This guide provides an understanding and an overall picture of Pub/Sub reliability features.
Why Pub/Sub?
As a messaging paradigm, publish-subscribe is designed to decouple the producers of messages from the consumers of those messages. Instead of producers sending direct requests to the consumers with the data, they instead publish that data to a Pub/Sub service like Pub/Sub. The service asynchronously delivers those messages to interested consumers that have subscribed.
The result is that the service absorbs all of the intricacies of finding consumers that are interested in the data. The service also manages the rate at which the consumers receive the data, based on their capacity. The decoupling allows data producers to write messages at high scale with low latency, independent of the behavior of the consumers.
Pub/Sub offers highly scalable, reliable delivery of messages. While the service handles much of this automatically, you have control over different aspects of your publishers and subscribers that can affect availability and performance. The rest of this guide provides some details on these aspects.
Isolation
By default, Pub/Sub is a global service: topics and subscriptions
are not inherently tied to specific regions, and messages flow within the
Pub/Sub service between regions when needed. When using the
global endpoint,
pubsub.googleapis.com, publishers and subscribers connect to the
network-nearest region where Pub/Sub runs. When using the
regional endpoints,
such as us-central1-pubsub.googleapis.com, or
locational endpoints,
such as pubsub.us-central1.rep.googleapis.com, publishers and subscribers
connect to Pub/Sub in the specified region. When running
publishers or subscribers outside of Google Cloud, it is best to use
regional or locational endpoints in order to ensure messages flow among the
expected regions consistently.
Regional Isolation
To minimize the infrastructure that publish and subscribe operations depend on outside a single region and to ensure that all data stays isolated to that region, follow these steps:
Create a topic per region.
While Pub/Sub's namespace is global and you cannot tie topics and subscriptions to a specific region, metadata for all resources is replicated to local data stores within the region. Therefore, once you create a resource, its configuration is available even in the event of an issue in another region. Note that updates to the topic or subscription configurations may not propagate immediately in the event of an outage.
Avoid using global endpoints.
Instead, use regional endpoints where available and locational endpoints where regional endpoints are not available. Regional endpoints offer more regional isolation, but are not yet available in all regions.
Use a message storage policy and set
enforceInTransittoTrue.With Enforce in transit enabled, data never leaves the region and all clients that connect to the topic in a specific region, set the message storage policy to that region.
With topics configured in this way, you can be sure that all publish and subscribe operations write and read data exclusively within the region. In the event of publisher, subscriber, or Pub/Sub failures in a single region, message delivery stops in that region. Message delivery on topics and subscriptions for other regions are unaffected.
If you need the administrative operations and the namespace of your topics and subscriptions to be regionally isolated as well, consider using Managed Service for Apache Kafka.
Failover
If you don't need regional isolation, you may want to take advantage of Pub/Sub's ability to deliver messages efficiently across multiple regions in order to achieve multi-region failover capabailities. The rest of this section talks about how to create topics and subscriptions and place publishers and subscribers in order to support different kinds of failover and data redundancy.
Default failover semantics
Consider a case where there is a single topic and subscription. Publishers are located in regions of the United States and Australia, and subscribers are located in the Google Cloud regions of Europe and Australia. In the case where all subscribers have enough capacity to receive messages, the flow of messages looks like this:
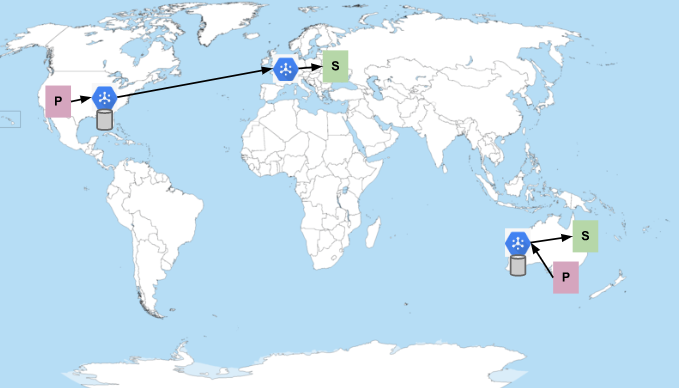
The P's represent publishers, the S's represent subscribers. The blue hexagon represents the Pub/Sub service. The cylinders represent the places where messages are stored (messages are always persisted to multiple zones in the region where they are published). Pub/Sub prefers to send messages within the same region where they were published when subscribers are available. Otherwise, it sends the messages to the network-nearest region with subscribers that have capacity. Therefore, as shown in the previous image, messages published in the United States are delivered to subscribers in Europe and messages published within Australia stay in Australia.
The following sections discuss what happens in different failure scenarios.
Subscribers in Europe are unavailable
Assume subscribers in Europe were turned down, or crashing frequently, and unable to maintain a connection to Pub/Sub. If this occurred, the service would start to deliver messages to subscribers in Australia:
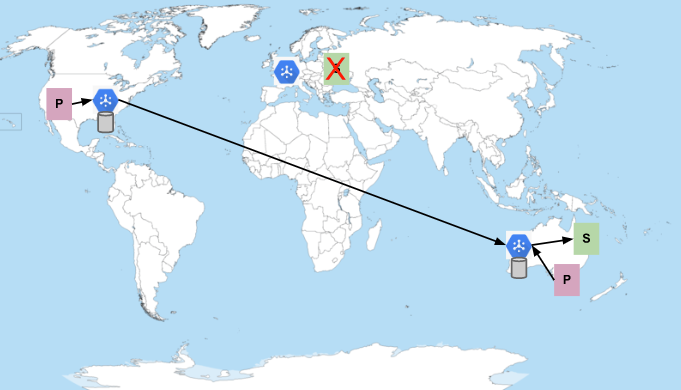
Subscribers in Europe and Australia are unavailable
In the event all subscribers are unavailable, then Pub/Sub stores the messages up to the configured message retention duration.
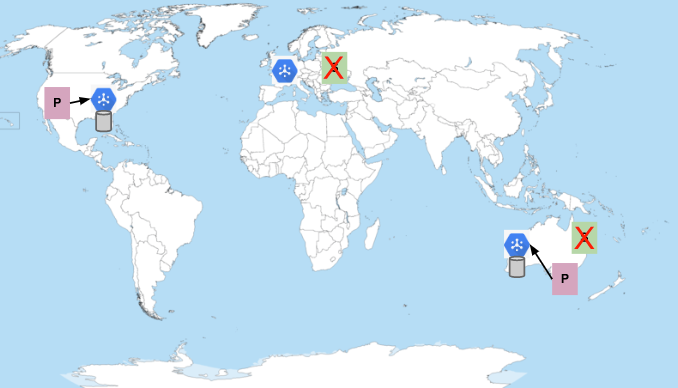
Once the subscribers reconnect, the messages are delivered unless the outage lasts longer than the configured message retention duration. By default, subscription message retention is set to 7 days. You can also configure message retention on a topic for up to 31 days. Don't choose a message retention duration shorter than the maximum outage you expect or are willing to tolerate.
Pub/Sub is unavailable in Europe
Although rare, you may also want to deal with cases where Pub/Sub itself is unavailable. Unavailability of Pub/Sub manifests itself as extended periods of unexpected errors on publish or subscribe requests, or the inability to deliver published messages to subscribers. For example, if Pub/Sub were down in the region in Europe, then the scenario looks much the same as when subscribers are down:

Note that in this case, the subscribers in Europe don't fail over to another region, even if using the global endpoint. Pub/Sub intentionally does not fail over automatically. Imagine it is the subscribers themselves that are causing an unexpected issue in Pub/Sub that results in unavailability. Such an issue is treated as a major outage. However, the scope of impact of the outage can be contained to the region to which the subscribers connected. If the service allowed them to fail over to another region, the subscribers could also cause unavailability there, resulting in a cascading failure across the service.
Publishers in Australia are unavailable
If the publishers in one region become unavailable, the messages that are already published are still delivered to the nearest subscribers:

Eventually, all messages are consumed and acknowledged by subscribers. When sending messages, Pub/Sub tries to minimize the network distance. Therefore, the subscribers in the region in Australia can stop receiving messages if the subscribers in Europe have enough capacity to handle all of the messages published in the United States.
Pub/Sub is unavailable in the United States
Pub/Sub synchronously writes messages to multiple zones within a region. Therefore, a zonal outage isn't sufficient to prevent the delivery of messages; the entire region has to be unavailable. If Pub/Sub becomes unavailable in a region where publishers are sending messages, then messages in that region may not be delivered until service is fully restored:

The message is still ultimately delivered (assuming the message retention period has not passed), delayed by the duration of the outage. Note that similar to subscribers, the publishers in the United States also don't fail over to another region when the service fails. This behavior helps prevent the likelihood of cascading failures across regions due to a faulty publisher or subscriber.
Customer-controlled failover and redundancy
The default failover semantics of Pub/Sub may not fully guarantee that messages can always flow from publishers to subscribers if there is an outage anywhere in between. Outages could occur in several different places including your clients, in the service on which your publishers or subscribers run, in the network, or even rarely in Pub/Sub itself. If you need your services to be resilient to such outages, you must implement your own redundancies. Typically, these redundancies include the use of multiple instances of publisher and subscriber clients where each uses a different locational endpoint.
You may want resiliency to two different scopes of impact: zonal or regional. Here are the setup options for each.
Zonal resiliency
Pub/Sub has built-in cross-zonal replication. You don't have to take any special steps to deal with single-zone outages that affect the service itself. However, to have resiliency to outages for your clients or network, it is best to run publishers and subscribers with sufficient capacity in multiple zones within the region. If a single zone is down, then the clients in the other zone is able to pick up the traffic and process the messages. It is a best practice to not publish changes to these clients simultaneously so that if a bug is introduced, the other, untouched zones can continue to process messages.
Regional resiliency
In order to be resilient to regional failures, set up additional redundancies in your publishers and subscribers. You can run publishers and subscribers in multiple regions to deal with the possibility of outages in those clients or in networking.
If you want to be resilient against potential Pub/Sub failures in a region, then you must have a failover mechanism ready to deal with such an outage. The possible approaches are a tradeoff between end-to-end message delivery latency and your cost.
To minimize latency in the event that cost is not a concern, then the best strategy is to always publish and subscribe simultaneously in different regions. First, choose the number of regions in which you want redundancy. Next, though not strictly necessary, you can set up a topic and subscription for each of those regions.
Each publisher creates as many publisher clients as there are regions (one for each region) and uses a different locational endpoint to ensure messages are directed to distinct regions. If using separate topics, each publisher client must publish to the corresponding, per-region topic. For every message, the publisher calls publish on each client. With the redundant publishes, there is no need to retry publishes if any single one fails.
Similarly, each subscriber creates that many subscriber clients--one for each region--and uses a locational endpoint to connect to a different region. If using different subscriptions for each region, each subscriber client must use the corresponding subscription. Note that the regions used for publishers and subscribers don't necessarily have to be the same. Subscribers receive messages across the three subscriptions and process them.
This setup has several key features and requirements:
- Any single-region outage does not affect the processing of messages already published, nor those published during the outage. Since messages were published to multiple regions, they are still available in other regions in the event one region was down. During the outage, publish calls fail in the affected region, but succeed in the others.
- Message processing latency is not affected as long as any of the regions through which messages are flowing is available.
- Message processing must be idempotent. Since every message is going to be delivered multiple times, the message processing must be resilient to duplicates. In the event of a regional outage, some of those duplicates may come much later than the first time the message was delivered. Those duplicates likely came from a different region that was not experiencing an outage.
Running with this kind of redundancy provides the highest resiliency to any kind of outages. For internal Google services that rely on Pub/Sub and require the highest availability, this setup is preferred. However, this setup comes with the tradeoff of multiplying the cost for message delivery by the number of regions used. There is also the additional cost of inter-regional network usage for messages that have to move across regions.
Another approach to redundancy is to only fail over when requests fail or messages are not flowing from publishers to subscribers as expected. In this scenario, you have a primary region to which you direct your publishers and subscribers through locational endpoints. As before, these don't have to be the same region. You also then have a fallback region for publishers and subscribers that is used when the primary region is unavailable.
Publishers publish only to the primary region (through the locational endpoint) when its requests are sent successfully. Whenever the region is determined to be down, publishers instead start publishing to the fallback region. Determining that the region is down and failing over can be done in two ways. It can be done by a manual process, and the configuration being dynamically updated in the publishers. The publishers can also update the configuration themselves if the error rate in publish requests is sufficiently high.
Subscribers must always connect to the primary region through the locational endpoint. You can decide that the subscriber can use the fallback region with one or more of the following triggers:
- Always subscribe to the fallback region. In this case, the subscriber maintains a connection to both the primary region and fallback region at all times. The same regions can be used for the primary and fallback for both publishers and subscribers. If this is the case, then the subscriber must only receive messages through the backup region if the publisher failed over.
- Manually detect and switch the subscribers to the fallback region through a configuration. If you detect an outage, you can fail over to the fallback region and then move back to the primary region when the outage has subsided.
- Fail over on subscriber errors. If the subscriber requests are returning errors, you can use this as an indication that you must fail over to the fallback region. Note that the Pub/Sub client libraries retry streaming pull requests internally on transient errors, so you may not be able to detect that there are long periods of unexpected errors. Additionally, the streaming pull error rate is expected to be 100%, even during normal operation.
- Fail over if the subscriber goes through an unexpectedly long time without receiving messages. Assuming there is consistent publishing of messages, the subscribers can always be receiving messages. If they go through an extended period of time without receiving any messages, there may be a subscribe-side issue in Pub/Sub in the primary region. This is fixed by failing over to the fallback region.
Of all four options, the first one is ideal. A subscriber connection does not cost any money if there are no messages flowing on it. The only cost is in the footprint of the additional instance of the subscriber client library, which can be negligible. You also must be mindful of the number of open streaming pull connections per region quota.
The advantage of this second model is that there is not a multiplier in the Pub/Sub cost since messages are only published once. However, the tradeoff is that for certain types of outages, messages published before the outage began may not be available until after the outage is resolved. Messages stored in the region that is unavailable may not be able to be delivered to subscribers, regardless of where they are connected. Messages published during the outage to the fallback region can be available. Additionally, there may be a period of unavailability with increased error rates for the publishers or the subscribers. This depends on the method used to detect an outage and the time to fail over to the fallback region.
No matter which option you choose, be aware of how this may interact with features of Pub/Sub. Both ordered delivery and exactly once delivery offer their guarantees within a region. For example, if you use the failover redundancy technique, message delivery is only guaranteed to be in order for messages published in the same region. The subscriber could receive messages published to the fallback region before messages published to the primary region, even if the messages were published to the primary region first.
Fine-tuning publishers
No matter which of the failover options you choose, there are some additional tuning steps you want to take within publishers themselves. Tuning publisher behavior ensures optimal performance under high load. Batching messages is a way to trade off latency for reduced cost, but isn't so much a reliability concern and therefore is not covered here. Instead, focus on some of the other parameters that are useful to tune for reliability including retry settings and flow control settings.
Publishes may fail for different reasons, including transient ones like network unavailability or ones that require user intervention like permission changes. The Pub/Sub client library retries transient errors using the parameters specified in the retry settings. These settings control the behavior of the exponential backoff on retries of publish RPCs that fail for transient reasons. While the default settings can typically work well in most scenarios, there are situations where you might want to tune these values.
The two properties you are most likely to want to tune are the initial RPC timeout and the total timeout. The initial RPC timeout is how long the first publish RPC is given to complete. If any RPC fails or times out, another is tried with a longer timeout until the total number of requests or the total timeout is exceeded.
The initial timeout can be tuned if your publisher is network constrained or far away from the nearest Google Cloud data center that runs Pub/Sub. Network constraints could be limitations on throughput of the machine the publisher is running on or could be the result of other services running on the same machine that are network-intensive. With the timeout set too short, initial RPCs could fail repeatedly, resulting in more attempts (with longer timeouts) being necessary to publish successfully. The repeated need for retries increases publish latency. In this situation, increasing the initial timeout could result in faster publishes.
If the network connection is unreliable, increasing the total timeout as well as the initial timeout could help. An increased total timeout givesthe publish RPC more time to complete successfully. When publish RPCs consistently fail with deadline exceeded errors, consider tuning these values.
Continuous deadline exceeded errors on publish may also indicate the need to tune the publisher flow control. These settings allow you to ensure that your publishers are resilient to spikes of incoming traffic that generate more messages to be sent to Pub/Sub. A large increase in outgoing requests could overload the publisher's CPU, memory, or network capacity. When the publish is overloaded, it is unable to process publish requests or responses before the timeouts. This results in even more publish requests and ultimately, reaching the total timeout. The publisher flow control limits the number of messages or bytes that can be outstanding without a response from the publish request. Limiting the number of requests in this way keeps the resource utilization at a level that is manageable, even during spikes. Depending on how your publisher operates, you may allow subsequent publish RPCs to wait for capacity by allowing publish to block further requests. Alternatively, you can push back to the callers of your service by having flow control return an error when capacity is reached. You configure how the publisher client library responds with the limit exceeded behavior.
Fine-tuning subscribers
Subscriber tuning may also be necessary to ensure they operate reliably. Similar to publishers, you can tune the flow control settings of subscribers to ensure they don't get overwhelmed. The subscriber client library uses streaming pull, where the client opens a persistent stream to the server and the server sends messages as they become available. In the event of a large increase in published messages, the subscriber may receive more messages than it can process. With flow control in place, the number of unacknowledged messages outstanding to the client at a time is limited. This reduces the number of messages handled simultaneously and spreads out their processing over a longer period of time. Spreading the load out allows subscribers to stay under any resource limitations that impacts message processing, which may result in a cascade effect that develops into the inability to process any messages.
Flow control alone is sufficient if you only expect spikes in the amount of data to process that ultimately recede. If traffic is generally increasing over time due to more usage, flow control protects the subscribers. However, it may result in a backlog that continues to build up and leads to messages not being able to be delivered before the message retention duration passes. In such cases, you may also want to set autoscaling to turn up more subscribers in response to a growing number of unacknowledged messages. How you set this up depends on the compute platform you are using for your subscribers. For example, Compute Engine's autoscaler lets you scale based on metrics like the number of undelivered messages. Using both autoscaling and flow control lets you ensure that your subscribers are resilient to other short-term spikes in message throughput and longer-term growth that requires more compute power. Make sure you follow the Best practices for using Pub/Sub metrics as a scaling signal.
Use snapshot and seek for safe deployments
Message loss is usually a catastrophic event. Pub/Sub offers at-least-once delivery for all messages published. However, the correct processing of these messages depends on subscriber behavior. If messages are successfully acknowledged, Pub/Sub does not redeliver them. Therefore, a bug introduced in new subscriber code you deploy that acknowledges messages without having processed them correctly could result in subscriber-induced message loss. Pub/Sub offers the snapshot and seek feature, which can help you to ensure you process every message correctly, even in the face of subscriber bugs.
The pattern for every subscriber deployment must be as follows:
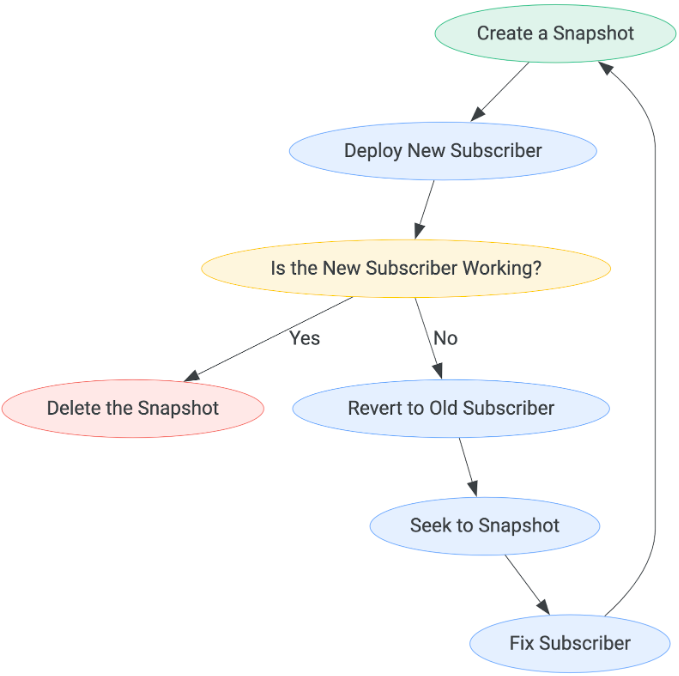
The amount of time to wait before determining if the new subscriber is working may vary based on your use case. The only way to exit the flow of steps is when a subscriber is deemed working, at which point the snapshot can be deleted.
The use of snapshot and seek is not meant to replace best practices around first running software in a non-prod environment and gradual deployment to production. They provide an additional level of protection to ensure the reliable processing of data. The tradeoff is that seeking to the snapshot may result in duplicate delivery of messages your subscriber did process successfully. However, given that Pub/Sub has at-least-once delivery semantics by default, your subscribers are already resilient to message redelivery.