu pemulihan. Karena tidak ada load balancer bawaan yang terlibat dalam promosi replika, alihkan aplikasi secara manual ke aplikasi utama yang dipromosikan.
Untuk mengetahui detail selengkapnya tentang opsi replika lintas-region, lihat dokumentasi replika lintas-region Cloud SQL.
Untuk informasi selengkapnya tentang Cloud SQL DR, lihat referensi berikut:
- Pemulihan dari bencana (disaster recovery) database Cloud SQL untuk MySQL
- Pemulihan dari bencana (disaster recovery) database Cloud SQL untuk PostgreSQL
- Pemulihan dari bencana (disaster recovery) database Cloud SQL untuk SQL Server
Cloud Storage
Cloud Storage menyediakan penyimpanan objek yang terpadu, skalabel, dan sangat tahan lama secara global. Bucket Cloud Storage dapat dibuat di salah satu dari tiga jenis lokasi berbeda: di satu region, di dual-region, atau di multi-region dalam satu benua. Dengan bucket regional, objek disimpan secara redundan di seluruh zona ketersediaan dalam satu region. Di sisi lain, bucket dual-region dan multi-region bersifat geo-redundan. Ini berarti bahwa setelah data yang baru ditulis direplikasi ke setidaknya satu region jarak jauh, objek akan disimpan secara redundan di seluruh region. Pendekatan ini memberi data di bucket dual-region dan multi-region memiliki kumpulan perlindungan yang lebih luas daripada yang dapat dicapai dengan penyimpanan regional.
Bucket regional didesain agar tahan lama jika terjadi pemadaman layanan di satu zona ketersediaan. Jika suatu zona mengalami pemadaman layanan, objek di zona yang tidak tersedia akan otomatis dan transparan disajikan dari tempat lain di region tersebut. Data dan metadata disimpan secara redundan di seluruh zona, dimulai dengan penulisan awal. Tidak ada operasi tulis yang hilang jika zona tidak tersedia. Jika terjadi pemadaman layanan regional, bucket regional di region tersebut akan offline hingga region tersebut tersedia lagi.
Jika memerlukan ketersediaan yang lebih tinggi, Anda dapat menyimpan data dalam konfigurasi dual-region atau multi-region. Bucket dual-region dan multi-region adalah bucket tunggal (tidak ada lokasi utama dan sekunder yang terpisah), tetapi bucket ini menyimpan data dan metadata secara redundan di seluruh region. Jika terjadi pemadaman layanan regional, layanan tidak akan terganggu. Anda dapat menganggap bucket dual-region dan multi-region sebagai aktif-aktif karena Anda dapat membaca dan menulis beban kerja di lebih dari satu region secara bersamaan sementara bucket tetap sangat konsisten. Ini dapat sangat menarik bagi pelanggan yang ingin membagi beban kerja mereka di dua region sebagai bagian dari arsitektur pemulihan dari bencana (disaster recovery).
Dual-region dan multi-region memiliki konsistensi kuat karena metadata selalu ditulis secara sinkron di seluruh region. Pendekatan ini memungkinkan layanan untuk selalu menentukan versi terbaru sebuah objek dan tempat asal penyajian, termasuk dari region jarak jauh.
Data direplikasi secara asinkron. Artinya, ada periode waktu RPO saat objek yang baru ditulis mulai dilindungi sebagai objek regional, dengan redundansi di seluruh zona ketersediaan dalam satu region. Layanan kemudian mereplikasi objek di dalam jendela RPO tersebut ke satu atau beberapa region jarak jauh untuk menjadikannya geo-redundan. Setelah replikasi tersebut selesai, data dapat disajikan secara otomatis dan transparan dari region lain jika terjadi gangguan layanan regional. Replikasi Turbo adalah fitur premium yang tersedia pada bucket dual-region untuk mendapatkan jendela RPO yang lebih kecil, yang menargetkan 100% objek yang baru ditulis yang direplikasi dan dibuat geo-redundan dalam waktu 15 menit.
RPO adalah pertimbangan penting, karena selama pemadaman layanan regional, data yang baru-baru ini ditulis ke region yang terpengaruh dalam jendela RPO mungkin belum direplikasi ke region lain. Akibatnya, data tersebut mungkin tidak dapat diakses selama pemadaman layanan, dan dapat hilang jika terjadi penghancuran secara fisik data di region yang terpengaruh.
Cloud Translation
Cloud Translation memiliki server komputasi aktif di beberapa zona dan region. Ini juga mendukung replikasi data sinkron di seluruh zona dalam region. Fitur ini membantu Translation mencapai failover seketika tanpa kehilangan data apa pun akibat kegagalan zona, dan tanpa memerlukan input atau penyesuaian apa pun dari pelanggan. Jika terjadi kegagalan regional, Cloud Translation tidak tersedia.
Compute Engine
Compute Engine adalah salah satu opsi infrastructure-as-a-service Google Cloud. Compute Engine menggunakan infrastruktur Google yang mencakup seluruh dunia untuk menawarkan virtual machine (dan layanan terkait) kepada pelanggan.
Instance Compute Engine adalah resource zona. Jadi, jika terjadi pemadaman layanan zona, instance tidak akan tersedia secara default. Compute Engine menawarkan grup instance terkelola (MIG) yang dapat secara otomatis meningkatkan skala VM tambahan dari template instance yang telah dikonfigurasi sebelumnya, baik dalam satu zona maupun di beberapa zona dalam satu region. MIG ideal untuk aplikasi yang memerlukan ketahanan terhadap kehilangan zona dan bersifat stateless, tetapi memerlukan perencanaan konfigurasi dan resource. Beberapa MIG regional dapat digunakan untuk mencapai ketahanan pemadaman layanan region untuk aplikasi stateless.
Aplikasi yang memiliki workload stateful masih dapat menggunakan MIG stateful, tetapi kehati-hatian ekstra perlu dilakukan dalam perencanaan kapasitas karena tidak diskalakan secara horizontal. Dalam kedua skenario tersebut, penting untuk mengonfigurasi dan menguji template instance Compute Engine dan MIG dengan benar terlebih dahulu untuk memastikan kemampuan failover yang berfungsi ke zona lain. Baca bagian Mengembangkan arsitektur dan panduan referensi Anda sendiri di atas untuk mengetahui informasi selengkapnya.
Tenancy tunggal
Sole-tenancy memungkinkan Anda memiliki akses eksklusif ke sole-tenant node, yang merupakan server Compute Engine fisik yang dikhususkan untuk menghosting VM project Anda.
Sole-tenant node, seperti instance Compute Engine, adalah resource zona. Jika terjadi pemadaman layanan zona yang tidak mungkin terjadi, instance tersebut tidak akan tersedia. Untuk mengurangi kegagalan zona, Anda dapat membuat node khusus tenant di zona lain. Mengingat workload tertentu mungkin mendapatkan manfaat dari sole-tenant node untuk tujuan pemberian lisensi atau akuntansi CAPEX, Anda harus merencanakan strategi failover terlebih dahulu.
Membuat ulang resource ini di lokasi lain dapat menimbulkan biaya lisensi tambahan atau melanggar persyaratan akuntansi CAPEX. Untuk panduan umum, lihat Mengembangkan arsitektur dan panduan referensi Anda sendiri.
Node tenant eksklusif adalah resource zona, dan tidak dapat menahan kegagalan regional. Untuk melakukan penskalaan di seluruh zona, gunakan MIG regional.
Jaringan untuk Compute Engine
Untuk mengetahui informasi tentang penyiapan ketersediaan tinggi untuk koneksi Interconnect, lihat dokumen berikut:
Anda dapat menyediakan alamat IP eksternal dalam mode global atau regional, yang akan memengaruhi ketersediaannya jika terjadi kegagalan regional.
Ketahanan Cloud Load Balancing
Load balancer adalah komponen penting dari sebagian besar aplikasi yang sangat tersedia. Penting untuk dipahami bahwa ketahanan keseluruhan aplikasi Anda tidak hanya bergantung pada cakupan load balancer yang Anda pilih (global atau regional), tetapi juga pada redundansi layanan backend Anda.
Tabel berikut merangkum ketahanan load balancer berdasarkan distribusi atau cakupan load balancer.
| Cakupan load balancer | Arsitektur | Tahan terhadap pemadaman layanan zona | Tahan terhadap pemadaman layanan regional |
|---|---|---|---|
| Global | Setiap load balancer didistribusikan di semua region | ||
| Lintas region | Setiap load balancer didistribusikan di beberapa region | ||
| Regional | Setiap load balancer didistribusikan di beberapa zona dalam region | Pemadaman layanan di region tertentu akan memengaruhi load balancer regional di region tersebut |
Untuk mengetahui informasi selengkapnya tentang cara memilih load balancer, lihat dokumentasi Cloud Load Balancing.
Uji Konektivitas
Uji Konektivitas adalah alat diagnostik yang memungkinkan Anda memeriksa konektivitas antar-endpoint jaringan. Uji konektivitas menganalisis konfigurasi Anda dan dalam beberapa kasus melakukan analisis bidang data live antara endpoint. Endpoint adalah sumber atau tujuan traffic jaringan, seperti VM, cluster Google Kubernetes Engine (GKE), aturan penerusan load balancer, atau alamat IP. Uji Konektivitas adalah alat diagnostik tanpa komponen data plane. Layanan ini tidak memproses atau menghasilkan traffic pengguna.
Pemadaman layanan per zona: Resource Connectivity Tests bersifat global. Anda dapat mengelola dan melihatnya jika terjadi gangguan zonal. Resource Uji Konektivitas adalah hasil pengujian konfigurasi Anda. Hasil ini dapat mencakup data konfigurasi resource zonal (misalnya, instance VM) di zona yang terpengaruh. Jika terjadi pemadaman layanan, hasil analisis tidak akurat karena analisis didasarkan pada data lama dari sebelum pemadaman layanan. Jangan mengandalkannya.
Pemadaman layanan regional: Jika terjadi pemadaman layanan regional, Anda tetap dapat mengelola dan melihat resource Uji Konektivitas. Resource Uji Konektivitas dapat mencakup data konfigurasi resource regional, seperti subnetwork, di region yang terpengaruh. Jika terjadi pemadaman layanan, hasil analisis tidak akurat karena analisis didasarkan pada data lama dari sebelum pemadaman layanan. Jangan mengandalkannya.
Container Registry
Container Registry menyediakan implementasi Docker Registry yang dihosting dan skalabel yang menyimpan image container Docker secara aman dan pribadi. Container Registry mengimplementasikan HTTP Docker Registry API.
Container Registry adalah layanan global yang secara sinkron menyimpan metadata gambar secara redundan di beberapa zona dan wilayah secara default. Image container disimpan di bucket multi-regional Cloud Storage. Dengan strategi penyimpanan ini, Container Registry memberikan ketahanan pemadaman layanan zona di semua kasus, dan ketahanan pemadaman layanan regional untuk setiap data yang telah direplikasi secara asinkron ke beberapa region oleh Cloud Storage.
Database Migration Service
Database Migration Service adalah layanan Google Cloud yang terkelola sepenuhnya untuk memigrasikan database dari penyedia cloud lain atau dari pusat data lokal ke Google Cloud.
Database Migration Service dirancang sebagai bidang kontrol regional. Bidang kontrol tidak bergantung pada zona individual di region tertentu. Selama pemadaman layanan zona, Anda tetap memiliki akses ke Database Migration Service API, termasuk kemampuan untuk membuat dan mengelola tugas migrasi. Selama pemadaman layanan regional, Anda akan kehilangan akses ke resource Database Migration Service milik region tersebut hingga pemadaman layanan teratasi.
Database Migration Service bergantung pada ketersediaan database sumber dan tujuan yang digunakan untuk proses migrasi. Jika sumber Database Migration Service atau database tujuan tidak tersedia, migrasi akan berhenti membuat progres, tetapi tidak ada data inti pelanggan atau data tugas yang hilang. Tugas migrasi dilanjutkan saat database sumber dan tujuan kembali tersedia.
Misalnya, Anda dapat mengonfigurasi database Cloud SQL tujuan dengan ketersediaan tinggi (HA) yang diaktifkan untuk mendapatkan database tujuan yang tahan terhadap pemadaman layanan zona.
Migrasi Database Migration Service melalui dua fase:
- Dump penuh: Menjalankan salinan data lengkap dari sumber ke tujuan sesuai dengan spesifikasi tugas migrasi.
- Pengambilan data perubahan (CDC): Mereplikasi perubahan inkremental dari sumber ke tujuan.
Pemadaman layanan zona: Jika kegagalan zona terjadi selama salah satu fase ini, Anda tetap dapat mengakses dan mengelola resource di Database Migration Service. Migrasi data terpengaruh sebagai berikut:
- Dump penuh: Migrasi data gagal; Anda harus memulai ulang tugas migrasi setelah database tujuan menyelesaikan operasi failover.
- CDC: Migrasi data dijeda. Tugas migrasi dilanjutkan secara otomatis setelah database tujuan menyelesaikan operasi failover.
Pemadaman layanan regional: Database Migration Service tidak mendukung resource lintas regional, sehingga tidak tahan terhadap kegagalan regional.
Dataflow
Dataflow adalah layanan pemrosesan data serverless dan terkelola sepenuhnya dari Google Cloud untuk pipeline streaming dan batch. Google CloudSecara default, endpoint regional mengonfigurasi kumpulan worker Dataflow untuk menggunakan semua zona yang tersedia dalam region. Pemilihan zona dihitung untuk setiap pekerja pada saat pekerja dibuat, sehingga mengoptimalkan akuisisi resource dan penggunaan reservasi yang tidak digunakan. Dalam konfigurasi default untuk tugas Dataflow, data perantara disimpan oleh layanan Dataflow, dan status tugas disimpan di backend. Jika zona gagal, tugas Dataflow dapat terus berjalan karena worker dibuat ulang di zona lain.
Batasan berikut berlaku:
- Penempatan regional hanya didukung untuk tugas yang menggunakan Streaming Engine atau Dataflow Shuffle. Tugas yang tidak ikut Streaming Engine atau Dataflow Shuffle tidak dapat menggunakan penempatan regional.
- Penempatan regional hanya berlaku untuk VM. Ini tidak berlaku untuk resource terkait Streaming Engine dan Dataflow Shuffle.
- VM tidak direplikasi di beberapa zona. Jika VM menjadi tidak tersedia, item kerjanya akan dianggap hilang dan diproses ulang oleh VM lain.
- Jika terjadi stok habis untuk seluruh region, layanan Dataflow tidak dapat membuat VM lagi.
Merancang pipeline Dataflow untuk ketersediaan tinggi
Anda dapat menjalankan beberapa pipeline streaming secara paralel untuk pemrosesan data ketersediaan tinggi. Misalnya, Anda dapat menjalankan dua tugas streaming paralel di region yang berbeda. Menjalankan pipeline paralel memberikan redundansi geografis dan fault-tolerant untuk pemrosesan data. Dengan mempertimbangkan ketersediaan geografis sumber data dan sink, Anda dapat mengoperasikan pipeline menyeluruh dalam konfigurasi multi-region yang sangat tersedia. Untuk mengetahui informasi selengkapnya, lihat Ketersediaan tinggi dan redundansi geografis di "Mendesain alur kerja pipeline Dataflow".
Jika terjadi pemadaman layanan zona atau region, Anda dapat menghindari kehilangan data dengan menggunakan kembali langganan yang sama ke topik Pub/Sub. Untuk menjamin bahwa data tidak hilang selama shuffle, Dataflow menggunakan pencadangan upstream, yang berarti worker yang mengirim data akan mencoba kembali RPC hingga menerima konfirmasi positif bahwa data telah diterima dan bahwa efek samping dari pemrosesan data di-commit ke downstream penyimpanan persisten. Dataflow juga terus mencoba ulang RPC jika worker yang mengirim data tidak tersedia. Mencoba ulang RPC memastikan bahwa setiap data dikirimkan tepat satu kali. Untuk mengetahui informasi selengkapnya tentang jaminan Dataflow tepat satu kali, baca Tepat satu kali di Dataflow.
Jika pipeline menggunakan pengelompokan atau periode waktu, Anda dapat menggunakan fungsi Seek dari Pub/Sub atau Replay pada Kafka setelah pemadaman layanan zona atau regional untuk memproses ulang elemen data agar mendapatkan hasil perhitungan yang sama. Jika logika bisnis yang digunakan oleh pipeline tidak bergantung pada data sebelum pemadaman layanan, hilangnya data dari output pipeline dapat diminimalkan hingga 0 elemen. Jika logika bisnis pipeline mengandalkan data yang diproses sebelum pemadaman layanan (misalnya, jika jendela geser yang panjang digunakan, atau jika periode waktu global menyimpan penghitung yang terus meningkat), gunakan Snapshot Dataflow untuk menyimpan status pipeline streaming dan memulai versi baru tugas Anda tanpa kehilangan status.
Dataproc
Dataproc menyediakan kemampuan pemrosesan data batch dan streaming. Dataproc dirancang sebagai bidang kontrol regional yang memungkinkan pengguna mengelola cluster Dataproc. Bidang kontrol tidak bergantung pada zona individual di region tertentu. Oleh karena itu, selama pemadaman layanan zona, Anda mempertahankan akses ke Dataproc API, termasuk kemampuan untuk membuat cluster baru.
Anda dapat membuat cluster Dataproc di:
Cluster Dataproc di Compute Engine
Karena cluster Dataproc di Compute Engine merupakan resource zona, pemadaman layanan zona akan membuat cluster tidak tersedia, atau akan menghancurkan cluster. Dataproc tidak mengambil snapshot status cluster secara otomatis, sehingga pemadaman layanan zona dapat menyebabkan hilangnya data yang sedang diproses. Dataproc tidak mempertahankan data pengguna di dalam layanan. Pengguna dapat mengonfigurasi pipeline untuk menulis hasil ke banyak penyimpanan data; Anda harus mempertimbangkan arsitektur penyimpanan data dan memilih produk yang menawarkan ketahanan bencana yang diperlukan.
Jika zona mengalami pemadaman layanan, Anda dapat memilih untuk membuat ulang instance cluster baru di zona lain, baik dengan memilih zona lain maupun menggunakan fitur Penempatan Otomatis di Dataproc untuk memilih secara otomatis instance yang tersedia zona. Setelah cluster tersedia, pemrosesan data dapat dilanjutkan. Anda juga dapat menjalankan cluster dengan mode Ketersediaan Tinggi yang diaktifkan, sehingga mengurangi kemungkinan pemadaman layanan sebagian zona akan berdampak pada node utama dan, oleh karena itu, keseluruhan klaster.
Cluster Dataproc di GKE
Cluster Dataproc di GKE dapat bersifat zona atau regional.
Untuk mengetahui informasi selengkapnya tentang arsitektur dan kemampuan DR cluster GKE zona dan regional, lihat bagian Google Kubernetes Engine nanti dalam dokumen ini.
Datastream
Datastream adalah layanan pengambilan data perubahan (CDC) dan replikasi serverless yang memungkinkan Anda menyinkronkan data dengan andal, dan dengan latensi minimal. Datastream menyediakan replikasi data dari database operasional ke BigQuery dan Cloud Storage. Selain itu, layanan ini menawarkan integrasi yang disederhanakan dengan template Dataflow untuk membuat alur kerja kustom guna memuat data ke berbagai tujuan, seperti Cloud SQL dan Spanner.
Pemadaman layanan zona: Datastream adalah layanan multi-zona. Layanan ini dapat menahan gangguan zona yang tidak terencana dan lengkap tanpa kehilangan data atau ketersediaan. Jika terjadi kegagalan zona, Anda tetap dapat mengakses dan mengelola resource di Datastream.
Pemadaman layanan regional: Jika terjadi pemadaman layanan regional, Datastream akan tersedia lagi segera setelah pemadaman layanan teratasi.
Document AI
Document AI adalah platform pemahaman dokumen yang mengambil data tidak terstruktur dari dokumen dan mengubahnya menjadi data terstruktur, sehingga lebih mudah untuk dipahami, dianalisis, dan digunakan. Document AI adalah penawaran regional. Pelanggan dapat memilih region, tetapi tidak dapat memilih zona dalam region tersebut. Data dan traffic akan otomatis di-load balanced di seluruh zona dalam satu region. Server secara otomatis diskalakan untuk memenuhi traffic masuk dan di-load balanced di seluruh zona sesuai kebutuhan. Setiap zona mempertahankan scheduler yang menyediakan penskalaan otomatis per zona. Scheduler juga mengetahui beban yang diterima zona lain dan menyediakan kapasitas ekstra dalam zona untuk memungkinkan terjjadinya kegagalan zona.
Pemadaman layanan zona: Document AI menyimpan dokumen pengguna dan data versi prosesor. Data ini disimpan secara regional dan ditulis secara sinkron. Karena data disimpan secara regional, operasi bidang data tidak terpengaruh oleh kegagalan zona. Traffic secara otomatis dirutekan ke zona lain jika terjadi kegagalan zona, dengan penundaan berdasarkan waktu yang diperlukan untuk memulihkan layanan dependen, seperti Vertex AI.
Pemadaman layanan regional: Data tidak pernah direplikasi di seluruh region. Selama pemadaman layanan regional, Document AI tidak akan melakukan failover. Pelanggan memilih region Google Cloud tempat mereka ingin menggunakan Document AI. Namun, traffic pelanggan tersebut tidak pernah dirutekan ke wilayah lain.
Verifikasi Endpoint
Dengan Verifikasi Endpoint, administrator dan profesional operasi keamanan dapat membuat inventaris perangkat yang mengakses data organisasi. Verifikasi Endpoint juga memberikan kepercayaan perangkat yang penting dan kontrol akses berbasis keamanan sebagai bagian dari solusi Chrome Enterprise Premium.
Gunakan Verifikasi Endpoint jika Anda ingin melihat ringkasan postur keamanan perangkat laptop dan desktop organisasi Anda. Saat Verifikasi Endpoint disambungkan dengan penawaran Chrome Enterprise Premium, Verifikasi Endpoint membantu menerapkan kontrol akses terperinci pada Google Cloud resource Anda.
Verifikasi Endpoint tersedia untuk Google Cloud, Cloud Identity, Google Workspace Business, dan Google Workspace Enterprise.
Eventarc
Eventarc menyediakan peristiwa yang dikirim secara asinkron dari penyedia Google (pihak pertama), aplikasi pengguna (pihak kedua), dan software as a service (pihak ketiga) menggunakan layanan yang dikaitkan secara longgar yang bereaksi terhadap perubahan status. Dengan begitu, pelanggan dapat mengonfigurasi tujuan mereka (misalnya, instance Cloud Run atau fungsi Cloud Run generasi ke-2) untuk dipicu saat terjadi suatu peristiwa di layanan penyedia peristiwa atau kode pelanggan.
Pemadaman layanan zona: Eventarc menyimpan metadata yang terkait dengan pemicu. Data ini disimpan secara regional dan ditulis secara sinkron. Eventarc API yang membuat serta mengelola pemicu dan saluran hanya menampilkan panggilan API jika data telah di-commit ke kuorum dalam suatu region. Karena data disimpan secara regional, operasi bidang data tidak terpengaruh oleh kegagalan zona. Jika terjadi kegagalan zona, traffic akan otomatis dirutekan ke zona lain. Layanan Eventarc untuk menerima dan menayangkan peristiwa pihak kedua dan pihak ketiga direplikasi di seluruh zona. Layanan ini didistribusikan secara regional. Permintaan ke zona yang tidak tersedia akan otomatis disajikan dari zona yang tersedia di region tersebut.
Pemadaman layanan regional: Pelanggan memilih Google Cloud region yang diinginkan untuk membuat pemicu Eventarc. Data tidak pernah direplikasi di berbagai region. Traffic pelanggan tidak pernah dirutekan oleh Eventarc ke region yang berbeda. Jika terjadi kegagalan layanan regional, Eventarc akan tersedia kembali segera setelah pemadaman layanan teratasi. Untuk mencapai ketersediaan yang lebih tinggi, pelanggan dianjurkan untuk men-deploy pemicu ke beberapa region jika diinginkan.
Perhatikan hal-hal berikut:
- Layanan Eventarc untuk menerima dan menayangkan peristiwa pihak pertama disediakan berdasarkan upaya terbaik dan tidak tercakup oleh RTO/RPO.
- Penayangan peristiwa Eventarc untuk layanan Google Kubernetes Engine diberikan atas dasar upaya terbaik dan tidak tercakup oleh RTO/RPO.
Filestore
Tingkat Basic dan Zonal adalah resource zona. Keduanya tidak toleran terhadap kegagalan zona atau region yang di-deploy.
Instance Filestore tingkat regional adalah resource regional. Filestore mengadopsi kebijakan konsistensi ketat yang diperlukan oleh NFS. Saat klien menulis data, Filestore tidak menampilkan konfirmasi hingga perubahan dipertahankan dan direplikasi dalam dua zona, sehingga pembacaan berikutnya menampilkan data yang benar.
Jika terjadi kegagalan zona, instance tingkat Regional akan terus menyajikan data dari zona lain, dan sementara itu menerima penulisan baru. Baik operasi baca maupun tulis mungkin memiliki performa yang menurun; operasi tulis mungkin tidak direplikasi. Enkripsi tidak disusupi karena kunci akan disajikan dari zona lain.
Sebaiknya klien membuat cadangan eksternal jika terjadi pemadaman layanan lebih lanjut di zona lain di region yang sama. Cadangan dapat digunakan untuk memulihkan instance ke region lain.
Firestore
Firestore adalah database yang fleksibel dan skalabel untuk pengembangan seluler, web, dan server dari Firebase dan Google Cloud. Firestore menawarkan replikasi data multi-region otomatis, jaminan konsistensi yang kuat, operasi batch atomik, dan transaksi ACID.
Firestore menawarkan lokasi satu region dan multi-regional kepada pelanggan. Traffic akan otomatis di-load balanced di seluruh zona dalam satu region.
Instance Firestore regional mereplikasi data secara sinkron di setidaknya tiga zona. Jika terjadi kegagalan zona, operasi tulis masih dapat di-commit oleh dua replika (atau lebih) yang tersisa, dan data yang di-commit akan dipertahankan. Traffic secara otomatis dirutekan ke zona lain. Lokasi regional menawarkan biaya yang lebih rendah, latensi tulis yang lebih rendah, dan berbagi lokasi dengan resource Google Cloud lainnya.
Instance multi-regional Firestore mereplikasi data secara sinkron di lima zona dalam tiga region (dua region penyajian dan satu region saksi), serta kuat terhadap kegagalan zona dan region. Jika terjadi kegagalan zona atau regional, data yang di-commit akan dipertahankan. Lalu lintas secara otomatis dirutekan ke zona/wilayah penyajian, dan commit masih disajikan oleh setidaknya tiga zona di dua wilayah yang tersisa. Multi-region memaksimalkan ketersediaan dan ketahanan database.
Analisis Firewall
Analisis Firewall membantu Anda memahami dan mengoptimalkan aturan firewall Anda. Solusi ini memberikan insight, rekomendasi, dan metrik tentang penggunaan aturan firewall Anda. Analisis Firewall juga menggunakan machine learning untuk memprediksi penggunaan aturan firewall di masa mendatang. Analisis Firewall memungkinkan Anda membuat keputusan yang lebih baik selama pengoptimalan aturan firewall. Misalnya, Analisis Firewall mengidentifikasi aturan yang diklasifikasikan sebagai terlalu permisif. Anda dapat menggunakan informasi ini untuk membuat konfigurasi firewall Anda lebih ketat.
Pemadaman layanan zona: Karena data Firewall Insights direplikasi di seluruh zona, data tersebut tidak terpengaruh oleh pemadaman layanan zona, dan traffic pelanggan akan otomatis dirutekan ke zona lain.
Pemadaman layanan regional: Karena data Firewall Insights direplikasi di seluruh region, data tersebut tidak terpengaruh oleh pemadaman layanan regional, dan traffic pelanggan secara otomatis dirutekan ke region lain.
Fleet
Fleet memungkinkan pelanggan mengelola beberapa cluster Kubernetes sebagai grup, dan memungkinkan administrator platform menggunakan layanan multi-cluster. Misalnya, fleet memungkinkan administrator menerapkan kebijakan seragam di seluruh cluster atau menyiapkan Multi Cluster Ingress.
Saat Anda mendaftarkan cluster GKE ke suatu fleet, secara default, cluster tersebut memiliki keanggotaan regional di region yang sama. Saat mendaftarkan cluster non-Google Cloud ke fleet, Anda dapat memilih region mana pun atau lokasi global. Praktik terbaiknya adalah memilih region yang dekat dengan lokasi fisik cluster. Hal ini memberikan latensi optimal saat menggunakan Connect gateway untuk mengakses cluster.
Jika terjadi pemadaman layanan zona, fungsi fleet tidak akan terpengaruh kecuali jika cluster yang mendasarinya berada di zona dan menjadi tidak tersedia.
Jika terjadi pemadaman layanan regional, fungsi fleet akan gagal secara statis untuk cluster keanggotaan dalam region. Mitigasi pemadaman layanan regional memerlukan deployment di beberapa region, seperti yang disarankan oleh Merancang pemulihan dari bencana (disaster recovery) untuk pemadaman layanan infrastruktur cloud.
Google Cloud Armor
Cloud Armor membantu Anda melindungi deployment dan aplikasi Anda dari berbagai jenis ancaman, termasuk serangan DDoS volumetrik dan serangan aplikasi seperti pembuatan skrip lintas situs dan injeksi SQL. Cloud Armor memfilter traffic yang tidak diinginkan di load balancer Google Cloud dan mencegah traffic tersebut memasuki VPC Anda dan menggunakan resource. Beberapa perlindungan ini bersifat otomatis. Beberapa di antaranya mengharuskan Anda mengonfigurasi kebijakan keamanan dan melampirkannya ke layanan atau region backend. Kebijakan keamanan Cloud Armor dengan cakupan global diterapkan di load balancer global. Kebijakan keamanan dengan cakupan regional diterapkan di load balancer regional.
Pemadaman layanan zona: Jika terjadi pemadaman layanan zona, load balancer Google Cloud akan mengalihkan traffic Anda ke zona lain tempat instance backend yang responsif tersedia. Perlindungan Cloud Armor tersedia segera setelah failover traffic karena kebijakan keamanan Cloud Armor Anda direplikasi secara sinkron ke semua zona dalam suatu region.
Pemadaman layanan regional: Jika terjadi pemadaman layanan regional, load balancer Google Cloud global akan mengalihkan traffic Anda ke region lain tempat instance backend yang responsif tersedia. Perlindungan Cloud Armor tersedia segera setelah failover traffic karena kebijakan keamanan Cloud Armor global Anda direplikasi secara sinkron ke semua region. Agar tidak terpengaruh oleh kegagalan regional, Anda harus mengonfigurasi kebijakan keamanan regional Cloud Armor untuk semua region Anda.
Google Kubernetes Engine
Google Kubernetes Engine (GKE) menawarkan layanan Kubernetes terkelola dengan menyederhanakan deployment aplikasi dalam container di Google Cloud. Anda dapat memilih antara topologi cluster regional atau zona.
- Saat membuat cluster zona, GKE akan menyediakan satu mesin bidang kontrol di zona yang dipilih, serta mesin worker (node) dalam zona yang sama.
- Untuk cluster regional, GKE menyediakan tiga mesin bidang kontrol di tiga zona berbeda dalam region yang dipilih. Secara default, node juga dibentangkan di tiga zona, meskipun Anda dapat memilih untuk membuat cluster regional dengan node yang hanya disediakan di satu zona.
- Cluster multi-zona mirip dengan cluster zona karena mencakup satu mesin master, tetapi juga menawarkan kemampuan untuk menjangkau node di beberapa zona.
Pemadaman layanan zona: Untuk menghindari pemadaman layanan zona, gunakan cluster regional. Bidang kontrol dan node didistribusikan di tiga zona berbeda dalam suatu region. Pemadaman layanan zona tidak memengaruhi bidang kontrol dan node worker yang di-deploy di dua zona lainnya.
Pemadaman layanan regional: Mitigasi pemadaman layanan regional memerlukan deployment di beberapa region. Meskipun saat ini tidak ditawarkan sebagai kemampuan produk bawaan, topologi multi-region adalah pendekatan yang diambil oleh beberapa pelanggan GKE saat ini, dan dapat diimplementasikan secara manual. Anda dapat membuat beberapa cluster regional untuk mereplikasi workload di beberapa region, dan mengontrol traffic ke cluster ini menggunakan multi-cluster ingress.
VPN dengan ketersediaan tinggi (HA)
VPN dengan ketersediaan tinggi (HA) adalah penawaran Cloud VPN tangguh yang mengenkripsi traffic Anda dengan aman dari cloud pribadi lokal, cloud pribadi virtual lainnya, atau jaringan penyedia layanan cloud lainnya ke Virtual Private Cloud (VPC) Google Cloud Anda.
Gateway VPN dengan ketersediaan tinggi (HA) memiliki dua antarmuka, masing-masing dengan alamat IP dari kumpulan alamat IP yang terpisah, dan membagi secara logis dan fisik ke seluruh PoP dan cluster yang berbeda untuk memastikan redundansi yang optimal.
Pemadaman layanan zona: Jika terjadi pemadaman layanan zona, satu antarmuka mungkin kehilangan konektivitas, tetapi traffic dialihkan ke antarmuka lainnya melalui pemilihan rute dinamis menggunakan Border Gateway Protocol (BGP).
Pemadaman layanan regional: Jika terjadi pemadaman layanan regional, kedua antarmuka dapat kehilangan konektivitas untuk jangka waktu singkat.
Identity and Access Management
Identity and Access Management (IAM) bertanggung jawab atas semua keputusan otorisasi
untuk tindakan pada resource cloud. IAM mengonfirmasi bahwa kebijakan memberikan
izin untuk setiap tindakan (di bidang data), dan memproses update untuk kebijakan tersebut
melalui panggilan SetPolicy (di bidang kontrol).
Semua kebijakan IAM direplikasi di beberapa zona dalam setiap region, sehingga membantu operasi bidang data IAM pulih dari kegagalan region lain dan toleran terhadap kegagalan zona dalam setiap region. Ketahanan bidang data IAM terhadap kegagalan zona dan kegagalan region memungkinkan arsitektur multi-region dan multi-zona untuk ketersediaan tinggi.
Operasi bidang kontrol IAM dapat bergantung pada replikasi
lintas region. Saat panggilan SetPolicy berhasil, data telah ditulis ke
beberapa region, tetapi propagasi ke region lain adalah konsistensi tertunda.
Bidang kontrol IAM tahan terhadap kegagalan region tunggal.
Identity-Aware Proxy
Identity-Aware Proxy menyediakan akses ke aplikasi yang dihosting di Google Cloud, di cloud lain, dan di infrastruktur lokal. IAP didistribusikan secara regional, dan permintaan ke zona yang tidak tersedia akan otomatis disajikan dari zona lain yang tersedia di region tersebut.
Pemadaman layanan regional dalam IAP memengaruhi akses ke aplikasi yang dihosting di region yang terpengaruh. Sebaiknya Anda melakukan deployment ke beberapa region dan menggunakan Cloud Load Balancing untuk mencapai ketersediaan dan ketahanan yang lebih tinggi terhadap pemadaman layanan regional.
Identity Platform
Identity Platform memungkinkan pelanggan menambahkan pengelolaan akses dan identitas level Google yang dapat disesuaikan ke aplikasi mereka. Identity Platform adalah penawaran global. Pelanggan tidak dapat memilih region atau zona tempat data mereka disimpan.
Pemadaman layanan zona: Selama pemadaman layanan zona, Identity Platform melakukan failover permintaan ke sel terdekat berikutnya. Semua data disimpan dalam skala global, sehingga tidak ada data yang hilang.
Pemadaman layanan regional: Selama pemadaman layanan regional, permintaan Identity Platform ke region yang tidak tersedia akan gagal untuk sementara saat Identity Platform menghapus traffic dari region yang terpengaruh. Setelah tidak ada lagi traffic ke region yang terpengaruh, layanan load balancing server global akan merutekan permintaan ke region responsif terdekat yang tersedia. Semua data disimpan secara global, sehingga tidak ada data yang hilang.
Inferensi Knative
Layanan Knative adalah layanan global yang memungkinkan pelanggan menjalankan workload serverless di cluster pelanggan. Tujuannya adalah untuk memastikan bahwa workload layanan Knative di-deploy dengan benar di cluster pelanggan dan status penginstalan layanan Knative tercermin dalam resource Fitur GKE Fleet API. Layanan ini hanya berpartisipasi saat menginstal atau mengupgrade resource penayangan Knative di cluster pelanggan. Node ini tidak terlibat dalam menjalankan beban kerja cluster. Cluster pelanggan yang termasuk dalam project yang mengaktifkan layanan Knative didistribusikan di antara replika di beberapa region dan zona. Setiap cluster dipantau oleh satu replika.
Pemadaman layanan zonal dan regional: Cluster yang dipantau oleh replika yang dihosting di lokasi yang mengalami pemadaman layanan, akan otomatis didistribusikan ulang di antara replika yang responsif di zona dan region lain. Selama penetapan ulang ini berlangsung, mungkin ada waktu singkat saat beberapa cluster tidak dipantau oleh layanan Knative. Jika selama waktu tersebut pengguna memutuskan untuk mengaktifkan fitur penayangan Knative di cluster, penginstalan resource penayangan Knative di cluster akan dimulai setelah cluster terhubung kembali dengan replika layanan penayangan Knative yang berfungsi dengan baik.
Looker (Google Cloud core)
Looker (Google Cloud core) adalah platform business intelligence yang menyediakan penyediaan, konfigurasi, dan pengelolaan instance Looker yang disederhanakan dan dioptimalkan dari konsol Google Cloud . Looker (Google Cloud core) memungkinkan pengguna menjelajahi data, membuat dasbor, menyiapkan pemberitahuan, dan membagikan laporan. Selain itu, Looker (inti Google Cloud) menawarkan IDE untuk pemodel data serta fitur API dan penyematan yang canggih untuk developer.
Looker (Google Cloud core) terdiri dari instance yang diisolasi secara regional yang mereplikasi data secara sinkron di seluruh zona dalam region tersebut. Pastikan resource yang digunakan instance Anda, seperti sumber data yang terhubung ke Looker (inti Google Cloud), berada di region yang sama dengan tempat instance Anda berjalan.
Pemadaman layanan zona: Instance Looker (Google Cloud core) menyimpan metadata dan container yang di-deploy sendiri. Data ditulis secara sinkron di seluruh instance yang direplikasi. Jika terjadi pemadaman layanan zona, instance Looker (inti Google Cloud) akan terus melayani dari zona lain yang tersedia di region yang sama. Setiap transaksi atau panggilan API akan ditampilkan setelah data di-commit ke kuorum dalam suatu region. Jika replikasi gagal, transaksi tidak akan dilakukan dan pengguna akan diberi tahu tentang kegagalan tersebut. Jika lebih dari satu zona gagal, transaksi juga akan gagal dan pengguna akan diberi tahu. Looker (Google Cloud core) menghentikan jadwal atau kueri yang sedang berjalan. Anda harus menjadwalkan ulang atau mengantrekannya lagi setelah menyelesaikan kegagalan.
Pemadaman layanan regional: Instance Looker (Google Cloud core) dalam region yang terpengaruh tidak tersedia. Looker (Google Cloud core) menghentikan jadwal atau kueri yang sedang berjalan. Anda harus menjadwalkan ulang atau mengantrekan kueri lagi setelah menyelesaikan kegagalan. Anda dapat membuat instance baru secara manual di region yang berbeda. Anda juga dapat memulihkan instance menggunakan proses yang ditentukan dalam Mengimpor atau mengekspor data dari instance Looker (Google Cloud core). Sebaiknya siapkan proses ekspor data berkala untuk menyalin aset sebelumnya, jika terjadi pemadaman layanan regional.
Looker Studio
Looker Studio adalah produk visualisasi data dan business intelligence. Dengan platform ini, pelanggan dapat terhubung ke data yang disimpan di sistem lain, membuat laporan dan dasbor menggunakan data tersebut, serta membagikan laporan dan dasbor ke seluruh organisasi mereka. Looker Studio adalah layanan global dan tidak mengizinkan pengguna memilih cakupan resource.
Jika terjadi pemadaman layanan zona, Looker Studio akan terus menyajikan permintaan dari zona lain di region yang sama atau di region yang berbeda tanpa gangguan. Aset pengguna direplikasi secara sinkron di berbagai wilayah. Oleh karena itu, tidak ada data yang hilang.
Jika terjadi pemadaman layanan regional, Looker Studio akan terus menyajikan permintaan dari region lain tanpa gangguan. Aset pengguna direplikasi secara sinkron di berbagai region. Oleh karena itu, tidak ada data yang hilang.
Memorystore for Memcached
Memorystore for Memcached adalah penawaran Memcached terkelola dari Google Cloud. Memorystore for Memcached memungkinkan pelanggan membuat cluster Memcached yang dapat digunakan sebagai database throughput tinggi dengan nilai kunci untuk aplikasi.
Cluster Memcache bersifat regional, dengan node yang didistribusikan di semua zona yang ditentukan pelanggan. Namun, Memcached tidak mereplikasi data apa pun di seluruh node. Oleh karena itu, kegagalan zona dapat menyebabkan hilangnya data, yang juga dijelaskan sebagai pengosongan cache parsial. Instance Memcache akan terus beroperasi, tetapi memiliki node yang lebih sedikit—layanan tidak akan memulai node baru selama kegagalan zona. Node Memcache di zona yang tidak terpengaruh akan terus menyajikan traffic, meskipun kegagalan zona akan menghasilkan rasio cache ditemukan yang lebih rendah hingga zona tersebut dipulihkan.
Jika terjadi kegagalan regional, node Memcached tidak menyalurkan traffic. Dalam hal ini, data akan hilang, yang menyebabkan pengosongan cache sepenuhnya. Untuk mengurangi pemadaman layanan regional, Anda dapat menerapkan arsitektur yang men-deploy aplikasi dan Memorystore for Memcached di beberapa region.
Memorystore for Redis
Memorystore for Redis adalah layanan Redis yang terkelola sepenuhnya untuk Google Cloud, yang dapat mengurangi beban pengelolaan deployment Redis yang kompleks. Paket ini saat ini menawarkan 2 tingkat: Paket Dasar dan Paket Standar. Untuk Paket Dasar, pemadaman layanan zona atau regional akan menyebabkan hilangnya data, yang juga dikenal sebagai pengosongan cache sepenuhnya. Untuk Paket Standar, pemadaman layanan regional akan menyebabkan hilangnya data. Pemadaman layanan zona dapat menyebabkan hilangnya data parsial pada instance Tingkat Standar karena replikasi asinkronnya.
Pemadaman layanan zona: Instance Tingkat Standar mereplikasi operasi set data secara asinkron dari set data di node utama ke node replika. Saat pemadaman layanan terjadi di dalam zona node utama, node replika akan dipromosikan untuk menjadi node utama. Selama promosi, terjadi failover dan klien Redis harus terhubung kembali ke instance. Setelah terhubung kembali, operasi dilanjutkan. Untuk mengetahui informasi selengkapnya tentang ketersediaan tinggi instance Memorystore for Redis dalam Paket Standar, lihat Ketersediaan tinggi Memorystore for Redis.
Jika Anda mengaktifkan replika baca dalam instance Tingkat Standar dan hanya memiliki satu replika, endpoint baca tidak akan tersedia selama pemadaman layanan zona. Untuk mengetahui informasi selengkapnya tentang pemulihan dari bencana (disaster recovery) pada replika baca, lihat Mode kegagalan untuk replika baca.
Pemadaman layanan regional: Memorystore for Redis adalah produk regional, sehingga satu instance tidak dapat menahan kegagalan regional. Anda dapat menjadwalkan tugas berkala untuk mengekspor instance Redis ke bucket Cloud Storage di region yang berbeda. Saat terjadi pemadaman layanan regional, Anda dapat memulihkan instance Redis di region yang berbeda dari set data yang telah diekspor.
Penemuan Layanan Multi-Cluster dan Multi Cluster Ingress
Layanan multi-cluster (MCS) GKE terdiri atas beberapa komponen. Komponennya meliputi hub Google Kubernetes Engine (yang mengatur beberapa cluster Google Kubernetes Engine menggunakan keanggotaan), cluster itu sendiri, dan pengontrol hub GKE (Multi Cluster Ingress, Penemuan Layanan Multi-Cluster). Pengontrol hub mengatur konfigurasi load balancer Compute Engine menggunakan backend pada beberapa cluster.
Jika terjadi pemadaman layanan zona, Penemuan Layanan Multi-Cluster akan terus menyalurkan permintaan dari zona atau region lain. Jika terjadi pemadaman layanan regional, Penemuan Layanan Multi-Cluster tidak akan mengalami failover.
Dalam kasus pemadaman layanan zona untuk Multi Cluster Ingress, jika cluster konfigurasi berada di zona dan berada dalam cakupan kegagalan, pengguna harus melakukan failover secara manual. Bidang data bersifat statis dan akan terus menyajikan traffic sampai pengguna mengalami failover. Untuk menghindari kebutuhan failover manual, gunakan cluster regional untuk cluster konfigurasi.
Dalam kasus pemadaman layanan regional, Multi Cluster Ingress tidak akan mengalami failover. Pengguna harus memiliki rencana DR untuk melakukan failover secara manual pada kluster konfigurasi. Untuk mengetahui informasi selengkapnya, lihat Menyiapkan Multi Cluster Ingress dan Mengonfigurasi Layanan multi-cluster.
Untuk mengetahui informasi selengkapnya tentang GKE, lihat bagian "Google Kubernetes Engine" di Merancang pemulihan dari bencana (disaster recovery) untuk pemadaman layanan infrastruktur cloud.
Penganalisis Jaringan
Network Analyzer secara otomatis memantau konfigurasi jaringan VPC Anda serta mendeteksi kesalahan konfigurasi dan konfigurasi yang kurang optimal. Layanan ini memberikan insight tentang topologi jaringan, aturan firewall, rute, dependensi konfigurasi, dan konektivitas ke layanan dan aplikasi. Alat ini mengidentifikasi kegagalan jaringan, memberikan informasi penyebab utama, dan menyarankan kemungkinan solusi.
Network Analyzer berjalan terus-menerus dan memicu analisis yang relevan berdasarkan pembaruan konfigurasi yang hampir real-time di jaringan Anda. Jika mendeteksi kegagalan jaringan, Penganalisis Jaringan akan mencoba mengorelasikan kegagalan tersebut dengan perubahan konfigurasi terbaru untuk mengidentifikasi penyebab utamanya. Jika memungkinkan, alat ini memberikan rekomendasi untuk menyarankan detail tentang cara memperbaiki masalah.
Network Analyzer adalah alat diagnostik tanpa komponen bidang data. Layanan ini tidak memproses atau menghasilkan traffic pengguna.
Pemadaman layanan zona: Layanan Network Analyzer direplikasi secara global, dan ketersediaannya tidak terpengaruh oleh pemadaman layanan zona.
Jika insight dari Network Analyzer berisi konfigurasi dari zona yang mengalami gangguan, hal ini akan memengaruhi kualitas data. Insight jaringan yang merujuk pada konfigurasi di zona tersebut menjadi tidak valid. Jangan mengandalkan insight yang diberikan oleh Network Analyzer selama pemadaman layanan.
Pemadaman layanan regional: Layanan Network Analyzer direplikasi secara global, dan ketersediaannya tidak terpengaruh oleh pemadaman layanan regional.
Jika insight dari Network Analyzer berisi konfigurasi dari wilayah yang mengalami gangguan, hal ini akan memengaruhi kualitas data. Insight jaringan yang merujuk pada konfigurasi di region tersebut menjadi tidak valid. Jangan mengandalkan insight yang diberikan oleh Network Analyzer selama pemadaman layanan.
Topologi Jaringan
Network Topology adalah alat visualisasi yang menunjukkan topologi infrastruktur jaringan Anda. Tampilan Infrastruktur menampilkan jaringan Virtual Private Cloud (VPC), konektivitas hybrid ke dan dari jaringan lokal Anda, konektivitas ke layanan yang dikelola Google, serta metrik terkait.
Pemadaman layanan zonal: Jika terjadi pemadaman layanan zonal, data untuk zona tersebut tidak akan muncul di Network Topology. Data untuk zona lain tidak terpengaruh.
Pemadaman layanan regional: Jika terjadi pemadaman layanan regional, data untuk region tersebut tidak akan muncul di Network Topology. Data untuk wilayah lain tidak terpengaruh.
Dasbor Performa
Dasbor Performa memberikan visibilitas terkait performa seluruh Google Cloud jaringan, serta performa resource project Anda.
Dengan kemampuan pemantauan performa ini, Anda dapat membedakan antara masalah di aplikasi dan masalah di jaringan Google Cloud yang mendasarinya. Anda juga dapat menyelidiki masalah performa jaringan historis. Dasbor Performa juga mengekspor data ke Cloud Monitoring. Anda dapat menggunakan Monitoring untuk membuat kueri data dan mendapatkan akses ke informasi tambahan.
Pemadaman layanan zona:
Jika terjadi pemadaman layanan zona, data latensi dan kehilangan paket untuk traffic dari zona yang terpengaruh tidak akan muncul di Dasbor Performa. Data latensi dan kehilangan paket untuk traffic dari zona lain tidak terpengaruh. Saat gangguan berakhir, data latensi dan kehilangan paket akan dilanjutkan.
Pemadaman layanan regional:
Jika terjadi pemadaman layanan regional, data latensi dan kehilangan paket untuk traffic dari region yang terpengaruh tidak akan muncul di Performance Dashboard. Data latensi dan kehilangan paket untuk traffic dari region lain tidak terpengaruh. Saat gangguan berakhir, data latensi dan kehilangan paket akan dilanjutkan.
Network Connectivity Center
Network Connectivity Center adalah produk pengelolaan konektivitas jaringan yang menggunakan arsitektur hub-and-spoke. Dengan arsitektur ini, resource pengelolaan terpusat berfungsi sebagai hub dan setiap resource konektivitas berfungsi sebagai spoke. Spoke hybrid saat ini mendukung VPN dengan ketersediaan tinggi (HA), Dedicated and Partner Interconnect, serta peralatan router SD-WAN dari vendor pihak ketiga utama. Dengan spoke hybrid Network Connectivity Center, perusahaan dapat menghubungkan Google Cloud workload dan layanan ke pusat data lokal, cloud lain, dan kantor cabangnya melalui jangkauan global Google Cloud jaringan.
Pemadaman layanan zona: Spoke hybrid Network Connectivity Center dengan konfigurasi HA tahan terhadap kegagalan zona karena bidang kontrol dan bidang data jaringan redundan di beberapa zona dalam satu region.
Pemadaman layanan regional: Spoke hybrid Network Connectivity Center adalah resource regional, sehingga tidak dapat menahan kegagalan regional.
Network Service Tiers
Network Service Tiers dapat Anda gunakan untuk mengoptimalkan konektivitas antara sistem di internet dan instance Anda. Google Cloud Layanan ini menawarkan dua tingkat layanan yang berbeda, yaitu Tingkat Premium dan Tingkat Standar. Dengan Paket Premium, alamat IP Premium Paket Premium yang diumumkan secara global dapat berfungsi sebagai frontend untuk backend regional atau global. Dengan Paket Standar, alamat IP Paket Standar yang diumumkan secara regional dapat berfungsi sebagai frontend untuk backend regional. Ketahanan keseluruhan aplikasi dipengaruhi oleh tingkat layanan jaringan dan redundansi backend yang terkait dengannya.
Pemadaman layanan zona: Paket Premium dan Paket Standar menawarkan ketahanan terhadap pemadaman layanan zona jika dikaitkan dengan backend yang redundan secara regional. Saat terjadi pemadaman zonal, perilaku failover untuk kasus yang menggunakan backend yang redundan secara regional ditentukan oleh backend terkait itu sendiri. Jika dikaitkan dengan backend zonal, layanan akan tersedia kembali segera setelah pemadaman layanan teratasi.
Pemadaman layanan regional: Paket Premium menawarkan ketahanan terhadap pemadaman layanan regional jika dikaitkan dengan backend yang redundan secara global. Pada tingkat Standar, semua traffic ke region yang terpengaruh akan gagal. Traffic ke semua region lain tidak terpengaruh. Jika terjadi gangguan regional, perilaku failover untuk kasus yang menggunakan Paket Premium dengan backend yang redundan secara global ditentukan oleh backend terkait itu sendiri. Saat menggunakan Tingkat Premium dengan backend regional atau Tingkat Standar, layanan akan tersedia kembali segera setelah pemadaman layanan teratasi.
Organization Policy Service
Layanan Kebijakan Organisasi memberikan kontrol terpusat dan terprogram atas resource Google Cloud organisasi Anda. Sebagai administrator Kebijakan Organisasi, Anda dapat mengonfigurasi batasan di seluruh hierarki resource Anda.
Pemadaman layanan zona: Semua kebijakan organisasi yang dibuat oleh Organization Policy Service direplikasi secara asinkron di beberapa zona dalam setiap region. Data Kebijakan Organisasi dan operasi bidang kontrol toleran terhadap kegagalan zona dalam setiap region.
Pemadaman layanan regional: Semua kebijakan organisasi yang dibuat oleh Layanan Kebijakan Organisasi direplikasi secara asinkron di beberapa region. Operasi bidang kontrol Kebijakan Organisasi ditulis ke beberapa region dan propagasi ke region lain konsisten dalam beberapa menit. Bidang kontrol Kebijakan Organisasi tahan terhadap kegagalan region tunggal. Operasi bidang data Kebijakan Organisasi dapat pulih dari kegagalan di region lain dan ketahanan bidang data Kebijakan Organisasi terhadap kegagalan zona dan kegagalan region memungkinkan arsitektur multi-region dan multi-zona untuk ketersediaan tinggi.
Duplikasi Paket
Duplikasi Paket meng-clone traffic instance tertentu di jaringan Virtual Private Cloud (VPC) Anda dan meneruskan data yang di-clone ke instance di balik load balancer internal regional untuk diperiksa. Duplikasi Paket merekam semua data traffic dan paket, termasuk payload dan header.
Untuk mengetahui informasi selengkapnya tentang fungsi Duplikasi Paket, lihat halaman ringkasan Duplikasi Paket.
Pemadaman layanan zona: Konfigurasikan load balancer internal agar ada instance di beberapa zona. Jika terjadi pemadaman layanan zona, Duplikasi Paket mengalihkan paket yang di-clone ke zona yang sehat.
Pemadaman layanan regional: Duplikasi Paket adalah produk regional. Jika ada pemadaman layanan regional, paket di region yang terpengaruh tidak akan di-clone.
Persistent Disk
Persistent Disk tersedia dalam konfigurasi zona dan regional.
Persistent Disk Zonal dihosting di satu zona. Jika zona disk tidak tersedia, Persistent Disk tidak akan tersedia hingga pemadaman layanan zona diselesaikan.
Persistent Disk Regional menyediakan replikasi data sinkron di antara dua zona dalam satu region. Jika terjadi pemadaman layanan di zona virtual machine, Anda dapat memasang Persistent Disk regional ke instance VM di zona sekunder disk secara paksa. Untuk melakukan tugas ini, Anda harus memulai instance VM lain di zona tersebut atau mempertahankan instance VM hot standby di zona tersebut.
Untuk mereplikasi data secara asinkron di Persistent Disk di seluruh region, Anda dapat menggunakan Replikasi Asinkron Persistent Disk (Replikasi Asinkron PD), yang menyediakan replikasi block storage dengan RTO dan RPO rendah untuk DR aktif-pasif lintas region. Jika terjadi pemadaman listrik regional, Replikasi Asinkron PD memungkinkan Anda melakukan failover data ke region sekunder dan memulai ulang workload di region tersebut.
Personalized Service Health
Personalized Service Health menginformasikan gangguan layanan yang relevan dengan project Anda. Google Cloud Layanan ini menyediakan beberapa saluran dan proses untuk melihat atau mengintegrasikan peristiwa yang mengganggu (insiden, pemeliharaan terencana) ke dalam proses respons insiden Anda—termasuk yang berikut:
- Dasbor di konsol Google Cloud
- API layanan
- Notifikasi yang dapat dikonfigurasi
- Log yang dibuat dan dikirim ke Cloud Logging
Pemadaman layanan zona: Data disajikan dari database global tanpa ketergantungan pada lokasi tertentu. Jika terjadi pemadaman layanan zona, Service Health dapat menyalurkan permintaan dan otomatis merutekan ulang traffic ke zona di region yang sama yang masih berfungsi. Service Health dapat menampilkan panggilan API dengan berhasil jika dapat mengambil data peristiwa dari database Service Health.
Pemadaman layanan regional: Data disajikan dari database global tanpa ketergantungan pada lokasi tertentu. Jika terjadi pemadaman layanan regional, Service Health masih dapat melayani permintaan, tetapi mungkin beroperasi dengan kapasitas yang berkurang. Kegagalan regional di lokasi Logging dapat memengaruhi pengguna Service Health yang menggunakan log atau notifikasi pemberitahuan cloud.
Private Service Connect
Private Service Connect adalah kemampuan Google Cloud jaringan yang memungkinkan konsumen mengakses layanan terkelola secara pribadi dari dalam jaringan VPC mereka. Demikian pula, hal ini memungkinkan produsen layanan terkelola menghosting layanan ini di jaringan VPC masing-masing yang terpisah dan menawarkan koneksi pribadi kepada konsumen mereka.
Endpoint Private Service Connect untuk layanan yang ditayangkan
Endpoint Private Service Connect terhubung ke layanan di jaringan VPC produsen layanan menggunakan aturan penerusan Private Service Connect. Produsen layanan menyediakan layanan menggunakan konektivitas pribadi kepada konsumen layanan, dengan mengekspos lampiran layanan tunggal. Selanjutnya, konsumen layanan dapat menetapkan alamat IP virtual dari VPC mereka untuk layanan tersebut.
Pemadaman layanan zona: Traffic Private Service Connect yang berasal dari traffic VM yang dihasilkan oleh endpoint klien VPC konsumen masih dapat mengakses layanan terkelola yang terekspos di jaringan VPC internal produsen layanan. Akses ini dimungkinkan karena traffic Private Service Connect melakukan failover ke backend layanan yang lebih sehat di zona yang berbeda.
Pemadaman layanan regional: Private Service Connect adalah produk regional. Layanan ini tidak tahan terhadap pemadaman layanan regional. Layanan terkelola multi-regional dapat mencapai ketersediaan tinggi selama pemadaman layanan regional dengan mengonfigurasi endpoint Private Service Connect di beberapa region.
Endpoint Private Service Connect untuk Google API
Endpoint Private Service Connect terhubung ke Google API menggunakan aturan penerusan Private Service Connect. Aturan penerusan ini memungkinkan pelanggan menggunakan nama endpoint yang disesuaikan dengan alamat IP internal mereka.
Pemadaman layanan zona: Traffic Private Service Connect dari endpoint klien VPC konsumen masih dapat mengakses Google API karena konektivitas antara VM dan endpoint akan otomatis melakukan failover ke zona fungsional lain di region yang sama. Permintaan yang sudah dalam proses saat gangguan dimulai akan bergantung pada perilaku coba lagi dan waktu tunggu TCP klien untuk pemulihan.
Lihat pemulihan Compute Engine untuk mengetahui detail selengkapnya.
Pemadaman layanan regional: Private Service Connect adalah produk regional. Layanan ini tidak tahan terhadap pemadaman layanan regional. Layanan terkelola multi-regional dapat mencapai ketersediaan tinggi selama pemadaman layanan regional dengan mengonfigurasi endpoint Private Service Connect di beberapa region.
Untuk mengetahui informasi selengkapnya tentang Private Service Connect, lihat bagian "Endpoint" pada jenis Private Service Connect.
Pub/Sub
Pub/Sub adalah layanan pesan untuk integrasi aplikasi dan analisis streaming. Topik Pub/Sub bersifat global, artinya dapat dilihat dan diakses dari Google Cloud lokasi mana pun. Namun, setiap pesan yang dimaksud disimpan dalam satu region Google Cloud , yang terdekat dengan penayang dan diizinkan oleh kebijakan lokasi resource. Dengan demikian, topik dapat memiliki pesan yang disimpan di berbagai region di seluruh Google Cloud. Kebijakan penyimpanan pesan Pub/Sub dapat membatasi region tempat pesan disimpan.
Pemadaman layanan zona: Saat pesan Pub/Sub dipublikasikan, pesan tersebut ditulis secara sinkron ke penyimpanan di setidaknya dua zona dalam region. Oleh karena itu, jika satu zona menjadi tidak tersedia, tidak ada dampak yang terlihat oleh pelanggan.
Pemadaman layanan regional: Selama pemadaman layanan region, pesan yang disimpan dalam region yang terpengaruh tidak dapat diakses. Penayang dan pelanggan yang akan terhubung ke region yang terpengaruh, baik melalui endpoint regional maupun endpoint global, tidak dapat terhubung. Penerbit dan pelanggan yang terhubung ke wilayah lain tetap dapat terhubung, dan pesan yang tersedia di wilayah lain akan dikirimkan ke pelanggan jaringan terdekat yang memiliki kapasitas.
Jika aplikasi Anda mengandalkan pengurutan pesan, tinjau rekomendasi mendetail dari tim Pub/Sub. Jaminan pengurutan pesan disediakan per region, dan dapat terganggu jika Anda menggunakan endpoint global.
reCAPTCHA
reCAPTCHA adalah layanan global yang mendeteksi aktivitas penipuan, spam, dan penyalahgunaan. Layanan ini tidak memerlukan atau mengizinkan konfigurasi untuk ketahanan regional atau zona. Update pada metadata konfigurasi direplikasi secara asinkron ke setiap region tempat reCAPTCHA dijalankan.
Jika terjadi pemadaman layanan zona, reCAPTCHA akan terus menyajikan permintaan dari zona lain di region yang sama atau berbeda tanpa gangguan.
Jika terjadi pemadaman layanan regional, reCAPTCHA akan terus menyajikan permintaan dari region lain tanpa gangguan.
Secret Manager
Secret Manager adalah produk pengelolaan secret dan kredensial untuk Google Cloud. Dengan Secret Manager, Anda dapat dengan mudah mengaudit dan membatasi akses ke secret, mengenkripsi secret saat istirahat, dan memastikan informasi sensitif diamankan di Google Cloud.
Resource Secret Manager biasanya dibuat dengan kebijakan replikasi otomatis (direkomendasikan), yang menyebabkannya direplikasi secara global. Jika organisasi Anda memiliki kebijakan yang tidak mengizinkan replikasi global data secret, resource Secret Manager dapat dibuat dengan kebijakan replikasi yang dikelola pengguna. Dalam kebijakan tersebut, satu atau beberapa region dipilih untuk dijadikan rahasia direplikasi.
Pemadaman layanan zona: Jika terjadi pemadaman layanan zona, Secret Manager akan terus menyajikan permintaan dari zona lain di region yang sama atau berbeda tanpa gangguan. Dalam setiap region, Secret Manager selalu mempertahankan setidaknya 2 replika di zona terpisah (di sebagian besar region, 3 replika). Jika pemadaman layanan zona telah diatasi, redundansi penuh akan dipulihkan.
Pemadaman layanan regional: Jika terjadi pemadaman layanan regional, Secret Manager akan terus menyajikan permintaan dari region lain tanpa gangguan, dengan asumsi bahwa data telah direplikasi ke lebih dari satu region (baik melalui replikasi otomatis maupun melalui replikasi yang dikelola pengguna ke lebih dari satu region). Jika pemadaman layanan region diselesaikan, redundansi penuh akan dipulihkan.
Security Command Center
Security Command Center adalah platform pengelolaan risiko global dan real time untuk Google Cloud. Platform ini terdiri dari dua komponen utama: detektor dan temuan.
Detektor terpengaruh oleh pemadaman layanan regional dan zona dengan cara yang berbeda. Selama pemadaman layanan regional, detektor tidak dapat menghasilkan temuan baru untuk resource regional karena resource yang seharusnya dipindai tidak tersedia.
Selama pemadaman layanan zona, detektor dapat memerlukan waktu dari beberapa menit hingga jam untuk melanjutkan operasi secara normal. Security Command Center tidak akan kehilangan data temuan. Data temuan baru juga tidak akan dihasilkan untuk resource yang tidak tersedia. Dalam skenario terburuk, agen Deteksi Ancaman Container mungkin kehabisan ruang buffer saat terhubung ke sel yang sehat, yang dapat menyebabkan hilangnya deteksi.
Temuan tahan terhadap pemadaman layanan regional dan zona karena direplikasi secara sinkron di berbagai region.
Perlindungan Data Sensitif (termasuk DLP API)
Perlindungan Data Sensitif menyediakan layanan klasifikasi data sensitif, pembuatan profil, de-identifikasi, tokenisasi, dan analisis risiko privasi. Layanan ini berfungsi secara sinkron pada data yang dikirim dalam isi permintaan, atau secara asinkron pada data yang sudah ada di sistem penyimpanan cloud. Perlindungan Data Sensitif dapat dipanggil melalui endpoint global atau khusus region.
Endpoint global: Layanan ini dirancang agar tahan terhadap kegagalan
regional dan zona. Jika layanan kelebihan beban saat kegagalan terjadi, data
yang dikirim ke metode hybridInspect
layanan mungkin akan hilang.
Untuk membuat arsitektur yang tahan terhadap kegagalan, sertakan logika untuk memeriksa temuan
pra-kegagalan terbaru yang dihasilkan oleh metode hybridInspect. Jika terjadi
pemadaman layanan, data yang dikirim ke metode mungkin akan hilang, tetapi tidak
lebih dari 10 menit terakhir sebelum peristiwa kegagalan. Jika ada
temuan yang lebih baru dari 10 menit sebelum pemadaman layanan dimulai, hal ini menunjukkan
data yang menghasilkan temuan tersebut tidak hilang. Dalam hal ini, Anda tidak perlu
memutar ulang data yang muncul sebelum stempel waktu temuan, meskipun data tersebut berada dalam
interval 10 menit.
Endpoint regional: Endpoint regional tidak tahan terhadap kegagalan regional. Jika diperlukan ketahanan terhadap kegagalan regional, pertimbangkan untuk melakukan failover ke region lain. Karakteristik kegagalan zona sama dengan yang di atas.
Service Usage
Service Usage API adalah layanan infrastruktur Google Cloud yang memungkinkan Anda mencantumkan dan mengelola API serta layanan di project Google Cloud . Anda dapat membuat daftar dan mengelola API serta Layanan yang disediakan oleh Google, Google Cloud, dan produsen pihak ketiga. Service Usage API adalah layanan global dan andal terhadap pemadaman layanan zona dan regional. Jika terjadi pemadaman layanan zona atau pemadaman layanan regional, Service Usage API akan terus melayani permintaan dari zona lain di berbagai region.
Untuk mengetahui informasi selengkapnya tentang Penggunaan Layanan, lihat Dokumentasi Service Usage.
Speech-to-Text
Speech-to-Text memungkinkan Anda mengonversi audio ucapan menjadi teks menggunakan teknik machine learning seperti model jaringan neural. Audio dikirim secara real time dari mikrofon aplikasi, atau diproses sebagai batch file audio.
Pemadaman layanan zona:
Speech-to-Text API v1: Selama pemadaman layanan zona, Speech-to-Text API versi 1 akan terus melayani permintaan dari zona lain di region yang sama tanpa gangguan. Namun, semua tugas yang saat ini dijalankan dalam zona yang gagal akan hilang. Pengguna harus mencoba lagi tugas yang gagal, yang akan otomatis dirutekan ke zona yang tersedia.
Speech-to-Text API v2: Selama pemadaman layanan zona, Speech-to-Text API versi 2 akan terus melayani permintaan dari zona lain di region yang sama. Namun, semua tugas yang saat ini dijalankan dalam zona yang gagal akan hilang. Pengguna harus mencoba lagi tugas yang gagal, yang akan otomatis dirutekan ke zona yang tersedia. Speech-to-Text API hanya menampilkan panggilan API setelah data di-commit ke kuorum dalam suatu region. Di beberapa region, akselerator AI (TPU) hanya tersedia di satu zona. Dalam hal ini, pemadaman di zona tersebut menyebabkan pengenalan ucapan gagal, tetapi tidak ada data yang hilang.
Pemadaman layanan regional:
Speech-to-Text API v1: Speech-to-Text API versi 1 tidak terpengaruh oleh kegagalan regional karena merupakan layanan multi-region global. Layanan akan terus melayani permintaan dari region lain tanpa gangguan. Namun, tugas yang sedang dijalankan di dalam region yang gagal akan hilang. Pengguna harus mencoba lagi tugas yang gagal tersebut, yang akan dirutekan ke region yang tersedia secara otomatis.
Speech-to-Text API v2:
Speech-to-Text API versi 2 multi-region, layanan ini akan terus melayani permintaan dari zona lain di region yang sama tanpa gangguan.
Speech-to-Text API versi 2 satu region, layanan mencakup eksekusi tugas ke region yang diminta. Speech-to-Text API versi 2 tidak merutekan traffic ke region lain, dan data tidak direplikasi ke region lain. Selama kegagalan regional, Speech-to-Text API versi 2 tidak tersedia di region tersebut. Namun, Eventarc akan tersedia kembali saat pemadaman layanan teratasi.
Storage Transfer Service
Storage Transfer Service mengelola transfer data dari berbagai sumber cloud ke Cloud Storage, serta ke, dari, dan di antara sistem file.
Storage Transfer Service API adalah resource global.
Storage Transfer Service bergantung pada ketersediaan sumber dan tujuan transfer. Jika sumber atau tujuan transfer tidak tersedia, proses transfer akan berhenti menghasilkan progres. Namun, tidak ada data inti pelanggan atau data tugas yang hilang. Transfer dilanjutkan saat sumber dan tujuan tersedia lagi.
Anda dapat menggunakan Storage Transfer Service dengan atau tanpa agen, sebagai berikut:
Transfer tanpa agen menggunakan worker regional untuk mengatur tugas transfer.
Transfer berbasis agen menggunakan agen software yang diinstal di infrastruktur Anda. Transfer berbasis agen bergantung pada ketersediaan agen transfer dan kemampuan agen untuk terhubung ke sistem file. Saat Anda memutuskan tempat menginstal agen transfer, pertimbangkan ketersediaan sistem file. Misalnya, jika Anda menjalankan agen transfer di beberapa VM Compute Engine untuk mentransfer data ke instance Filestore tingkat Enterprise (resource regional), sebaiknya cari VM di zona berbeda dalam region instance Filestore.
Jika agen menjadi tidak tersedia, atau jika koneksi mereka ke sistem file terganggu, proses transfer akan berhenti menghasilkan progres, tetapi tidak ada data yang hilang. Jika semua proses agen dihentikan, tugas transfer akan dijeda hingga agen baru ditambahkan ke kumpulan agen transfer.
Selama pemadaman layanan, perilaku Storage Transfer Service adalah sebagai berikut:
Pemadaman layanan zona: Selama pemadaman layanan zona, Storage Transfer Service API akan tetap tersedia, dan Anda dapat terus membuat tugas transfer. Data akan terus ditransfer.
Pemadaman layanan regional: Selama pemadaman layanan regional, Storage Transfer Service API akan tetap tersedia, dan Anda dapat terus membuat tugas transfer. Jika worker transfer Anda berada di wilayah yang terpengaruh, transfer data akan berhenti hingga region tersebut tersedia kembali dan transfer dilanjutkan secara otomatis.
Vertex ML Metadata
Dengan Vertex ML Metadata, Anda dapat merekam metadata dan artefak yang dihasilkan oleh sistem ML Anda dan membuat kueri metadata tersebut untuk membantu menganalisis, men-debug, dan mengaudit performa sistem ML Anda atau artefak yang dihasilkannya.
Pemadaman layanan zona: Dalam konfigurasi default, Vertex ML Metadata menawarkan perlindungan dari kegagalan zona. Layanan di-deploy di beberapa zona di setiap region, dengan data yang direplikasi secara sinkron di berbagai zona dalam setiap region. Jika terjadi kegagalan zona, zona yang tersisa akan mengambil alih dengan gangguan minimal.
Pemadaman layanan regional: Vertex ML Metadata adalah layanan regional. Jika terjadi pemadaman layanan regional, Vertex ML Metadata tidak akan melakukan failover ke region lain.
Prediksi batch Vertex AI
Prediksi batch memungkinkan pengguna menjalankan prediksi batch terhadap model AI/ML di infrastruktur Google. Prediksi batch adalah penawaran regional. Pelanggan dapat memilih region tempat mereka menjalankan tugas, tetapi tidak dapat memilih zona tertentu dalam region tersebut. Layanan prediksi batch akan otomatis melakukan load balance tugas di berbagai zona dalam region yang dipilih.
Pemadaman layanan zona: Prediksi batch menyimpan metadata untuk tugas prediksi batch dalam suatu region. Data ditulis secara sinkron di beberapa zona dalam region tersebut. Jika terjadi pemadaman layanan zona, prediksi batch akan kehilangan sebagian pekerja yang menjalankan tugas, tetapi akan otomatis menambahkannya kembali di zona lain yang tersedia. Jika beberapa percobaan ulang prediksi batch gagal, UI akan mencantumkan status tugas sebagai gagal di UI dan dalam permintaan panggilan API. Permintaan pengguna berikutnya untuk menjalankan tugas akan dirutekan ke zona yang tersedia.
Pemadaman layanan regional: Pelanggan memilih Google Cloud region tempat mereka ingin menjalankan tugas prediksi batch. Data tidak pernah direplikasi di seluruh region. Prediksi batch mencakup eksekusi tugas ke region yang diminta dan tidak pernah merutekan permintaan prediksi ke region yang berbeda. Jika terjadi kegagalan regional, prediksi batch tidak tersedia di region tersebut. Layanan ini akan tersedia kembali saat pemadaman layanan teratasi. Sebaiknya pelanggan menggunakan beberapa region untuk menjalankan tugas mereka. Jika terjadi pemadaman layanan regional, arahkan tugas ke region lain yang tersedia.
Vertex AI Model Registry
Dengan Vertex AI Model Registry, pengguna dapat menyederhanakan pengelolaan model, tata kelola, dan deployment model ML di repositori pusat. Vertex AI Model Registry adalah penawaran regional dengan ketersediaan tinggi dan menawarkan perlindungan dari pemadaman layanan zona.
Pemadaman layanan zona: Vertex AI Model Registry menawarkan perlindungan dari pemadaman layanan zona. Layanan di-deploy di tiga zona di setiap region, dengan data yang direplikasi secara sinkron di berbagai zona dalam region tersebut. Jika satu zona gagal, zona yang tersisa akan mengambil alih tanpa kehilangan data dan gangguan layanan minimum.
Pemadaman layanan regional: Vertex AI Model Registry adalah layanan regional. Jika region gagal, Model Registry tidak akan melakukan failover.
Vertex AI - Prediksi online
Prediksi online memungkinkan pengguna men-deploy model AI/ML di Google Cloud. Prediksi online adalah penawaran regional. Pelanggan dapat memilih region tempat mereka men-deploy model, tetapi tidak dapat memilih zona tertentu dalam region tersebut. Layanan prediksi akan otomatis melakukan load balance pada beban kerja di berbagai zona dalam region yang dipilih.
Pemadaman layanan zona: Prediksi online tidak menyimpan konten pelanggan apa pun. Pemadaman layanan zona menyebabkan kegagalan eksekusi permintaan prediksi saat ini. Prediksi online dapat atau tidak dapat mencoba ulang permintaan prediksi secara otomatis, bergantung pada jenis endpoint yang digunakan. Secara khusus, endpoint publik akan mencoba ulang secara otomatis, sedangkan endpoint pribadi tidak akan melakukannya. Untuk membantu menangani kegagalan dan meningkatkan ketahanan, sertakan logika percobaan ulang dengan backoff eksponensial dalam kode Anda.
Pemadaman layanan regional: Pelanggan memilih Google Cloud region tempat mereka ingin menjalankan model AI/ML dan layanan prediksi online. Data tidak pernah direplikasi di seluruh region. Prediksi online mencakup eksekusi model AI/ML ke region yang diminta dan tidak pernah merutekan permintaan prediksi ke region lain. Jika terjadi kegagalan regional, layanan prediksi online tidak akan tersedia di region tersebut. Layanan ini akan tersedia kembali setelah pemadaman layanan teratasi. Sebaiknya pelanggan menggunakan beberapa region untuk menjalankan model AI/ML mereka. Jika terjadi pemadaman layanan regional, arahkan traffic langsung ke region lain yang tersedia.
Vertex AI Pipelines
Vertex AI Pipelines adalah layanan Vertex AI yang memungkinkan Anda mengotomatiskan, memantau, dan mengelola alur kerja machine learning (ML) dengan cara serverless. Vertex AI Pipelines dibuat untuk memberikan ketersediaan tinggi dan menawarkan perlindungan terhadap kegagalan zona.
Pemadaman layanan zona: Dalam konfigurasi default, Vertex AI Pipelines menawarkan perlindungan dari kegagalan zona. Layanan di-deploy di beberapa zona di setiap region, dengan data yang direplikasi secara sinkron di berbagai zona dalam region tersebut. Jika terjadi kegagalan zona, zona yang tersisa akan mengambil alih dengan gangguan minimal.
Pemadaman layanan regional: Vertex AI Pipelines adalah layanan regional. Dalam kasus pemadaman layanan regional, Vertex AI Pipelines tidak akan melakukan failover ke region lain. Jika terjadi pemadaman layanan regional, sebaiknya jalankan tugas pipeline Anda di region cadangan.
Vertex AI Search
Vertex AI Search adalah solusi penelusuran yang dapat disesuaikan dengan fitur AI generatif dan kepatuhan perusahaan bawaan. Vertex AI Search otomatis di-deploy dan direplikasi di beberapa region dalam Google Cloud. Anda dapat mengonfigurasi lokasi penyimpanan data dengan memilih multi-region yang didukung, seperti: global, AS, atau Uni Eropa.
Pemadaman layanan Zonal dan Regional: UserEvents yang diupload ke
Vertex AI Search mungkin tidak dapat dipulihkan karena keterlambatan
replikasi asinkron. Data dan layanan lain yang disediakan oleh Vertex AI Search tetap tersedia karena failover otomatis dan replikasi data sinkron.
Vertex AI Training
Dengan Vertex AI Training, pengguna dapat menjalankan tugas pelatihan kustom di infrastruktur Google. Vertex AI Training adalah penawaran regional, yang berarti pelanggan dapat memilih region untuk menjalankan tugas pelatihan mereka. Namun, pelanggan tidak dapat memilih zona tertentu dalam region tersebut. Layanan pelatihan mungkin akan otomatis melakukan load-balance terhadap eksekusi tugas di berbagai zona dalam suatu region.
Pemadaman layanan zona: Vertex AI Training menyimpan metadata untuk tugas pelatihan kustom. Data ini disimpan secara regional dan ditulis secara sinkron. Panggilan API Vertex AI Training hanya ditampilkan setelah metadata ini di-commit ke kuorum dalam suatu region. Tugas pelatihan dapat berjalan di zona tertentu. Pemadaman layanan zona menyebabkan kegagalan eksekusi tugas saat ini. Jika demikian, layanan akan otomatis mencoba kembali tugas dengan memilih rute ke zona lain. Jika beberapa percobaan ulang gagal, status tugas akan diperbarui menjadi gagal. Permintaan pengguna berikutnya untuk menjalankan tugas akan dirutekan ke zona yang tersedia.
Pemadaman layanan regional: Pelanggan memilih Google Cloud region tempat mereka ingin menjalankan tugas pelatihan. Data tidak pernah direplikasi di seluruh region. Vertex AI Training mencakup eksekusi tugas ke region yang diminta dan tidak pernah merutekan tugas pelatihan ke region berbeda. Dalam kasus kegagalan regional, layanan Vertex AI Training tidak tersedia di region tersebut dan tersedia kembali saat pemadaman layanan teratasi. Sebaiknya pelanggan menggunakan beberapa region untuk menjalankan tugas mereka, dan jika terjadi pemadaman layanan regional, untuk mengarahkan tugas ke region lain yang tersedia.
Virtual Private Cloud (VPC)
VPC adalah layanan global yang menyediakan konektivitas jaringan ke resource (misalnya, VM). Namun, kegagalan bersifat zona. Jika terjadi kegagalan zona, resource di zona tersebut tidak akan tersedia. Demikian pula, jika region gagal, hanya traffic ke dan dari region yang gagal yang akan terpengaruh. Konektivitas region yang responsif tidak terpengaruh.
Pemadaman layanan zona: Jika jaringan VPC mencakup beberapa zona dan satu zona gagal, jaringan VPC akan tetap responsif untuk zona responsif. Traffic jaringan di antara resource di zona yang responsif akan terus berfungsi seperti biasa selama terjadi kegagalan. Kegagalan zona hanya memengaruhi traffic jaringan ke dan dari resource di zona yang gagal. Untuk mengurangi dampak kegagalan zona, sebaiknya jangan membuat semua resource di satu zona. Sebaliknya, saat Anda membuat resource, sebarkan resource di seluruh zona.
Pemadaman layanan regional: Jika jaringan VPC mencakup beberapa region dan satu region gagal, jaringan VPC akan tetap responsif untuk region yang responsif. Traffic jaringan di antara resource di region yang responsif akan terus berfungsi secara normal selama terjadi kegagalan. Kegagalan regional hanya memengaruhi traffic jaringan ke dan dari resource di region yang gagal. Untuk mengurangi dampak kegagalan regional, sebaiknya Anda menyebarkan resource di beberapa region.
Kontrol Layanan VPC
Kontrol Layanan VPC adalah layanan regional. Dengan menggunakan Kontrol Layanan VPC, tim keamanan perusahaan dapat menentukan kontrol perimeter yang terperinci dan menerapkan postur keamanan tersebut di berbagai layanan dan project Google Cloud. Google Cloud Kebijakan pelanggan diduplikasi secara regional.
Pemadaman layanan zona: Kontrol Layanan VPC terus menyajikan permintaan dari zona lain di region yang sama tanpa gangguan.
Pemadaman layanan regional: API yang dikonfigurasi untuk penerapan kebijakan Kontrol Layanan VPC di region yang terpengaruh tidak tersedia hingga region tersebut tersedia kembali. Pelanggan dianjurkan untuk men-deploy layanan yang diterapkan Kontrol Layanan VPC ke beberapa region jika menginginkan ketersediaan yang lebih tinggi.
Workflows
Workflows adalah produk orkestrasi yang memungkinkan pelanggan Google Cloud:
- men-deploy dan menjalankan alur kerja yang menghubungkan layanan lain yang ada menggunakan HTTP,
- mengotomatisasi proses, termasuk menunggu respons HTTP dengan percobaan ulang otomatis hingga satu tahun, dan
- menerapkan proses real-time dengan eksekusi berbasis peristiwa latensi rendah.
Pelanggan Workflows dapat men-deploy alur kerja yang mendeskripsikan logika bisnis yang ingin mereka jalankan, lalu menjalankan alur kerja secara langsung dengan API atau dengan pemicu berbasis peristiwa (saat ini dibatasi untuk Pub/Sub atau Eventarc). Alur kerja yang sedang dijalankan dapat memanipulasi variabel, melakukan panggilan HTTP dan menyimpan hasilnya, atau menentukan callback dan menunggu untuk dilanjutkan oleh layanan lain.
Pemadaman layanan zona: Kode sumber Workflows tidak terpengaruh oleh pemadaman layanan zona. Workflows menyimpan kode sumber alur kerja, beserta nilai variabel dan respons HTTP yang diterima oleh alur kerja yang berjalan. Kode sumber disimpan secara regional dan ditulis secara sinkron: API bidang kontrol hanya ditampilkan setelah metadata ini di-commit ke kuorum dalam suatu region. Variabel dan hasil HTTP juga disimpan secara regional dan ditulis secara sinkron, setidaknya setiap lima detik.
Jika zona gagal, alur kerja akan otomatis dilanjutkan berdasarkan data yang terakhir disimpan. Namun, permintaan HTTP apa pun yang belum menerima respons tidak akan dicoba ulang secara otomatis. Gunakan kebijakan percobaan ulang untuk permintaan yang dapat dicoba ulang dengan aman seperti yang dijelaskan dalam dokumentasi kami.
Pemadaman layanan regional: Workflows adalah layanan regional; jika terjadi pemadaman layanan regional, Workflows tidak akan mengalami kegagalan. Pelanggan dianjurkan untuk men-deploy Workflows ke beberapa region jika menginginkan ketersediaan yang lebih tinggi.
Mesh Layanan Cloud
Cloud Service Mesh memungkinkan Anda mengonfigurasi mesh layanan terkelola yang mencakup beberapa cluster GKE. Dokumentasi ini hanya mencakup Cloud Service Mesh terkelola, varian dalam cluster dihosting sendiri dan panduan platform reguler harus diikuti.
Pemadaman layanan zona: Konfigurasi mesh, seperti yang disimpan dalam cluster GKE, tahan terhadap pemadaman layanan zona selama cluster tersebut bersifat regional. Data yang digunakan produk untuk pembukuan internal disimpan secara regional atau global, dan tidak terpengaruh jika satu zona tidak berfungsi. Bidang kontrol dijalankan di region yang sama dengan cluster GKE yang didukungnya (untuk cluster zona, ini adalah region penampungnya), dan tidak terpengaruh oleh pemadaman layanan dalam satu zona.
Pemadaman layanan regional: Cloud Service Mesh menyediakan layanan ke cluster GKE, baik bersifat regional maupun zona. Jika terjadi pemadaman layanan regional, Cloud Service Mesh tidak akan mengalami failover. Begitu juga dengan GKE. Pelanggan dianjurkan untuk men-deploy mesh yang merupakan cluster GKE yang mencakup berbagai region.
Direktori Layanan
Direktori Layanan adalah platform untuk menemukan, memublikasikan, dan menghubungkan layanan. Platform ini memberikan informasi real-time tentang semua layanan Anda di satu tempat. Direktori Layanan memungkinkan Anda melakukan manajemen inventaris layanan dalam skala besar, baik Anda memiliki beberapa atau ribuan titik akhir layanan.
Resource Direktori Layanan dibuat secara regional, yang cocok dengan parameter lokasi yang ditentukan oleh pengguna.
Pemadaman layanan zona: Selama pemadaman layanan zona, Direktori Layanan terus menyajikan permintaan dari zona lain di region yang sama atau berbeda tanpa gangguan. Dalam setiap region, Direktori Layanan selalu mempertahankan beberapa replika. Setelah pemadaman layanan zona teratasi, redundansi penuh akan dipulihkan.
Pemadaman layanan regional: Direktori Layanan tidak tahan terhadap pemadaman layanan regional.