大半のロードバランサは、ラウンドロビンまたはフローベースのハッシングでトラフィックを分散しています。この方法を採用しているロードバランサは、利用可能なサービス容量を超えてトラフィックが急増すると適応が難しくなります。このチュートリアルでは、Cloud Load Balancing でグローバル アプリケーションの処理能力を改善する方法を説明します。このアプローチにより、他のロード バランシング方法よりもユーザー エクスペリエンスを向上させ、コストも抑えることができます。
この記事は、Cloud Load Balancing プロダクトのベスト プラクティスを了解するシリーズの一部です。このチュートリアルに関連するグローバルなロード バランシングでは、グローバルなロード バランシングの基盤となるメカニズムについて詳しく説明しています。レイテンシの詳細については、Cloud Load Balancing によるアプリケーション レイテンシの最適化をご覧ください。
このチュートリアルは、Compute Engine の使用経験がある方を対象にしています。また、外部アプリケーション ロードバランサの基礎についても理解している必要があります。
目標
このチュートリアルでは、簡単なウェブサーバーを構築して、マンデルブロ集合を計算するアプリケーションを実行します。このアプリケーションは多くの CPU リソースを必要とします。まず、負荷テストツール(siege と httperf)を使用してネットワークの処理能力を測定します。次に、ネットワークをスケーリングして 1 つのリージョンで複数の VM インスタンスを実行し、負荷をかけた状態でレスポンス時間を測定します。最後に、複数のリージョンでグローバル負荷分散を行い、サーバーのレスポンス時間を測定し、単一リージョンの負荷分散の結果と比較します。このテストを行うことで、Cloud Load Balancing を使用してリージョン間で負荷管理を行うメリットを理解できます。
標準的な 3 層のサーバー アーキテクチャのネットワーク通信速度は、ウェブサーバーの CPU の負荷ではなく、アプリケーション サーバーの速度やデータベースの容量によって制限されます。このチュートリアルで使用した同じ負荷テストツールと容量設定を使用して、実際のアプリケーションの負荷分散を改善できます。
このチュートリアルでは、次のことを行います。
- 負荷テストツール(
siegeとhttperf)の使用方法を学習します。 - 単一 VM インスタンスの処理能力を判断する。
- 単一リージョンのロード バランシングで過負荷状態の影響を測定する。
- 他のリージョンとグローバル ロード バランシングを行った場合の効果を測定する。
費用
このチュートリアルでは、以下を含む、 Google Cloudの課金対象となるコンポーネントを使用します。
- Compute Engine
- 負荷分散と転送ルール
料金計算ツールを使うと、予想使用量に基づいて費用の見積もりを出すことができます。
始める前に
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Compute Engine API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.
環境設定
このセクションでは、チュートリアルに必要な構成(プロジェクト、VPC ネットワーク、基本的なファイアウォール ルール)を行います。
Cloud Shell インスタンスを起動する
Google Cloud コンソールから Cloud Shell を開きます。特に断りのない限り、チュートリアルの残りの部分は Cloud Shell から実行します。
プロジェクトの構成
gcloud コマンドを簡単に実行できるようにプロパティを設定します。これにより、コマンドを実行するたびに、プロパティのオプションを指定する必要がなくなります。
[PROJECT_ID]にプロジェクト ID を指定して、デフォルトのプロジェクトを設定します。gcloud config set project [PROJECT_ID]
[ZONE]に優先ゾーンを指定して、デフォルトの Compute Engine ゾーンを設定します。後で使用できるように、この値を環境変数に設定します。gcloud config set compute/zone [ZONE] export ZONE=[ZONE]
VPC ネットワークの作成と構成
テスト用の VPC ネットワークを作成します。
gcloud compute networks create lb-testing --subnet-mode auto
内部トラフィックを許可するファイアウォール ルールを定義します。
gcloud compute firewall-rules create lb-testing-internal \ --network lb-testing --allow all --source-ranges 10.128.0.0/11VPC ネットワークとの通信で SSH トラフィックを許可するファイアウォール ルールを定義します。
gcloud compute firewall-rules create lb-testing-ssh \ --network lb-testing --allow tcp:22 --source-ranges 0.0.0.0/0
単一 VM インスタンスの処理能力の確認
VM インスタンス タイプのパフォーマンス特性を調査するため、次の操作を行います。
サンプル ワークロード(ウェブサーバー インスタンス)を処理する VM インスタンスを設定します。
同じゾーンに 2 つ目の VM インスタンスを作成します(インスタンスの負荷テスト用)。
2 つ目の VM インスタンスで、簡単な負荷テストとパフォーマンス測定と行うツールを使用して、パフォーマンスを測定します。チュートリアルの後半で、この測定値は使用して、インスタンス グループに適切な負荷分散能力を定義します。
最初の VM インスタンスは、Python スクリプトを使用して、CPU 使用率の高いタスクを作成します。このタスクでは、ルート(/)パスへのリクエストに対して、マンデルブロ集合を計算し、結果を表示します。この結果はキャッシュに格納されません。このチュートリアルでは、このソリューションの GitHub リポジトリから Python スクリプトを取得します。
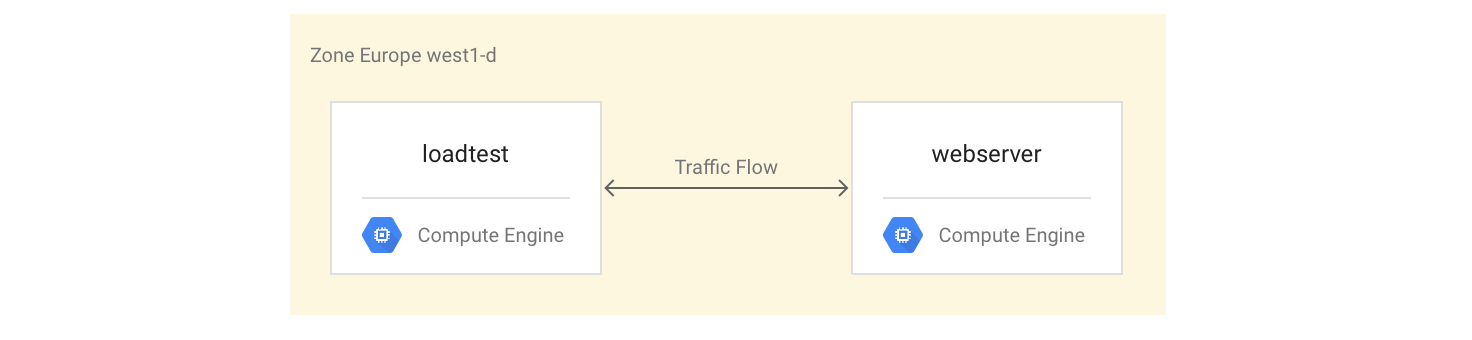
VM インスタンスの設定
4 コア VM インスタンスとして
webserverVM インスタンスを設定します。マンデルブロ集合を計算するサーバーをインストールして開始します。gcloud compute instances create webserver --machine-type n1-highcpu-4 \ --network=lb-testing --image-family=debian-12 \ --image-project=debian-cloud --tags=http-server \ --metadata startup-script='#! /bin/bash apt-get -y update apt-get install -y git python-numpy python-matplotlib git clone \ https://github.com/GoogleCloudPlatform/lb-app-capacity-tutorial-python.git cd lb-app-capacity-tutorial-python python webserver.py'自身のマシンから
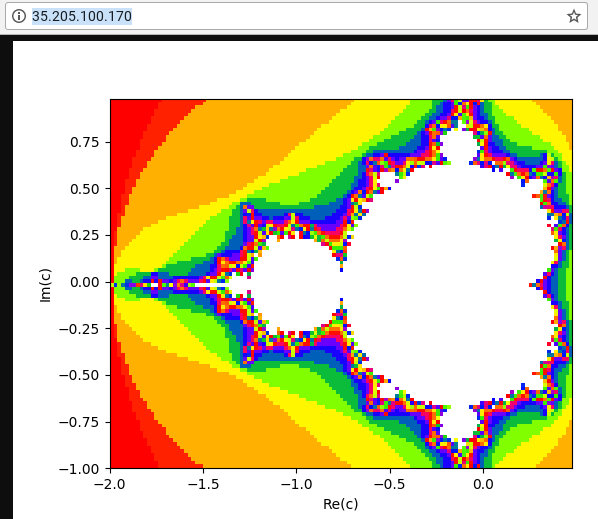
webserverインスタンスへの外部アクセスを許可するファイアウォール ルールを作成します。gcloud compute firewall-rules create lb-testing-http \ --network lb-testing --allow tcp:80 --source-ranges 0.0.0.0/0 \ --target-tags http-serverwebserverインスタンスの IP アドレスを取得します。gcloud compute instances describe webserver \ --format "value(networkInterfaces[0].accessConfigs[0].natIP)"ウェブブラウザで、前のコマンドで返された IP アドレスに移動します。 計算後のマンデルブロ集合が表示されます。
負荷テスト用のインスタンスを作成します。
gcloud compute instances create loadtest --machine-type n1-standard-1 \ --network=lb-testing --image-family=debian-12 \ --image-project=debian-cloud
VM インスタンスのテスト
次に、負荷テスト用の VM インスタンスのパフォーマンス特性を測定するリクエストを実行します。
sshコマンドを使用して負荷テスト用の VM インスタンスに接続します。gcloud compute ssh loadtest
負荷テストを行うインスタンスに、負荷テストツールとして siege と httperf をインストールします。
sudo apt-get install -y siege httperf
siegeツールを使用すると、指定した数のユーザーからリクエストをシミュレートし、ユーザーからレスポンスがあった場合にのみ以降のリクエストを処理できます。これにより、実際の環境でのアプリケーションの処理能力と想定されるレスポンス時間を把握できます。httperfツールでは、レスポンスやエラーを受信したかどうかに関係なく、1 秒あたり特定のリクエスト数を送信できます。これにより、特定の負荷に対するアプリケーションの対応を確認できます。ウェブサーバーに対する簡単なリクエストの時間を設定します。
curl -w "%{time_total}\n" -o /dev/#objectives_2 -s webserver0.395260 のようなレスポンスを受信します。この場合、サーバーがリクエストに応答するまでに 395 ミリ秒 (ms) ほどかかる場合があります。
次のコマンドを使用して、4 人のユーザーから同時に 20 個のリクエストを実行します。
siege -c 4 -r 20 webserver
次のような出力が表示されます。
** SIEGE 4.0.2 ** Preparing 4 concurrent users for battle. The server is now under siege... Transactions: 80 hits Availability: 100.00 % Elapsed time: 14.45 secs Data transferred: 1.81 MB Response time: 0.52 secs Transaction rate: 5.05 trans/sec Throughput: 0.12 MB/sec Concurrency: 3.92 Successful transactions: 80 Failed transactions: 0 **Longest transaction: 0.70 Shortest transaction: 0.37 **
出力内容の詳細については、siege のマニュアルをご覧ください。この例では、レスポンス時間は 0.37s から 0.7s の間になります。平均で見ると、毎秒 5.05 個のリクエストに対応できます。このデータからシステムの処理能力は予測します。
httperf負荷テストツールを使用して次のコマンドを実行し、調査結果を検証します。httperf --server webserver --num-conns 500 --rate 4
このコマンドは毎秒 4 個の割合で 500 個のリクエストを実行します。この速度は、
siegeの測定結果(毎秒 5.05 個のトランザクション)を下回っています。次のような出力が表示されます。
httperf --client=0/1 --server=webserver --port=80 --uri=/ --rate=4 --send-buffer=4096 --recv-buffer=16384 --num-conns=500 --num-calls=1 httperf: warning: open file limit > FD_SETSIZE; limiting max. # of open files to FD_SETSIZE Maximum connect burst length: 1 Total: connections 500 requests 500 replies 500 test-duration 125.333 s Connection rate: 4.0 conn/s (251.4 ms/conn, <=2 concurrent connections) **Connection time [ms]: min 369.6 avg 384.5 max 487.8 median 377.5 stddev 18.0 Connection time [ms]: connect 0.3** Connection length [replies/conn]: 1.000 Request rate: 4.0 req/s (251.4 ms/req) Request size [B]: 62.0 Reply rate [replies/s]: min 3.8 avg 4.0 max 4.0 stddev 0.1 (5 samples) Reply time [ms]: response 383.8 transfer 0.4 Reply size [B]: header 117.0 content 24051.0 footer 0.0 (total 24168.0) Reply status: 1xx=0 2xx=100 3xx=0 4xx=0 5xx=0 CPU time [s]: user 4.94 system 20.19 (user 19.6% system 80.3% total 99.9%) Net I/O: 94.1 KB/s (0.8*10^6 bps) Errors: total 0 client-timo 0 socket-timo 0 connrefused 0 connreset 0 Errors: fd-unavail 0 addrunavail 0 ftab-full 0 other 0
出力の説明が httperf README ファイルにあります。
Connection time [ms]で始まる行を見ると、接続にかかった時間の合計は 369.6~487.8 ミリ秒で、エラーは発生していません。1 秒あたりのリクエスト数を変えてテストを 3 回実行します。
rateオプションを 5、7 または 10 に設定します。次のブロックは、
httperfコマンドとその出力を示します(接続時間に関連する行のみを表示しています)。毎秒 5 個のリクエストを送信するコマンド:
httperf --server webserver --num-conns 500 --rate 5 2>&1| grep 'Errors\|ion time'
毎秒 5 個のリクエストを送信した結果:
Connection time [ms]: min 371.2 avg 381.1 max 447.7 median 378.5 stddev 7.2 Connection time [ms]: connect 0.2 Errors: total 0 client-timo 0 socket-timo 0 connrefused 0 connreset 0 Errors: fd-unavail 0 addrunavail 0 ftab-full 0 other 0
毎秒 7 個のリクエストを送信するコマンド:
httperf --server webserver --num-conns 500 --rate 7 2>&1| grep 'Errors\|ion time'
毎秒 7 個のリクエストを送信した結果:
Connection time [ms]: min 373.4 avg 11075.5 max 60100.6 median 8481.5 stddev 10284.2 Connection time [ms]: connect 654.9 Errors: total 4 client-timo 0 socket-timo 0 connrefused 0 connreset 4 Errors: fd-unavail 0 addrunavail 0 ftab-full 0 other 0
毎秒 10 個のリクエストを送信するコマンド:
httperf --server webserver --num-conns 500 --rate 10 2>&1| grep 'Errors\|ion time'
毎秒 10 個のリクエストを送信した結果:
Connection time [ms]: min 374.3 avg 18335.6 max 65533.9 median 10052.5 stddev 16654.5 Connection time [ms]: connect 181.3 Errors: total 32 client-timo 0 socket-timo 0 connrefused 0 connreset 32 Errors: fd-unavail 0 addrunavail 0 ftab-full 0 other 0
webserverインスタンスからログアウトします。exit
この測定結果から、このシステムが 1 秒あたりに処理できるリクエスト数(RPS)は約 5 個と考えることができます。1 秒あたり 5 個のリクエストでは、接続数が 4 の場合と同じレイテンシが VM インスタンスで発生します。1 秒あたりの接続数が 7 と 10 の場合、平均レスポンス時間は大幅に増加し、10 秒を超え、複数の接続エラーが発生します。つまり、1 秒あたりのリクエスト数が 5 を超えると、処理速度が大幅に低下します。
より複雑なシステムでも同様の方法で処理能力を計測できますが、この場合、各コンポーネントの処理能力が重要になります。siege ツールと httperf ツールをすべてのコンポーネント(フロントエンド サーバー、アプリケーション サーバー、データベース サーバーなど)の CPU および I/O 負荷モニタリングと併用すると、ボトルネックを特定するのに役立ちます。これにより、各コンポーネントのスケーリングを適切に行うことができます。
単一リージョンのロードバランサでの過負荷状態の影響の測定
このセクションでは、単一リージョンのロードバランサ(オンプレミスの標準的なロードバランサ、 Google Cloudの外部パススルー ネットワーク ロードバランサなど)で過負荷状態の影響を測定します。ロードバランサをグローバル デプロイでなく、リージョン デプロイで使用している場合は、HTTP(S) ロードバランサの影響も評価できます。
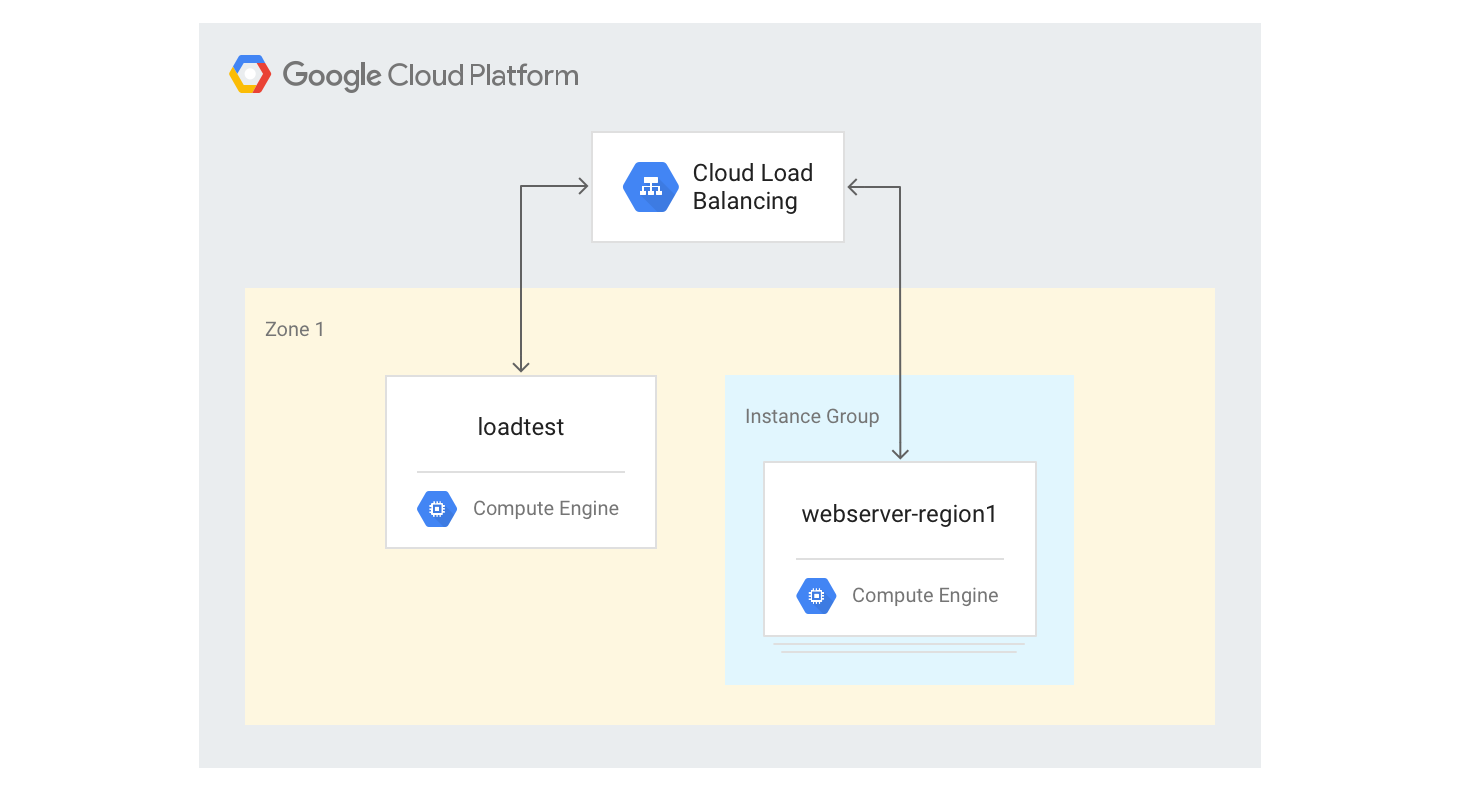
単一リージョンの HTTP(S) ロードバランサの作成
以下では、固定サイズの 3 つの VM インスタンスに単一リージョンの HTTP(S) ロードバランサを作成します。
以前に使用した Python マンデルブロ生成スクリプトを使用して、ウェブサーバーの VM インスタンスにインスタンス テンプレートを作成します。Cloud Shell で次のコマンドを実行します。
gcloud compute instance-templates create webservers \ --machine-type n1-highcpu-4 \ --image-family=debian-12 --image-project=debian-cloud \ --tags=http-server \ --network=lb-testing \ --metadata startup-script='#! /bin/bash apt-get -y update apt-get install -y git python-numpy python-matplotlib git clone \ https://github.com/GoogleCloudPlatform/lb-app-capacity-tutorial-python.git cd lb-app-capacity-tutorial-python python webserver.py'前のステップのテンプレートを使用して、3 つのインスタンスから構成されるマネージド インスタンス グループを作成します。
gcloud compute instance-groups managed create webserver-region1 \ --size=3 --template=webserversHTTP ロード バランシングの生成に必要なヘルスチェック、バックエンド サービス、URL マップ、ターゲット プロキシ、グローバル転送ルールを作成します。
gcloud compute health-checks create http basic-check \ --request-path="/health-check" --check-interval=60s gcloud compute backend-services create web-service \ --health-checks basic-check --global gcloud compute backend-services add-backend web-service \ --global --instance-group=webserver-region1 \ --instance-group-zone $ZONE gcloud compute url-maps create web-map --default-service web-service gcloud compute target-http-proxies create web-proxy --url-map web-map gcloud compute forwarding-rules create web-rule --global \ --target-http-proxy web-proxy --ports 80転送ルールの IP アドレスを取得します。
gcloud compute forwarding-rules describe --global web-rule --format "value(IPAddress)"
作成したロードバランサのパブリック IP アドレスが出力されます。
ブラウザで、前のコマンドで返された IP アドレスに移動します。数分後、前に見たマンデルブロの画像が表示されます。ただし、今回の画像は、新しく作成したグループの VM インスタンスの 1 つで処理されています。
loadtestマシンにログインします。gcloud compute ssh loadtest
loadtestマシンのコマンドラインで、1 秒あたりのリクエスト数(RPS)を変えてサーバー レスポンスをテストします。RPS 値は 5~20 の範囲内にします。たとえば、次のコマンドは 10 RPS を生成します。
[IP_address]は、この手順の前のステップで取得したロードバランサの IP アドレスに置き換えます。httperf --server [IP_address] --num-conns 500 --rate 10 2>&1| grep 'Errors\|ion time'
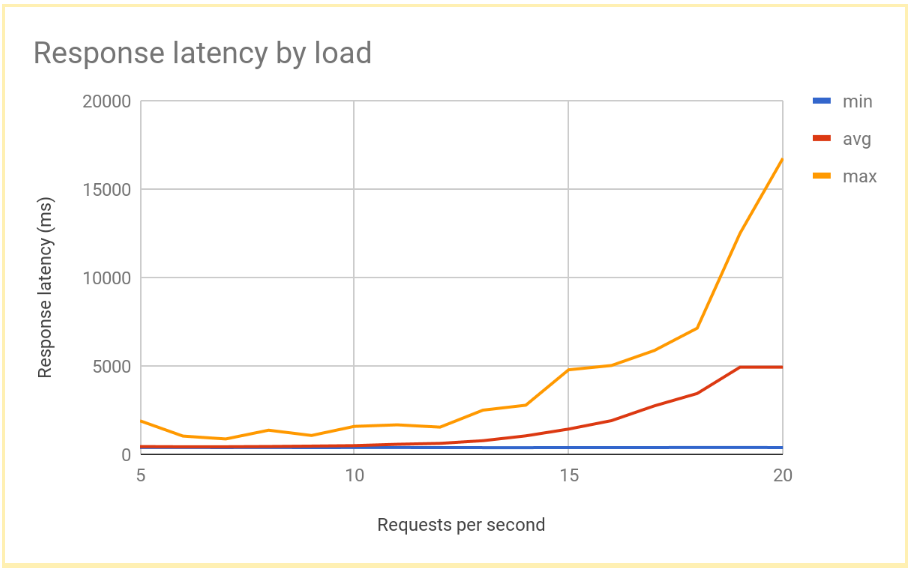
RPS の数が 12~13 を超えると、レスポンスのレイテンシが大幅に増加します。典型的な結果を以下に示します。
loadtestVM インスタンスからログアウトします。exit
これは、リージョンで負荷分散を行っているシステムで標準的なパフォーマンスです。負荷が処理能力を超えると、リクエスト レイテンシの平均値と最大値が急激に上昇します。RPS が 10 の場合、リクエスト レイテンシの平均値は 500 ms 近くになり、RPS が 20 になるとレイテンシは 5,000 ms になります。レイテンシは 10 倍になり、ユーザーの操作性は急速に低下します。この状態では、ユーザーが離れてしまうか、アプリケーションのタイムアウトが発生します。
次のセクションでは、負荷分散トポロジに 2 つ目のリージョンを追加し、リージョン間でフェイルオーバーを行い、エンドユーザーのレイテンシに対する影響を比較します。
別のリージョンへの負荷分散を行った場合の影響
外部アプリケーション ロードバランサでグローバル アプリケーションを使用している場合や、複数のリージョンにバックエンドをデプロイしている場合、1 つのリージョンで処理能力を超えると、トラフィックは別のリージョンに自動的に配信されます。前のセクションで作成した構成で、別のリージョンに 2 つ目の VM インスタンス グループを追加し、この処理を確認してみましょう。
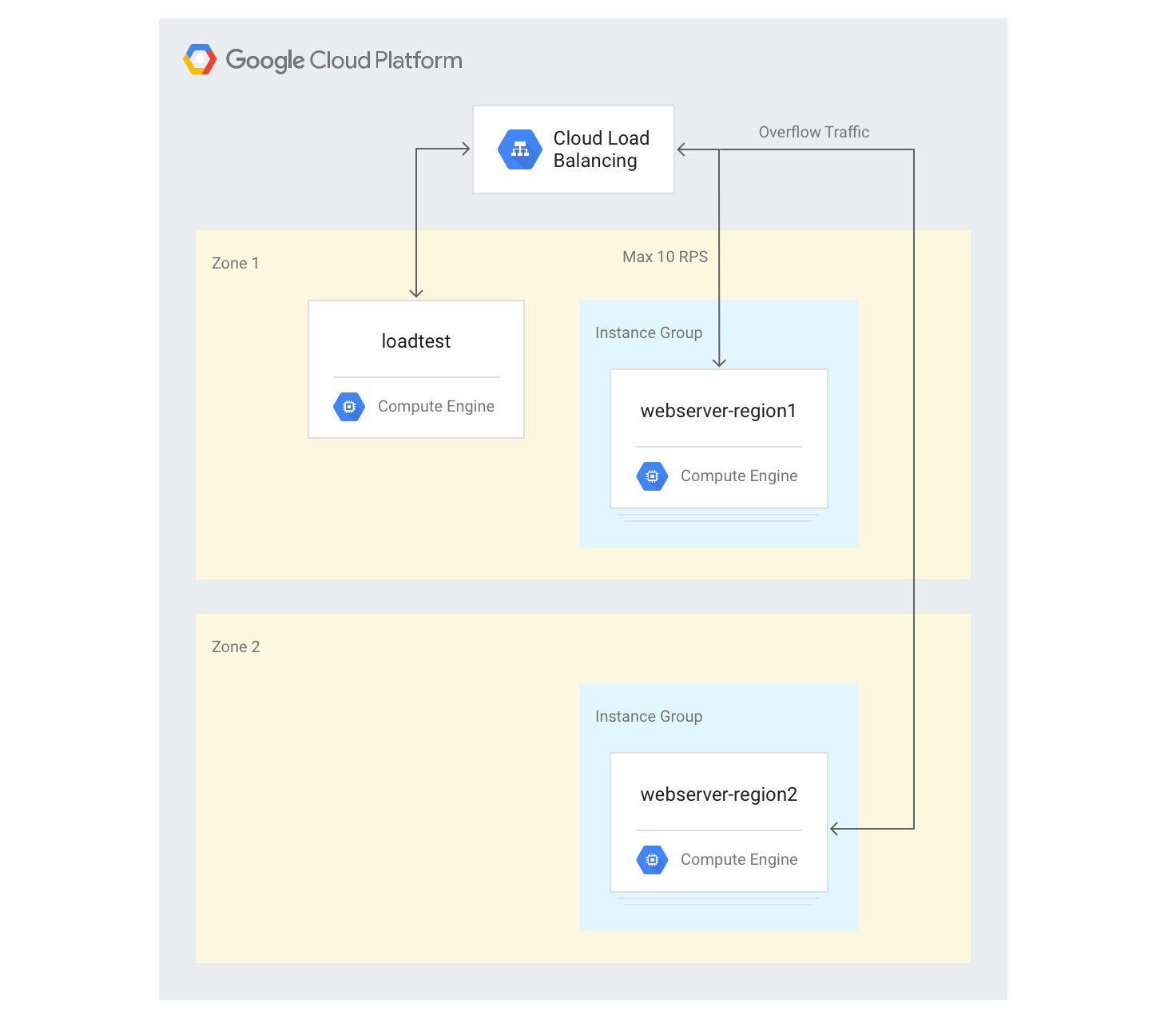
複数のリージョンにサーバーを作成する
以下では、別のリージョンの別のバックエンド グループを追加し、リージョンあたり 10 RPS の容量を割り当てます。次に、この制限を超えたときにロード バランシングがどのように機能するか確認します。
Cloud Shell で、デフォルト ゾーンと異なるリージョンのゾーンを選択し、このゾーンを環境変数に設定します。
export ZONE2=[zone]
2 番目のリージョンに新しいインスタンス グループを作成して、3 つの VM インスタンスを割り当てます。
gcloud compute instance-groups managed create webserver-region2 \ --size=3 --template=webservers --zone $ZONE2既存のバックエンド サービスにインスタンス グループを追加し、最大容量を 10 RPS に設定します。
gcloud compute backend-services add-backend web-service \ --global --instance-group=webserver-region2 \ --instance-group-zone $ZONE2 --max-rate 10既存のバックエンド サービスの
max-rateを 10 RPS に調整します。gcloud compute backend-services update-backend web-service \ --global --instance-group=webserver-region1 \ --instance-group-zone $ZONE --max-rate 10すべてのインスタンスが起動したら、
loadtestVM インスタンスにログインします。gcloud compute ssh loadtest
10 RPS で 500 リクエストを実行します。
[IP_address]は、ロードバランサの IP アドレスに置き換えます。httperf --server [IP_address] --num-conns 500 --rate 10 2>&1| grep 'ion time'
結果は次のようになります。
Connection time [ms]: min 405.9 avg 584.7 max 1390.4 median 531.5 stddev 181.3 Connection time [ms]: connect 1.1
この結果は、リージョン ロードバランサの結果と類似しています。
実際の環境と異なり、テストツールを実行するとすぐに最大負荷になるため、過負荷状態になるまでテストを数回繰り返す必要があります。20 RPS で 500 リクエストのテストを 5 回実行します。
[IP_address]は、ロードバランサの IP アドレスに置き換えます。for a in \`seq 1 5\`; do httperf --server [IP_address] \ --num-conns 500 --rate 20 2>&1| grep 'ion time' ; done結果は次のようになります。
Connection time [ms]: min 426.7 avg 6396.8 max 13615.1 median 7351.5 stddev 3226.8 Connection time [ms]: connect 0.9 Connection time [ms]: min 417.2 avg 3782.9 max 7979.5 median 3623.5 stddev 2479.8 Connection time [ms]: connect 0.9 Connection time [ms]: min 411.6 avg 860.0 max 3971.2 median 705.5 stddev 492.9 Connection time [ms]: connect 0.7 Connection time [ms]: min 407.3 avg 700.8 max 1927.8 median 667.5 stddev 232.1 Connection time [ms]: connect 0.7 Connection time [ms]: min 410.8 avg 701.8 max 1612.3 median 669.5 stddev 209.0 Connection time [ms]: connect 0.8
システムが安定すると、レスポンスの平均時間は 10 RPS で 400 ms になり、20 RPS で 700 ms になります。リージョン ロードバランサでは 5,000 ms の遅延でしたので、これは大幅な改善といえます。ユーザー エクスペリエンスも向上します。
次のグラフは、グローバル負荷分散で測定したレスポンス時間を RPS 別に表したものです。
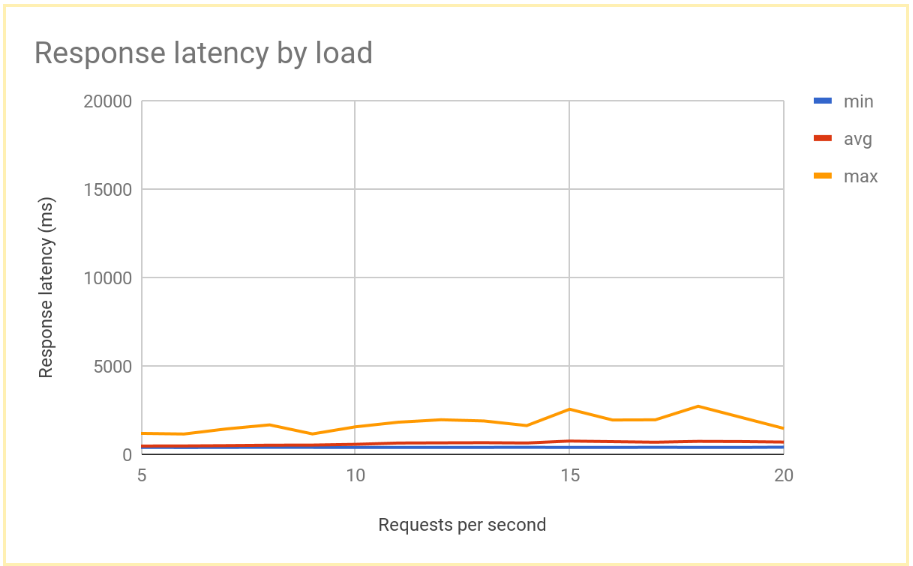
リージョン負荷分散とグローバル負荷分散の比較
単一ノードの処理能力が決まると、リージョン負荷分散とグローバル負荷分散でエンドユーザーが体験するレイテンシを比較できます。単一リージョンのリクエスト数は、そのリージョン全体の処理能力よりも少なくなりますが、ユーザーは最も近いリージョンにリダイレクトされるため、エンドユーザーのレイテンシはどちらのシステムでもそれほど違いはありません。
リージョンへの負荷が処理能力を上回った場合、エンドユーザーのレイテンシはソリューションによって大きく異なります。
リージョン ロード バランシング ソリューションの場合、トラフィック量が処理能力を超えると、過負荷状態になります。過負荷状態になったバックエンド VM インスタンス以外にトラフィックの配信先がなくなるためです。これには、従来のオンプレミス ロードバランサ、 Google Cloudの外部パススルー ネットワーク ロードバランサ、単一リージョン構成の外部アプリケーション ロードバランサ(スタンダード ティア ネットワーキングを使用した場合など)が含まれます。リクエスト レイテンシの平均値と最大値は 10 倍以上増加し、ユーザー エクスペリエンスが大幅に劣化した結果、多くのユーザーが離れる可能性があります。
複数のリージョンにバックエンドがあるグローバル外部アプリケーション ロードバランサでは、利用可能な処理能力のある最も近いリージョンにトラフィックが分散されます。この場合、エンドユーザーのレイテンシの増加は比較的緩やかになり、ユーザー エクスペリエンスが向上します。アプリケーションで十分な速さのリージョンにスケールアウトできない場合は、グローバル外部アプリケーション ロードバランサをおすすめします。リージョンのユーザー アプリケーション サーバーで障害が発生しても、トラフィックがすぐに他のリージョンにリダイレクトされるので、完全なサービスの停止は回避できます。
クリーンアップ
プロジェクトの削除
課金されないようにする最も簡単な方法は、チュートリアル用に作成したプロジェクトを削除することです。
プロジェクトを削除するには:
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
次のステップ
Google の負荷分散オプションの詳細とバックグランドについては、次のページをご覧ください。
- Cloud Load Balancing によるアプリケーション レイテンシの改善
- Networking 101 Codelab
- 外部パススルー ネットワーク ロードバランサ
- 外部アプリケーション ロードバランサ
- 外部プロキシ ネットワーク ロードバランサ