Nesta página, mostramos como resolver problemas relacionados ao balanceamento de carga em clusters do Google Kubernetes Engine (GKE) usando recursos de Serviço, Entrada ou Gateway.
BackendConfig não encontrado
Esse erro ocorre quando um BackendConfig de uma porta de serviço é especificado na anotação de serviço, mas o recurso BackendConfig real não é encontrado.
Para avaliar um evento do Kubernetes, execute o seguinte comando:
kubectl get event
O exemplo de saída a seguir indica que seu BackendConfig não foi encontrado:
KIND ... SOURCE
Ingress ... loadbalancer-controller
MESSAGE
Error during sync: error getting BackendConfig for port 80 on service "default/my-service":
no BackendConfig for service port exists
Para resolver esse problema, verifique se você não criou o recurso BackendConfig no namespace errado ou se digitou incorretamente a referência na anotação do serviço.
Política de segurança de entrada não encontrada
Depois que o objeto de Entrada é criado, se a política de segurança não estiver adequadamente associada ao serviço LoadBalancer, avalie o evento do Kubernetes para ver se há um erro de configuração. Se o BackendConfig especificar uma política de segurança que não existe, um evento de aviso vai ser emitido periodicamente.
Para avaliar um evento do Kubernetes, execute o seguinte comando:
kubectl get event
O exemplo de saída a seguir indica que sua política de segurança não foi encontrada:
KIND ... SOURCE
Ingress ... loadbalancer-controller
MESSAGE
Error during sync: The given security policy "my-policy" does not exist.
Para resolver esse problema, especifique o nome correto da política de segurança no BackendConfig.
Como solucionar erros da série 500 com NEGs durante o escalonamento de cargas de trabalho no GKE
Sintoma:
Ao usar NEGs provisionados pelo GKE para o balanceamento de carga, podem ocorrer erros 502 ou 503 nos serviços durante a redução da escala vertical das cargas de trabalho. Os erros 502 ocorrem quando os pods são encerrados antes do encerramento das conexões atuais, enquanto os erros 503 ocorrem quando o tráfego é direcionado para pods excluídos.
Esse problema pode afetar os clusters ao empregar produtos de balanceamento de carga gerenciado do GKE que usam NEGs, como NEGs de gateway, de entrada e independentes. Se você escalona as cargas de trabalho com frequência, seu cluster corre mais risco de ser afetado.
Diagnóstico:
Remover um pod no Kubernetes sem diminuir a conexão do endpoint dele e removê-lo do
NEG primeiro resulta em erros da série 500. Para evitar problemas durante o
encerramento do pod, considere a ordem das operações. As imagens a seguir
mostram cenários em que BackendService Drain Timeout não está definido e
BackendService Drain Timeout está definido com BackendConfig.
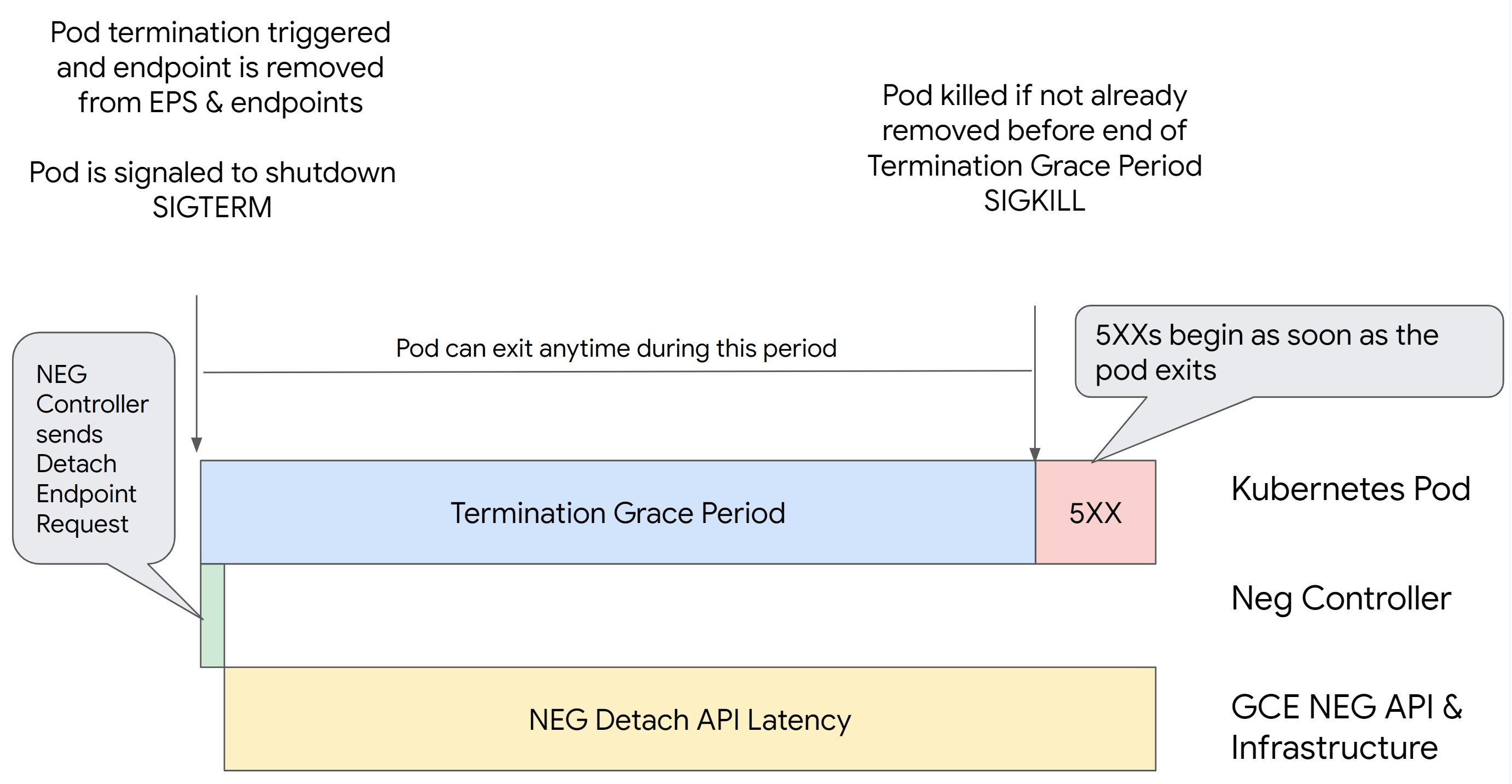
Cenário 1: BackendService Drain Timeout não está definido.
A imagem a seguir exibe um cenário em que BackendService Drain Timeout não está
configurado.
Cenário 2: BackendService Drain Timeout está definido.
A imagem a seguir exibe um cenário em que BackendService Drain Timeout está definido.

O momento exato em que os erros da série 500 ocorrem depende dos seguintes fatores:
Latência de remoção da API NEG: representa o tempo atual necessário para finalizar a operação de remoção em Google Cloud. Isso é afetado por vários fatores externos ao Kubernetes, como o tipo de balanceador de carga e a zona específica.
Latência de diminuição da conexão: é o tempo que o balanceador de carga leva para começar a direcionar o tráfego para longe de uma parte específica do sistema. Depois que a diminuição da conexão é iniciada, o balanceador de carga para de enviar novas solicitações ao endpoint. No entanto, ainda há uma latência no acionamento dessa diminuição (latência de diminuição da conexão), que pode causar erros 503 temporários caso o pod não exista mais.
Configuração da verificação de integridade: limites de verificação de integridade mais precisos reduzem a duração dos erros 503, porque podem sinalizar ao balanceador de carga que ele deve interromper o envio de solicitações aos endpoints, mesmo que a operação de remoção não tenha sido concluída.
Período de carência para o encerramento: determina o tempo máximo que um pod tem para ser encerrado. No entanto, lembre-se de que um pod pode ser encerrado antes do término desse período. Se um pod demorar mais do que isso para ser encerrado, o encerramento ocorrerá de modo forçado ao final do período. Essa configuração é feita no pod e precisa ser realizada na definição da carga de trabalho.
Possível resolução:
Para evitar erros 5XX, aplique as configurações a seguir. Os valores de tempo limite são sugestões, e talvez seja necessário ajustá-los para aplicativos específicos. Na seção a seguir, você encontra instruções sobre o processo de personalização.
A imagem a seguir mostra como manter o pod ativo com um hook preStop:
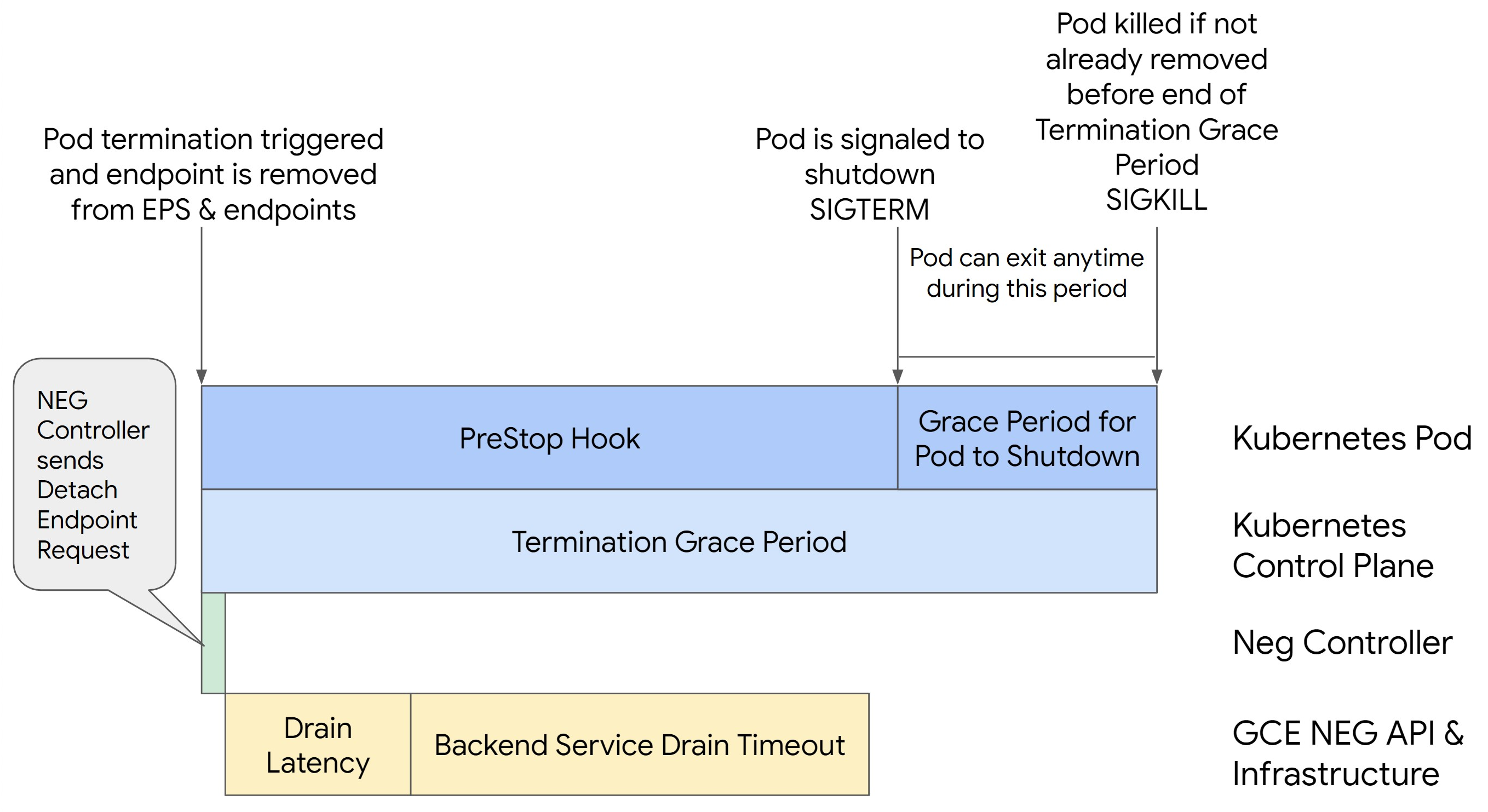
Para evitar erros da série 500, siga estas etapas:
Defina
BackendService Drain Timeoutpara o serviço como 1 minuto.Para usuários do Ingress, consulte Definir o tempo limite no BackendConfig.
Para usuários de gateway, consulte Configurar o tempo limite no GCPBackendPolicy.
Se você gerencia BackendServices diretamente usando NEGs independentes, consulte Definir o tempo limite diretamente no serviço de back-end.
Estenda
terminationGracePeriodno pod.Defina
terminationGracePeriodSecondsno pod como 3,5 minutos. Quando combinado com as configurações recomendadas, isso permite que os pods tenham uma janela de 30 a 45 segundos para realizar um encerramento normal depois da remoção do endpoint associado do NEG. Se você precisar de mais tempo para o encerramento normal, estenda o período de carência ou siga as instruções na seção Personalizar tempos limite.O seguinte Pod manifesto especifica um tempo limite de diminuição da conexão de 210 segundos (3,5 minutos):
spec: terminationGracePeriodSeconds: 210 containers: - name: my-app ... ...Aplique um hook
preStopa todos os contêineres.Aplique um hook
preStopque garanta que o pod fique ativo por mais 120 segundos enquanto ocorre a diminuição da conexão do endpoint dele no balanceador de carga e a remoção desse endpoint do NEG.spec: containers: - name: my-app ... lifecycle: preStop: exec: command: ["/bin/sh", "-c", "sleep 120s"] ...
Personalizar tempos limite
Para que você possa garantir a continuidade do pod e evitar erros da série 500, ele precisa estar ativo
até que o endpoint seja removido do NEG. Especialmente para evitar os erros 502 e 503, considere a implementação de uma combinação de tempos limite e um hook preStop.
Para manter o pod ativo por mais tempo durante o processo de encerramento, adicione um hook preStop
a ele. Execute o hook preStop antes que o encerramento de um pod seja solicitado. Assim, o hook preStop pode ser usado para manter o pod ativo até que o endpoint correspondente
seja removido do NEG.
Para manter um pod ativo por mais tempo durante o processo de encerramento,
insira um hook preStop na configuração dele, da seguinte maneira:
spec:
containers:
- name: my-app
...
lifecycle:
preStop:
exec:
command: ["/bin/sh", "-c", "sleep <latency time>"]
É possível definir tempos limite e configurações relacionadas para gerenciar o encerramento normal
de pods durante as reduções de escala vertical das cargas de trabalho. Você pode ajustar os tempos limites com base em
casos de uso específicos. Recomendamos que você comece com tempos limite mais longos e reduza a
duração conforme necessário. É possível personalizar os tempos limite configurando
parâmetros relacionados a eles e o hook preStop das seguintes maneiras:
Tempo limite de diminuição da conexão do serviço de back-end
O parâmetro Backend Service Drain Timeout não é definido por padrão e não tem
efeito. Se você definir o parâmetro Backend Service Drain Timeout e ativá-lo,
o balanceador de carga deixará de encaminhar novas solicitações ao endpoint e aguardará
o tempo limite antes de encerrar as conexões atuais.
É possível definir o parâmetro Backend Service Drain Timeout usando
BackendConfig com o Ingress, GCPBackendPolicy com o gateway ou de modo manual em
BackendService, no caso de NEGs independentes. O tempo limite precisa ser de 1,5 a 2 vezes
maior que o tempo necessário para processar uma solicitação. Isso garante que uma solicitação que
tenha chegado antes do início da diminuição da conexão seja concluída
antes do tempo limite. Definir o parâmetro Backend Service Drain Timeout como um
valor maior que 0 ajuda a reduzir erros 503, porque nenhuma nova solicitação é enviada
aos endpoints programados para remoção. Para que esse tempo limite seja eficaz, é preciso
usá-lo com o hook preStop, a fim de garantir que o pod permaneça
ativo enquanto ocorre a diminuição da conexão. Sem essa combinação, as solicitações atuais que
não foram concluídas vão receber um erro 502.
Tempo de gancho preStop
O hook preStop precisa atrasar o encerramento do pod o suficiente para
que haja tempo de concluir a latência de diminuição da conexão e o tempo limite de diminuição da conexão do serviço de back-end. Com isso, você garante a diminuição adequada da conexão e a remoção do endpoint do NEG antes do
encerramento do pod.
Para resultados ideais, verifique se o tempo de execução do hook preStop é maior
ou igual à soma de Backend Service Drain Timeout e da latência de diminuição da conexão.
Calcule o tempo ideal de execução do hook preStop com a seguinte fórmula:
preStop hook execution time >= BACKEND_SERVICE_DRAIN_TIMEOUT + DRAIN_LATENCY
Substitua:
BACKEND_SERVICE_DRAIN_TIMEOUT: o tempo que você configurou para oBackend Service Drain Timeout.DRAIN_LATENCY: um tempo estimado para a latência de drenagem. Recomendamos que você use um minuto como estimativa.
Se os erros 500 persistirem, estime a duração total da ocorrência e adicione o dobro desse tempo à latência de drenagem estimada. Isso garante que haja tempo suficiente para a diminuição adequada da conexão do pod antes da remoção dele do serviço. É possível ajustar esse valor se ele for muito grande para seu caso de uso específico.
Também é possível estimar esse tempo analisando o carimbo de data/hora da exclusão do pod e o carimbo de data/hora de quando o endpoint foi removido do NEG nos Registros de auditoria do Cloud.
Parâmetro do período de carência para o encerramento
Configure o parâmetro terminationGracePeriod para que haja tempo suficiente para que o hook preStop
seja concluído e o pod realize um
encerramento normal.
Por padrão, quando terminationGracePeriod não é definido de modo explícito, a duração é de 30 segundos.
É possível calcular o terminationGracePeriod ideal usando a seguinte fórmula:
terminationGracePeriod >= preStop hook time + Pod shutdown time
Defina terminationGracePeriod na configuração do pod da seguinte maneira:
spec:
terminationGracePeriodSeconds: <terminationGracePeriod>
containers:
- name: my-app
...
...
NEG não encontrado ao criar um recurso de Entrada interna
O seguinte erro pode ocorrer ao criar uma entrada interna no GKE:
Error syncing: error running backend syncing routine: googleapi: Error 404: The resource 'projects/PROJECT_ID/zones/ZONE/networkEndpointGroups/NEG' was not found, notFound
Esse erro ocorre porque o Ingress para balanceadores de carga internos de aplicativos requer grupos de endpoints de rede (NEGs, na sigla em inglês) como back-ends.
Em ambientes de VPC compartilhada ou clusters com políticas de rede ativadas, adicione a anotação cloud.google.com/neg: '{"ingress": true}' ao manifesto de serviço.
504 tempo limite do gateway: tempo limite da solicitação upstream
O seguinte erro pode ocorrer quando você acessa um serviço de uma entrada interna no GKE:
HTTP/1.1 504 Gateway Timeout
content-length: 24
content-type: text/plain
upsteam request timeout
Esse erro ocorre porque o tráfego enviado para balanceadores de carga de aplicativo internos é enviado por proxies Envoy no intervalo de sub-redes somente proxy.
Para permitir o tráfego do intervalo de sub-rede somente proxy,
crie uma regra de firewall
no targetPort do serviço.
Erro 400: valor inválido para o campo "resource.target"
O seguinte erro pode ocorrer quando você acessa um serviço de uma entrada interna no GKE:
Error syncing:LB_NAME does not exist: googleapi: Error 400: Invalid value for field 'resource.target': 'https://www.googleapis.com/compute/v1/projects/PROJECT_NAME/regions/REGION_NAME/targetHttpProxies/LB_NAME. A reserved and active subnetwork is required in the same region and VPC as the forwarding rule.
Para resolver esse problema, implante uma sub-rede apenas de proxy.
Erro durante a sincronização: erro ao executar a rotina de sincronização do balanceador de carga: o balanceador de carga não existe
Um dos seguintes erros pode ocorrer quando o plano de controle do GKE é atualizado ou quando você modifica um objeto de Entrada:
"Error during sync: error running load balancer syncing routine: loadbalancer
INGRESS_NAME does not exist: invalid ingress frontend configuration, please
check your usage of the 'kubernetes.io/ingress.allow-http' annotation."
Ou:
Error during sync: error running load balancer syncing routine: loadbalancer LOAD_BALANCER_NAME does not exist:
googleapi: Error 400: Invalid value for field 'resource.IPAddress':'INGRESS_VIP'. Specified IP address is in-use and would result in a conflict., invalid
Para resolver esses problemas, siga estas etapas:
- Adicione o campo
hostsna seçãotlsdo manifesto de entrada e exclua o Ingress. Aguarde cinco minutos para que o GKE exclua os recursos de Entrada não utilizados. Em seguida, recrie a Entrada. Para mais informações, consulte Campo "Hosts" de um objeto de Entrada. - Reverta as alterações feitas no Ingress. Em seguida, adicione um certificado usando uma anotação ou secret do Kubernetes.
A Entrada externa produz erros HTTP 502
Use as orientações a seguir para solucionar erros HTTP 502 com recursos de Entrada externa:
- Ative os registros para cada serviço de back-end associado a cada serviço do GKE referenciado pela Entrada.
- Use os detalhes do status para identificar as causas das respostas HTTP 502. Os detalhes do status que indicam a resposta HTTP 502 originada do back-end exigem solução de problemas nos pods de exibição, não no balanceador de carga.
Grupos de instâncias não gerenciadas
É possível que ocorram erros HTTP 502 com os recursos de Entrada externos se sua Entrada externa usar back-ends de grupos de instâncias não gerenciados. Esse problema ocorre quando todas as condições a seguir são atendidas:
- O cluster tem um grande número total de nós em todos os pools.
- Os pods de exibição para um ou mais serviços que são referenciados pela Entrada estão localizados em apenas alguns nós.
- Os serviços referenciados pela Entrada usam
externalTrafficPolicy: Local.
Para determinar se a Entrada externa usa back-ends de grupos de instâncias não gerenciadas, faça o seguinte:
Acesse a página Ingress no console do Google Cloud .
Clique no nome do Ingress externo.
Clique no nome do balanceador de carga. A página Detalhes do balanceamento de carga é exibida.
Verifique a tabela na seção Serviços de back-end para determinar se a Entrada externa usa NEGs ou grupos de instâncias.
Para resolver esse problema, use um dos métodos a seguir.
- Use um cluster nativo de VPC.
- Use
externalTrafficPolicy: Clusterpara cada Serviço referenciado pelo Ingress externo. Essa solução faz com que você perca o endereço IP original do cliente nas origens do pacote. - Use a anotação
node.kubernetes.io/exclude-from-external-load-balancers=true: Adicione a anotação aos nós ou pools de nós que não executam qualquer pod de veiculação para qualquer serviço referenciado por qualquer entrada externa ou serviçoLoadBalancerno cluster.
Usar registros do balanceador de carga para resolver problemas
É possível usar registros do balanceador de carga de rede de passagem interna e registros do balanceador de carga de rede de passagem externa para solucionar problemas com balanceadores de carga e correlacionar tráfego de balanceadores de carga para recursos do GKE.
Os registros são agregados por conexão e exportados quase em tempo real. Os registros são gerados para cada nó do GKE envolvido no caminho de dados de um serviço LoadBalancer, para o tráfego de entrada e saída. As entradas de registro incluem campos adicionais para recursos do GKE, como:
- Nome do cluster
- Local do cluster
- Nome do serviço
- Namespace do serviço
- Nome do pod
- Namespace do pod
Preços
Não há cobranças extras pelo uso de registros. Dependendo da maneira como você ingere registros, são aplicados os preços padrão ao Cloud Logging, BigQuery ou Pub/Sub. A ativação de registros não afeta o desempenho do balanceador de carga.
Usar ferramentas de diagnóstico para resolver problemas
A ferramenta de diagnóstico check-gke-ingress inspeciona os recursos do Ingress em busca de
erros de configuração comuns. É possível usar a ferramenta check-gke-ingress das seguintes
maneiras:
- Execute a
ferramenta de linha de comando
gcpdiagno cluster. Os resultados do Ingress aparecem na seçãogke/ERR/2023_004da regra de verificação. - Use a ferramenta
check-gke-ingresssozinha ou como um plug-in do kubectl seguindo as instruções em check-gke-ingress.
A seguir
Se você não encontrar uma solução para seu problema na documentação, consulte Receber suporte para mais ajuda, incluindo conselhos sobre os seguintes tópicos:
- Abrir um caso de suporte entrando em contato com o Cloud Customer Care.
- Receber suporte da comunidade fazendo perguntas no StackOverflow e usando a tag
google-kubernetes-enginepara pesquisar problemas semelhantes. Você também pode participar do canal do Slack#kubernetes-enginepara receber mais suporte da comunidade. - Abrir bugs ou solicitações de recursos usando o Issue Tracker público.