Die meisten Load Balancer nutzen Round-Robin-Hashing oder ablaufbasiertes Hashing, um den Traffic zu verteilen. Solche Load Balancer können sich oft schlecht anpassen, wenn die Traffic-Nachfrage die verfügbare Bereitstellungskapazität überschreitet. In dieser Anleitung wird gezeigt, wie Ihre globale Anwendungskapazität durch Cloud Load Balancing optimiert werden kann, was zu einer besseren Nutzererfahrung und niedrigeren Kosten als bei den meisten anderen Load-Balancing-Varianten führt.
Dieser Artikel ist Teil einer Best-Practices-Reihe zu Produkten für das Cloud Load Balancing. Diese Anleitung wird vom konzeptionellen Artikel Optimierung der Anwendungskapazität mit globalem Load-Balancing begleitet, in dem die zugrunde liegenden Mechanismen des globalen Load-Balancing ausführlicher erläutert werden. Weitere Informationen zur Latenz finden Sie unter Anwendungslatenz mit Cloud Load Balancing optimieren.
In dieser Anleitung wird davon ausgegangen, dass Sie Erfahrung mit Compute Engine haben. Außerdem sollten Sie mit den Grundlagen von externen Application Load Balancern vertraut sein.
Ziele
In dieser Anleitung richten Sie einen einfachen Webserver ein, der eine CPU-intensive Anwendung ausführt, mit der Mandelbrot-Mengen berechnet werden. Zuerst messen Sie mithilfe der Lasttesttools siege und httperf seine Netzwerkkapazität. Dann skalieren Sie das Netzwerk auf mehrere VM-Instanzen in einer einzelnen Region und messen die Antwortzeit unter Last. Zum Schluss skalieren Sie das Netzwerk mithilfe des globalen Load-Balancing auf mehrere Regionen, messen die Antwortzeit des Servers unter Last und vergleichen sie mit dem Load-Balancing für eine einzelne Region. Anhand dieser Testreihe können Sie selbst die positiven Auswirkungen der regionsübergreifenden Lastenverwaltung des Cloud Load Balancing erleben.
Die Netzwerk-Kommunikationsgeschwindigkeit einer typischen dreischichtigen Serverarchitektur ist normalerweise durch die Geschwindigkeit des Anwendungsservers oder die Datenbankkapazität und nicht durch die CPU-Last auf dem Webserver begrenzt. Nachdem Sie die Anleitung durchgegangen sind, können Sie dieselben Lasttesttools und Kapazitätseinstellungen nutzen, um das Load-Balancing-Verhalten in einer realen Anwendung zu optimieren.
Sie werden Folgendes tun:
- Mehr über die Verwendung von Lasttesttools (
siegeundhttperf) erfahren - Die Bereitstellungskapazität einer einzelnen VM-Instanz ermitteln
- Die Auswirkungen einer Überlast beim Load-Balancing für eine einzelne Region messen
- Die Auswirkungen eines Überlaufs in eine andere Region beim globalen Load-Balancing messen
Kosten
In dieser Anleitung werden kostenpflichtige Komponenten von Google Cloudverwendet, darunter:
- Compute Engine
- Load-Balancing und Weiterleitungsregeln
Mit dem Preisrechner können Sie eine Kostenschätzung für Ihre voraussichtliche Nutzung erstellen.
Vorbereitung
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Compute Engine API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.
Umgebung einrichten
In diesem Abschnitt konfigurieren Sie die Projekteinstellungen, das VPC-Netzwerk und die grundlegenden Firewallregeln, die Sie für die Anleitung benötigen.
Cloud Shell-Instanz starten
Öffnen Sie Cloud Shell über die Google Cloud Console. Wenn nicht anders angegeben, führen Sie die übrigen Schritte dieser Anleitung in Cloud Shell aus.
Projekteinstellungen konfigurieren
Wenn Sie das Ausführen von gcloud-Befehlen erleichtern möchten, können Sie Attribute festlegen, sodass Sie nicht zu jedem Befehl Optionen für diese Attribute angeben müssen.
Geben Sie das Standardprojekt mit Ihrer Projekt-ID für
[PROJECT_ID]an:gcloud config set project [PROJECT_ID]
Geben Sie Ihre Compute Engine-Standardzone unter Verwendung Ihrer bevorzugten Zone für
[ZONE]an und legen Sie dies dann als Umgebungsvariable für die spätere Verwendung fest:gcloud config set compute/zone [ZONE] export ZONE=[ZONE]
VPC-Netzwerk erstellen und konfigurieren
Erstellen Sie ein VPC-Netzwerk zum Testen:
gcloud compute networks create lb-testing --subnet-mode auto
Definieren Sie eine Firewallregel, um internen Traffic zuzulassen:
gcloud compute firewall-rules create lb-testing-internal \ --network lb-testing --allow all --source-ranges 10.128.0.0/11Definieren Sie eine Firewallregel, um SSH-Traffic zur Kommunikation mit dem VPC-Netzwerk zuzulassen:
gcloud compute firewall-rules create lb-testing-ssh \ --network lb-testing --allow tcp:22 --source-ranges 0.0.0.0/0
Bereitstellungskapazität einer einzelnen VM-Instanz ermitteln
So untersuchen Sie die Leistungsmerkmale eines VM-Instanztyps:
Richten Sie eine VM-Instanz ein, über die die Beispielarbeitslast bereitgestellt wird (die Webserverinstanz).
Erstellen Sie eine zweite VM-Instanz in derselben Zone (die Lasttestinstanz).
Mit der zweiten VM-Instanz messen Sie die Leistung mithilfe einfacher Lasttest- und Leistungsmesstools. Sie verwenden diese Messungen später in der Anleitung, um für die Instanzgruppe die richtige Einstellung für die Load-Balancing-Kapazität zu definieren.
Für die erste VM-Instanz wird ein Python-Skript verwendet, um eine CPU-intensive Aufgabe durch Berechnen und Anzeigen des Bilds einer Mandelbrot-Menge für die einzelnen Anfragen an den Root-Pfad zu erstellen. Das Ergebnis wird nicht im Cache gespeichert. Sie erhalten das Python-Skript für diese Anleitung aus dem GitHub-Repository, das für diese Lösung verwendet wird.
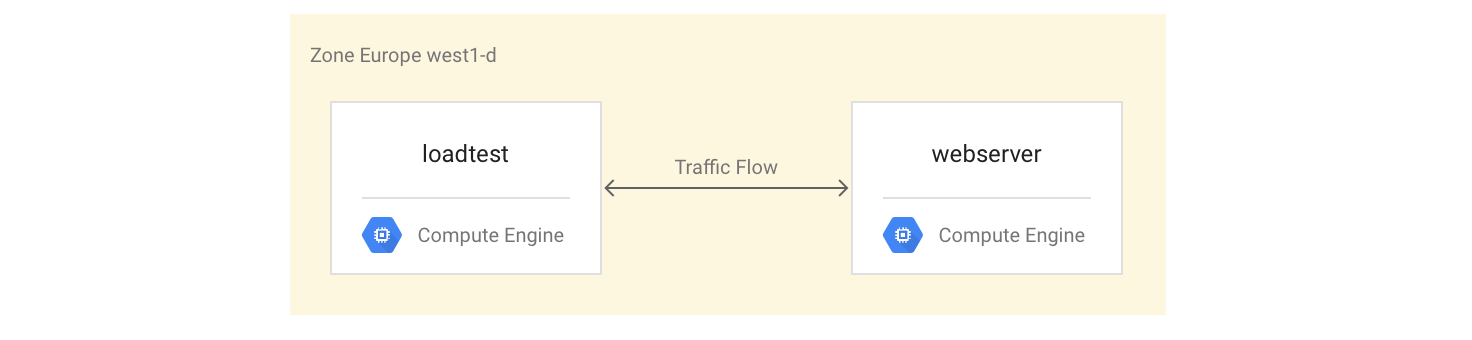
VM-Instanzen einrichten
Richten Sie die VM-Instanz
webserverals VM-Instanz mit vier Kernen ein. Dafür installieren Sie den Mandelbrot-Server und starten ihn:gcloud compute instances create webserver --machine-type n1-highcpu-4 \ --network=lb-testing --image-family=debian-12 \ --image-project=debian-cloud --tags=http-server \ --metadata startup-script='#! /bin/bash apt-get -y update apt-get install -y git python-numpy python-matplotlib git clone \ https://github.com/GoogleCloudPlatform/lb-app-capacity-tutorial-python.git cd lb-app-capacity-tutorial-python python webserver.py'Erstellen Sie eine Firewallregel, um den externen Zugriff auf die
webserver-Instanz von Ihrem eigenen Computer aus zuzulassen:gcloud compute firewall-rules create lb-testing-http \ --network lb-testing --allow tcp:80 --source-ranges 0.0.0.0/0 \ --target-tags http-serverRufen Sie die IP-Adresse der
webserver-Instanz ab:gcloud compute instances describe webserver \ --format "value(networkInterfaces[0].accessConfigs[0].natIP)"Wechseln Sie in einem Webbrowser zu der IP-Adresse, die vom vorherigen Befehl zurückgegeben wurde. Sie sehen eine berechnete Mandelbrot-Menge:
Erstellen Sie die Lasttestinstanz:
gcloud compute instances create loadtest --machine-type n1-standard-1 \ --network=lb-testing --image-family=debian-12 \ --image-project=debian-cloud
VM-Instanzen testen
Der nächste Schritt besteht darin, Anfragen auszuführen, um die Leistungsmerkmale der Lasttest-VM-Instanz zu bestimmen.
Verwenden Sie den Befehl
ssh, um für den Lasttest eine Verbindung zur VM-Instanz herzustellen:gcloud compute ssh loadtest
Installieren Sie auf der Lasttestinstanz siege und httperf als Lasttesttools:
sudo apt-get install -y siege httperf
Das Tool
siegeermöglicht es Ihnen, Anfragen von einer bestimmten Anzahl von Nutzern zu simulieren, wobei Folgeanfragen erst gestellt werden, nachdem die Nutzer eine Antwort erhalten haben. Dadurch erhalten Sie einen Eindruck von der Kapazität und den zu erwartenden Antwortzeiten für Anwendungen in einer realen Umgebung.Das Tool
httperfermöglicht es Ihnen, eine bestimmte Anzahl von Anfragen pro Sekunde zu senden, unabhängig davon, ob Antworten oder Fehler empfangen wurden. Dadurch erfahren Sie, wie Anwendungen auf eine bestimmte Last reagieren.Messen Sie die Zeit für eine einfache Anfrage an den Webserver:
curl -w "%{time_total}\n" -o /dev/#objectives_2 -s webserverSie erhalten eine Antwort wie "0.395260". Dies bedeutet, dass der Server 395 Millisekunden (ms) gebraucht hat, um auf die Anfrage zu antworten.
Verwenden Sie den folgenden Befehl, um parallel 20 Anfragen von vier Nutzern auszuführen:
siege -c 4 -r 20 webserver
Die Ausgabe sollte in etwa so aussehen:
** SIEGE 4.0.2 ** Preparing 4 concurrent users for battle. The server is now under siege... Transactions: 80 hits Availability: 100.00 % Elapsed time: 14.45 secs Data transferred: 1.81 MB Response time: 0.52 secs Transaction rate: 5.05 trans/sec Throughput: 0.12 MB/sec Concurrency: 3.92 Successful transactions: 80 Failed transactions: 0 **Longest transaction: 0.70 Shortest transaction: 0.37 **
Die Ausgabe wird im siege-Handbuch ausführlich erklärt. Sie können in diesem Beispiel aber sehen, dass die Antwortzeiten zwischen 0,37 s und 0,7 s lagen. Im Durchschnitt wurden 5,05 Anfragen pro Sekunde beantwortet. Mithilfe dieser Daten kann die Bereitstellungskapazität des Systems eingeschätzt werden.
Führen Sie die folgenden Befehle aus, um die Ergebnisse mit dem Lasttesttool
httperfzu validieren:httperf --server webserver --num-conns 500 --rate 4
Durch diesen Befehl werden 500 Anfragen mit einer Rate von vier Anfragen pro Sekunde ausgeführt. Das sind weniger als die 5,05 Transaktionen pro Sekunde, die von
siegeabgeschlossen wurden.Die Ausgabe sollte in etwa so aussehen:
httperf --client=0/1 --server=webserver --port=80 --uri=/ --rate=4 --send-buffer=4096 --recv-buffer=16384 --num-conns=500 --num-calls=1 httperf: warning: open file limit > FD_SETSIZE; limiting max. # of open files to FD_SETSIZE Maximum connect burst length: 1 Total: connections 500 requests 500 replies 500 test-duration 125.333 s Connection rate: 4.0 conn/s (251.4 ms/conn, <=2 concurrent connections) **Connection time [ms]: min 369.6 avg 384.5 max 487.8 median 377.5 stddev 18.0 Connection time [ms]: connect 0.3** Connection length [replies/conn]: 1.000 Request rate: 4.0 req/s (251.4 ms/req) Request size [B]: 62.0 Reply rate [replies/s]: min 3.8 avg 4.0 max 4.0 stddev 0.1 (5 samples) Reply time [ms]: response 383.8 transfer 0.4 Reply size [B]: header 117.0 content 24051.0 footer 0.0 (total 24168.0) Reply status: 1xx=0 2xx=100 3xx=0 4xx=0 5xx=0 CPU time [s]: user 4.94 system 20.19 (user 19.6% system 80.3% total 99.9%) Net I/O: 94.1 KB/s (0.8*10^6 bps) Errors: total 0 client-timo 0 socket-timo 0 connrefused 0 connreset 0 Errors: fd-unavail 0 addrunavail 0 ftab-full 0 other 0
Die Ausgabe wird in der httperf-README-Datei erläutert. Beachten Sie die Zeile, die mit
Connection time [ms]beginnt. Sie zeigt, dass die Verbindungszeiten insgesamt zwischen 369,6 und 487,8 ms betrugen und keine Fehler generiert wurden.Wiederholen Sie den Test dreimal und setzen Sie die Option
rateauf fünf, sieben und zehn Anfragen pro Sekunde.Die folgenden Blöcke zeigen die Befehle für
httperfund ihre Ausgabe. Dabei sind nur die relevanten Zeilen mit Informationen zur Verbindungszeit aufgeführt.Befehl für fünf Anfragen pro Sekunde:
httperf --server webserver --num-conns 500 --rate 5 2>&1| grep 'Errors\|ion time'
Ergebnisse für fünf Anfragen pro Sekunde:
Connection time [ms]: min 371.2 avg 381.1 max 447.7 median 378.5 stddev 7.2 Connection time [ms]: connect 0.2 Errors: total 0 client-timo 0 socket-timo 0 connrefused 0 connreset 0 Errors: fd-unavail 0 addrunavail 0 ftab-full 0 other 0
Befehl für sieben Anfragen pro Sekunde:
httperf --server webserver --num-conns 500 --rate 7 2>&1| grep 'Errors\|ion time'
Ergebnisse für sieben Anfragen pro Sekunde:
Connection time [ms]: min 373.4 avg 11075.5 max 60100.6 median 8481.5 stddev 10284.2 Connection time [ms]: connect 654.9 Errors: total 4 client-timo 0 socket-timo 0 connrefused 0 connreset 4 Errors: fd-unavail 0 addrunavail 0 ftab-full 0 other 0
Befehl für zehn Anfragen pro Sekunde:
httperf --server webserver --num-conns 500 --rate 10 2>&1| grep 'Errors\|ion time'
Ergebnisse für zehn Anfragen pro Sekunde:
Connection time [ms]: min 374.3 avg 18335.6 max 65533.9 median 10052.5 stddev 16654.5 Connection time [ms]: connect 181.3 Errors: total 32 client-timo 0 socket-timo 0 connrefused 0 connreset 32 Errors: fd-unavail 0 addrunavail 0 ftab-full 0 other 0
Melden Sie sich von der Instanz
webserverab:exit
Aus diesen Messungen können Sie schließen, dass das System eine Kapazität von etwa fünf Anfragen pro Sekunde (RPS) hat. Bei fünf Anfragen pro Sekunde reagiert die VM-Instanz mit einer Latenz wie bei vier Verbindungen. Bei sieben und zehn Verbindungen pro Sekunde erhöht sich die durchschnittliche Antwortzeit deutlich auf über zehn Sekunden mit mehrfachen Verbindungsfehlern. Anders gesagt: Alles, was über fünf Anfragen pro Sekunde liegt, führt zu einer deutlichen Verlangsamung.
In einem komplexeren System wird die Kapazität des Servers in ähnlicher Weise bestimmt, hängt aber stark von der Kapazität aller seiner Komponenten ab. Sie können die Tools siege und httperf zusammen mit dem CPU- und E/A-Lastmonitoring aller Komponenten verwenden, z. B. der Komponenten des Frontend-Servers, des Anwendungsservers und des Datenbankservers, um Engpässe zu identifizieren. Dies wiederum hilft Ihnen, die optimale Skalierung für jede Komponente zu ermöglichen.
Auswirkungen einer Überlast beim Load-Balancing für eine einzelne Region messen
In diesem Abschnitt untersuchen Sie die Auswirkungen von Überlasten auf Load Balancer für einzelne Regionen, z. B. typische lokal genutzte Load Balancer oder Google Cloud externe Passthrough-Network-Load-Balancer. Sie können diesen Effekt auch bei einem HTTP(S)-Load-Balancer beobachten, wenn dieses für eine regionale statt für eine globale Bereitstellung genutzt wird.
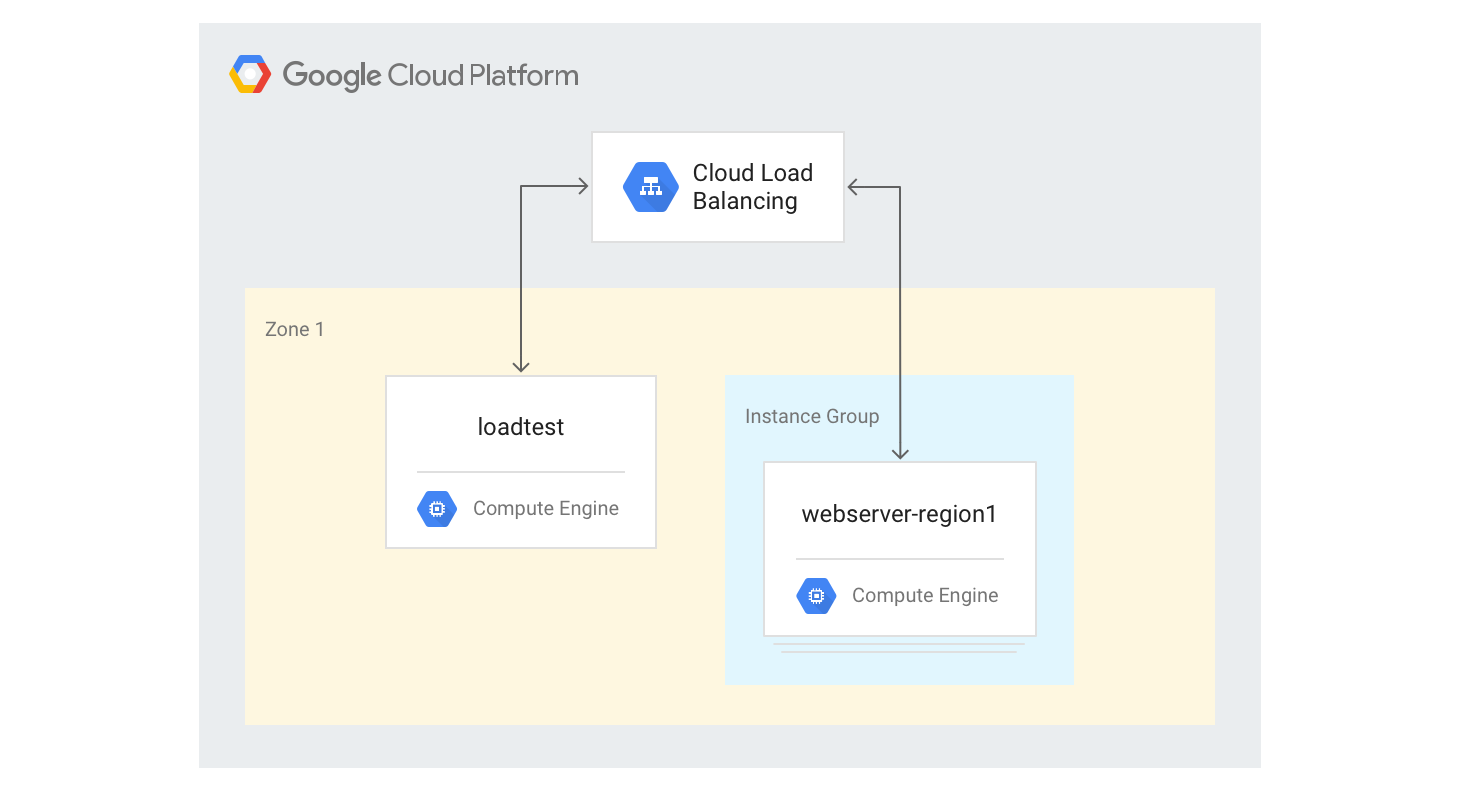
HTTP(S)-Load-Balancer für eine einzelne Region erstellen
In den folgenden Schritten wird beschrieben, wie Sie ein HTTP(S)-Load-Balancer für eine einzelne Region mit einer festen Größe von drei VM-Instanzen erstellen.
Erstellen Sie eine Instanzvorlage für die Webserver-VM-Instanzen mithilfe des Python-Mandelbrot-Generierungsskripts, das Sie zuvor verwendet haben. Führen Sie die folgenden Befehle in Cloud Shell aus:
gcloud compute instance-templates create webservers \ --machine-type n1-highcpu-4 \ --image-family=debian-12 --image-project=debian-cloud \ --tags=http-server \ --network=lb-testing \ --metadata startup-script='#! /bin/bash apt-get -y update apt-get install -y git python-numpy python-matplotlib git clone \ https://github.com/GoogleCloudPlatform/lb-app-capacity-tutorial-python.git cd lb-app-capacity-tutorial-python python webserver.py'Erstellen Sie eine verwaltete Instanzgruppe mit drei Instanzen basierend auf der Vorlage aus dem vorherigen Schritt:
gcloud compute instance-groups managed create webserver-region1 \ --size=3 --template=webserversErstellen Sie die Systemdiagnose, den Back-End-Dienst, die URL-Zuordnung, den Ziel-Proxy und die globale Weiterleitungsregel, die zum Generieren des HTTP-Load-Balancing erforderlich sind:
gcloud compute health-checks create http basic-check \ --request-path="/health-check" --check-interval=60s gcloud compute backend-services create web-service \ --health-checks basic-check --global gcloud compute backend-services add-backend web-service \ --global --instance-group=webserver-region1 \ --instance-group-zone $ZONE gcloud compute url-maps create web-map --default-service web-service gcloud compute target-http-proxies create web-proxy --url-map web-map gcloud compute forwarding-rules create web-rule --global \ --target-http-proxy web-proxy --ports 80Ermitteln Sie die IP-Adresse der Weiterleitungsregel:
gcloud compute forwarding-rules describe --global web-rule --format "value(IPAddress)"
Die Ausgabe ist die öffentliche IP-Adresse des von Ihnen erstellten Load-Balancers.
Gehen Sie in einem Browser zu der IP-Adresse, die vom vorherigen Befehl zurückgegeben wurde. Nach ein paar Minuten sehen Sie das gleiche Mandelbrot-Bild wie zuvor. Dieses Mal wird das Bild jedoch von einer der VM-Instanzen in der neu erstellten Gruppe bereitgestellt.
Melden Sie sich auf dem Computer
loadtestan:gcloud compute ssh loadtest
Testen Sie in der Befehlszeile der
loadtest-Maschine die Serverantwort mit unterschiedlich vielen Anfragen pro Sekunde (RPS). Achten Sie darauf, dass Sie RPS-Werte mindestens im Bereich von 5 bis 20 verwenden.Mit dem folgenden Befehl wird beispielsweise 10 RPS generiert. Ersetzen Sie
[IP_address]durch die IP-Adresse des Load-Balancers aus einem früheren Schritt in dieser Anleitung.httperf --server [IP_address] --num-conns 500 --rate 10 2>&1| grep 'Errors\|ion time'
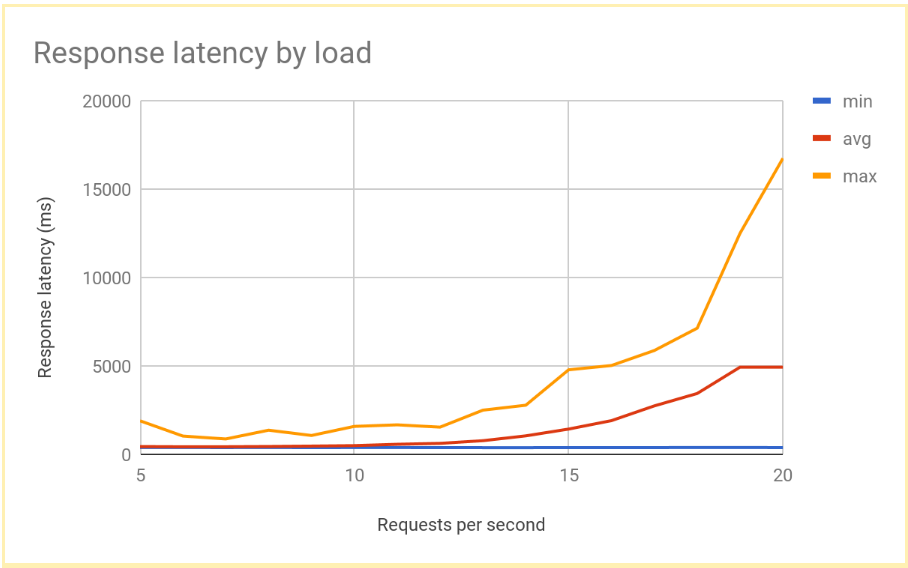
Die Antwortlatenz nimmt deutlich zu, wenn der RPS-Wert 12 oder 13 RPS übersteigt. Hier sehen Sie eine Darstellung typischer Ergebnisse:
Melden Sie sich von der VM-Instanz
loadtestab:exit
Diese Leistung ist typisch für ein System mit regionalem Load-Balancing. Wenn die Last die Bereitstellungskapazität übersteigt, nehmen die durchschnittliche Latenz sowie die maximale Anfragelatenz deutlich zu. Bei 10 RPS liegt die durchschnittliche Anfragelatenz nahe bei 500 ms. Bei 20 RPS beträgt sie hingegen 5.000 ms. Die Latenz hat sich verzehnfacht und die Nutzererfahrung verschlechtert sich schnell, was zu einem Rückgang der Nutzerzahlen, zu Zeitüberschreitungen der Anwendung oder zu beidem führt.
Im nächsten Abschnitt fügen Sie der Load-Balancing-Topologie eine zweite Region hinzu und vergleichen, wie der regionsübergreifende Failover die Endnutzerlatenz beeinflusst.
Auswirkungen eines Überlaufs in eine andere Region messen
Wenn Sie eine globale Anwendung mit einem externen Application Load Balancer verwenden und Back-Ends in mehreren Regionen bereitgestellt haben und dann in einer einzelnen Region eine Kapazitätsüberlastung auftritt, fließt der Traffic automatisch in eine andere Region. Sie können dies überprüfen, indem Sie der Konfiguration, die Sie im vorherigen Abschnitt erstellt haben, eine zweite VM-Instanzgruppe in einer anderen Region hinzufügen.
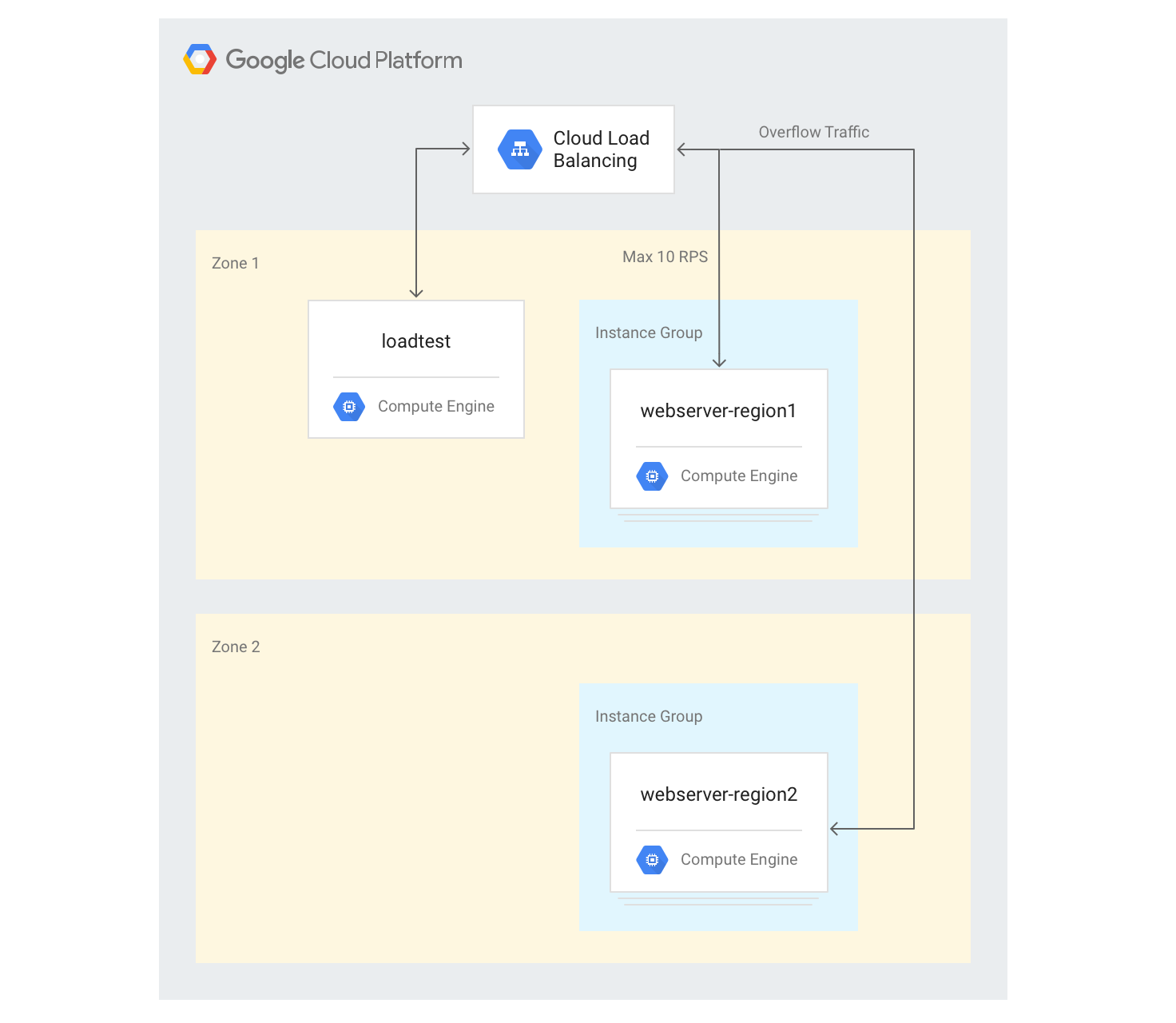
Server in mehreren Regionen erstellen
In den folgenden Schritten fügen Sie eine weitere Gruppe von Back-Ends in einer anderen Region hinzu und weisen eine Kapazität von 10 RPS pro Region zu. Sie sehen dann, wie das Load-Balancing reagiert, wenn dieses Limit überschritten wird.
Wählen Sie in Cloud Shell eine Zone in einer anderen Region als der Region der Standardzone aus und legen Sie sie als Umgebungsvariable fest:
export ZONE2=[zone]
Erstellen Sie in der zweiten Region eine neue Instanzgruppe mit drei VM-Instanzen:
gcloud compute instance-groups managed create webserver-region2 \ --size=3 --template=webservers --zone $ZONE2Fügen Sie die Instanzgruppe dem vorhandenen Back-End-Dienst mit einer maximalen Kapazität von 10 RPS hinzu:
gcloud compute backend-services add-backend web-service \ --global --instance-group=webserver-region2 \ --instance-group-zone $ZONE2 --max-rate 10Setzen Sie die
max-ratefür den vorhandenen Back-End-Dienst auf 10 RPS:gcloud compute backend-services update-backend web-service \ --global --instance-group=webserver-region1 \ --instance-group-zone $ZONE --max-rate 10Melden Sie sich, nachdem alle Instanzen gestartet worden sind, in der
loadtest-VM-Instanz an:gcloud compute ssh loadtest
Führen Sie 500 Anfragen mit 10 RPS aus. Ersetzen Sie
[IP_address]durch die IP-Adresse des Load-Balancers:httperf --server [IP_address] --num-conns 500 --rate 10 2>&1| grep 'ion time'
Die Ergebnisse sollten so aussehen:
Connection time [ms]: min 405.9 avg 584.7 max 1390.4 median 531.5 stddev 181.3 Connection time [ms]: connect 1.1
Die Ergebnisse ähneln denen beim regionalen Load-Balancing.
Da das Testtool sofort eine vollständige Last ausführt und diese nicht wie bei einer realen Implementierung langsam erhöht, müssen Sie den Test mehrmals wiederholen, damit der Überlaufmechanismus wirksam wird. Führen Sie fünfmal 500 Anfragen mit 20 RPS aus. Ersetzen Sie
[IP_address]durch die IP-Adresse des Load-Balancers.for a in \`seq 1 5\`; do httperf --server [IP_address] \ --num-conns 500 --rate 20 2>&1| grep 'ion time' ; doneDie Ergebnisse sollten so aussehen:
Connection time [ms]: min 426.7 avg 6396.8 max 13615.1 median 7351.5 stddev 3226.8 Connection time [ms]: connect 0.9 Connection time [ms]: min 417.2 avg 3782.9 max 7979.5 median 3623.5 stddev 2479.8 Connection time [ms]: connect 0.9 Connection time [ms]: min 411.6 avg 860.0 max 3971.2 median 705.5 stddev 492.9 Connection time [ms]: connect 0.7 Connection time [ms]: min 407.3 avg 700.8 max 1927.8 median 667.5 stddev 232.1 Connection time [ms]: connect 0.7 Connection time [ms]: min 410.8 avg 701.8 max 1612.3 median 669.5 stddev 209.0 Connection time [ms]: connect 0.8
Nachdem sich das System stabilisiert hat, beträgt die durchschnittliche Antwortzeit 400 ms bei 10 RPS und steigt bei 20 RPS nur auf 700 ms. Dies ist eine enorme Verbesserung gegenüber der Verzögerung von 5.000 ms, die bei einem regionalen Load-Balancer auftritt, und bedeutet eine deutliche Verbesserung der Nutzererfahrung.
In der folgenden Grafik ist die gemessene Antwortzeit in Abhängigkeit von den Anfragen pro Sekunde bei globalem Load-Balancing dargestellt:
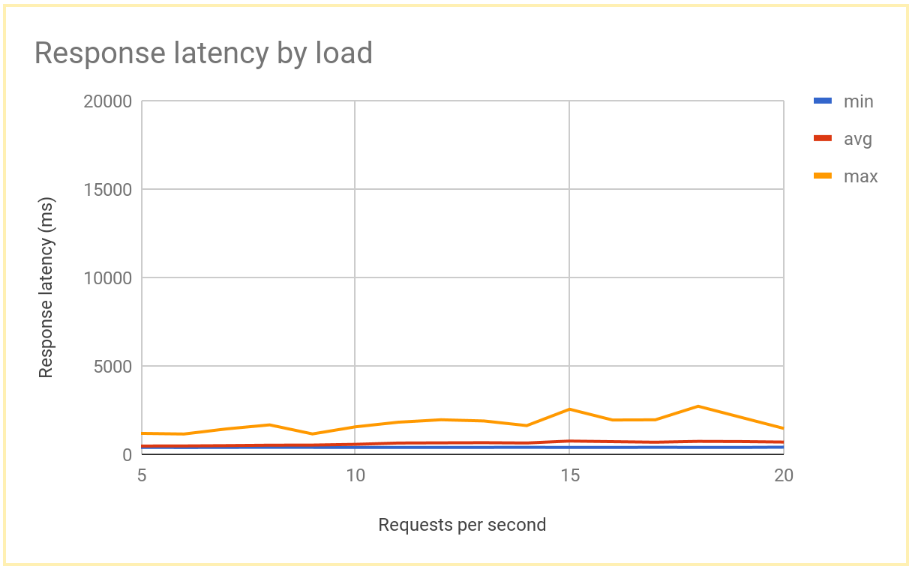
Ergebnisse des regionalen und des globalen Load-Balancing vergleichen
Nachdem Sie die Kapazität eines einzelnen Knotens ermittelt haben, können Sie die von Endnutzern in einer regionalen Bereitstellung wahrgenommene Latenz mit der Latenz in einer Architektur mit globalem Load-Balancing vergleichen. Obwohl die Anzahl der Anfragen in eine einzelne Region niedriger als die Gesamtbereitstellungskapazität in dieser Region ist, haben beide Systeme eine ähnliche Endnutzerlatenz, weil Nutzer immer zur nächsten Region weitergeleitet werden.
Wenn die Last einer Region die Bereitstellungskapazität für diese Region übersteigt, unterscheidet sich die Latenzzeit für den Endnutzer bei den Lösungen erheblich:
Lösungen mit regionalem Load-Balancing werden überlastet, wenn der Traffic die Kapazität überschreitet, weil er nur zu den überlasteten Backend-VM-Instanzen fließen kann. Dazu gehören herkömmliche lokale Load Balancer,externe Passthrough-Network-Load-Balancer auf Google Cloudund externe Application Load Balancer in einer Konfiguration mit einer einzelnen Region (z. B. bei einem Netzwerk der Standard-Stufe). Die durchschnittliche und die maximale Anfragelatenz erhöhen sich um mehr als den Faktor 10, was eine schlechte Nutzererfahrung zur Folge hat und wiederum zu einem deutlichen Rückgang der Nutzerzahlen führen kann.
Globale externe Application Load Balancer mit Back-Ends in mehreren Regionen lassen den Traffic zu der nächstgelegenen Region mit verfügbarer Bereitstellungskapazität überlaufen. Dies führt zu einem messbaren, aber vergleichsweise geringen Anstieg der Endnutzerlatenz und zu einer viel besseren Nutzererfahrung. Wenn Ihre Anwendung in einer Region nicht schnell genug skaliert werden kann, ist der globale externe Application Load Balancer die empfohlene Option. Sogar während eines Ausfalls der Nutzeranwendungsserver in der gesamten Region wird der Traffic schnell zu anderen Regionen weitergeleitet, sodass vollständige Dienstausfälle verhindert werden können.
Bereinigen
Projekt löschen
Am einfachsten vermeiden Sie weitere Kosten durch Löschen des für die Anleitung erstellten Projekts.
So löschen Sie das Projekt:
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Nächste Schritte
Auf den folgenden Seiten finden Sie weitere Informationen zu den Load-Balancing-Ooptionen von Google:
- Anwendungslatenz mithilfe von Cloud Load Balancing optimieren
- Codelab "Networking 101"
- Externer Passthrough Network Load Balancer
- Externer Application Load Balancer
- Externer Proxy-Network Load Balancer