El nivel Estándar de Memorystore para Redis te permite escalar las consultas de lectura de tu aplicación con réplicas de lectura. En esta página, se supone que conoces las diferentes capacidades de los niveles de Redis de Memorystore.
Las réplicas de lectura te permiten escalar tu carga de trabajo de lectura consultando las réplicas. Se proporciona un extremo de lectura para que las aplicaciones puedan distribuir consultas entre las réplicas con mayor facilidad. Para obtener más información, consulta Cómo escalar las lecturas con el extremo de lectura.
Si deseas obtener instrucciones para administrar una instancia de Redis con réplicas de lectura, consulta Administra réplicas de lectura.
Casos de uso de las réplicas de lectura
El almacén de sesiones, el ranking, el motor de recomendaciones y otros casos de uso requieren que la instancia tenga alta disponibilidad. En estos casos de uso, hay muchas más lecturas que escrituras, y, en general, se pueden tolerar algunas lecturas obsoletas. En casos como estos, tiene sentido aprovechar las réplicas de lectura para aumentar la disponibilidad y la escalabilidad de la instancia.
Comportamiento de la réplica de lectura
- Las réplicas de lectura no están habilitadas en las instancias de nivel Estándar de forma predeterminada.
- Una vez que se habilitan las réplicas de lectura en una instancia, ya no se pueden inhabilitar para esa instancia.
- Las instancias de nivel Estándar pueden tener de 1 a 5 réplicas de lectura.
- El extremo de lectura proporciona un solo extremo para distribuir las consultas entre los nodos de réplica.
- Las réplicas de lectura se mantienen con la replicación asíncrona de Redis.
Advertencias y limitaciones
- Las réplicas de lectura solo se admiten para tamaños de instancias con nodos de más de 5 GB.
- Las réplicas de lectura solo se pueden habilitar en instancias que usan la versión 5.0 de Redis o una posterior.
- Si designas una zona y una zona alternativa para aprovisionar nodos, Memorystore usará esas zonas para el primer y el segundo nodo de la instancia. Después de eso, Memorystore selecciona las zonas para todos los nodos restantes aprovisionados para la instancia.
- Debes aprovisionar la instancia con un rango de direcciones IP de CIDR de
/28o superior. Los tamaños de rango más grandes, como/27y/26, son válidos. Los rangos más pequeños, como/29, no son compatibles con esta función.
Arquitectura
Cuando habilitas réplicas de lectura, especificas la cantidad de réplicas que deseas en la instancia. Memorystore distribuye automáticamente los nodos principales y de réplica de lectura en las zonas disponibles de una región.
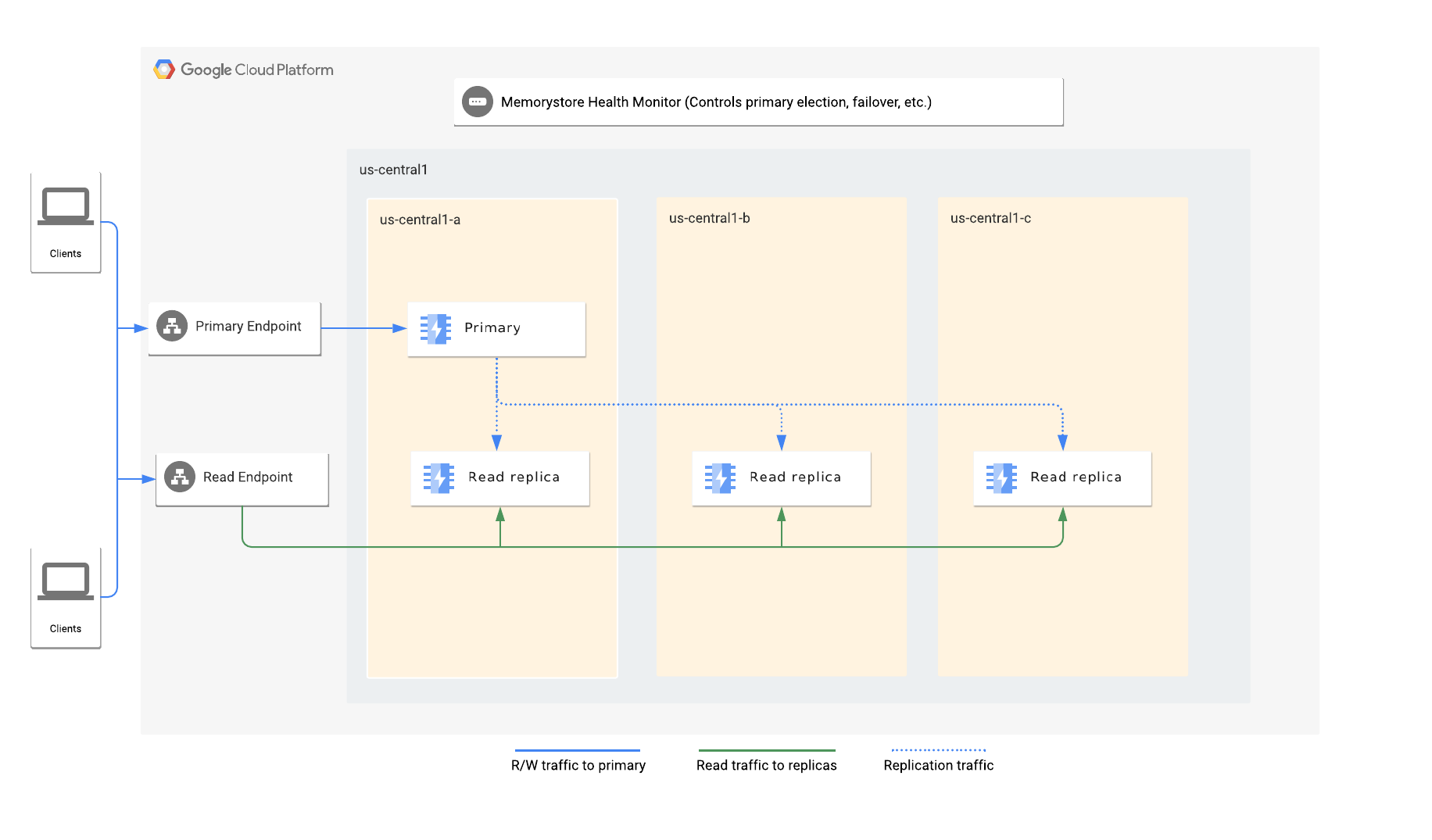
Cada instancia tiene un extremo principal y un extremo de lectura. El extremo principal siempre dirige el tráfico al nodo principal, mientras que el extremo de lectura balancea automáticamente la carga de las consultas de lectura en las réplicas disponibles.
El servicio de supervisión del estado de Memorystore para Redis supervisa la instancia y es responsable de detectar cualquier falla del nodo principal, elegir una réplica como el nuevo nodo principal y, luego, iniciar una conmutación por error automática al nuevo nodo principal.
Conmutaciones por error para instancias con réplicas de lectura
Cuando falla un nodo principal, el servicio de supervisión del estado de Memorystore inicia la conmutación por error, y el nuevo nodo principal queda disponible para lecturas y escrituras. Por lo general, la conmutación por error se completa en menos de 30 segundos.
Cuando ocurre una conmutación por error, el extremo principal redirecciona automáticamente el tráfico al nuevo principal. Sin embargo, todas las conexiones de cliente al extremo principal se desconectan durante una conmutación por error. Las aplicaciones con lógica de reintento de conexión se volverán a conectar automáticamente una vez que la nueva instancia principal esté en línea. Algunas de las conexiones del cliente al extremo de lectura también se desconectan de la réplica de lectura que se promueve a principal durante la conmutación por error. Las conexiones a las réplicas restantes se siguen atendiendo durante una conmutación por error. Cuando se reintenta, las conexiones se redireccionan a las réplicas nuevas.
Cuando se produce una conmutación por error, debido a la naturaleza asíncrona de la replicación, las réplicas pueden tener un retraso de replicación diferente. Sin embargo, el proceso de conmutación por error hace todo lo posible para conmutar por error a la réplica con el menor retraso. Esto ayuda a minimizar la cantidad de pérdida de datos y la reducción del rendimiento de lectura durante una conmutación por error. La instancia principal recién promovida puede estar en la misma zona o en una zona diferente que la instancia principal anterior. Se selecciona una réplica para que sea la nueva principal si se encuentra en la misma zona que la principal anterior y tiene el menor retraso. De lo contrario, una réplica de otra zona puede convertirse en la nueva principal.
Dado que la replicación es asíncrona, siempre existe la posibilidad de leer datos obsoletos durante una conmutación por error. Además, mientras se promueve la nueva instancia principal, es posible que se pierdan algunas escrituras en la instancia. Las aplicaciones deben poder controlar este comportamiento.
Redis hace todo lo posible para evitar que las otras réplicas requieran una sincronización completa durante la conmutación por error, pero esto puede ocurrir en situaciones excepcionales. Una sincronización completa puede tardar entre unos minutos y una hora, según la tasa de escritura y el tamaño del conjunto de datos que se replica. Durante este tiempo, las réplicas que se someten a una sincronización completa no están disponibles para las lecturas. Una vez que se completa la sincronización, se puede acceder a las réplicas para realizar lecturas.
Modos de falla para las réplicas de lectura
Las instancias con réplicas de lectura pueden experimentar varias fallas y condiciones no saludables que afectan la aplicación. El comportamiento varía según si la instancia tiene una réplica o dos o más. En esta sección, se describen algunos modos de falla comunes y el comportamiento de la instancia durante estas condiciones.
La réplica no está disponible
Cuando una réplica falla por cualquier motivo, se marca como no disponible y se finalizan todas las conexiones a ella después de un tiempo de espera determinado. Una vez que se recupera la réplica, las conexiones nuevas se enrutan a la réplica restablecida. El tiempo para recuperar una réplica varía según el modo de falla.
Si se produce una falla en la zona, Memorystore para Redis no recupera la réplica hasta que la zona esté disponible.
Falla de zona
Si falla la zona en la que se encuentra la instancia principal, esta se conmuta por error automáticamente a una réplica en otra zona. Si la instancia solo tiene una réplica, el extremo de lectura no estará disponible mientras dure la interrupción de la zona. Si la instancia tiene más de una réplica, las réplicas fuera de la zona afectada están disponibles para lecturas.
Si falla la zona en la que se encuentra una o más de las réplicas, esas réplicas no estarán disponibles mientras dure la falla de la zona. Si se produce una falla en dos zonas y hay dos o más réplicas, la réplica con el menor retraso en las zonas restantes se promueve a principal. Las réplicas restantes en las zonas no afectadas están disponibles para lecturas.
Partición de red
Una partición de red es una situación en la que los nodos siguen en ejecución, pero no pueden llegar a todos los clientes, las zonas o los nodos pares. Memorystore usa un sistema basado en quórum para evitar que los nodos aislados publiquen escrituras. En caso de una partición de red, cualquier instancia principal en una partición minoritaria se degrada automáticamente. La partición mayoritaria (si existe) elige un nuevo elemento principal si aún no tiene uno. Las réplicas aisladas siguen publicando lecturas. Sin embargo, es posible que se desactualicen si no se pueden sincronizar desde el servidor principal.
Para determinar si el vínculo está roto, supervisa las métricas master_link_down_since_seconds y offset_diff para identificar nodos aislados.
Sincronización completa
Cuando una réplica se retrasa demasiado con respecto a la principal, se activa una sincronización completa que copia una instantánea completa de la principal a una réplica. Esta operación puede tardar desde unos minutos hasta una hora en el peor de los casos. Una sincronización completa no provoca una falla en la instancia, pero, durante este tiempo, la réplica que se somete a la sincronización completa no está disponible para las lecturas y la instancia principal experimenta un mayor uso de CPU y memoria.
El extremo principal devuelve READONLY
Es posible que tus escrituras en el extremo principal de una instancia de Memorystore para Redis con réplicas de lectura reciban errores -READONLY You can't write against a read
only replica. de forma inesperada. Te recomendamos que cierres y vuelvas a crear las conexiones a la instancia. En la mayoría de los casos, reiniciar la aplicación cliente puede mitigar el problema. Si estas opciones no son factibles o el comportamiento persiste, comunícate con el Google Cloud equipo de asistencia al cliente.
Cómo escalar las lecturas con el extremo de lectura
Las réplicas de lectura permiten que las aplicaciones escalen sus lecturas leyendo desde las réplicas. Las aplicaciones pueden conectarse a las réplicas de lectura a través del extremo de lectura.
Extremo de lectura
El extremo de lectura es una dirección IP a la que se conecta tu aplicación. Balancea la carga de las conexiones de manera uniforme entre las réplicas de la instancia. Las conexiones a la réplica de lectura pueden enviar consultas de lectura, pero no de escritura. Cada instancia de nivel Estándar que tiene habilitadas las réplicas de lectura tiene un extremo de lectura. Para obtener instrucciones sobre cómo ver el extremo de lectura de tu instancia, consulta Cómo ver la información de la réplica de lectura de tu instancia.
Comportamiento del extremo de lectura
- El extremo de lectura distribuye automáticamente las conexiones entre todas las réplicas disponibles. Las conexiones no se dirigen a la primaria.
- Se considera que una réplica está disponible siempre que pueda atender el tráfico de clientes. Esto no incluye los momentos en que una réplica se somete a una sincronización completa con su instancia principal.
- Una réplica con un retraso de replicación alto sigue entregando tráfico. Las aplicaciones con un volumen alto de escrituras pueden leer datos obsoletos de una réplica que procesa una gran cantidad de escrituras.
- En caso de que un nodo de réplica se convierta en el principal, se terminarán las conexiones a ese nodo y se redireccionarán las conexiones nuevas a un nuevo nodo de réplica.
- Las conexiones individuales al extremo de lectura tienen como objetivo la misma réplica durante la vida útil de la conexión. No se garantiza que las diferentes conexiones desde el mismo host del cliente se dirijan al mismo nodo de réplica.
Coherencia de lectura
Las réplicas de lectura se mantienen con la replicación asíncrona nativa de Redis de OSS. Debido a la naturaleza de la replicación asíncrona, es posible que la réplica se retrase con respecto a la instancia principal. Las aplicaciones con escrituras constantes que también leen desde la réplica deben poder tolerar lecturas incoherentes.
Si la aplicación requiere coherencia de "lectura de escritura", te recomendamos que uses el endpoint principal para las escrituras y las lecturas. El uso del endpoint principal garantiza que las lecturas siempre se dirijan al principal. Incluso en este caso, es posible tener lecturas inactivas después de una conmutación por error.
Establecer TTL en las claves de la instancia principal garantiza que no se lean las claves vencidas ni de la instancia principal ni de la réplica. Esto se debe a que Redis garantiza que no se pueda leer una clave vencida de la réplica.
Comportamiento de la habilitación de réplicas de lectura en una instancia existente
Habilitar réplicas de lectura es una operación exclusiva, lo que significa que no puedes realizar otras modificaciones en la instancia de operación de actualización como parte de la misma operación que habilita las réplicas de lectura.
Para habilitar réplicas de lectura en una instancia de Redis existente, debes asignar un rango de direcciones IP secundarias válido para la colocación de nodos. Debe ser un rango de enrutamiento entre dominios sin clases (CIDR) de tamaño
/28, independientemente del tamaño del rango de direcciones IP existente que se asigne a Memorystore para Redis.- Debes proporcionar el rango de IP adicional cuando habilites las réplicas de lectura para la instancia de Redis. Puedes elegir un rango específico o permitir que Memorystore seleccione uno automáticamente.
La dirección IP de lectura y escritura de tu instancia no cambia cuando habilitas las réplicas de lectura. La dirección IP del endpoint de lectura se encuentra en el rango original asignado para tu instancia de Memorystore, no en el rango adicional que proporcionas cuando habilitas las réplicas de lectura.
Para encontrar el nuevo extremo de lectura, consulta la información de la réplica de lectura de tu instancia después de que se complete la operación para habilitar las réplicas de lectura.
Escalar una instancia
Puedes escalar la cantidad de réplicas de lectura de tu instancia y también modificar el tamaño del nodo:
Para obtener instrucciones sobre cómo agregar y quitar nodos, consulta Cómo agregar o quitar nodos de réplica de tu instancia de Redis.
Para obtener instrucciones sobre cómo escalar el tamaño de los nodos de Redis, consulta Cómo escalar el tamaño de los nodos de Redis.
Te recomendamos que escale tu instancia durante un período de tráfico de lectura y escritura bajo para minimizar el impacto en la aplicación.
Agregar una réplica nueva genera una carga adicional en la instancia principal mientras la réplica realiza una sincronización completa. Cuando se agregan nodos, las conexiones existentes no se ven afectadas ni se transfieren. Una vez que la réplica nueva está disponible, comienza a recibir conexiones desde el extremo y a atender las lecturas. Si quitas una réplica, se cierran las conexiones activas que se enrutaron a esa réplica. La aplicación cliente debe configurarse para volver a conectarse automáticamente al extremo de lectura y restablecer las conexiones con las réplicas restantes.
Prácticas recomendadas
Administración de la memoria
Redis no permite que las escrituras del cliente superen el límite de maxmemory de la instancia. Sin embargo, la sobrecarga, como la fragmentación, los búferes de replicación y los comandos costosos, como EVAL, pueden aumentar la utilización de la memoria más allá de este límite. En estos casos, Memorystore falla en las escrituras hasta que se reduce la presión de la memoria. Consulta Prácticas recomendadas para la administración de memoria
para obtener más detalles.
Si Memorystore está en proceso de realizar una operación BGSAVE debido a una exportación o una replicación de sincronización completa, y se produce una condición de OOM, se detiene el proceso secundario. En este caso, la operación BGSAVE falla y el servidor del nodo de Redis permanece disponible.
Para garantizar la replicación y la creación de instantáneas en todas las circunstancias, te recomendamos que mantengas la utilización de la memoria por debajo del 50% durante las operaciones importantes, como la exportación, el ajuste de escala, etcétera. Puedes activar manualmente la exportación o la conmutación por error para ver el impacto en el rendimiento de estas operaciones.
Administración de la CPU
Memorystore proporciona métricas sobre el uso de la CPU y el recuento de conexiones para cada nodo. Te recomendamos que asignes suficiente capacidad adicional para que se pueda tolerar la pérdida de una sola zona de disponibilidad. El objetivo ideal puede variar según la cantidad de réplicas y los patrones de uso, pero un buen punto de partida es mantener el uso de CPU de las réplicas por debajo del 50%.
Los nodos individuales pueden experimentar un uso elevado si los patrones de uso del cliente están desequilibrados o si las operaciones de conmutación por error generan una distribución de conexiones desequilibrada. En este caso, te recomendamos que cierres tus conexiones periódicamente para permitir que Memorystore las vuelva a equilibrar automáticamente. Memorystore no vuelve a balancear las conexiones abiertas.
Administración del saldo de la conexión
Cada vez que se cierran las conexiones de un nodo, los clientes deben volver a conectarse, por lo general, habilitando la reconexión automática en la biblioteca cliente que elijas. Cuando se reintroduce el nodo, no se redireccionan las conexiones existentes, pero las conexiones nuevas se redireccionan al nodo nuevo. Los clientes pueden interrumpir las conexiones de forma periódica para asegurarse de que estén balanceadas en los nodos disponibles.
Administración del retraso de replicación
Es posible que las réplicas se retrasen, especialmente cuando la tasa de escritura es muy alta. En estos casos, la réplica sigue estando disponible para las lecturas. En esta circunstancia, las lecturas de la réplica pueden estar desactualizadas, y la aplicación debería poder controlarlo, o bien se debería abordar la alta tasa de escritura.
¿Qué sigue?
- Obtén más información para administrar réplicas de lectura.
- Obtén información para exportar datos desde una instancia de Redis.
- Obtén más información sobre la alta disponibilidad de Memorystore para Redis.