Halaman ini menunjukkan cara menyelesaikan masalah terkait load balancing di cluster Google Kubernetes Engine (GKE) menggunakan resource Service, Ingress, atau Gateway.
BackendConfig tidak ditemukan
Error ini terjadi saat BackendConfig untuk port Layanan ditetapkan dalam anotasi Service, tetapi resource BackendConfig yang sebenarnya tidak dapat ditemukan.
Untuk mengevaluasi peristiwa Kubernetes, jalankan perintah berikut:
kubectl get event
Contoh output berikut menunjukkan BackendConfig Anda tidak ditemukan:
KIND ... SOURCE
Ingress ... loadbalancer-controller
MESSAGE
Error during sync: error getting BackendConfig for port 80 on service "default/my-service":
no BackendConfig for service port exists
Untuk mengatasi masalah ini, pastikan Anda tidak membuat resource BackendConfig di namespace yang salah atau salah mengeja referensinya di anotasi Service.
Kebijakan keamanan Ingress tidak ditemukan
Setelah objek Ingress dibuat, jika kebijakan keamanan tidak dikaitkan dengan benar dengan Layanan LoadBalancer, evaluasi peristiwa Kubernetes untuk melihat apakah ada kesalahan konfigurasi. Jika BackendConfig menentukan kebijakan keamanan yang tidak ada, peristiwa peringatan akan dikeluarkan secara berkala.
Untuk mengevaluasi peristiwa Kubernetes, jalankan perintah berikut:
kubectl get event
Contoh output berikut menunjukkan bahwa kebijakan keamanan Anda tidak ditemukan:
KIND ... SOURCE
Ingress ... loadbalancer-controller
MESSAGE
Error during sync: The given security policy "my-policy" does not exist.
Untuk mengatasi masalah ini, tentukan nama kebijakan keamanan yang benar di BackendConfig.
Mengatasi error seri 500 dengan NEG selama penskalaan workload di GKE
Gejala:
Saat menggunakan NEG yang disediakan GKE untuk load balancing, Anda mungkin mengalami error 502 atau 503 untuk layanan selama penurunan skala workload. Error 502 terjadi saat Pod dihentikan sebelum koneksi yang ada ditutup, sedangkan error 503 terjadi saat traffic diarahkan ke Pod yang dihapus.
Masalah ini dapat memengaruhi cluster jika Anda menggunakan produk load balancing yang dikelola GKE yang menggunakan NEG, termasuk Gateway, Ingress, dan NEG mandiri. Jika Anda sering menskalakan workload, cluster Anda berisiko lebih tinggi terpengaruh.
Diagnosis:
Menghapus Pod di Kubernetes tanpa menguras endpoint-nya dan menghapusnya dari
NEG terlebih dahulu akan menyebabkan error seri 500. Untuk menghindari masalah selama penghentian Pod, Anda harus mempertimbangkan urutan operasi. Gambar berikut menampilkan skenario saat BackendService Drain Timeout tidak disetel dan BackendService Drain Timeout disetel dengan BackendConfig.
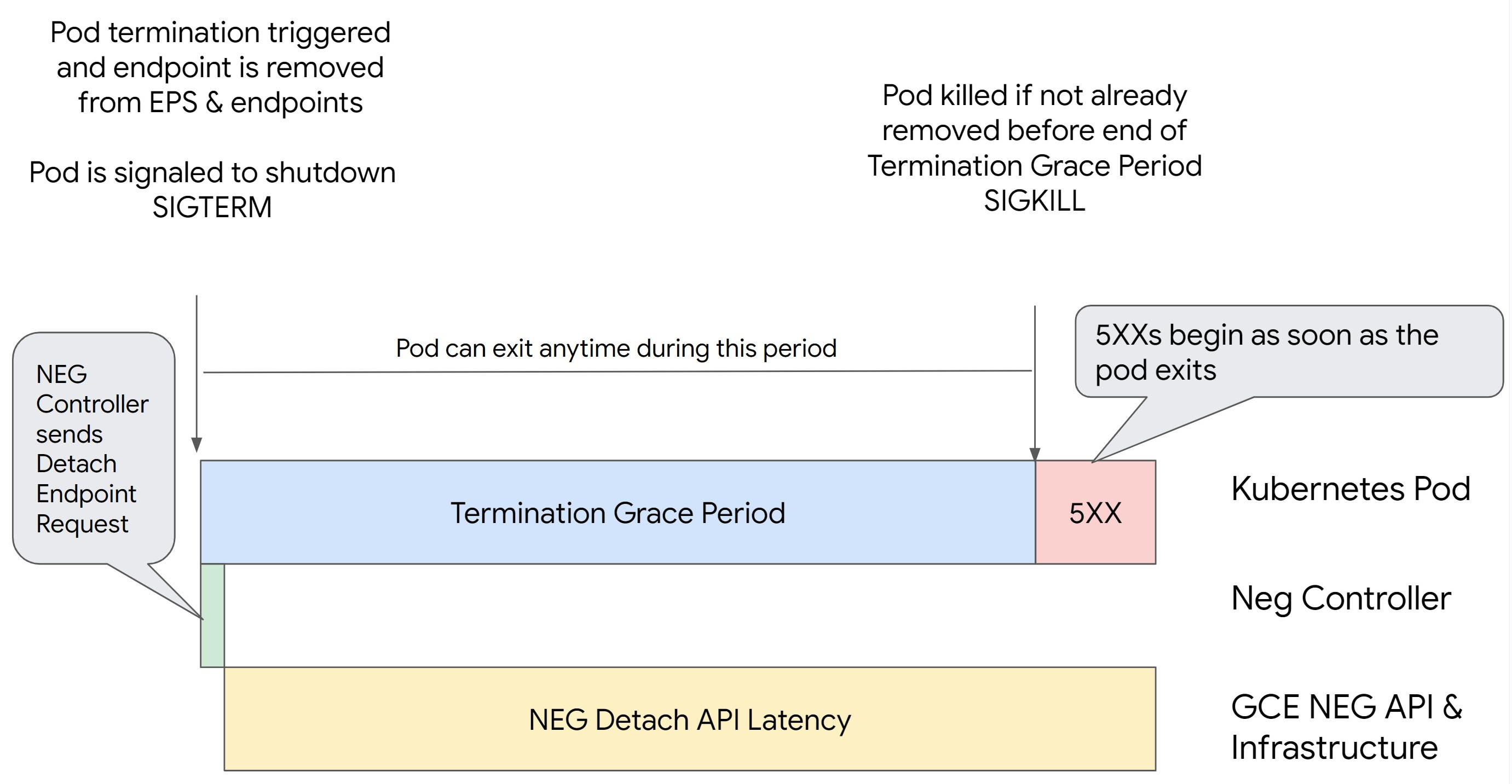
Skenario 1: BackendService Drain Timeout tidak disetel.
Gambar berikut menampilkan skenario saat BackendService Drain Timeout tidak
ditetapkan.
Skenario 2: BackendService Drain Timeout ditetapkan.
Gambar berikut menampilkan skenario saat BackendService Drain Timeout disetel.
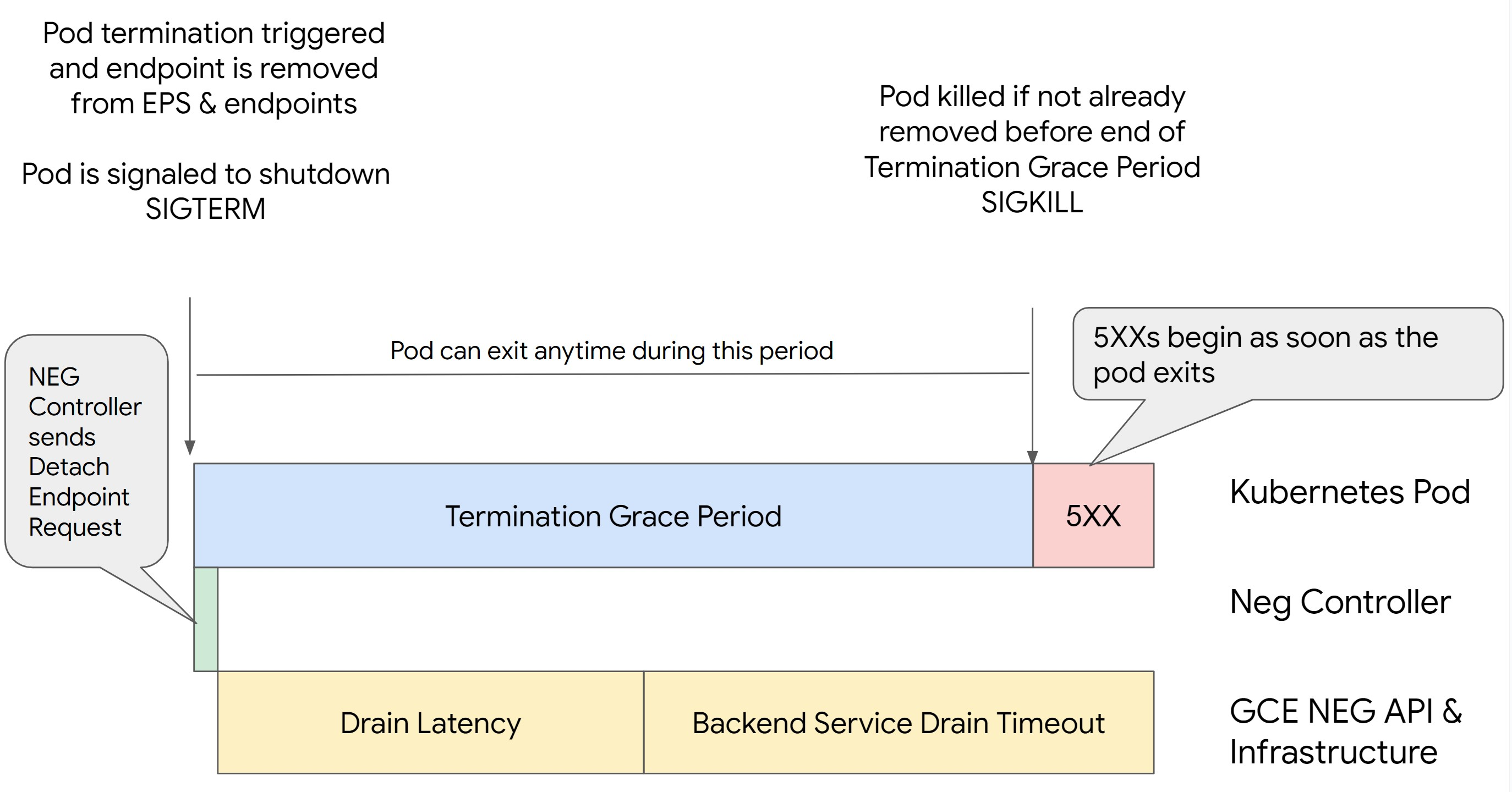
Waktu persisnya error seri 500 terjadi bergantung pada faktor-faktor berikut:
Latensi pelepasan NEG API: Latensi pelepasan NEG API mewakili waktu yang diperlukan saat ini agar operasi pelepasan selesai di Google Cloud. Hal ini dipengaruhi oleh berbagai faktor di luar Kubernetes, termasuk jenis load balancer dan zona tertentu.
Latensi pengurasan: Latensi pengurasan adalah waktu yang diperlukan load balancer untuk mulai mengalihkan traffic dari bagian tertentu sistem Anda. Setelah pengurasan dimulai, load balancer berhenti mengirim permintaan baru ke endpoint, tetapi masih ada latensi dalam memicu pengurasan (latensi pengurasan) yang dapat menyebabkan error 503 sementara jika Pod tidak ada lagi.
Konfigurasi health check: Nilai minimum health check yang lebih sensitif akan mengurangi durasi error 503 karena dapat memberi sinyal kepada load balancer untuk berhenti mengirim permintaan ke endpoint meskipun operasi pelepasan belum selesai.
Masa tenggang penghentian: Masa tenggang penghentian menentukan jumlah waktu maksimum yang diberikan kepada Pod untuk keluar. Namun, Pod dapat keluar sebelum masa tenggang penghentian selesai. Jika Pod membutuhkan waktu lebih lama dari periode ini, Pod akan dipaksa keluar di akhir periode ini. Ini adalah setelan di Pod dan harus dikonfigurasi dalam definisi workload.
Potensi penyelesaian:
Untuk mencegah error 5XX tersebut, terapkan setelan berikut. Nilai waktu tunggu bersifat sugestif dan Anda mungkin perlu menyesuaikannya untuk aplikasi tertentu. Bagian berikut akan memandu Anda dalam proses penyesuaian.
Gambar berikut menampilkan cara agar Pod tetap aktif dengan hook preStop:
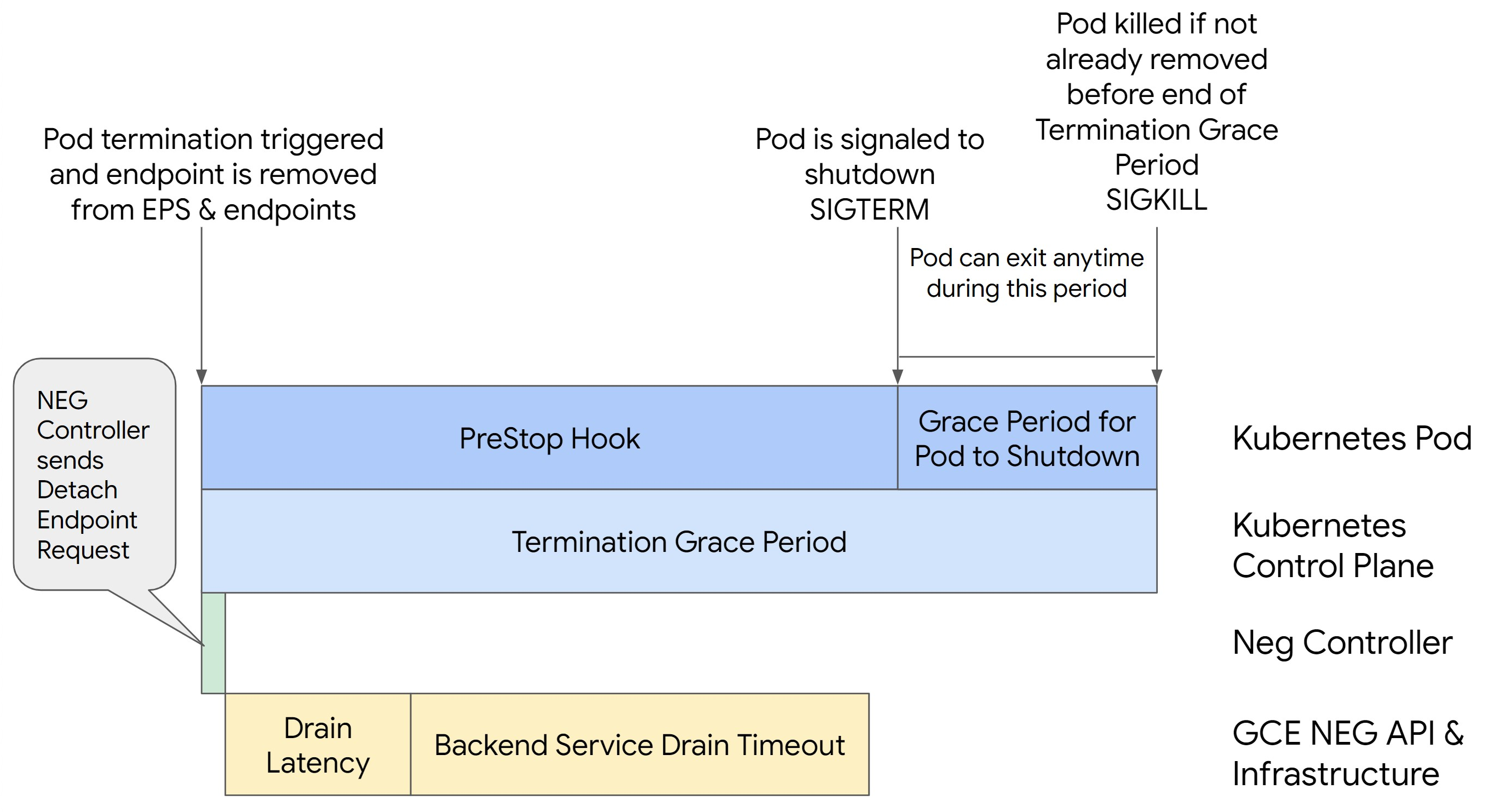
Untuk menghindari error seri 500, lakukan langkah-langkah berikut:
Tetapkan
BackendService Drain Timeoutuntuk layanan Anda ke 1 menit.Untuk Pengguna Ingress, lihat menetapkan waktu tunggu di BackendConfig.
Untuk Pengguna Gateway, lihat mengonfigurasi waktu tunggu di GCPBackendPolicy.
Bagi yang mengelola BackendService secara langsung saat menggunakan NEG Mandiri, lihat menetapkan waktu tunggu langsung di Layanan Backend.
Perluas
terminationGracePerioddi Pod.Setel
terminationGracePeriodSecondsdi Pod ke 3,5 menit. Jika digabungkan dengan setelan yang direkomendasikan, Pod Anda akan memiliki jendela selama 30 hingga 45 detik untuk melakukan penonaktifan yang tuntas setelah endpoint Pod dihapus dari NEG. Jika Anda memerlukan lebih banyak waktu untuk penonaktifan yang lancar, Anda dapat memperpanjang masa tenggang atau mengikuti petunjuk yang disebutkan di bagian Menyesuaikan waktu tunggu.Manifes Pod berikut menentukan waktu tunggu pengosongan koneksi selama 210 detik (3,5 menit):
spec: terminationGracePeriodSeconds: 210 containers: - name: my-app ... ...Terapkan hook
preStopke semua penampung.Terapkan hook
preStopyang akan memastikan Pod tetap aktif selama 120 detik lebih lama saat endpoint Pod dikuras di load balancer dan endpoint dihapus dari NEG.spec: containers: - name: my-app ... lifecycle: preStop: exec: command: ["/bin/sh", "-c", "sleep 120s"] ...
Menyesuaikan waktu tunggu
Untuk memastikan kelangsungan Pod dan mencegah error seri 500, Pod harus tetap aktif
hingga endpoint dihapus dari NEG. Khususnya untuk mencegah error 502 dan 503, pertimbangkan untuk menerapkan kombinasi batas waktu dan hook preStop.
Untuk menjaga Pod tetap aktif lebih lama selama proses penonaktifan, tambahkan hook preStop ke Pod. Jalankan hook preStop sebelum Pod diberi sinyal untuk keluar, sehingga hook
preStop dapat digunakan untuk menjaga Pod tetap aktif hingga endpoint
yang sesuai dihapus dari NEG.
Untuk memperpanjang durasi Pod tetap aktif selama proses penonaktifan,
sisipkan hook preStop ke dalam konfigurasi Pod sebagai berikut:
spec:
containers:
- name: my-app
...
lifecycle:
preStop:
exec:
command: ["/bin/sh", "-c", "sleep <latency time>"]
Anda dapat mengonfigurasi waktu tunggu dan setelan terkait untuk mengelola penonaktifan yang benar
dari Pod selama penskalaan beban kerja. Anda dapat menyesuaikan waktu tunggu berdasarkan kasus penggunaan tertentu. Sebaiknya mulai dengan waktu tunggu yang lebih lama dan kurangi durasinya sesuai kebutuhan. Anda dapat menyesuaikan waktu tunggu dengan mengonfigurasi parameter terkait waktu tunggu dan hook preStop dengan cara berikut:
Waktu Tunggu Pengosongan Layanan Backend
Parameter Backend Service Drain Timeout tidak ditetapkan secara default dan tidak
berpengaruh. Jika Anda menetapkan parameter Backend Service Drain Timeout dan mengaktifkannya, load balancer akan berhenti merutekan permintaan baru ke endpoint dan menunggu waktu tunggu sebelum menghentikan koneksi yang ada.
Anda dapat menetapkan parameter Backend Service Drain Timeout menggunakan
BackendConfig dengan Ingress, GCPBackendPolicy dengan Gateway, atau secara manual di
BackendService dengan NEG mandiri. Waktu tunggu harus 1,5 hingga 2 kali
lebih lama dari waktu yang diperlukan untuk memproses permintaan. Hal ini memastikan bahwa jika permintaan
masuk tepat sebelum pengurasan dimulai, permintaan tersebut akan selesai sebelum
waktu tunggu habis. Menetapkan parameter Backend Service Drain Timeout ke nilai yang lebih besar dari 0 membantu mengurangi error 503 karena tidak ada permintaan baru yang dikirim ke endpoint yang dijadwalkan untuk dihapus. Agar waktu tunggu ini efektif, Anda harus
menggunakannya dengan hook preStop untuk memastikan Pod tetap
aktif selama pengurasan terjadi. Tanpa kombinasi ini, permintaan yang ada yang
tidak selesai akan menerima error 502.
Waktu pengaitan preStop
Hook preStop harus menunda penonaktifan Pod secara memadai agar latensi pengurasan dan waktu tunggu pengurasan layanan backend selesai, sehingga memastikan pengurasan koneksi dan penghapusan endpoint yang tepat dari NEG sebelum Pod dinonaktifkan.
Untuk hasil yang optimal, pastikan waktu eksekusi hook preStop lebih besar dari
atau sama dengan jumlah latensi pengurasan dan Backend Service Drain Timeout.
Hitung waktu eksekusi hook preStop yang ideal dengan rumus berikut:
preStop hook execution time >= BACKEND_SERVICE_DRAIN_TIMEOUT + DRAIN_LATENCY
Ganti kode berikut:
BACKEND_SERVICE_DRAIN_TIMEOUT: waktu yang Anda konfigurasi untukBackend Service Drain Timeout.DRAIN_LATENCY: perkiraan waktu untuk latensi pengosongan. Sebaiknya gunakan satu menit sebagai perkiraan Anda.
Jika error 500 terus terjadi, perkirakan durasi total terjadinya error dan tambahkan dua kali lipat durasi tersebut ke perkiraan latensi pengurasan. Hal ini memastikan bahwa Pod Anda memiliki waktu yang cukup untuk dikuras secara normal sebelum dihapus dari layanan. Anda dapat menyesuaikan nilai ini jika terlalu panjang untuk kasus penggunaan tertentu.
Atau, Anda dapat memperkirakan waktunya dengan memeriksa stempel waktu penghapusan dari Pod dan stempel waktu saat endpoint dihapus dari NEG di Cloud Audit Logs.
Parameter Masa Tenggang Penghentian
Anda harus mengonfigurasi parameter terminationGracePeriod untuk memberikan waktu yang cukup
agar hook preStop selesai dan Pod dapat menyelesaikan penonaktifan
yang benar.
Secara default, jika tidak ditetapkan secara eksplisit, terminationGracePeriod adalah 30 detik.
Anda dapat menghitung terminationGracePeriod yang optimal menggunakan rumus:
terminationGracePeriod >= preStop hook time + Pod shutdown time
Untuk menentukan terminationGracePeriod dalam konfigurasi Pod sebagai berikut:
spec:
terminationGracePeriodSeconds: <terminationGracePeriod>
containers:
- name: my-app
...
...
NEG tidak ditemukan saat membuat resource Ingress Internal
Error berikut mungkin terjadi saat Anda membuat Ingress internal di GKE:
Error syncing: error running backend syncing routine: googleapi: Error 404: The resource 'projects/PROJECT_ID/zones/ZONE/networkEndpointGroups/NEG' was not found, notFound
Error ini terjadi karena Ingress untuk Load Balancer Aplikasi internal memerlukan Grup Endpoint Jaringan (NEG) sebagai backend.
Di lingkungan VPC Bersama atau cluster yang mengaktifkan Kebijakan Jaringan, tambahkan anotasi cloud.google.com/neg: '{"ingress": true}' ke manifes Layanan.
Waktu Tunggu Gateway 504: waktu tunggu permintaan upstream
Error berikut mungkin terjadi saat Anda mengakses Layanan dari Ingress internal di GKE:
HTTP/1.1 504 Gateway Timeout
content-length: 24
content-type: text/plain
upsteam request timeout
Error ini terjadi karena traffic yang dikirim ke Load Balancer Aplikasi internal di-proxy-kan oleh proxy envoy dalam rentang subnet khusus proxy.
Untuk mengizinkan traffic dari rentang subnet khusus proxy, buat aturan firewall di targetPort Layanan.
Error 400: Nilai tidak valid untuk kolom 'resource.target'
Error berikut mungkin terjadi saat Anda mengakses Layanan dari Ingress internal di GKE:
Error syncing:LB_NAME does not exist: googleapi: Error 400: Invalid value for field 'resource.target': 'https://www.googleapis.com/compute/v1/projects/PROJECT_NAME/regions/REGION_NAME/targetHttpProxies/LB_NAME. A reserved and active subnetwork is required in the same region and VPC as the forwarding rule.
Untuk mengatasi masalah ini, buat subnet khusus proxy.
Kesalahan selama sinkronisasi: kesalahan menjalankan rutinitas sinkronisasi load balancer: loadbalancer tidak tersedia
Salah satu error berikut mungkin terjadi ketika upgrade bidang kontrol GKE atau saat Anda memodifikasi objek Ingress:
"Error during sync: error running load balancer syncing routine: loadbalancer
INGRESS_NAME does not exist: invalid ingress frontend configuration, please
check your usage of the 'kubernetes.io/ingress.allow-http' annotation."
Atau:
Error during sync: error running load balancer syncing routine: loadbalancer LOAD_BALANCER_NAME does not exist:
googleapi: Error 400: Invalid value for field 'resource.IPAddress':'INGRESS_VIP'. Specified IP address is in-use and would result in a conflict., invalid
Untuk mengatasi masalah ini, coba langkah-langkah berikut:
- Tambahkan kolom
hostsdi bagiantlsdari manifes Ingress, lalu hapus Ingress. Tunggu selama lima menit hingga GKE menghapus resource Ingress yang tidak digunakan. Kemudian, buat ulang Ingress. Untuk informasi selengkapnya, lihat Kolom host objek Ingress. - Kembalikan perubahan yang Anda buat ke Ingress. Kemudian, tambahkan sertifikat menggunakan anotasi atau Secret Kubernetes.
Ingress Eksternal menghasilkan error HTTP 502
Gunakan panduan berikut untuk memecahkan masalah error HTTP 502 dengan resource Ingress eksternal:
- Aktifkan log untuk setiap layanan backend yang terkait dengan setiap Layanan GKE yang direferensikan oleh Ingress.
- Gunakan detail status untuk mengidentifikasi penyebab respons HTTP 502. Detail status yang menunjukkan bahwa respons HTTP 502 yang berasal dari backend memerlukan pemecahan masalah dalam Pod penyaluran, bukan load balancer.
Grup instance tidak terkelola
Anda mungkin mengalami error HTTP 502 dengan resource Ingress eksternal jika Ingress eksternal Anda menggunakan backend grup instance yang tidak dikelola. Masalah ini terjadi saat semua persyaratan berikut terpenuhi:
- Cluster memiliki jumlah total node yang besar di antara semua kumpulan node.
- Pod yang aktif untuk satu atau beberapa Layanan yang direferensikan oleh Ingress hanya terletak di beberapa node.
- Layanan yang dirujuk oleh Ingress menggunakan
externalTrafficPolicy: Local.
Untuk menentukan apakah Ingress eksternal Anda menggunakan backend grup instance yang tidak dikelola, lakukan hal berikut:
Buka halaman Ingress di konsol Google Cloud .
Klik nama Ingress eksternal Anda.
Klik nama Load balancer. Halaman Detail load balancing ditampilkan.
Periksa tabel di bagian Layanan backend untuk menentukan apakah Ingress eksternal Anda menggunakan NEG atau grup instance.
Untuk mengatasi masalah ini, gunakan salah satu solusi berikut:
- Gunakan cluster native VPC.
- Gunakan
externalTrafficPolicy: Clusteruntuk setiap Layanan yang dirujuk oleh Ingress eksternal. Solusi ini menyebabkan Anda kehilangan alamat IP klien asli di sumber paket. - Gunakan anotasi
node.kubernetes.io/exclude-from-external-load-balancers=true. Tambahkan anotasi ke node atau kumpulan node yang tidak menjalankan Pod penayangan untuk Layanan apa pun yang direferensikan oleh Ingress eksternal atau LayananLoadBalancerdi cluster Anda.
Menggunakan log load balancer untuk memecahkan masalah
Anda dapat menggunakan log Load Balancer Jaringan passthrough internal dan log Load Balancer Jaringan passthrough eksternal untuk memecahkan masalah dengan load balancer dan menghubungkan dari load balancing hingga resource GKE.
Log digabungkan per koneksi dan diekspor hampir secara real time. Log dibuat untuk setiap node GKE yang terlibat di jalur data Layanan LoadBalancer, untuk traffic ingress dan egress. Entri log mencakup kolom tambahan untuk resource GKE, seperti:
- Cluster name
- Lokasi cluster
- Nama layanan
- Namespace layanan
- Nama pod
- Namespace pod
Harga
Tidak ada biaya tambahan untuk menggunakan log. Berdasarkan cara Anda menyerap log, harga standar untuk Cloud Logging, BigQuery, atau Pub/Sub berlaku. Mengaktifkan log tidak berpengaruh pada performa load balancer.
Menggunakan alat diagnostik untuk memecahkan masalah
Alat diagnostik check-gke-ingress memeriksa resource Ingress untuk menemukan kesalahan konfigurasi umum. Anda dapat menggunakan alat check-gke-ingress dengan cara berikut:
- Jalankan
alat command line
gcpdiagdi cluster Anda. Hasil traffic ingress muncul di bagiangke/ERR/2023_004aturan pemeriksaan. - Gunakan alat
check-gke-ingresssaja atau sebagai plugin kubectl dengan mengikuti petunjuk di check-gke-ingress.
Langkah berikutnya
Jika Anda tidak dapat menemukan solusi untuk masalah Anda dalam dokumentasi, lihat Mendapatkan dukungan untuk mendapatkan bantuan lebih lanjut, termasuk saran tentang topik berikut:
- Membuka kasus dukungan dengan menghubungi Layanan Pelanggan Cloud.
- Mendapatkan dukungan dari komunitas dengan
mengajukan pertanyaan di StackOverflow
dan menggunakan tag
google-kubernetes-engineuntuk menelusuri masalah serupa. Anda juga dapat bergabung ke#kubernetes-enginechannel Slack untuk mendapatkan dukungan komunitas lainnya. - Membuka bug atau permintaan fitur menggunakan issue tracker publik.