このガイドでは、セキュリティ担当者を対象に、セキュリティ分析で使用される Google Cloudログを導入する方法について説明します。セキュリティ分析を行うことで、組織はマルウェア、フィッシング、ランサムウェア、適切に構成されていないアセットなどの脅威について防止、検出、対応できます。
このガイドでは、次の方法について説明します。
- 分析対象のログを有効にする。
- それらのログをセキュリティ分析ツール(ログ分析、BigQuery、Google Security Operations、サードパーティのセキュリティ情報およびイベント管理(SIEM)テクノロジーなど)の選択に応じて、1 つの宛先に転送する。
- それらのログを分析してクラウドの利用状況を監査し、コミュニティ セキュリティ分析(CSA)プロジェクトのサンプルクエリを使用して、データやワークロードに対する潜在的な脅威を検出する。
このガイドに記載されている情報は、 Google Cloud の自律型のセキュリティ運用の一部であり、エンジニアリング主導の検知・対応手法の変革や、脅威検知能力を向上させるためのセキュリティ分析が含まれています。
このガイドでは、ログを分析対象のデータソースとして説明を進めます。ただし、このガイドのコンセプトを適用して、Security Command Center のセキュリティ結果など、 Google Cloudの他の補完的なセキュリティ関連データを分析できます。Security Command Center Premium には、定期的に更新される管理対象検出機能のリストが用意されており、システム内の脅威、脆弱性、構成ミスをほぼリアルタイムで特定するように設計されています。Security Command Center からこうしたシグナルを分析し、本ガイドで説明するようにセキュリティ分析ツールに取り込まれたログと関連付けることで、潜在的なセキュリティの脅威をより広い視野で把握することが可能になります。
次の図は、セキュリティ データソース、セキュリティ分析ツール、CSA クエリがどのように連携しているかを示しています。
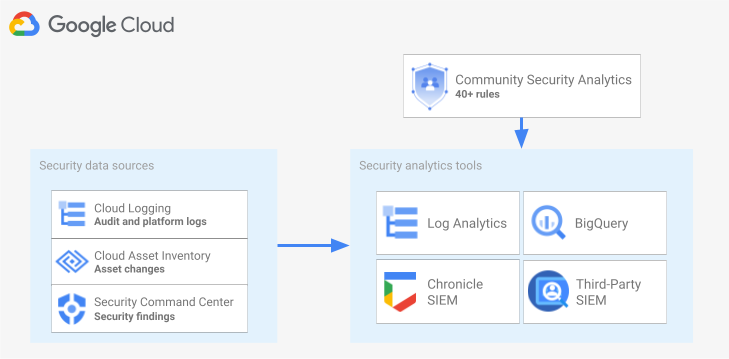
この図は、セキュリティ データソース(Cloud Logging のログ、Cloud Asset Inventory のアセット変更、Security Command Center のセキュリティ検出結果)から始まります。次に、こうしたセキュリティ データソースが、選択したセキュリティ分析ツール(Cloud Logging、BigQuery、Google Security Operations、サードパーティの SIEM のログ分析)に転送される様子を図に示しています。最後に、分析ツールで CSA クエリを使用して、照合されたセキュリティ データを分析する様子を示しています。
セキュリティ ログ分析ワークフロー
このセクションでは、Google Cloudでセキュリティ ログ分析を設定する手順について説明します。このワークフローは、次の図に示す 3 つのステップで構成されており、以下のパラグラフで各ステップについて説明します。
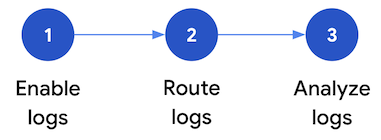
ログを有効化:Google Cloudでは多くのセキュリティ ログを使用できます。各ログには、特定のセキュリティ保護用の質問に答える際に役に立つさまざまな情報が含まれています。管理アクティビティ監査ログなどの一部のログはデフォルトで有効になっていますが、その他のログは Cloud Logging で追加の取り込み費用が発生するため、手動で有効にする必要があります。したがって、ワークフローの最初のステップは、セキュリティ分析のニーズに最も関連性が高いセキュリティ ログを優先し、そうした特定のログを個別に有効にすることです。
可視性と脅威検出のカバレッジの観点からログを評価できるように、このガイドにはログスコープ ツールが含まれています。このツールは、各ログを MITRE ATT&CK® Matrix for Enterprise の関連する脅威の戦術と手法にマッピングします。このツールを使用すると、Security Command Center の Event Threat Detection ルールと、それらが依存するログとのマッピングも行われます。ログスコープ ツールを使用すると、使用する分析ツールに関係なくログを評価できます。
ログを転送: 分析するログを特定して有効にしたら、次のステップでは、組織(含まれるフォルダ、プロジェクト、請求先アカウントを含む)からのログを転送して集計します。ログの転送方法は、使用する分析ツールによって異なります。
このガイドでは、一般的なログの転送先について説明します。また、分析にログ分析と BigQuery のどちらを使用するかに応じて、Cloud Logging の集約シンクで組織全体のログを Cloud Logging ログバケットまたは BigQuery データセットに転送する方法についても説明します。
ログを分析: 分析ツールにログを転送したら、次のステップでは、これらのログを分析して、潜在的なセキュリティ上の脅威を特定します。ログの分析方法は、使用する分析ツールによって異なります。ログ分析または BigQuery を使用する場合は、SQL クエリを使用してログを分析できます。Google Security Operations を使用している場合は、YARA-L ルールを使用してログを分析します。サードパーティの SIEM ツールを使用している場合は、そのツールで指定されたクエリ言語を使用します。
このガイドでは、ログ分析や BigQuery でログを分析するために使用できる SQL クエリを紹介します。このガイドで提供される SQL クエリは、Community Security Analytics(CSA)プロジェクトに由来しています。CSA は基礎的なセキュリティ分析のオープンソースのセットで、 Google Cloud ログの分析を開始するために再利用できる事前構築されたクエリとルールのベースラインを提供するように設計されています。
以降のセクションでは、セキュリティ ログの分析ワークフローの各ステップを設定して適用する方法について詳しく説明します。
ログを有効化
ログを有効にするプロセスは、次の手順で構成されています。
- 本ガイドのログスコープ ツールを使用して、必要なログを特定します。
- 後でログシンクを構成するときに使用するために、ログスコープ ツールによって生成されたログフィルタを記録します。
- 特定されたログタイプまたは Google Cloud サービスごとにロギングを有効にします。サービスによっては、このセクションの後半で詳述するように、対応するデータアクセス監査ログを有効にしなければならない場合もあります。
ログスコープ ツールを使用してログを特定する
このセクションで示されているログスコープ ツールを使用すると、セキュリティとコンプライアンスのニーズを満たすログを特定できます。このツールには、Cloud Audit Logs、アクセスの透明性ログ、ネットワーク ログ、いくつかのプラットフォーム ログなど、Google Cloud 全体の貴重なセキュリティ関連ログを一覧表示する対話型のテーブルが用意されています。このツールは、各ログタイプを次の領域にマッピングします。
- 対象のログでモニタリングできる MITRE ATT&CK の脅威の戦術と手法。
- 対象のログで検出できる CIS Google Cloud Computing Platform のコンプライアンス違反。
- 対象のログに依存する Event Threat Detection ルール。
ログスコープ ツールは、テーブルの直後に表示されるログフィルタも生成します。必要なログを特定したら、ツールでそのログを選択して、そのログフィルタを自動的に更新します。
以下の短い手順で、ログスコープ ツールの使用方法を説明します。
- ログスコープ ツールでログを選択または削除するには、ログの名前の横にある切り替えボタンをクリックします。
- すべてのログを選択または削除するには、[Log type] の見出しの横にある切り替えボタンをクリックします。
- 各ログタイプでモニタリングできる MITRE ATT&CK の手法を確認するには、[MITRE ATT&CK tactics and techniques] の見出しの横にある をクリックします。
ログスコープ ツール
ログフィルタを記録する
ログスコープ ツールによって自動的に生成されるログフィルタには、ツールで選択したすべてのログが含まれます。このフィルタはそのまま使用することも、要件に応じてログフィルタをさらに絞り込むこともできます。たとえば、1 つ以上の特定のプロジェクトにあるリソースのみを含める(または除外する)ことができます。ロギング要件を満たすログフィルタを作成したら、ログの転送時に使用するために、フィルタを保存する必要があります。たとえば、次のようにテキスト エディタでフィルタを保存するか、環境変数に保存できます。
- ツールに続く「自動生成されたログフィルタ」セクションで、ログフィルタのコードをコピーします。
- 省略可: コピーしたコードを編集してフィルタを絞り込みます。
Cloud Shell で、ログフィルタを保存する変数を作成します。
export LOG_FILTER='LOG_FILTER'LOG_FILTERは、ログフィルタのコードに置き換えます。
サービス固有のプラットフォーム ログを有効にする
ログスコープ ツールで選択した各プラットフォーム ログについて、これらのログをサービスごとに(通常はリソースレベルで)有効にする必要があります。たとえば、Cloud DNS ログは VPC ネットワーク レベルで有効化されます。同様に、VPC Flow Logs は、サブネット内のすべての VM のサブネット レベルで有効化され、ファイアウォール ルール ロギングのログは、個別のファイアウォール ルールレベルで有効化されます。
各プラットフォーム ログには、ロギングを有効にする方法について独自の手順があります。ただし、ログスコープ ツールを使用すると、各プラットフォーム ログに関連する手順をすばやく開くことができます。
特定のプラットフォーム ログのロギングを有効にする方法を確認するには、以下のようにします。
- ログスコープ ツールで、有効にするプラットフォーム ログを探します。
- [Enabled by default] 列で、そのログに対応する [Enable] リンクをクリックします。リンクをクリックすると、そのサービスのロギングを有効にするための詳細な手順が表示されます。
データアクセス監査ログを有効にする
ログスコープ ツールで確認できるように、Cloud Audit Logs のデータアクセス監査ログを使用することで、脅威を広い範囲で検出できます。ただし、ログのボリュームが極めて大きくなる可能性があります。したがって、このデータアクセス監査ログを有効にすると、こうしたログの取り込み、保存、エクスポート、処理に関連して追加料金が発生する場合があります。このセクションでは、こうしたログを有効にする方法と、価値とコストのトレードオフの判断に役立つベスト プラクティスの両方について説明します。
データアクセス監査ログは、BigQuery を除き、デフォルトで無効になっています。BigQuery 以外の Google Cloud サービスのデータアクセス監査ログを構成するには、 Google Cloud コンソールまたは Google Cloud CLI を使用してデータアクセス監査ログを明示的に有効にし、Identity and Access Management(IAM)ポリシー オブジェクトを編集する必要があります。データアクセス監査ログを有効にすると、記録されるオペレーションの種類も構成できます。データアクセス監査ログは次の 3 種類です。
ADMIN_READ: メタデータまたは構成情報を読み取るオペレーションを記録します。DATA_READ: ユーザー提供データを読み取るオペレーションを記録します。DATA_WRITE: ユーザー提供データを書き込むオペレーションを記録します。
メタデータや構成情報を書き込むオペレーションである、ADMIN_WRITE オペレーションの記録は構成できないことに注意してください。ADMIN_WRITE オペレーションは、Cloud Audit Logs の管理アクティビティ監査ログに含まれているため、無効にすることはできません。
データアクセス監査ログの量を管理する
データアクセス監査ログを有効にする場合の目標は、セキュリティの可視化という観点でその価値を最大化することと、費用と管理のオーバーヘッドを抑えることです。この目標を達成するために、以下の操作を行って、価値の低い大量のログを除外することをおすすめします。
- 機密性の高いワークロード、キー、データをホストするサービスなど、関連性の高いサービスを優先的に処理します。他のサービスよりも優先させたいサービスの具体例については、データアクセス監査ログの構成例をご覧ください。
デベロッパー環境やステージング環境をホストするプロジェクトではなく、本番環境ワークロードをホストするプロジェクトなど、関連性の高いプロジェクトを優先的に処理します。特定のプロジェクトのログをすべて除外するには、次の式をシンクのログフィルタに追加します。PROJECT_ID の部分は、すべてのログを除外するプロジェクトの ID に置き換えます。
プロジェクト ログフィルタ式 指定されたプロジェクトのすべてのログを除外する NOT logName =~ "^projects/PROJECT_ID"
ADMIN_READ、DATA_READ、DATA_WRITEなどのデータアクセス オペレーションのサブセットを優先して、記録されるオペレーションを最小限に抑えます。たとえば、Cloud DNS などの一部のサービスでは 3 種類のオペレーションがすべて書き込まれますが、ロギングを有効にできるのはADMIN_READオペレーションに対してのみです。これら 3 種類のデータアクセス オペレーションの 1 つまたは複数を構成した後に、特に量の多い特定のオペレーションを除外することもできます。シンクのログフィルタを変更することで、そのような量の多いオペレーションを除外できます。たとえば、一部の重要なストレージ サービスについては、DATA_READオペレーションを含む完全なデータアクセス監査ロギングを有効にすることを決定したとします。この状況で、トラフィックの多い特定のデータ読み取りオペレーションを除外するには、次の推奨ログフィルタ式をシンクのログフィルタに追加します。サービス ログフィルタ式 大量のログを Cloud Storage から除外する NOT (resource.type="gcs_bucket" AND (protoPayload.methodName="storage.buckets.get" OR protoPayload.methodName="storage.buckets.list"))
大量のログを Cloud SQL から除外する NOT (resource.type="cloudsql_database" AND protoPayload.request.cmd="select")
最も機密性が高いワークロードやデータをホストするリソースなど、関連性の高いリソースを優先的に処理します。処理するデータの価値と、外部からアクセス可能かどうかなどのセキュリティ リスクに基づいて、リソースを分類できます。データアクセス監査ログはサービスごとに有効になりますが、ログフィルタによって特定のリソースやリソースタイプを除外できます。
データアクセスを記録する対象から、特定のプリンシパルを除外します。たとえば、内部テスト アカウントは、オペレーションが記録されないように除外できます。詳しくは、データアクセス監査ログのドキュメントの除外を設定するをご覧ください。
データアクセス監査ログの構成例
次に表示するのは、 Google Cloud プロジェクトでログのボリュームを制限しつつ、貴重なセキュリティの可視性を高めるために使用できる、ベースライン データアクセス監査ログの構成です。
| 階層 | サービス | データアクセス監査ログのタイプ | MITRE ATT&CK の戦術 |
|---|---|---|---|
| 認証と承認サービス | IAM Identity-Aware Proxy(IAP)1 Cloud KMS Secret Manager Resource Manager |
ADMIN_READ DATA_READ |
発見 ID 情報へのアクセス 特権の昇格 |
| ストレージ サービス | BigQuery(デフォルトで有効) Cloud Storage1、2 |
DATA_READ DATA_WRITE |
コレクション 浸透 |
| インフラストラクチャ サービス | Compute Engine 組織のポリシー |
ADMIN_READ | 発見 |
1 IAP または Cloud Storage でデータアクセス監査ログを有効にすると、IAP で保護されたウェブリソースや Cloud Storage オブジェクトへのトラフィックが多い場合に、大量のログが生成される可能性があります。
2 Cloud Storage でデータアクセス監査ログを有効にすると、非公開オブジェクトに対する認証済みブラウザでのダウンロードの使用が中断される可能性があります。この問題の詳細と提案される回避策については、Cloud Storage トラブルシューティング ガイドをご覧ください。
構成例では、基になるデータ、メタデータ、または構成に基づいて、サービスがどのように機密性の階層にグループ化されるかに注目します。これらの階層では、次の粒度のデータアクセス監査ロギングをおすすめします。
- 認証と承認サービス: この階層のサービスでは、すべてのデータアクセス オペレーションを監査することをおすすめします。このレベルの監査は、機密鍵、シークレット、IAM ポリシーへのアクセスのモニタリングに役立ちます。このアクセスをモニタリングすると、発見、ID 情報へのアクセス、特権の昇格などの MITRE ATT&CK の戦術を検出できる場合があります。
- ストレージ サービス: この階層のサービスでは、ユーザー提供データに関連するデータアクセス オペレーションを監査することをおすすめします。このレベルの監査は、貴重なデータやセンシティブ データへのアクセスをモニタリングするのに役立ちます。このアクセスをモニタリングすると、コレクションや浸透などの MITRE ATT&CK の戦術を検出できる場合があります。
- インフラストラクチャ サービス: この階層のサービスでは、メタデータや構成情報を含むデータアクセス オペレーションを監査することをおすすめします。このレベルの監査は、インフラストラクチャ構成のスキャンをモニタリングするのに役立ちます。このアクセスをモニタリングすると、ワークロードに対する発見などの MITRE ATT&CK の戦術を検出できる場合があります。
ログを転送する
ログを特定して有効にしたら、その次のステップでは、ログを単一の宛先に転送します。転送先、パス、複雑さは、次の図に示すように、使用する分析ツールによって異なります。
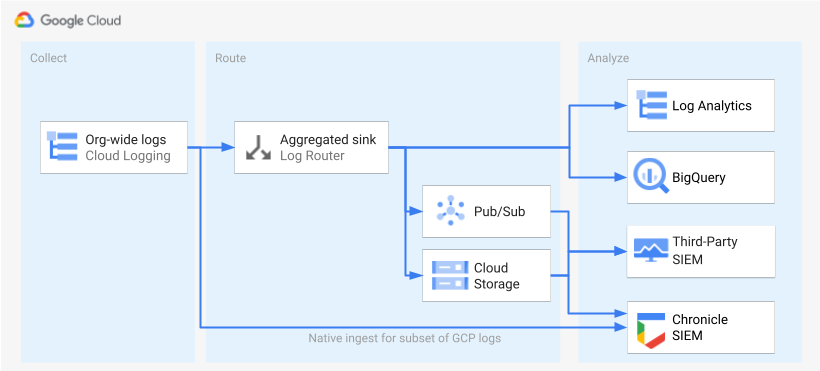
この図では、次の転送オプションが示されています。
ログ分析を使用する場合は、 Google Cloud 組織全体のログを単一の Cloud Logging バケットに集約するための集約シンクが必要です。
BigQuery を使用する場合は、 Google Cloud 組織全体のログを単一の BigQuery データセットに集約するための集約シンクが必要です。
Google Security Operations を使用し、この事前定義されたログのサブセットがセキュリティ分析のニーズを満たす場合は、組み込みの Google Security Operations の取り込み機能を使用して、これらのログを Google Security Operations アカウントに自動的に集約できます。この事前定義されたログセットは、ログスコープ ツールの [Exportable directly to Google Security Operations] 列を確認して表示することもできます。これらの事前定義されたログのエクスポートの詳細については、Google Security Operations に Google Cloud ログを取り込むをご覧ください。
BigQuery またはサードパーティの SIEM を使用している場合、または拡張されたログセットを Google Security Operations にエクスポートする場合は、図で示すとおり、ログの有効化と分析の間にステップを追加する必要があります。この追加のステップでは、選択したログを適切に転送する集約シンクを構成します。BigQuery を使用している場合、このシンクはログを BigQuery に転送するためだけに必要となります。サードパーティの SIEM を使用している場合は、分析ツールに pull する前に、シンクで選択したログを Pub/Sub または Cloud Storage に集約させる必要があります。
Google Security Operations とサードパーティの SIEM への転送オプションについては、このガイドでは説明しません。以降のセクションでは、ログをログ分析または BigQuery に転送するための詳細な手順を説明します。
- 単一の宛先を設定する
- 集約ログシンクを作成する
- シンクにアクセス権を付与する
- 転送先への読み取りアクセス権を構成する
- ログが宛先に転送されていることを確認する
単一の宛先を設定する
ログ分析
ログの集約先となる Google Cloud プロジェクトで Google Cloud コンソールを開きます。
Cloud Shell ターミナルで、次の
gcloudコマンドを実行してログバケットを作成します。gcloud logging buckets create BUCKET_NAME \ --location=BUCKET_LOCATION \ --project=PROJECT_ID次のように置き換えます。
PROJECT_ID: 集約されたログを保存するプロジェクトの ID。 Google CloudBUCKET_NAME: 新しい Logging バケットの名前。BUCKET_LOCATION: 新しい Logging バケットの地理的なロケーション。サポートされているロケーションはglobal、us、またはeuです。これらのストレージ リージョンの詳細については、サポートされているリージョンをご覧ください。ロケーションを指定しない場合はglobalリージョンが使用されます。つまり、ログは物理的にどのリージョンにも配置される可能性があります。
バケットが作成されたことを確認します。
gcloud logging buckets list --project=PROJECT_ID(省略可)バケット内のログの保持期間を設定します。次の例では、バケットに保存されたログの保持期間を 365 日間に延長します。
gcloud logging buckets update BUCKET_NAME \ --location=BUCKET_LOCATION \ --project=PROJECT_ID \ --retention-days=365こちらの手順に沿って、新しいバケットをログ分析を使用するようにアップグレードします。
BigQuery
ログの集約先となる Google Cloud プロジェクトで Google Cloud コンソールを開きます。
Cloud Shell ターミナルで次の
bq mkコマンドを実行して、データセットを作成します。bq --location=DATASET_LOCATION mk \ --dataset \ --default_partition_expiration=PARTITION_EXPIRATION \ PROJECT_ID:DATASET_ID次のように置き換えます。
PROJECT_ID: 集約されたログを保存するプロジェクトの ID。 Google CloudDATASET_ID: 新しい BigQuery データセットの ID。DATASET_LOCATION: データセットの地理的なロケーション。データセットの作成後はロケーションを変更できません。PARTITION_EXPIRATION: ログシンクによって作成されるパーティション分割テーブルのパーティションのデフォルトの存続期間(秒単位)です。ログシンクは次のセクションで構成します。構成するログシンクは、ログエントリのタイムスタンプに基づいて日ごとに分割されたパーティション分割テーブルを使用します。パーティション(関連するログエントリを含む)は、パーティションの日付からPARTITION_EXPIRATION秒後に削除されます。
集約ログシンクを作成する
組織レベルで集約シンクを作成することで、組織のログを宛先に転送します。ログスコープ ツールで選択したすべてのログを含めるには、ログスコープ ツールで生成されたログフィルタを使用してシンクを構成します。
ログ分析
Cloud Shell ターミナルで次の
gcloudコマンドを実行して、組織レベルで集約シンクを作成します。gcloud logging sinks create SINK_NAME \ logging.googleapis.com/projects/PROJECT_ID/locations/BUCKET_LOCATION/buckets/BUCKET_NAME \ --log-filter="LOG_FILTER" \ --organization=ORGANIZATION_ID \ --include-children次のように置き換えます。
SINK_NAME: ログを転送するシンクの名前。PROJECT_ID: 集約されたログを保存するプロジェクトの ID。 Google CloudBUCKET_LOCATION: ログストレージ用に作成した Logging バケットのロケーション。BUCKET_NAME: ログストレージ用に作成した Logging バケットの名前。LOG_FILTER: ログスコープ ツールから保存したログフィルタ。ORGANIZATION_ID: 組織のリソース ID。
組織内のすべてのGoogle Cloud プロジェクトのログも含まれるようにするうえで、
--include-childrenフラグが重要になります。詳細については、組織レベルのログをサポートされている宛先に照合して転送するをご覧ください。シンクが作成されたことを確認します。
gcloud logging sinks list --organization=ORGANIZATION_ID作成したシンクに関連付けられているサービス アカウントの名前を取得します。
gcloud logging sinks describe SINK_NAME --organization=ORGANIZATION_ID出力は次のようになります。
writerIdentity: serviceAccount:p1234567890-12345@logging-o1234567890.iam.gserviceaccount.com`serviceAccount: で始まる
writerIdentityの文字列全体をコピーします。 この ID はシンクのサービス アカウントです。このサービス アカウントにログバケットへの書き込みアクセス権を付与するまで、このシンクからのログ転送は失敗します。次のセクションでは、シンクのライター ID に書き込みアクセス権を付与します。
BigQuery
Cloud Shell ターミナルで次の
gcloudコマンドを実行して、組織レベルで集約シンクを作成します。gcloud logging sinks create SINK_NAME \ bigquery.googleapis.com/projects/PROJECT_ID/datasets/DATASET_ID \ --log-filter="LOG_FILTER" \ --organization=ORGANIZATION_ID \ --use-partitioned-tables \ --include-children次のように置き換えます。
SINK_NAME: ログを転送するシンクの名前。PROJECT_ID: ログを集約する Google Cloud プロジェクトの ID。DATASET_ID: 作成した BigQuery データセットの ID。LOG_FILTER: ログスコープ ツールから保存したログフィルタ。ORGANIZATION_ID: 組織のリソース ID。
組織内のすべてのGoogle Cloud プロジェクトのログも含まれるようにするうえで、
--include-childrenフラグが重要になります。詳細については、組織レベルのログをサポートされている宛先に照合して転送するをご覧ください。--use-partitioned-tablesフラグは、データがログエントリのtimestampフィールドに基づいて日単位で分割されるようにするうえで重要です。これにより、データのクエリが簡素化され、クエリでスキャンされるデータ量が減少するため、クエリ費用を削減できます。パーティション分割テーブルのもう 1 つの利点は、データセット レベルでデフォルトのパーティション有効期限を設定して、ログの保持要件を満せることです。デフォルトのパーティション有効期限は、前のセクションでデータセットの宛先を作成した際にすでに設定しています。個々のテーブルレベルでパーティションの有効期限を設定して、ログタイプに基づくきめ細かいデータ保持制御を行うこともできます。シンクが作成されたことを確認します。
gcloud logging sinks list --organization=ORGANIZATION_ID作成したシンクに関連付けられているサービス アカウントの名前を取得します。
gcloud logging sinks describe SINK_NAME --organization=ORGANIZATION_ID出力は次のようになります。
writerIdentity: serviceAccount:p1234567890-12345@logging-o1234567890.iam.gserviceaccount.com`serviceAccount: で始まる
writerIdentityの文字列全体をコピーします。 この ID はシンクのサービス アカウントです。このサービス アカウントに BigQuery データセットへの書き込みアクセス権を付与するまで、このシンクからのログの転送は失敗します。次のセクションでは、シンクのライター ID に書き込みアクセス権を付与します。
シンクにアクセス権を付与する
ログシンクを作成したら、シンクに宛先(Logging バケットまたは BigQuery データセット)への書き込みアクセス権を付与する必要があります。
ログ分析
シンクのサービス アカウントに権限を付与するには、次の手順で操作します。
Google Cloud コンソールで、[IAM] ページに移動します。
中央のログストレージ用に作成した Logging バケットを含む宛先の Google Cloud プロジェクトを選択していることを確認します。
[person_add アクセス権を付与] をクリックします。
[新しいプリンシパル] フィールドに、
serviceAccount:接頭辞を付けずにシンクのサービス アカウントを入力します。この ID は、シンクの作成後に前のセクションで取得したwriterIdentityフィールドに由来していることを思い出してください。[ロールを選択] プルダウン メニューで [ログバケット書き込み] を選択します。
[IAM の条件を追加] をクリックして、サービス アカウントのアクセス権を作成したログバケットのみに制限します。
条件の [タイトル] と [説明] を入力します。
[条件タイプ] のプルダウン メニューで、[リソース] > [名前] を選択します。
[演算子] のプルダウン メニューから [次で終わる] を選択します。
[値] フィールドに、次のようにバケットのロケーションと名前を入力します。
locations/BUCKET_LOCATION/buckets/BUCKET_NAME[保存] をクリックして、条件を追加します。
[保存] をクリックして、権限を設定します。
BigQuery
シンクのサービス アカウントに権限を付与するには、次の手順で操作します。
Google Cloud コンソールで、BigQuery に移動します。
中央のログストレージ用に作成した BigQuery データセットを開きます。
データセットの情報タブで、[共有keyboard_arrow_down] プルダウン メニューをクリックし、[権限] をクリックします。
[データセットの権限] サイドパネルで、[プリンシパルを追加] をクリックします。
[新しいプリンシパル] フィールドに、
serviceAccount:接頭辞を付けずにシンクのサービス アカウントを入力します。この ID は、シンクの作成後に前のセクションで取得したwriterIdentityフィールドに由来していることを思い出してください。[ロール] プルダウン メニューで、[BigQuery データ編集者] を選択します。
[保存] をクリックします。
シンクにアクセス権を付与すると、ログエントリはシンクの宛先(Logging バケットまたは BigQuery データセット)への入力を開始します。
転送先への読み取りアクセス権を構成する
ログシンクが組織全体のログを単一の宛先に転送するようになったため、それらのログをすべて検索できます。IAM 権限を使用して権限を管理し、必要に応じてアクセス権を付与します。
ログ分析
新しいログバケットでログを表示およびクエリするためのアクセス権を付与するには、次の手順で操作します。
Google Cloud コンソールで、[IAM] ページに移動します。
ログの集約に使用している Google Cloud プロジェクトが選択されていることを確認します。
person_add[追加] をクリックします。
[新しいプリンシパル] フィールドに、メール アカウントを追加します。
[ロールを選択] プルダウン メニューで [ログ表示アクセス者] を選択します。
このロールは、新しく追加されたプリンシパルに、 Google Cloud プロジェクト内のすべてのバケットのすべてのビューへの読み取りアクセス権を付与します。ユーザーのアクセスを制限するには、ユーザーに新しいバケット限定の読み取り専用アクセス権を付与する条件を追加します。
[条件を追加] をクリックします。
条件の [タイトル] と [説明] を入力します。
[条件タイプ] のプルダウン メニューで、[リソース] > [名前] を選択します。
[演算子] のプルダウン メニューから [次で終わる] を選択します。
[値] フィールドに、バケットのロケーションと名前、デフォルトのログビュー
_AllLogsを次のように入力します。locations/BUCKET_LOCATION/buckets/BUCKET_NAME/views/_AllLogs[保存] をクリックして、条件を追加します。
[保存] をクリックして、権限を設定します。
BigQuery
BigQuery データセット内のログの表示とクエリを行うためのアクセス権を付与するには、BigQuery ドキュメントのデータセットへのアクセス権の付与の手順に沿って操作します。
ログが宛先に転送されていることを確認する
ログ分析
ログ分析にアップグレードされたログバケットにログを転送すると、すべてのログタイプに対して統一されたスキーマを持つ単一のログビューによる、すべてのログエントリの表示とクエリが可能になります。ログが正しく転送されていることを、以下の手順で確認します。
Google Cloud コンソールで、[ログ分析] ページに移動します。
ログの集約に使用している Google Cloud プロジェクトが選択されていることを確認します。
[ログビュー] タブをクリックします。
作成したログバケット(
BUCKET_NAME)の下にあるログビューがまだ展開されていない場合は展開します。デフォルトのログビュー
_AllLogsを選択します。これにより、次のスクリーンショットに示すように、右側のパネルでログスキーマ全体を確認できるようになります。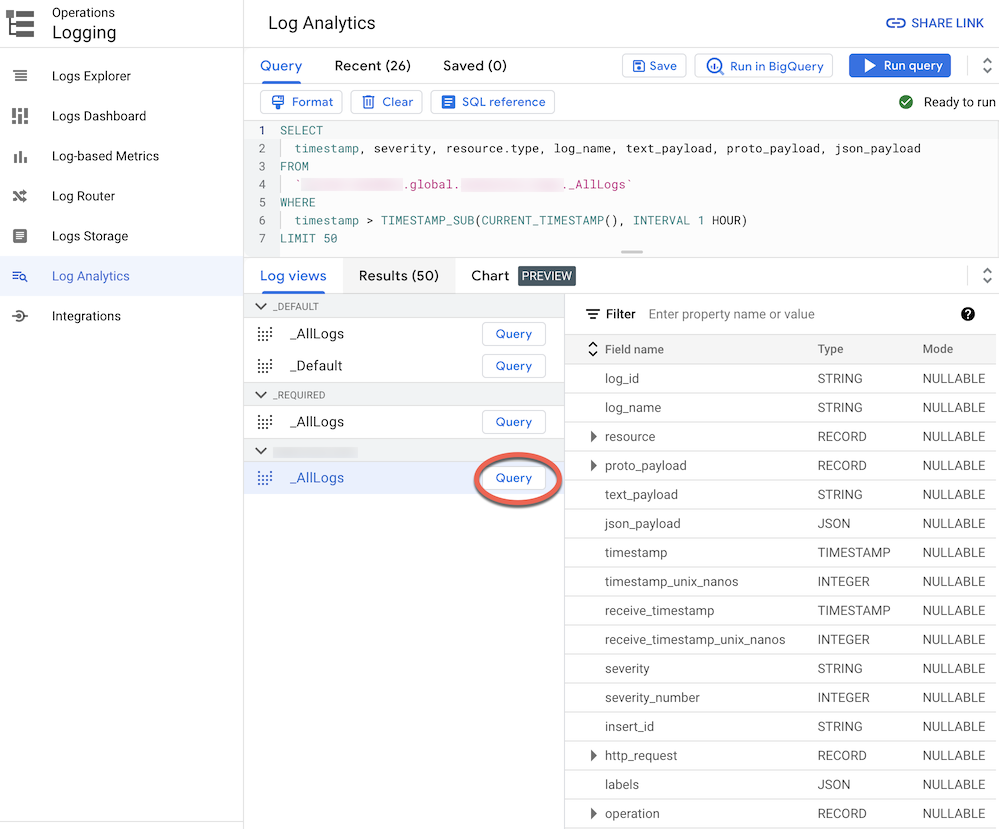
_AllLogsの横にある [クエリ] をクリックします。これにより、[クエリ] エディタに、最近転送されたログエントリを取得する SQL サンプルクエリが入力されます。最近転送されたログエントリを表示するには、[クエリを実行] をクリックします。
組織内の Google Cloud プロジェクトのアクティビティ レベルによっては、ログが生成されてログバケットに転送されるまで数分かかる場合があります。
BigQuery
ログを BigQuery データセットに転送すると、次のスクリーンショットに示すように、Cloud Logging によってログエントリを保持するための BigQuery テーブルが作成されます。
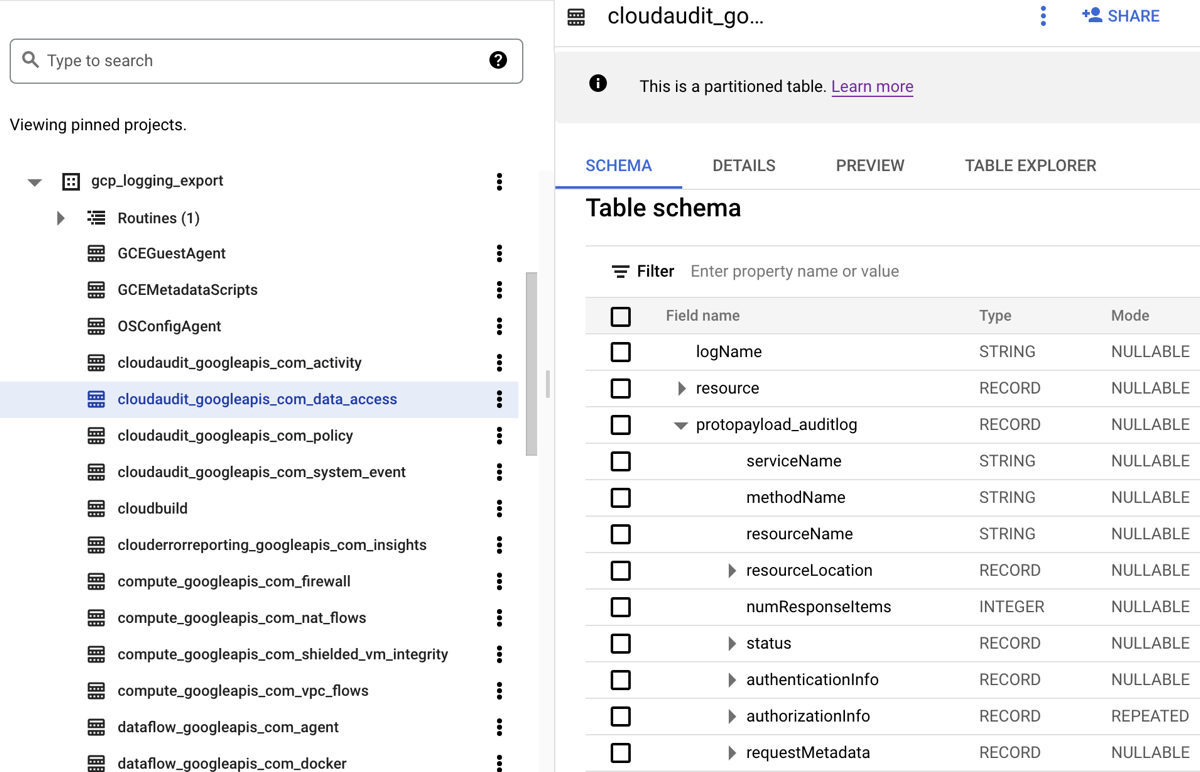
このスクリーンショットは、Cloud Logging が、ログエントリが属するログの名前に基づいて、各 BigQuery テーブルにどのように名前を付けるかを示しています。たとえば、スクリーンショットで選択されている cloudaudit_googleapis_com_data_access テーブルには、ログ ID が cloudaudit.googleapis.com%2Fdata_access のデータアクセス監査ログが含まれています。各テーブルは、対応するログエントリに基づいて命名されるだけでなく、各ログエントリのタイムスタンプに基づいてパーティション分割されます。
組織内の Google Cloud プロジェクトのアクティビティ レベルによっては、ログが生成されて BigQuery データセットに転送されるまで数分かかる場合があります。
ログを分析する
監査ログとプラットフォーム ログに対して、さまざまなクエリを実行できます。次のリストは、自分が管理するログについて自問できる、セキュリティ保護に関する一連の質問のサンプルを示したものです。このリストの各質問には、対応する CSA クエリの 2 つのバージョン(ログ分析で使用するバージョンと BigQuery で使用するバージョン)が用意されています。事前に設定したシンクの宛先と一致するクエリ バージョンを使用してください。
ログ分析
次の SQL クエリを使用する前に、MY_PROJECT_ID をログバケットを作成した Google Cloud プロジェクトの ID(PROJECT_ID))に、MY_DATASET_ID をそのログバケットのリージョンと名前(BUCKET_LOCATION.BUCKET_NAME)に置き換えます。
BigQuery
次の SQL クエリを使用する前に、MY_PROJECT_ID を BigQuery データセットを作成した Google Cloud プロジェクトの ID(PROJECT_ID))に、MY_DATASET_ID をそのデータセットの名前(DATASET_ID)に置き換えます。
- ログインとアクセスに関する質問
- 権限変更に関する質問
- プロビジョニング アクティビティに関する質問
- ワークロードの使用状況に関する質問
- データアクセスに関する質問
- ネットワーク セキュリティに関する質問
ログインとアクセスに関する質問
次に示すサンプルクエリは、 Google Cloud 環境への不審なログイン試行や初期アクセス試行を検出するための分析を実行します。
Google Workspace によって不審なログイン試行が報告されましたか?
次のクエリは、Google Workspace ログイン監査の一部である Cloud Identity ログを検索し、Google Workspace によってフラグが立てられた不審なログイン試行を検出します。このようなログイン試行は、 Google Cloud コンソール、管理コンソール、gcloud CLI から行われる可能性があります。
ログ分析
BigQuery
任意のユーザー ID でログインエラーが何回も発生していますか?
次のクエリは、Google Workspace ログイン監査の一部である Cloud Identity ログを検索し、過去 24 時間以内にログインが連続して 3 回以上失敗したユーザーを検出します。
ログ分析
BigQuery
VPC Service Controls に違反するアクセス試行は見られますか?
次のクエリは、Cloud Audit Logs からポリシー拒否監査ログを分析し、VPC Service Controls によってブロックされたアクセス試行を検出します。クエリ結果は、盗難された認証情報を使用した不正なネットワークからのアクセス試行など悪意のあるアクティビティを示している可能性があります。
ログ分析
BigQuery
IAP のアクセス制御に違反するアクセス試行は見られますか?
次のクエリは、外部アプリケーション ロードバランサのログを分析することで、IAP によってブロックされたアクセス試行を検出します。クエリ結果は、初期アクセス試行または脆弱性悪用の試行を示している可能性があります。
ログ分析
BigQuery
権限変更に関する質問
次に示す各サンプルクエリは、IAM ポリシー、グループとグループ メンバーシップ、サービス アカウント、関連するキーの変更といった、権限を変更する管理者のアクティビティに関する分析を実行します。このような権限の変更により、センシティブ データや環境に対する高レベルのアクセス権が付与される可能性があります。
高度な権限が付与されたグループにユーザーが追加されていますか?
次のクエリは、Google Workspace 管理者監査の監査ログを分析し、クエリに一覧表示されている高い権限を持つグループのいずれかに追加されたユーザーを検出します。クエリでは正規表現を使用して、モニタリングするグループ(admin@example.com や prod@example.com など)を定義します。クエリ結果に、悪意のある権限昇格や偶発的な権限昇格が示される場合があります。
ログ分析
BigQuery
サービス アカウントに付与された権限はありますか?
次のクエリは、Cloud Audit Logs の管理アクティビティ監査ログを分析し、サービス アカウントのプリンシパルに付与されている権限を検出します。付与される権限の例としては、そのサービス アカウントの権限を借用する能力やサービス アカウント キーを作成する能力が挙げられます。クエリ結果は、権限昇格のインスタンスや認証情報の漏洩のリスクを示している可能性があります。
ログ分析
BigQuery
未承認の ID によって作成されたサービス アカウントまたはキーはありますか?
次のクエリは、管理アクティビティ監査ログを分析し、ユーザーが手動で作成したサービス アカウントまたはキーを検出します。たとえば、「サービス アカウントの作成は、承認済みのサービス アカウントが自動化されたワークフローの一部として作成する場合にのみ許可する」というベスト プラクティスに従うことができます。そのようにすると、そのワークフロー外でのサービス アカウントの作成は、ポリシーに適合しておらず、悪意がある可能性があるものとみなされます。
ログ分析
BigQuery
機密性の高い IAM ポリシーに追加された(または削除された)ユーザーは存在しますか?
次のクエリは、管理アクティビティ監査ログを検索し、IAP で保護されたリソース(Compute Engine バックエンド サービスなど)に対するユーザーまたはグループのアクセス権の変更を検出します。次のクエリは、IAM ロール roles/iap.httpsResourceAccessor を含む IAP リソースのすべての IAM ポリシー更新を検索します。このロールにより、HTTPS リソースまたはバックエンド サービスにアクセスする権限が付与されます。クエリの結果は、インターネットに公開されている可能性のあるバックエンド サービスの防御をバイパスしようとする試みを示している可能性があります。
ログ分析
BigQuery
プロビジョニング アクティビティに関する質問
これらのサンプルクエリは、リソースのプロビジョニングや構成など、不審な管理アクティビティや異常な管理アクティビティを検出するための分析を実行します。
ログイン設定に変更が加えられていますか?
次のクエリは、管理アクティビティ監査ログを検索し、ロギング設定に対する変更を検出します。ロギング設定のモニタリングにより、監査ログの偶発的な無効化、悪意のある無効化、あるいはそれに類似した防御回避の手法を検出できます。
ログ分析
BigQuery
アクティブに無効化されている VPC Flow Logs はありますか?
次のクエリは、管理アクティビティ監査ログを検索することで、VPC Flow Logs がアクティブに無効化されているサブネットを検出します。VPC Flow Logs の設定をモニタリングすると、VPC Flow Logs の偶発的な無効化、悪意のある無効化、あるいはそれに類似した防御回避の手法を検出できます。
ログ分析
BigQuery
過去 1 週間に異常な数のファイアウォール ルールが変更されていますか?
次のクエリは、管理アクティビティの監査ログを検索し、過去 1 週間の特定の日にファイアウォール ルールの変更が異常に発生していればそれを検出します。このクエリでは、異常値があるかどうかを判断するために、ファイアウォール ルールの 1 日あたりの変更数に対して統計分析が実行されます。90 日間のルックバック ウィンドウで、前日の 1 日の数量を振り返り、各日の平均と標準偏差が計算されます。1 日の数量が平均より 2 標準偏差以上大きい場合は、異常値とみなされます。標準偏差係数とルックバック ウィンドウを含むクエリはすべて、クラウド プロビジョニング アクティビティ プロファイルに適合し、誤検出を最小限に抑えるように構成できます。
ログ分析
BigQuery
過去 1 週間に削除された VM はありますか?
次のクエリは、管理アクティビティの監査ログを検索し、過去 1 週間に削除された Compute Engine インスタンスを一覧表示します。このクエリは、リソースの削除を監査して、潜在的な悪意のあるアクティビティを検出するのに役立ちます。
ログ分析
BigQuery
ワークロードの使用状況に関する質問
これらのサンプルクエリは、誰がまたは何がクラウドのワークロードと API を使用しているか把握するための分析を行います。これにより、内部または外部で行われた潜在的に悪意のある行動を検出できます。
過去 1 週間に任意のユーザー ID による異常な量の API の使用が見られますか?
次のクエリは、すべての Cloud Audit Logs を分析し、過去 1 週間の特定の日に特定のユーザー ID で、API 使用率が異常に高いものがあれば検出します。このような異常に高い使用率は、潜在的な API の不正使用、内部の脅威、または認証情報の漏洩を示している可能性があります。異常値があるかどうかを判断するために、このクエリはプリンシパルごとに 1 日あたりのアクション数に対して統計分析を実行します。60 日間のルックバック ウィンドウで、前日の 1 日の数量を振り返り、各日のプリンシパルごとの平均と標準偏差が計算されます。ユーザーあたりの 1 日の数量が平均より 3 標準偏差以上大きい場合は、異常値とみなされます。標準偏差係数とルックバック ウィンドウを含むクエリはすべて、クラウド プロビジョニング アクティビティ プロファイルに適合し、誤検出を最小限に抑えるように構成できます。
ログ分析
BigQuery
過去 1 か月における 1 日あたりの自動スケーリングの使用量はどの程度ですか?
次のクエリは、管理アクティビティ監査ログを分析し、前月の自動スケーリング使用量を日単位で報告します。このクエリは、詳細なセキュリティ調査を保証するパターンや異常値を特定するために使用できます。
ログ分析
BigQuery
データアクセスに関する質問
これらのサンプルクエリは、 Google Cloudのデータにアクセスまたは修正を行ったユーザーを把握するための分析を行います。
前週に最も頻繁にデータにアクセスしたユーザーは誰ですか?
次のクエリでは、データアクセス監査ログを使用して、過去 1 週間に BigQuery テーブルに最も頻繁にアクセスしたユーザー ID を確認します。
ログ分析
BigQuery
先月「accounts」テーブルのデータにアクセスしたのはどのユーザーですか?
次のクエリは、データアクセス監査ログを使用して、過去 1 か月間に特定の accounts テーブルに最も頻繁にクエリを実行したユーザー ID を検索します。次のクエリでは、BigQuery のエクスポート先として MY_DATASET_ID および MY_PROJECT_ID のプレースホルダを使用するほか、DATASET_ID と PROJECT_ID のプレースホルダを使用しています。アクセス権が分析されるターゲット テーブル(この例では accounts テーブルなど)を指定するためには、DATASET_ID プレースホルダと PROJECT_ID プレースホルダに置き換える必要があります。
ログ分析
BigQuery
最も頻繁にアクセスされているのはどのテーブルで、アクセスしたのはどのユーザーですか?
次のクエリは、データアクセス監査ログを使用して、過去 1 か月間に頻繁に読み取り、変更されたデータが含まれる BigQuery テーブルを検索します。関連するユーザー ID と、データの読み取り総回数に対する変更の総回数の内訳が表示されます。
ログ分析
BigQuery
前週の BigQuery に対するクエリの上位 10 件は何ですか?
次のクエリは、データアクセス監査ログを使用して、過去 1 週間で最も頻繁に実行されたクエリを確認します。また、対応するユーザーと参照されたテーブルも一覧表示されます。
ログ分析
BigQuery
過去 1 か月間にデータアクセス ログに記録された最も多い操作は何ですか?
次のクエリでは、Cloud Audit Logs からのすべてのログを使用して、過去 1 か月間に記録された頻度の高い 100 件のアクションを確認します。
ログ分析
BigQuery
ネットワーク セキュリティに関する質問
これらのサンプルクエリは、 Google Cloudのネットワーク アクティビティの分析を行います。
新しい IP アドレスから特定のサブネットワークへの接続はありますか?
次のクエリは、VPC Flow Logs を分析し、新しい送信元 IP アドレスから特定のサブネットへの接続を検出します。この例では、60 日間のルックバック ウィンドウで過去 24 時間に初めて検出された場合、送信元 IP アドレスは新規とみなされます。このクエリは、PCI などの特定のコンプライアンス要件の対象となるサブネットに対して使用および調整できます。
ログ分析
BigQuery
Google Cloud Armor でブロックされた接続はありますか?
次のクエリは、外部アプリケーション ロードバランサ ログを分析して、Google Cloud Armor で構成されたセキュリティ ポリシーによってブロックされた接続を発見し、潜在的な脆弱性利用型不正プログラムの試みを検出するのに役立ちます。このクエリは、外部アプリケーション ロードバランサで Google Cloud Armor のセキュリティ ポリシーが構成されていることを前提としています。また、このクエリは、ログスコープ ツールの [Enable] リンクで提供されている手順で説明されているように、外部のアプリケーション ロードバランサのロギングが有効になっていることを前提としています。
ログ分析
BigQuery
Cloud IDS で検出された重大なウイルスやマルウェアはありますか?
次のクエリは、Cloud IDS 脅威ログを検索して、Cloud IDS によって検出された重大なウイルスやマルウェアを表示します。このクエリは、Cloud IDS エンドポイントが構成されていることを前提としています。
ログ分析
BigQuery
VPC ネットワークからの上位の Cloud DNS クエリドメインは何ですか?
次のクエリは、過去 60 日間の VPC ネットワークからの上位 10 件の Cloud DNS クエリドメインを一覧表示します。このクエリでは、ログ スコープ ツールのEnableリンクで提供されている手順にある通り、VPC サービスで Cloud DNS ロギングが有効になっていることを前提としています。
ログ分析
BigQuery
次のステップ
Google Cloud に関するリファレンス アーキテクチャ、図、ベスト プラクティスを確認する。Cloud アーキテクチャ センターをご覧ください。