Afin de répartir le trafic, la plupart des équilibreurs de charge utilisent une méthode de hachage par interrogation à répétition alternée ou basée sur le flux. Toutefois, cette approche peut entraîner certaines difficultés d'adaptation lors des pics de demande dépassant la capacité de service disponible. Cet article explique comment résoudre ces problèmes et optimiser la capacité globale de vos applications à l'aide de Cloud Load Balancing. Cela se traduit souvent par une expérience utilisateur améliorée et des coûts réduits par rapport aux mises en œuvre traditionnelles d'équilibrage de charge.
Cet article fait partie d'une série de documents consacrés aux bonnes pratiques d'utilisation des produits Cloud Load Balancing. Consultez la section Gérer la capacité à l'aide de l'équilibrage de charge pour accéder au tutoriel associé à cet article. Pour une analyse approfondie de la latence, consultez la section Optimiser la latence des applications avec l'équilibrage de charge.
Défis liés à la capacité des applications de classe mondiale
Le scaling d'applications de classe mondiale peut s'avérer difficile, en particulier si vous avez des budgets informatiques limités ainsi que des charges de travail imprévisibles et intensives. Dans les environnements cloud publics tels que Google Cloud, la flexibilité fournie par des fonctionnalités telles que l'autoscaling et l'équilibrage de charge peut s'avérer utile. Toutefois, les autoscalers sont soumis à certaines limites, tel que l'explique cette section.
Latence lors du démarrage de nouvelles instances
Le problème le plus courant lié à l'autoscaling est que l'application requise n'est pas prête à diffuser votre trafic suffisamment rapidement. En fonction des images de votre instance de VM, les scripts doivent généralement être exécutés et les informations chargées avant que les instances de VM ne soient prêtes. L'équilibrage de charge a souvent besoin de quelques minutes avant de pouvoir rediriger les utilisateurs vers de nouvelles instances de VM. Pendant ce temps, le trafic est distribué aux instances de VM existantes, qui peuvent déjà être en surcapacité.
Applications limitées par la capacité de backend
Certaines applications ne peuvent pas du tout bénéficier de l'autoscaling. Par exemple, les bases de données ont souvent une capacité de backend limitée. Seul un nombre spécifique de frontends peut accéder à une base de données ne pouvant pas subir de scaling horizontal. Si votre application repose sur des API externes n'acceptant qu'un nombre limité de requêtes par seconde, elle ne peut pas non plus subir d'autoscaling.
Licences non élastiques
Lorsque vous utilisez un logiciel sous licence, votre licence vous limite souvent à une capacité maximale prédéfinie. Votre capacité d'autoscaling peut donc être limitée, car vous ne pouvez pas ajouter de licences instantanément.
Marge d'instance de VM insuffisante
Pour prendre en compte les pics de trafic soudains, un autoscaler doit disposer d'une marge suffisante (par exemple, se déclencher à 70 % de la capacité du processeur). Afin de réduire les coûts, vous pourriez être tenté de faire passer cette valeur à 90 % de la capacité du processeur. Toutefois, des valeurs de déclenchement plus élevées peuvent entraîner des goulots d'étranglement lors des pics de trafic, comme une campagne publicitaire qui augmente soudainement la demande. Vous devez équilibrer la taille de la marge en fonction de l'ampleur de votre trafic et du temps que mettent vos nouvelles instances de VM pour être prêtes.
Quotas régionaux
Si vous rencontrez des pics inattendus dans une région, vos quotas de ressources existants peuvent limiter le nombre d'instances adaptables au-dessous du niveau requis pour pouvoir gérer le pic actuel. Le traitement d'une augmentation de votre quota de ressources peut prendre quelques heures ou quelques jours.
Relever ces défis à l'aide de l'équilibrage de charge global
Les équilibreurs de charge d'application externes et les équilibreurs de charge réseau proxy externes sont des produits d'équilibrage de charge mondiaux transmis par proxy via des serveurs Google Front End (GFE) synchronisés à l'échelle mondiale, ce qui facilite la résolution de tels problèmes d'équilibrage de charge. Ces produits représentent une solution à ces défis, car le trafic est distribué aux backends d'une manière différente que dans la plupart des solutions d'équilibrage de charge régional.
Ces différences sont décrites dans les sections suivantes.
Algorithmes utilisés par d'autres équilibreurs de charge
La plupart des équilibreurs de charge utilisent les mêmes algorithmes pour répartir le trafic entre les backends :
- Interrogation à répétition alternée. Les paquets sont répartis équitablement entre tous les backends, indépendamment de leur source et de leur destination.
- Hachage. Les flux de paquets sont identifiés en fonction des hachages d'informations liées au trafic, y compris l'adresse IP source, l'adresse IP de destination, le port et le protocole. Le trafic avec la même valeur de hachage circule vers le même backend.
Le hachage d'équilibrage de charge est l'algorithme actuellement disponible pour les équilibreurs de charge réseau passthrough externes. Cet équilibreur de charge accepte le hachage 2-tuple (en fonction de l'IP source et de destination), le hachage 3-tuple (en fonction de l'IP source, de l'IP de destination et du protocole) et le hachage 5-tuple (en fonction de l'IP source, de l'IP de destination, du port source, du port de destination et du protocole).
Ces deux algorithmes entraînent le retrait de la distribution des instances défectueuses. Toutefois, la charge actuelle sur les backends constitue rarement un facteur de répartition de la charge.
Certains équilibreurs de charge matériels ou logiciels utilisent des algorithmes qui transfèrent le trafic en fonction d'autres métriques, telles que l'interrogation à répétition alternée pondérée, la charge minimale, le temps de réponse le plus rapide ou le nombre de connexions actives. Toutefois, si la charge dépasse le niveau attendu en raison de pics de trafic soudains, le trafic est quand même distribué aux instances backend en surcapacité, ce qui entraîne une augmentation considérable du temps de latence.
Certains équilibreurs de charge autorisent des règles avancées selon lesquelles le trafic dépassant la capacité du backend est transféré vers un autre pool ou redirigé vers un site Web statique. Cela vous permet de rejeter efficacement ce trafic et d'envoyer le message suivant : "Le service est indisponible. Veuillez réessayer ultérieurement". Certains équilibreurs de charge offrent la possibilité de mettre des requêtes en file d'attente.
Les solutions d'équilibrage de charge global sont souvent mises en œuvre à l'aide d'un algorithme basé sur le DNS, desservant différentes adresses IP d'équilibrage de charge régional en fonction de l'emplacement de l'utilisateur et de la charge du backend. Ces solutions offrent un basculement vers une autre région pour l'ensemble ou une partie du trafic lors d'un déploiement régional. Toutefois, sur une solution basée sur DNS, le basculement prend généralement quelques minutes, selon les valeurs TTL (Time To Live) des entrées DNS. En général, une petite quantité de trafic continuera d'être dirigée vers les anciens serveurs bien après le délai d'expiration de la valeur TTL. L'équilibrage de charge global basé sur le DNS n'est donc pas la solution optimale pour la gestion du trafic dans des scénarios intensifs.
Fonctionnement des équilibreurs de charge d'applications externes
L'équilibreur de charge d'application externe utilise une approche différente. Le trafic est mis en proxy via les serveurs GFE déployés dans la plupart des emplacements périphériques du réseau mondial de Google. Cela représente actuellement plus de 80 emplacements dans le monde. L'algorithme d'équilibrage de charge est appliqué au niveau des serveurs GFE.

L'équilibreur de charge d'application externe est disponible via une adresse IP stable unique qui est annoncée à l'échelle mondiale au niveau des nœuds périphériques et les connexions sont effectuées par n'importe quel serveur GFE.
Les GFE sont interconnectés via le réseau mondial de Google. Les données décrivant les backends disponibles et la capacité de diffusion disponible pour chaque ressource à équilibrage de charge sont distribuées en permanence à tous les GFE à l'aide d'un plan de contrôle global.
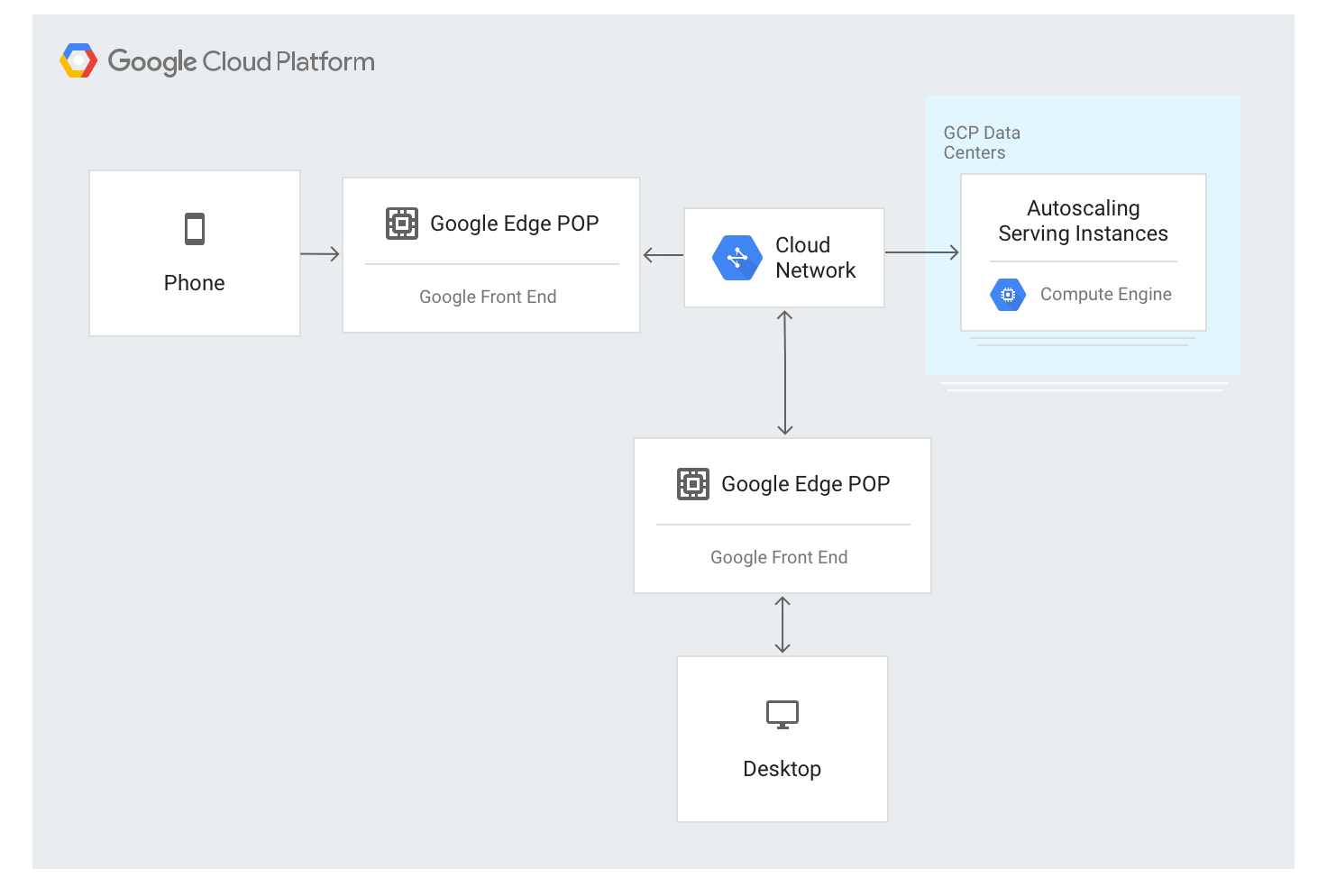
Le trafic vers les adresses IP à équilibrage de charge est envoyé par proxy aux instances backend, qui sont définies dans la configuration de l'équilibreur de charge d'application externe, à l'aide d'un algorithme d'équilibrage de charge spécial nommé Waterfall by Region (cascade par région). Cet algorithme détermine le backend optimal pour traiter la demande en tenant compte de la proximité des instances par rapport aux utilisateurs, de la charge entrante ainsi que de la capacité disponible des backends dans chaque zone et région. Enfin, la charge et la capacité mondiales sont également prises en compte.
L'équilibreur de charge d'application externe répartit le trafic en fonction des instances disponibles. Pour ajouter des instances en fonction de la charge, l'algorithme fonctionne simultanément avec des groupes d'instances pour l'autoscaling.
Flux de trafic au sein d'une région
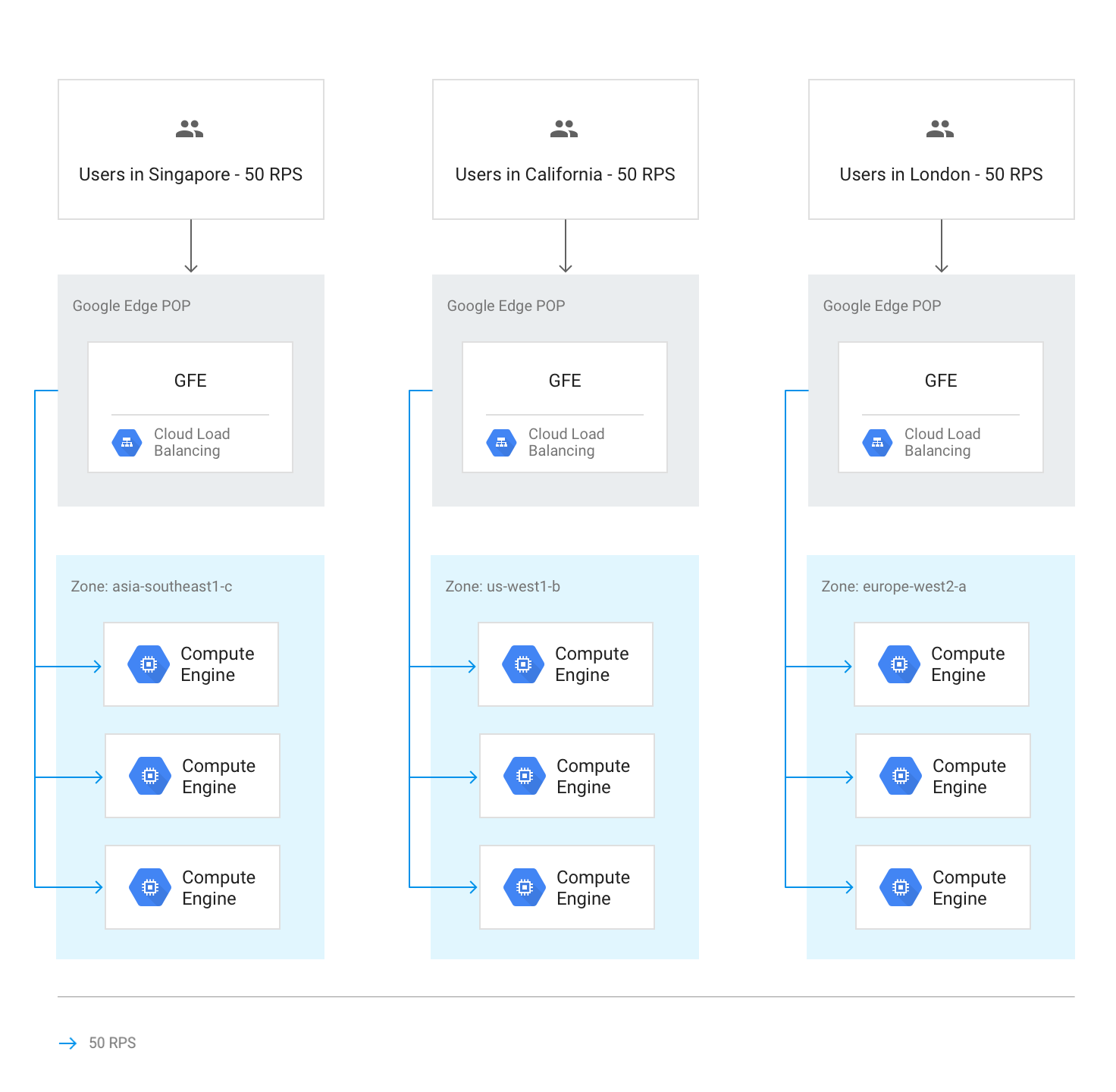
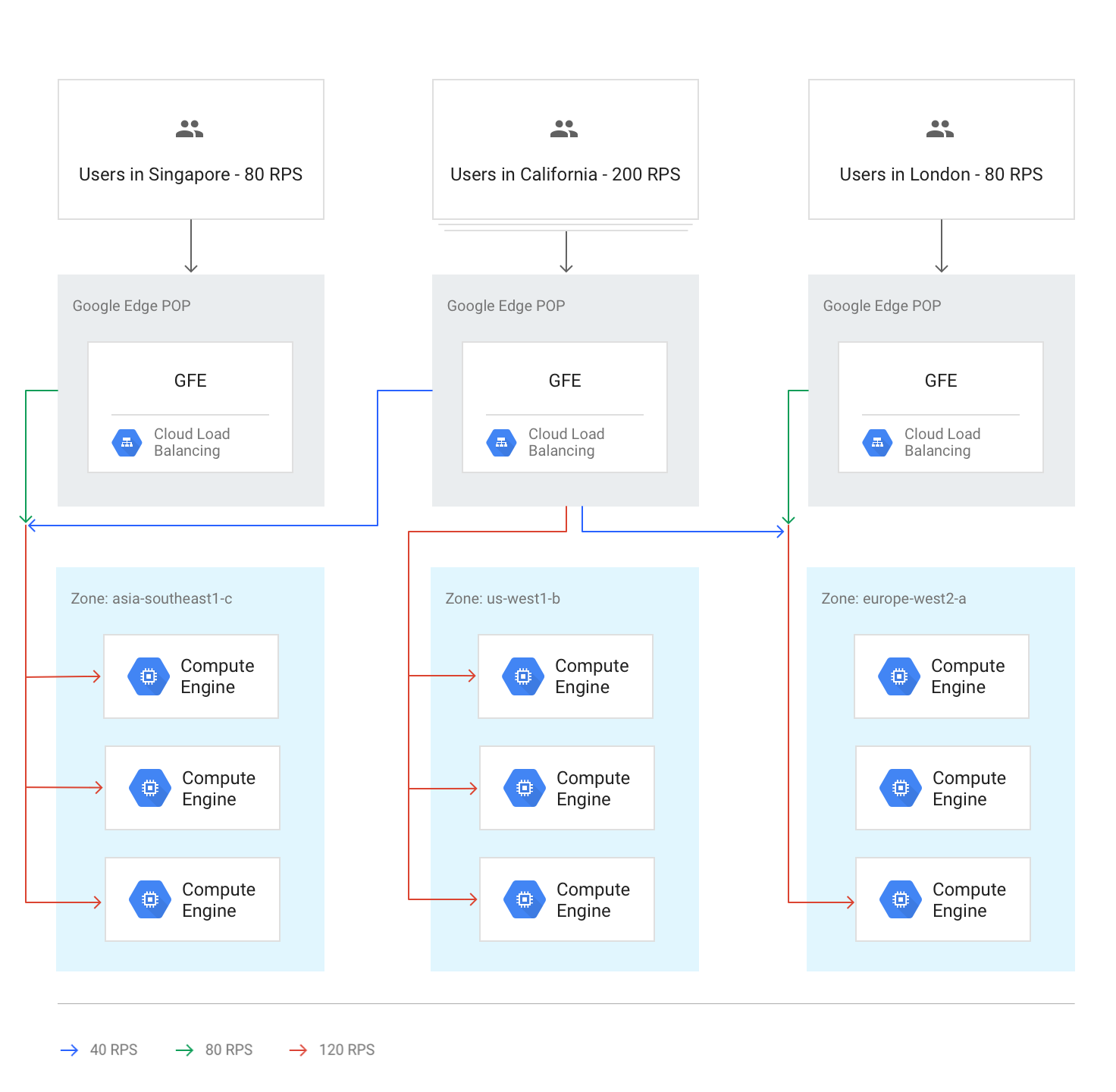
En temps normal, tout le trafic est envoyé à la région la plus proche de l'utilisateur. L'équilibrage de charge est ensuite effectué conformément à ces instructions :
Dans chaque région, le trafic est réparti entre des groupes d'instances, qui peuvent se trouver dans plusieurs zones en fonction de la capacité de chaque groupe.
Si la capacité est inégale d'une zone à l'autre, les zones sont chargées proportionnellement à leur capacité de diffusion disponible.
Dans les zones, les requêtes sont réparties uniformément sur les instances de chaque groupe d'instances.
Les sessions sont conservées en fonction de l'adresse IP du client ou d'une valeur de cookie, selon le paramètre d'affinité de session.
À moins que le serveur ne devienne indisponible, les connexions TCP existantes ne sont jamais transférées vers un backend différent.
Le schéma suivant montre la distribution de la charge dans ce cas, où chaque région est en sous-capacité et capable de gérer la charge des utilisateurs les plus proches de cette région.
Débordement du trafic vers d'autres régions
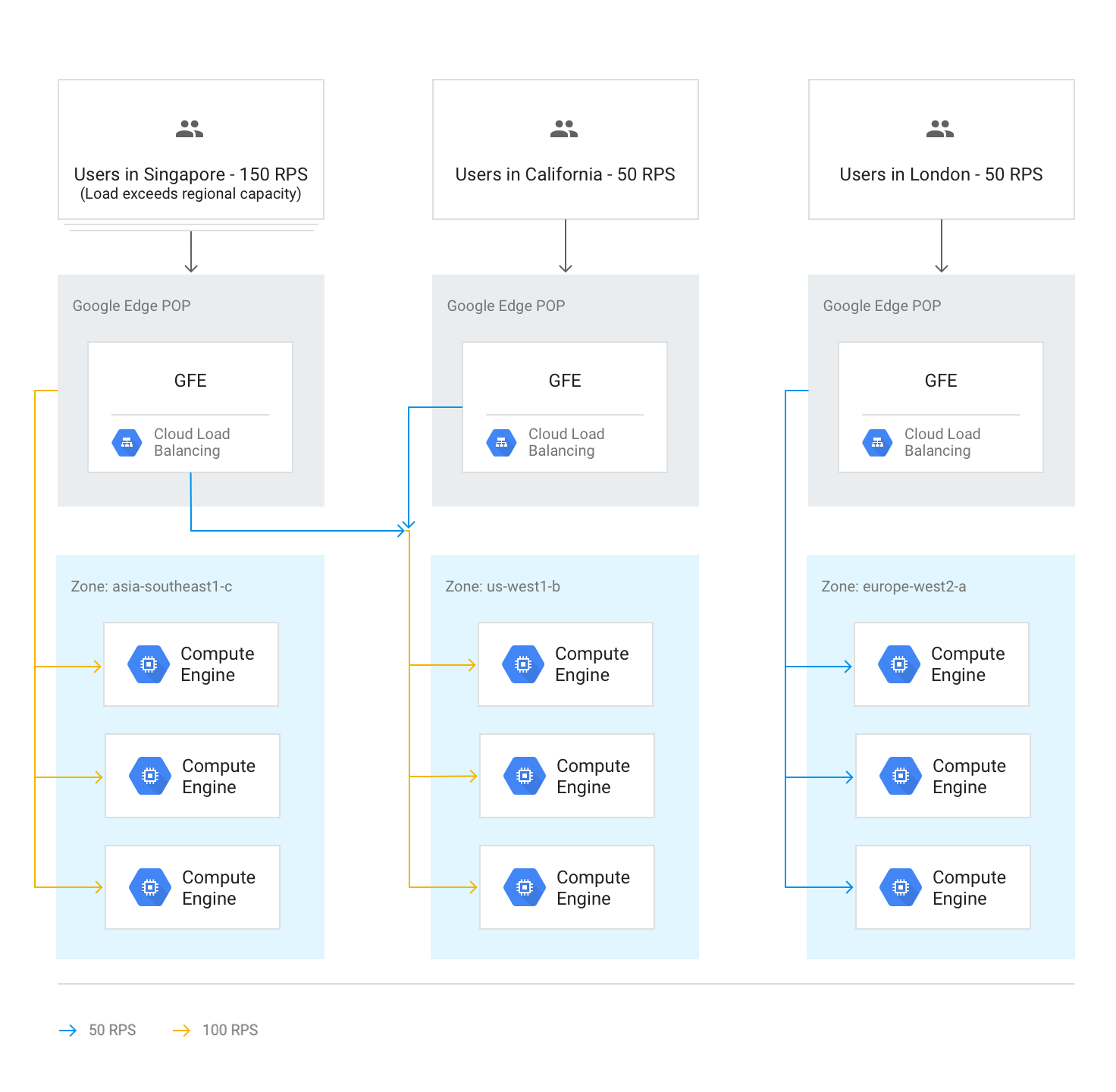
Si une région entière atteint la capacité maximale déterminée par la capacité de diffusion définie dans les services de backend, l'algorithme Waterfall by Region se déclenche et le trafic déborde vers la région la plus proche disposant de la capacité disponible. Lorsque chaque région atteint sa capacité maximale, le trafic se déverse dans la région la plus proche, et ainsi de suite. La proximité d'une région avec l'utilisateur est définie par le délai aller-retour du réseau depuis le GFE vers les backends de l'instance.
Le schéma suivant illustre le débordement vers la région la plus proche suivante lorsqu'une région reçoit plus de trafic qu'elle ne peut en traiter au niveau régional.
Débordement sur plusieurs régions en raison de backends défectueux
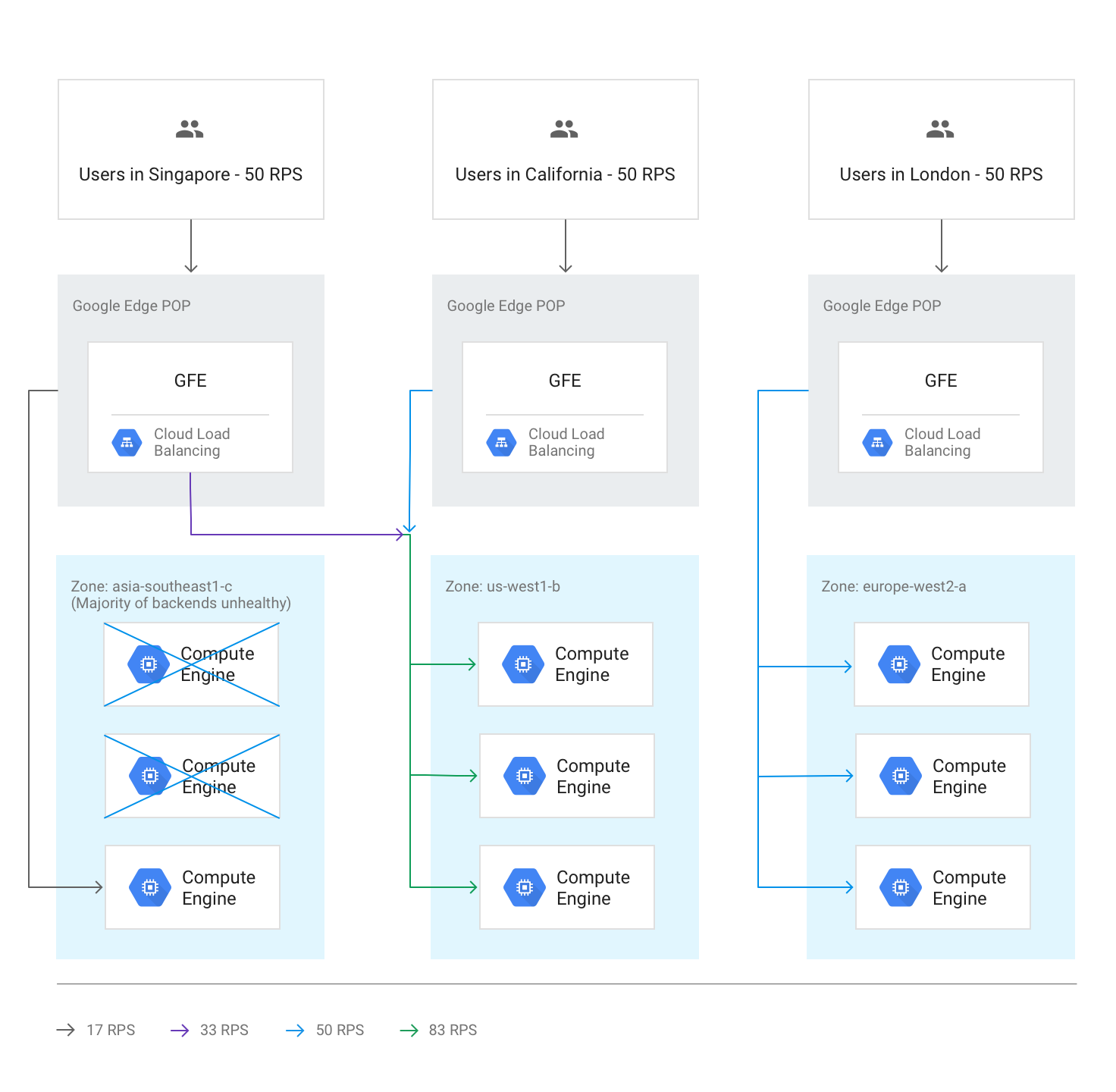
Si les vérifications d'état indiquent que plus de la moitié des backends d'une région sont défectueux, les GFE font déborder de manière préemptive une partie du trafic vers la région la plus proche. Ce phénomène permet d'éviter que le trafic échoue complètement alors que la région devient non opérationnelle. Ce débordement se produit même si la capacité restante dans la région avec les backends défectueux est suffisante.
Le schéma ci-dessous illustre le mécanisme de débordement en action, car la majorité des backends d'une zone sont défectueux.
Surcapacité de toutes les régions
Lorsque le trafic de toutes les régions est égal ou supérieur à sa capacité, le trafic est équilibré de sorte que chaque région présente le même niveau de débordement relatif par rapport à sa capacité. Par exemple, si la demande mondiale dépasse la capacité mondiale de 20 %, le trafic est réparti de manière que toutes les régions reçoivent des demandes à 20 % de leur capacité régionale, tout en conservant le trafic aussi local que possible.
Le schéma suivant illustre cette règle de débordement global en action. Dans ce cas, une seule région reçoit une quantité de trafic si élevée que la capacité de diffusion disponible au niveau mondial ne lui permet pas de le distribuer.
Débordement temporaire durant l'autoscaling
L'autoscaling est basé sur les limites de capacité configurées sur chaque service de backend et affiche de nouvelles instances lorsque le trafic se rapproche de ces limites. Selon la rapidité de l'augmentation des niveaux de requête et de la publication en ligne des nouvelles instances, un débordement vers d'autres régions peut s'avérer inutile. Dans d'autres cas, le débordement peut servir de tampon temporaire jusqu'à ce que de nouvelles instances locales soient en ligne et prêtes à diffuser le trafic en temps réel. Lorsque la capacité élargie par l'autoscaling est suffisante, toutes les nouvelles sessions sont réparties dans la région la plus proche.
Effets de latence du débordement
Selon l'algorithme "Waterfall by Region", un débordement d'une partie du trafic par l'équilibreur de charge d'application externe vers d'autres régions peut se produire. Toutefois, les sessions TCP et le trafic SSL sont toujours effectués par le GFE le plus proche de l'utilisateur. Ce phénomène est bénéfique à la latence des applications. Pour en savoir plus, consultez la section Optimiser la latence des applications avec l'équilibrage de charge.
Atelier pratique : mesurer les effets de la gestion de la capacité
Pour comprendre comment se produisent les débordements et comment les gérer à l'aide de l'équilibreur de charge HTTP, consultez le tutoriel Gérer la capacité avec l'équilibrage de charge associé à cet article.
Utiliser un équilibreur de charge d'application externe pour résoudre les problèmes de capacité
Pour aider à la résolution des problèmes évoqués précédemment, les équilibreurs de charge d'application externe et les équilibreurs de charge réseau proxy externes peuvent faire déborder la capacité vers d'autres régions. Pour les applications de classe mondiale, répondre aux utilisateurs avec une latence globale légèrement plus élevée est souvent plus avantageux que d'utiliser un backend régional. Les applications qui utilisent un backend régional ont une latence nominale inférieure, mais elles peuvent être surchargées.
Revoyons comment un équilibreur de charge d'application externe peut aider à résoudre les scénarios mentionnés au début de l'article :
Latence lors du démarrage de nouvelles instances. Si l'autoscaler ne peut pas ajouter de capacité suffisamment rapidement lors des pics de trafic local, l'équilibreur de charge d'application externe fait temporairement déborder les connexions vers la région la plus proche. Cela garantit que les sessions utilisateur existantes dans la région d'origine sont gérées à une vitesse optimale étant donné qu'elles restent sur les backends existants, tandis que les nouvelles sessions utilisateur ne subissent qu'une légère augmentation de latence. Dès que des instances de backend supplémentaires sont adaptées dans la région d'origine, le nouveau trafic est à nouveau acheminé vers la région la plus proche des utilisateurs.
Applications limitées par la capacité de backend. Les applications qui ne peuvent pas subir d'autoscaling, mais qui sont disponibles dans plusieurs régions peuvent toujours déborder sur la région la plus proche suivante lorsque la demande dans une région dépasse la capacité déployée pour les besoins en trafic habituels.
Licences non élastiques. Si le nombre de licences logicielles est limité et si le pool de licences de la région actuelle est épuisé, l'équilibreur de charge d'application externe peut transférer le trafic vers une région où des licences sont disponibles. Pour ce faire, le nombre maximal d'instances est défini sur le nombre maximal de licences sur l'autoscaler.
Marge de VM insuffisante. La possibilité de débordement régional permet de faire des économies, car vous pouvez configurer l'autoscaling avec un déclencheur d'utilisation élevée du processeur. Vous pouvez également configurer la capacité de backend disponible en dessous de chaque pic régional, car un débordement vers d'autres régions garantit que la capacité globale sera toujours suffisante.
Quotas régionaux. Si les quotas de ressources Compute Engine ne correspondent pas à la demande, le débordement de l'équilibreur de charge d'application externe redirige automatiquement une partie du trafic vers une région pouvant encore évoluer dans les limites de son quota régional.
Étapes suivantes
Consultez les pages suivantes pour obtenir des informations complémentaires en contexte à propos des solutions d'équilibrage de charge de Google :
- Gérer la capacité à l'aide de l'équilibrage de charge (tutoriel)
- Optimiser la latence des applications avec l'équilibrage de charge
- Atelier de programmation sur les bases de la mise en réseau
- Équilibreur de charge réseau passthrough externe
- Équilibreur de charge d'application externe
- Équilibreur de charge réseau proxy externe