Halaman ini menjelaskan cara memigrasikan penyiapan GKE Inference Gateway dari
API v1alpha2 pratinjau ke API v1 yang tersedia secara umum.
Dokumen ini ditujukan bagi administrator platform dan spesialis jaringan
yang menggunakan GKE Inference Gateway versi v1alpha2 dan ingin
mengupgrade ke versi v1 untuk menggunakan fitur terbaru.
Sebelum memulai migrasi, pastikan Anda memahami konsep dan deployment GKE Inference Gateway. Sebaiknya tinjau Men-deploy GKE Inference Gateway.
Sebelum memulai
Sebelum memulai migrasi, tentukan apakah Anda perlu mengikuti panduan ini.
Memeriksa API v1alpha2 yang ada
Untuk memeriksa apakah Anda menggunakan v1alpha2 GKE Inference Gateway API, jalankan perintah berikut:
kubectl get inferencepools.inference.networking.x-k8s.io --all-namespaces
kubectl get inferencemodels.inference.networking.x-k8s.io --all-namespaces
Output dari perintah ini menentukan apakah Anda perlu bermigrasi:
- Jika salah satu perintah menampilkan satu atau beberapa resource
InferencePoolatauInferenceModel, Anda menggunakanv1alpha2API dan harus mengikuti panduan ini. - Jika kedua perintah menampilkan
No resources found, Anda tidak menggunakanv1alpha2API. Anda dapat melanjutkan dengan penginstalan baruv1GKE Inference Gateway.
Jalur migrasi
Ada dua jalur untuk bermigrasi dari v1alpha2 ke v1:
- Migrasi sederhana (dengan periode nonaktif): jalur ini lebih cepat dan sederhana, tetapi mengakibatkan periode nonaktif yang singkat. Jalur ini direkomendasikan jika Anda tidak memerlukan migrasi tanpa periode nonaktif.
- Migrasi tanpa periode nonaktif: jalur ini ditujukan bagi pengguna yang tidak dapat mentoleransi gangguan layanan apa pun. Hal ini melibatkan menjalankan stack
v1alpha2danv1secara berdampingan dan mengalihkan traffic secara bertahap.
Migrasi sederhana (dengan waktu non-operasional)
Bagian ini menjelaskan cara melakukan migrasi sederhana dengan periode nonaktif.
Menghapus resource
v1alpha2yang ada: untuk menghapus resourcev1alpha2, pilih salah satu opsi berikut:Opsi 1: Uninstal menggunakan Helm
helm uninstall HELM_PREVIEW_INFERENCEPOOL_NAMEOpsi 2: Menghapus resource secara manual
Jika Anda tidak menggunakan Helm, hapus semua resource yang terkait dengan deployment
v1alpha2secara manual:- Perbarui atau hapus
HTTPRouteuntuk menghapusbackendRefyang mengarah kev1alpha2InferencePool. - Hapus
v1alpha2InferencePool, semua resourceInferenceModelyang mengarah ke sana, serta Deployment dan Layanan Endpoint Picker (EPP) yang sesuai.
Setelah semua resource kustom
v1alpha2dihapus, hapus Definisi Resource Kustom (CRD) dari cluster Anda:kubectl delete -f https://github.com/kubernetes-sigs/gateway-api-inference-extension/releases/download/v0.3.0/manifests.yaml- Perbarui atau hapus
Instal resource v1: setelah Anda membersihkan resource lama, instal
v1GKE Inference Gateway. Proses ini melibatkan hal-hal berikut:- Instal Definisi Resource Kustom (CRD)
v1yang baru. - Buat
v1InferencePoolbaru dan resourceInferenceObjectiveyang sesuai. ResourceInferenceObjectivemasih ditentukan div1alpha2API. - Buat
HTTPRoutebaru yang mengarahkan traffic kev1InferencePoolbaru Anda.
- Instal Definisi Resource Kustom (CRD)
Verifikasi deployment: setelah beberapa menit, verifikasi bahwa stack
v1baru Anda melayani traffic dengan benar.Konfirmasi bahwa status Gateway adalah
PROGRAMMED:kubectl get gateway -o wideOutput-nya akan terlihat seperti ini:
NAME CLASS ADDRESS PROGRAMMED AGE inference-gateway gke-l7-regional-external-managed <IP_ADDRESS> True 10mVerifikasi endpoint dengan mengirim permintaan:
IP=$(kubectl get gateway/inference-gateway -o jsonpath='{.status.addresses[0].value}') PORT=80 curl -i ${IP}:${PORT}/v1/completions -H 'Content-Type: application/json' -d '{"model": "<var>YOUR_MODEL</var>","prompt": "<var>YOUR_PROMPT</var>","max_tokens": 100,"temperature": 0}'Pastikan Anda menerima respons yang berhasil dengan kode respons
200.
Migrasi tanpa periode nonaktif
Jalur migrasi ini dirancang untuk pengguna yang tidak dapat mengalami gangguan layanan. Diagram berikut menggambarkan cara GKE Inference Gateway memfasilitasi penayangan beberapa model AI generatif, yang merupakan aspek utama dari strategi migrasi tanpa waktu henti.
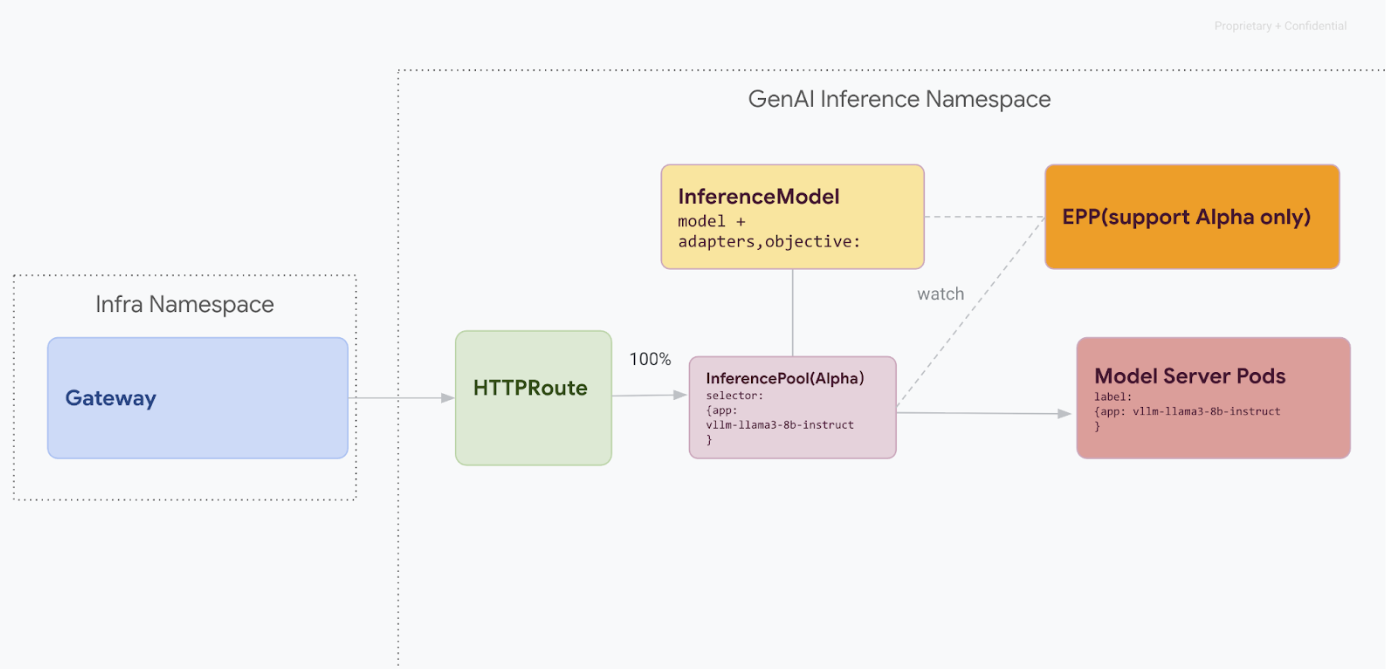
Membedakan versi API dengan kubectl
Selama migrasi tanpa waktu henti, CRD v1alpha2 dan v1 akan diinstal di cluster Anda. Hal ini dapat menimbulkan ambiguitas saat menggunakan kubectl untuk membuat kueri resource
InferencePool. Untuk memastikan Anda berinteraksi dengan versi yang benar, Anda harus menggunakan nama resource lengkap:
Untuk
v1alpha2:kubectl get inferencepools.inference.networking.x-k8s.ioUntuk
v1:kubectl get inferencepools.inference.networking.k8s.io
v1 API juga menyediakan nama singkat yang mudah, infpool, yang dapat Anda gunakan untuk mengkueri resource v1 secara khusus:
kubectl get infpool
Tahap 1: Deployment v1 berdampingan
Pada tahap ini, Anda men-deploy stack InferencePool v1 baru bersama dengan stack v1alpha2 yang ada, yang memungkinkan migrasi yang aman dan bertahap.
Setelah menyelesaikan semua langkah di tahap ini, Anda akan memiliki infrastruktur berikut dalam diagram berikut:
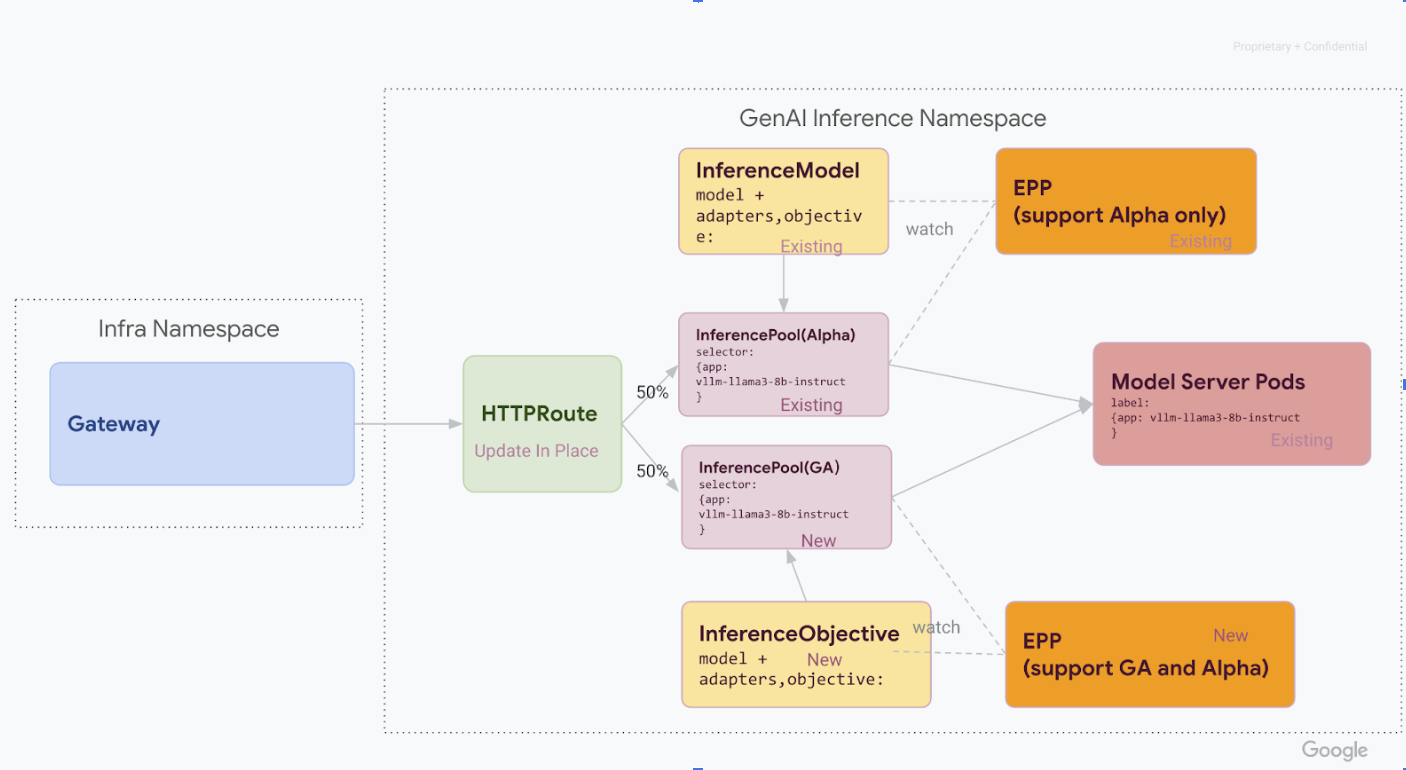
Instal Definisi Resource Kustom (CRD) yang diperlukan di cluster GKE Anda:
- Untuk versi GKE yang lebih lama dari
1.34.0-gke.1626000, jalankan perintah berikut untuk menginstal CRD v1InferencePooldan alfaInferenceObjective:
kubectl apply -f https://github.com/kubernetes-sigs/gateway-api-inference-extension/releases/download/v1.0.0/manifests.yaml- Untuk GKE versi
1.34.0-gke.1626000atau yang lebih baru, instal hanya CRD alfaInferenceObjectivedengan menjalankan perintah berikut:
kubectl apply -f https://github.com/kubernetes-sigs/gateway-api-inference-extension/raw/v1.0.0/config/crd/bases/inference.networking.x-k8s.io_inferenceobjectives.yaml- Untuk versi GKE yang lebih lama dari
Instal
v1 InferencePool.Gunakan Helm untuk menginstal
v1 InferencePoolbaru dengan nama rilis yang berbeda, sepertivllm-llama3-8b-instruct-ga.InferencePoolharus menargetkan pod Server Model yang sama denganInferencePoolalfa menggunakaninferencePool.modelServers.matchLabels.app.Untuk menginstal
InferencePool, gunakan perintah berikut:helm install vllm-llama3-8b-instruct-ga \ --set inferencePool.modelServers.matchLabels.app=MODEL_SERVER_DEPLOYMENT_LABEL \ --set provider.name=gke \ --version RELEASE \ oci://registry.k8s.io/gateway-api-inference-extension/charts/inferencepoolBuat resource
v1alpha2 InferenceObjective.Sebagai bagian dari migrasi ke rilis v1.0 Gateway API Inference Extension, kita juga perlu bermigrasi dari API
InferenceModelalfa ke APIInferenceObjectivebaru.Terapkan YAML berikut untuk membuat resource
InferenceObjective:kubectl apply -f - <<EOF --- apiVersion: inference.networking.x-k8s.io/v1alpha2 kind: InferenceObjective metadata: name: food-review spec: priority: 2 poolRef: group: inference.networking.k8s.io name: vllm-llama3-8b-instruct-ga --- apiVersion: inference.networking.x-k8s.io/v1alpha2 kind: InferenceObjective metadata: name: base-model spec: priority: 2 poolRef: group: inference.networking.k8s.io name: vllm-llama3-8b-instruct-ga --- EOF
Tahap 2: Pengalihan traffic
Dengan kedua stack berjalan, Anda dapat mulai mengalihkan traffic dari v1alpha2 ke v1
dengan memperbarui HTTPRoute untuk memisahkan traffic. Contoh ini menunjukkan pembagian 50-50.
Perbarui HTTPRoute untuk pembagian traffic.
Untuk memperbarui
HTTPRouteuntuk pemisahan traffic, jalankan perintah berikut:kubectl apply -f - <<EOF --- apiVersion: gateway.networking.k8s.io/v1 kind: HTTPRoute metadata: name: llm-route spec: parentRefs: - group: gateway.networking.k8s.io kind: Gateway name: inference-gateway rules: - backendRefs: - group: inference.networking.x-k8s.io kind: InferencePool name: vllm-llama3-8b-instruct-preview weight: 50 - group: inference.networking.k8s.io kind: InferencePool name: vllm-llama3-8b-instruct-ga weight: 50 --- EOFVerifikasi dan pantau.
Setelah menerapkan perubahan, pantau performa dan stabilitas stack
v1baru. Verifikasi bahwa gatewayinference-gatewaymemiliki statusPROGRAMMEDTRUE.
Tahap 3: Penyelesaian dan pembersihan
Setelah memverifikasi bahwa v1 InferencePool stabil, Anda dapat mengarahkan semua traffic ke v1 InferencePool dan menonaktifkan resource v1alpha2 lama.
Alihkan 100% traffic ke
v1 InferencePool.Untuk mengalihkan 100 persen traffic ke
v1 InferencePool, jalankan perintah berikut:kubectl apply -f - <<EOF --- apiVersion: gateway.networking.k8s.io/v1 kind: HTTPRoute metadata: name: llm-route spec: parentRefs: - group: gateway.networking.k8s.io kind: Gateway name: inference-gateway rules: - backendRefs: - group: inference.networking.k8s.io kind: InferencePool name: vllm-llama3-8b-instruct-ga weight: 100 --- EOFLakukan verifikasi akhir.
Setelah mengarahkan semua traffic ke stack
v1, pastikan stack tersebut menangani semua traffic seperti yang diharapkan.Konfirmasi bahwa status Gateway adalah
PROGRAMMED:kubectl get gateway -o wideOutput-nya akan terlihat seperti ini:
NAME CLASS ADDRESS PROGRAMMED AGE inference-gateway gke-l7-regional-external-managed <IP_ADDRESS> True 10mVerifikasi endpoint dengan mengirim permintaan:
IP=$(kubectl get gateway/inference-gateway -o jsonpath='{.status.addresses[0].value}') PORT=80 curl -i ${IP}:${PORT}/v1/completions -H 'Content-Type: application/json' -d '{ "model": "YOUR_MODEL, "prompt": YOUR_PROMPT, "max_tokens": 100, "temperature": 0 }'Pastikan Anda menerima respons yang berhasil dengan kode respons
200.
Bersihkan resource v1alpha2.
Setelah mengonfirmasi bahwa stack
v1beroperasi sepenuhnya, hapus resourcev1alpha2lama dengan aman.Periksa sisa sumber daya
v1alpha2.Setelah Anda bermigrasi ke
v1InferencePoolAPI, Anda dapat menghapus CRD lama dengan aman. Periksa API v1alpha2 yang ada untuk memastikan Anda tidak lagi menggunakan resourcev1alpha2. Jika masih ada beberapa yang tersisa, Anda dapat melanjutkan proses migrasi untuk akun tersebut.Hapus CRD
v1alpha2.Setelah semua resource kustom
v1alpha2dihapus, hapus Definisi Resource Kustom (CRD) dari cluster Anda:kubectl delete -f https://github.com/kubernetes-sigs/gateway-api-inference-extension/releases/download/v0.3.0/manifests.yamlSetelah menyelesaikan semua langkah, infrastruktur Anda akan terlihat seperti diagram berikut:
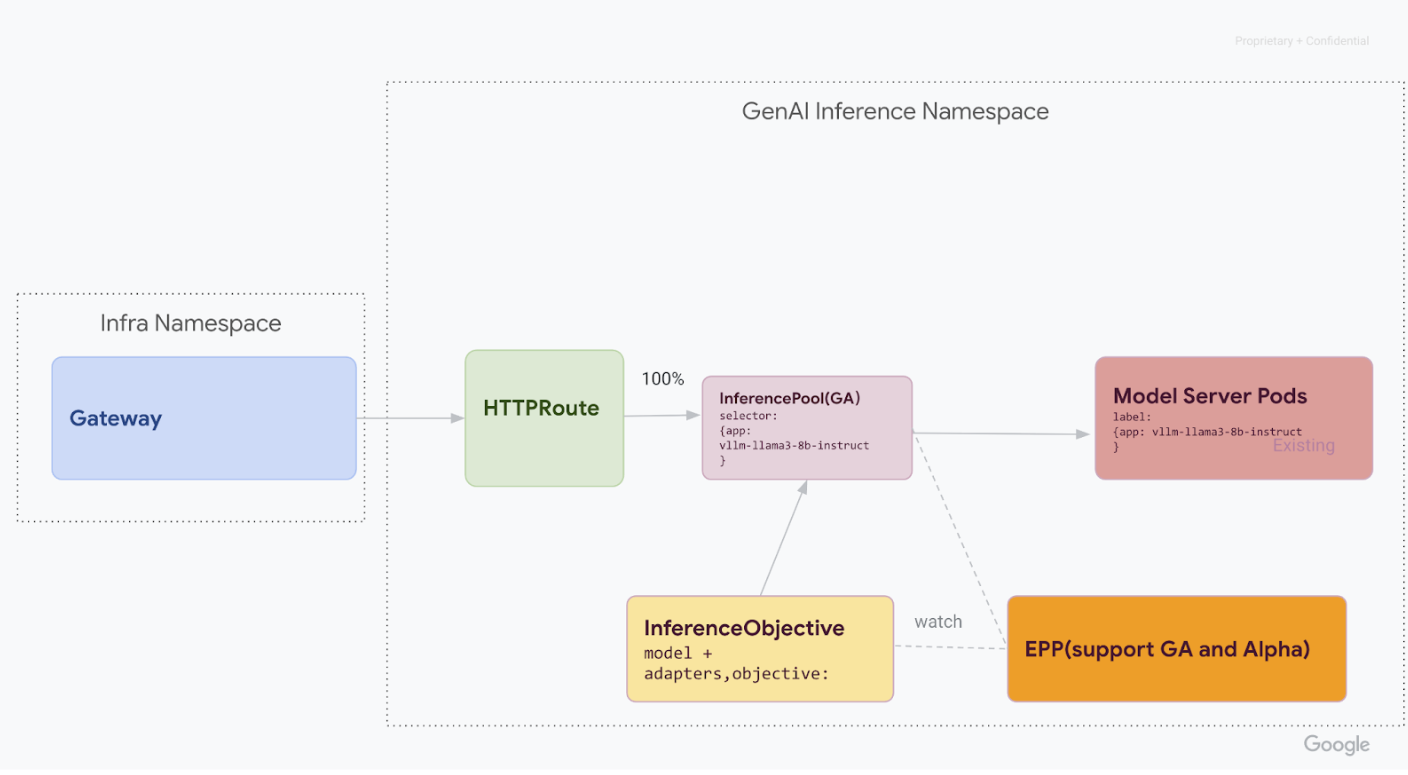
Gambar: GKE Inference Gateway merutekan permintaan ke berbagai model AI generatif berdasarkan nama dan prioritas model
Langkah berikutnya
- Pelajari lebih lanjut cara Men-deploy
GKE Inference Gateway.
- Jelajahi fitur jaringan GKE lainnya.