在 GKE 上使用 Cloud Service Mesh 時的擴充最佳做法
本指南說明如何運用最佳做法,解決 Google Kubernetes Engine 上代管 Cloud Service Mesh 架構的擴充問題。這些建議的主要目標,是確保微服務應用程式在成長過程中,能維持最佳效能、可靠性及資源用量。
如要瞭解擴充性限制,請參閱 Cloud Service Mesh 擴充性限制
GKE 上的 Cloud Service Mesh 擴充性取決於兩個主要元件 (資料層和控制層) 的運作效率。本文主要著重於擴充資料層。
識別控制層與資料層的資源調度問題
在 Cloud Service Mesh 中,控制層或資料層都可能發生擴縮問題。以下說明如何判斷您遇到的縮放問題類型:
控制層資源調度問題的徵兆
服務探索速度緩慢:新服務或端點需要很長時間才能探索完畢並開始提供服務。
設定延遲:流量管理規則或安全政策的變更需要很長時間才能傳播。
控制層作業延遲時間增加:建立、更新或刪除 Cloud Service Mesh 資源等作業變慢或沒有回應。
與 Traffic Director 相關的錯誤:您可能會在 Cloud Service Mesh 記錄或控制層指標中發現錯誤,指出連線、資源耗盡或 API 節流問題。
影響範圍:控制層問題通常會影響整個網格,導致效能大幅降低。
資料層級擴充問題的症狀
服務間通訊的延遲時間增加:對網格內服務的要求延遲時間或逾時時間增加,但服務容器的 CPU/記憶體用量並未增加。
Envoy 代理程式的 CPU 或記憶體用量偏高:CPU 或記憶體用量偏高可能表示代理程式難以處理流量負載。
區域性影響:資料平面問題通常會影響特定服務或工作負載,具體取決於 Envoy 代理程式的流量模式和資源用量。
擴充資料層
如要調整資料層的資源配置,請嘗試下列方法:
為工作負載設定水平 Pod 自動調度資源 (HPA)
使用水平 Pod 自動調度資源 (HPA),根據資源用量動態調度工作負載,並新增 Pod。設定 HPA 時,請考量下列事項:
使用
--horizontal-pod-autoscaler-sync-period參數kube-controller-manager調整 HPA 控制器的輪詢率。預設輪詢率為 15 秒,如果預期流量會快速飆升,可以考慮調低這個值。如要進一步瞭解何時應搭配 GKE 使用 HPA,請參閱「水平 Pod 自動調度資源」。預設的縮放行為可能會導致大量 Pod 同時部署 (或終止),進而造成資源用量暴增。建議使用資源調度政策,限制 Pod 的部署速率。
使用 EXIT_ON_ZERO_ACTIVE_CONNECTIONS,避免在縮減期間連線中斷。
如要進一步瞭解 HPA,請參閱 Kubernetes 說明文件中的「水平 Pod 自動調度」一文。
最佳化 Envoy Proxy 設定
如要最佳化 Envoy Proxy 設定,請參考下列建議:
資源限制
您可以在 Pod 規格中,為 Envoy Sidecar 定義資源要求和限制。這可避免資源爭用,並確保效能一致。
您也可以使用資源註解,為網格中的所有 Envoy 代理程式設定預設資源限制。
Envoy Proxy 的最佳資源限制取決於流量、工作負載複雜度和 GKE 節點資源等因素。持續監控及微調服務網格,確保達到最佳效能。
重要考量:
- 服務品質 (QoS):同時設定要求和限制,可確保 Envoy Proxy 具有可預測的服務品質。
範圍服務依附元件
請考慮透過 Sidecar API 宣告所有依附元件,藉此修剪網格的依附元件關係圖。這會限制傳送至特定工作負載的設定大小和複雜度,對於較大的網格而言至關重要。
舉例來說,以下是線上精品店範例應用程式的流量圖。
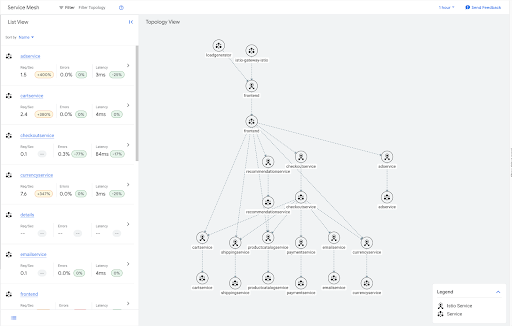
這些服務大多是圖表中的葉節點,因此不需要網格中任何其他服務的輸出資訊。您可以套用 Sidecar 資源,限制這些葉子服務的 Sidecar 設定範圍,如下列範例所示。
apiVersion: networking.istio.io/v1beta1
kind: Sidecar
metadata:
name: leafservices
namespace: default
spec:
workloadSelector:
labels:
app: cartservice
app: shippingservice
app: productcatalogservice
app: paymentservice
app: emailservice
app: currencyservice
egress:
- hosts:
- "~/*"
如要進一步瞭解如何部署這個範例應用程式,請參閱「Online Boutique 範例應用程式」。
側車範圍的另一項優點是減少不必要的 DNS 查詢。設定服務依附元件的範圍,可確保 Envoy 補充 Proxy 只會查詢實際要通訊的服務,而不是服務網格中的每個叢集。
如果大規模部署作業的 Sidecar 中有大型設定,導致發生問題,強烈建議您設定服務依附元件的範圍,以提升網格的可擴充性。
如要限制單一命名空間內所有工作負載的設定範圍,請在該命名空間中建立一個 Sidecar 資源。這會指示該命名空間內的所有 Envoy Proxy,只接收自身命名空間中服務的設定。
apiVersion: networking.istio.io/v1beta1
kind: Sidecar
metadata:
name: sidecar
namespace: my-app
spec:
egress:
- hosts:
- "my-app/*"
如要為網格中的每個命名空間套用預設行為,請將單一 Sidecar 資源套用至根命名空間 (通常是 istio-system)。
下列 Sidecar 會將網格中每個 Sidecar 的輸出流量限制在自身命名空間內的服務。
apiVersion: networking.istio.io/v1beta1
kind: Sidecar
metadata:
name: sidear
namespace: istio-system
spec:
egress:
- hosts:
- "./*"
請注意,Cloud Service Mesh 對單一網格中可建立的 Sidecar 資源總數設有限制。因此建議您建立命名空間層級的 Sidecar。
監控及微調
設定初始資源限制後,請務必監控 Envoy 代理程式,確保效能達到最佳狀態。使用 GKE 資訊主頁監控 CPU 和記憶體用量,並視需要調整資源限制。
如要判斷 Envoy 代理程式是否需要提高資源限制,請監控其在一般和尖峰流量條件下的資源消耗量。請注意以下事項:
CPU 使用率偏高:如果 Envoy 的 CPU 使用率持續接近或超過上限,可能難以處理要求,導致延遲增加或要求遭到捨棄。建議您提高 CPU 上限。
在這種情況下,您可能會傾向使用水平擴充功能進行擴充,但如果 Sidecar 代理程式持續無法像應用程式容器一樣快速處理要求,調整 CPU 限制可能會產生最佳結果。
記憶體用量偏高:如果 Envoy 的記憶體用量接近或超過限制,可能會開始捨棄連線,或發生記憶體不足 (OOM) 錯誤。請提高記憶體上限,避免發生這些問題。
錯誤記錄:檢查 Envoy 的記錄,找出與資源耗盡相關的錯誤,例如上游連線錯誤、在標頭之前中斷連線或重設,或開啟的檔案過多錯誤。這些錯誤可能表示 Proxy 需要更多資源。如要瞭解與資源調度問題相關的其他錯誤,請參閱資源調度疑難排解文件。
成效指標:監控要求延遲時間、錯誤率和輸送量等主要成效指標。如果發現效能降低與資源使用率偏高有關,可能就需要提高限制。
主動設定及監控資料層代理程式的資源限制,可確保服務網格在 GKE 上有效擴充。
調整控制層規模
本節說明如何調整設定,以便擴充控制層。
探索選取器
探索選取器是 MeshConfig 中的欄位,可讓您指定控制平面在計算 Sidecar 的設定更新時,會考量的命名空間集。
根據預設,Cloud Service Mesh 會監控叢集中的所有命名空間。對於不需要監控所有資源的大型叢集,這可能會造成瓶頸。
使用 discoverySelectors 限制監控和處理的 Kubernetes 資源 (例如服務、Pod 和端點) 數量,藉此減少控制平面的運算負載。
使用 TRAFFIC_DIRECTOR 控制平面實作時,Cloud Service Mesh 只會為 discoverySelectors 中指定的命名空間建立 Kubernetes 資源 (例如 Backend Service 和網路端點群組)。 Google Cloud
詳情請參閱 Istio 說明文件中的探索選取器。
建構韌性
您可以調整下列設定,在服務網格中建構韌性:
離群值偵測
異常情況偵測功能會監控上游服務中的主機,並在達到錯誤門檻時,將主機從負載平衡集區中移除。
- 重要設定:
outlierDetection:這些設定可以控管是否將健康狀態不良的主機從負載平衡集區中移除。
- 優點:在負載平衡集區中維持一組健康狀態良好的主機。
詳情請參閱 Istio 說明文件中的「離群值偵測」。
重試
自動重試失敗的要求,減少暫時性錯誤。
- 重要設定:
attempts:重試次數。perTryTimeout:每次重試的逾時時間。設定的時間必須短於整體逾時時間。這項設定會決定每次重試嘗試的等待時間。retryBudget:並行重試次數上限。
- 優點:要求成功率更高,間歇性失敗的影響較小。
考量因素:
- 冪等性:請確保重試的作業是冪等作業,也就是可以重複執行,不會產生非預期的副作用。
- 重試次數上限:限制重試次數 (例如最多重試 3 次),避免無限迴圈。
- 斷路:整合重試與斷路器,防止服務持續失敗時重試。
詳情請參閱 Istio 說明文件中的「重試」。
逾時
使用逾時來定義要求處理允許的最長時間。
- 重要設定:
timeout:特定服務的要求逾時。idleTimeout:連線在關閉前可保持閒置的時間。
- 優點:提升系統回應速度、防止資源洩漏、防範惡意流量。
考量因素:
- 網路延遲:考量服務之間的預期封包往返時間 (RTT)。預留緩衝時間,以因應意外延誤。
- 服務依附元件圖表:如果是鏈結要求,請確保呼叫服務的逾時時間短於其依附元件的累計逾時時間,以免發生連鎖故障。
- 作業類型:長時間執行的工作可能需要比資料擷取更長的逾時時間。
- 錯誤處理:逾時應觸發適當的錯誤處理邏輯 (例如重試、備援、斷路)。
詳情請參閱 Istio 說明文件中的「逾時」。
監控及微調
建議您先使用逾時、離群值偵測和重試的預設設定,然後根據特定服務需求和觀察到的流量模式,逐步調整這些設定。舉例來說,您可以查看服務通常需要多久才能回應的實際資料。然後調整逾時時間,以符合各項服務或端點的特定特徵。
遙測
使用遙測技術持續監控服務網格,並調整其設定,以提升效能和可靠性。
- 指標:使用全面指標,特別是要求量、延遲時間和錯誤率。與 Cloud Monitoring 整合,以進行視覺化和設定快訊。
- 分散式追蹤:啟用與 Cloud Trace 的分散式追蹤整合功能,深入瞭解服務間的要求流程。
- 記錄:設定存取記錄,擷取要求和回應的詳細資訊。
延伸閱讀
- 如要進一步瞭解 Cloud Service Mesh,請參閱 Cloud Service Mesh 總覽。
- 如需有關可擴充性的一般網站穩定性工程 (SRE) 指引,請參閱 Google SRE 書籍中的「處理過載」和「解決連鎖故障」章節。