Cette page explique comment résoudre les problèmes liés à l'équilibrage de charge dans les clusters Google Kubernetes Engine (GKE) à l'aide de ressources Service, Ingress ou Gateway.
BackendConfig introuvable
Cette erreur se produit lorsqu'une ressource BackendConfig est spécifiée pour un port de Service dans l'annotation Service, mais que la ressource BackendConfig réelle est introuvable.
Pour évaluer un événement Kubernetes, exécutez la commande suivante :
kubectl get event
Le résultat suivant indique que votre BackendConfig est introuvable :
KIND ... SOURCE
Ingress ... loadbalancer-controller
MESSAGE
Error during sync: error getting BackendConfig for port 80 on service "default/my-service":
no BackendConfig for service port exists
Pour résoudre ce problème, assurez-vous que vous n'avez pas créé la ressource BackendConfig dans le mauvais espace de noms ou que sa référence n'est pas mal orthographiée dans l'annotation Service.
Règle de sécurité d'objet Ingress introuvable
Une fois l'objet Ingress créé, si la stratégie de sécurité n'est pas correctement associée au service LoadBalancer, évaluez l'événement Kubernetes pour voir s'il existe une erreur de configuration. Si votre BackendConfig spécifie une règle de sécurité qui n'existe pas, un événement d'avertissement est émis régulièrement.
Pour évaluer un événement Kubernetes, exécutez la commande suivante :
kubectl get event
Le résultat suivant indique que votre règle de sécurité est introuvable :
KIND ... SOURCE
Ingress ... loadbalancer-controller
MESSAGE
Error during sync: The given security policy "my-policy" does not exist.
Pour résoudre ce problème, spécifiez le nom correct de la règle de sécurité dans votre CRD BackendConfig.
Résoudre les erreurs de série 500 avec des NEG lors du scaling des charges de travail dans GKE
Symptôme :
Lorsque vous utilisez des NEG provisionnés par GKE pour l'équilibrage de charge, vous pouvez rencontrer des erreurs 502 ou 503 pour les services pendant le scaling à la baisse des charges de travail. Les erreurs 502 se produisent lorsque les pods sont arrêtés avant la fermeture des connexions existantes, tandis que les erreurs 503 se produisent lorsque le trafic est dirigé vers des pods supprimés.
Ce problème peut affecter les clusters si vous utilisez des produits d'équilibrage de charge gérés par GKE qui utilisent des NEG, y compris des ressources Gateway et Ingress, et des NEG autonomes. Si vous effectuez fréquemment le scaling de vos charges de travail, le risque que votre cluster soit affecté est plus élevé.
Diagnostic :
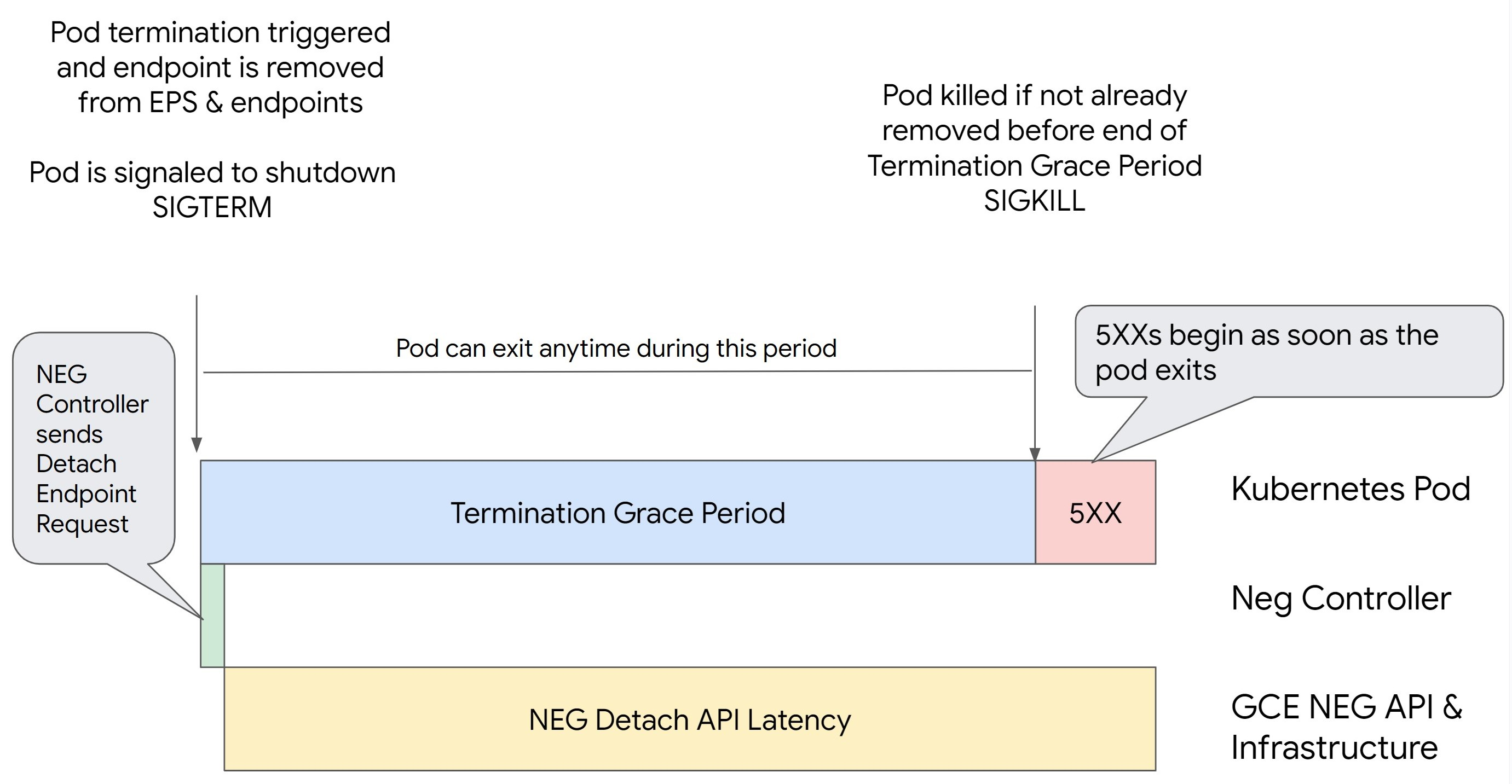
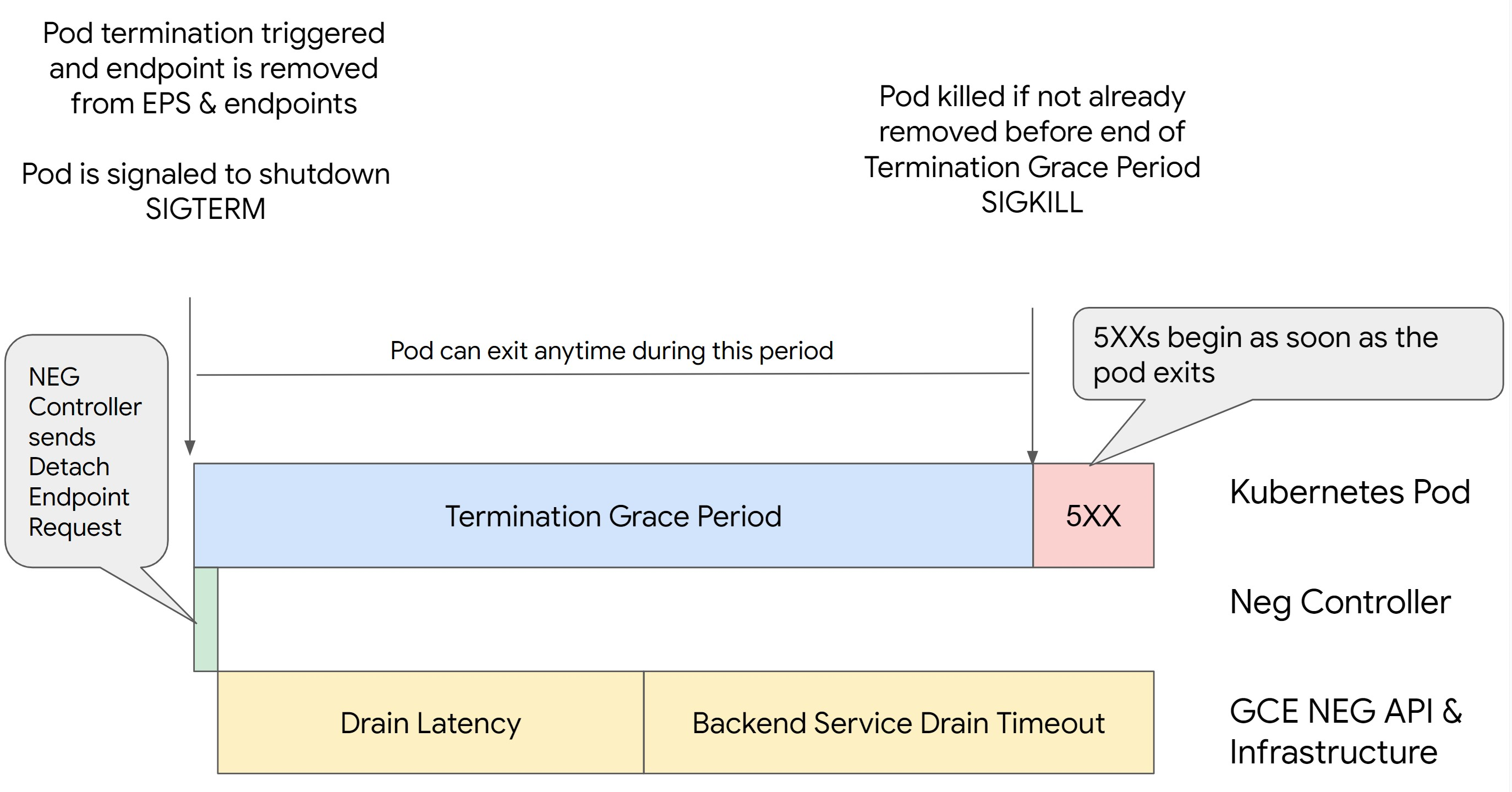
La suppression d'un pod dans Kubernetes sans drainer son point de terminaison et sans le supprimer du NEG entraîne d'abord des erreurs de série 500. Pour éviter les problèmes lors de l'arrêt des pods, vous devez prendre en compte l'ordre des opérations. Les images suivantes affichent des scénarios lorsque BackendService Drain Timeout n'est pas défini et que BackendService Drain Timeout est défini avec BackendConfig.
Scénario 1 : BackendService Drain Timeout n'est pas défini.
L'image suivante montre un scénario dans lequel BackendService Drain Timeout n'est pas défini.
Scénario 2 : BackendService Drain Timeout est défini.
L'image suivante montre un scénario dans lequel BackendService Drain Timeout est défini.
Le moment exact où les erreurs de série 500 se produisent dépend des facteurs suivants :
Latence de dissociation d'API NEG : la latence de dissociation d'API NEG représente le temps nécessaire à la finalisation de l'opération de dissociation dans Google Cloud. Ce temps est influencé par divers facteurs en dehors de Kubernetes, tels que le type d'équilibreur de charge et la zone spécifique.
Latence de drainage : la latence de drainage correspond au temps nécessaire à l'équilibreur de charge pour commencer à détourner le trafic d'une partie spécifique de votre système. Une fois le drainage initié, l'équilibreur de charge cesse d'envoyer de nouvelles requêtes au point de terminaison, mais il existe toujours un temps de latence pour déclencher le drainage (latence de drainage), ce qui peut provoquer des erreurs 503 temporaires si le pod n'existe plus.
Configuration de la vérification de l'état : des seuils de vérification d'état plus sensibles limitent la durée des erreurs 503, car ils peuvent signaler à l'équilibreur de charge d'arrêter d'envoyer des requêtes aux points de terminaison même si l'opération de dissociation n'est pas terminée.
Délai de grâce avant l'arrêt : le délai de grâce avant l'arrêt détermine la durée maximale accordée à un pod pour s'arrêter. Toutefois, un pod peut être arrêté avant la fin du délai de grâce avant l'arrêt. Si un pod prend plus de temps que ce délai, il est contraint de s'arrêter à la fin de celui-ci. Il s'agit d'un paramètre sur le pod et il doit être configuré dans la définition de la charge de travail.
Solution potentielle :
Pour éviter ces erreurs 5XX, appliquez les paramètres suivants. Les valeurs de délai avant expiration sont indicatives et il se peut que vous deviez les adapter à votre application spécifique. La section suivante vous guide tout au long du processus de personnalisation.
L'image suivante montre comment maintenir le pod actif avec un hook preStop :
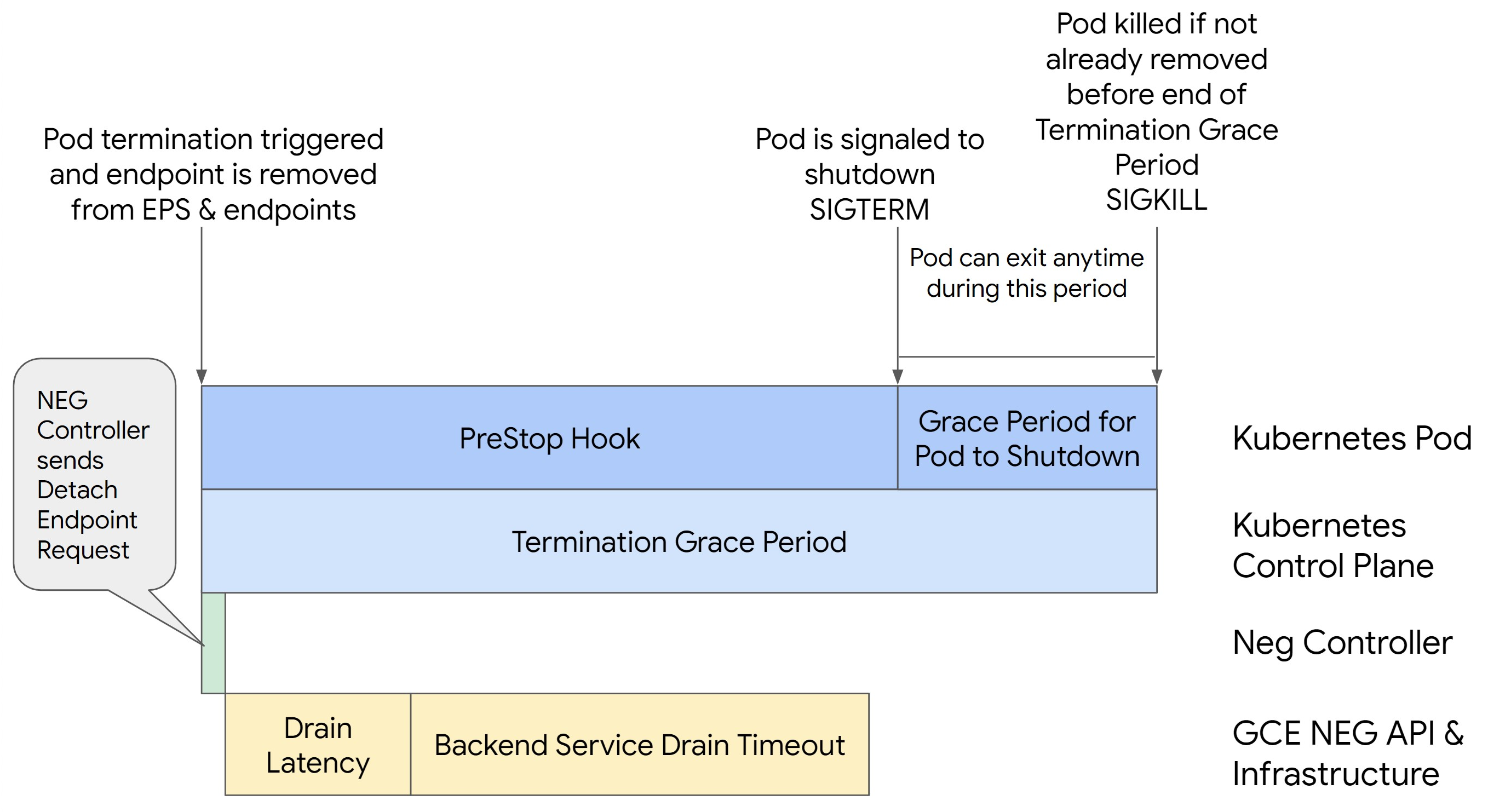
Pour éviter les erreurs de série 500, procédez comme suit :
Définissez le paramètre
BackendService Drain Timeoutpour votre service sur 1 minute.Pour les utilisateurs d'Ingress, consultez la section Définir le délai avant expiration sur la ressource BackendConfig.
Pour les utilisateurs de Gateway, consultez la section Configurer le délai avant expiration sur la ressource GCPBackendPolicy.
Pour ceux qui gèrent leurs services de backend directement lors de l'utilisation de NEG autonomes, consultez la section Définir le délai avant expiration directement sur le service de backend.
Étendez
terminationGracePeriodsur le pod.Définissez
terminationGracePeriodSecondssur 3,5 minutes sur le pod. Combiné aux paramètres recommandés, cela permet à vos pods de disposer d'une fenêtre de 30 à 45 secondes pour un arrêt progressif après que le point de terminaison du pod a été supprimé du NEG. Si vous avez besoin de plus de temps pour effectuer un arrêt progressif, vous pouvez prolonger le délai de grâce ou suivre les instructions mentionnées dans la section Personnaliser les délais avant expiration.Le fichier manifeste suivant spécifie un délai avant expiration du drainage de connexion de 210 secondes (3,5 minutes) :
spec: terminationGracePeriodSeconds: 210 containers: - name: my-app ... ...Appliquez un crochet
preStopà tous les conteneurs.Appliquez un crochet
preStopqui garantira que le pod est actif pendant 120 secondes de plus pendant que le point de terminaison du pod est drainé dans l'équilibreur de charge et que le point de terminaison est supprimé du NEG.spec: containers: - name: my-app ... lifecycle: preStop: exec: command: ["/bin/sh", "-c", "sleep 120s"] ...
Personnaliser les délais avant expiration
Pour garantir la continuité du pod et éviter les erreurs de série 500, le pod doit être actif jusqu'à ce que le point de terminaison soit supprimé du NEG. Pour éviter les erreurs 502 et 503, envisagez d'implémenter une combinaison de délais avant expiration et d'un crochet preStop.
Pour maintenir le pod actif plus longtemps pendant le processus d'arrêt, ajoutez un hook preStop au pod. Exécutez le crochet preStop avant qu'un pod ne reçoive le signal d'arrêt, de sorte que le crochet preStop puisse être utilisé pour maintenir le pod en activité jusqu'à ce que le point de terminaison correspondant soit supprimé du NEG.
Pour prolonger la durée pendant laquelle un pod reste actif pendant le processus d'arrêt, insérez un crochet preStop dans la configuration du pod comme suit :
spec:
containers:
- name: my-app
...
lifecycle:
preStop:
exec:
command: ["/bin/sh", "-c", "sleep <latency time>"]
Vous pouvez configurer des délais avant expiration et les paramètres associés pour gérer l'arrêt progressif des pods lors du scaling à la baisse des charges de travail. Vous pouvez ajuster les délais avant expiration en fonction de cas d'utilisation spécifiques. Nous vous recommandons de commencer par des délais plus longs et de réduire la durée si nécessaire. Vous pouvez personnaliser les délais avant expiration en configurant les paramètres liés au délai d'expiration et le hook preStop de différentes manières :
Délai avant expiration du drainage du service de backend
Le paramètre Backend Service Drain Timeout n'est pas défini par défaut et n'a aucun effet. Si vous définissez le paramètre Backend Service Drain Timeout et que vous l'activez, l'équilibreur de charge arrête d'acheminer de nouvelles requêtes vers le point de terminaison et attend la fin du délai avant d'arrêter les connexions existantes.
Vous pouvez définir le paramètre Backend Service Drain Timeout à l'aide du BackendConfig avec Ingress, du GCPBackendPolicy avec Gateway, ou manuellement sur le BackendService avec les NEG autonomes. Le délai avant expiration doit être 1,5 à 2 fois plus long que le temps nécessaire au traitement d'une requête. Cela garantit que si une requête arrive juste avant le début du drainage, elle se termine avant l'expiration du délai. La définition du paramètre Backend Service Drain Timeout sur une valeur supérieure à 0 permet de limiter les erreurs 503, car aucune nouvelle requête n'est envoyée aux points de terminaison dont la suppression est planifiée. Pour que ce délai avant expiration soit effectif, vous devez l'utiliser avec le crochet preStop pour vous assurer que le pod reste actif pendant le drainage. Sans cette combinaison, les requêtes existantes qui n'ont pas abouti reçoivent une erreur 502.
Durée de l'accroche : preStop
Le crochet preStop doit retarder suffisamment l'arrêt du pod pour que la latence de drainage et le délai avant expiration du drainage du service de backend soient terminés, garantissant ainsi un drainage de connexion correct et la suppression des points de terminaison du NEG avant l'arrêt du pod.
Pour obtenir des résultats optimaux, assurez-vous que le temps d'exécution du crochet preStop est supérieur ou égal à la somme de Backend Service Drain Timeout et de la latence de drainage.
Calculez le temps d'exécution idéal de votre crochet preStop à l'aide de la formule suivante :
preStop hook execution time >= BACKEND_SERVICE_DRAIN_TIMEOUT + DRAIN_LATENCY
Remplacez les éléments suivants :
BACKEND_SERVICE_DRAIN_TIMEOUT: heure que vous avez configurée pourBackend Service Drain Timeout.DRAIN_LATENCY: durée de latence de vidange estimée. Nous vous recommandons d'utiliser une minute comme estimation.
Si les erreurs 500 persistent, estimez la durée totale d'occurrence et ajoutez le double de ce temps à la latence de vidange estimée. Ainsi, votre pod dispose de suffisamment de temps pour être drainé progressivement avant d'être supprimé du service. Vous pouvez ajuster cette valeur si le délai est trop long pour votre cas d'utilisation spécifique.
Vous pouvez également estimer le délai en examinant le code temporel de suppression du pod et le code temporel lorsque le point de terminaison a été supprimé du NEG dans Cloud Audit Logs.
Paramètre de délai de grâce avant l'arrêt
Vous devez configurer le paramètre terminationGracePeriod de façon à laisser suffisamment de temps pour que le hook preStop se termine et que le pod s'arrête de manière progressive.
Par défaut, lorsqu'il n'est pas explicitement défini, le délai de terminationGracePeriod est de 30 secondes.
Vous pouvez calculer le délai optimal de terminationGracePeriod à l'aide de la formule suivante :
terminationGracePeriod >= preStop hook time + Pod shutdown time
Pour définir terminationGracePeriod dans la configuration du pod, procédez comme suit :
spec:
terminationGracePeriodSeconds: <terminationGracePeriod>
containers:
- name: my-app
...
...
NEG introuvable lors de la création d'une ressource Ingress interne
L'erreur suivante peut se produire lorsque vous créez une ressource Ingress interne dans GKE :
Error syncing: error running backend syncing routine: googleapi: Error 404: The resource 'projects/PROJECT_ID/zones/ZONE/networkEndpointGroups/NEG' was not found, notFound
Cette erreur se produit, car Ingress pour les équilibreurs de charge d'application internes nécessite des groupes de points de terminaison du réseau (NEG, Network Endpoint Group) en tant que backends.
Dans les environnements de VPC partagé ou les clusters sur lesquels des règles de réseau sont activées, ajoutez l'annotation cloud.google.com/neg: '{"ingress": true}' au fichier manifeste de service.
504 Expiration du délai imparti pour la passerelle : expiration du délai de la requête en amont
L'erreur suivante peut se produire lorsque vous accédez à un service à partir d'une ressource Ingress interne dans GKE :
HTTP/1.1 504 Gateway Timeout
content-length: 24
content-type: text/plain
upsteam request timeout
Cette erreur se produit, car le trafic envoyé aux équilibreurs de charge d'application internes est transmis par les proxys Envoy dans la plage de sous-réseau proxy réservé.
Pour autoriser le trafic provenant de la plage de sous-réseau proxy réservé, créez une règle de pare-feu sur le targetPort du service.
Erreur 400 : valeur non valide pour le champ "resource.target"
L'erreur suivante peut se produire lorsque vous accédez à un service à partir d'une ressource Ingress interne dans GKE :
Error syncing:LB_NAME does not exist: googleapi: Error 400: Invalid value for field 'resource.target': 'https://www.googleapis.com/compute/v1/projects/PROJECT_NAME/regions/REGION_NAME/targetHttpProxies/LB_NAME. A reserved and active subnetwork is required in the same region and VPC as the forwarding rule.
Pour résoudre ce problème, déployez un sous-réseau proxy réservé.
Erreur lors de la synchronisation : erreur lors de l'exécution de la routine de synchronisation de l'équilibreur de charge : l'équilibreur de charge n'existe pas.
L'une des erreurs suivantes peut se produire lorsque le plan de contrôle GKE est mis à niveau ou que vous modifiez un objet Ingress :
"Error during sync: error running load balancer syncing routine: loadbalancer
INGRESS_NAME does not exist: invalid ingress frontend configuration, please
check your usage of the 'kubernetes.io/ingress.allow-http' annotation."
ou
Error during sync: error running load balancer syncing routine: loadbalancer LOAD_BALANCER_NAME does not exist:
googleapi: Error 400: Invalid value for field 'resource.IPAddress':'INGRESS_VIP'. Specified IP address is in-use and would result in a conflict., invalid
Pour résoudre ces problèmes, procédez comme suit :
- Ajoutez le champ
hostsdans la sectiontlsdu fichier manifeste d'entrée, puis supprimez l'objet Ingress. Attendez cinq minutes que GKE supprime les ressources Ingress inutilisées. Recréez ensuite ces ressources. Pour plus d'informations, consultez la section Champ d'hôtes d'un objet Ingress. - Annulez les modifications que vous avez apportées sur l'objet Ingress. Ajoutez ensuite un certificat à l'aide d'une annotation ou d'un secret Kubernetes.
Ingress externe génère des erreurs HTTP 502
Suivez les conseils ci-dessous pour résoudre les erreurs HTTP 502 avec des ressources Ingress externes :
- Activez les journaux pour chaque service de backend associé à chaque service GKE référencé par l'objet Ingress.
- Utilisez les détails de l'état pour identifier les causes des réponses HTTP 502. Les détails de l'état indiquant que la réponse HTTP 502 provient du backend nécessitent un dépannage dans les pods actifs, et non dans l'équilibreur de charge.
Groupes d'instances non gérés
Vous pouvez rencontrer des erreurs HTTP 502 avec des ressources Ingress externes si votre entrée externe utilise des backends de groupes d'instances non gérés. Ce problème se produit lorsque toutes les conditions suivantes sont remplies :
- Le cluster comporte un grand nombre total de nœuds parmi tous les pools de nœuds.
- Les pods actifs d'un ou de plusieurs services référencés par Ingress sont situés sur seulement quelques nœuds.
- Les services référencés par Ingress utilisent
externalTrafficPolicy: Local.
Pour déterminer si votre entrée externe utilise des backends de groupes d'instances non gérés, procédez comme suit :
Accédez à la page Ingress de la console Google Cloud .
Cliquez sur le nom de votre Ingress externe.
Cliquez sur le nom de l'équilibreur de charge. La page Détails de l'équilibrage de charge s'affiche.
Consultez le tableau de la section Services de backend pour déterminer si votre Ingress externe utilise des NEG ou des groupes d'instances.
Pour résoudre ce problème, utilisez l'une des méthodes suivantes :
- Utilisez un cluster de VPC natif.
- Utilisez
externalTrafficPolicy: Clusterpour chaque service référencé par l'objet Ingress externe. Cette solution vous fait perdre l'adresse IP du client d'origine dans les sources du paquet. - Utilisez l'annotation
node.kubernetes.io/exclude-from-external-load-balancers=true. Ajoutez l'annotation aux nœuds ou aux pools de nœuds qui n'exécutent aucun pod actif pour un service référencé par un objet Ingress externe ou un serviceLoadBalancerdans votre cluster.
Résoudre les problèmes à l'aide des journaux de l'équilibreur de charge
Vous pouvez utiliser les journaux de l'équilibreur de charge réseau passthrough interne et les journaux de l'équilibreur de charge réseau passthrough externe pour résoudre les problèmes liés aux équilibreurs de charge et corréler le trafic des équilibreurs de charge vers les ressources GKE.
Les journaux sont agrégés par connexion et exportés en quasi-temps réel. Les journaux sont générés pour chaque nœud GKE impliqué dans le chemin de données d'un service LoadBalancer, pour le trafic entrant et sortant. Les entrées de journal incluent des champs supplémentaires pour les ressources GKE, par exemple :
- Nom du cluster
- Emplacement du cluster
- Nom du service
- Espace de noms du service
- Nom du pod
- Espace de noms du pod
Tarifs
L'utilisation des journaux n'entraîne aucuns frais supplémentaires. Selon la manière dont vous ingérez les journaux, les tarifs standards pour Cloud Logging, BigQuery ou Pub/Sub s'appliquent. L'activation des journaux n'a aucun effet sur les performances de l'équilibreur de charge.
Utiliser des outils de diagnostic pour résoudre les problèmes
L'outil de diagnostic check-gke-ingress inspecte les ressources Ingress afin de détecter les erreurs de configuration courantes. Vous pouvez utiliser l'outil check-gke-ingress de différentes manières :
- Exécutez l'outil de ligne de commande
gcpdiagsur votre cluster. Les résultats de la ressource Ingress s'affichent dans la sectiongke/ERR/2023_004de la règle de vérification. - Utilisez l'outil
check-gke-ingressseul ou en tant que plug-in kubectl en suivant les instructions de la section check-gke-ingress.
Étapes suivantes
Si vous ne trouvez pas de solution à votre problème dans la documentation, consultez Obtenir de l'aide pour bénéficier d'une assistance supplémentaire, y compris des conseils sur les sujets suivants :
- Ouvrir une demande d'assistance en contactant Cloud Customer Care.
- Obtenir de l'aide de la communauté en posant des questions sur Stack Overflow et en utilisant le tag
google-kubernetes-enginepour rechercher des problèmes similaires. Vous pouvez également rejoindre le canal Slack#kubernetes-enginepour obtenir une assistance supplémentaire de la communauté. - Signaler des bugs ou demander des fonctionnalités à l'aide de l'outil public de suivi des problèmes.