Esta página mostra-lhe como resolver problemas relacionados com o equilíbrio de carga em clusters do Google Kubernetes Engine (GKE) através de recursos de serviço, entrada ou gateway.
BackendConfig não encontrado
Este erro ocorre quando um BackendConfig para uma porta de serviço é especificado na anotação de serviço, mas não foi possível encontrar o recurso BackendConfig real.
Para avaliar um evento do Kubernetes, execute o seguinte comando:
kubectl get event
O exemplo de saída que se segue indica que o BackendConfig não foi encontrado:
KIND ... SOURCE
Ingress ... loadbalancer-controller
MESSAGE
Error during sync: error getting BackendConfig for port 80 on service "default/my-service":
no BackendConfig for service port exists
Para resolver este problema, certifique-se de que não criou o recurso BackendConfig no espaço de nomes errado nem escreveu incorretamente a respetiva referência na anotação do serviço.
Política de segurança de entrada não encontrada
Depois de criar o objeto Ingress, se a política de segurança não estiver associada corretamente ao serviço LoadBalancer, avalie o evento do Kubernetes para ver se existe um erro de configuração. Se o BackendConfig especificar uma política de segurança que não existe, é emitido periodicamente um evento de aviso.
Para avaliar um evento do Kubernetes, execute o seguinte comando:
kubectl get event
O seguinte resultado de exemplo indica que a sua política de segurança não foi encontrada:
KIND ... SOURCE
Ingress ... loadbalancer-controller
MESSAGE
Error during sync: The given security policy "my-policy" does not exist.
Para resolver este problema, especifique o nome da política de segurança correto no seu BackendConfig.
Resolver erros da série 500 com NEGs durante o dimensionamento da carga de trabalho no GKE
Sintoma:
Quando usa NEGs aprovisionados pelo GKE para o equilíbrio de carga, pode ter erros 502 ou 503 para os serviços durante a redução da escala da carga de trabalho. Os erros 502 ocorrem quando os pods são terminados antes de as ligações existentes serem fechadas, enquanto os erros 503 ocorrem quando o tráfego é direcionado para pods eliminados.
Este problema pode afetar os clusters se estiver a usar produtos de equilíbrio de carga geridos pelo GKE que usam NEGs, incluindo o Gateway, o Ingress e os NEGs autónomos. Se dimensionar frequentemente as suas cargas de trabalho, o cluster corre um risco mais elevado de ser afetado.
Diagnóstico:
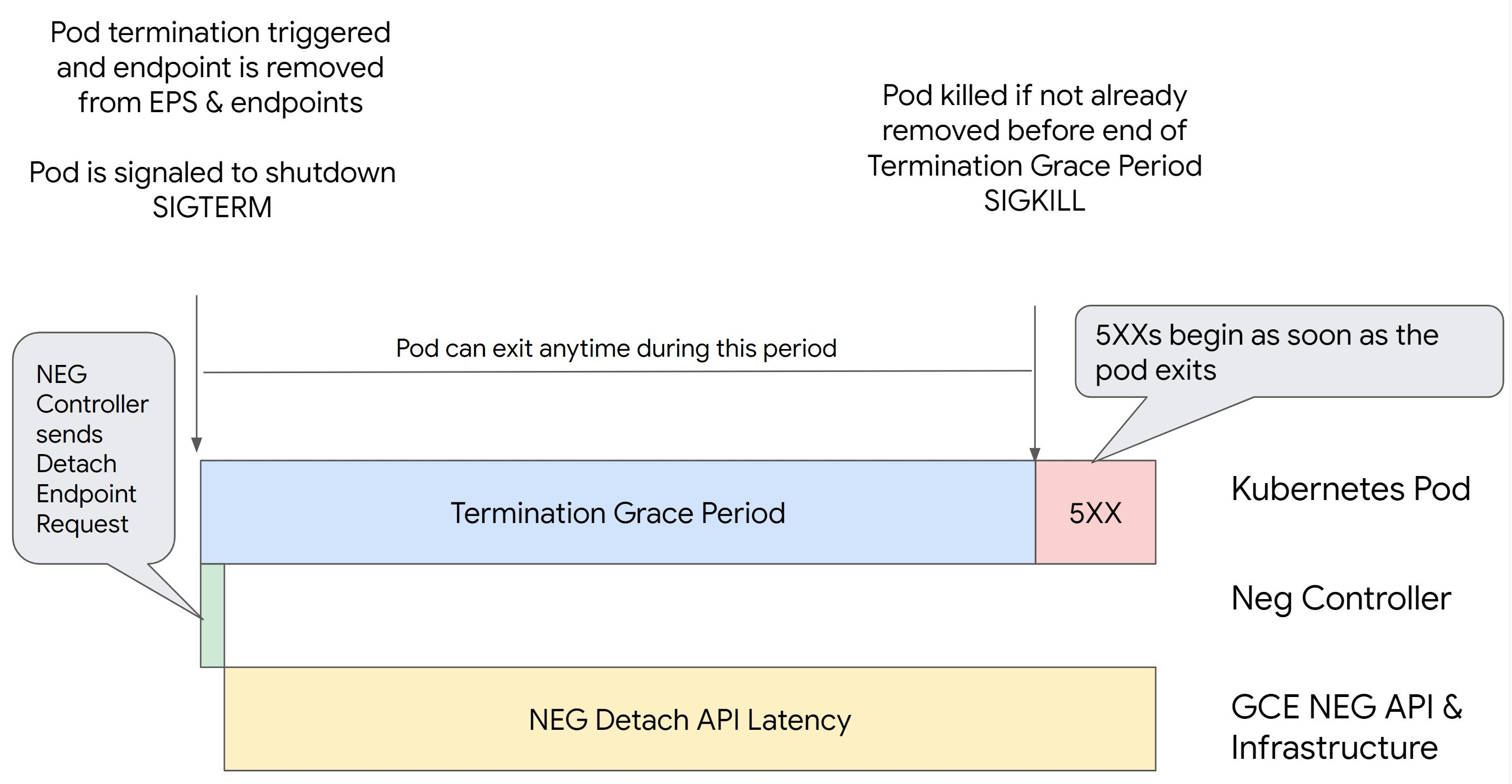
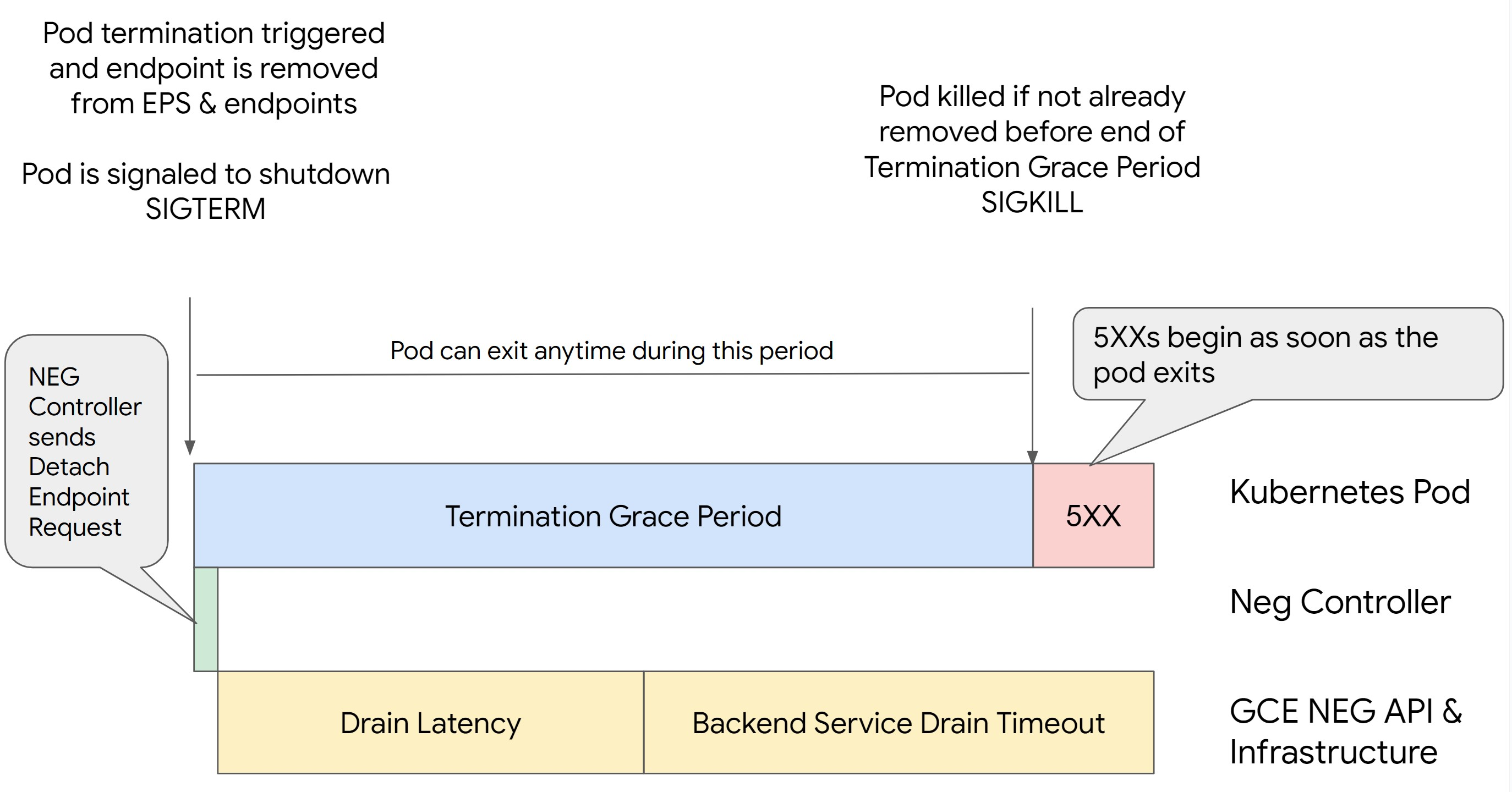
A remoção de um pod no Kubernetes sem esvaziar o respetivo ponto final e removê-lo primeiro do NEG resulta em erros da série 500. Para evitar problemas durante a terminação do pod, tem de considerar a ordem das operações. As imagens seguintes mostram cenários quando BackendService Drain Timeout não está definido e BackendService Drain Timeout está definido com BackendConfig.
Cenário 1: BackendService Drain Timeout não está definido.
A imagem seguinte apresenta um cenário em que o elemento BackendService Drain Timeout não está definido.
Cenário 2: BackendService Drain Timeout está definido.
A imagem seguinte apresenta um cenário em que o BackendService Drain Timeout está definido.
A altura exata em que ocorrem os erros da série 500 depende dos seguintes fatores:
Latência de desassociação da API NEG: a latência de desassociação da API NEG representa o tempo atual necessário para a operação de desassociação ser finalizada no Google Cloud. Isto é influenciado por vários fatores externos ao Kubernetes, incluindo o tipo de equilibrador de carga e a zona específica.
Latência de esgotamento: a latência de esgotamento é o tempo que o equilibrador de carga demora a começar a direcionar o tráfego para longe de uma parte específica do seu sistema. Depois de o esgotamento ser iniciado, o equilibrador de carga deixa de enviar novos pedidos para o ponto final. No entanto, ainda existe uma latência no acionamento do esgotamento (latência de esgotamento), o que pode causar erros 503 temporários se o pod já não existir.
Configuração da verificação de funcionamento: os limites de verificação de funcionamento mais sensíveis mitigam a duração dos erros 503, uma vez que podem sinalizar ao balanceador de carga que pare de enviar pedidos para os pontos finais, mesmo que a operação de desanexação não tenha terminado.
Período de tolerância para rescisão: o período de tolerância para rescisão determina o tempo máximo que um pod tem para sair. No entanto, um Pod pode sair antes de o período de tolerância de encerramento ser concluído. Se um agrupamento demorar mais do que este período, o agrupamento é forçado a sair no final deste período. Esta é uma definição no POD e tem de ser configurada na definição da carga de trabalho.
Potencial resolução:
Para evitar esses erros 5XX, aplique as seguintes definições. Os valores de tempo limite são sugestivos e pode ter de os ajustar para a sua aplicação específica. A secção seguinte explica o processo de personalização.
A imagem seguinte mostra como manter o Pod ativo com um gancho preStop:

Para evitar erros da série 500, siga estes passos:
Defina o
BackendService Drain Timeoutpara o seu serviço como 1 minuto.Para utilizadores de entrada, consulte defina o limite de tempo no BackendConfig.
Para utilizadores do Gateway, consulte configure o limite de tempo na GCPBackendPolicy.
Para quem gere os respetivos BackendServices diretamente quando usa NEGs autónomos, consulte como definir o limite de tempo diretamente no serviço de back-end.
Prolongue a
terminationGracePeriodno Pod.Defina o
terminationGracePeriodSecondsno Pod para 3,5 minutos. Quando combinado com as definições recomendadas, isto permite que os seus Pods tenham uma janela de 30 a 45 segundos para um encerramento normal após o ponto final do Pod ter sido removido do NEG. Se precisar de mais tempo para o encerramento gradual, pode prolongar o período de tolerância ou seguir as instruções mencionadas na secção Personalizar limites de tempo.O manifesto do pod seguinte especifica um limite de tempo de esgotamento da ligação de 210 segundos (3,5 minutos):
spec: terminationGracePeriodSeconds: 210 containers: - name: my-app ... ...Aplique um gancho
preStopa todos os contentores.Aplique um gancho
necessário.preStopque garanta que o pod está ativo durante mais 120 segundos enquanto o ponto final do pod é esgotado no equilibrador de carga e o ponto final é removido do NEG.spec: containers: - name: my-app ... lifecycle: preStop: exec: command: ["/bin/sh", "-c", "sleep 120s"] ...
Personalize os limites de tempo
Para garantir a continuidade do Pod e evitar erros da série 500, o Pod tem de estar ativo até o ponto final ser removido do NEG. Especificamente para evitar erros 502 e 503, considere implementar uma combinação de limites de tempo e um gancho preStop.
Para manter o Pod ativo durante mais tempo durante o processo de encerramento, adicione um preStopgancho
ao Pod. Execute o gancho preStop antes de um pod ser sinalizado para sair, para que o gancho preStop possa ser usado para manter o pod ativo até que o respetivo ponto final seja removido do NEG.
Para prolongar a duração durante a qual um Pod permanece ativo durante o processo de encerramento,
insira um gancho preStop na configuração do Pod da seguinte forma:
spec:
containers:
- name: my-app
...
lifecycle:
preStop:
exec:
command: ["/bin/sh", "-c", "sleep <latency time>"]
Pode configurar os limites de tempo e as definições relacionadas para gerir o encerramento controlado dos pods durante as reduções da escala da carga de trabalho. Pode ajustar os limites de tempo com base em exemplos de utilização específicos. Recomendamos que comece com limites de tempo mais longos e reduza a duração conforme necessário. Pode personalizar os limites de tempo configurando os parâmetros relacionados com o limite de tempo e o gancho preStop das seguintes formas:
Limite de tempo de esgotamento do serviço de back-end
O parâmetro Backend Service Drain Timeout não está definido por predefinição e não tem qualquer efeito. Se definir o parâmetro Backend Service Drain Timeout e ativá-lo, o balanceador de carga deixa de encaminhar novos pedidos para o ponto final e aguarda o tempo limite antes de terminar as ligações existentes.
Pode definir o parâmetro Backend Service Drain Timeout usando o BackendConfig com o Ingress, o GCPBackendPolicy com o Gateway ou manualmente no BackendService com NEGs autónomos. O limite de tempo deve ser 1,5 a 2 vezes
superior ao tempo necessário para processar um pedido. Isto garante que, se um pedido for recebido imediatamente antes de o esvaziamento ser iniciado, é concluído antes de o limite de tempo se esgotar. Definir o parâmetro Backend Service Drain Timeout para um valor superior a 0 ajuda a mitigar os erros 503, porque não são enviados novos pedidos para os pontos finais agendados para remoção. Para que este limite de tempo seja eficaz, tem de o usar com o comando preStop para garantir que o Pod permanece ativo enquanto ocorre a drenagem. Sem esta combinação, os pedidos existentes que não foram concluídos recebem um erro 502.
preStop tempo de gancho
O comando preStop tem de atrasar o encerramento do pod o suficiente para que a latência de esgotamento e o limite de tempo de esgotamento do serviço de back-end sejam concluídos, garantindo o esgotamento adequado das ligações e a remoção do ponto final do NEG antes de o pod ser encerrado.
Para obter os melhores resultados, certifique-se de que o tempo de execução do gancho preStop é superior ou igual à soma da latência de Backend Service Drain Timeout e de esgotamento.
Calcule o tempo de execução ideal do preStop gancho com a seguinte fórmula:
preStop hook execution time >= BACKEND_SERVICE_DRAIN_TIMEOUT + DRAIN_LATENCY
Substitua o seguinte:
BACKEND_SERVICE_DRAIN_TIMEOUT: a hora que configurou para oBackend Service Drain Timeout.DRAIN_LATENCY: um tempo estimado para a latência de esgotamento. Recomendamos que use um minuto como estimativa.
Se os erros 500 persistirem, estime a duração total da ocorrência e adicione o dobro desse tempo à latência de esgotamento estimada. Isto garante que o seu Pod tem tempo suficiente para esgotar a bateria antes de ser removido do serviço. Pode ajustar este valor se for demasiado longo para o seu exemplo de utilização específico.
Em alternativa, pode estimar a data/hora examinando a data/hora da eliminação do pod e a data/hora em que o ponto final foi removido do NEG nos registos de auditoria do Google Cloud.
Parâmetro do período de tolerância de rescisão
Tem de configurar o parâmetro terminationGracePeriod para permitir tempo suficiente para a conclusão do gancho preStop e para que o pod conclua um encerramento normal.
Por predefinição, quando não é definido explicitamente, o valor de terminationGracePeriod é 30 segundos.
Pode calcular o valor terminationGracePeriod ideal através da seguinte fórmula:
terminationGracePeriod >= preStop hook time + Pod shutdown time
Para definir terminationGracePeriod na configuração do pod da seguinte forma:
spec:
terminationGracePeriodSeconds: <terminationGracePeriod>
containers:
- name: my-app
...
...
Não foi encontrado um NEG ao criar um recurso Internal Ingress
O seguinte erro pode ocorrer quando cria um Ingress interno no GKE:
Error syncing: error running backend syncing routine: googleapi: Error 404: The resource 'projects/PROJECT_ID/zones/ZONE/networkEndpointGroups/NEG' was not found, notFound
Este erro ocorre porque o Ingress para equilibradores de carga de aplicações internos requer grupos de pontos finais de rede (NEGs) como back-ends.
Em ambientes de VPC partilhada ou clusters com políticas de rede ativadas,
adicione a anotação cloud.google.com/neg: '{"ingress": true}' ao manifesto do serviço.
504 Tempo limite do gateway: tempo limite do pedido a montante
O seguinte erro pode ocorrer quando acede a um serviço a partir de um Ingress interno no GKE:
HTTP/1.1 504 Gateway Timeout
content-length: 24
content-type: text/plain
upsteam request timeout
Este erro ocorre porque o tráfego enviado para equilibradores de carga de aplicações internos é encaminhado por proxy através de proxies do Envoy no intervalo de sub-rede apenas de proxy.
Para permitir o tráfego do intervalo de sub-rede só de proxy,
crie uma regra de firewall
no targetPort do serviço.
Erro 400: valor inválido para o campo "resource.target"
O seguinte erro pode ocorrer quando acede a um serviço a partir de um Ingress interno no GKE:
Error syncing:LB_NAME does not exist: googleapi: Error 400: Invalid value for field 'resource.target': 'https://www.googleapis.com/compute/v1/projects/PROJECT_NAME/regions/REGION_NAME/targetHttpProxies/LB_NAME. A reserved and active subnetwork is required in the same region and VPC as the forwarding rule.
Para resolver este problema, crie uma sub-rede apenas de proxy.
Erro durante a sincronização: erro ao executar a rotina de sincronização do equilibrador de carga: o equilibrador de carga não existe
Pode ocorrer um dos seguintes erros quando atualiza o plano de controlo do GKE ou quando modifica um objeto Ingress:
"Error during sync: error running load balancer syncing routine: loadbalancer
INGRESS_NAME does not exist: invalid ingress frontend configuration, please
check your usage of the 'kubernetes.io/ingress.allow-http' annotation."
Ou:
Error during sync: error running load balancer syncing routine: loadbalancer LOAD_BALANCER_NAME does not exist:
googleapi: Error 400: Invalid value for field 'resource.IPAddress':'INGRESS_VIP'. Specified IP address is in-use and would result in a conflict., invalid
Para resolver estes problemas, experimente os seguintes passos:
- Adicione o campo
hostsna secçãotlsdo manifesto do Ingress e, em seguida, elimine o Ingress. Aguarde cinco minutos para que o GKE elimine os recursos Ingress não usados. Em seguida, recrie o Ingress. Para mais informações, consulte O campo hosts de um objeto Ingress. - Reverta as alterações feitas ao Ingress. Em seguida, adicione um certificado através de uma anotação ou um secret do Kubernetes.
A entrada externa produz erros HTTP 502
Use as seguintes orientações para resolver problemas de erros HTTP 502 com recursos de entrada externos:
- Ative os registos para cada serviço de back-end associado a cada serviço do GKE que é referenciado pelo Ingress.
- Use os detalhes do estado para identificar as causas das respostas HTTP 502. Os detalhes do estado que indicam que a resposta HTTP 502 teve origem no back-end requerem a resolução de problemas nos pods de publicação, e não no equilibrador de carga.
Grupos de instâncias não geridos
Pode ter erros HTTP 502 com recursos de entrada externos se a entrada externa usar back-ends de grupos de instâncias não geridos. Este problema ocorre quando todas as seguintes condições são cumpridas:
- O cluster tem um número total elevado de nós entre todos os conjuntos de nós.
- Os pods de publicação de um ou mais serviços referenciados pelo Ingress estão localizados apenas em alguns nós.
- Os serviços referenciados pelo Ingress usam
externalTrafficPolicy: Local.
Para determinar se o seu Ingress externo usa back-ends de grupos de instâncias não geridos, faça o seguinte:
Aceda à página Ingress na Google Cloud consola.
Clique no nome do seu Ingress externo.
Clique no nome do balanceador de carga. É apresentada a página Detalhes do equilíbrio de carga.
Consulte a tabela na secção Serviços de back-end para determinar se o seu Ingress externo usa NEGs ou grupos de instâncias.
Para resolver este problema, use uma das seguintes soluções:
- Use um cluster nativo de VPC.
- Use
externalTrafficPolicy: Clusterpara cada serviço referenciado pelo Ingress externo. Esta solução faz com que perca o endereço IP do cliente original nas origens do pacote. - Use a anotação
node.kubernetes.io/exclude-from-external-load-balancers=true. Adicione a anotação aos nós ou aos conjuntos de nós que não executam nenhum pod de fornecimento para nenhum serviço referenciado por qualquer entrada externa ou serviçoLoadBalancerno seu cluster.
Use registos do balanceador de carga para resolver problemas
Pode usar os registos do balanceador de carga de rede de passagem interna e os registos do balanceador de carga de rede de passagem externa para resolver problemas com balanceadores de carga e correlacionar o tráfego dos balanceadores de carga com os recursos do GKE.
Os registos são agregados por ligação e exportados quase em tempo real. Os registos são gerados para cada nó do GKE envolvido no caminho de dados de um serviço LoadBalancer, tanto para o tráfego de entrada como de saída. As entradas do registo incluem campos adicionais para recursos do GKE, como:
- Nome do cluster
- Localização do cluster
- Nome do serviço
- Espaço de nomes do serviço
- Nome do agrupamento
- Espaço de nomes do agrupamento
Preços
Não existem custos adicionais pela utilização de registos. Com base na forma como carrega os registos, aplicam-se os preços padrão do Cloud Logging, do BigQuery ou do Pub/Sub. A ativação dos registos não afeta o desempenho do equilibrador de carga.
Use ferramentas de diagnóstico para resolver problemas
A ferramenta de diagnóstico check-gke-ingressinspeciona os recursos de entrada para detetar erros de configuração comuns. Pode usar a ferramenta check-gke-ingress das seguintes formas:
- Execute a
gcpdiagferramenta de linhas de comandos no seu cluster. Os resultados da entrada são apresentados na secção de verificação de regras.gke/ERR/2023_004 - Use a ferramenta
check-gke-ingresssozinha ou como um plug-in do kubectl seguindo as instruções em check-gke-ingress.
O que se segue?
Se não conseguir encontrar uma solução para o seu problema na documentação, consulte a secção Obtenha apoio técnico para receber mais ajuda, incluindo aconselhamento sobre os seguintes tópicos:
- Abrindo um registo de apoio técnico através do contacto com o Cloud Customer Care.
- Receber apoio técnico da comunidade fazendo perguntas no StackOverflow e usando a etiqueta
google-kubernetes-enginepara pesquisar problemas semelhantes. Também pode juntar-se ao#kubernetes-enginecanal do Slack para receber mais apoio técnico da comunidade. - Abrir erros ou pedidos de funcionalidades através do rastreador de problemas público.