大半のロードバランサは、ラウンドロビンまたはフローベースのハッシングでトラフィックを分散しています。しかし、この方法を採用しているロードバランサは、トラフィックが急増して利用可能なサービス容量を超えると適応が難しくなります。この記事では、これらの問題を Cloud Load Balancing で解決し、グローバル アプリケーションの処理能力を改善する方法について説明します。これにより、従来の負荷分散方法と比べて、ユーザー エクスペリエンスを向上させ、コストを削減できます。
この記事は、Google Cloud Load Balancing プロダクトのベスト プラクティスに関連するシリーズの 1 つです。この記事に関連するチュートリアルについては、負荷分散による容量管理をご覧ください。レイテンシに関する問題については、負荷分散によるアプリケーション レイテンシの最適化をご覧ください。
グローバル アプリケーションの処理能力に関する課題
グローバル アプリケーションのスケーリングは困難な場合があります。特に、IT 予算が限られ、ワークロードの急増が予測できない場合は難しくなります。Google Cloud などのパブリック クラウド環境では、自動スケーリングや負荷分散などの機能でこの問題に対応できます。ただし、このセクションで説明するように、オートスケーラーにはいくつかの制限があります。
新しいインスタンスを開始する際のレイテンシ
自動スケーリングの最も一般的な問題は、リクエストされたアプリケーションがトラフィックをすぐに処理できない点です。VM インスタンスのイメージにもよりますが、通常は VM インスタンスを準備する前にスクリプトを実行し、情報を読み込む必要があります。負荷分散がユーザーを新しい VM インスタンスに誘導するまでに数分かかります。その間、トラフィックは既存の VM インスタンスに分散されますが、転送先のインスタンスですでに容量を超えている可能性もあります。
バックエンド容量によるアプリケーションの制限
自動スケーリングができないアプリケーションもあります。たとえば、多くのデータベースはバックエンド容量が制限されています。水平スケーリングを行わないデータベースの場合、アクセスできるフロントエンドは特定の数に限られます。1 秒あたりのリクエスト数に制限がある外部 API に依存しているアプリケーションも自動スケーリングできません。
柔軟性のないライセンス
ライセンス付きのソフトウェアを使用する場合、ライセンスで最大容量が事前に設定されていることが少なくありません。ライセンスはすぐに追加できないため、結果的に自動スケーリングが制限されることになります。
VM インスタンスのヘッドルームが少ない
突然のトラフィックの急増に対応するため、オートスケーラーには十分なヘッドルームが必要です(たとえば、オートスケーラーを CPU 使用率の 70% で開始するように設定します)。コストを抑えるには目標値を高く設定したほうが効果的です(CPU 使用率 90% など)。しかし、突発的に需要が増加する広告キャンペーンなど、トラフィックが急増する環境では、トリガー値を高く設定するとスケーリングが機能しない可能性があります。トラフィックの増加率や新しい VM インスタンスの準備期間を考慮し、ヘッドルームのサイズを調整する必要があります。
リージョンの割り当て
どこかのリージョンで予期せぬトラフィックの急増があったとき、既存のリソースの割り当てによる制限のために、この状況に対応できるレベルまでスケールできないこともあります。リソースの割り当てを増やすには、数時間から数日かかることがあります。
グローバル ロード バランシングによる対応
外部アプリケーション ロードバランサと外部プロキシ ネットワーク ロードバランサは、グローバルに同期された Google Front End(GFE)サーバーを介してプロキシされるグローバル ロード バランシング プロダクトです。このようなタイプのロード バランシングの課題を容易に軽減できます。これらのサービスは、リージョン ロード バランシング ソリューションと異なる方法でトラフィックをバックエンドに分散します。
以下では、この違いについて説明します。
他のロードバランサが使用するアルゴリズム
ほとんどのロードバランサは、同じアルゴリズムを使用してバックエンド間でトラフィックを分散しています。
- ラウンドロビン。パケットの送信元と宛先に関係なく、すべてのバックエンド間でパケットが均等に分散されます。
- ハッシング。パケットフローは、送信元 IP、宛先 IP、ポート、プロトコルなどのトラフィック情報のハッシュ値に基づいて識別されます。同じハッシュ値を生成するトラフィックはすべて同じバックエンドに送信されます。
外部パススルー ネットワーク ロードバランサで現在利用可能なアルゴリズムは、ハッシングによるロード バランシングです。このロードバランサは、2 タプル ハッシング(送信元 IP と宛先 IP)、3 タプル ハッシング(送信元 IP、宛先 IP、プロトコル)、5 タプル ハッシング(送信元 IP、宛先 IP、ソースポート、宛先ポート、プロトコル)をサポートしています。
この両方のアルゴリズムで、異常なインスタンスが分散対象から除外されます。しかし、バックエンドの現在の負荷が負荷分散の要因となることはまれです。
一部のハードウェアまたはソフトウェアのロードバランサは、重み付けされたラウンドロビン、最小負荷、最速レスポンス時間、アクティブな接続数など、他の指標に基づいてトラフィックを転送します。しかし、トラフィックが突発的に増加して想定レベルを上回ると、容量を超えているバックエンド インスタンスにトラフィックが分散され、レイテンシが大幅に増加します。
一部のロードバランサでは、バックエンドの容量を超えるトラフィックを別のプールに転送するか、静的なウェブサイトにリダイレクトする高度なルールを使用しています。これにより、トラフィックを効果的に拒否し、「サービスを利用できません。後でやり直してください」というメッセージを送信します。また、リクエストをキューに入れるロードバランサもあります。
グローバル負荷分散ソリューションの多くは、DNS ベースのアルゴリズムで実装され、ユーザーの場所とバックエンドの負荷に応じて異なるリージョンの IP を提供します。これらのソリューションは、一部またはすべてのトラフィックを別のリージョンにフェイルオーバーします。ただし、DNS ベースのソリューションの場合、DNS エントリの有効期間(TTL)によってはフェイルオーバーに数分かかることも少なくありません。TTL を大幅に過ぎても、少量のトラフィックは引き続き古いサーバーに転送されます。DNS ベースのグローバル ロード バランシングは、急増するトラフィックの処理に最適なソリューションとはいえません。
外部アプリケーション ロードバランサの仕組み
外部アプリケーション ロードバランサは異なる方法を使用します。トラフィックは、Google の大半のグローバル ネットワーク エッジに配置されている GFE サーバーを介して転送されます。これは現在、世界で 80 以上の場所に存在します。ロード バランシング アルゴリズムは GFE サーバーに適用されます。

外部アプリケーション ロードバランサには、エッジノードでグローバルにアナウンスされた単一の安定した IP アドレスを介して接続できます。接続は任意の GFE によって終端されます。
GFE は、Google のグローバル ネットワークを通じて相互に接続されています。使用可能なバックエンドと負荷分散されたリソースごとに利用可能な容量を記述したデータが、グローバル コントロール プレーンを介してすべての GFE に継続的に配信されます。
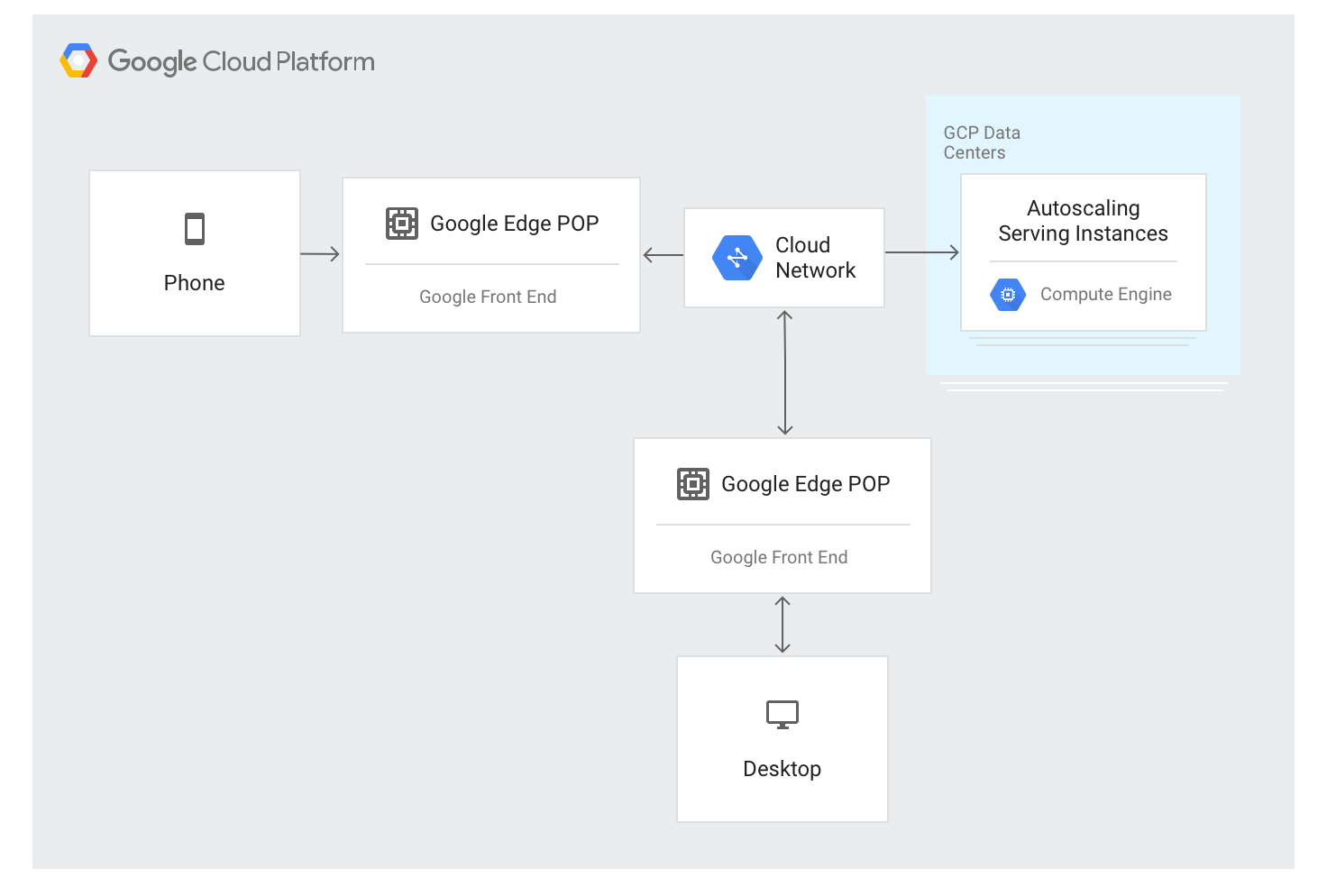
ロード バランシングされる IP アドレスへのトラフィックは、特別なロード バランシング アルゴリズム(リージョン別ウォーターフォール)を使用して、外部アプリケーション ロードバランサの構成で定義されているバックエンド インスタンスにプロキシされます。このアルゴリズムは、インスタンスとユーザー近接性、受信負荷、各ゾーンとリージョンのバックエンド容量を考慮し、リクエストの処理に最適なバックエンドを決定します。最終的には、世界全体で負荷と容量が考慮されます。
外部アプリケーション ロードバランサは、使用可能なインスタンスに基づいてトラフィックを分散します。負荷に基づいて新しいインスタンスを追加する場合、このアルゴリズムが自動スケーリング インスタンス グループと連携して機能します。
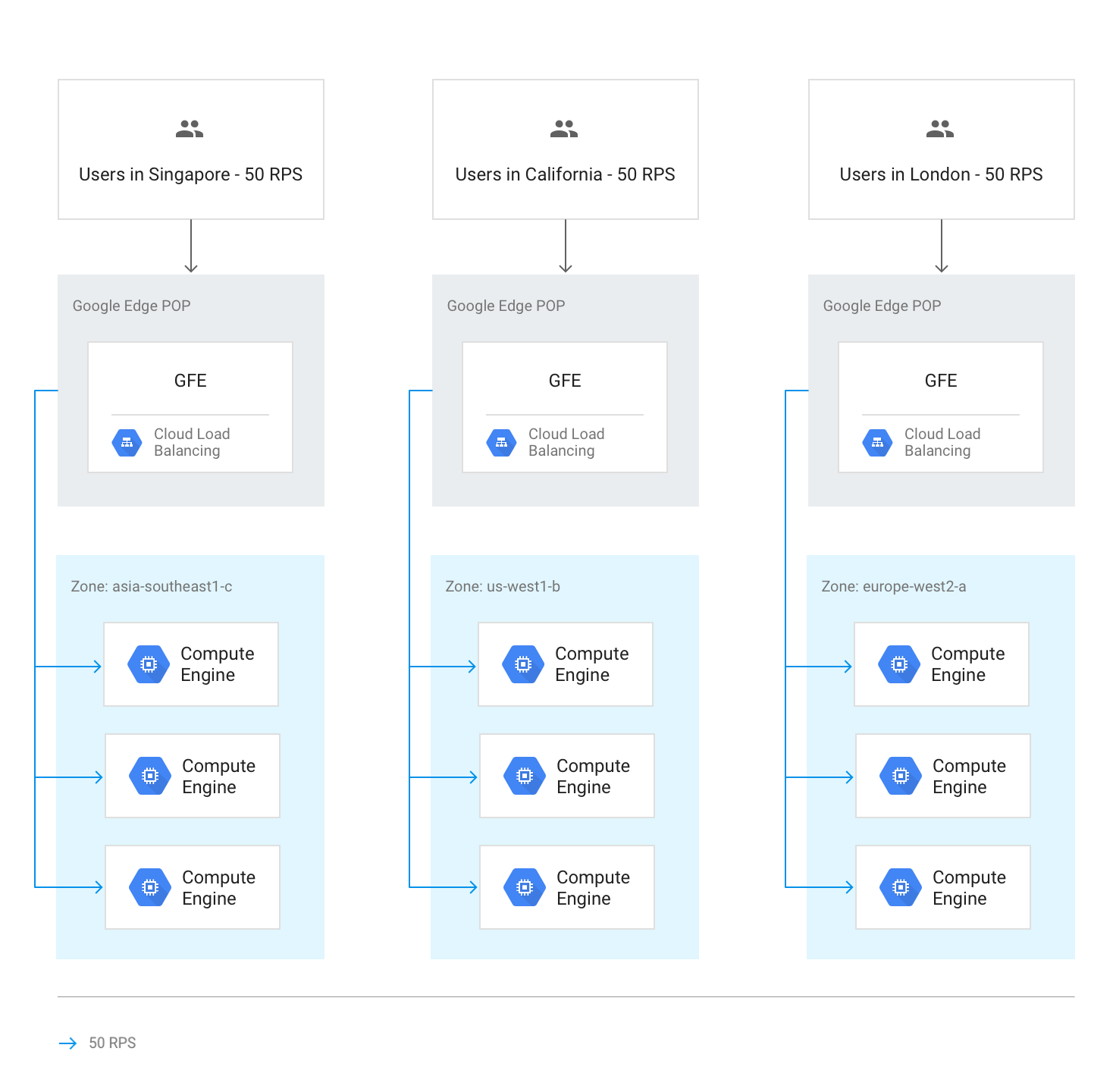
リージョン内のトラフィック フロー
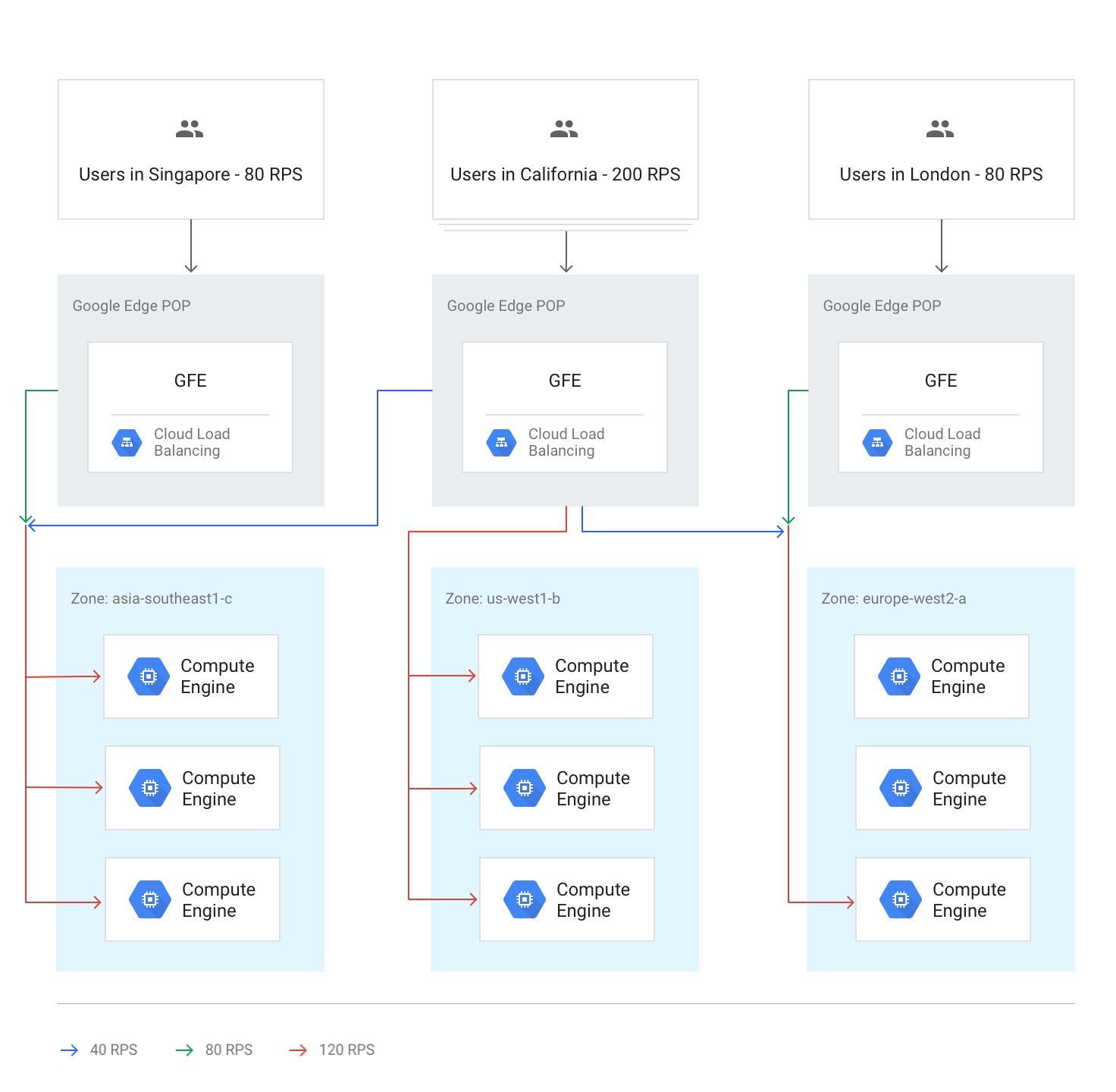
通常の状況下では、トラフィックはユーザーに最も近いリージョンに送信されます。負荷分散は次のガイドラインに従って実行されます。
各リージョン内では、トラフィックは各グループの容量に応じてインスタンス グループ全体で分散されます。このグループは複数のゾーンに存在する可能性があります。
容量がゾーン間で均等でない場合、使用可能なサービス容量に応じて負荷が分散されます。
ゾーン内では、リクエストは各インスタンス グループのインスタンスに均等に分散されます。
セッションは、セッション アフィニティの設定に応じてクライアント IP アドレスまたは Cookie 値に従って維持されます。
バックエンドが利用不能にならない限り、既存の TCP 接続は別のバックエンドに移動しません。
この負荷分散を次の図に示します。各リージョンの容量には余裕があり、このリージョンに最も近いユーザーからの負荷を処理できます。
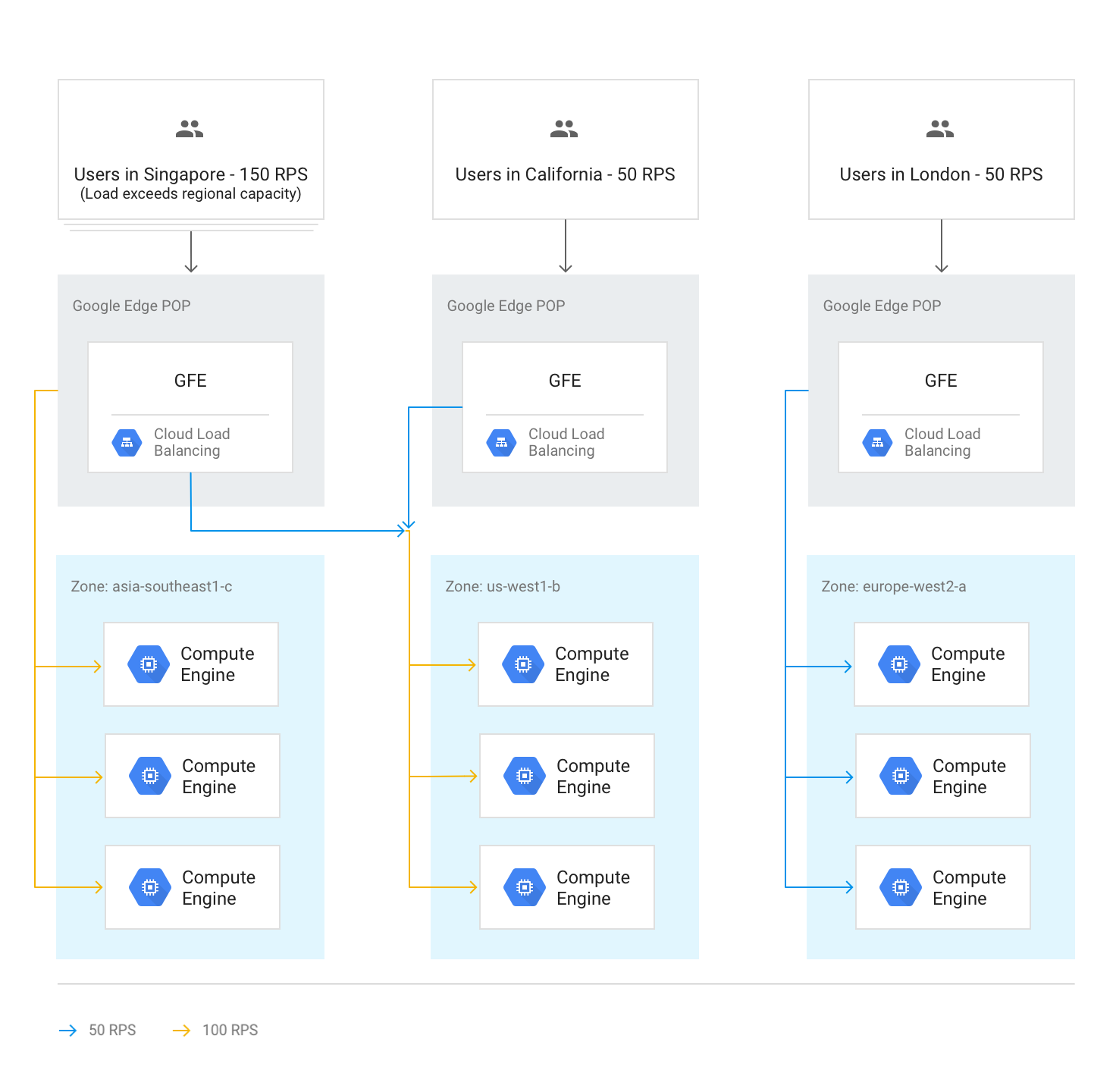
他のリージョンへのトラフィックのオーバーフロー
バックエンド サービスに設定されたサービス容量から判断し、リージョン全体で容量の上限に達したとみなされると、リージョン別ウォーターフォールのアルゴリズムに従って、使用可能な容量がある最も近いリージョンにトラフィックがオーバーフローします。各リージョンの上限に達すると、次に最も近いリージョンにトラフィックが転送されます。ユーザーとリージョンの距離は、GFE からインスタンス バックエンドまでのネットワーク ラウンド トリップ時間によって定義されます。
次の図は、リージョンで処理可能な上限を超えた場合に最も近いリージョンに転送される流れを示しています。
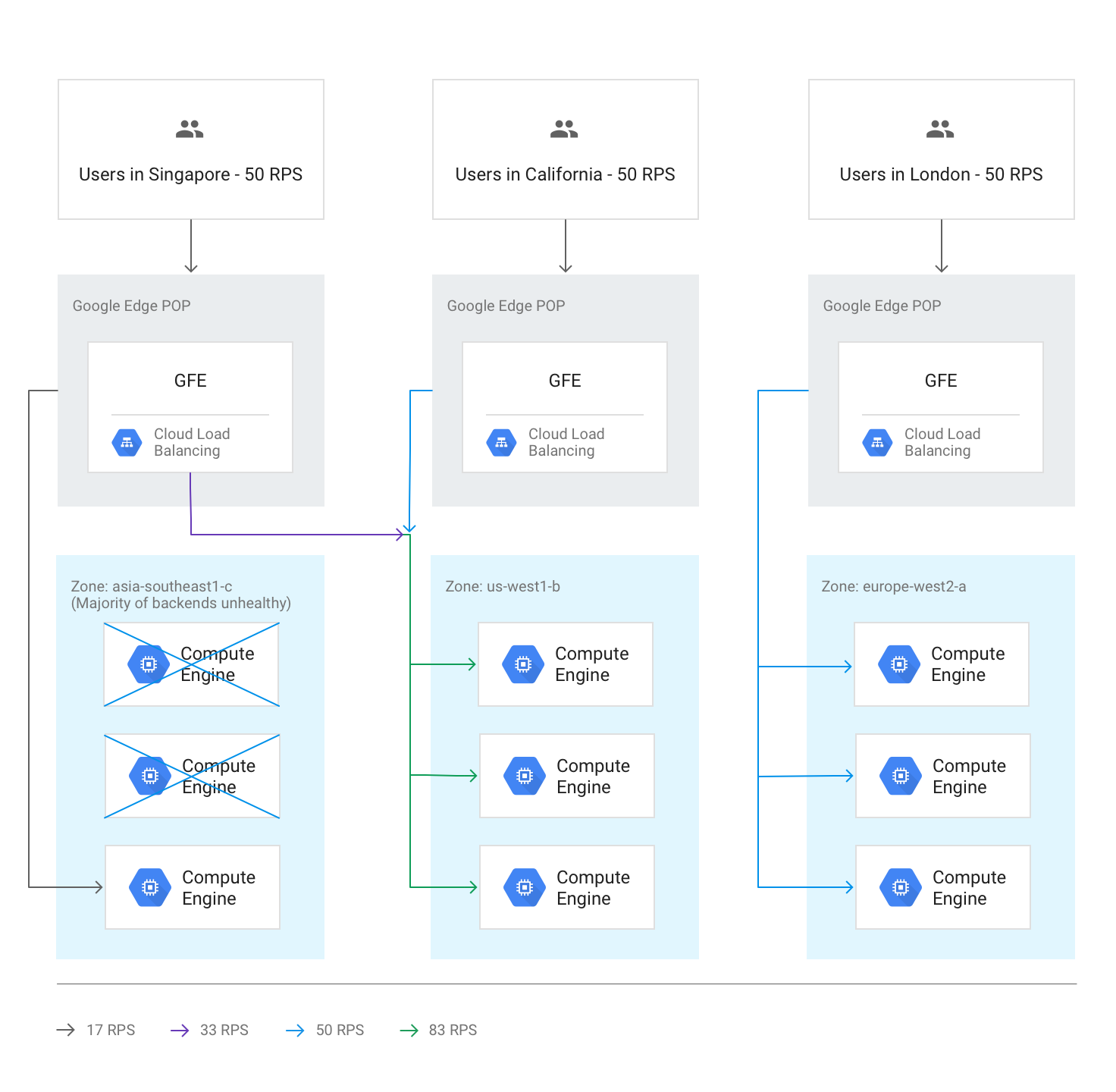
異常なバックエンドによるリージョン間のオーバーフロー
ヘルスチェックで、あるリージョンのバックエンドの半数以上が異常な状態であることが判明すると、GFE は次に最も近いリージョンに一部のトラフィックを転送し始めます。リージョンが異常な状態になったときに、トラフィックが完全に停止しないようにするため、このような処理が実行されます。このオーバーフローは、異常なバックエンドの残り容量が十分であっても発生します。
次の図は、1 つのゾーンのほとんどのバックエンドが異常な状態になったときのオーバーフローを示しています。
すべてのリージョンで容量を超えた場合
すべてのリージョンで上限に達したか、容量を上回った場合、容量と比較して各リージョンのオーバーフロー量が相対的に決まり、トラフィックのバランスが維持されます。たとえば、グローバルで容量が 20% を超過した場合、トラフィックをローカルで処理できるように、すべてのリージョンが自分の容量よりも 20% 多くリクエストを受信し、トラフィックを分散させます。
次の図は、このグローバル オーバーフロー ルールが有効であることを示しています。この場合、1 つのリージョン サーバーが非常に多くのトラフィックを処理するため、グローバルで利用可能なサービス容量では分散されません。
自動スケーリングでの一時的なオーバーフロー
自動スケーリングは、各バックエンド サービスで設定された容量制限に基づいて行われます。トラフィックが設定された容量制限に近づくと、新しいインスタンスを起動します。リクエスト レベルの急増度と新しいインスタンスがオンラインになるまでの時間によっては、他のリージョンへのオーバーフローが不要になる場合があります。それ以外の場合、オーバーフローは、新しいローカル インスタンスがオンラインになり、トラフィックを処理する準備ができるまでの一時的なバッファとして機能します。自動スケーリングで拡張された容量が十分であれば、すべての新しいセッションが最も近いリージョンに負荷分散されます。
レイテンシに対するオーバーフローの影響
リージョン別ウォーターフォール アルゴリズムにより、外部アプリケーション ロードバランサから他のリージョンへのトラフィックの一部でオーバーフローが発生する可能性があります。ただし、TCP セッションと SSL トラフィックは、ユーザーに最も近い GFE によって終了します。これは、アプリケーション レイテンシにはメリットになります。詳細については、負荷分散によるアプリケーション レイテンシの最適化をご覧ください。
ハンズオン: 処理能力管理の効果を測定する
オーバーフローが発生する仕組みや、HTTP ロードバランサでオーバーフローを管理する方法については、この記事に付属のロード バランシングによる処理能力の管理(チュートリアル)をご覧ください。
外部アプリケーション ロードバランサを使用して容量の課題に対処する
前述の課題を解決するために、外部アプリケーション ロードバランサと外部プロキシ ネットワーク ロードバランサは、容量を他のリージョンにオーバーフローさせることができます。グローバル アプリケーションの場合、ユーザーに対するレスポンスは若干遅くなりますが、リージョン バックエンドを使用する場合よりもユーザー エクスペリエンスは向上します。リージョン バックエンドを使用するアプリケーションの場合、レイテンシは短くなりますが、過負荷状態になる可能性があります。
冒頭のシナリオで外部アプリケーション ロードバランサが課題解決にどのように役立つのか見てみましょう。
新しいインスタンスを開始する際のレイテンシ。オートスケーラーの処理がローカル トラフィックの急増に対応できない場合、外部アプリケーション ロードバランサは 2 番目に近いリージョンに接続を一時的にオーバーフローします。これにより、元のリージョン内の既存のユーザー セッションは、既存のバックエンドに残ったまま最大限の速度で処理されますが、新しいユーザー セッションではわずかなレイテンシが発生します。追加のバックエンド インスタンスが元のリージョンでスケールアップされるとすぐに、新しいトラフィックはユーザーに最も近いリージョンにルーティングされます。
バックエンドの処理能力に制限されるアプリケーション。自動スケーリングできないアプリケーションでも、複数のリージョンで使用可能であれば、1 つのリージョンで通常のトラフィック処理に必要な容量を超えたときに、2 番目の近いリージョンに処理をオーバーフローできます。
柔軟性のないライセンス。ソフトウェア ライセンスの数に制限があり、現在のリージョンで使用可能なライセンスが残っていない場合、外部アプリケーション ロードバランサは、ライセンスが使用可能なリージョンにトラフィックを移動します。この処理を行うには、インスタンスの最大数がオートスケーラーの最大ライセンス数に設定されている必要があります。
VM インスタンスのヘッドルームが少ない。自動スケーリングのトリガーに高い CPU 使用率を設定できるので、リージョン オーバーフローによってコストを抑えることができます。他のリージョンへのオーバーフローにより、グローバル容量が常に十分であることが保証されるため、各リージョンのピークを下回るバックエンド容量を設定することもできます。
リージョンの割り当て。Compute Engine リソースの割り当てが需要に一致しない場合、外部アプリケーション ロードバランサは、リージョン割り当て内でスケーラブルなリージョンにトラフィックの一部を自動的にリダイレクトします。
次のステップ
Google の負荷分散オプションの詳細とバックグランドについては、次のページをご覧ください。
- 「負荷分散による処理能力の管理」チュートリアル
- 負荷分散によるアプリケーション レイテンシの最適化
- Networking 101 Codelab
- 外部パススルー ネットワーク ロードバランサ
- 外部アプリケーション ロードバランサ
- 外部プロキシ ネットワーク ロードバランサ