Dokumen ini adalah bagian kedua dari rangkaian yang membahas pemulihan bencana (DR) di Google Cloud. Bagian ini membahas layanan dan produk yang dapat Anda gunakan sebagai elemen penyusun untuk rencana DR produk Google Cloud dan produk yang berfungsi di seluruh platform. Google Cloud
Rangkaian ini terdiri dari bagian-bagian berikut:
- Panduan perencanaan pemulihan dari bencana
- Elemen penyusun pemulihan dari bencana (artikel ini)
- Skenario pemulihan dari bencana untuk data
- Skenario pemulihan dari bencana untuk aplikasi
- Merancang pemulihan dari bencana untuk workload yang dibatasi lokalitas
- Kasus penggunaan pemulihan dari bencana: aplikasi analisis data yang dibatasi lokalitas
- Merancang pemulihan dari bencana untuk pemadaman infrastruktur cloud
Google Cloud memiliki berbagai produk yang dapat Anda gunakan sebagai bagian dari arsitektur pemulihan dari bencana. Bagian ini membahas fitur terkait DR dari produk yang paling umum digunakan sebagai elemen penyusun DR. Google Cloud
Banyak dari layanan ini memiliki fitur ketersediaan tinggi (HA). HA tidak sepenuhnya tumpang-tindih dengan DR, tetapi banyak tujuan HA juga berlaku untuk merancang rencana DR. Misalnya, dengan memanfaatkan fitur dengan ketersediaan tinggi (HA), Anda dapat merancang arsitektur yang mengoptimalkan waktu beroperasi dan yang dapat mengurangi efek kegagalan berskala kecil, seperti kegagalan VM tunggal. Untuk informasi selengkapnya tentang hubungan DR dan HA, lihat Panduan perencanaan pemulihan dari bencana (disaster recovery).
Bagian berikut menjelaskan elemen penyusun DR ini dan cara elemen tersebut membantu Anda menerapkan sasaran DR. Google Cloud
Komputasi dan penyimpanan
Tabel berikut memberikan ringkasan fitur di layanan komputasi dan penyimpanan yang berfungsi sebagai elemen penyusun untuk DR: Google Cloud
| Produk | Fitur |
|---|---|
| Compute Engine |
|
| Cloud Storage |
|
| Google Kubernetes Engine (GKE) |
|
Untuk mengetahui informasi selengkapnya tentang cara fitur dan desain produk-produk ini dan produk lainnya dapat memengaruhi strategi DR Anda, lihat Merancang pemulihan dari bencana untuk pemadaman infrastruktur cloud: referensi produk.Google Cloud
Compute Engine
Compute Engine menyediakan instance virtual machine (VM); ini adalah pekerja keras Google Cloud. Selain mengonfigurasi, meluncurkan, dan memantau instance Compute Engine, umumnya Anda menggunakan berbagai fitur terkait untuk menerapkan paket DR.
Untuk skenario DR, Anda dapat mencegah penghapusan VM secara tidak sengaja dengan menyetel tanda perlindungan hapus. Hal ini sangat berguna saat Anda menghosting layanan stateful seperti database.
Untuk mengetahui informasi tentang cara memenuhi nilai RTO dan RPO yang rendah, lihat Mendesain sistem yang tangguh.
Template instance
Anda dapat menggunakan template instance Compute Engine untuk menyimpan detail konfigurasi VM, lalu membuat instance Compute Engine dari template instance yang ada. Anda dapat menggunakan template untuk meluncurkan instance sebanyak yang dibutuhkan, yang dikonfigurasi persis seperti yang diinginkan saat Anda perlu membuat lingkungan target DR. Template instance direplikasi secara global, sehingga Anda dapat membuat ulang instance di mana saja di Google Cloud dengan konfigurasi yang sama.
Untuk informasi selengkapnya, lihat referensi berikut:
Untuk mengetahui detail tentang penggunaan image Compute Engine, lihat bagian menyeimbangkan konfigurasi image dan kecepatan deployment nanti dalam dokumen ini.
Grup instance terkelola
Grup instance terkelola bekerja dengan Cloud Load Balancing (akan dibahas nanti dalam dokumen ini) untuk mendistribusikan traffic ke grup instance yang dikonfigurasi secara identik yang disalin di seluruh zona. Grup instance terkelola memungkinkan fitur seperti penskalaan otomatis dan autohealing, di mana grup instance terkelola dapat menghapus dan membuat ulang instance secara otomatis.
Reservasi
Compute Engine memungkinkan reservasi instance VM di zona tertentu, menggunakan jenis mesin kustom atau yang telah ditetapkan, dengan atau tanpa GPU tambahan atau SSD lokal. Guna memastikan kapasitas untuk beban kerja yang sangat penting bagi DR, Anda harus membuat reservasi di zona target DR. Tanpa reservasi, Anda mungkin tidak akan mendapatkan kapasitas on demand yang diperlukan untuk memenuhi batas waktu pemulihan Anda. Reservasi dapat berguna dalam skenario DR cold, warm, atau hot. Dengan API ini, Anda dapat menyimpan resource pemulihan yang tersedia untuk failover guna memenuhi kebutuhan RTO yang lebih rendah, tanpa harus mengonfigurasi dan men-deploy sepenuhnya terlebih dahulu.
Persistent disk dan snapshot
Persistent disk adalah perangkat penyimpanan jaringan tahan lama yang dapat diakses instance Anda. Keduanya tidak bergantung pada instance, sehingga Anda dapat melepas dan memindahkan persistent disk agar data tetap tersimpan walaupun Anda telah menghapus instance.
Anda dapat mengambil cadangan atau snapshot VM Compute Engine tambahan yang dapat disalin dari berbagai region dan digunakan untuk membuat ulang persistent disk jika terjadi bencana. Selain itu, Anda dapat membuat snapshot persistent disk untuk melindungi data dari kehilangan data karena error pengguna. Snapshot bersifat inkremental, dan hanya memerlukan waktu beberapa menit untuk dibuat meskipun disk snapshot Anda terpasang ke instance yang berjalan.
Persistent disk memiliki redundansi bawaan untuk melindungi data Anda dari kegagalan peralatan dan untuk memastikan ketersediaan data melalui peristiwa pemeliharaan pusat data. Persistent disk dapat berbentuk zonal atau regional. Persistent disk regional mereplikasi penulisan di dua zona dalam satu region. Jika terjadi pemadaman layanan di zona tertentu, instance VM cadangan dapat memasang persistent disk regional secara paksa di zona sekunder. Untuk mempelajari lebih lanjut, baca Opsi ketersediaan tinggi yang menggunakan persistent disk regional.
Pemeliharaan yang transparan
Google secara rutin memelihara infrastrukturnya dengan mem-patch sistem menggunakan software terbaru, melakukan pengujian rutin dan pemeliharaan preventif, serta berupaya memastikan bahwa infrastruktur Google berjalan secepat dan seefisien mungkin.
Secara default, semua instance Compute Engine dikonfigurasi sehingga peristiwa pemeliharaan ini bersifat transparan untuk aplikasi dan workload Anda. Untuk mengetahui informasi selengkapnya, lihat Pemeliharaan transparan.
Saat peristiwa pemeliharaan terjadi, Compute Engine menggunakan Migrasi Langsung untuk memigrasikan instance yang sedang berjalan secara otomatis ke host lain di zona yang sama. Dengan Migrasi Langsung, Google dapat melakukan pemeliharaan yang merupakan bagian penting dalam menjaga keamanan dan keandalan infrastruktur tanpa mengganggu VM Anda.
Alat impor disk virtual
Alat impor disk virtual memungkinkan Anda mengimpor format file termasuk VMDK, VHD, dan RAW untuk membuat mesin virtual Compute Engine baru. Dengan alat ini, Anda dapat membuat virtual machine Compute Engine yang memiliki konfigurasi yang sama dengan virtual machine lokal. Ini adalah pendekatan yang tepat ketika Anda tidak dapat mengonfigurasi image Compute Engine dari biner sumber software yang sudah diinstal di image Anda.
Pencadangan otomatis
Anda dapat mengotomatiskan pencadangan instance Compute Engine menggunakan tag. Misalnya, Anda dapat membuat template rencana pencadangan menggunakan Layanan Backup dan DR, lalu menerapkan template tersebut secara otomatis ke instance Compute Engine Anda.
Untuk mengetahui informasi selengkapnya, lihat Mengotomatiskan perlindungan instance Compute Engine baru.
Cloud Storage
Cloud Storage adalah penyimpanan objek yang ideal untuk menyimpan file cadangan. Penyimpanan ini menyediakan kelas penyimpanan berbeda yang cocok untuk kasus penggunaan tertentu, seperti yang diuraikan dalam diagram berikut.

Dalam skenario DR, Nearline, Coldline, dan Archive Storage memiliki kepentingan tertentu. Kelas penyimpanan ini mengurangi biaya penyimpanan Anda dibandingkan dengan Penyimpanan standar. Namun, ada biaya tambahan yang terkait dengan pengambilan data atau metadata yang disimpan di kelas ini serta durasi penyimpanan minimum yang ditagihkan kepada Anda. Nearline dirancang untuk skenario pencadangan dengan akses maksimal sebulan sekali, sehingga Anda dapat melakukan pengujian stres DR secara rutin sambil menjaga biaya tetap rendah.
Nearline, Coldline, dan Archive dioptimalkan untuk akses yang jarang terjadi, dan model penetapan harganya dirancang dengan mempertimbangkan hal ini. Oleh karena itu, Anda dikenai biaya untuk durasi penyimpanan minimum, dan ada biaya tambahan untuk pengambilan data atau metadata di kelas ini yang lebih besar dari durasi penyimpanan minimum untuk kelas tersebut.
Untuk melindungi data Anda di bucket Cloud Storage dari penghapusan yang tidak disengaja atau berbahaya, Anda dapat menggunakan fitur Penghapusan Sementara untuk menyimpan objek yang dihapus dan ditimpa selama jangka waktu tertentu, dan fitur Penyimpanan objek untuk mencegah penghapusan atau pembaruan objek.
Storage Transfer Service memungkinkan Anda mengimpor data dari Amazon S3, Azure Blob Storage, atau sumber data lokal ke Cloud Storage. Dalam skenario DR, Anda dapat menggunakan Storage Transfer Service untuk melakukan hal berikut:
- Mencadangkan data dari penyedia penyimpanan lain ke bucket Cloud Storage.
- Pindahkan data dari bucket di dual-region atau multi-region ke bucket di suatu region guna menghemat biaya penyimpanan cadangan Anda.
Filestore
Instance Filestore adalah server file NFS yang terkelola sepenuhnya untuk digunakan dengan aplikasi yang berjalan di instance Compute Engine atau cluster GKE.
Tingkat Filestore Basic dan Zonal adalah resource zona dan tidak mendukung replikasi lintas zona, sedangkan instance tingkat Filestore Enterprise adalah resource regional. Untuk membantu Anda meningkatkan ketahanan lingkungan Filestore, sebaiknya gunakan instance tingkat Enterprise.
Google Kubernetes Engine
GKE adalah lingkungan terkelola dan siap produksi untuk men-deploy aplikasi dalam container. GKE memungkinkan Anda mengorkestrasi sistem HA, dan mencakup fitur-fitur berikut:
- Perbaikan otomatis node. Jika sebuah node gagal melakukan health check berturut-turut selama jangka waktu yang lebih lama (sekitar 10 menit), GKE akan memulai proses perbaikan untuk node tersebut.
- Pemeriksaan keaktifan dan kesiapan. Anda dapat menentukan pemeriksaan keaktifan, yang secara berkala memberi tahu GKE bahwa pod sedang berjalan. Jika gagal dalam pemeriksaan, pod dapat dimulai ulang.
- Cluster multi-zona dan regional. Anda dapat mendistribusikan resource Kubernetes di beberapa zona dalam satu region.
- Multi-cluster Gateway memungkinkan Anda mengonfigurasi resource load balancing bersama di beberapa cluster GKE di region yang berbeda.
- Pencadangan untuk GKE memungkinkan Anda mencadangkan dan memulihkan workload di cluster GKE.
Jaringan dan transfer data
Tabel berikut memberikan ringkasan fitur dalam layanan transfer data dan jaringan yang berfungsi sebagai blok penyusun untuk DR: Google Cloud
| Produk | Fitur |
|---|---|
| Cloud Load Balancing |
|
| Cloud Service Mesh |
|
| Cloud DNS |
|
| Cloud Interconnect |
|
Cloud Load Balancing
Cloud Load Balancing menyediakan HA untuk produk komputasi dengan mendistribusikan traffic pengguna di beberapa instance aplikasi Anda. Google Cloud Anda dapat mengonfigurasi Cloud Load Balancing dengan health check yang menentukan apakah instance tersedia untuk berfungsi sehingga traffic tidak dirutekan ke instance yang gagal.
Cloud Load Balancing menyediakan satu alamat IP anycast untuk menampilkan aplikasi Anda. Aplikasi Anda dapat menjalankan instance di berbagai region (misalnya, di Eropa dan AS), dan pengguna akhir akan diarahkan ke kumpulan instance terdekat. Selain menyediakan load balancing untuk layanan yang terekspos ke internet, Anda dapat mengonfigurasi load balancing internal untuk layanan Anda di balik alamat IP load balancing pribadi. Alamat IP ini hanya dapat diakses oleh instance VM yang bersifat internal untuk Virtual Private Cloud (VPC) Anda.
Untuk mengetahui informasi selengkapnya, lihat Ringkasan Cloud Load Balancing.
Cloud Service Mesh
Cloud Service Mesh adalah mesh layanan terkelola Google yang tersedia di Google Cloud. Cloud Service Mesh menyediakan telemetri mendalam untuk membantu Anda mengumpulkan insight mendetail tentang aplikasi Anda. Layanan ini mendukung layanan yang berjalan di berbagai infrastruktur komputasi.
Cloud Service Mesh juga mendukung fitur pengelolaan dan perutean traffic lanjutan, seperti pemutusan sirkuit dan injeksi kesalahan. Dengan pemutusan sirkuit, Anda dapat menerapkan batas pada permintaan ke layanan tertentu. Jika batas pemutusan sirkuit tercapai, permintaan akan dicegah mencapai layanan, sehingga mencegah layanan mengalami penurunan versi lebih lanjut. Dengan injeksi kesalahan, Cloud Service Mesh dapat menyebabkan penundaan atau membatalkan sebagian kecil permintaan ke layanan. Injeksi kesalahan memungkinkan Anda menguji kemampuan layanan Anda untuk tetap berlaku terhadap penundaan permintaan atau permintaan yang dibatalkan.
Untuk mengetahui informasi selengkapnya, lihat Ringkasan Cloud Service Mesh.
Cloud DNS
Cloud DNS menyediakan cara terprogram untuk mengelola entri DNS sebagai bagian dari proses pemulihan otomatis. Cloud DNS menggunakan jaringan global server nama Anycast Google untuk melayani zona DNS Anda dari lokasi redundan di seluruh dunia, yang memberikan ketersediaan tinggi dan latensi yang lebih rendah untuk pengguna Anda.
Jika memilih untuk mengelola entri DNS secara lokal, Anda dapat mengaktifkan VM di Google Cloud untuk me-resolve alamat ini melalui penerusan Cloud DNS.
Cloud DNS mendukung kebijakan untuk mengonfigurasi cara merespons permintaan DNS. Misalnya, Anda dapat mengonfigurasi kebijakan perutean DNS untuk mengarahkan traffic berdasarkan kriteria tertentu, seperti mengaktifkan failover ke konfigurasi cadangan untuk memberikan ketersediaan tinggi, atau merutekan permintaan DNS berdasarkan lokasi geografisnya.
Cloud Interconnect
Cloud Interconnect memberikan cara untuk memindahkan informasi dari sumber lain ke Google Cloud. Kita akan membahas produk ini nanti di bagian Mentransfer data ke dan dari Google Cloud.
Pengelolaan dan pemantauan
Tabel berikut memberikan ringkasan fitur dalam layanan pengelolaan dan pemantauan Google Cloud yang berfungsi sebagai elemen penyusun untuk DR:
| Produk | Fitur |
|---|---|
| Dasbor status Cloud |
|
| Google Cloud Observability |
|
| Google Cloud Managed Service for Prometheus |
|
Dasbor status Cloud
Dasbor Status Cloud menampilkan ketersediaan layanan saat ini. Google Cloud Anda dapat melihat status di halaman dan berlangganan feed RSS yang diperbarui setiap kali ada berita tentang suatu layanan.
Cloud Monitoring
Cloud Monitoring mengumpulkan metrik, peristiwa, dan metadata dari Google Cloud, AWS, pemeriksaan waktu beroperasi yang dihosting, instrumentasi aplikasi, dan berbagai komponen aplikasi lainnya. Anda dapat mengonfigurasi pemberitahuan untuk mengirim notifikasi ke alat pihak ketiga seperti Slack atau Pagerduty guna memberikan info terbaru yang tepat waktu tentang administrator.
Cloud Monitoring memungkinkan Anda membuat cek uptime untuk endpoint yang tersedia secara publik dan untuk endpoint dalam VPC Anda. Misalnya, Anda dapat memantau URL, instance Compute Engine, revisi Cloud Run, dan resource pihak ketiga, seperti instance Amazon Elastic Compute Cloud (EC2).
Google Cloud Managed Service for Prometheus
Google Cloud Managed Service for Prometheus adalah solusi lintas project multi-cloud yang dikelola Google untuk metrik Prometheus. Dengan layanan ini, Anda dapat memantau dan membuat pemberitahuan terkait workload secara global dengan menggunakan Prometheus, tanpa harus mengelola dan mengoperasikan Prometheus secara manual dalam skala besar.
Untuk mengetahui informasi selengkapnya, lihat Google Cloud Managed Service for Prometheus.
Elemen penyusun DR lintas platform
Saat Anda menjalankan beban kerja di lebih dari satu platform, cara untuk mengurangi overhead operasional adalah dengan memilih alat yang berfungsi dengan semua platform yang Anda gunakan. Bagian ini membahas beberapa alat dan layanan yang tidak bergantung pada platform, sehingga mendukung skenario DR lintas platform.
Infrastruktur sebagai kode
Dengan menentukan infrastruktur menggunakan kode, bukan antarmuka grafis atau skrip, Anda dapat menggunakan alat template deklaratif dan mengotomatiskan penyediaan dan konfigurasi infrastruktur di berbagai platform. Misalnya, Anda dapat menggunakan Terraform dan Infrastructure Manager untuk mengaktifkan konfigurasi infrastruktur deklaratif Anda.
Alat pengelolaan konfigurasi
Untuk infrastruktur DR yang besar atau kompleks, kami merekomendasikan alat pengelolaan software yang tidak bergantung pada platform seperti Chef dan Ansible. Alat ini memastikan bahwa konfigurasi yang dapat direproduksi dapat diterapkan di mana pun beban kerja komputasi Anda berada.
Alat Orchestrator
Container juga dapat dianggap sebagai elemen penyusun DR. Container adalah cara untuk mengemas layanan dan memperkenalkan konsistensi di seluruh platform.
Jika bekerja dengan container, Anda biasanya menggunakan orchestrator. Kubernetes tidak hanya berfungsi untuk mengelola container dalam Google Cloud (menggunakan GKE), tetapi juga menyediakan cara untuk mengorkestrasi workload berbasis container di beberapa platform. Google Cloud, AWS, dan Microsoft Azure menyediakan versi Kubernetes terkelola.
Untuk mendistribusikan traffic ke cluster Kubernetes yang berjalan di berbagai platform cloud, Anda dapat menggunakan layanan DNS yang mendukung data berbobot dan menggabungkan health check.
Anda juga perlu memastikan bahwa Anda dapat menarik image ke lingkungan target. Artinya, Anda harus dapat mengakses registry image Anda jika terjadi bencana. Opsi bagus yang juga tidak bergantung pada platform adalah Artifact Registry.
Transfer data
Transfer data adalah komponen penting dari skenario DR lintas platform. Pastikan Anda mendesain, menerapkan, dan menguji skenario DR lintas platform menggunakan maket realistis yang sesuai dengan skenario transfer data DR. Kami membahas skenario transfer data di bagian berikutnya.
Backup and DR Service
Backup and DR Service adalah solusi pencadangan dan DR untuk workload cloud. Layanan ini membantu Anda memulihkan data dan melanjutkan operasi bisnis penting, serta mendukung beberapaGoogle Cloud produk dan database pihak ketiga serta sistem penyimpanan data.
Untuk mengetahui informasi selengkapnya, lihat Ringkasan Layanan Pencadangan dan DR.
Pola untuk DR
Bagian ini membahas beberapa pola paling umum untuk arsitektur DR berdasarkan elemen penyusun yang telah dibahas sebelumnya.
Mentransfer data ke dan dari Google Cloud
Aspek penting dari rencana DR Anda adalah seberapa cepat data dapat ditransfer ke dan dari Google Cloud. Hal ini penting jika rencana DR Anda didasarkan pada pemindahan data dari infrastruktur lokal ke Google Cloud atau dari penyedia cloud lain ke Google Cloud. Bagian ini membahas layanan jaringan dan Google Cloud yang dapat memastikan throughput yang baik.
Saat Anda menggunakan Google Cloud sebagai situs pemulihan untuk workload yang berada di infrastruktur lokal atau di lingkungan cloud lain, pertimbangkan item utama berikut:
- Bagaimana cara Anda terhubung ke Google Cloud?
- Berapa banyak bandwidth yang tersedia antara Anda dan penyedia interkoneksi?
- Berapa bandwidth yang disediakan langsung oleh penyedia ke Google Cloud?
- Data lain apa yang akan ditransfer menggunakan link tersebut?
Untuk mengetahui informasi selengkapnya tentang cara mentransfer data ke Google Cloud, lihat Bermigrasi ke Google Cloud: Mentransfer set data besar Anda.
Menyeimbangkan konfigurasi image dan kecepatan deployment
Saat Anda mengonfigurasi image mesin untuk men-deploy instance baru, pertimbangkan efek konfigurasi Anda terhadap kecepatan deployment. Ada kompromi antara jumlah prakonfigurasi image, biaya pemeliharaan image, dan kecepatan deployment. Misalnya, jika image mesin dikonfigurasi secara minimal, instance yang menggunakannya akan memerlukan lebih banyak waktu untuk diluncurkan, karena harus mendownload dan menginstal dependensi. Di sisi lain, jika image mesin Anda sangat dikonfigurasi, instance yang menggunakannya akan diluncurkan lebih cepat, tetapi Anda harus mengupdate image lebih sering. Waktu yang diperlukan untuk meluncurkan instance yang beroperasi penuh akan memiliki korelasi langsung dengan RTO Anda.
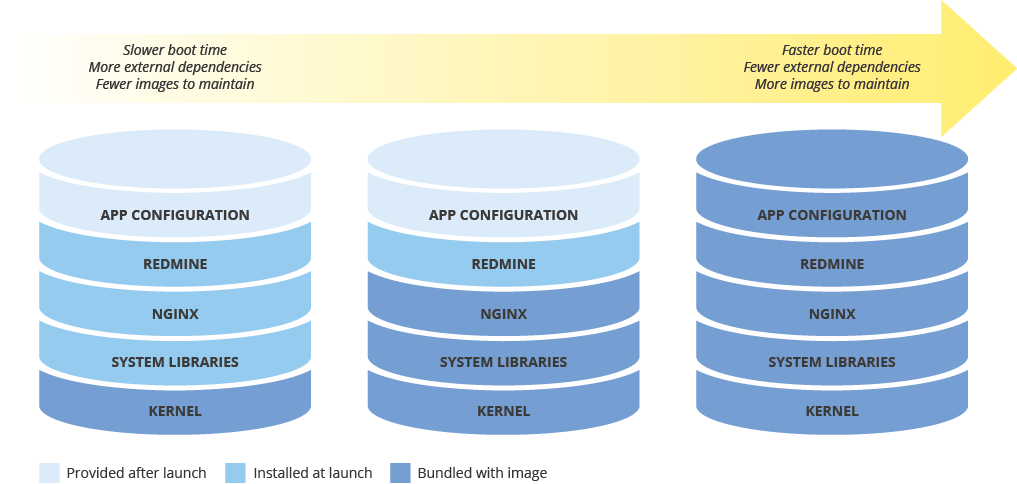
Mempertahankan konsistensi image mesin di seluruh lingkungan hybrid
Jika menerapkan solusi hybrid (lokal ke cloud atau cloud ke cloud), Anda perlu menemukan cara untuk mempertahankan konsistensi image di seluruh lingkungan produksi.
Jika image yang dikonfigurasi sepenuhnya diperlukan, pertimbangkan hal seperti Packer, yang dapat membuat image mesin identik untuk beberapa platform. Anda dapat menggunakan skrip yang sama dengan file konfigurasi khusus platform. Dalam kasus Packer, Anda dapat menempatkan file konfigurasi di kontrol versi untuk melacak versi yang di-deploy dalam produksi.
Sebagai opsi lainnya, Anda dapat menggunakan alat pengelolaan konfigurasi, seperti Chef, Puppet, Ansible, atau Saltstack untuk mengonfigurasi instance dengan perincian yang lebih baik, membuat image dasar, image yang dikonfigurasi secara minimal, atau image yang dikonfigurasi sepenuhnya sebagai diperlukan.
Anda juga dapat mengonversi dan mengimpor image yang ada secara manual, seperti AMI Amazon, image Virtualbox, dan disk image RAW ke Compute Engine.
Menerapkan penyimpanan bertingkat
Pola penyimpanan bertingkat biasanya digunakan untuk pencadangan, yang pencadangan terbarunya berada di penyimpanan yang lebih cepat, dan Anda perlahan-lahan memigrasikan cadangan lama ke penyimpanan berbiaya lebih rendah (tetapi lambat). Dengan menerapkan pola ini, Anda memigrasikan cadangan di antara bucket dengan kelas penyimpanan yang berbeda, biasanya dari Standard ke kelas penyimpanan yang lebih murah, seperti Nearline dan Coldline.
Untuk menerapkan pola ini, Anda dapat menggunakan Object Lifecycle Management. Misalnya, Anda dapat mengubah kelas penyimpanan objek yang lebih lama dari jangka waktu tertentu ke Coldline secara otomatis.
Langkah berikutnya
- Baca tentang Google Cloud geografi dan region.
Baca artikel lain dalam rangkaian DR ini:
- Panduan perencanaan pemulihan dari bencana
- Skenario pemulihan dari bencana untuk data
- Skenario pemulihan dari bencana untuk aplikasi
- Merancang pemulihan dari bencana untuk workload yang dibatasi lokalitas
- Kasus penggunaan pemulihan dari bencana: aplikasi analisis data yang dibatasi lokalitas
- Merancang pemulihan dari bencana untuk pemadaman infrastruktur cloud
Untuk mengetahui lebih banyak tentang arsitektur referensi, diagram, dan praktik terbaik lainnya, jelajahi Pusat Arsitektur Cloud.
Kontributor
Penulis:
- Grace Mollison | Solutions Lead
- Marco Ferrari | Cloud Solutions Architect