Ce document présente un abonnement BigQuery, son workflow et les propriétés associées.
Un abonnement BigQuery est un type d'abonnement d'exportation qui écrit les messages dans une table BigQuery existante à mesure qu'ils sont reçus. Vous n'avez pas besoin de configurer un client abonné distinct. Utilisez la console Google Cloud , Google Cloud CLI, les bibliothèques clientes ou l'API Pub/Sub pour créer, modifier, lister, dissocier ou supprimer un abonnement BigQuery.
Sans le type d'abonnement BigQuery, vous avez besoin d'un abonnement pull ou push et d'un abonné (tel que Dataflow) qui lit les messages et les écrit dans une table BigQuery. Les frais généraux liés à l'exécution d'un job Dataflow ne sont pas nécessaires lorsque les messages ne nécessitent pas de traitement supplémentaire avant d'être stockés dans une table BigQuery. Vous pouvez utiliser un abonnement BigQuery à la place.
Toutefois, un pipeline Dataflow est toujours recommandé pour les systèmes Pub/Sub où une transformation des données est requise avant que les données ne soient stockées dans une table BigQuery. Pour savoir comment transférer des données par flux de Pub/Sub vers BigQuery avec transformation à l'aide de Dataflow, consultez Transférer des données par flux de Pub/Sub vers BigQuery.
Le modèle d'abonnement Pub/Sub vers BigQuery de Dataflow applique par défaut la distribution de type "exactement une fois". Cela se fait généralement grâce à des mécanismes de déduplication dans le pipeline Dataflow. Toutefois, l'abonnement BigQuery n'est compatible qu'avec la distribution sans faute au minimum d'une fois. Si la déduplication exacte est essentielle pour votre cas d'utilisation, envisagez d'utiliser des processus en aval dans BigQuery pour gérer les doublons potentiels.
Avant de commencer
Avant de lire ce document, assurez-vous de connaître les éléments suivants :
Le fonctionnement de Pub/Sub et les différents termes Pub/Sub.
Les différents types d'abonnements compatibles avec Pub/Sub et les raisons pour lesquelles vous pouvez utiliser un abonnement BigQuery.
Fonctionnement de BigQuery, et configuration et gestion des tables BigQuery.
Workflow d'abonnement BigQuery
L'image suivante illustre le workflow entre un abonnement BigQuery et BigQuery.
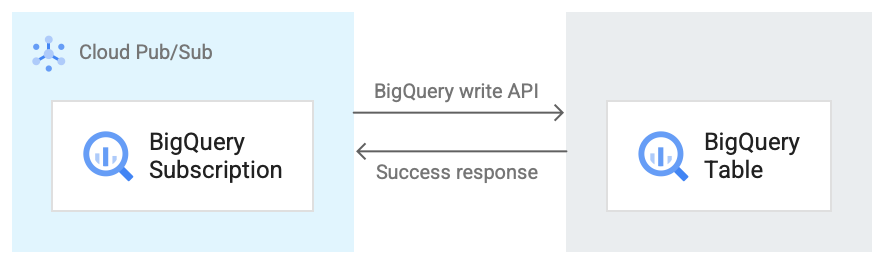
Voici une brève description du workflow qui fait référence à la figure 1 :
- Pub/Sub utilise l'API BigQuery Storage Write pour envoyer des données à la table BigQuery.
- Les messages sont envoyés par lots à la table BigQuery.
- Une fois une opération d'écriture terminée, l'API renvoie une réponse "OK".
- En cas d'échec de l'opération d'écriture, le message Pub/Sub lui-même est accusé de réception négativement. Le message est ensuite renvoyé. Si le message échoue un nombre suffisant de fois et qu'un sujet de lettres mortes est configuré sur l'abonnement, le message est déplacé vers le sujet de lettres mortes.
Propriétés d'un abonnement BigQuery
Les propriétés que vous configurez pour un abonnement BigQuery déterminent la table BigQuery dans laquelle Pub/Sub écrit les messages et le type de schéma de cette table.
Pour en savoir plus, consultez Propriétés BigQuery.
Compatibilité du schéma
Cette section ne s'applique que si vous sélectionnez l'option Utiliser un schéma avec sujet lorsque vous créez un abonnement BigQuery.
Pub/Sub et BigQuery utilisent différentes méthodes pour définir leurs schémas. Les schémas Pub/Sub sont définis au format Apache Avro ou Protocol Buffer, tandis que les schémas BigQuery sont définis à l'aide de différents formats.
Vous trouverez ci-dessous une liste d'informations importantes concernant la compatibilité des schémas entre un sujet Pub/Sub et une table BigQuery.
Tout message contenant un champ mal formaté n'est pas écrit dans BigQuery.
Dans le schéma BigQuery,
INT,SMALLINT,INTEGER,BIGINT,TINYINTetBYTEINTsont des alias pourINTEGER,DECIMALest un alias pourNUMERICetBIGDECIMALest un alias pourBIGNUMERIC.Lorsque le type dans le schéma du sujet est
stringet que le type dans la table BigQuery estJSON,TIMESTAMP,DATETIME,DATE,TIME,NUMERICouBIGNUMERIC, toute valeur pour ce champ dans un message Pub/Sub doit respecter le format spécifié pour le type de données BigQuery.Certains types logiques Avro sont acceptés, comme indiqué dans le tableau suivant. Tous les types logiques non listés ne correspondent qu'au type Avro équivalent qu'ils annotent, comme indiqué dans la spécification Avro.
Vous trouverez ci-dessous une collection de mappages de différents formats de schéma vers les types de données BigQuery.
Types Avro
| Type Avro | Type de données BigQuery |
null |
Any NULLABLE |
boolean |
BOOLEAN |
int |
INTEGER, NUMERIC ou BIGNUMERIC |
long |
INTEGER, NUMERIC ou BIGNUMERIC |
float |
FLOAT64, NUMERIC ou BIGNUMERIC |
double |
FLOAT64, NUMERIC ou BIGNUMERIC |
bytes |
BYTES, NUMERIC ou BIGNUMERIC |
string |
STRING, JSON,
TIMESTAMP, DATETIME,
DATE, TIME,
NUMERIC ou BIGNUMERIC |
record |
RECORD/STRUCT |
array sur Type |
REPEATED Type |
map avec le type de valeur ValueType
|
REPEATED STRUCT <key STRING, value
ValueType> |
union avec deux types, l'un null et l'autre Type |
NULLABLE Type |
autres union |
Non mappable |
fixed |
BYTES, NUMERIC ou BIGNUMERIC |
enum |
INTEGER |
Types logiques Avro
| Type logique Avro | Type de données BigQuery |
timestamp-micros |
TIMESTAMP |
date |
DATE |
time-micros |
TIME |
duration |
INTERVAL |
decimal |
NUMERIC ou BIGNUMERIC |
Types de Protocol Buffer
| Type de tampon de protocole | Type de données BigQuery |
double |
FLOAT64, NUMERIC ou BIGNUMERIC |
float |
FLOAT64, NUMERIC ou BIGNUMERIC |
int32 |
INTEGER, NUMERIC, BIGNUMERIC ou DATE |
int64 |
INTEGER, NUMERIC,
BIGNUMERIC, DATE,
DATETIME ou TIMESTAMP |
uint32 |
INTEGER, NUMERIC, BIGNUMERIC ou DATE |
uint64 |
NUMERIC ou BIGNUMERIC |
sint32 |
INTEGER, NUMERIC ou BIGNUMERIC |
sint64 |
INTEGER, NUMERIC,
BIGNUMERIC, DATE,
DATETIME ou TIMESTAMP |
fixed32 |
INTEGER, NUMERIC, BIGNUMERIC ou DATE |
fixed64 |
NUMERIC ou BIGNUMERIC |
sfixed32 |
INTEGER, NUMERIC, BIGNUMERIC ou DATE |
sfixed64 |
INTEGER, NUMERIC,
BIGNUMERIC, DATE,
DATETIME ou TIMESTAMP |
bool |
BOOLEAN |
string |
STRING, JSON,
TIMESTAMP, DATETIME,
DATE, TIME,
NUMERIC ou BIGNUMERIC |
bytes |
BYTES, NUMERIC ou BIGNUMERIC |
enum |
INTEGER |
message |
RECORD/STRUCT |
oneof |
Non mappable |
map<KeyType, ValueType> |
REPEATED RECORD<key KeyType, value
ValueType> |
enum |
INTEGER |
repeated/array of Type |
REPEATED Type |
Représentation entière de la date et de l'heure
Lorsque vous mappez un nombre entier à l'un des types de date ou d'heure, le nombre doit représenter la valeur correcte. Vous trouverez ci-dessous le mappage des types de données BigQuery vers l'entier qui les représente.
| Type de données BigQuery | Représentation sous forme d'entier |
DATE |
Nombre de jours écoulés depuis l'époque Unix, le 1er janvier 1970 |
DATETIME |
Date et heure en microsecondes exprimées en heure civile à l'aide de CivilTimeEncoder. |
TIME |
Heure en microsecondes exprimée en heure civile à l'aide de CivilTimeEncoder |
TIMESTAMP |
Nombre de microsecondes écoulées depuis l'epoch Unix (1er janvier 1970 à 00:00:00 UTC) |
Capture des données modifiées BigQuery
Les abonnements BigQuery sont compatibles avec les mises à jour de la capture des données modifiées (CDC, Change Data Capture) lorsque use_topic_schema ou use_table_schema est défini sur true dans les propriétés de l'abonnement. Pour utiliser la fonctionnalité avec use_topic_schema, définissez le schéma du sujet avec les champs suivants :
_CHANGE_TYPE(obligatoire) : champstringdéfini surUPSERTouDELETE.Si un message Pub/Sub écrit dans la table BigQuery a la valeur
UPSERTpour_CHANGE_TYPE, BigQuery met à jour la ligne avec la même clé si elle existe, ou insère une nouvelle ligne si elle n'existe pas.Si un message Pub/Sub écrit dans la table BigQuery a la valeur
DELETEpour_CHANGE_TYPE, BigQuery supprime la ligne de la table avec la même clé, le cas échéant.
_CHANGE_SEQUENCE_NUMBER(facultatif) : champstringdéfini pour s'assurer que les mises à jour et les suppressions apportées à la table BigQuery sont traitées dans l'ordre. Les messages pour la même clé de ligne doivent contenir une valeur qui augmente de façon linéaire pour_CHANGE_SEQUENCE_NUMBER. Les messages dont le numéro de séquence est inférieur au numéro de séquence le plus élevé traité pour une ligne n'ont aucun effet sur la ligne de la table BigQuery. Le numéro de séquence doit respecter le format_CHANGE_SEQUENCE_NUMBER.
Pour utiliser cette fonctionnalité avec use_table_schema, incluez les champs précédents dans le message JSON.
Pour en savoir plus sur les tarifs de CDC, consultez la page Tarifs de CDC.
Tables BigLake pour Apache Iceberg dans BigQuery
Les abonnements BigQuery peuvent être utilisés avec les tables BigLake pour Apache Iceberg dans BigQuery sans aucune modification supplémentaire.
Les tables BigLake pour Apache Iceberg dans BigQuery constituent la base de la création de lakehouses au format ouvert sur Google Cloud. Ces tables offrent la même expérience entièrement gérée que les tables BigQuery standards (intégrées), mais stockent les données dans des buckets de stockage détenus par le client, en passant par Parquet afin d'assurer l'interopérabilité avec les formats de table ouverts Iceberg.
Pour savoir comment créer des tables BigLake pour Apache Iceberg dans BigQuery , consultez Créer une table Iceberg.
Gérer les échecs de messages
Lorsqu'un message Pub/Sub ne peut pas être écrit dans BigQuery, il ne peut pas être confirmé. Pour transférer ces messages non distribuables, configurez un sujet de lettres mortes sur l'abonnement BigQuery. Le message Pub/Sub transféré vers la file d'attente de lettres mortes contient un attribut CloudPubSubDeadLetterSourceDeliveryErrorMessage qui indique la raison pour laquelle le message Pub/Sub n'a pas pu être écrit dans BigQuery.
Si Pub/Sub ne peut pas écrire de messages dans BigQuery, il reporte la distribution des messages de la même manière que le comportement de report des notifications push. Toutefois, si un sujet de lettres mortes est associé à l'abonnement, Pub/Sub ne réduit pas la distribution lorsque les échecs de messages sont dus à des erreurs de compatibilité de schéma.
Quotas et limites
Le débit des abonnés BigQuery est soumis à des limites de quota par région. Pour en savoir plus, consultez Quotas et limites de Pub/Sub.
Les abonnements BigQuery écrivent des données à l'aide de l' API BigQuery Storage Write. Pour en savoir plus sur les quotas et limites de l'API Storage Write, consultez la page Requêtes de l'API BigQuery Storage Write. Les abonnements BigQuery ne consomment que le quota de débit de l'API Storage Write. Dans ce cas, vous pouvez ignorer les autres considérations concernant le quota de l'API Storage Write.
Tarifs
Pour connaître les tarifs des abonnements BigQuery, consultez la page des tarifs de Pub/Sub.
Étapes suivantes
Créez un abonnement, tel qu'un abonnement BigQuery.
Résolvez les problèmes liés à un abonnement BigQuery.
En savoir plus sur BigQuery
Consultez les tarifs de Pub/Sub, y compris les abonnements BigQuery.
Créez ou modifiez un abonnement à l'aide des commandes
gcloudCLI.Créez ou modifiez un abonnement avec les API REST.