Este artigo faz parte de uma série que aborda a recuperação de desastres (RD) no Google Cloud. Esta parte aborda o processo de arquitetura de cargas de trabalho com Google Cloud e blocos de construção resilientes a interrupções da infraestrutura na nuvem.
A série é composta pelas seguintes partes:
- Guia de planeamento de recuperação de desastres
- Bases de recuperação de desastres
- Cenários de recuperação de desastres para dados
- Cenários de recuperação de desastres para aplicações
- Arquitetar a recuperação de desastres para cargas de trabalho restritas por localidade
- Exemplos de utilização de recuperação de desastres: aplicações de estatísticas de dados restritas à localidade
- Criar arquiteturas de recuperação de desastres para interrupções da infraestrutura na nuvem (este documento)
Introdução
À medida que as empresas movem cargas de trabalho para a nuvem pública, têm de traduzir a sua compreensão da criação de sistemas no local resilientes para a infraestrutura de hiperescala de fornecedores de nuvem como a Google Cloud. Este artigo mapeia conceitos padrão da indústria em torno da recuperação de desastres, como o OTR (objetivo de tempo de recuperação) e o OPR (objetivo de ponto de recuperação) para a Google Cloud infraestrutura.
As orientações neste documento seguem um dos princípios fundamentais da Google para alcançar uma disponibilidade de serviço extremamente elevada: planear para a falha. Embora a Google Cloud ofereça um serviço extremamente fiável, ocorrem desastres, como desastres naturais, cortes de fibra e falhas de infraestrutura complexas e imprevisíveis, que causam interrupções. O planeamento de indisponibilidades permite que os clientes criem aplicações com um desempenho previsível nestes eventos inevitáveis, através da utilização de produtos com mecanismos de DR "incorporados".Google Cloud Google Cloud
A recuperação de desastres é um tópico amplo que abrange muito mais do que apenas falhas de infraestrutura, como erros de software ou corrupção de dados, e deve ter um plano abrangente de ponta a ponta. No entanto, este artigo foca-se numa parte de um plano de recuperação de desastres geral: como criar aplicações resilientes a interrupções da infraestrutura na nuvem. Especificamente, este artigo explica:
- A Google Cloud infraestrutura, como os eventos de desastre se manifestam como Google Cloud interrupções e como a Google Cloud está arquitetada para minimizar a frequência e o âmbito das interrupções.
- Um guia de planeamento de arquitetura que fornece uma framework para categorizar e criar aplicações com base nos resultados de fiabilidade desejados.
- Uma lista detalhada de determinados Google Cloud produtos que oferecem capacidades de DR incorporadas que pode querer usar na sua aplicação.
Para mais detalhes sobre o planeamento geral de recuperação de desastres e a utilização do Google Cloud como componente na sua estratégia de recuperação de desastres no local, consulte o guia de planeamento de recuperação de desastres. Além disso, embora a alta disponibilidade seja um conceito estreitamente relacionado com a recuperação de desastres, não é abordado neste artigo. Para mais detalhes sobre a arquitetura para alta disponibilidade, consulte o Well-Architected Framework.
Nota sobre a terminologia: este artigo refere-se à disponibilidade quando discute a capacidade de um produto ser acedido e usado de forma significativa ao longo do tempo, enquanto a fiabilidade se refere a um conjunto de atributos, incluindo a disponibilidade, mas também aspetos como a durabilidade e a correção.
Como o Google Cloud foi concebido para a resiliência
Centros de dados da Google
Os centros de dados tradicionais baseiam-se na maximização da disponibilidade de componentes individuais. Na nuvem, a escala permite que os operadores, como a Google, distribuam serviços por muitos componentes através de tecnologias de virtualização e, assim, excedam a fiabilidade dos componentes tradicionais. Isto significa que pode mudar a sua perspetiva da arquitetura de fiabilidade dos inúmeros detalhes com que se preocupava no local. Em vez de se preocupar com os vários modos de falha dos componentes, como o arrefecimento e o fornecimento de energia, pode planear em função dos produtos e das respetivas métricas de fiabilidade indicadas. Google Cloud Estas métricas refletem o risco de indisponibilidade agregado de toda a infraestrutura subjacente. Isto permite-lhe concentrar-se muito mais no design, na implementação e nas operações das aplicações, em vez da gestão da infraestrutura.
A Google concebe a sua infraestrutura para cumprir objetivos de disponibilidade ambiciosos com base na nossa vasta experiência na criação e execução de centros de dados modernos. A Google é líder mundial em design de centros de dados. Desde a energia ao arrefecimento e às redes, cada tecnologia de centro de dados tem as suas próprias redundâncias e mitigações, incluindo planos de FMEA. Os centros de dados da Google são criados de forma a equilibrar estes vários riscos diferentes e apresentar aos clientes um nível esperado consistente de disponibilidade para os Google Cloud produtos. A Google usa a sua experiência para modelar a disponibilidade da arquitetura física e lógica geral do sistema para garantir que o design do centro de dados cumpre as expetativas. Os engenheiros da Google esforçam-se muito a nível operacional para ajudar a garantir que essas expetativas são cumpridas. A disponibilidade medida real excede normalmente os nossos objetivos de design por uma margem confortável.
Ao destilar todos estes riscos e mitigações de centros de dados em produtos orientados para o utilizador, Google Cloud liberta-se dessas responsabilidades de design e operacionais. Em alternativa, pode concentrar-se na fiabilidade concebida para asGoogle Cloud regiões e zonas.
Regiões e zonas
As regiões são áreas geográficas independentes compostas por zonas. As zonas e as regiões são abstrações lógicas dos recursos físicos subjacentes. Para mais informações sobre considerações específicas da região, consulte o artigo Geografia e regiões.
Google Cloud Os produtos estão divididos em recursos zonais, recursos regionais ou recursos multirregionais.
Os recursos zonais são alojados numa única zona. Uma interrupção do serviço nessa zona pode afetar todos os recursos nessa zona. Por exemplo, uma instância do Compute Engine é executada numa única zona especificada. Se uma falha de hardware interromper o serviço nessa zona, a instância do Compute Engine fica indisponível durante a interrupção.
Os recursos regionais são implementados de forma redundante em várias zonas numa região. Deste modo, têm maior fiabilidade em relação aos recursos zonais.
Os recursos multirregionais são distribuídos dentro e entre regiões. Em geral, os recursos multirregionais têm uma fiabilidade superior à dos recursos regionais. No entanto, a este nível, os produtos têm de otimizar a disponibilidade, o desempenho e a eficiência dos recursos. Como resultado, é importante compreender as concessões feitas por cada produto multirregional que decidir usar. As soluções de compromisso necessárias para a obtenção deste equilíbrio são documentadas em função de cada produto mais adiante neste documento.
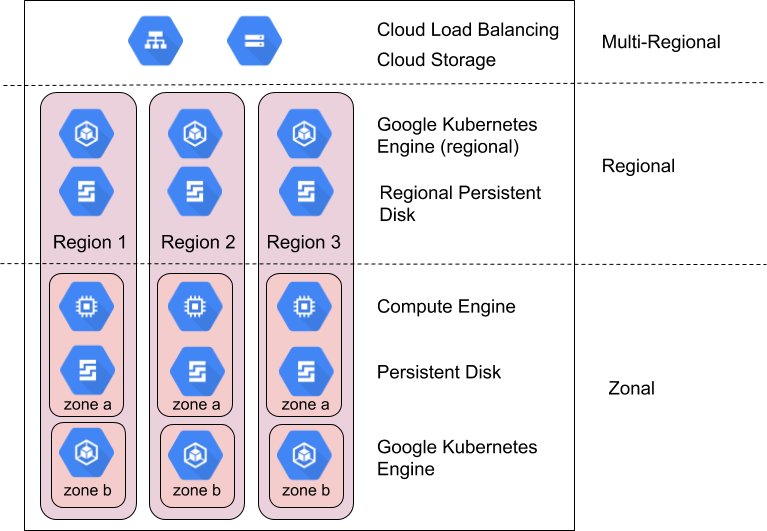
Como tirar partido das zonas e das regiões para alcançar a fiabilidade
Os SREs da Google gerem e dimensionam produtos de utilizadores globais altamente fiáveis, como o Gmail e a Pesquisa, através de várias técnicas e tecnologias que tiram partido de forma integrada da infraestrutura de computação em todo o mundo. Isto inclui o redirecionamento do tráfego de localizações indisponíveis através do equilíbrio de carga global, a execução de várias réplicas em muitas localizações em todo o mundo e a replicação de dados entre localizações. Estas mesmas capacidades estão disponíveis para os Google Cloud clientes através de produtos como o Cloud Load Balancing, o Google Kubernetes Engine (GKE) e o Spanner.
Google Cloud geralmente, cria produtos para oferecer os seguintes níveis de disponibilidade para zonas e regiões:
| Recurso | Exemplos | Objetivo de design de disponibilidade | Período de descanso implícito |
|---|---|---|---|
| Zonal | Compute Engine, Persistent Disk | 99,9% | 8,75 horas / ano |
| Regional | Regional Cloud Storage, disco persistente replicado e GKE regional | 99,99% | 52 minutos / ano |
Compare os Google Cloud objetivos de conceção de disponibilidade com o seu nível aceitável de tempo de inatividade para identificar os Google Cloud recursos adequados. Embora os designs tradicionais se foquem na melhoria da disponibilidade ao nível dos componentes para melhorar a disponibilidade da aplicação resultante, os modelos na nuvem focam-se, em alternativa, na composição dos componentes para alcançar este objetivo. Muitos produtos Google Cloud usam esta técnica. Por exemplo, o Spanner oferece uma base de dados multirregional que compõe várias regiões para oferecer uma disponibilidade de 99,999%.
A composição é importante porque, sem ela, a disponibilidade da sua aplicação não pode exceder a dos produtos que usa. Na verdade, a menos que a sua aplicação nunca falhe, terá uma disponibilidade inferior à dos produtos subjacentes. Google Cloud Google Cloud O resto desta secção mostra geralmente como pode usar uma composição de produtos zonais e regionais para alcançar uma disponibilidade da aplicação superior à que uma única zona ou região ofereceria. A secção seguinte apresenta um guia prático para aplicar estes princípios às suas aplicações.
Planeamento dos âmbitos de indisponibilidade da zona
As falhas de infraestrutura causam normalmente interrupções de serviço numa única zona. Numa região, as zonas são concebidas para minimizar o risco de falhas correlacionadas com outras zonas, e uma interrupção do serviço numa zona normalmente não afeta o serviço de outra zona na mesma região. Uma indisponibilidade limitada a uma zona não significa necessariamente que toda a zona esteja indisponível. Apenas define o limite do incidente. É possível que uma indisponibilidade de zona não tenha um efeito tangível nos seus recursos específicos nessa zona.
É uma ocorrência mais rara, mas também é fundamental ter em atenção que várias zonas vão, eventualmente, continuar a sofrer uma indisponibilidade correlacionada em algum momento numa única região. Quando duas ou mais zonas sofrem uma indisponibilidade, aplica-se a estratégia de âmbito de indisponibilidade regional abaixo.
Os recursos regionais foram concebidos para resistir a interrupções de zonas, fornecendo serviço a partir de uma composição de várias zonas. Se uma das zonas que suportam um recurso regional for interrompida, o recurso disponibiliza-se automaticamente a partir de outra zona. Verifique cuidadosamente a descrição da capacidade do produto no anexo para mais detalhes.
Google Cloud oferece apenas alguns recursos zonais, nomeadamente máquinas virtuais (VMs) do Compute Engine e o disco persistente. Se planeia usar recursos zonais, tem de fazer a sua própria composição de recursos ao conceber, criar e testar a comutação por falha e a recuperação entre recursos zonais localizados em várias zonas. Algumas estratégias incluem:
- Encaminhar rapidamente o seu tráfego para máquinas virtuais noutra zona através do Cloud Load Balancing quando uma verificação de estado determina que uma zona está a ter problemas.
- Use modelos de instâncias do Compute Engine e/ou grupos de instâncias geridas para executar e dimensionar instâncias de VM idênticas em várias zonas.
- Use um disco persistente regional para replicar dados de forma síncrona para outra zona numa região. Consulte as opções de alta disponibilidade com PDs regionais para ver mais detalhes.
Planeamento de âmbitos de interrupções regionais
Uma indisponibilidade regional é uma interrupção do serviço que afeta mais do que uma zona numa única região. Estas são indisponibilidades menos frequentes e de maior escala, que podem ser causadas por desastres naturais ou falhas de infraestrutura de grande escala.
Para um produto regional concebido para oferecer uma disponibilidade de 99,99%, uma indisponibilidade pode ainda traduzir-se em quase uma hora de inatividade para um produto específico todos os anos. Por conseguinte, as suas aplicações críticas podem ter de ter um plano de recuperação de desastres (RD) em várias regiões se esta duração da indisponibilidade for inaceitável.
Os recursos multirregionais são concebidos para serem resistentes a interrupções regionais através da prestação de serviços a partir de várias regiões. Conforme descrito acima, os produtos multirregionais equilibram a latência, a consistência e o custo. A compensação mais comum é entre a replicação de dados síncrona e assíncrona. A replicação assíncrona oferece uma latência inferior ao custo do risco de perda de dados durante uma interrupção. Por isso, é importante verificar a descrição da capacidade do produto no anexo para ver mais detalhes.
Se quiser usar recursos regionais e manter a resiliência a interrupções regionais, tem de fazer a sua própria composição de recursos ao conceber, criar e testar a respetiva comutação por falha e recuperação entre recursos regionais localizados em várias regiões. Além das estratégias ao nível da zona descritas acima, que também pode aplicar em várias regiões, considere o seguinte:
- Os recursos regionais devem replicar os dados para uma região secundária, para uma opção de armazenamento multirregional, como o Cloud Storage, ou uma opção de nuvem híbrida, como o GKE e o Google Distributed Cloud.
- Depois de ter uma mitigação de interrupções regionais implementada, teste-a regularmente. Há poucas coisas piores do que pensar que é resistente a uma interrupção de uma única região e descobrir que não é o caso quando acontece na realidade.
Google Cloud abordagem de resiliência e disponibilidade
Google Cloud supera regularmente os alvos de design de disponibilidade, mas não deve partir do princípio de que este forte desempenho passado é a disponibilidade mínima para a qual pode criar o design. Em alternativa, deve selecionar Google Cloud dependências cujos destinos concebidos excedam a fiabilidade pretendida da sua aplicação, de modo que o tempo de inatividade da aplicação mais o Google Cloud tempo de inatividade produzam o resultado que procura.
Um sistema bem concebido pode responder à pergunta: "O que acontece quando uma zona ou uma região tem uma indisponibilidade de 1, 5, 10 ou 30 minutos?" Isto deve ser considerado em várias camadas, incluindo:
- O que vão os meus clientes sentir durante uma indisponibilidade?
- Como posso detetar que está a ocorrer uma indisponibilidade?
- O que acontece à minha aplicação durante uma indisponibilidade?
- O que acontece aos meus dados durante uma indisponibilidade?
- O que acontece às minhas outras aplicações devido a uma indisponibilidade (devido a interdependências)?
- O que tenho de fazer para recuperar o acesso após a resolução de uma indisponibilidade? Quem o faz?
- Quem tenho de notificar acerca de uma indisponibilidade e dentro de que período?
Guia passo a passo para conceber a recuperação de desastres para aplicações no Google Cloud
As secções anteriores abordaram a forma como a Google cria a infraestrutura na nuvem e algumas abordagens para lidar com interrupções zonais e regionais.
Esta secção ajuda a desenvolver uma estrutura para aplicar o princípio da composição às suas aplicações com base nos resultados de fiabilidade desejados.
As aplicações do cliente que Google Cloud visam objetivos de recuperação de desastres, como o OTR e o OPR, têm de ser arquitetadas de forma que as operações essenciais para a empresa, sujeitas ao OTR/OPR, só tenham dependências de componentes do plano de dados responsáveis pelo processamento contínuo de operações para o serviço. Por outras palavras, estas operações empresariais críticas para o cliente não devem depender de operações do plano de gestão, que gerem o estado de configuração e enviem a configuração para o plano de controlo e o plano de dados.
Por exemplo, Google Cloud os clientes que pretendem alcançar o RTO para operações críticas para a empresa não devem depender de uma API de criação de VMs nem da atualização de uma autorização do IAM.
Passo 1: reúna os requisitos existentes
O primeiro passo é definir os requisitos de disponibilidade das suas aplicações. A maioria das empresas já tem algum nível de orientações de design neste espaço, que podem ser desenvolvidas internamente ou derivadas de regulamentos ou outros requisitos legais. Estas orientações de design são normalmente codificadas em duas métricas principais: objetivo de tempo de recuperação (OTR) e objetivo de ponto de recuperação (OPR). Em termos empresariais, o RTO traduz-se em "Quanto tempo após um desastre até estar operacional". O RPO traduz-se em "Que quantidade de dados posso perder em caso de desastre".

Historicamente, as empresas definiram requisitos de RTO e RPO para uma vasta gama de eventos de desastre, desde falhas de componentes a terramotos. Isto fazia sentido no mundo local, onde os planeadores tinham de mapear os requisitos de RTO/RPO através de toda a pilha de software e hardware. Na nuvem, já não precisa de definir os seus requisitos com tanto detalhe porque o fornecedor encarrega-se disso. Em alternativa, pode definir os seus requisitos de RTO e RPO em termos do âmbito da perda (zonas ou regiões inteiras) sem especificar os motivos subjacentes. Isto Google Cloud simplifica a recolha de requisitos para 3 cenários: uma indisponibilidade zonal, uma indisponibilidade regional ou a indisponibilidade de várias regiões, que é extremamente improvável.
Reconhecendo que nem todas as aplicações têm a mesma criticidade, a maioria dos clientes categoriza as respetivas aplicações em níveis de criticidade em relação aos quais se pode aplicar um requisito de RTO/RPO específico. Quando considerados em conjunto, o RTO/RPO e a criticidade da aplicação simplificam o processo de arquitetura de uma determinada aplicação respondendo às seguintes perguntas:
- A aplicação tem de ser executada em várias zonas na mesma região ou em várias zonas em várias regiões?
- De que Google Cloud produtos pode a aplicação depender?
Este é um exemplo do resultado do exercício de recolha de requisitos:
OTR e OPR por criticidade da aplicação para a empresa de exemplo:
| Criticidade da aplicação | % de apps | Exemplos de apps | Interrupção da zona | Indisponibilidade da região |
|---|---|---|---|---|
| Nível 1
(mais importante) |
5% | Normalmente, aplicações globais ou externas viradas para o cliente, como pagamentos em tempo real e montras de comércio eletrónico. | ORT zero
RPO Zero |
ORT zero
RPO Zero |
| Nível 2 | 35% | Normalmente, aplicações regionais ou aplicações internas importantes, como CRM ou ERP. | RTO 15 min
RPO 15 min |
RTO 1 h
RPO 1 h |
| Nível 3
(menos importante) |
60% | Normalmente, aplicações de equipa ou departamentais, como back office, reserva de ausências, viagens internas, contabilidade e recursos humanos. | RTO 1 h
RPO 1 h |
RTO 12 h
RPO 12 h |
Passo 2: mapeamento de capacidades para produtos disponíveis
O segundo passo é compreender as capacidades de resiliência dos Google Cloud produtos que as suas aplicações vão usar. A maioria das empresas revê as informações relevantes sobre os produtos e, em seguida, adiciona orientações sobre como modificar as respetivas arquiteturas para colmatar eventuais lacunas entre as capacidades dos produtos e os respetivos requisitos de resiliência. Esta secção aborda algumas áreas comuns e recomendações relativas a limitações de dados e aplicações neste espaço.
Conforme mencionado anteriormente, os produtos com DR da Google atendem amplamente a dois tipos de âmbitos de indisponibilidade: regional e zonal. As indisponibilidades parciais devem ser planeadas da mesma forma que uma indisponibilidade total no que diz respeito à recuperação de desastres. Isto dá uma matriz inicial de alto nível dos produtos adequados para cada cenário por predefinição:
Google Cloud Capacidades gerais do produto
(consulte o Apêndice para ver as capacidades específicas do produto)
| Todos os produtos Google Cloud | Produtos Google Cloud regionais com replicação automática em zonas | Produtos multirregionais ou globais Google Cloud com replicação automática entre regiões | |
|---|---|---|---|
| Falha de um componente numa zona | Coberto* | Abrangido | Abrangido |
| Interrupção da zona | Não coberto | Abrangido | Abrangido |
| Indisponibilidade da região | Não coberto | Não coberto | Abrangido |
* Todos os Google Cloud produtos são resilientes a falhas de componentes, exceto em casos específicos indicados na documentação do produto. Normalmente, estes são cenários em que o produto oferece acesso direto ou mapeamento estático a um componente de hardware especializado, como memória ou discos de estado sólido (SSD).
Como a RPO limita as escolhas de produtos
Na maioria das implementações na nuvem, a integridade dos dados é o aspeto arquitetónico mais significativo a ter em conta para um serviço. Pelo menos, algumas aplicações têm um requisito de RPO de zero, o que significa que não deve haver perda de dados em caso de indisponibilidade. Normalmente, isto requer que os dados sejam replicados de forma síncrona para outra zona ou região. A replicação síncrona tem compromissos de custo e latência, pelo que, embora muitos produtos ofereçam replicação síncrona em várias zonas, apenas alguns a oferecem em várias regiões. Google Cloud Esta compensação entre o custo e a complexidade significa que não é invulgar que diferentes tipos de dados numa aplicação tenham valores de RPO diferentes.
Para dados com um RPO superior a zero, as aplicações podem tirar partido da replicação assíncrona. A replicação assíncrona é aceitável quando os dados perdidos podem ser recriados facilmente ou podem ser recuperados de uma origem de dados principal, se necessário. Também pode ser uma escolha razoável quando uma pequena quantidade de perda de dados é uma compensação aceitável no contexto das durações esperadas de indisponibilidade zonais e regionais. Também é relevante que, durante uma indisponibilidade transitória, os dados escritos na localização afetada, mas ainda não replicados para outra localização, geralmente, ficam disponíveis após a resolução da indisponibilidade. Isto significa que o risco de perda de dados permanente é inferior ao risco de perder o acesso aos dados durante uma indisponibilidade.
Ações principais: determine se precisa mesmo de um RPO zero e, se for o caso, se pode fazê-lo para um subconjunto dos seus dados. Isto aumenta drasticamente o intervalo de serviços ativados para DR disponíveis para si. Ao Google Cloud, atingir o RPO zero, significa usar predominantemente produtos regionais para a sua aplicação, que, por predefinição, são resilientes a interrupções à escala da zona, mas não à escala da região.
Como o RTO limita as escolhas de produtos
Uma das principais vantagens da computação na nuvem é a capacidade de implementar infraestrutura a pedido. No entanto, isto não é o mesmo que uma implementação instantânea. O valor de RTO da sua aplicação tem de acomodar o RTO combinado dos produtos que a sua aplicação usa e quaisquer ações que os seus engenheiros ou SREs tenham de tomar para reiniciar as VMs ou os componentes da aplicação. Google Cloud Um RTO medido em minutos significa criar uma aplicação que recupere automaticamente de um desastre sem intervenção humana ou com passos mínimos, como premir um botão para fazer failover. Historicamente, o custo e a complexidade deste tipo de sistema têm sido muito elevados, mas os Google Cloud produtos, como os balanceadores de carga e os grupos de instâncias, tornam este design muito mais acessível e simples. Por conseguinte, deve considerar a comutação por falha e a recuperação automáticas para a maioria das aplicações. Tenha em atenção que conceber um sistema para este tipo de comutação em quente entre regiões é complicado e dispendioso. Apenas uma pequena fração dos serviços críticos justifica esta capacidade.
A maioria das aplicações tem um RTO entre uma hora e um dia, o que permite uma comutação por falha a quente num cenário de desastre, com alguns componentes da aplicação a serem executados sempre num modo de espera, como bases de dados, enquanto outros são dimensionados em caso de um desastre real, como servidores Web. Para estas aplicações, deve considerar seriamente a automatização dos eventos de expansão. Os serviços com um RTO superior a um dia têm a criticidade mais baixa e, muitas vezes, podem ser recuperados a partir de uma cópia de segurança ou recriados de raiz.
Ações principais: determine se precisa mesmo de um RTO de (quase) zero para a comutação por falha regional e, se for o caso, se pode fazê-lo para um subconjunto dos seus serviços. Isto altera o custo de execução e manutenção do seu serviço.
Passo 3: desenvolva as suas próprias arquiteturas de referência e guias
O último passo recomendado é criar os seus próprios padrões de arquitetura específicos da empresa para ajudar as suas equipas a padronizar a respetiva abordagem à recuperação de desastres. A maioria dos Google Cloud clientes produz um guia para as respetivas equipas de desenvolvimento que corresponde às suas expetativas individuais de resiliência empresarial em relação às duas principais categorias de cenários de indisponibilidade no Google Cloud. Isto permite que as equipas categorizem facilmente os produtos com DR ativado adequados para cada nível de criticidade.
Crie diretrizes de produtos
Voltando a analisar a tabela de RTO/RPO do exemplo acima, tem um guia hipotético que indica os produtos que seriam permitidos por predefinição para cada nível de criticidade. Tenha em atenção que, quando determinados produtos são identificados como não adequados por predefinição, pode sempre adicionar os seus próprios mecanismos de replicação e de comutação por falha para ativar a sincronização entre zonas ou entre regiões, mas este exercício está fora do âmbito deste artigo. As tabelas também incluem links para mais informações sobre cada produto para ajudar a compreender as respetivas capacidades no que diz respeito à gestão de indisponibilidades de zonas ou regiões.
Padrões de arquitetura de exemplo para a resiliência da organização de exemplo Co perante interrupções de zonas
| Google Cloud Produto | O produto cumpre os requisitos de indisponibilidade zonal para o exemplo Organização (com a configuração do produto adequada) | ||
|---|---|---|---|
| Nível 1 | Nível 2 | Nível 3 | |
| Compute Engine | Não | Não | Não |
| Dataflow | Não | Não | Não |
| BigQuery | Não | Não | Sim |
| GKE | Sim | Sim | Sim |
| Cloud Storage | Sim | Sim | Sim |
| Cloud SQL | Não | Sim | Sim |
| Spanner | Sim | Sim | Sim |
| Cloud Load Balancing | Sim | Sim | Sim |
Esta tabela é apenas um exemplo baseado nos níveis hipotéticos apresentados acima.
Padrões de arquitetura de exemplo para a resiliência de exemplo da organização Co perante interrupções na região
| Google Cloud Produto | O produto cumpre os requisitos de indisponibilidade da região para a organização de exemplo (com a configuração do produto adequada) | ||
|---|---|---|---|
| Nível 1 | Nível 2 | Nível 3 | |
| Compute Engine | Sim | Sim | Sim |
| Dataflow | Não | Não | Não |
| BigQuery | Não | Não | Sim |
| GKE | Sim | Sim | Sim |
| Cloud Storage | Não | Não | Não |
| Cloud SQL | Não | Sim | Sim |
| Spanner | Sim | Sim | Sim |
| Cloud Load Balancing | Sim | Sim | Sim |
Esta tabela é apenas um exemplo baseado nos níveis hipotéticos apresentados acima.
Para mostrar como estes produtos seriam usados, as secções seguintes explicam algumas arquiteturas de referência para cada um dos níveis de criticidade hipotéticos da aplicação. Estas são descrições deliberadamente de nível superior para ilustrar as principais decisões de arquitetura e não são representativas de um design de solução completo.
Exemplo de arquitetura de nível 3
| Criticidade da aplicação | Interrupção da zona | Indisponibilidade da região |
|---|---|---|
| Nível 3 (menos importante) |
RTO 12 horas RPO 24 horas |
RTO 28 dias RPO 24 horas |
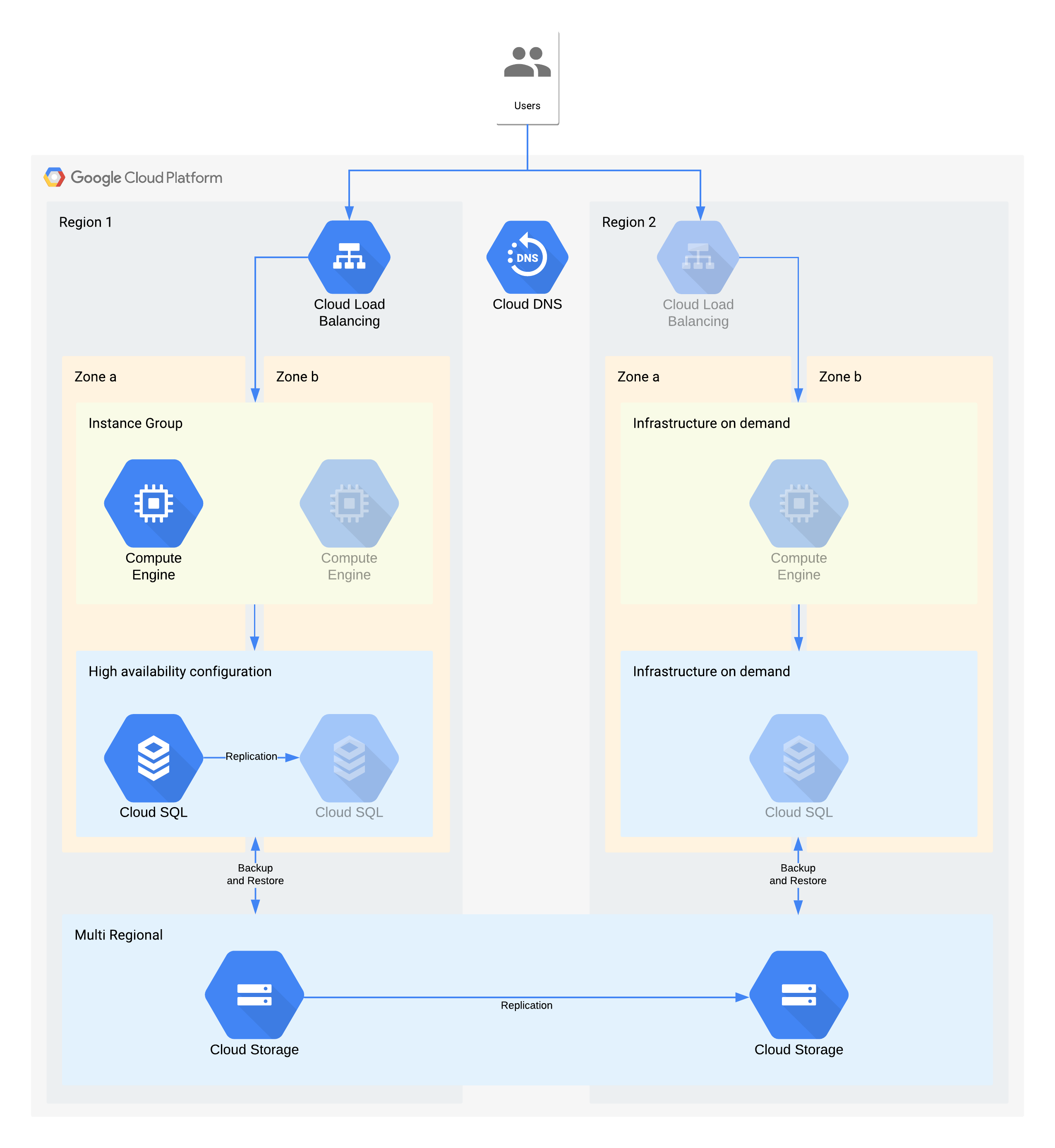
(Os ícones esbatidos indicam a infraestrutura a ativar para recuperação)
Esta arquitetura descreve uma aplicação cliente/servidor tradicional: os utilizadores internos estabelecem ligação a uma aplicação executada numa instância de computação que é suportada por uma base de dados para armazenamento persistente.
É importante ter em atenção que esta arquitetura suporta valores de RTO e RPO melhores do que os necessários. No entanto, também deve considerar eliminar passos manuais adicionais quando estes podem revelar-se dispendiosos ou pouco fiáveis. Por exemplo, a recuperação de uma base de dados a partir de uma cópia de segurança noturna pode suportar o RPO de 24 horas, mas normalmente precisa de um indivíduo qualificado, como um administrador de base de dados, que pode não estar disponível, especialmente se vários serviços forem afetados ao mesmo tempo. Com a infraestrutura a pedido da Google Cloud, pode criar esta capacidade sem fazer uma grande compensação de custos. Por isso, esta arquitetura usa o Cloud SQL HA em vez de uma cópia de segurança/restauro manual para interrupções zonais.
Principais decisões de arquitetura para interrupção da zona: RTO de 12 horas e RPO de 24 horas:
- Um equilibrador de carga interno é usado para fornecer um ponto de acesso escalável para os utilizadores, o que permite a comutação por falha automática para outra zona. Embora o RTO seja de 12 horas, as alterações manuais aos endereços IP ou até mesmo as atualizações de DNS podem demorar mais tempo do que o esperado.
- Um grupo de instâncias gerido regional está configurado com várias zonas, mas recursos mínimos. Esta opção otimiza os custos, mas continua a permitir o escalamento horizontal rápido das máquinas virtuais na zona de backup.
- Uma configuração do Cloud SQL de alta disponibilidade permite a comutação automática para outra zona. As bases de dados são significativamente mais difíceis de recriar e restaurar em comparação com as máquinas virtuais do Compute Engine.
Principais decisões de arquitetura para interrupções regionais: RTO de 28 dias e RPO de 24 horas:
- Um balanceador de carga seria construído na região 2 apenas em caso de indisponibilidade regional. O Cloud DNS é usado para fornecer uma capacidade de comutação por falha regional orquestrada, mas manual, uma vez que a infraestrutura na região 2 só seria disponibilizada no caso de uma indisponibilidade da região.
- Um novo grupo de instâncias gerido seria criado apenas em caso de indisponibilidade de uma região. Esta opção é otimizada para o custo e é improvável que seja invocada devido à curta duração da maioria das interrupções regionais. Tenha em atenção que, para simplificar, o diagrama não mostra as ferramentas associadas necessárias para reimplementar nem a cópia das imagens do Compute Engine necessárias.
- Uma nova instância do Cloud SQL seria recriada e os dados restaurados a partir de uma cópia de segurança. Mais uma vez, o risco de uma indisponibilidade prolongada numa região é extremamente baixo, pelo que esta é outra compensação de otimização de custos.
- O Cloud Storage multirregional é usado para armazenar estas cópias de segurança. Isto oferece resiliência automática de zonas e regional dentro do RTO e RPO.
Exemplo de arquitetura de nível 2
| Criticidade da aplicação | Interrupção da zona | Indisponibilidade da região |
|---|---|---|
| Nível 2 | RTO 4 horas RPO zero |
RTO 24 horas RPO 4 horas |
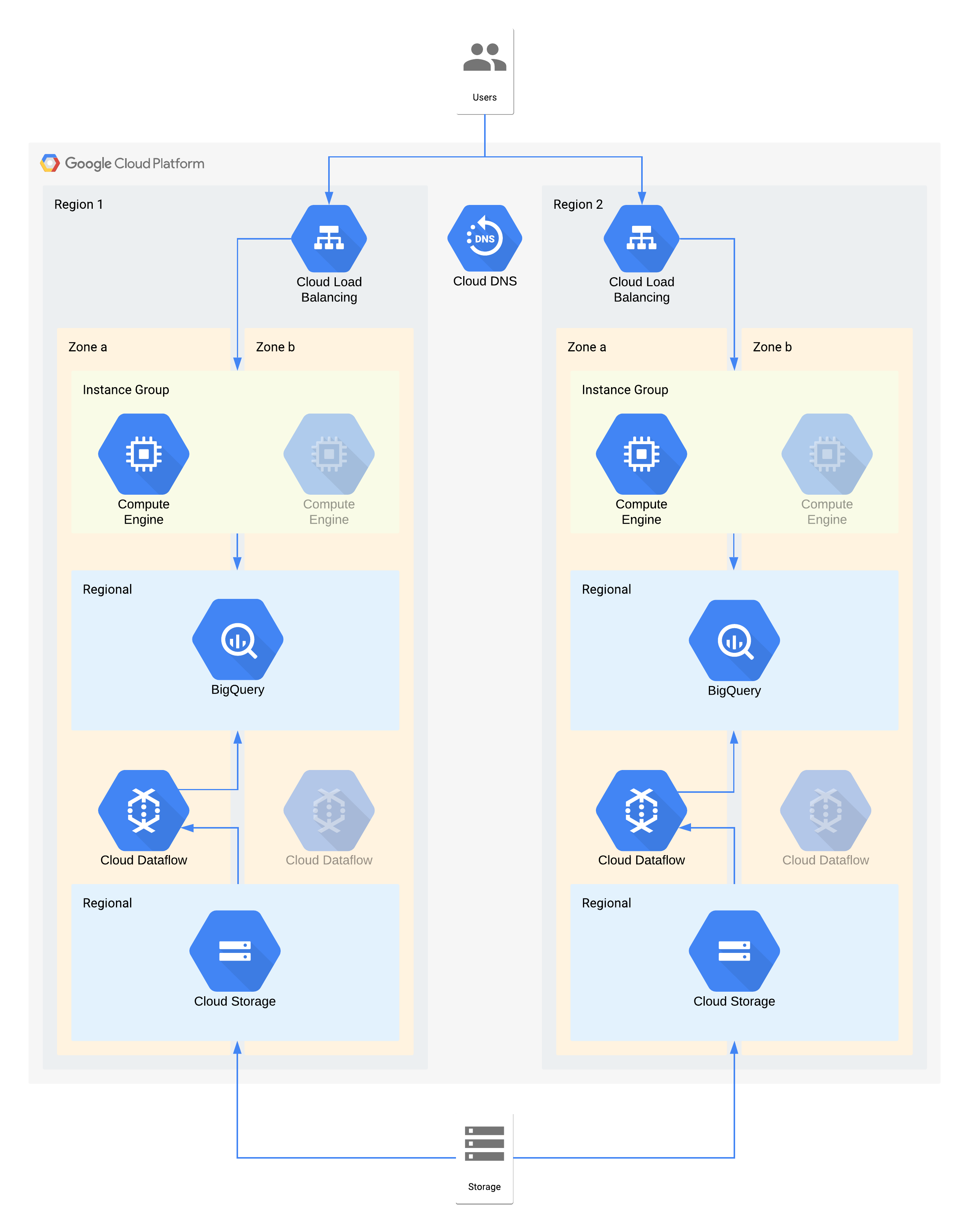
Esta arquitetura descreve um armazém de dados com utilizadores internos a estabelecer ligação a uma camada de visualização de instâncias de computação e uma camada de ingestão e transformação de dados que preenche o armazém de dados de back-end.
Alguns componentes individuais desta arquitetura não suportam diretamente o RPO necessário para o respetivo nível. No entanto, devido à forma como são usados em conjunto, o serviço geral cumpre o RPO. Neste caso, uma vez que o Dataflow é um produto zonal, siga as recomendações para um design de alta disponibilidade para ajudar a evitar a perda de dados durante uma indisponibilidade. No entanto, a camada do Cloud Storage é a origem principal destes dados e suporta um RPO de zero. Como resultado, pode voltar a carregar todos os dados perdidos para o BigQuery usando a zona b em caso de indisponibilidade na zona a.
Principais decisões de arquitetura para interrupções de zonas: RTO de 4 horas e RPO de zero:
- Um equilibrador de carga é usado para fornecer um ponto de acesso escalável para os utilizadores, o que permite uma comutação por falha automática para outra zona. Embora o RTO seja de 4 horas, as alterações manuais aos endereços IP ou até mesmo as atualizações de DNS podem demorar mais do que o esperado.
- Um grupo de instâncias gerido regional para a camada de computação de visualização de dados está configurado com várias zonas mas recursos mínimos. Esta opção otimiza os custos, mas continua a permitir o aumento rápido da escala das máquinas virtuais.
- O Cloud Storage regional é usado como uma camada de preparação para o carregamento inicial de dados, oferecendo resiliência automática de zonas.
- O Dataflow é usado para extrair dados do Cloud Storage e transformá-los antes de os carregar para o BigQuery. No caso de uma interrupção de zona, este é um processo sem estado que pode ser reiniciado noutra zona.
- O BigQuery fornece o back-end do armazém de dados para o front-end de visualização de dados. Em caso de indisponibilidade de uma zona, todos os dados perdidos seriam novamente carregados a partir do Cloud Storage.
Principais decisões de arquitetura para interrupções regionais: RTO de 24 horas e RPO de 4 horas:
- Um equilibrador de carga em cada região é usado para fornecer um ponto de acesso escalável para os utilizadores. O Cloud DNS é usado para fornecer uma capacidade de comutação por falha regional orquestrada, mas manual, uma vez que a infraestrutura na região 2 só seria disponibilizada em caso de indisponibilidade da região.
- Um grupo de instâncias gerido regional para a camada de computação de visualização de dados está configurado com várias zonas mas recursos mínimos. Esta opção não está acessível até que o equilibrador de carga seja reconfigurado, mas não requer intervenção manual.
- O Cloud Storage regional é usado como uma camada de preparação para o carregamento inicial de dados. Estes dados estão a ser carregados ao mesmo tempo em ambas as regiões para cumprir os requisitos do RPO.
- O Dataflow é usado para extrair dados do Cloud Storage e transformá-los antes de os carregar para o BigQuery. Em caso de indisponibilidade de uma região, esta ação preencheria o BigQuery com os dados mais recentes do Cloud Storage.
- O BigQuery fornece o back-end do armazém de dados. Em condições normais, esta informação seria atualizada intermitentemente. No caso de uma indisponibilidade da região, os dados mais recentes seriam novamente carregados através do Dataflow a partir do Cloud Storage.
Exemplo de arquitetura de nível 1
| Criticidade da aplicação | Interrupção da zona | Indisponibilidade da região |
|---|---|---|
| Nível 1 (mais importante) |
ORT zero RPO zero |
RTO 4 horas RPO 1 hora |
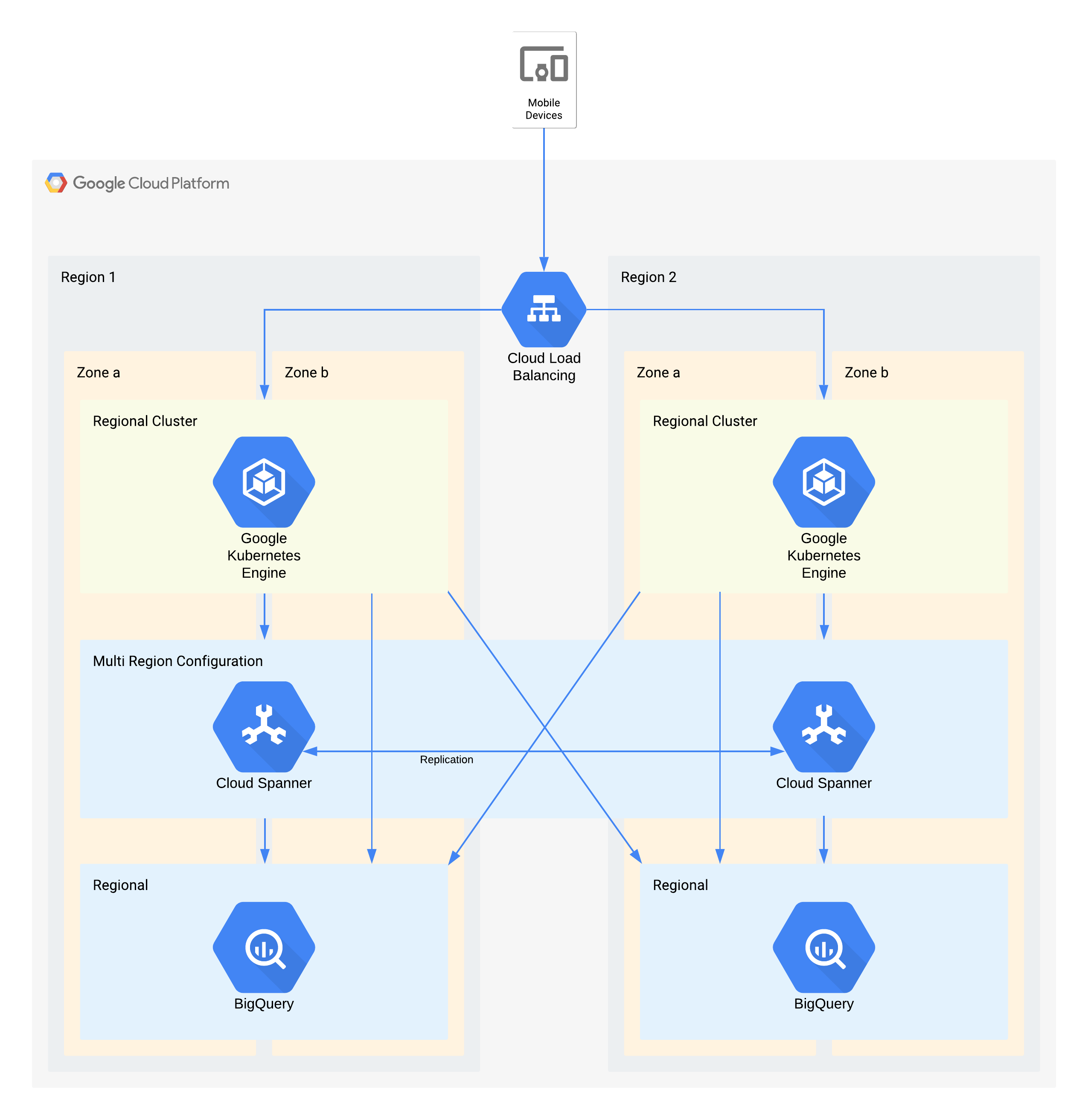
Esta arquitetura descreve uma infraestrutura de back-end de apps para dispositivos móveis com utilizadores externos que estabelecem ligação a um conjunto de microsserviços executados no GKE. O Spanner fornece a camada de armazenamento de dados de back-end para dados em tempo real, e os dados do histórico são transmitidos em stream para um lago de dados do BigQuery em cada região.
Mais uma vez, alguns componentes individuais desta arquitetura não suportam diretamente o RPO necessário para o respetivo nível, mas, devido à forma como são usados em conjunto, o serviço geral suporta. Neste caso, o BigQuery está a ser usado para consultas analíticas. Cada região é alimentada simultaneamente a partir do Spanner.
Principais decisões de arquitetura para interrupção da zona: RTO de zero e RPO de zero:
- Um equilibrador de carga é usado para fornecer um ponto de acesso escalável para os utilizadores, o que permite uma comutação por falha automática para outra zona.
- Um cluster do GKE regional é usado para a camada de aplicação, que é configurada com várias zonas. Isto cumpre o RTO de zero em cada região.
- As regiões múltiplas do Spanner são usadas como uma camada de persistência de dados, o que oferece resiliência automática dos dados da zona e consistência das transações.
- O BigQuery oferece a capacidade de análise para a aplicação. Cada região recebe dados de forma independente do Spanner e a aplicação acede a estes dados de forma independente.
Principais decisões de arquitetura para interrupções regionais: RTO de 4 horas e RPO de 1 hora:
- Um equilibrador de carga é usado para fornecer um ponto de acesso escalável para os utilizadores, o que permite a transferência automática para outra região em caso de falha.
- Um cluster do GKE regional é usado para a camada de aplicação, que é configurada com várias zonas. Em caso de indisponibilidade de uma região, o cluster na região alternativa é automaticamente dimensionado para assumir a carga de processamento adicional.
- A opção multirregião do Spanner é usada como uma camada de persistência de dados, o que oferece resiliência automática dos dados regionais e consistência das transações. Este é o componente principal para alcançar o RPO entre regiões de 1 hora.
- O BigQuery oferece a capacidade de análise para a aplicação. Cada região recebe dados de forma independente do Spanner e a aplicação acede a estes dados de forma independente. Esta arquitetura compensa o componente do BigQuery, permitindo-lhe corresponder aos requisitos gerais da aplicação.
Apêndice: referência do produto
Esta secção descreve a arquitetura e as capacidades de DR dos Google Cloud produtos mais usados em aplicações de clientes e que podem ser facilmente usados para cumprir os seus requisitos de DR.
Temas comuns
Muitos Google Cloud produtos oferecem configurações regionais ou multirregionais. Os produtos regionais são resilientes a falhas de zonas, e os produtos multirregionais e globais são resilientes a falhas de regiões. Em geral, isto significa que, durante uma indisponibilidade, a sua aplicação sofre uma interrupção mínima. A Google alcança estes resultados através de algumas abordagens arquitetónicas comuns, que refletem as orientações arquitetónicas acima.
Implementação redundante: os backends de aplicações e o armazenamento de dados são implementados em várias zonas numa região e em várias regiões numa localização multirregional. Para mais informações sobre considerações específicas da região, consulte o artigo Geografia e regiões.
Replicação de dados: os produtos usam a replicação síncrona ou assíncrona nas localizações redundantes.
A replicação síncrona significa que, quando a sua aplicação faz uma chamada de API para criar ou modificar dados armazenados pelo produto, recebe uma resposta bem-sucedida apenas quando o produto tiver escrito os dados em várias localizações. A replicação síncrona garante que não perde o acesso a nenhum dos seus dados durante uma indisponibilidade da infraestrutura, uma vez que todos os seus dados estão disponíveis numa das localizações de back-end disponíveis. Google Cloud
Embora esta técnica ofereça a máxima proteção de dados, pode ter compromissos em termos de latência e desempenho. Os produtos multirregiões que usam a replicação síncrona sentem este compromisso de forma mais significativa, normalmente na ordem das dezenas ou centenas de milissegundos de latência adicionada.
A replicação assíncrona significa que, quando a sua aplicação faz uma chamada de API para criar ou modificar dados armazenados pelo produto, recebe uma resposta bem-sucedida assim que o produto tiver escrito os dados numa única localização. Após o seu pedido de gravação, o produto replica os seus dados para localizações adicionais.
Esta técnica oferece uma latência inferior e um débito mais elevado na API do que a replicação síncrona, mas à custa da proteção de dados. Se a localização na qual escreveu dados sofrer uma indisponibilidade antes de a replicação estar concluída, perde o acesso a esses dados até que a indisponibilidade da localização seja resolvida.
Processar interrupções com o balanceamento de carga: Google Cloud usa o balanceamento de carga de software para encaminhar pedidos para os back-ends de aplicações adequados. Em comparação com outras abordagens, como o equilíbrio de carga de DNS, esta abordagem reduz o tempo de resposta do sistema a uma indisponibilidade. Quando ocorre uma Google Cloud indisponibilidade de localização, o balanceador de carga deteta rapidamente que o back-end implementado nessa localização ficou "não saudável" e direciona todos os pedidos para um back-end numa localização alternativa. Isto permite que o produto continue a publicar os pedidos da sua aplicação durante uma indisponibilidade de localização. Quando a indisponibilidade de localização é resolvida, o balanceador de carga deteta a disponibilidade dos back-ends do produto nessa localização e retoma o envio de tráfego para aí.
Gestor de acesso sensível ao contexto
O Gestor de acesso sensível ao contexto permite às empresas configurar níveis de acesso que são mapeados para uma política definida com base em atributos de pedido. As políticas são replicadas regionalmente.
No caso de uma indisponibilidade zonal, os pedidos para zonas indisponíveis são servidos automaticamente e de forma transparente a partir de outras zonas disponíveis na região.
No caso de uma indisponibilidade regional, os cálculos das políticas da região afetada ficam indisponíveis até que a região volte a estar disponível.
Transparência de acesso
A transparência de acesso permite que os administradores da organização definam um controlo de acesso detalhado baseado em atributos para projetos e recursos no Google Cloud. Google Cloud Google CloudOcasionalmente, a Google tem de aceder aos dados de clientes para fins administrativos. Quando acedemos aos dados dos clientes, a Transparência de acesso fornece registos de acesso aos clientes afetados. Google CloudEstes registos da Transparência de acesso ajudam a garantir o compromisso da Google com a segurança dos dados e a transparência no processamento de dados.
A transparência de acesso é resiliente a interrupções zonais e regionais. Se ocorrer uma indisponibilidade zonal ou regional, a Transparência de acesso continua a processar os registos de acesso administrativo noutra zona ou região.
AlloyDB para PostgreSQL
O AlloyDB para PostgreSQL é um serviço de base de dados totalmente gerido e compatível com o PostgreSQL. O AlloyDB para PostgreSQL oferece alta disponibilidade numa região através dos nós redundantes da instância principal, que estão localizados em duas zonas diferentes da região. A instância principal mantém a disponibilidade regional acionando uma comutação por falha automática para a zona de reserva se a zona ativa tiver um problema. O armazenamento regional garante a durabilidade dos dados em caso de perda de uma única zona.
Como método adicional de recuperação de desastres, o AlloyDB for PostgreSQL usa a replicação entre regiões para oferecer capacidades de recuperação de desastres replicando de forma assíncrona os dados do cluster principal em clusters secundários localizados em Google Cloud regiões separadas.
Interrupção zonal: durante o funcionamento normal, apenas um dos dois nós de uma instância principal de alta disponibilidade está ativo e serve todas as gravações de dados. Este nó ativo armazena os dados na camada de armazenamento regional separada do cluster.
O AlloyDB para PostgreSQL deteta automaticamente falhas ao nível da zona e aciona uma comutação por falha para restaurar a disponibilidade da base de dados. Durante a comutação por falha, o AlloyDB para PostgreSQL inicia a base de dados no nó de reserva, que já está aprovisionado numa zona diferente. As novas associações de bases de dados são encaminhadas automaticamente para esta zona.
Do ponto de vista de uma aplicação cliente, uma indisponibilidade zonal assemelha-se a uma interrupção temporária da conetividade de rede. Após a conclusão da comutação por falha, um cliente pode voltar a ligar-se à instância no mesmo endereço, usando as mesmas credenciais, sem perda de dados.
Interrupção regional: a replicação entre regiões usa a replicação assíncrona, o que permite que a instância principal confirme as transações antes de serem confirmadas nas réplicas. A diferença de tempo entre o momento em que uma transação é confirmada na instância principal e o momento em que é confirmada na réplica é conhecida como intervalo de tempo de replicação. A diferença de tempo entre o momento em que o servidor principal gera o registo de transações (WAL) e o momento em que o WAL chega à réplica é conhecida como atraso de descarga. O atraso de replicação e o atraso de descarga dependem da configuração da instância da base de dados e da carga de trabalho gerada pelo utilizador.
Em caso de indisponibilidade regional, pode promover clusters secundários numa região diferente para um cluster principal autónomo gravável. Este cluster promovido já não replica os dados do cluster principal original ao qual estava anteriormente associado. Devido ao atraso de descarga, pode ocorrer alguma perda de dados, uma vez que podem existir transações no servidor principal original que não foram propagadas para o cluster secundário.
O RPO da replicação entre regiões é afetado pela utilização da CPU do cluster principal e pela distância física entre a região do cluster principal e a região do cluster secundário. Para otimizar o RPO, recomendamos que teste a sua carga de trabalho com uma configuração que inclua uma réplica para estabelecer um limite de transações por segundo (TPS) seguro, que é o TPS sustentado mais elevado que não acumula atraso de descarga. Se a sua carga de trabalho exceder o limite de TPS seguro, o atraso de descarga acumula-se, o que pode afetar o RPO. Para limitar o atraso da rede, escolha pares de regiões no mesmo continente.
Para mais informações sobre a monitorização do atraso da rede e outras métricas do AlloyDB para PostgreSQL, consulte o artigo Monitorize instâncias.
IA antilavagem de dinheiro
A IA antilavagem de dinheiro (AML AI) fornece uma API para ajudar as instituições financeiras globais a detetar a lavagem de dinheiro de forma mais eficaz e eficiente. A IA de combate ao branqueamento de capitais é uma oferta regional, o que significa que os clientes podem escolher a região, mas não as zonas que compõem uma região. Os dados e o tráfego são automaticamente equilibrados em várias zonas de uma região. As operações (por exemplo, para criar um pipeline ou executar uma previsão) são dimensionadas automaticamente em segundo plano e são equilibradas em termos de carga entre zonas, conforme necessário.
Indisponibilidade zonal: a IA da AML armazena dados para os respetivos recursos de forma regional, replicados de forma síncrona. Quando uma operação de longa duração termina com êxito, pode confiar nos recursos, independentemente das falhas zonais. O processamento também é replicado em várias zonas, mas esta replicação destina-se ao balanceamento de carga e não à elevada disponibilidade, pelo que uma falha zonal durante uma operação pode resultar numa falha da operação. Se isso acontecer, repetir a operação pode resolver o problema. Durante uma indisponibilidade zonal, os tempos de processamento podem ser afetados.
Indisponibilidade regional: os clientes escolhem a região do Google Cloud na qual querem criar os respetivos recursos de IA de AML. Os dados nunca são replicados em várias regiões. O tráfego de clientes nunca é encaminhado para uma região diferente pela IA de AML. No caso de uma falha regional, a IA de AML vai ficar novamente disponível assim que a indisponibilidade for resolvida.
Chaves da API
As chaves da API oferecem uma gestão de recursos de chaves da API escalável para um projeto. As chaves da API são um serviço global, o que significa que as chaves são visíveis e acessíveis a partir de qualquer Google Cloud localização. Os respetivos dados e metadados são armazenados de forma redundante em várias zonas e regiões.
As chaves da API são resilientes a interrupções zonais e regionais. No caso de uma interrupção zonal ou regional, as chaves de API continuam a processar pedidos de outra zona na mesma região ou numa região diferente.
Para mais informações sobre chaves da API, consulte o artigo Vista geral da API de chaves da API.
Apigee
O Apigee oferece uma plataforma segura, escalável e fiável para desenvolver e gerir APIs. O Apigee oferece implementações de região única e multirregionais.
Indisponibilidade zonal: os dados de tempo de execução do cliente são replicados em várias zonas de disponibilidade. Por isso, uma indisponibilidade de uma única zona não afeta o Apigee.
Indisponibilidade regional: para instâncias do Apigee de região única, se uma região ficar inativa, as instâncias do Apigee ficam indisponíveis nessa região e não podem ser restauradas para regiões diferentes. Para instâncias do Apigee multirregionais, os dados são replicados de forma assíncrona em todas as regiões. Por conseguinte, a falha de uma região não reduz totalmente o tráfego. No entanto, pode não conseguir aceder aos dados não comprometidos na região com falha. Pode desviar o tráfego de regiões não saudáveis. Para alcançar uma comutação por falha de tráfego automática, pode configurar o encaminhamento de rede através de grupos de instâncias geridas (MIGs).
AutoML Translation
O AutoML Translation é um serviço de tradução automática que lhe permite importar os seus próprios dados (pares de frases) para preparar modelos personalizados para as suas necessidades específicas do domínio.
Indisponibilidade zonal: o AutoML Translation tem servidores de computação ativos em várias zonas e regiões. Também suporta a replicação de dados síncrona entre zonas nas regiões. Estas funcionalidades ajudam a AutoML Translation a alcançar uma comutação por falha instantânea sem perda de dados para falhas zonais e sem exigir qualquer introdução ou ajuste por parte do cliente.
Indisponibilidade regional: no caso de uma falha regional, o AutoML Translation não está disponível.
AutoML Vision
O AutoML Vision faz parte do Vertex AI. Oferece uma estrutura unificada para criar conjuntos de dados, importar dados, preparar modelos e publicar modelos para previsão online e previsão em lote.
O AutoML Vision é uma oferta regional. Os clientes podem escolher a região a partir da qual querem iniciar uma tarefa, mas não podem escolher as zonas específicas nessa região. O serviço equilibra automaticamente a carga de trabalho em diferentes zonas da região.
Indisponibilidade zonal: o AutoML Vision armazena metadados para as tarefas regionalmente e escreve de forma síncrona em várias zonas da região. As tarefas são iniciadas numa zona específica, conforme selecionado pelo Cloud Load Balancing.
Tarefas de preparação do AutoML Vision: uma indisponibilidade zonal faz com que todas as tarefas em execução falhem e o estado da tarefa é atualizado para falhado. Se uma tarefa falhar, tente novamente imediatamente. A nova tarefa é encaminhada para uma zona disponível.
Tarefas de previsão em lote do AutoML Vision: a previsão em lote é criada com base na previsão em lote da Vertex AI. Quando ocorre uma indisponibilidade zonal, o serviço tenta novamente a tarefa automaticamente encaminhando-a para zonas disponíveis. Se várias tentativas falharem, o estado do trabalho é atualizado para falhou. Os pedidos subsequentes dos utilizadores para executar a tarefa são encaminhados para uma zona disponível.
Indisponibilidade regional: os clientes escolhem a Google Cloud região na qual querem executar os respetivos trabalhos. Os dados nunca são replicados entre regiões. Numa falha regional, o serviço AutoML Vision fica indisponível nessa região. Fica disponível novamente quando a indisponibilidade for resolvida. Para executar os respetivos trabalhos, recomendamos que os clientes usem várias regiões. No caso de ocorrer uma indisponibilidade regional, direcione as tarefas para uma região disponível diferente.
Lote
O Batch é um serviço totalmente gerido para colocar em fila, agendar e executar tarefas em lote no Google Cloud. As definições de lote são definidas ao nível da região. Os clientes têm de escolher uma região para enviar os respetivos trabalhos em lote e não uma zona numa região. Quando uma tarefa é enviada, o Batch escreve de forma síncrona os dados dos clientes em várias zonas. No entanto, os clientes podem especificar as zonas onde as VMs em lote executam tarefas.
Falha zonal: quando uma única zona falha, as tarefas em execução nessa zona também falham. Se as tarefas tiverem definições de repetição, o Batch transfere automaticamente essas tarefas para outras zonas ativas na mesma região. A comutação por falha automática está sujeita à disponibilidade de recursos nas zonas ativas na mesma região. As tarefas que requerem recursos zonais (como VMs, GPUs ou discos persistentes zonais) que só estão disponíveis na zona com falhas são colocadas em fila até a zona com falhas ser recuperada ou até os limites de tempo de colocação em fila das tarefas serem atingidos. Sempre que possível, recomendamos que os clientes permitam que o Batch escolha recursos zonais para executar as respetivas tarefas. Isto ajuda a garantir que os trabalhos são resilientes a uma indisponibilidade zonal.
Falha regional: em caso de falha regional, o plano de controlo do serviço fica indisponível na região. O serviço não replica dados nem redireciona pedidos entre regiões. Recomendamos que os clientes usem várias regiões para executar os respetivos trabalhos e redirecionem os trabalhos para uma região diferente se uma região falhar.
Proteção de dados e contra ameaças do Chrome Enterprise Premium
A proteção de dados e contra ameaças do Chrome Enterprise Premium faz parte da solução Chrome Enterprise Premium. Expande o Chrome com várias funcionalidades de segurança, incluindo proteção contra software malicioso e phishing, Prevenção contra a perda de dados (DLP), regras de filtragem de URLs e relatórios de segurança.
Os administradores do Chrome Enterprise Premium podem optar por armazenar conteúdos principais de clientes que violem as políticas de DLP ou software malicioso nos eventos de registo de regras do Google Workspace e/ou no Cloud Storage para investigação futura. Os eventos de registo de regras do Google Workspace são baseados numa base de dados do Spanner multirregional. O Chrome Enterprise Premium pode demorar até várias horas a detetar violações de políticas. Durante este período, todos os dados não processados estão sujeitos a perda de dados devido a uma interrupção zonal ou regional. Assim que é detetada uma violação, o conteúdo que viola as suas políticas é escrito em eventos do registo de regras do Google Workspace e/ou no Cloud Storage.
Interrupção zonal e regional: uma vez que a proteção de dados e contra ameaças do Chrome Enterprise Premium é multizonal e multirregional, pode sobreviver a uma perda completa e não planeada de uma zona ou de uma região sem uma perda de disponibilidade. Oferece este nível de fiabilidade através do redirecionamento do tráfego para o respetivo serviço noutras zonas ou regiões ativas. No entanto, uma vez que a proteção de dados e contra ameaças do Chrome Enterprise Premium pode demorar várias horas a detetar violações de DLP e software malicioso, todos os dados não processados numa zona ou região específica estão sujeitos a perda devido a uma indisponibilidade zonal ou regional.
BigQuery
O BigQuery é um armazém de dados na nuvem sem servidor, altamente escalável e rentável concebido para a agilidade empresarial. O BigQuery suporta os seguintes tipos de localização para conjuntos de dados do utilizador:
- Uma região: uma localização geográfica específica, como Iowa (
us-central1) ou Montreal (northamerica-northeast1). - Uma região múltipla: uma grande área geográfica que contém dois ou mais locais geográficos, como os Estados Unidos (
US) ou a Europa (EU).
Em ambos os casos, os dados são armazenados de forma redundante em duas zonas numa única região na localização selecionada. Os dados escritos no BigQuery são escritos de forma síncrona nas zonas primária e secundária. Isto protege contra a indisponibilidade de uma única zona na região, mas não contra uma interrupção regional.
Autorização binária
A autorização binária é um produto de segurança da cadeia de abastecimento de software para o GKE e o Cloud Run.
Todas as políticas de autorização binária são replicadas em várias zonas em todas as regiões. A replicação ajuda as operações de leitura da política de autorização binária a recuperar de falhas de outras regiões. A replicação também torna as operações de leitura tolerantes a falhas zonais em cada região.
As operações de aplicação da autorização binária são resilientes a interrupções zonais, mas não são resilientes a interrupções regionais. As operações de aplicação são executadas na mesma região que o cluster do GKE ou a tarefa do Cloud Run que está a fazer o pedido. Por conseguinte, em caso de indisponibilidade regional, não existe nada em execução para fazer pedidos de aplicação da autorização binária.
Gestor de certificados
O Certificate Manager permite-lhe adquirir e gerir certificados Transport Layer Security (TLS) para utilização com diferentes tipos de Cloud Load Balancing.
No caso de uma interrupção zonal, o Certificate Manager regional e global é resiliente a falhas zonais, uma vez que as tarefas e as bases de dados são redundantes em várias zonas numa região. No caso de uma interrupção regional, o Certificate Manager global é resiliente a falhas regionais porque as tarefas e as bases de dados são redundantes em várias regiões. O Regional Certificate Manager é um produto regional, pelo que não consegue resistir a uma falha regional.
Sistema de deteção de intrusos do Cloud
O sistema de deteção de intrusos do Cloud (Cloud IDS) é um serviço zonal que fornece pontos finais do IDS com âmbito zonal, que processam o tráfego de VMs numa zona específica e, por isso, não é tolerante a interrupções zonais ou regionais.
Indisponibilidade zonal: o Cloud IDS está associado a instâncias de VM. Se um cliente planear mitigar as indisponibilidades zonais implementando VMs em várias zonas (manualmente ou através de grupos de instâncias geridos regionais), também tem de implementar pontos finais do Cloud IDS nessas zonas.
Indisponibilidade regional: o Cloud IDS é um produto regional. Não oferece qualquer funcionalidade entre regiões. Uma falha regional desativa toda a funcionalidade do Cloud IDS em todas as zonas dessa região.
SIEM do Google Security Operations
O SIEM do Google Security Operations (que faz parte do Google Security Operations) é um serviço totalmente gerido que ajuda as equipas de segurança a detetar, investigar e responder a ameaças.
O SIEM do Google Security Operations tem ofertas regionais e multirregionais.
Nas ofertas regionais, os dados e o tráfego são automaticamente equilibrados entre as zonas na região escolhida, e os dados são armazenados de forma redundante entre as zonas de disponibilidade na região.
As multirregiões são georredundantes. Essa redundância oferece um conjunto mais amplo de proteções do que o armazenamento regional. Também ajuda a garantir que o serviço continua a funcionar mesmo que uma região completa seja perdida.
A maioria dos caminhos de carregamento de dados replica os dados de clientes de forma síncrona em várias localizações. Quando os dados são replicados de forma assíncrona, existe um período (um objetivo de ponto de recuperação ou RPO) durante o qual os dados ainda não são replicados em várias localizações. É o caso quando carrega dados com feeds em implementações multirregionais. Após o RPO, os dados estão disponíveis em várias localizações.
Interrupção zonal:
Implementações regionais: as solicitações são publicadas a partir de qualquer zona na região. Os dados são replicados de forma síncrona em várias zonas. Em caso de uma indisponibilidade total da zona, as zonas restantes continuam a publicar tráfego e a processar os dados. O aprovisionamento redundante e o escalamento automático para o SIEM do Google Security Operations ajudam a garantir que o serviço permanece operacional nas zonas restantes durante estas mudanças de carga.
Implementações multirregionais: as interrupções zonais são equivalentes a interrupções regionais.
Indisponibilidade regional:
Implementações regionais: o SIEM do Google Security Operations armazena todos os dados de clientes numa única região, e o tráfego nunca é encaminhado entre regiões. Em caso de uma falha de serviço regional, a SIEM do Google Security Operations fica indisponível na região até a falha de serviço ser resolvida.
Implementações multirregionais (sem feeds): os pedidos são publicados a partir de qualquer região da implementação multirregional. Os dados são replicados de forma síncrona em várias regiões. Em caso de uma indisponibilidade de região completa, as regiões restantes continuam a publicar tráfego e a processar os dados. O aprovisionamento redundante e o dimensionamento automático para o SIEM das operações de segurança da Google ajudam a garantir que o serviço permanece operacional nas regiões restantes durante estas mudanças de carga.
Implementações multirregionais (com feeds): os pedidos são publicados a partir de qualquer região da implementação multirregional. Os dados são replicados de forma assíncrona em várias regiões com o RPO fornecido. Em caso de uma indisponibilidade de toda a região, apenas os dados armazenados após o RPO estão disponíveis nas regiões restantes. Os dados na janela de RPO podem não ser replicados.
Cloud Asset Inventory
O Cloud Asset Inventory é um serviço global resiliente e de elevado desempenho que mantém um repositório de metadados de recursos e políticas. Google Cloud O Cloud Asset Inventory oferece ferramentas de pesquisa e análise que ajudam a monitorizar os recursos implementados em organizações, pastas e projetos.
No caso de uma indisponibilidade de zona, o Cloud Asset Inventory continua a processar pedidos de outra zona na mesma região ou numa região diferente.
No caso de uma indisponibilidade regional, o Cloud Asset Inventory continua a processar pedidos de outras regiões.
Bigtable
O Bigtable é um serviço de base de dados NoSQL de elevado desempenho totalmente gerido para grandes cargas de trabalho analíticas e operacionais.
Vista geral da replicação do Bigtable
O Bigtable oferece uma funcionalidade de replicação flexível e totalmente configurável, que pode usar para aumentar a disponibilidade e a durabilidade dos seus dados copiando-os para clusters em várias regiões ou várias zonas na mesma região. O Bigtable também pode fornecer failover automático para os seus pedidos quando usa a replicação.
Quando usar configurações multizonais ou multirregionais com encaminhamento de vários clusters, no caso de uma indisponibilidade zonal ou regional, o Bigtable reencaminha automaticamente o tráfego e apresenta pedidos do cluster disponível mais próximo. Uma vez que a replicação do Bigtable é assíncrona e eventualmente consistente, as alterações muito recentes aos dados na localização da indisponibilidade podem não estar disponíveis se ainda não tiverem sido replicadas para outras localizações.
Considerações sobre o desempenho
Quando as exigências de recursos da CPU excedem a capacidade do nó disponível, o Bigtable dá sempre prioridade ao processamento de pedidos recebidos em detrimento do tráfego de replicação.
Para mais informações sobre como usar a replicação do Bigtable com a sua carga de trabalho, consulte a vista geral da replicação do Cloud Bigtable e exemplos de definições de replicação.
Os nós do Bigtable são usados para processar pedidos recebidos e para realizar a replicação de dados de outros clusters. Além de manter um número suficiente de nós por cluster, também tem de garantir que as suas aplicações usam um design de esquema adequado para evitar pontos críticos, que podem causar uma utilização excessiva ou desequilibrada da CPU e um aumento da latência de replicação.
Para mais informações sobre a criação do esquema da sua aplicação para maximizar o desempenho e a eficiência do Bigtable, consulte as práticas recomendadas de criação de esquemas.
Monitorização
O Bigtable oferece várias formas de monitorizar visualmente a latência de replicação das suas instâncias e clusters através dos gráficos de replicação disponíveis na Google Cloud console.
Também pode monitorizar programaticamente as métricas de replicação do Bigtable usando a API Cloud Monitoring.
Certificate Authority Service
O serviço de autoridade de certificação (serviço de AC) permite que os clientes simplifiquem, automatizem e personalizem a implementação, a gestão e a segurança de autoridades de certificação (AC) privadas, bem como emitam certificados de forma resiliente em grande escala.
Indisponibilidade zonal: o serviço CA é resiliente a falhas zonais porque o respetivo plano de controlo é redundante em várias zonas numa região. Se houver uma indisponibilidade zonal, o serviço CA continua a publicar pedidos de outra zona na mesma região sem interrupção. Uma vez que os dados são replicados de forma síncrona, não há perda nem corrupção de dados.
Indisponibilidade regional: o serviço de CA é um produto regional, pelo que não consegue resistir a uma falha regional. Se precisar de resiliência a falhas regionais, crie ACs de emissão em duas regiões diferentes. Crie a AC de emissão principal na região onde precisa de certificados. Crie uma AC alternativa numa região diferente. Use o alternativo quando a região da AC subordinada principal tiver uma indisponibilidade. Se necessário, ambas as ACs podem encadear até à mesma AC raiz.
Cloud Billing
A API Cloud Billing permite aos programadores gerirem a faturação dos respetivosGoogle Cloud projetos de forma programática. A Cloud Billing API foi concebida como um sistema global com atualizações escritas de forma síncrona em várias zonas e regiões.
Falha zonal ou regional: a API Cloud Billing vai mudar automaticamente para outra zona ou região. Os pedidos individuais podem falhar, mas uma política de repetição deve permitir que as tentativas subsequentes sejam bem-sucedidas.
Cloud Build
O Cloud Build é um serviço que executa as suas compilações na Google Cloud.
O Cloud Build é composto por instâncias isoladas regionalmente que replicam dados de forma síncrona em várias zonas da região. Recomendamos que use regiões específicas Google Cloud em vez da região global e se certifique de que os recursos que a sua compilação usa (incluindo contentores de registos, repositórios do Artifact Registry, etc.) estão alinhados com a região em que a sua compilação é executada.
No caso de uma indisponibilidade zonal, as operações do plano de controlo não são afetadas. No entanto, as compilações em execução na zona com falhas vão sofrer atrasos ou vão ser perdidas permanentemente. As compilações acionadas recentemente são distribuídas automaticamente para as zonas em funcionamento restantes.
No caso de uma falha regional, o plano de controlo fica offline e as compilações em execução são atrasadas ou perdidas permanentemente. Os acionadores, os conjuntos de trabalhadores e os dados de compilação nunca são replicados entre regiões. Recomendamos que prepare acionadores e conjuntos de trabalhadores em várias regiões para facilitar a mitigação de uma indisponibilidade.
Cloud CDN
O Cloud CDN distribui e coloca conteúdo em cache em várias localizações na rede da Google para reduzir a latência de publicação para os clientes. O conteúdo em cache é publicado com base no melhor esforço possível. Quando um pedido não pode ser publicado pela cache da RFC na nuvem, o pedido é encaminhado para servidores de origem, como VMs de back-end ou contentores do Cloud Storage, onde o conteúdo original está armazenado.
Quando uma zona ou uma região falha, as caches nas localizações afetadas ficam indisponíveis. Os pedidos de entrada são encaminhados para as localizações de limite da rede e caches da Google disponíveis. Se estas caches alternativas não puderem processar o pedido, encaminham-no para um servidor de origem disponível. Desde que o servidor possa responder ao pedido com dados atualizados, não haverá perda de conteúdo. Uma taxa de falhas de cache aumentada faz com que os servidores de origem registem volumes de tráfego superiores ao normal à medida que as caches são preenchidas. Os pedidos subsequentes são servidos a partir das caches não afetadas pela indisponibilidade da zona ou da região.
Para mais informações sobre o Cloud CDN e o comportamento da cache, consulte a documentação do Cloud CDN.
Cloud Composer
O Cloud Composer é um serviço de orquestração de fluxos de trabalho gerido que lhe permite criar, agendar, monitorizar e gerir fluxos de trabalho que abrangem várias nuvens e centros de dados no local. Os ambientes do Cloud Composer são criados com base no projeto de código aberto Apache Airflow.
A disponibilidade da API Cloud Composer não é afetada pela indisponibilidade zonal. Durante uma interrupção zonal, mantém o acesso à API Cloud Composer, incluindo a capacidade de criar novos ambientes do Cloud Composer.
Um ambiente do Cloud Composer tem um cluster do GKE como parte da respetiva arquitetura. Durante uma indisponibilidade zonal, os fluxos de trabalho no cluster podem ser interrompidos:
- No Cloud Composer 1, o cluster do ambiente é um recurso zonal. Por isso, uma indisponibilidade zonal pode tornar o cluster indisponível. Os fluxos de trabalho que estão a ser executados no momento da indisponibilidade podem ser interrompidos antes da conclusão.
- No Cloud Composer 2, o cluster do ambiente é um recurso regional. No entanto, os fluxos de trabalho executados em nós nas zonas afetadas por uma indisponibilidade zonal podem ser interrompidos antes da conclusão.
Em ambas as versões do Cloud Composer, uma indisponibilidade zonal pode fazer com que os fluxos de trabalho parcialmente executados parem de ser executados, incluindo quaisquer ações externas que tenha configurado para o fluxo de trabalho realizar. Consoante o fluxo de trabalho, isto pode causar inconsistências externamente, por exemplo, se o fluxo de trabalho parar a meio de uma execução de vários passos para modificar armazenamentos de dados externos. Por conseguinte, deve considerar o processo de recuperação quando conceber o fluxo de trabalho do Airflow, incluindo como detetar estados de fluxo de trabalho parcialmente não executados e reparar quaisquer alterações parciais aos dados.
No Cloud Composer 1, durante uma indisponibilidade de zona, pode optar por iniciar um novo ambiente do Cloud Composer noutra zona. Uma vez que o Airflow mantém o estado dos seus fluxos de trabalho na respetiva base de dados de metadados, a transferência destas informações para um novo ambiente do Cloud Composer pode exigir passos e preparação adicionais.
No Cloud Composer 2, pode resolver interrupções zonais configurando a recuperação de desastres com instantâneos do ambiente antecipadamente. Durante uma indisponibilidade de zona, pode mudar para outro ambiente transferindo o estado dos seus fluxos de trabalho com uma captura instantânea do ambiente. Apenas o Cloud Composer 2 suporta a recuperação de desastres com instantâneos do ambiente.
Cloud Data Fusion
O Cloud Data Fusion é um serviço de integração de dados empresarial totalmente gerido para criar e gerir rapidamente pipelines de dados. Oferece três edições.
As indisponibilidades zonais afetam as instâncias da edição Developer.
As falhas regionais afetam as instâncias das edições Basic e Enterprise.
Para controlar o acesso aos recursos, pode conceber e executar pipelines em ambientes separados. Esta separação permite-lhe criar um pipeline uma vez e, em seguida, executá-lo em vários ambientes. Pode recuperar pipelines em ambos os ambientes. Para mais informações, consulte o artigo Faça uma cópia de segurança e restaure os dados da instância.
As seguintes recomendações aplicam-se a interrupções regionais e zonais.
Indisponibilidades no ambiente de design de pipelines
No ambiente de design, guarde os rascunhos de pipelines em caso de indisponibilidade. Consoante os requisitos específicos de RTO e RPO, pode usar os rascunhos guardados para restaurar o pipeline numa instância diferente do Cloud Data Fusion durante uma indisponibilidade.
Indisponibilidades no ambiente de execução da pipeline
No ambiente de execução, inicia o pipeline internamente com acionadores ou agendamentos do Cloud Data Fusion, ou externamente com ferramentas de orquestração, como o Cloud Composer. Para poder recuperar as configurações de tempo de execução dos pipelines, faça uma cópia de segurança dos pipelines e das configurações, como plug-ins e agendamentos. Em caso de indisponibilidade, pode usar a cópia de segurança para replicar uma instância numa região ou zona não afetada.
Outra forma de se preparar para indisponibilidades é ter várias instâncias nas regiões com a mesma configuração e conjunto de pipeline. Se usar a orquestração externa, o equilíbrio de carga das pipelines em execução pode ser feito automaticamente entre as instâncias. Tome especial cuidado para garantir que não existem recursos (como origens de dados ou ferramentas de orquestração) associados a uma única região e usados por todas as instâncias, uma vez que isto pode tornar-se um ponto central de falha em caso de indisponibilidade. Por exemplo, pode ter várias instâncias em diferentes regiões e usar o Cloud Load Balancing e o Cloud DNS para direcionar os pedidos de execução da pipeline para uma instância que não seja afetada por uma indisponibilidade (consulte as arquiteturas de nível um e nível três).
Indisponibilidades de outros Google Cloud serviços de dados no pipeline
A sua instância pode usar outros Google Cloud serviços como origens de dados ou ambientes de execução de pipelines, como o Dataproc, o Cloud Storage ou o BigQuery. Esses serviços podem estar em regiões diferentes. Quando a execução entre regiões é necessária, uma falha em qualquer uma das regiões leva a uma indisponibilidade. Neste cenário, segue os passos de recuperação de desastres padrão, tendo em atenção que a configuração entre regiões com serviços críticos em regiões diferentes é menos resiliente.
Cloud Deploy
O Cloud Deploy oferece entrega contínua de cargas de trabalho em serviços de tempo de execução, como o GKE e o Cloud Run. O serviço é composto por instâncias regionais que replicam dados de forma síncrona em várias zonas da região.
Indisponibilidade zonal: as operações do plano de controlo não são afetadas. No entanto, as compilações do Cloud Build (por exemplo, operações de renderização ou implementação) que estão a ser executadas quando uma zona falha são atrasadas ou perdidas permanentemente. Durante uma indisponibilidade, o recurso do Cloud Deploy que acionou a compilação (um lançamento ou uma implementação) apresenta um estado de falha que indica que a operação subjacente falhou. Pode recriar o recurso para iniciar uma nova compilação nas zonas funcionais restantes. Por exemplo, crie uma nova implementação reimplementando o lançamento num destino.
Indisponibilidade regional: as operações do plano de controlo estão indisponíveis, tal como os dados do Cloud Deploy, até a região ser restaurada. Para ajudar a facilitar o restauro do serviço em caso de uma indisponibilidade regional, recomendamos que armazene o pipeline de entrega e as definições de segmentação no controlo de origem. Pode usar estes ficheiros de configuração para recriar os pipelines do Cloud Deploy numa região funcional. Durante uma indisponibilidade, os dados sobre lançamentos existentes são perdidos. Crie um novo lançamento para continuar a implementar software nos seus alvos.
Cloud DNS
O Cloud DNS é um serviço de Sistema de Nomes de Domínio (DNS) global, resiliente e de alto desempenho que publica os seus nomes de domínios no DNS global de forma rentável.
No caso de uma indisponibilidade zonal, o Cloud DNS continua a processar pedidos de outra zona na mesma região ou numa região diferente sem interrupção. As atualizações aos registos do Cloud DNS são replicadas de forma síncrona em todas as zonas da região onde são recebidas. Por conseguinte, não há perda de dados.
No caso de uma indisponibilidade regional, o Cloud DNS continua a publicar pedidos de outras regiões. É possível que as atualizações muito recentes aos registos do Cloud DNS estejam indisponíveis porque as atualizações são processadas primeiro numa única região antes de serem replicadas de forma assíncrona para outras regiões.
API Cloud Healthcare
A Cloud Healthcare API, um serviço para armazenar e gerir dados de cuidados de saúde, foi criada para oferecer elevada disponibilidade e proteção contra falhas zonais e regionais, consoante uma configuração escolhida.
Configuração regional: na sua configuração predefinida, a Cloud Healthcare API oferece proteção contra falhas zonais. O serviço é implementado em três zonas numa região, com os dados também triplicados em diferentes zonas na região. Em caso de falha zonal que afete a camada de serviço ou a camada de dados, as zonas restantes assumem o controlo sem interrupção. Com a configuração regional, se uma região inteira onde o serviço está localizado sofrer uma interrupção, o serviço fica indisponível até a região voltar a ficar online. No caso improvável de uma destruição física de uma região inteira, os dados armazenados nessa região são perdidos.
Configuração multirregional: na respetiva configuração multirregional, a Cloud Healthcare API é implementada em três zonas pertencentes a três regiões diferentes. Os dados também são replicados em três regiões. Isto protege contra a perda de serviço em caso de uma indisponibilidade de toda a região, uma vez que as regiões restantes assumiriam automaticamente o controlo. Os dados estruturados, como o FHIR, são replicados de forma síncrona em várias regiões, pelo que estão protegidos contra a perda de dados em caso de uma interrupção em toda a região. Os dados armazenados em contentores do Cloud Storage, como DICOM e Dictation ou objetos HL7v2/FHIR grandes, são replicados de forma assíncrona em várias regiões.
Cloud ID
Os serviços do Cloud Identity são distribuídos por várias regiões e usam o equilíbrio de carga dinâmico. O Cloud Identity não permite que os utilizadores selecionem um âmbito de recursos. Se uma zona ou uma região específica sofrer uma indisponibilidade, o tráfego é distribuído automaticamente para outras zonas ou regiões.
Os dados persistentes são espelhados em várias regiões com replicação síncrona na maioria dos casos. Por motivos relacionados com o desempenho, alguns sistemas, como as caches ou as alterações que afetam um grande número de entidades, são replicados de forma assíncrona nas regiões. Se a região principal na qual os dados mais atuais estão armazenados sofrer uma indisponibilidade, o Cloud Identity disponibiliza dados desatualizados de outra localização até que a região principal fique disponível.
Cloud Interconnect
O Cloud Interconnect oferece aos clientes acesso RFC 1918 a redes dos respetivos centros de dados nas instalações, através de cabos físicos ligados ao limite de peering da Google. Google Cloud
O Cloud Interconnect oferece aos clientes um SLA de 99,9% se aprovisionarem ligações a dois EADs (domínios de disponibilidade de limites) numa área metropolitana. Um SLA de 99,99% está disponível se o cliente aprovisionar ligações em dois EADs em duas áreas metropolitanas para duas regiões com encaminhamento global. Consulte a Descrição geral da topologia para aplicações não críticas e a Descrição geral da topologia para aplicações ao nível da produção para mais informações.
O Cloud Interconnect é independente da zona de computação e oferece alta disponibilidade sob a forma de EADs. Em caso de falha de um EAD, a sessão de BGP para esse EAD é interrompida e o tráfego é transferido para o outro EAD.
Em caso de falha regional, as sessões BGP para essa região são interrompidas e o tráfego é redirecionado para os recursos na região em funcionamento. Isto aplica-se quando o encaminhamento global está ativado.
Cloud Key Management Service
O Cloud Key Management Service (Cloud KMS) oferece uma gestão de recursos de chaves criptográficas escalável e altamente duradoura. O Cloud KMS armazena todos os respetivos dados e metadados em bases de dados do Spanner que oferecem uma elevada durabilidade e disponibilidade dos dados com replicação síncrona.
Os recursos do Cloud KMS podem ser criados numa única região, em várias regiões ou globalmente.
No caso de uma indisponibilidade zonal, o Cloud KMS continua a processar pedidos de outra zona na mesma região ou numa região diferente sem interrupção. Uma vez que os dados são replicados de forma síncrona, não há perda nem corrupção de dados. Quando a indisponibilidade da zona é resolvida, a redundância total é restaurada.
No caso de uma indisponibilidade regional, os recursos regionais nessa região ficam offline até a região ficar novamente disponível. Tenha em atenção que, mesmo numa região, são mantidas, pelo menos, 3 réplicas em zonas separadas. Quando é necessária uma maior disponibilidade, os recursos devem ser armazenados numa configuração multirregional ou global. As configurações multirregionais e globais foram concebidas para permanecerem disponíveis através de uma indisponibilidade regional, armazenando e fornecendo dados de forma georredundante em mais de uma região.
Cloud External Key Manager (Cloud EKM)
O Cloud External Key Manager está integrado com o Cloud Key Management Service para lhe permitir controlar e aceder a chaves externas através de parceiros externos suportados. Pode usar estas chaves externas para encriptar dados em repouso para utilização noutros Google Cloud serviços que suportam a integração de chaves de encriptação geridas pelo cliente (CMEK).
Indisponibilidade zonal: o Cloud External Key Manager é resiliente a indisponibilidades zonais devido à redundância fornecida por várias zonas numa região. Se ocorrer uma indisponibilidade zonal, o tráfego é reencaminhado para outras zonas na região. Enquanto o tráfego é reencaminhado, pode observar um aumento nos erros, mas o serviço continua disponível.
Indisponibilidade regional: o Cloud External Key Manager não está disponível durante uma indisponibilidade regional na região afetada. Não existe um mecanismo de alternativa que redirecione pedidos entre regiões. Recomendamos que os clientes usem várias regiões para executar os respetivos trabalhos.
O Cloud External Key Manager não armazena dados de clientes de forma persistente. Assim, não há perda de dados durante uma indisponibilidade regional no sistema Cloud External Key Manager. No entanto, o Cloud External Key Manager depende da disponibilidade de outros serviços, como o Cloud Key Management Service e fornecedores externos terceiros. Se esses sistemas falharem durante uma interrupção regional, pode perder dados. O RPO/RTO destes sistemas está fora do âmbito dos compromissos do Cloud External Key Manager.
Cloud Load Balancing
O Cloud Load Balancing é um serviço gerido totalmente distribuído e definido por software. Com o Cloud Load Balancing, um único endereço IP anycast pode servir como a interface para back-ends em regiões de todo o mundo. Não é baseado em hardware, pelo que não tem de gerir uma infraestrutura de equilíbrio de carga física. Os balanceadores de carga são um componente essencial da maioria das aplicações de elevada disponibilidade.
O Cloud Load Balancing oferece balanceadores de carga regionais e globais. Também oferece balanceamento de carga entre regiões, incluindo ativação pós-falha automática em várias regiões, que move o tráfego para back-ends de ativação pós-falha se os seus back-ends principais ficarem em mau estado.
Os balanceadores de carga globais são resilientes a interrupções zonais e regionais. Os balanceadores de carga regionais são resilientes a falhas zonais, mas são afetados por falhas na respetiva região. No entanto, em qualquer dos casos, é importante compreender que a resiliência da sua aplicação geral não depende apenas do tipo de equilibrador de carga que implementa, mas também da redundância dos seus back-ends.
Para mais informações sobre o Cloud Load Balancing e as respetivas funcionalidades, consulte a Vista geral do Cloud Load Balancing.
Cloud Logging
O Cloud Logging é composto por duas partes principais: o Logs Router e o armazenamento do Cloud Logging.
O encaminhador de registos processa eventos de registo de streaming e direciona os registos para o armazenamento do Cloud Storage, Pub/Sub, BigQuery ou Cloud Logging.
O armazenamento do Cloud Logging é um serviço para armazenar, consultar e gerir a conformidade dos registos. Suporta muitos utilizadores e fluxos de trabalho, incluindo desenvolvimento, conformidade, resolução de problemas e alertas proativos.
Logs Router e registos recebidos: durante uma indisponibilidade zonal, a API Cloud Logging encaminha os registos para outras zonas na região. Normalmente, os registos encaminhados pelo Logs Router para o Cloud Logging, o BigQuery ou o Pub/Sub são escritos no respetivo destino final assim que possível, enquanto os registos enviados para o Cloud Storage são armazenados em buffer e escritos em lotes por hora.
Entradas de registo: no caso de uma indisponibilidade zonal ou regional, as entradas de registo que foram armazenadas em buffer na zona ou região afetada e não escritas no destino de exportação tornam-se inacessíveis. As métricas baseadas em registos também são calculadas no Logs Router e estão sujeitas às mesmas restrições. Depois de entregues na localização de exportação de registos selecionada, os registos são replicados de acordo com o serviço de destino. Os registos exportados para o armazenamento do Cloud Logging são replicados de forma síncrona em duas zonas numa região. Para o comportamento de replicação de outros tipos de destinos, consulte a secção relevante neste artigo. Tenha em atenção que os registos exportados para o Cloud Storage são processados em lote e escritos a cada hora. Por conseguinte, recomendamos que use o armazenamento do Cloud Logging, o BigQuery ou o Pub/Sub para minimizar a quantidade de dados afetados por uma indisponibilidade.
Metadados de registo: os metadados, como a configuração de destino e exclusão, são armazenados globalmente, mas são colocados em cache regionalmente. Assim, em caso de indisponibilidade, as instâncias regionais do Log Router funcionam. As indisponibilidades de uma única região não têm impacto fora da região.
Cloud Monitoring
O Cloud Monitoring consiste numa variedade de funcionalidades interligadas, como painéis de controlo (integrados e definidos pelo utilizador), alertas e monitorização do tempo de atividade.
Toda a configuração do Cloud Monitoring, incluindo painéis de controlo, verificações de tempo de atividade e políticas de alerta, é definida globalmente. Todas as alterações são replicadas de forma síncrona em várias regiões. Por conseguinte, durante as interrupções zonais e regionais, as alterações de configuração bem-sucedidas são duradouras. Além disso, embora possam ocorrer falhas de leitura e escrita transitórias quando uma zona ou uma região falha inicialmente, o Cloud Monitoring redireciona os pedidos para zonas e regiões disponíveis. Nesta situação, pode tentar novamente as alterações de configuração com recuo exponencial.
Quando escreve métricas para um recurso específico, o Cloud Monitoring identifica primeiro a região em que o recurso reside. Em seguida, escreve três réplicas independentes dos dados das métricas na região. A gravação da métrica regional geral é devolvida como bem-sucedida assim que uma das três gravações for bem-sucedida. Não é garantido que as três réplicas estejam em zonas diferentes na região.
Zonal: durante uma indisponibilidade zonal, as escritas e as leituras de métricas ficam completamente indisponíveis para os recursos na zona afetada. Efetivamente, o Cloud Monitoring age como se a zona afetada não existisse.
Regional: durante uma indisponibilidade regional, as gravações e as leituras de métricas ficam completamente indisponíveis para os recursos na região afetada. Efetivamente, o Cloud Monitoring age como se a região afetada não existisse.
NAT na nuvem
O Cloud NAT (tradução de endereços de rede) é um serviço gerido definido por software distribuído que permite que determinados recursos sem endereços IP externos criem ligações de saída à Internet. Não se baseia em VMs ou dispositivos proxy. Em alternativa, o Cloud NAT configura o software Andromeda que alimenta a sua rede de nuvem privada virtual para que forneça tradução de endereços de rede de origem (NAT de origem ou SNAT) para VMs sem endereços IP externos. O Cloud NAT também fornece a tradução de endereços de rede de destino (NAT de destino ou DNAT) para pacotes de resposta de entrada estabelecidos.
Para mais informações sobre a funcionalidade do Cloud NAT, consulte a documentação.
Indisponibilidade zonal: o Cloud NAT é resiliente a falhas zonais porque o plano de controlo e o plano de dados de rede são redundantes em várias zonas numa região.
Interrupção regional: o Cloud NAT é um produto regional, pelo que não consegue resistir a uma falha regional.
Cloud Router
O Cloud Router é um serviço totalmente distribuído e gerido que usa o Border Gateway Protocol (BGP) para anunciar intervalos de endereços IP. Google Cloud Programa rotas dinâmicas com base nos anúncios BGP que recebe de um par. Em vez de um dispositivo ou um aparelho físico, cada Cloud Router consiste em tarefas de software que atuam como altifalantes e respondentes BGP.
No caso de uma indisponibilidade zonal, o Cloud Router com uma configuração de alta disponibilidade (HA) é resiliente a falhas zonais. Nesse caso, uma interface pode perder a conetividade, mas o tráfego é redirecionado para a outra interface através do encaminhamento dinâmico com o BGP.
No caso de uma indisponibilidade regional, o Cloud Router é um produto regional e, por isso, não consegue resistir a uma falha regional. Se os clientes tiverem ativado o modo de encaminhamento global, o encaminhamento entre a região com falhas e outras regiões pode ser afetado.
Cloud Run
O Cloud Run é um ambiente de computação sem estado em que os clientes podem executar o respetivo código em contentores na infraestrutura da Google. O Cloud Run é uma oferta regional, o que significa que os clientes podem escolher a região, mas não as zonas que compõem uma região. Os dados e o tráfego são automaticamente equilibrados em várias zonas de uma região. As instâncias de contentores são dimensionadas automaticamente para satisfazer o tráfego recebido e são equilibradas em termos de carga entre zonas, conforme necessário. Cada zona mantém um programador que fornece este ajuste de escala automático por zona. Também tem conhecimento da carga que outras zonas estão a receber e disponibiliza capacidade adicional na zona para permitir eventuais falhas zonais.
Se usar GPUs do Cloud Run, tem a opção de desativar a redundância zonal para o serviço e, em alternativa, usar a fiabilidade de melhor esforço em caso de uma interrupção zonal, a um custo inferior. Para ver detalhes, consulte as opções de redundância zonal da GPU.
Indisponibilidade zonal: o Cloud Run armazena metadados, bem como o contentor implementado. Estes dados são armazenados regionalmente e escritos de forma síncrona. A API Cloud Run Admin só devolve a chamada API quando os dados tiverem sido confirmados num quórum numa região. Uma vez que os dados são armazenados regionalmente, as operações do plano de dados também não são afetadas por falhas zonais. O tráfego é encaminhado para outras zonas em caso de falha zonal.
Indisponibilidade regional: os clientes escolhem a Google Cloud região na qual querem criar o respetivo serviço do Cloud Run. Os dados nunca são replicados em várias regiões. O tráfego de clientes nunca é encaminhado para uma região diferente pelo Cloud Run. No caso de uma falha regional, o Cloud Run volta a ficar disponível assim que a indisponibilidade for resolvida. Recomendamos que os clientes façam a implementação em várias regiões e usem o Cloud Load Balancing para alcançar uma maior disponibilidade, se quiserem.
Cloud Shell
O Cloud Shell oferece aos utilizadores Google Cloud acesso a instâncias do Compute Engine de utilizador único pré-configuradas para tarefas de integração, formação, desenvolvimento e operador.
O Cloud Shell não é adequado para executar cargas de trabalho de aplicações e destina-se, em alternativa, a exemplos de utilização educativos e de programação interativa. Tem limites de quota de tempo de execução por utilizador, é encerrada automaticamente após um curto período de inatividade e a instância só está acessível ao utilizador atribuído.
As instâncias do Compute Engine que suportam o serviço são recursos zonais. Por isso, em caso de falha de energia numa zona, o Cloud Shell de um utilizador fica indisponível.
Cloud Source Repositories
Os Cloud Source Repositories permitem aos utilizadores criar e gerir repositórios de código fonte privados. Este produto foi concebido com um modelo global, pelo que não precisa de o configurar para resiliência regional ou zonal.
Em alternativa, as operações git push nos Cloud Source Repositories replicam de forma síncrona a atualização do repositório de origem em várias zonas em várias regiões. Isto significa que o serviço é resiliente a interrupções em qualquer região.
Se uma zona ou uma região específica sofrer uma indisponibilidade, o tráfego é automaticamente distribuído para outras zonas ou regiões.
A funcionalidade de espelhamento automático de repositórios do GitHub ou Bitbucket pode ser afetada por problemas nesses produtos. Por exemplo, a sincronização é afetada se o GitHub ou o Bitbucket não puderem alertar os Cloud Source Repositories sobre novos commits ou se os Cloud Source Repositories não puderem obter conteúdo do repositório atualizado.
Spanner
O Spanner é uma base de dados escalável, de alta disponibilidade, com várias versões, replicada de forma síncrona e fortemente consistente com semântica relacional.
As instâncias regionais do Spanner replicam dados de forma síncrona em três zonas numa única região. Uma gravação numa instância do Spanner regional é enviada de forma síncrona a todas as 3 réplicas e confirmada ao cliente depois de, pelo menos, 2 réplicas (quorum maioritário de 2 em 3) terem confirmado a gravação. Isto torna o Spanner resiliente a uma falha de zona, uma vez que fornece acesso a todos os dados, uma vez que as escritas mais recentes foram mantidas e ainda é possível alcançar um quórum maioritário para escritas com 2 réplicas.
As instâncias multirregionais do Spanner incluem um quórum de escrita que replica os dados de forma síncrona em 5 zonas localizadas em três regiões (duas réplicas de leitura/escrita em cada uma das regiões principal predefinida e noutra região, e uma réplica na região de testemunho). Uma gravação numa instância do Spanner multirregional é confirmada depois de, pelo menos, 3 réplicas (quorum maioritário de 3 em 5) terem confirmado a gravação. Em caso de falha de uma zona ou de uma região, o Spanner tem acesso a todos os dados (incluindo as gravações mais recentes) e processa os pedidos de leitura/gravação, uma vez que os dados são mantidos em, pelo menos, 3 zonas em 2 regiões no momento em que a gravação é confirmada ao cliente.
Consulte a documentação da instância do Spanner para mais informações sobre estas configurações e a documentação sobre a replicação para mais informações sobre como funciona a replicação do Spanner.
Cloud SQL
O Cloud SQL é um serviço de base de dados relacional totalmente gerido para MySQL, PostgreSQL e SQL Server. O Cloud SQL usa máquinas virtuais do Compute Engine geridas para executar o software de base de dados. Oferece uma configuração de alta disponibilidade para redundância regional, protegendo a base de dados contra uma indisponibilidade de zona. É possível aprovisionar réplicas entre regiões para proteger a base de dados de uma interrupção na região. Uma vez que o produto também oferece uma opção zonal, que não é resiliente a uma indisponibilidade de uma zona ou de uma região, deve ter cuidado ao selecionar a configuração de alta disponibilidade, as réplicas entre regiões ou ambas.
Indisponibilidade zonal: a opção de alta disponibilidade cria uma instância de VM principal e de reserva em duas zonas separadas numa região. Durante o funcionamento normal, a instância de VM principal processa todos os pedidos, escrevendo ficheiros de base de dados num disco persistente regional, que é replicado de forma síncrona para as zonas principal e de reserva. Se uma indisponibilidade da zona afetar a instância principal, o Cloud SQL inicia uma comutação por falha durante a qual o disco persistente é anexado à VM de reserva e o tráfego é reencaminhado.
Durante este processo, a base de dados tem de ser inicializada, o que inclui o processamento de quaisquer transações escritas no registo de transações, mas não aplicadas à base de dados. O número e o tipo de transações não processadas podem aumentar o tempo de RTO. As escritas recentes elevadas podem originar um atraso de transações não processadas. O tempo de RTO é mais afetado por (a) uma atividade de escrita recente elevada e (b) alterações recentes aos esquemas da base de dados.
Por último, quando a indisponibilidade zonal for resolvida, pode acionar manualmente uma operação de retorno para retomar a publicação na zona principal.
Para mais detalhes sobre a opção de alta disponibilidade, consulte a documentação de alta disponibilidade do Cloud SQL.
Indisponibilidade regional: a opção réplica entre regiões protege a sua base de dados de indisponibilidades regionais através da criação de réplicas de leitura da sua instância principal noutras regiões. A replicação entre regiões usa a replicação assíncrona, que permite à instância principal confirmar transações antes de serem confirmadas nas réplicas. A diferença de tempo entre o momento em que uma transação é confirmada na instância principal e o momento em que é confirmada na réplica é conhecida como "atraso de replicação" (que pode ser monitorizado). Esta métrica reflete as transações que não foram enviadas da base de dados principal para as réplicas, bem como as transações que foram recebidas, mas não foram processadas pela réplica. As transações não enviadas para a réplica ficariam indisponíveis durante uma interrupção regional. As transações recebidas, mas não processadas pela réplica, afetam o tempo de recuperação, conforme descrito abaixo.
O Cloud SQL recomenda testar a sua carga de trabalho com uma configuração que inclua uma réplica para estabelecer um limite de "transações seguras por segundo (TPS)", que é o TPS sustentado mais elevado que não acumula atraso de replicação. Se a sua carga de trabalho exceder o limite de TPS seguro, o atraso na replicação acumula-se, afetando negativamente os valores de RPO e RTO. Como orientação geral, evite usar configurações de instâncias pequenas (<2 núcleos de CPU virtual, <100 GB de discos ou PD-HDD), que são suscetíveis a atrasos na replicação.
Em caso de indisponibilidade regional, tem de decidir se promove manualmente uma réplica de leitura. Esta é uma operação manual porque a promoção pode causar um cenário de cérebro dividido em que a réplica promovida aceita novas transações, apesar de ter ficado atrás da instância principal no momento da promoção. Isto pode causar problemas quando a indisponibilidade regional for resolvida e tiver de conciliar as transações que nunca foram propagadas das instâncias principais para as instâncias de réplica. Se isto for problemático para as suas necessidades, pode considerar um produto de base de dados de replicação síncrona entre regiões, como o Spanner.
Assim que é acionado pelo utilizador, o processo de promoção segue passos semelhantes aos da ativação de uma instância em espera na configuração de alta disponibilidade. Nesse processo, a réplica de leitura tem de processar o registo de transações que determina o tempo de recuperação total. Uma vez que não existe um balanceador de carga integrado envolvido na promoção de réplicas, redirecione manualmente as aplicações para a principal promovida.
Para mais detalhes sobre a opção de réplica entre regiões, consulte a documentação da réplica entre regiões do Cloud SQL.
Para mais informações sobre a recuperação de desastres do Cloud SQL, consulte o seguinte:
- Recuperação de desastres da base de dados do Cloud SQL para MySQL
- Recuperação de desastres da base de dados do Cloud SQL para PostgreSQL
- Recuperação após desastre da base de dados do Cloud SQL para SQL Server
Cloud Storage
O Cloud Storage oferece armazenamento de objetos unificado, escalável e altamente duradouro a nível global. Os contentores do Cloud Storage podem ser criados num de três tipos de localizações diferentes: numa única região, numa região dupla ou numa região múltipla num continente. Com os contentores regionais, os objetos são armazenados de forma redundante em zonas de disponibilidade numa única região. Por outro lado, os contentores de duas regiões e multirregionais são georredundantes. Isto significa que, depois de os dados recém-escritos serem replicados para, pelo menos, uma região remota, os objetos são armazenados de forma redundante em várias regiões. Esta abordagem oferece aos dados em contentores de duas regiões e multirregiões um conjunto mais amplo de proteções do que as que podem ser alcançadas com o armazenamento regional.
Os contentores regionais foram concebidos para serem resilientes em caso de indisponibilidade numa única zona de disponibilidade. Se uma zona sofrer uma indisponibilidade, os objetos na zona indisponível são servidos automaticamente e de forma transparente a partir de outro local na região. Os dados e os metadados são armazenados de forma redundante em várias zonas, a partir da gravação inicial. Não são perdidas gravações se uma zona ficar indisponível. No caso de uma interrupção regional, os contentores regionais nessa região ficam offline até que a região fique novamente disponível.
Se precisar de uma maior disponibilidade, pode armazenar dados numa configuração de duas regiões ou multirregional. Os contentores de duas regiões e multirregionais são contentores únicos (sem localizações principais e secundárias separadas), mas armazenam dados e metadados de forma redundante em várias regiões. No caso de uma indisponibilidade regional, o serviço não é interrompido. Pode considerar os contentores de região dupla e multirregião como ativos-ativos, uma vez que pode ler e escrever cargas de trabalho em mais do que uma região em simultâneo, enquanto o contentor permanece fortemente consistente. Isto pode ser especialmente atrativo para os clientes que querem dividir a respetiva carga de trabalho nas duas regiões como parte de uma arquitetura de recuperação de desastres.
As regiões duplas e as multirregiões são fortemente consistentes porque os metadados são sempre escritos de forma síncrona nas regiões. Esta abordagem permite que o serviço determine sempre qual é a versão mais recente de um objeto e de onde pode ser publicado, incluindo a partir de regiões remotas.
Os dados são replicados de forma assíncrona. Isto significa que existe um período de tempo de RPO em que os objetos recém-escritos começam protegidos como objetos regionais, com redundância nas zonas de disponibilidade numa única região. Em seguida, o serviço replica os objetos nessa janela de RPO para uma ou mais regiões remotas para os tornar georredundantes. Após a conclusão da replicação, os dados podem ser publicados de forma automática e transparente a partir de outra região em caso de indisponibilidade regional. A replicação turbo é uma funcionalidade premium disponível num contentor de duas regiões para obter uma janela de RPO mais pequena, que tem como alvo 100% dos objetos recém-escritos que são replicados e tornados georredundantes no prazo de 15 minutos.
O RPO é uma consideração importante, porque, durante uma indisponibilidade regional, os dados escritos recentemente na região afetada dentro do período do RPO podem ainda não ter sido replicados para outras regiões. Como resultado, esses dados podem não estar acessíveis durante a interrupção e podem ser perdidos em caso de destruição física dos dados na região afetada.
Cloud Translation
O Cloud Translation tem servidores de computação ativos em várias zonas e regiões. Também suporta a replicação de dados síncrona entre zonas nas regiões. Estas funcionalidades ajudam a tradução a alcançar a comutação por falha instantânea sem perda de dados para falhas zonais e sem exigir qualquer introdução ou ajuste por parte do cliente. No caso de uma falha regional, o Cloud Translation não está disponível.
Compute Engine
O Compute Engine é uma das opções de infraestrutura como serviço Google Cloud. Utiliza a infraestrutura mundial da Google para oferecer máquinas virtuais (e serviços relacionados) aos clientes.
As instâncias do Compute Engine são recursos zonais, pelo que, em caso de indisponibilidade de uma zona, as instâncias ficam indisponíveis por predefinição. O Compute Engine oferece grupos de instâncias geridas (GIGs) que podem dimensionar automaticamente VMs adicionais a partir de modelos de instâncias pré-configurados, tanto numa única zona como em várias zonas numa região. Os MIGs são ideais para aplicações que requerem resiliência à perda de zonas e são sem estado, mas requerem configuração e planeamento de recursos. É possível usar vários MIGs regionais para alcançar a resiliência a interrupções regionais para aplicações sem estado.
As aplicações que têm cargas de trabalho com estado podem continuar a usar os MIGs com estado, mas é preciso ter especial cuidado no planeamento da capacidade, uma vez que não são escaláveis horizontalmente. Em qualquer dos cenários, é importante configurar e testar corretamente os modelos de instâncias e os MIGs do Compute Engine antecipadamente para garantir capacidades de comutação em caso de falha para outras zonas. Consulte a secção Desenvolva as suas próprias arquiteturas de referência e guias acima para mais informações.
Arrendamento único
A funcionalidade de inquilino único permite-lhe ter acesso exclusivo a um nó de inquilino único, que é um servidor físico do Compute Engine dedicado ao alojamento exclusivo das VMs do seu projeto.
Os nós de inquilino único, como as instâncias do Compute Engine, são recursos zonais. No caso improvável de uma indisponibilidade zonal, não estão disponíveis. Para mitigar falhas zonais, pode criar um nó de inquilino único noutra zona. Uma vez que determinadas cargas de trabalho podem beneficiar de nós de inquilino único para fins de licenciamento ou contabilidade de CAPEX, deve planear uma estratégia de comutação por falha antecipadamente.
A recriação destes recursos numa localização diferente pode incorrer em custos de licenciamento adicionais ou violar os requisitos de contabilidade de CAPEX. Para orientações gerais, consulte Desenvolva as suas próprias arquiteturas de referência e guias.
Os nós de inquilino único são recursos zonais e não conseguem resistir a falhas regionais. Para dimensionar em várias zonas, use GIGs regionais.
Redes para o Compute Engine
Para obter informações sobre configurações de alta disponibilidade para ligações do Interconnect, consulte os seguintes documentos:
- Disponibilidade de 99,99% para a Interligação dedicada
- Disponibilidade de 99,99% para a Interligação de parceiro
Pode aprovisionar endereços IP externos no modo global ou regional, o que afeta a respetiva disponibilidade em caso de falha regional.
Resiliência do Cloud Load Balancing
Os balanceadores de carga são um componente essencial da maioria das aplicações de elevada disponibilidade. É importante compreender que a resiliência da sua aplicação geral depende não só do âmbito do equilibrador de carga que escolher (global ou regional), mas também da redundância dos seus serviços de back-end.
A tabela seguinte resume a resiliência do balanceador de carga com base na distribuição ou no âmbito do balanceador de carga.
| Âmbito do balanceador de carga | Arquitetura | Resiliente a falhas de energia zonais | Resiliente a falhas regionais |
|---|---|---|---|
| Global | Cada balanceador de carga é distribuído por todas as regiões | ||
| Entre regiões | Cada balanceador de carga é distribuído por várias regiões | ||
| Regional | Cada balanceador de carga é distribuído por várias zonas na região | Uma indisponibilidade numa determinada região afeta os balanceadores de carga regionais nessa região |
Para mais informações sobre como escolher um balanceador de carga, consulte a documentação do Cloud Load Balancing.
Connectivity Tests
Os testes de conetividade são uma ferramenta de diagnóstico que lhe permite verificar a conetividade entre pontos finais de rede. Analisa a sua configuração e, em alguns casos, realiza uma análise do plano de dados em direto entre os pontos finais. Um ponto final é uma origem ou um destino de tráfego de rede, como uma VM, um cluster do Google Kubernetes Engine (GKE), uma regra de encaminhamento do equilibrador de carga ou um endereço IP. Os testes de conetividade são uma ferramenta de diagnóstico sem componentes do plano de dados. Não processa nem gera tráfego de utilizadores.
Indisponibilidade zonal: os recursos dos testes de conetividade são globais. Pode geri-los e vê-los em caso de uma indisponibilidade zonal. Os recursos dos testes de conetividade são os resultados dos testes de configuração. Estes resultados podem incluir os dados de configuração dos recursos zonais (por exemplo, instâncias de VMs) numa zona afetada. Se houver uma indisponibilidade, os resultados da análise não são precisos porque a análise baseia-se em dados desatualizados de antes da indisponibilidade. Não confie nisso.
Indisponibilidade regional: numa indisponibilidade regional, continua a poder gerir e ver os recursos dos testes de conectividade. Os recursos dos testes de conetividade podem incluir dados de configuração de recursos regionais, como sub-redes, numa região afetada. Se houver uma indisponibilidade, os resultados da análise não são precisos porque a análise baseia-se em dados desatualizados de antes da indisponibilidade. Não confie nisso.
Container Registry
O Container Registry oferece uma implementação do Docker Registry alojada e escalável que armazena imagens de contentores Docker de forma segura e privada. O Container Registry implementa a API HTTP Docker Registry.
O Container Registry é um serviço global que armazena de forma síncrona metadados de imagens de forma redundante em várias zonas e regiões por predefinição. As imagens de contentores são armazenadas em contentores multirregionais do Cloud Storage. Com esta estratégia de armazenamento, o Container Registry oferece resiliência a falhas zonais em todos os casos e resiliência a falhas regionais para todos os dados que foram replicados de forma assíncrona para várias regiões pelo Cloud Storage.
Database Migration Service
O Database Migration Service é um serviço do Google Cloud totalmente gerido para migrar bases de dados de outros fornecedores de nuvem ou de centros de dados no local para o Google Cloud.
O serviço de migração de base de dados está arquitetado como um plano de controlo regional. O plano de controlo não depende de uma zona individual numa determinada região. Durante uma indisponibilidade zonal, mantém o acesso às APIs do serviço de migração de bases de dados, incluindo a capacidade de criar e gerir tarefas de migração. Durante uma indisponibilidade regional, perde o acesso aos recursos do serviço de migração de base de dados pertencentes a essa região até que a indisponibilidade seja resolvida.
O Database Migration Service depende da disponibilidade das bases de dados de origem e de destino que são usadas para o processo de migração. Se uma base de dados de origem ou de destino do serviço de migração de bases de dados estiver indisponível, as migrações deixam de progredir, mas não se perdem dados essenciais do cliente nem dados de tarefas. As tarefas de migração são retomadas quando as bases de dados de origem e de destino ficam novamente disponíveis.
Por exemplo, pode configurar uma base de dados do Cloud SQL de destino com a alta disponibilidade (HA) ativada para ter uma base de dados de destino resiliente para falhas zonais.
As migrações do Database Migration Service passam por duas fases:
- Captura completa: executa uma cópia completa dos dados da origem para o destino de acordo com a especificação da tarefa de migração.
- Captura de dados de alterações (CDC): replica as alterações incrementais da origem para o destino.
Indisponibilidade zonal: se ocorrer uma falha zonal durante qualquer uma destas fases, continua a poder aceder e gerir recursos no serviço de migração de bases de dados. A migração de dados é afetada da seguinte forma:
- Dump completo: a migração de dados falha. Tem de reiniciar a tarefa de migração assim que a base de dados de destino concluir a operação de ativação pós-falha.
- CDC: a migração de dados está em pausa. A tarefa de migração é retomada automaticamente assim que a base de dados de destino concluir a operação de comutação por falha.
Indisponibilidade regional: o serviço de migração de bases de dados não suporta recursos entre regiões e, por isso, não é resiliente a falhas regionais.
Dataflow
O Dataflow é um serviço de processamento de dados totalmente gerido e sem servidor para pipelines de streaming e em lote. Google CloudPor predefinição, um ponto final regional configura o conjunto de trabalhadores do Dataflow para usar todas as zonas disponíveis na região. A seleção de zonas é calculada para cada trabalhador no momento em que o trabalhador é criado, otimizando a aquisição de recursos e a utilização de reservas não utilizadas. Na configuração predefinida para tarefas do Dataflow, os dados intermédios são armazenados pelo serviço Dataflow e o estado da tarefa é armazenado no back-end. Se uma zona falhar, as tarefas do Dataflow podem continuar a ser executadas, porque os trabalhadores são recriados noutras zonas.
Aplicam-se as seguintes limitações:
- O posicionamento regional só é suportado para trabalhos que usam o Streaming Engine ou o Dataflow Shuffle. Os trabalhos que desativaram o Streaming Engine ou o Dataflow Shuffle não podem usar o posicionamento regional.
- O posicionamento regional aplica-se apenas a VMs. Não se aplica aos recursos relacionados com o Streaming Engine e a ordenação aleatória do Dataflow.
- As VMs não são replicadas em várias zonas. Se uma VM ficar indisponível, os respetivos itens de trabalho são considerados perdidos e são novamente processados por outra VM.
- Se ocorrer uma indisponibilidade de stock ao nível de uma região, o serviço Dataflow não pode criar mais VMs.
Arquitetar pipelines do Dataflow para alta disponibilidade
Pode executar vários pipelines de streaming em paralelo para o processamento de dados de alta disponibilidade. Por exemplo, pode executar duas tarefas de streaming paralelas em diferentes regiões. A execução de pipelines paralelos oferece redundância geográfica e tolerância a falhas para o processamento de dados. Ao considerar a disponibilidade geográfica das origens de dados e dos destinos, pode operar pipelines completos numa configuração multirregião de alta disponibilidade. Para mais informações, consulte a secção Elevada disponibilidade e redundância geográfica no artigo "Crie fluxos de trabalho de pipelines do Dataflow".
Em caso de uma interrupção de zona ou região, pode evitar a perda de dados reutilizando a mesma subscrição no tópico do Pub/Sub. Para garantir que os registos não são perdidos durante a mistura aleatória, o Dataflow usa a cópia de segurança a montante, o que significa que o trabalhador que envia os registos tenta novamente as RPCs até receber uma confirmação positiva de que o registo foi recebido e que os efeitos secundários do processamento do registo são comprometidos com o armazenamento persistente a jusante. O Dataflow também continua a tentar novamente os RPCs se o trabalhador que envia os registos ficar indisponível. As novas tentativas de RPCs garantem que cada registo é entregue exatamente uma vez. Para mais informações sobre a garantia de exatamente uma vez do Dataflow, consulte o artigo Exatamente uma vez no Dataflow.
Se o pipeline estiver a usar o agrupamento ou a janela temporal, pode usar a funcionalidade de procura do Pub/Sub ou a funcionalidade de repetição do Kafka após uma indisponibilidade zonal ou regional para voltar a processar os elementos de dados e chegar aos mesmos resultados de cálculo. Se a lógica empresarial usada pelo pipeline não depender de dados anteriores à indisponibilidade, a perda de dados das saídas do pipeline pode ser minimizada até 0 elementos. Se a lógica empresarial do pipeline depender de dados que foram processados antes da indisponibilidade (por exemplo, se forem usadas janelas deslizantes longas ou se uma janela de tempo global estiver a armazenar contadores em constante aumento), use instantâneos do Dataflow para guardar o estado do pipeline de streaming e iniciar uma nova versão da tarefa sem perder o estado.
Dataproc
O Dataproc oferece capacidades de processamento de dados por streaming e em lote. O Dataproc é arquitetado como um plano de controlo regional que permite aos utilizadores gerir clusters do Dataproc. O plano de controlo não depende de uma zona individual numa determinada região. Por conseguinte, durante uma indisponibilidade zonal, mantém o acesso às APIs Dataproc, incluindo a capacidade de criar novos clusters.
Pode criar clusters do Dataproc nos seguintes sistemas operativos:
Clusters do Dataproc no Compute Engine
Uma vez que um cluster do Dataproc no Compute Engine é um recurso zonal, uma interrupção zonal torna o cluster indisponível ou destrói o cluster. O Dataproc não cria automaticamente instantâneos do estado do cluster, pelo que uma interrupção de zona pode causar a perda de dados em processamento. O Dataproc não mantém os dados do utilizador no serviço. Os utilizadores podem configurar os respetivos pipelines para escrever resultados em muitas lojas de dados. Deve considerar a arquitetura da loja de dados e escolher um produto que ofereça a resiliência a desastres necessária.
Se uma zona sofrer uma indisponibilidade, pode optar por recriar uma nova instância do cluster noutra zona, selecionando uma zona diferente ou usando a funcionalidade de posicionamento automático no Dataproc para selecionar automaticamente uma zona disponível. Assim que o cluster estiver disponível, o tratamento de dados pode ser retomado. Também pode executar um cluster com o modo de alta disponibilidade ativado, o que reduz a probabilidade de uma indisponibilidade parcial da zona afetar um nó principal e, por conseguinte, todo o cluster.
Clusters do Dataproc no GKE
Os clusters do Dataproc no GKE podem ser zonais ou regionais.
Para mais informações sobre a arquitetura e as capacidades de DR dos clusters do GKE zonais e regionais, consulte a secção do Google Kubernetes Engine mais adiante neste documento.
Datastream
O Datastream é um serviço de replicação e captura de dados de alterações (CDC) sem servidor que lhe permite sincronizar dados de forma fiável e com uma latência mínima. O Datastream oferece replicação de dados de bases de dados operacionais para o BigQuery e o Cloud Storage. Além disso, oferece uma integração simplificada com modelos do Dataflow para criar fluxos de trabalho personalizados para carregar dados para uma vasta gama de destinos, como o Cloud SQL e o Spanner.
Indisponibilidade zonal: o Datastream é um serviço multizonal. Pode resistir a uma interrupção zonal completa e não planeada sem perda de dados nem disponibilidade. Se ocorrer uma falha zonal, continua a poder aceder e gerir os seus recursos no Datastream.
Interrupção regional: no caso de uma interrupção regional, o fluxo de dados fica novamente disponível assim que a interrupção for resolvida.
Document AI
O Document AI é uma plataforma de compreensão de documentos que extrai dados não estruturados de documentos e os transforma em dados estruturados, o que facilita a compreensão, a análise e o consumo. A IA Documentos é uma oferta regional. Os clientes podem escolher a região, mas não as zonas nessa região. Os dados e o tráfego são automaticamente equilibrados em várias zonas de uma região. Os servidores são dimensionados automaticamente para satisfazer o tráfego recebido e são equilibrados em termos de carga nas zonas, conforme necessário. Cada zona mantém um programador que fornece este ajuste de escala automático por zona. O programador também tem conhecimento da carga que outras zonas estão a receber e disponibiliza capacidade adicional na zona para permitir eventuais falhas zonais.
Indisponibilidade zonal: a IA Documentos armazena documentos do utilizador e dados da versão do processador. Estes dados são armazenados regionalmente e escritos de forma síncrona. Uma vez que os dados são armazenados regionalmente, as operações do plano de dados não são afetadas por falhas zonais. O tráfego é encaminhado automaticamente para outras zonas em caso de falha zonal, com um atraso com base no tempo que os serviços dependentes, como a Vertex AI, demoram a recuperar.
Indisponibilidade regional: os dados nunca são replicados entre regiões. Durante uma interrupção regional, o Document AI não vai fazer failover. Os clientes escolhem a região do Google Cloud na qual querem usar o Document AI. No entanto, esse tráfego de clientes nunca é encaminhado para outra região.
Validação de pontos finais
A validação de pontos finais permite que os administradores e os profissionais de operações de segurança criem um inventário de dispositivos que acedem aos dados de uma organização. A validação de pontos finais também oferece fidedignidade do dispositivo crítica e controlo de acesso baseado na segurança como parte da solução Chrome Enterprise Premium.
Use a validação de pontos finais quando quiser uma vista geral da postura de segurança dos dispositivos portáteis e computadores da sua organização. Quando a Validação de pontos finais é sincronizada com as ofertas do Chrome Enterprise Premium, a Validação de pontos finais ajuda a aplicar o controlo de acesso detalhado nos seus Google Cloud recursos.
A validação de pontos finais está disponível para o Google Cloud, Cloud ID, Google Workspace Business e Google Workspace Enterprise.
Eventarc
O Eventarc fornece eventos entregues de forma assíncrona de fornecedores Google (originais), apps de utilizadores (secundários) e software como serviço (terceiros) através de serviços fracamente acoplados que reagem a alterações de estado. Permite que os clientes configurem os respetivos destinos (por exemplo, uma instância do Cloud Run ou uma função do Cloud Run de 2.ª geração) para serem acionados quando ocorre um evento num serviço de fornecedor de eventos ou no código do cliente.
Indisponibilidade zonal: o Eventarc armazena metadados relacionados com acionadores. Estes dados são armazenados regionalmente e escritos de forma síncrona. A API Eventarc que cria e gere acionadores e canais só devolve a chamada API quando os dados foram comprometidos com um quórum numa região. Uma vez que os dados são armazenados regionalmente, as operações do plano de dados não são afetadas por falhas zonais. Em caso de falha zonal, o tráfego é encaminhado automaticamente para outras zonas. Os serviços do Eventarc para receber e entregar eventos de segunda e terceiros são replicados em várias zonas. Estes serviços são distribuídos regionalmente. Os pedidos para zonas indisponíveis são publicados automaticamente a partir de zonas disponíveis na região.
Indisponibilidade regional: os clientes escolhem a Google Cloud região na qual querem criar os respetivos acionadores do Eventarc. Os dados nunca são replicados entre regiões. O tráfego de clientes nunca é encaminhado pelo Eventarc para uma região diferente. No caso de uma falha regional, o Eventarc volta a ficar disponível assim que a indisponibilidade for resolvida. Para alcançar uma maior disponibilidade, recomendamos que os clientes implementem acionadores em várias regiões, se quiserem.
Tenha em conta o seguinte:
- Os serviços do Eventarc para receber e entregar eventos originais são fornecidos com base no melhor esforço e não são abrangidos pelo RTO/RPO.
- A entrega de eventos do Eventarc para serviços do Google Kubernetes Engine é fornecida com base no melhor esforço e não é abrangida pelo RTO/RPO.
Filestore
Os níveis Básico e Zonal são recursos zonais. Não são tolerantes a falhas da zona ou região implementada.
As instâncias do Filestore de nível regional são recursos regionais. O Filestore adota a política de consistência rigorosa exigida pelo NFS. Quando um cliente escreve dados, o Filestore não devolve uma confirmação até que a alteração seja persistida e replicada em duas zonas para que as leituras subsequentes devolvam os dados corretos.
Em caso de falha de uma zona, uma instância do nível regional continua a publicar dados de outras zonas e, entretanto, aceita novas gravações. As operações de leitura e escrita podem ter um desempenho degradado. A operação de escrita pode não ser replicada. A encriptação não é comprometida porque a chave é publicada a partir de outras zonas.
Recomendamos que os clientes criem cópias de segurança externas em caso de mais interrupções noutras zonas da mesma região. A cópia de segurança pode ser usada para restaurar a instância noutras regiões.
Firestore
O Firestore é uma base de dados flexível e escalável para desenvolvimento de apps para dispositivos móveis, Web e servidores do Firebase e Google Cloud. O Firestore oferece replicação de dados multirregional automática, garantias de consistência fortes, operações em lote atómicas e transações ACID.
O Firestore oferece localizações de região única e multirregionais aos clientes. O tráfego é automaticamente equilibrado em várias zonas de uma região.
As instâncias regionais do Firestore replicam dados de forma síncrona em, pelo menos, três zonas. No caso de falha zonal, as gravações podem continuar a ser confirmadas pelas duas (ou mais) réplicas restantes, e os dados confirmados são mantidos. O tráfego é encaminhado automaticamente para outras zonas. Uma localização regional oferece custos mais baixos, menor latência de escrita e colocação conjunta com outros Google Cloud recursos.
As instâncias multirregionais do Firestore replicam dados de forma síncrona em cinco zonas em três regiões (duas regiões de serviço e uma região de testemunho) e são robustas contra falhas zonais e regionais. Em caso de falha zonal ou regional, os dados comprometidos são mantidos. O tráfego é encaminhado automaticamente para as zonas/regiões de publicação, e os compromissos continuam a ser publicados por, pelo menos, três zonas nas duas regiões restantes. As multirregiões maximizam a disponibilidade e a durabilidade das bases de dados.
Firewall Insights
As estatísticas da firewall ajudam a compreender e otimizar as regras da firewall. Fornece estatísticas, recomendações e métricas sobre a forma como as regras de firewall estão a ser usadas. O Firewall Insights também usa a aprendizagem automática para prever a utilização futura de regras de firewall. As Estatísticas de firewall permitem-lhe tomar melhores decisões durante a otimização das regras de firewall. Por exemplo, as Estatísticas da firewall identificam regras que classifica como excessivamente permissivas. Pode usar estas informações para tornar a configuração da firewall mais rigorosa.
Indisponibilidade zonal: uma vez que os dados do Firewall Insights são replicados em várias zonas, não são afetados por uma indisponibilidade zonal, e o tráfego do cliente é encaminhado automaticamente para outras zonas.
Indisponibilidade regional: uma vez que os dados do Firewall Insights são replicados em várias regiões, não são afetados por uma indisponibilidade regional, e o tráfego do cliente é automaticamente encaminhado para outras regiões.
Fleet
As frotas permitem que os clientes geram vários clusters do Kubernetes como um grupo e permitem que os administradores da plataforma usem serviços de vários clusters. Por exemplo, as frotas permitem que os administradores apliquem políticas uniformes em todos os clusters ou configurem a entrada de vários clusters.
Quando regista um cluster do GKE numa frota, por predefinição, o cluster tem uma associação regional na mesma região. Quando regista um cluster não pertencente a um conjunto num frota, pode escolher qualquer região ou a localização global.Google Cloud A prática recomendada é escolher uma região próxima da localização física do cluster. Isto oferece uma latência ideal quando usa o gateway Connect para aceder ao cluster.
No caso de uma indisponibilidade zonal, as funcionalidades da frota não são afetadas, a menos que o cluster subjacente seja zonal e fique indisponível.
No caso de uma indisponibilidade regional, as funcionalidades da frota falham estaticamente para os clusters de membros na região. A mitigação de uma interrupção regional requer a implementação em várias regiões, conforme sugerido no artigo Criação de arquiteturas de recuperação de desastres para interrupções de infraestrutura na nuvem.
Google Cloud Armor
O Cloud Armor ajuda a proteger as suas implementações e aplicações de vários tipos de ameaças, incluindo ataques DDoS volumétricos e ataques de aplicações, como cross-site scripting e injeção de SQL. O Cloud Armor filtra o tráfego indesejado nos balanceadores de carga do Google Cloud e impede que esse tráfego entre na sua VPC e consuma recursos. Algumas destas proteções são automáticas. Algumas requerem que configure políticas de segurança e as anexe a serviços ou regiões de back-end. As políticas de segurança do Cloud Armor com âmbito global são aplicadas nos balanceadores de carga globais. As políticas de segurança com âmbito regional são aplicadas nos balanceadores de carga regionais.
Indisponibilidade zonal: em caso de indisponibilidade zonal, os balanceadores de carga do Google Cloud redirecionam o seu tráfego para outras zonas onde estão disponíveis instâncias de back-end em bom estado. A proteção do Cloud Armor está disponível imediatamente após a comutação por falha do tráfego, uma vez que as suas políticas de segurança do Cloud Armor são replicadas de forma síncrona para todas as zonas numa região.
Indisponibilidade regional: em caso de indisponibilidades regionais, os balanceadores de carga do Google Cloud globais redirecionam o seu tráfego para outras regiões onde estão disponíveis instâncias de back-end em bom estado. A proteção do Cloud Armor está disponível imediatamente após a comutação por falha do tráfego, porque as suas políticas de segurança globais do Cloud Armor são replicadas de forma síncrona para todas as regiões. Para assegurar a resiliência em caso de falhas regionais, tem de configurar políticas de segurança regionais do Cloud Armor para todas as suas regiões.
Google Kubernetes Engine
O Google Kubernetes Engine (GKE) oferece um serviço Kubernetes gerido através da simplificação da implementação de aplicações contentorizadas no Google Cloud. Pode escolher entre topologias de cluster regionais ou zonais.
- Quando cria um cluster zonal, o GKE aprovisiona uma máquina do plano de controlo na zona escolhida, bem como máquinas de trabalho (nós) na mesma zona.
- Para clusters regionais, o GKE aprovisiona três máquinas do plano de controlo em três zonas diferentes na região escolhida. Por predefinição, os nós também abrangem três zonas, embora possa optar por criar um cluster regional com nós aprovisionados apenas numa zona.
- Os clusters multizonais são semelhantes aos clusters zonais, pois incluem uma máquina principal, mas também oferecem a capacidade de abranger nós em várias zonas.
Indisponibilidade zonal: para evitar indisponibilidades zonais, use clusters regionais. O plano de controlo e os nós são distribuídos por três zonas diferentes numa região. Uma indisponibilidade de zona não afeta o plano de controlo nem os nós de trabalho implementados nas outras duas zonas.
Indisponibilidade regional: a mitigação de uma indisponibilidade regional requer a implementação em várias regiões. Embora atualmente não seja oferecida como uma capacidade de produto incorporada, a topologia multirregião é uma abordagem adotada por vários clientes do GKE atualmente e pode ser implementada manualmente. Pode criar vários clusters regionais para replicar as suas cargas de trabalho em várias regiões e controlar o tráfego para estes clusters através do acesso de entrada de vários clusters.
HA VPN
A VPN de HA (alta disponibilidade) é uma oferta de Cloud VPN resiliente que encripta em segurança o seu tráfego da sua nuvem privada no local, de outra nuvem privada virtual ou de outra rede de fornecedor de serviços na nuvem para a sua nuvem virtual privada (VPC) do Google Cloud.
Os gateways da VPN de HA têm duas interfaces, cada uma com um endereço IP de pools de endereços IP separados, divididos lógica e fisicamente em diferentes PoPs e clusters, para garantir uma redundância ideal.
Indisponibilidade zonal: no caso de uma indisponibilidade zonal, uma interface pode perder a conetividade, mas o tráfego é redirecionado para a outra interface através do encaminhamento dinâmico com o Protocolo de gateway exterior (BGP).
Indisponibilidade regional: no caso de uma indisponibilidade regional, ambas as interfaces podem perder a conetividade durante um breve período.
Gestão de identidade e de acesso
A gestão de identidade e de acesso (IAM) é responsável por todas as decisões de autorização
para ações em recursos na nuvem. O IAM confirma que uma política concede autorização para cada ação (no plano de dados) e processa atualizações dessas políticas através de uma chamada SetPolicy (no plano de controlo).
Todas as políticas de IAM são replicadas em várias zonas em todas as regiões, o que ajuda as operações do plano de dados da IAM a recuperar de falhas de outras regiões e a tolerar falhas de zonas em cada região. A resiliência do plano de dados da IAM contra falhas de zonas e falhas de regiões permite arquiteturas multirregionais e multizonais para alta disponibilidade.
As operações do plano de controlo da IAM podem depender da replicação entre regiões. Quando as chamadas SetPolicy são bem-sucedidas, os dados foram escritos em várias regiões, mas a propagação para outras regiões é eventualmente consistente.
O plano de controlo da IAM é resiliente a falhas de uma única região.
Identity-Aware Proxy
O Identity-Aware Proxy fornece acesso a aplicações alojadas no Google Cloud, noutras nuvens e nas instalações. As CNA são distribuídas regionalmente e as solicitações para zonas indisponíveis são automaticamente servidas a partir de outras zonas disponíveis na região.
As indisponibilidades regionais na IAP afetam o acesso às aplicações alojadas na região afetada. Recomendamos que faça a implementação em várias regiões e use o Cloud Load Balancing para alcançar uma maior disponibilidade e resiliência contra interrupções regionais.
Identity Platform
A Identity Platform permite que os clientes adicionem gestão de identidade e acesso personalizável de nível Google às respetivas apps. O Identity Platform é uma oferta global. Os clientes não podem escolher as regiões ou as zonas nas quais os respetivos dados são armazenados.
Indisponibilidade zonal: durante uma indisponibilidade zonal, o Identity Platform transfere os pedidos para a célula mais próxima seguinte. Todos os dados são guardados à escala global, pelo que não há perda de dados.
Indisponibilidade regional: durante uma indisponibilidade regional, os pedidos do Identity Platform para a região indisponível falham temporariamente enquanto o Identity Platform remove o tráfego da região afetada. Quando não existir mais tráfego para a região afetada, um serviço de equilíbrio de carga do servidor global encaminha os pedidos para a região disponível em bom estado mais próxima. Todos os dados são guardados globalmente, pelo que não há perda de dados.
Knative Serving
O Knative serving é um serviço global que permite aos clientes executar cargas de trabalho sem servidor em clusters de clientes. O objetivo é garantir que as cargas de trabalho de serviço do Knative são implementadas corretamente nos clusters dos clientes e que o estado de instalação do serviço do Knative se reflete no recurso da funcionalidade da API GKE Fleet. Este serviço só participa quando instala ou atualiza recursos de publicação do Knative em clusters de clientes. Não está envolvido na execução de cargas de trabalho de clusters. Os clusters de clientes pertencentes a projetos com o Knative serving ativado são distribuídos entre réplicas em várias regiões e zonas. Cada cluster é monitorizado por uma réplica.
Interrupção zonal e regional: os clusters monitorizados por réplicas alojadas numa localização em que está a ocorrer uma interrupção são redistribuídos automaticamente entre réplicas em bom estado noutras zonas e regiões. Enquanto esta reatribuição estiver em curso, pode haver um curto período em que alguns clusters não são monitorizados pelo Knative serving. Se, durante esse período, o utilizador decidir ativar as funcionalidades do Knative Serving no cluster, a instalação dos recursos do Knative Serving no cluster começa depois de o cluster se voltar a ligar a uma réplica de serviço do Knative Serving em bom estado.
Looker (Google Cloud Core)
O Looker (essencial para o Google Cloud) é uma plataforma de Business Intelligence que oferece aprovisionamento, configuração e gestão simplificados e otimizados de uma instância do Looker a partir da Google Cloud consola. O Looker (Google Cloud core) permite que os utilizadores explorem dados, criem painéis de controlo, configurem alertas e partilhem relatórios. Além disso, o Looker (núcleo do Google Cloud) oferece um IDE para modeladores de dados e funcionalidades de incorporação e API avançadas para programadores.
O Looker (Google Cloud core) é composto por instâncias isoladas regionalmente que replicam dados de forma síncrona em várias zonas da região. Certifique-se de que os recursos usados pela sua instância, como as origens de dados às quais o Looker (Google Cloud core) se liga, estão na mesma região em que a sua instância é executada.
Indisponibilidade zonal: as instâncias do Looker (Google Cloud core) armazenam metadados e os respetivos contentores implementados. Os dados são escritos de forma síncrona em todas as instâncias replicadas. Numa indisponibilidade zonal, as instâncias do Looker (essencial para o Google Cloud) continuam a servir a partir de outras zonas disponíveis na mesma região. Todas as transações ou chamadas API são devolvidas depois de os dados serem confirmados num quórum numa região. Se a replicação falhar, a transação não é confirmada e o utilizador é notificado acerca da falha. Se falhar mais do que uma zona, as transações também falham e o utilizador é notificado. O Looker (Google Cloud core) interrompe todas as agendas ou consultas que estão atualmente em execução. Tem de reagendá-los ou colocá-los novamente na fila após resolver a falha.
Indisponibilidade regional: as instâncias do Looker (Google Cloud core) na região afetada não estão disponíveis. O Looker (Google Cloud Core) interrompe todos os agendamentos ou consultas atualmente em execução. Tem de reagendar ou colocar novamente em fila as consultas após resolver a falha. Pode criar manualmente novas instâncias numa região diferente. Também pode recuperar as suas instâncias através do processo definido no artigo Importe ou exporte dados de uma instância do Looker (Google Cloud core). Recomendamos que configure um processo de exportação de dados periódico para copiar os recursos antecipadamente, no caso improvável de uma indisponibilidade regional.
Looker Studio
O Looker Studio é um produto de visualização de dados e inteligência empresarial. Permite que os clientes estabeleçam ligação aos respetivos dados armazenados noutros sistemas, criem relatórios e painéis de controlo com esses dados e partilhem os relatórios e painéis de controlo em toda a organização. O Looker Studio é um serviço global e não permite que os utilizadores selecionem um âmbito de recursos.
No caso de uma indisponibilidade zonal, o Looker Studio continua a publicar pedidos de outra zona na mesma região ou numa região diferente sem interrupção. Os recursos do utilizador são replicados de forma síncrona nas várias regiões. Por conseguinte, não há perda de dados.
No caso de uma indisponibilidade regional, o Looker Studio continua a processar pedidos de outra região sem interrupções. Os recursos do utilizador são replicados de forma síncrona nas regiões. Por conseguinte, não há perda de dados.
Memorystore for Memcached
O Memorystore for Memcached é a oferta de Memcached gerida da Google Cloud. O Memorystore for Memcached permite que os clientes criem clusters Memcached que podem ser usados como bases de dados de chave-valor de elevado débito para aplicações.
Os clusters do Memcached são regionais, com nós distribuídos por todas as zonas especificadas pelo cliente. No entanto, o Memcached não replica dados entre nós. Por conseguinte, uma falha zonal pode resultar na perda de dados, também descrita como uma limpeza parcial da cache. As instâncias do Memcached continuam a funcionar, mas têm menos nós. O serviço não inicia novos nós durante uma falha zonal. Os nós do Memcached em zonas não afetadas continuam a servir tráfego, embora a falha zonal resulte numa taxa de acertos da cache inferior até a zona ser recuperada.
Em caso de falha regional, os nós do Memcached não publicam tráfego. Nesse caso, os dados são perdidos, o que resulta numa limpeza total da cache. Para mitigar uma indisponibilidade regional, pode implementar uma arquitetura que implemente a aplicação e o Memorystore for Memcached em várias regiões.
Memorystore for Redis
O Memorystore for Redis é um serviço Redis totalmente gerido para o Google Cloud que pode reduzir o encargo da gestão de implementações complexas do Redis. Atualmente, oferece 2 níveis: nível básico e nível padrão. Para o nível básico, uma interrupção zonal ou regional causa a perda de dados, também conhecida como limpeza total da cache. Para o nível padrão, uma interrupção regional causa perda de dados. Uma interrupção zonal pode causar perda parcial de dados na instância do nível Standard devido à respetiva replicação assíncrona.
Indisponibilidade zonal: as instâncias do nível padrão replicam de forma assíncrona as operações do conjunto de dados do nó principal para o nó de réplica. Quando a indisponibilidade ocorre na zona do nó principal, o nó de réplica é promovido a nó principal. Durante a promoção, ocorre uma comutação por falha e o cliente Redis tem de voltar a ligar-se à instância. Depois de voltar a estabelecer ligação, as operações são retomadas. Para mais informações acerca da alta disponibilidade das instâncias do Memorystore for Redis no nível Standard, consulte o artigo Alta disponibilidade do Memorystore for Redis.
Se ativar as réplicas de leitura na sua instância de nível Standard e tiver apenas uma réplica, o ponto final de leitura não está disponível durante uma indisponibilidade zonal. Para mais informações sobre a recuperação de desastres de réplicas de leitura, consulte os modos de falha das réplicas de leitura.
Interrupção regional: o Memorystore for Redis é um produto regional, pelo que uma única instância não consegue resistir a uma falha regional. Pode agendar tarefas periódicas para exportar uma instância do Redis para um contentor do Cloud Storage numa região diferente. Quando ocorre uma indisponibilidade regional, pode restaurar a instância do Redis numa região diferente a partir do conjunto de dados que exportou.
Deteção de serviços em vários clusters e entrada em vários clusters
Os serviços em vários clusters (MCS) do GKE consistem em vários componentes. Os componentes incluem o hub do Google Kubernetes Engine (que orquestra vários clusters do Google Kubernetes Engine através de associações), os próprios clusters e os controladores do hub do GKE (entrada em vários clusters e deteção de serviços em vários clusters). Os controladores do hub orquestram a configuração do equilibrador de carga do Compute Engine através de back-ends em vários clusters.
No caso de uma indisponibilidade zonal, o serviço de deteção de serviços em vários clusters continua a processar pedidos de outra zona ou região. No caso de uma indisponibilidade regional, a deteção de serviços multicluster não faz failover.
No caso de uma indisponibilidade zonal para o Multi Cluster Ingress, se o cluster de configuração for zonal e estiver no âmbito da falha, o utilizador tem de fazer a comutação por falha manualmente. O plano de dados é estático em caso de falha e continua a publicar tráfego até o utilizador ter feito a comutação por falha. Para evitar a necessidade de uma comutação por falha manual, use um cluster regional para o cluster de configuração.
No caso de uma indisponibilidade regional, a entrada em vários clusters não faz failover. Os utilizadores têm de ter um plano de recuperação de desastres implementado para fazer manualmente a comutação por falha do cluster de configuração. Para mais informações, consulte os artigos Configurar o Multi Cluster Ingress e Configurar serviços de vários clusters.
Para mais informações sobre o GKE, consulte a secção "Google Kubernetes Engine" no artigo Arquitetar a recuperação de desastres para interrupções da infraestrutura na nuvem.
Analisador de rede
O analisador de rede monitoriza automaticamente as configurações da sua rede VPC e deteta configurações incorretas e configurações abaixo do ideal. Fornece estatísticas sobre a topologia de rede, as regras de firewall, as rotas, as dependências de configuração e a conetividade a serviços e aplicações. Identifica falhas de rede, fornece informações sobre a causa principal e sugere possíveis resoluções.
O analisador de rede é executado continuamente e aciona análises relevantes com base em atualizações de configuração quase em tempo real na sua rede. Se o analisador de rede detetar uma falha de rede, tenta correlacionar a falha com alterações de configuração recentes para identificar as causas principais. Sempre que possível, fornece recomendações para sugerir detalhes sobre como corrigir os problemas.
O analisador de rede é uma ferramenta de diagnóstico sem componentes do plano de dados. Não processa nem gera tráfego de utilizadores.
Indisponibilidade zonal: o serviço do Analisador de rede é replicado globalmente e a respetiva disponibilidade não é afetada por uma indisponibilidade zonal.
Se as estatísticas do analisador de rede contiverem configurações de uma zona com uma indisponibilidade, a qualidade dos dados é afetada. As informações da rede que se referem a configurações nessa zona ficam desatualizadas. Não confie em nenhuma estatística fornecida pelo analisador de rede durante interrupções.
Indisponibilidade regional: o serviço Network Analyzer é replicado globalmente e a respetiva disponibilidade não é afetada por uma indisponibilidade regional.
Se as estatísticas do analisador de rede contiverem configurações de uma região afetada por uma indisponibilidade, a qualidade dos dados é afetada. As informações da rede que se referem a configurações nessa região ficam desatualizadas. Não confie em nenhuma estatística fornecida pelo analisador de rede durante interrupções.
Network Topology
A topologia de rede é uma ferramenta de visualização que mostra a topologia da sua infraestrutura de rede. A vista de infraestrutura mostra redes de nuvem virtual privada (VPC), conectividade híbrida de e para as suas redes no local, conectividade a serviços geridos pela Google e as métricas associadas.
Indisponibilidade zonal: em caso de indisponibilidade zonal, os dados dessa zona não são apresentados na topologia de rede. Os dados de outras zonas não são afetados.
Indisponibilidade regional: em caso de indisponibilidade regional, os dados dessa região não são apresentados na topologia de rede. Os dados de outras regiões não são afetados.
Performance Dashboard
O Performance Dashboard dá-lhe visibilidade do desempenho de toda a Google Cloud rede, bem como do desempenho dos recursos do seu projeto.
Com estas capacidades de monitorização do desempenho, pode distinguir entre um problema na sua aplicação e um problema na Google Cloud rede Google Cloud subjacente. Também pode investigar problemas de desempenho da rede do histórico. O painel de controlo de desempenho também exporta dados para o Cloud Monitoring. Pode usar a monitorização para consultar os dados e aceder a informações adicionais.
Interrupção zonal:
Em caso de uma indisponibilidade zonal, os dados de latência e perda de pacotes para o tráfego da zona afetada não aparecem no Performance Dashboard. Os dados de latência e perda de pacotes para o tráfego de outras zonas não são afetados. Quando a indisponibilidade termina, os dados de latência e perda de pacotes são retomados.
Indisponibilidade regional:
Em caso de uma indisponibilidade regional, os dados de latência e perda de pacotes para o tráfego da região afetada não aparecem no Performance Dashboard. Os dados de latência e perda de pacotes para o tráfego de outras regiões não são afetados. Quando a indisponibilidade termina, os dados de latência e perda de pacotes são retomados.
Network Connectivity Center
O Network Connectivity Center é um produto de gestão da conetividade de rede que usa uma arquitetura de hub e spoke. Com esta arquitetura, um recurso de gestão central funciona como um hub e cada recurso de conetividade funciona como um spoke. Atualmente, os spokes híbridos suportam a VPN de HA, a interligação dedicada e de parceiros, bem como os dispositivos de router SD-WAN dos principais fornecedores externos. Com os raios híbridos do Network Connectivity Center, as empresas podem ligar Google Cloud cargas de trabalho e serviços a centros de dados no local, outras nuvens e os respetivos escritórios através do alcance global da Google Cloud rede.
Indisponibilidade zonal: um spoke híbrido do Network Connectivity Center com configuração de HA é resiliente a falhas zonais porque o plano de controlo e o plano de dados de rede são redundantes em várias zonas numa região.
Indisponibilidade regional: um spoke híbrido do Network Connectivity Center é um recurso regional e, por isso, não consegue resistir a uma falha regional.
Níveis de serviço de rede
Os níveis de serviço de rede permitem-lhe otimizar a conetividade entre sistemas na Internet e as suas instâncias do Google Cloud. Google Cloud Oferece dois níveis de serviço distintos: o nível Premium e o nível padrão. Com o nível Premium, um endereço IP de nível Premium de anycast anunciado globalmente pode funcionar como o front-end para back-ends regionais ou globais. Com o nível padrão, um endereço IP de nível padrão anunciado regionalmente pode servir como front-end para back-ends regionais. A resiliência geral de uma aplicação é influenciada pelo nível de serviço de rede e pela redundância dos back-ends aos quais está associada.
Indisponibilidade zonal: o nível Premium e o nível Standard oferecem resiliência contra indisponibilidades zonais quando associados a backends regionalmente redundantes. Quando ocorre uma interrupção zonal, o comportamento de comutação por falha para casos que usam back-ends regionalmente redundantes é determinado pelos próprios back-ends associados. Quando associado a back-ends zonais, o serviço volta a ficar disponível assim que a interrupção for resolvida.
Indisponibilidade regional: o nível Premium oferece resiliência contra indisponibilidades regionais quando está associado a back-ends redundantes a nível global. No nível Standard, todo o tráfego para a região afetada vai falhar. O tráfego para todas as outras regiões não é afetado. Quando ocorre uma indisponibilidade regional, o comportamento de comutação por falha para casos que usam o nível Premium com back-ends globalmente redundantes é determinado pelos próprios back-ends associados. Quando usar o nível Premium com back-ends regionais ou o nível Standard, o serviço volta a ficar disponível assim que a indisponibilidade for resolvida.
Serviço de políticas da organização
O serviço de políticas da organização oferece um controlo centralizado e programático sobre os Google Cloud recursos da sua organização. Enquanto administrador da política da organização, pode configurar restrições em toda a hierarquia de recursos.
Indisponibilidade zonal: todas as políticas da organização criadas pelo serviço de políticas da organização são replicadas de forma assíncrona em várias zonas em todas as regiões. Os dados da política da organização e as operações do plano de controlo são tolerantes a falhas de zonas em cada região.
Indisponibilidade regional: todas as políticas da organização criadas pelo serviço de políticas da organização são replicadas de forma assíncrona em várias regiões. As operações do plano de controlo da política da organização são escritas em várias regiões, e a propagação para outras regiões é consistente em minutos. O plano de controlo da política organizacional é resiliente a falhas de uma única região. As operações do plano de dados da política da organização podem recuperar de falhas noutras regiões, e a resiliência do plano de dados da política da organização contra falhas de zonas e falhas de regiões permite arquiteturas de várias regiões e várias zonas para alta disponibilidade.
Espelhamento de pacotes
A espelhagem de pacotes clona o tráfego de instâncias especificadas na sua rede da nuvem virtual privada (VPC) e encaminha os dados clonados para instâncias atrás de um equilibrador de carga interno regional para exame. A replicação de pacotes captura todo o tráfego e dados de pacotes, incluindo cargas úteis e cabeçalhos.
Para mais informações sobre a funcionalidade de espelhamento de pacotes, consulte a página de vista geral do espelhamento de pacotes.
Indisponibilidade zonal: configure o equilibrador de carga interno para que existam instâncias em várias zonas. Se ocorrer uma indisponibilidade zonal, a replicação de pacotes desvia os pacotes clonados para uma zona em bom estado.
Indisponibilidade regional: o Packet Mirroring é um produto regional. Se houver uma indisponibilidade regional, os pacotes na região afetada não são clonados.
Persistent Disk
Os discos persistentes estão disponíveis em configurações zonais e regionais.
Os discos persistentes zonais são alojados numa única zona. Se a zona do disco estiver indisponível, o disco persistente fica indisponível até a indisponibilidade da zona ser resolvida.
Os discos persistentes regionais oferecem replicação síncrona de dados entre duas zonas numa região. No caso de uma indisponibilidade na zona da sua máquina virtual, pode forçar a associação de um disco persistente regional a uma instância de VM na zona secundária do disco. Para realizar esta tarefa, tem de iniciar outra instância de VM nessa zona ou manter uma instância de VM em espera ativa nessa zona.
Para replicar dados de forma assíncrona num disco persistente em várias regiões, pode usar a replicação assíncrona de discos persistentes (replicação assíncrona de DP), que oferece replicação de armazenamento de blocos com RTO e RPO baixos para recuperação de desastres ativo-passivo entre regiões. No caso improvável de uma indisponibilidade regional, a replicação assíncrona de DP permite-lhe fazer failover dos seus dados para uma região secundária e reiniciar a sua carga de trabalho nessa região.
Personalized Service Health
O Personalized Service Health comunica interrupções de serviço relevantes para os seus Google Cloud projetos. Oferece vários canais e processos para ver ou integrar eventos disruptivos (incidentes, manutenção planeada) no seu processo de resposta a incidentes, incluindo o seguinte:
- Um painel de controlo na Google Cloud console
- Uma API de serviço
- Alertas configuráveis
- Registos gerados e enviados para o Cloud Logging
Indisponibilidade zonal: os dados são fornecidos a partir de uma base de dados global sem dependência de localizações específicas. Se ocorrer uma indisponibilidade zonal, o Service Health consegue processar pedidos e redirecionar automaticamente o tráfego para zonas na mesma região que ainda funcionam. O Service Health pode devolver chamadas API com êxito se conseguir obter dados de eventos da base de dados do Service Health.
Indisponibilidade regional: os dados são fornecidos a partir de uma base de dados global sem dependência de localizações específicas. Se existir uma indisponibilidade regional, o estado do serviço continua a poder publicar pedidos, mas pode ter um desempenho com capacidade reduzida. As falhas regionais nas localizações de registo podem afetar os utilizadores do estado de funcionamento do serviço que consomem registos ou notificações de alertas na nuvem.
Private Service Connect
O Private Service Connect é uma capacidade de Google Cloud rede que permite aos consumidores aceder a serviços geridos de forma privada a partir do interior da respetiva rede VPC. Da mesma forma, permite que os produtores de serviços geridos alojem estes serviços nas suas próprias redes VPC separadas e ofereçam uma ligação privada aos respetivos consumidores.
Pontos finais do Private Service Connect para serviços publicados
Um ponto final do Private Service Connect liga-se a serviços na rede VPC de produtores de serviços através de uma regra de encaminhamento do Private Service Connect. O produtor de serviços fornece um serviço através de conetividade privada a um consumidor de serviços, expondo uma única associação de serviços. Em seguida, o consumidor do serviço poderá atribuir um endereço IP virtual da respetiva VPC para esse serviço.
Indisponibilidade zonal: o tráfego do Private Service Connect que tem origem no tráfego de VMs gerado pelos pontos finais do cliente da VPC do consumidor continua a poder aceder aos serviços geridos expostos na rede VPC interna do produtor de serviços. Este acesso é possível porque o tráfego do Private Service Connect é transferido para back-ends de serviços mais saudáveis numa zona diferente.
Indisponibilidade regional: o Private Service Connect é um produto regional. Não é resiliente a falhas regionais. Os serviços geridos multirregionais podem alcançar uma elevada disponibilidade durante interrupções regionais configurando pontos finais do Private Service Connect em várias regiões.
Pontos finais do Private Service Connect para APIs Google
Um ponto final do Private Service Connect estabelece ligação às APIs Google através de uma regra de encaminhamento do Private Service Connect. Esta regra de encaminhamento permite que os clientes usem nomes de pontos finais personalizados com os respetivos endereços IP internos.
Indisponibilidade zonal: o tráfego do Private Service Connect dos pontos finais do cliente da VPC do consumidor ainda pode aceder às APIs Google, porque a conetividade entre a VM e o ponto final vai automaticamente mudar para outra zona funcional na mesma região. Os pedidos que já estão em curso quando ocorre uma indisponibilidade dependem do tempo limite de TCP e do comportamento de repetição do cliente para recuperação.
Consulte a recuperação do Compute Engine para ver mais detalhes.
Indisponibilidade regional: o Private Service Connect é um produto regional. Não é resiliente a falhas regionais. Os serviços geridos multirregionais podem alcançar uma elevada disponibilidade durante interrupções regionais configurando pontos finais do Private Service Connect em várias regiões.
Para mais informações sobre o Private Service Connect, consulte a secção "Pontos finais" em Tipos de Private Service Connect.
Pub/Sub
O Pub/Sub é um serviço de mensagens para integração de aplicações e análise de streams. Os tópicos do Pub/Sub são globais, o que significa que são visíveis e acessíveis a partir de qualquer Google Cloud localização. No entanto, qualquer mensagem específica é armazenada numa única região, mais próxima do publicador e permitida pela política de localização de recursos. Google Cloud Assim, um tópico pode ter mensagens armazenadas em diferentes regiões em todo o mundo Google Cloud. A política de armazenamento de mensagens do Pub/Sub pode restringir as regiões nas quais as mensagens são armazenadas.
Interrupção zonal: quando uma mensagem do Pub/Sub é publicada, é escrita de forma síncrona no armazenamento em, pelo menos, duas zonas na região. Por conseguinte, se uma única zona ficar indisponível, não existe qualquer impacto visível para o cliente.
Interrupção regional: durante uma interrupção regional, as mensagens armazenadas na região afetada ficam inacessíveis. Os publicadores e os subscritores que se ligariam à região afetada, através de um ponto final regional ou do ponto final global, não conseguem estabelecer ligação. Os publicadores e os subscritores que se ligam a outras regiões continuam a poder estabelecer ligação, e as mensagens disponíveis noutras regiões são entregues aos subscritores mais próximos da rede que tenham capacidade.
Se a sua aplicação depender da ordenação de mensagens, reveja as recomendações detalhadas da equipa do Pub/Sub. As garantias de ordenação de mensagens são fornecidas por região e podem ser interrompidas se usar um ponto final global.
reCAPTCHA
O reCAPTCHA é um serviço global que deteta atividade fraudulenta, spam e abuso. Não requer nem permite a configuração para resiliência regional ou zonal. As atualizações aos metadados de configuração são replicadas de forma assíncrona em cada região onde o reCAPTCHA é executado.
No caso de uma indisponibilidade zonal, o reCAPTCHA continua a processar pedidos de outra zona na mesma região ou numa região diferente sem interrupção.
No caso de uma indisponibilidade regional, o reCAPTCHA continua a publicar pedidos de outra região sem interrupção.
Secret Manager
O Secret Manager é um produto de gestão de informações secretas e credenciais paraGoogle Cloud. Com o Secret Manager, pode auditar e restringir facilmente o acesso a segredos, encriptar segredos em repouso e garantir que as informações confidenciais estão protegidas Google Cloud.
Normalmente, os recursos do Secret Manager são criados com a política de replicação automática (recomendada), o que faz com que sejam replicados globalmente. Se a sua organização tiver políticas que não permitam a replicação global de dados secretos, os recursos do Secret Manager podem ser criados com políticas de replicação geridas pelo utilizador, nas quais são escolhidas uma ou mais regiões para replicar um segredo.
Indisponibilidade zonal: no caso de indisponibilidade zonal, o Secret Manager continua a publicar pedidos de outra zona na mesma região ou numa região diferente sem interrupção. Em cada região, o Secret Manager mantém sempre, pelo menos, 2 réplicas em zonas separadas (na maioria das regiões, 3 réplicas). Quando a indisponibilidade da zona é resolvida, a redundância total é restaurada.
Indisponibilidade regional: no caso de uma indisponibilidade regional, o Secret Manager continua a processar pedidos de outra região sem interrupções, partindo do princípio de que os dados foram replicados para mais do que uma região (através da replicação automática ou da replicação gerida pelo utilizador para mais do que uma região). Quando a indisponibilidade da região for resolvida, a redundância total é restaurada.
Security Command Center
O Security Command Center é a plataforma de gestão de riscos global em tempo real para o Google Cloud. Consiste em dois componentes principais: detetores e resultados.
Os detetores são afetados por interrupções regionais e zonais, de formas diferentes. Durante uma indisponibilidade regional, os detetores não podem gerar novas conclusões para recursos regionais porque os recursos que devem analisar não estão disponíveis.
Durante uma indisponibilidade zonal, os detetores podem demorar vários minutos a horas a retomar o funcionamento normal. O Security Command Center não perde dados de resultados. Também não gera novos dados de resultados para recursos indisponíveis. No pior cenário, os agentes de deteção de ameaças de contentores podem ficar sem espaço no buffer enquanto se ligam a uma célula saudável, o que pode levar à perda de deteções.
As conclusões são resilientes a interrupções regionais e zonais porque são replicadas de forma síncrona entre regiões.
Proteção de dados confidenciais (incluindo a API DLP)
A proteção de dados confidenciais oferece serviços de classificação, criação de perfis, desidentificação, tokenização e análise de riscos de privacidade de dados confidenciais. Funciona de forma síncrona nos dados enviados nos corpos dos pedidos ou de forma assíncrona nos dados já presentes nos sistemas de armazenamento na nuvem. A proteção de dados confidenciais pode ser invocada através dos pontos finais globais ou específicos da região.
Ponto final global: o serviço foi concebido para ser resiliente a falhas regionais e zonais. Se o serviço estiver sobrecarregado enquanto ocorre uma falha, os dados
enviados para o método hybridInspect do serviço podem ser perdidos.
Para criar uma arquitetura resistente a falhas, inclua lógica para examinar a descoberta de pré-falha mais recente produzida pelo método hybridInspect. Em caso de indisponibilidade, os dados enviados para o método podem ser perdidos, mas não mais do que os últimos 10 minutos antes do evento de falha. Se existirem
descobertas mais recentes do que 10 minutos antes do início da indisponibilidade, significa que os
dados que resultaram nessa descoberta não foram perdidos. Nesse caso, não é necessário reproduzir os dados anteriores à indicação de tempo da descoberta, mesmo que estejam dentro do intervalo de 10 minutos.
Ponto final regional: os pontos finais regionais não são resilientes a falhas regionais. Se for necessária resiliência contra uma falha regional, considere a comutação por falha para outras regiões. As caraterísticas de falha ao nível da zona são as mesmas que acima.
Utilização do serviço
A API Service Usage é um serviço de infraestrutura da Google Cloud Google Cloud Platform que lhe permite listar e gerir APIs e serviços nos seus projetos Google Cloud . Pode listar e gerir APIs e serviços fornecidos pela Google Google Cloude produtores terceiros. A API Service Usage é um serviço global e resiliente a interrupções zonais e regionais. No caso de uma indisponibilidade zonal ou regional, a API Service Usage continua a publicar pedidos de outra zona em diferentes regiões.
Para mais informações sobre a utilização do serviço, consulte a documentação de utilização do serviço.
Conversão de voz em texto
A conversão de voz em texto permite-lhe converter áudio de voz em texto através de técnicas de aprendizagem automática, como modelos de redes neurais. O áudio é enviado em tempo real a partir do microfone de uma aplicação ou é processado como um lote de ficheiros de áudio.
Interrupção zonal:
API Speech-to-Text v1: durante uma indisponibilidade zonal, a versão 1 da API Speech-to-Text continua a processar pedidos de outra zona na mesma região sem interrupção. No entanto, todas as tarefas que estão atualmente a ser executadas na zona com falhas são perdidas. Os utilizadores têm de repetir as tarefas com falhas, que são encaminhadas automaticamente para uma zona disponível.
API Speech-to-Text v2: durante uma indisponibilidade zonal, a versão 2 da API Speech-to-Text continua a publicar pedidos de outra zona na mesma região. No entanto, todas as tarefas que estão atualmente a ser executadas na zona com falhas são perdidas. Os utilizadores têm de repetir as tarefas com falhas, que são encaminhadas automaticamente para uma zona disponível. A API Speech-to-Text só devolve a chamada da API quando os dados são confirmados num quórum numa região. Em algumas regiões, os aceleradores de IA (TPUs) só estão disponíveis numa zona. Nesse caso, uma interrupção nessa zona faz com que o reconhecimento de voz falhe, mas não há perda de dados.
Indisponibilidade regional:
API Speech-to-Text v1: a API Speech-to-Text versão 1 não é afetada por falhas regionais porque é um serviço global de várias regiões. O serviço continua a responder a pedidos de outra região sem interrupções. No entanto, as tarefas que estão atualmente a ser executadas na região com falhas são perdidas. Os utilizadores têm de repetir essas tarefas com falhas, que são encaminhadas automaticamente para uma região disponível.
Speech-to-Text API v2:
Na versão 2 da API Speech-to-Text multirregião, o serviço continua a processar pedidos de outra zona na mesma região sem interrupções.
Na versão 2 da API Speech-to-Text de região única, o serviço limita a execução da tarefa à região pedida. A versão 2 da API Speech-to-Text não encaminha o tráfego para uma região diferente e os dados não são replicados para uma região diferente. Durante uma falha regional, a versão 2 da API Speech-to-Text não está disponível nessa região. No entanto, volta a ficar disponível quando a indisponibilidade é resolvida.
Serviço de transferência de armazenamento
O Serviço de transferência de armazenamento gere transferências de dados de várias origens na nuvem para o Cloud Storage, bem como para, a partir de e entre sistemas de ficheiros.
A API Storage Transfer Service é um recurso global.
O Serviço de transferência de armazenamento depende da disponibilidade da origem e do destino de uma transferência. Se uma origem ou um destino de transferência não estiver disponível, as transferências deixam de progredir. No entanto, não se perdem dados essenciais de clientes nem dados de tarefas. As transferências são retomadas quando a origem e o destino ficarem novamente disponíveis.
Pode usar o Serviço de transferência de dados com ou sem um agente, da seguinte forma:
As transferências sem agente usam trabalhadores regionais para orquestrar tarefas de transferência.
As transferências baseadas em agentes usam agentes de software instalados na sua infraestrutura. As transferências baseadas em agentes dependem da disponibilidade dos agentes de transferência e da capacidade dos agentes de estabelecer ligação ao sistema de ficheiros. Quando estiver a decidir onde instalar os agentes de transferência, considere a disponibilidade do sistema de ficheiros. Por exemplo, se estiver a executar agentes de transferência em várias VMs do Compute Engine para transferir dados para uma instância do Filestore de nível empresarial (um recurso regional), deve considerar localizar as VMs em zonas diferentes na região da instância do Filestore.
Se os agentes ficarem indisponíveis ou se a respetiva ligação ao sistema de ficheiros for interrompida, as transferências deixam de progredir, mas não são perdidos dados. Se todos os processos do agente forem terminados, a tarefa de transferência é pausada até serem adicionados novos agentes ao conjunto de agentes da transferência.
Durante uma indisponibilidade, o comportamento do Serviço de transferência de armazenamento é o seguinte:
Indisponibilidade zonal: durante uma indisponibilidade zonal, as APIs do Serviço de transferência de armazenamento permanecem disponíveis, e pode continuar a criar tarefas de transferência. Os dados continuam a ser transferidos.
Indisponibilidade regional: durante uma indisponibilidade regional, as APIs do Serviço de transferência de armazenamento permanecem disponíveis, e pode continuar a criar tarefas de transferência. Se os trabalhadores da sua transferência estiverem localizados na região afetada, a transferência de dados é interrompida até que a região fique novamente disponível e a transferência seja retomada automaticamente.
Vertex ML Metadata
O Vertex ML Metadata permite-lhe registar os metadados e os artefactos produzidos pelo seu sistema de ML e consultar esses metadados para ajudar a analisar, depurar e auditar o desempenho do seu sistema de ML ou os artefactos que produz.
Indisponibilidade zonal: na configuração predefinida, o Vertex ML Metadata oferece proteção contra falhas zonais. O serviço é implementado em várias zonas em cada região, com dados replicados de forma síncrona em diferentes zonas em cada região. Em caso de falha zonal, as zonas restantes assumem o controlo com uma interrupção mínima.
Indisponibilidade regional: o Vertex ML Metadata é um serviço regionalizado. No caso de uma interrupção regional, o Vertex ML Metadata não vai fazer failover para outra região.
Vertex AI Batch Prediction
A previsão em lote permite que os utilizadores executem a previsão em lote em modelos de IA/AA na infraestrutura da Google. A previsão em lote é uma oferta regional. Os clientes podem escolher a região na qual executam tarefas, mas não as zonas específicas nessa região. O serviço de previsão em lote equilibra automaticamente a carga da tarefa em diferentes zonas na região escolhida.
Indisponibilidade zonal: a previsão em lote armazena metadados para tarefas de previsão em lote numa região. Os dados são escritos de forma síncrona em várias zonas nessa região. Numa indisponibilidade zonal, a previsão em lote perde parcialmente os trabalhadores que executam tarefas, mas adiciona-os automaticamente noutras zonas disponíveis. Se várias novas tentativas de previsão em lote falharem, a IU apresenta o estado da tarefa como falhou na IU e nos pedidos de chamadas da API. Os pedidos subsequentes dos utilizadores para executar a tarefa são encaminhados para zonas disponíveis.
Indisponibilidade regional: os clientes escolhem a Google Cloud região na qual querem executar as respetivas tarefas de previsão em lote. Os dados nunca são replicados em várias regiões. A previsão em lote limita a execução da tarefa à região pedida e nunca encaminha pedidos de previsão para uma região diferente. Quando ocorre uma falha regional, a previsão em lote fica indisponível nessa região. Fica novamente disponível quando a indisponibilidade for resolvida. Recomendamos que os clientes usem várias regiões para executar os respetivos trabalhos. Em caso de uma indisponibilidade regional, encaminhe as tarefas para uma região disponível diferente.
Registo de modelos Vertex AI
O Registo de modelos do Vertex AI permite que os utilizadores simplifiquem a gestão, a governação e a implementação de modelos de ML num repositório central. O Registo de modelos da Vertex AI é uma oferta regional com alta disponibilidade e oferece proteção contra interrupções zonais.
Indisponibilidade zonal: o Registo de modelos Vertex AI oferece proteção contra indisponibilidades zonais. O serviço é implementado em três zonas em cada região, com dados replicados de forma síncrona em diferentes zonas na região. Se uma zona falhar, as zonas restantes assumem o controlo sem perda de dados e com uma interrupção mínima do serviço.
Indisponibilidade regional: o Registo de modelos Vertex AI é um serviço regionalizado. Se uma região falhar, o Model Registry não faz failover.
Vertex AI Online prediction
A previsão online permite que os utilizadores implementem modelos de IA/AA no Google Cloud. A previsão online é uma oferta regional. Os clientes podem escolher a região onde implementam os respetivos modelos, mas não as zonas específicas nessa região. O serviço de previsão equilibra automaticamente a carga de trabalho em diferentes zonas na região selecionada.
Indisponibilidade zonal: a previsão online não armazena conteúdo do cliente. Uma indisponibilidade zonal leva à falha da execução do pedido de previsão atual. A previsão online pode ou não tentar novamente o pedido de previsão automaticamente, consoante o tipo de ponto final usado. Especificamente, um ponto final público tenta novamente automaticamente, enquanto o ponto final privado não o faz. Para ajudar a processar falhas e melhorar a resiliência, incorpore a lógica de repetição com retirada exponencial no seu código.
Indisponibilidade regional: os clientes escolhem a Google Cloud região na qual querem executar os respetivos modelos de IA/ML e serviços de previsão online. Os dados nunca são replicados entre regiões. A previsão online limita a execução do modelo de IA/ML à região pedida e nunca encaminha pedidos de previsão para uma região diferente. Quando ocorre uma falha regional, o serviço de previsão online fica indisponível nessa região. Fica novamente disponível quando a indisponibilidade for resolvida. Recomendamos que os clientes usem várias regiões para executar os respetivos modelos de IA/ML. Em caso de indisponibilidade regional, direcione o tráfego para uma região diferente disponível.
Vertex AI Pipelines
O Vertex AI Pipelines é um serviço do Vertex AI que lhe permite automatizar, monitorizar e controlar os seus fluxos de trabalho de aprendizagem automática (ML) sem servidor. Os Vertex AI Pipelines foram criados para oferecer alta disponibilidade e proteção contra falhas zonais.
Indisponibilidade zonal: na configuração predefinida, o Vertex AI Pipelines oferece proteção contra falhas zonais. O serviço é implementado em várias zonas em cada região, com dados replicados de forma síncrona em diferentes zonas na região. Em caso de falha zonal, as zonas restantes assumem o controlo com uma interrupção mínima.
Interrupção regional: o Vertex AI Pipelines é um serviço regionalizado. No caso de uma indisponibilidade regional, os pipelines do Vertex AI não mudam para outra região. Se ocorrer uma indisponibilidade regional, recomendamos que execute os trabalhos de pipeline numa região de cópia de segurança.
Vertex AI Search
O Vertex AI Search é uma solução de pesquisa personalizável com funcionalidades de IA generativa e conformidade empresarial nativa. O Vertex AI Search é implementado e replicado automaticamente em várias regiões dentro do Google Cloud. Pode configurar onde os dados são armazenados escolhendo uma multirregião suportada, como: global, EUA ou UE.
Indisponibilidade zonal e regional: UserEvents carregados para o Vertex AI Search podem não ser recuperáveis devido ao atraso na replicação assíncrona. Outros dados e serviços fornecidos pela
Pesquisa da Vertex AI permanecem disponíveis devido à
comutação por falha automática e à replicação de dados síncrona.
Vertex AI Training
O Vertex AI Training oferece aos utilizadores a capacidade de executar tarefas de preparação personalizadas na infraestrutura da Google. O Vertex AI Training é uma oferta regional, o que significa que os clientes podem escolher a região para executar as respetivas tarefas de preparação. No entanto, os clientes não podem escolher as zonas específicas nessa região. O serviço de preparação pode equilibrar automaticamente a carga da execução da tarefa em diferentes zonas na região.
Indisponibilidade zonal: o Vertex AI Training armazena metadados para a tarefa de preparação personalizada. Estes dados são armazenados regionalmente e escritos de forma síncrona. A chamada da API Vertex AI Training só é devolvida quando estes metadados são confirmados num quórum numa região. A tarefa de preparação pode ser executada numa zona específica. Uma indisponibilidade zonal leva à falha da execução da tarefa atual. Se for o caso, o serviço tenta novamente a tarefa automaticamente encaminhando-a para outra zona. Se várias tentativas falharem, o estado da tarefa é atualizado para falhou. Os pedidos subsequentes dos utilizadores para executar a tarefa são encaminhados para uma zona disponível.
Indisponibilidade regional: os clientes escolhem a Google Cloud região na qual querem executar as respetivas tarefas de preparação. Os dados nunca são replicados entre regiões. O Vertex AI Training limita a execução da tarefa à região pedida e nunca encaminha tarefas de preparação para uma região diferente. No caso de uma falha regional, o serviço Vertex AI Training fica indisponível nessa região e volta a ficar disponível quando a indisponibilidade for resolvida. Recomendamos que os clientes usem várias regiões para executar os respetivos trabalhos e, em caso de uma interrupção regional, direcionem os trabalhos para uma região diferente que esteja disponível.
Nuvem virtual privada (VPC)
A VPC é um serviço global que fornece conetividade de rede a recursos (por exemplo, VMs). No entanto, as falhas são zonais. Em caso de falha zonal, os recursos nessa zona ficam indisponíveis. Da mesma forma, se uma região falhar, apenas o tráfego de e para a região com falhas é afetado. A conetividade das regiões saudáveis não é afetada.
Indisponibilidade zonal: se uma rede VPC abranger várias zonas e uma zona falhar, a rede VPC continua a estar em bom estado para as zonas em bom estado. O tráfego de rede entre recursos em zonas em bom estado de funcionamento continua a funcionar normalmente durante a falha. Uma falha zonal afeta apenas o tráfego de rede para e dos recursos na zona com falhas. Para mitigar o impacto das falhas zonais, recomendamos que não crie todos os recursos numa única zona. Em alternativa, quando criar recursos, distribua-os por várias zonas.
Interrupção regional: se uma rede VPC abranger várias regiões e uma região falhar, a rede VPC continua a funcionar corretamente para as regiões em bom estado. O tráfego de rede entre recursos em regiões em bom estado de funcionamento continua a funcionar normalmente durante a falha. Uma falha regional afeta apenas o tráfego de rede para e a partir de recursos na região com falhas. Para mitigar o impacto das falhas regionais, recomendamos que distribua os recursos por várias regiões.
VPC Service Controls
O VPC Service Controls é um serviço regional. Com os VPC Service Controls, as equipas de segurança empresariais podem definir controlos de perímetro detalhados e aplicar essa postura de segurança em vários Google Cloud serviços e projetos. As políticas de clientes são replicadas regionalmente.
Indisponibilidade zonal: os VPC Service Controls continuam a processar pedidos de outra zona na mesma região sem interrupções.
Indisponibilidade regional: as APIs configuradas para a aplicação da política de VPC Service Controls na região afetada estão indisponíveis até que a região fique novamente disponível. Recomendamos que os clientes implementem serviços aplicados do VPC Service Controls em várias regiões se quiserem uma maior disponibilidade.
Workflows
O Workflows é um produto de orquestração que permite aos clientes: Google Cloud
- Implementar e executar fluxos de trabalho que ligam outros serviços existentes através de HTTP,
- Automatizar processos, incluindo a espera por respostas HTTP com novas tentativas automáticas durante um período máximo de um ano, e
- Implementar processos em tempo real com execuções baseadas em eventos e de baixa latência.
Um cliente do Workflows pode implementar fluxos de trabalho que descrevem a lógica empresarial que quer executar e, em seguida, executar os fluxos de trabalho diretamente com a API ou com acionadores orientados por eventos (atualmente, limitados ao Pub/Sub ou ao Eventarc). O fluxo de trabalho em execução pode manipular variáveis, fazer chamadas HTTP e armazenar os resultados ou definir callbacks e aguardar a retoma por outro serviço.
Indisponibilidade zonal: o código-fonte dos fluxos de trabalho não é afetado por indisponibilidades zonais. Os fluxos de trabalho armazenam o código fonte dos fluxos de trabalho, juntamente com os valores das variáveis e as respostas HTTP recebidas pelos fluxos de trabalho em execução. O código fonte é armazenado regionalmente e escrito de forma síncrona: a API do plano de controlo só é devolvida depois de estes metadados serem confirmados num quórum numa região. As variáveis e os resultados HTTP também são armazenados regionalmente e escritos de forma síncrona, pelo menos, a cada cinco segundos.
Se uma zona falhar, os fluxos de trabalho são retomados automaticamente com base nos últimos dados armazenados. No entanto, os pedidos HTTP que ainda não receberam respostas não são repetidos automaticamente. Use políticas de repetição para pedidos que podem ser repetidos com segurança, conforme descrito na nossa documentação.
Indisponibilidade regional: o Workflows é um serviço regionalizado. Em caso de indisponibilidade regional, o Workflows não faz failover. Recomendamos que os clientes implementem fluxos de trabalho em várias regiões se quiserem uma maior disponibilidade.
Cloud Service Mesh
O Cloud Service Mesh permite-lhe configurar uma malha de serviços gerida que abrange vários clusters do GKE. Esta documentação refere-se apenas à malha de serviços na nuvem gerida. A variante no cluster é autoalojada e devem ser seguidas as diretrizes da plataforma normais.
Indisponibilidade zonal: a configuração da malha, uma vez que está armazenada no cluster do GKE, é resiliente a indisponibilidades zonais, desde que o cluster seja regional. Os dados que o produto usa para contabilidade interna são armazenados regional ou globalmente e não são afetados se uma única zona estiver fora de serviço. O plano de controlo é executado na mesma região que o cluster do GKE que suporta (para clusters zonais, é a região que contém) e não é afetado por interrupções numa única zona.
Indisponibilidade regional: o Cloud Service Mesh fornece serviços a clusters do GKE, que são regionais ou zonais. Em caso de uma indisponibilidade regional, o Cloud Service Mesh não faz failover. O GKE também não. Recomendamos que os clientes implementem malhas constituídas por clusters do GKE que abrangem diferentes regiões.
Diretório de serviços
O Service Directory é uma plataforma para descobrir, publicar e associar serviços. Fornece informações em tempo real, num único local, sobre todos os seus serviços. O Service Directory permite-lhe fazer a gestão do inventário de serviços em grande escala, quer tenha alguns pontos finais de serviço ou milhares.
Os recursos do diretório de serviços são criados regionalmente, correspondendo ao parâmetro de localização especificado pelo utilizador.
Indisponibilidade zonal: durante uma indisponibilidade zonal, o Service Directory continua a publicar pedidos de outra zona na mesma região ou numa região diferente sem interrupção. Em cada região, o Service Directory mantém sempre várias réplicas. Assim que a indisponibilidade zonal for resolvida, a redundância total é restaurada.
Indisponibilidade regional: o Service Directory não é resiliente a indisponibilidades regionais.