Overview
This page provides a comprehensive overview of what you can configure through Kubernetes Ingress on Google Cloud. The document also compares supported features for Ingress on Google Cloud and provides instructions for configuring Ingress using the default controller, FrontendConfig parameters, and BackendConfig parameters.
This page is for Networking specialists who design and architect the network for their organization and install, configure, and support network equipment. To learn more about common roles and example tasks that we reference in Google Cloud content, see Common GKE user roles and tasks.
Feature comparison
The following table provides a list of supported features for Ingress on Google Cloud. The availability of the feature, General availability (GA) or Beta is also indicated.
| Ingress class | External Ingress | Internal Ingress | Multi Cluster Ingress |
|---|---|---|---|
| Ingress controller | Google-hosted Ingress controller | ||
| Google Cloud load balancer type | External HTTP(S) LB | Internal HTTP(S) LB | External HTTP(S) LB |
| Cluster scope | Single cluster | Single cluster | Multi-cluster |
| Load balancer scope | Global | Regional | Global |
| Environment support | GKE | GKE | GKE |
| Shared VPC support | GA | GA | GA |
| Service annotations | |||
| Container-native Load Balancing (NEGs) | GA | GA | GA |
| HTTPS from load balancer to backends | GA | GA | GA |
| HTTP/2 | GA | GA TLS Only |
GA |
| Ingress annotations | |||
| Static IP addresses | GA | GA | GA |
| Kubernetes Secrets-based certificates | GA | GA | GA |
| Self-managed SSL certificates | GA | GA | GA |
| Google-managed SSL certificates | GA | GA | |
| FrontendConfig | |||
| SSL policy | GA | GA with Gateway | GA |
| HTTP-to-HTTPS redirect | GA
1.17.13-gke.2600+GA |
GA | |
| BackendConfig | |||
| Backend service timeout | GA | GA | GA |
| Cloud CDN | GA | GA | |
| Connection draining timeout | GA | GA | GA |
| Custom load balancer health check configuration | GA | GA | GA |
| Google Cloud Armor security policy | GA
1.19.10-gke.700G |
GA | |
| HTTP access logging configuration | GA | GA | GA |
| Identity-Aware Proxy (IAP) | GA | GA | GA |
| Session affinity | GA | GA | GA |
| User-defined request headers | GA | GA | |
| Custom response headers | GA
1.25-gke+G |
GA
1.25-gke+G |
|
BThis feature is available in beta starting from the specified version. Features without a version listed are supported for all available GKE versions.
GThis feature is supported as GA starting from the specified version.
Configuring Ingress using the default controller
You cannot manually configure LoadBalancer features using the Google Cloud SDK or the Google Cloud console. You must use BackendConfig or FrontendConfig Kubernetes resources.
When creating an Ingress using the default controller, you can choose the type of load balancer (an external Application Load Balancer or an internal Application Load Balancer) by using an annotation on the Ingress object. You can choose whether GKE creates zonal NEGs or if it uses instance groups by using an annotation on each Service object.
FrontendConfig and BackendConfig custom resource definitions (CRDs) allow you to further customize the load balancer. These CRDs allow you to define additional load balancer features hierarchically, in a more structured way than annotations. To use Ingress (and these CRDs), you must have the HTTP load balancing add-on enabled. GKE clusters have HTTP load balancing enabled by default; you must not disable it.
FrontendConfigs are referenced in an Ingress object and can only be used with external Ingresses. BackendConfigs are referenced by a Service object. The same CRDs can be referenced by multiple Service or Ingress objects for configuration consistency. The FrontendConfig and BackendConfig CRDs share the same lifecycle as their corresponding Ingress and Service resources and they are often deployed together.
The following diagram illustrates how:
An annotation on an Ingress or MultiClusterIngress object references a FrontendConfig CRD. The FrontendConfig CRD references a Google Cloud SSL Policy.
An annotation on a Service or MultiClusterService object references a BackendConfig CRD. The BackendConfig CRD specifies custom settings for the corresponding backend service's health check.

Associating FrontendConfig with your Ingress
FrontendConfig can only be used with External Ingresses.
You can associate a FrontendConfig with an Ingress or a MultiClusterIngress.
Ingress
Use the networking.gke.io/v1beta1.FrontendConfig annotation:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
annotations:
networking.gke.io/v1beta1.FrontendConfig: "FRONTENDCONFIG_NAME"
...
Replace FRONTENDCONFIG_NAME with the name of your
FrontendConfig.
MultiClusterIngress
Use the networking.gke.io/frontend-config annotation:
apiVersion: networking.gke.io/v1
kind: MultiClusterIngress
metadata:
annotations:
networking.gke.io/frontend-config: "FRONTENDCONFIG_NAME"
...
Replace FRONTENDCONFIG_NAME with the name of your
FrontendConfig.
Associating BackendConfig with your Ingress
You can use the
cloud.google.com/backend-config or beta.cloud.google.com/backend-config
annotation to specify the name of a BackendConfig.
Same BackendConfig for all Service ports
To use the same BackendConfig for all ports, use the default key in the
annotation. The Ingress controller uses the same BackendConfig each time it
creates a load balancer backend service to reference one of the Service's ports.
You can use the default key for both Ingress and MultiClusterIngress
resources.
apiVersion: v1
kind: Service
metadata:
annotations:
cloud.google.com/backend-config: '{"default": "my-backendconfig"}'
...
Unique BackendConfig per Service port
For both Ingress and MultiClusterIngress, you can specify a custom BackendConfig for one or more ports using a key that matches the port's name or number. The Ingress controller uses the specific BackendConfig when it creates a load balancer backend service for a referenced Service port.
GKE 1.16-gke.3 and later
apiVersion: v1
kind: Service
metadata:
annotations:
cloud.google.com/backend-config: '{"ports": {
"SERVICE_REFERENCE_A":"BACKENDCONFIG_REFERENCE_A",
"SERVICE_REFERENCE_B":"BACKENDCONFIG_REFERENCE_B"
}}'
spec:
ports:
- name: PORT_NAME_1
port: PORT_NUMBER_1
protocol: TCP
targetPort: 50000
- name: PORT_NAME_2
port: PORT_NUMBER_2
protocol: TCP
targetPort: 8080
...
All supported versions
apiVersion: v1
kind: Service
metadata:
annotations:
cloud.google.com/backend-config: '{"ports": {
PORT_NAME_1:"BACKENDCONFIG_REFERENCE_A",
PORT_NAME_2:"BACKENDCONFIG_REFERENCE_B"
}}'
spec:
ports:
- name: PORT_NAME_1
port: PORT_NUMBER_1
protocol: TCP
targetPort: 50000
- name: PORT_NAME_2
port: PORT_NUMBER_2
protocol: TCP
targetPort: 8080
...
Replace the following:
BACKENDCONFIG_REFERENCE_A: the name of an existing BackendConfig.BACKENDCONFIG_REFERENCE_B: the name of an existing BackendConfig.SERVICE_REFERENCE_A: use the value ofPORT_NUMBER_1orPORT_NAME_1. This is because a Service's BackendConfig annotation can refer to either the port's name (spec.ports[].name) or the port's number (spec.ports[].port).SERVICE_REFERENCE_B: use the value ofPORT_NUMBER_2orPORT_NAME_2. This is because a Service's BackendConfig annotation can refer to either the port's name (spec.ports[].name) or the port's number (spec.ports[].port).
When referring to the Service's port by number, you must use the port value instead of the targetPort value. The port number used here is only for binding the BackendConfig; it does not control the port to which the load balancer sends traffic or health check probes:
When using container-native load balancing, the load balancer sends traffic to an endpoint in a network endpoint group (matching a Pod IP address) on the referenced Service port's
targetPort(which must match acontainerPortfor a serving Pod). Otherwise, the load balancer sends traffic to a node's IP address on the referenced Service port'snodePort.When using a BackendConfig to provide a custom load balancer health check, the port number you use for the load balancer's health check can differ from the Service's
spec.ports[].portnumber. For details about port numbers for health checks, see Custom health check configuration.
Configuring Ingress features through FrontendConfig parameters
The following section shows you how to set your FrontendConfig to enable specific Ingress features.
SSL policies
SSL policies allow you to specify
a set of TLS versions and ciphers that the load balancer uses to terminate HTTPS
traffic from clients. You must first
create an SSL policy
outside of GKE. Once created, you can reference it in a
FrontendConfig CRD.
The sslPolicy field in the FrontendConfig
references the name of an SSL policy in the same Google Cloud project as the
GKE cluster. It attaches the SSL policy to the target HTTPS proxy,
which was created for the external HTTP(S) load balancer by the Ingress. The same
FrontendConfig resource and SSL policy
can be referenced by multiple Ingress resources. If a referenced SSL policy is
changed, the change is propagated to the Google Front Ends (GFEs) that power
your external HTTP(S) load balancer created by the Ingress.
The following FrontendConfig manifest enables an SSL policy named
gke-ingress-ssl-policy:
apiVersion: networking.gke.io/v1beta1
kind: FrontendConfig
metadata:
name: my-frontend-config
spec:
sslPolicy: gke-ingress-ssl-policy
HTTP to HTTPS redirects
An external HTTP load balancer can redirect unencrypted HTTP requests to an HTTPS load balancer that uses the same IP address. When you create an Ingress with HTTP to HTTPS redirects enabled, both of these load balancers are created automatically. Requests to the external IP address of the Ingress on port 80 are automatically redirected to the same external IP address on port 443. This functionality is built on HTTP to HTTPS redirects provided by Cloud Load Balancing.
To support HTTP to HTTPS redirection, an Ingress must be configured to serve both HTTP and HTTPS traffic. If either HTTP or HTTPS is disabled, redirection will not work.
HTTP to HTTPS redirects are configured using the redirectToHttps field in a
FrontendConfig custom resource. Redirects are enabled for the entire Ingress
resource so all services referenced by the Ingress will have HTTPS redirects
enabled.
The following FrontendConfig manifest enables HTTP to HTTPS redirects. Set the
spec.redirectToHttps.enabled field to true to enable HTTPS redirects. The
spec.responseCodeName field is optional. If it's omitted a 301 Moved
Permanently redirect is used.
apiVersion: networking.gke.io/v1beta1
kind: FrontendConfig
metadata:
name: my-frontend-config
spec:
redirectToHttps:
enabled: true
responseCodeName: RESPONSE_CODE
Replace RESPONSE_CODE with one of the following:
MOVED_PERMANENTLY_DEFAULTto return a 301 redirect response code (default ifresponseCodeNameis unspecified).FOUNDto return a 302 redirect response code.SEE_OTHERto return a 303 redirect response code.TEMPORARY_REDIRECTto return a 307 redirect response code.PERMANENT_REDIRECTto return a 308 redirect response code.
When redirects are enabled the Ingress controller creates a load balancer as shown in the following diagram:

To validate that your redirect is working, use a curl command:
curl http://IP_ADDRESS
Replace IP_ADDRESS with the IP address of your Ingress.
The response shows the redirect response code that you configured. For example
the following example is for a FrontendConfig configured with a
301: MovedPermanently redirect:
<HTML><HEAD><meta http-equiv="content-type" content="text/html;charset=utf-8">
<TITLE>301 Moved</TITLE></HEAD><BODY>
<H1>301 Moved</H1>
The document has moved
<A HREF="https://35.244.160.59/">here</A>.</BODY></HTML>
Configuring Ingress features through BackendConfig parameters
The following sections show you how to set your BackendConfig to enable specific Ingress features. Changes to a BackendConfig resource are constantly reconciled, so you do not need to delete and recreate your Ingress to see that BackendConfig changes are reflected.
For information on BackendConfig limitations, see the limitations section.
Backend service timeout
You can use a BackendConfig to set a backend service timeout period in seconds. If you do not specify a value, the default value is 30 seconds.
The following BackendConfig manifest specifies a timeout of 40 seconds:
apiVersion: cloud.google.com/v1
kind: BackendConfig
metadata:
name: my-backendconfig
spec:
timeoutSec: 40
Cloud CDN
You can enable Cloud CDN using a BackendConfig.
The following BackendConfig manifest shows all the fields available when enabling Cloud CDN:
apiVersion: cloud.google.com/v1
kind: BackendConfig
metadata:
name: my-backendconfig
spec:
cdn:
enabled: CDN_ENABLED
cachePolicy:
includeHost: INCLUDE_HOST
includeProtocol: INCLUDE_PROTOCOL
includeQueryString: INCLUDE_QUERY_STRING
# Specify only one of queryStringBlacklist and queryStringWhitelist.
queryStringBlacklist: QUERY_STRING_DENYLIST
queryStringWhitelist: QUERY_STRING_ALLOWLIST
cacheMode: CACHE_MODE
clientTtl: CLIENT_TTL
defaultTtl: DEFAULT_TTL
maxTtl: MAX_TTL
negativeCaching: NEGATIVE_CACHING
negativeCachingPolicy:
code: NEGATIVE_CACHING_CODE
ttl: NEGATIVE_CACHING_TTL
requestCoalescing: REQ_COALESCING
# Time, in seconds, to continue serving a stale version after request expiry.
serveWhileStale: SERVE_WHILE_STALE
signedUrlCacheMaxAgeSec: SIGNED_MAX_AGE
signedUrlKeys:
keyName: KEY_NAME
keyValue: KEY_VALUE
secretName: SECRET_NAME
Replace the following:
CDN_ENABLED: If set totrue, Cloud CDN is enabled for this Ingress backend.INCLUDE_HOST: If set totrue, requests to different hosts are cached separately.INCLUDE_PROTOCOL: If set totrue, HTTP and HTTPS requests are cached separately.INCLUDE_QUERY_STRING: If set totrue, query string parameters are included in the cache key according toqueryStringBlacklistorqueryStringWhitelist. If neither is set, the entire query string is included. If set tofalse, the entire query string is excluded from the cache key.QUERY_STRING_DENYLIST: Specify a string array with the names of query string parameters to exclude from cache keys. All other parameters are included. You can specifyqueryStringBlacklistorqueryStringWhitelist, but not both.QUERY_STRING_ALLOWLIST: Specify a string array with the names of query string parameters to include in cache keys. All other parameters are excluded. You canqueryStringBlacklistorqueryStringWhitelist, but not both.
The following fields are only supported in GKE versions 1.23.3-gke.900 and later using GKE Ingress. They are not supported using Multi Cluster Ingress:
CACHE_MODE: The cache mode.CLIENT_TTL,DEFAULT_TTL, andMAX_TTL: TTL configuration. For more information, see Using TTL settings and overrides.NEGATIVE_CACHING: If set totrue, negative caching is enabled. For more information, see Using negative caching.NEGATIVE_CACHING_CODEandNEGATIVE_CACHING_TTL: Negative caching configuration. For more information, see Using negative caching.REQ_COALESCING: If set totrue, collapsing is enabled. For more information, see Request collapsing (coalescing).SERVE_WHILE_STALE: Time, in seconds, after the response has expired that Cloud CDN continues serving a stale version. For more information, see Serving stale content.SIGNED_MAX_AGE: Maximum time responses can be cached, in seconds. For more information, see Optionally customizing the maximum cache time.KEY_NAME,KEY_VALUEandSECRET_NAME: Signed URL key configuration. For more information, see Creating signed request keys.
Expand the following section to see an example that deploys Cloud CDN through Ingress and then validates that application content is being cached.
Connection draining timeout
You can configure connection draining timeout using a BackendConfig. Connection draining timeout is the time, in seconds, to wait for connections to drain. For the specified duration of the timeout, existing requests to the removed backend are given time to complete. The load balancer does not send new requests to the removed backend. After the timeout duration is reached, all remaining connections to the backend are closed. The timeout duration can be from 0 to 3600 seconds. The default value is 0, which also disables connection draining.
The following BackendConfig manifest specifies a connection draining timeout of 60 seconds:
apiVersion: cloud.google.com/v1
kind: BackendConfig
metadata:
name: my-backendconfig
spec:
connectionDraining:
drainingTimeoutSec: 60
Custom health check configuration
There are a variety of ways that GKE configures Google Cloud load balancer health checks when deploying through Ingress. To learn more about how GKE Ingress deploys health checks, see Ingress health checks.
A BackendConfig allows you to precisely control the load balancer health check settings.
You can configure multiple GKE Services to reference the same
BackendConfig as a reusable template. For healthCheck parameters, a unique
Google Cloud health check is created for each backend service
corresponding to each GKE Service.
The following BackendConfig manifest shows all the fields available when configuring a BackendConfig health check:
apiVersion: cloud.google.com/v1
kind: BackendConfig
metadata:
name: my-backendconfig
spec:
healthCheck:
# Time, in seconds, between prober checks. Default is `5`.
checkIntervalSec: INTERVAL
# Probe timeout period. Must be less than or equal to checkIntervalSec.
timeoutSec: TIMEOUT
healthyThreshold: HEALTH_THRESHOLD
unhealthyThreshold: UNHEALTHY_THRESHOLD
# Protocol to use. Must be `HTTP`, `HTTP2`, or `HTTPS`.
type: PROTOCOL
# Path for probe to use. Default is `/`.
requestPath: PATH
# Port number of the load balancer health check port. Default is `80`.
port: PORT
Replace the following:
INTERVAL: Specify thecheck-interval, in seconds, for each health check prober. This is the time from the start of one prober's check to the start of its next check. If you omit this parameter, the Google Cloud default of 5 seconds is used. For additional implementation details, see Multiple probes and frequency.TIMEOUT: Specify the amount of time that Google Cloud waits for a response to a probe. The value ofTIMEOUTmust be less than or equal to theINTERVAL. Units are seconds. Each probe requires anHTTP 200 (OK)response code to be delivered before the probe timeout.HEALTH_THRESHOLDandUNHEALTHY_THRESHOLD: Specify the number of sequential connection attempts that must succeed or fail, for at least one prober, in order to change the health state from healthy to unhealthy or vice versa. If you omit one of these parameters, Google Cloud uses the default value of 2.PROTOCOL: Specify a protocol used by probe systems for health checking. TheBackendConfigonly supports creating health checks using the HTTP, HTTPS, or HTTP2 protocols. For more information, see Success criteria for HTTP, HTTPS, and HTTP/2. You cannot omit this parameter.PATH: For HTTP, HTTPS, or HTTP2 health checks, specify therequest-pathto which the probe system should connect. If you omit this parameter, Google Cloud uses the default of/.PORT: A BackendConfig only supports specifying the load balancer health check port by using a port number. If you omit this parameter, Google Cloud uses the default value80.When using container native load balancing, you should select a port matching a
containerPortof a serving Pod (whether or not thatcontainerPortis referenced by atargetPortof the Service). Because the load balancer sends probes to the Pod's IP address directly, you are not limited tocontainerPorts referenced by a Service'stargetPort. Health check probe systems connect to a serving Pod's IP address on the port you specify.For instance group backends, you must select a port matching a
nodePortexposed by the Service. Health check probe systems then connect to each node on that port.
To set up GKE Ingress with a custom HTTP health check, see GKE Ingress with custom HTTP health check.
Google Cloud Armor Ingress security policy
Google Cloud Armor security policies help you protect your load-balanced applications from web-based attacks. Once you have configured a Google Cloud Armor security policy, you can reference it using a BackendConfig.
Add the name of your security policy to the BackendConfig. The following
BackendConfig manifest specifies a security policy named
example-security-policy:
apiVersion: cloud.google.com/v1
kind: BackendConfig
metadata:
namespace: cloud-armor-how-to
name: my-backendconfig
spec:
securityPolicy:
name: "example-security-policy"
Two Sources Of Truth
Though configured through GKE, the underlying
Compute Engine BackendService APIs can still be used to directly modify
which security policy to apply. This creates two sources of truth:
GKE and Compute Engine. GKE Ingress
Controller's behavior in response to the securityPolicy field within
BackendConfig is documented in the table below. To avoid conflict and
unexpected behavior, we recommend using the GKE BackendConfig
for the management of which security policy to use.
| BackendConfig field | Value | Behaviour |
|---|---|---|
spec.securityPolicy.name |
CloudArmorPolicyName |
The GKE Ingress Controller sets Cloud Armor policy named CloudArmorPolicyName to the load balancer. The GKE Ingress Controller overwrites whatever policy that was previously set. |
spec.securityPolicy.name |
Empty string ("") |
The GKE Ingress Controller removes any configured Cloud Armor policy from the load balancer. |
spec.securityPolicy |
nil |
The GKE Ingress Controller uses the configuration set on the BackendService object configured through the Compute Engine API using the Google Cloud console, or gcloud CLI, or Terraform. |
To set up GKE Ingress with Google Cloud Armor protection, see Google Cloud Armor enabled Ingress.
HTTP access logging
Ingress can log all HTTP requests from clients to Cloud Logging. You can enable and disable access logging using BackendConfig along with setting the access logging sampling rate.
To configure access logging, use the logging field in your BackendConfig. If
logging is omitted, access logging takes the default behavior. This is
dependent on the GKE version.
You can configure the following fields:
enable: If set totrue, access logging will be enabled for this Ingress and logs is available in Cloud Logging. Otherwise, access logging is disabled for this Ingress.sampleRate: Specify a value from 0.0 through 1.0, where 0.0 means no packets are logged and 1.0 means 100% of packets are logged. This field is only relevant ifenableis set totrue.sampleRateis an optional field, but if it's configured thenenable: truemust also be set or else it is interpreted asenable: false.
The following BackendConfig manifest enables access logging and sets the sample rate to 50% of the HTTP requests for a given Ingress resource:
apiVersion: cloud.google.com/v1
kind: BackendConfig
metadata:
name: my-backendconfig
spec:
logging:
enable: true
sampleRate: 0.5
Identity-Aware Proxy
To configure the BackendConfig for
Identity-Aware Proxy IAP,
you need to specify the enabled and secretName values to your iap block
in your BackendConfig. To specify these values, ensure that GKE service agent has the
compute.backendServices.update permission.
The following BackendConfig manifest enables Identity-Aware Proxy:
apiVersion: cloud.google.com/v1
kind: BackendConfig
metadata:
name: my-backendconfig
spec:
iap:
enabled: true
oauthclientCredentials:
secretName: my-secret
Enable IAP with the Google-managed OAuth client
Starting in GKE 1.29.4-gke.1043000, IAP can be configured to use the Google-managed OAuth client using a BackendConfig. To decide whether to use the Google-managed OAuth client or a custom OAuth client, see When to use a custom OAuth configuration in the IAP documentation.
To enable IAP with the Google-managed OAuth client, do not provide the OAuthCredentials in the BackendConfig. For users who already configured IAP using OAuthCredentials, there is no migration path to switch to using the Google-managed OAuth client: you must recreate the Backend (remove the Service from the Ingress and re-attach). We suggest performing this operation during a maintenance window as this will cause downtime. The opposite migration path, switching from the Google-managed OAuth client to OAuthCredentials is possible.
The following BackendConfig manifest enables Identity-Aware Proxy with the Google-managed OAuth client:
apiVersion: cloud.google.com/v1
kind: BackendConfig
metadata:
name: my-backendconfig
spec:
iap:
enabled: true
For full instructions, see Enabling IAP for GKE in the IAP documentation.
Identity-Aware Proxy with internal Ingress
To configure internal Ingress for IAP, you must use the Premium Tier. If you do not use the Premium Tier, you cannot view or create internal Application Load Balancers with Identity-Aware Proxy. You must also have a Chrome Enterprise Premium subscription to use internal Ingress for IAP.
To set up secure GKE Ingress with Identity-Aware Proxy based authentication, see example, IAP enabled ingress.
Session affinity
You can use a BackendConfig to set session affinity to client IP or generated cookie.
Client IP affinity
To use a BackendConfig to set
client IP affinity,
set affinityType to "CLIENT_IP", as in the following example:
apiVersion: cloud.google.com/v1
kind: BackendConfig
metadata:
name: my-backendconfig
spec:
sessionAffinity:
affinityType: "CLIENT_IP"
Generated cookie affinity
To use a BackendConfig to set
generated cookie affinity
, set affinityType to
GENERATED_COOKIE in your BackendConfig manifest. You can also use
affinityCookieTtlSec to set the time period for the cookie to remain active.
The following manifest sets the affinity type to generated cookie and gives the cookies a TTL of 50 seconds:
apiVersion: cloud.google.com/v1
kind: BackendConfig
metadata:
name: my-backendconfig
spec:
sessionAffinity:
affinityType: "GENERATED_COOKIE"
affinityCookieTtlSec: 50
User-defined request headers
You can use a BackendConfig to configure user-defined request headers. The load balancer adds the headers you specify to the requests it forwards to the backends.
The load balancer adds custom request headers only to the client requests, not to the health check probes. If your backend requires a specific header for authorization that is missing from the health check packet, the health check might fail.
To enable user-defined request headers, you specify a list of headers in the
customRequestHeaders property of the BackendConfig resource. Specify each
header as a header-name:header-value string.
The following BackendConfig manifest adds three request headers:
apiVersion: cloud.google.com/v1
kind: BackendConfig
metadata:
name: my-backendconfig
spec:
customRequestHeaders:
headers:
- "X-Client-Region:{client_region}"
- "X-Client-City:{client_city}"
- "X-Client-CityLatLong:{client_city_lat_long}"
Custom response headers
To enable custom response headers, you specify a list of headers in the
customResponseHeaders property of the BackendConfig resource. Specify each
header as a header-name:header-value string.
Custom response headers are available only in GKE clusters version 1.25 and later.
The following BackendConfig manifest is an example to add an HTTP Strict Transport Security (HSTS) response header:
apiVersion: cloud.google.com/v1
kind: BackendConfig
metadata:
name: my-backendconfig
spec:
customResponseHeaders:
headers:
- "Strict-Transport-Security: max-age=28800; includeSubDomains"
Exercise: Setting Ingress timeouts using a backend service
The following exercise shows you the steps required for configuring timeouts and connection draining with an Ingress with a BackendConfig resource.
To configure the backend properties of an Ingress, complete the following tasks:
- Create a Deployment.
- Create a BackendConfig.
- Create a Service, and associate one of its ports with the BackendConfig.
- Create an Ingress, and associate the Ingress with the (Service, port) pair.
- Validate the properties of the backend service.
- Clean up.
Creating a Deployment
Before you create a BackendConfig and a Service, you need to create a Deployment.
The following example manifest is for a Deployment named
my-deployment.yaml:
# my-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-deployment
spec:
selector:
matchLabels:
purpose: bsc-config-demo
replicas: 2
template:
metadata:
labels:
purpose: bsc-config-demo
spec:
containers:
- name: hello-app-container
image: us-docker.pkg.dev/google-samples/containers/gke/hello-app:1.0
Create the Deployment by running the following command:
kubectl apply -f my-deployment.yaml
Creating a BackendConfig
Use your BackendConfig to specify the Ingress features you want to use.
This BackendConfig manifest, named my-backendconfig.yaml, specifies:
- A timeout of 40 seconds.
- A connection draining timeout of 60 seconds.
# my-backendconfig.yaml
apiVersion: cloud.google.com/v1
kind: BackendConfig
metadata:
name: my-backendconfig
spec:
timeoutSec: 40
connectionDraining:
drainingTimeoutSec: 60
Create the BackendConfig by running the following command:
kubectl apply -f my-backendconfig.yaml
Creating a Service
A BackendConfig corresponds to a single Service-Port combination, even if a Service has multiple ports. Each port can be associated with a single BackendConfig CRD. If a Service port is referenced by an Ingress, and if the Service port is associated with a BackendConfig, then the HTTP(S) load balancing backend service takes part of its configuration from the BackendConfig.
The following is an example Service manifest named my-service.yaml:
# my-service.yaml
apiVersion: v1
kind: Service
metadata:
name: my-service
# Associate the Service with Pods that have the same label.
labels:
purpose: bsc-config-demo
annotations:
# Associate TCP port 80 with a BackendConfig.
cloud.google.com/backend-config: '{"ports": {"80":"my-backendconfig"}}'
cloud.google.com/neg: '{"ingress": true}'
spec:
type: ClusterIP
selector:
purpose: bsc-config-demo
ports:
# Forward requests from port 80 in the Service to port 8080 in a member Pod.
- port: 80
protocol: TCP
targetPort: 8080
The cloud.google.com/backend-config annotation specifies a mapping between ports
and BackendConfig objects. In my-service.yaml:
- Any Pod that has the label
purpose: bsc-config-demois a member of the Service. - TCP port 80 of the Service is associated with a BackendConfig named
my-backendconfig. Thecloud.google.com/backend-configannotation specifies this. - A request sent to port 80 of the Service is forwarded to one of the member Pods on port 8080.
To create the Service, run the following command:
kubectl apply -f my-service.yaml
Creating an Ingress
The following is an Ingress manifest named my-ingress.yaml. In
this example, incoming requests are routed to port 80 of the Service named
my-service.
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: my-ingress
spec:
rules:
# Route all HTTP requests to port 80 in a Service.
- http:
paths:
- path: /*
pathType: ImplementationSpecific
backend:
service:
name: my-service
port:
number: 80
To create the Ingress, run the following command:
kubectl apply -f my-ingress.yaml
Wait a few minutes for the Ingress controller to configure an external Application Load Balancer and an associated backend service. Once this is complete, you have configured your Ingress to use a timeout of 40 seconds and a connection draining timeout of 60 seconds.
Validating backend service properties
You can validate that the correct load balancer settings have been applied through your BackendConfig. To do this, identify the backend service that Ingress has deployed and inspect its settings to validate that they match the Deployment manifests.
First, describe the my-ingress resource and filter for the annotation that
lists the backend services associated with the Ingress. For example:
kubectl describe ingress my-ingress | grep ingress.kubernetes.io/backends
You should see output similar to the following:
ingress.kubernetes.io/backends: '{"k8s1-27fde173-default-my-service-80-8d4ca500":"HEALTHY","k8s1-27fde173-kube-system-default-http-backend-80-18dfe76c":"HEALTHY"}
The output provides information about your backend services. For example, this annotation contains two backend services:
"k8s1-27fde173-default-my-service-80-8d4ca500":"HEALTHY"provides information about the backend service associated with themy-serviceKubernetes Service.k8s1-27fde173is a hash used to describe the cluster.defaultis the Kubernetes namespace.HEALTHYindicates that the backend is healthy.
"k8s1-27fde173-kube-system-default-http-backend-80-18dfe76c":"HEALTHY"provides information about the backend service associated with the default backend (404-server).k8s1-27fde173is a hash used to describe the cluster.kube-systemis the namespace.default-http-backendis the Kubernetes Service name.80is the host port.HEALTHYindicates that the backend is healthy.
Next, inspect the backend service associated with my-service using gcloud.
Filter for "drainingTimeoutSec" and "timeoutSec" to confirm that they've
been set in the Google Cloud Load Balancer control plane. For example:
# Optionally, set a variable
export BES=k8s1-27fde173-default-my-service-80-8d4ca500
# Filter for drainingTimeoutSec and timeoutSec
gcloud compute backend-services describe ${BES} --global | grep -e "drainingTimeoutSec" -e "timeoutSec"
Output:
drainingTimeoutSec: 60
timeoutSec: 40
Seeing drainingTimeoutSec and timeoutSec in the output confirms that their values
were correctly set through the BackendConfig.
Cleaning up
To prevent unwanted charges incurring on your account, delete the Kubernetes objects that you created for this exercise:
kubectl delete ingress my-ingress
kubectl delete service my-service
kubectl delete backendconfig my-backendconfig
kubectl delete deployment my-deployment
BackendConfig limitations
BackendConfigs have the following limitations:
Only one (Service, port) pair can consume only one BackendConfig, even if multiple Ingress objects reference the (Service, port). This means all Ingress objects that reference the same (Service, port) must use the same configuration for Cloud Armor, IAP, and Cloud CDN.
IAP and Cloud CDN cannot be enabled for the same HTTP(S) Load Balancing backend service. This means that you cannot configure both IAP and Cloud CDN in the same BackendConfig.
You must use
kubectl1.7 or later to interact with BackendConfig.
Removing the configuration specified in a FrontendConfig or BackendConfig
To revoke an Ingress feature, you must explicitly disable the feature configuration in the FrontendConfig or BackendConfig CRD. The Ingress controller only reconciles configurations specified in these CRDs.
To clear or disable a previously enabled configuration, set the field's value
to an empty string ("") or to a Boolean value of false, depending on the
field type.
The following BackendConfig manifest disables a Google Cloud Armor security policy and Cloud CDN:
apiVersion: cloud.google.com/v1
kind: BackendConfig
metadata:
name: my-backendconfig
spec:
cdn:
enabled: false
securityPolicy:
name: ""
Deleting a FrontendConfig or BackendConfig
FrontendConfig
To delete a FrontendConfig, follow these steps:
Remove the FrontendConfig's name from the
networking.gke.io/v1beta1.FrontendConfigannotation in the Ingress manifest.Apply the changed Ingress manifest to your cluster. For example, use
kubectl apply.Delete the FrontendConfig. For example, use
kubectl delete frontendconfig config my-frontendconfig.
BackendConfig
To delete a BackedConfig, follow these steps:
Remove the BackendConfig's name from the
cloud.google.com/backend-configannotation in the Service manifest.Apply the changed Service manifest to your cluster. For example, use
kubectl apply.Delete the BackendConfig. For example, use
kubectl delete backendconfig my-backendconfig.
Troubleshooting
You can detect common misconfigurations using the Ingress diagnostic tool. You should also ensure that any health checks are configured correctly.
BackendConfig not found
This error occurs when a BackendConfig for a Service port is specified in the Service annotation, but the actual BackendConfig resource couldn't be found.
To evaluate a Kubernetes event, run the following command:
kubectl get event
The following example output indicates your BackendConfig was not found:
KIND ... SOURCE
Ingress ... loadbalancer-controller
MESSAGE
Error during sync: error getting BackendConfig for port 80 on service "default/my-service":
no BackendConfig for service port exists
To resolve this issue, ensure you have not created the BackendConfig resource in the wrong namespace or misspelled its reference in the Service annotation.
Ingress security policy not found
After the Ingress object is created, if the security policy isn't properly associated with the LoadBalancer Service, evaluate the Kubernetes event to see if there is a configuration mistake. If your BackendConfig specifies a security policy that does not exist, a warning event is periodically emitted.
To evaluate a Kubernetes event, run the following command:
kubectl get event
The following example output indicates your security policy was not found:
KIND ... SOURCE
Ingress ... loadbalancer-controller
MESSAGE
Error during sync: The given security policy "my-policy" does not exist.
To resolve this issue, specify the correct security policy name in your BackendConfig.
Addressing 500 series errors with NEGs during workload scaling in GKE
Symptom:
When you use GKE provisioned NEGs for load balancing, you might experience 502 or 503 errors for the services during the workload scale down. 502 errors occur when Pods are terminated before existing connections close, while the 503 errors occur when traffic is directed to deleted Pods.
This issue can affect clusters if you are using GKE managed load balancing products that use NEGs, including Gateway, Ingress, and standalone NEGs. If you frequently scale your workloads, your cluster is at a higher risk of being affected.
Diagnosis:
Removing a Pod in Kubernetes without draining its endpoint and removing it from
the NEG first leads to 500 series errors. To avoid issues during Pod
termination, you must consider the order of operations. The following images
display scenarios when BackendService Drain Timeout is unset and
BackendService Drain Timeout is set with BackendConfig.
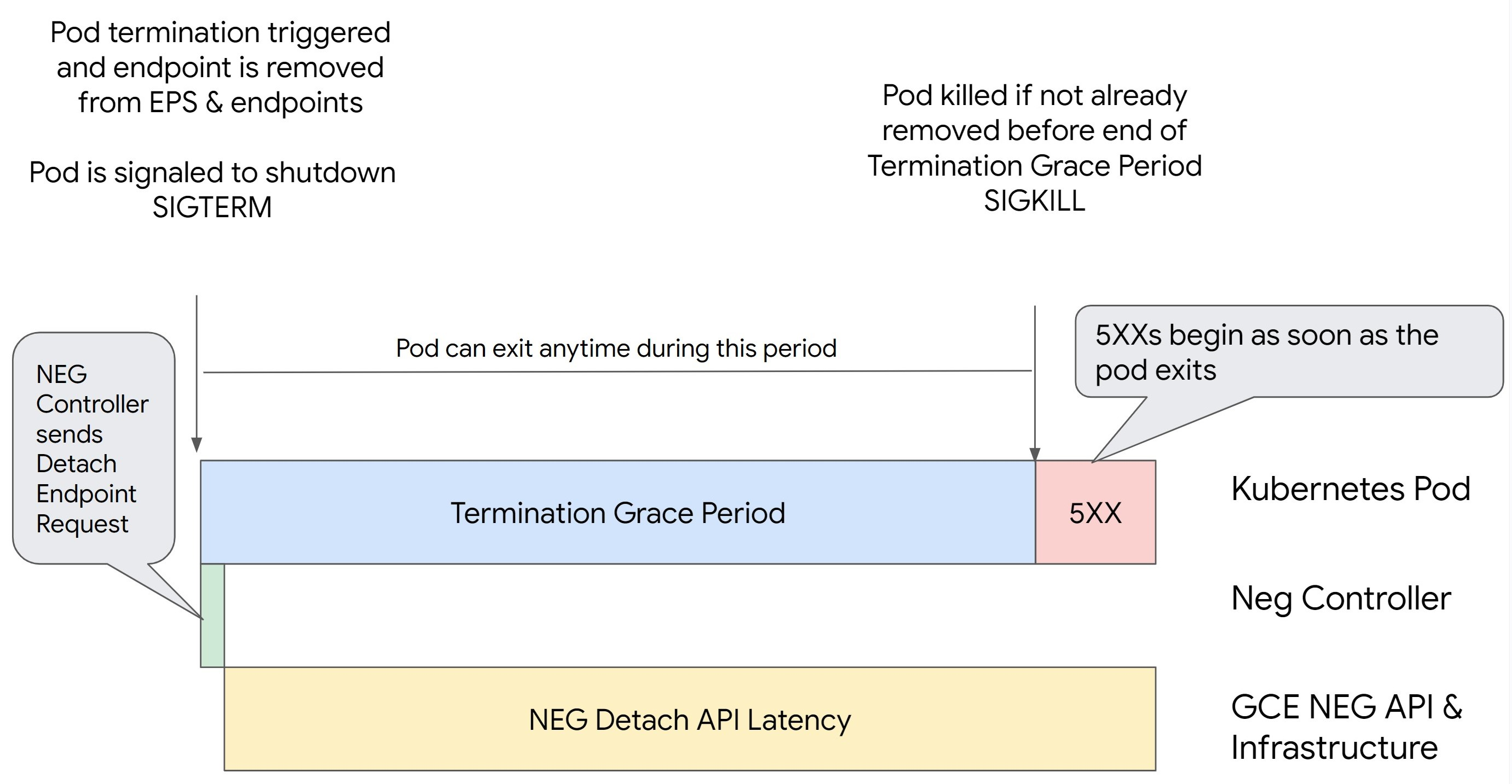
Scenario 1: BackendService Drain Timeout is unset.
The following image displays a scenario where the BackendService Drain Timeout is
unset.
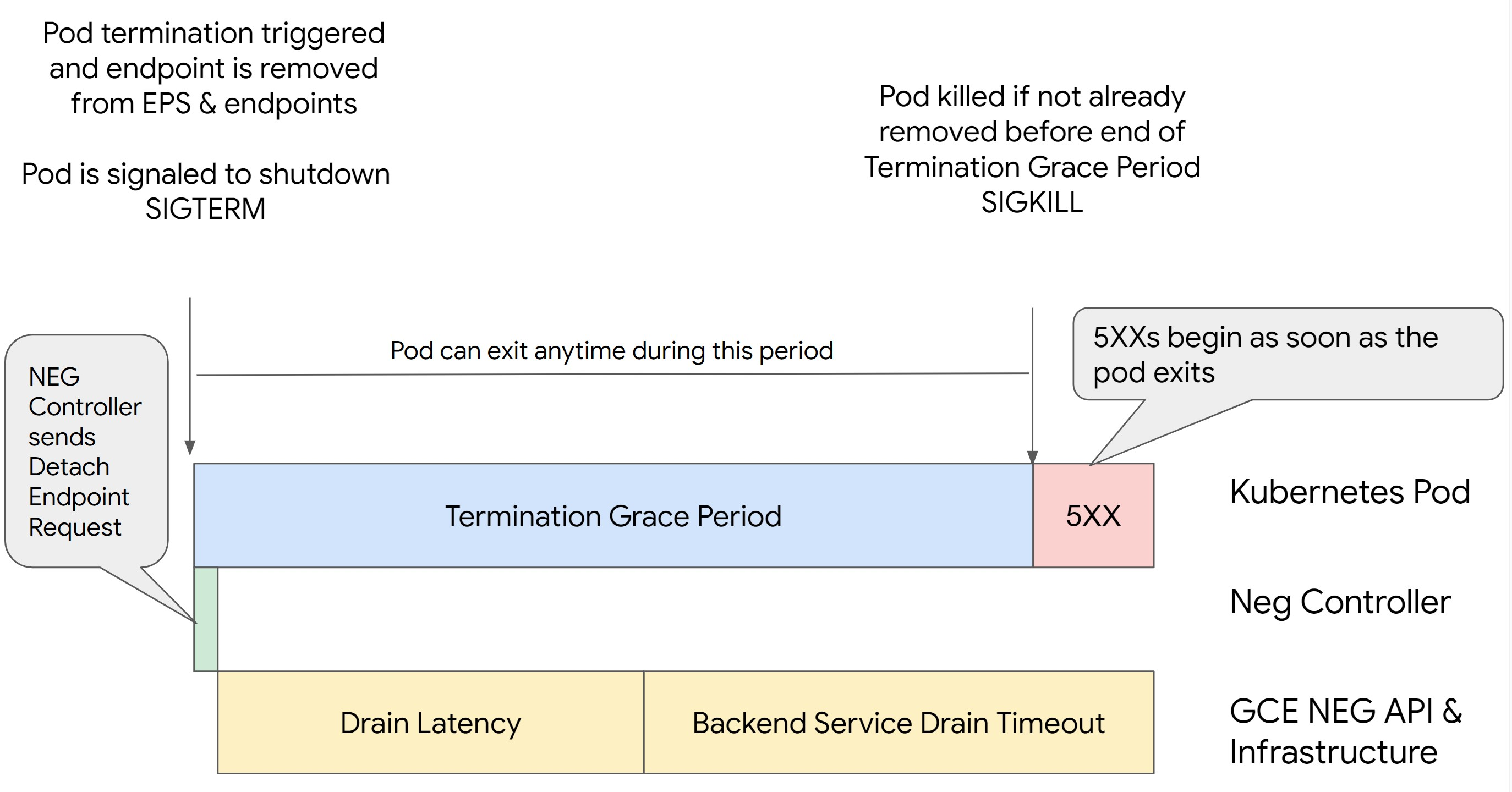
Scenario 2: BackendService Drain Timeout is set.
The following image displays a scenario where the BackendService Drain Timeout is set.
The exact time the 500 series errors occur depends on the following factors:
NEG API detach latency: The NEG API detach latency represents the current time taken for the detach operation to finalize in Google Cloud. This is influenced by a variety of factors outside Kubernetes, including the type of load balancer and the specific zone.
Drain latency: Drain latency is the time taken for the load balancer to start directing traffic away from a particular part of your system. After drain is initiated, the load balancer stops sending new requests to the endpoint, however there is still a latency in triggering drain (drain latency) which can cause temporary 503 errors if the Pod no longer exists.
Health check configuration: More sensitive health check thresholds mitigate the duration of 503 errors as it can signal the load balancer to stop sending requests to endpoints even if the detach operation has not finished.
Termination grace period: The termination grace period determines the maximum amount of time a Pod is given to exit. However, a Pod can exit before the termination grace period completes. If a Pod takes longer than this period, the Pod is forced to exit at the end of this period. This is a setting on the Pod and needs to be configured in the workload definition.
Potential resolution:
To prevent those 5XX errors, apply the following settings. The timeout values are suggestive and you might need to adjust them for your specific application. The following section guides you through the customization process.
The following image displays how to keep the Pod alive with a preStop hook:
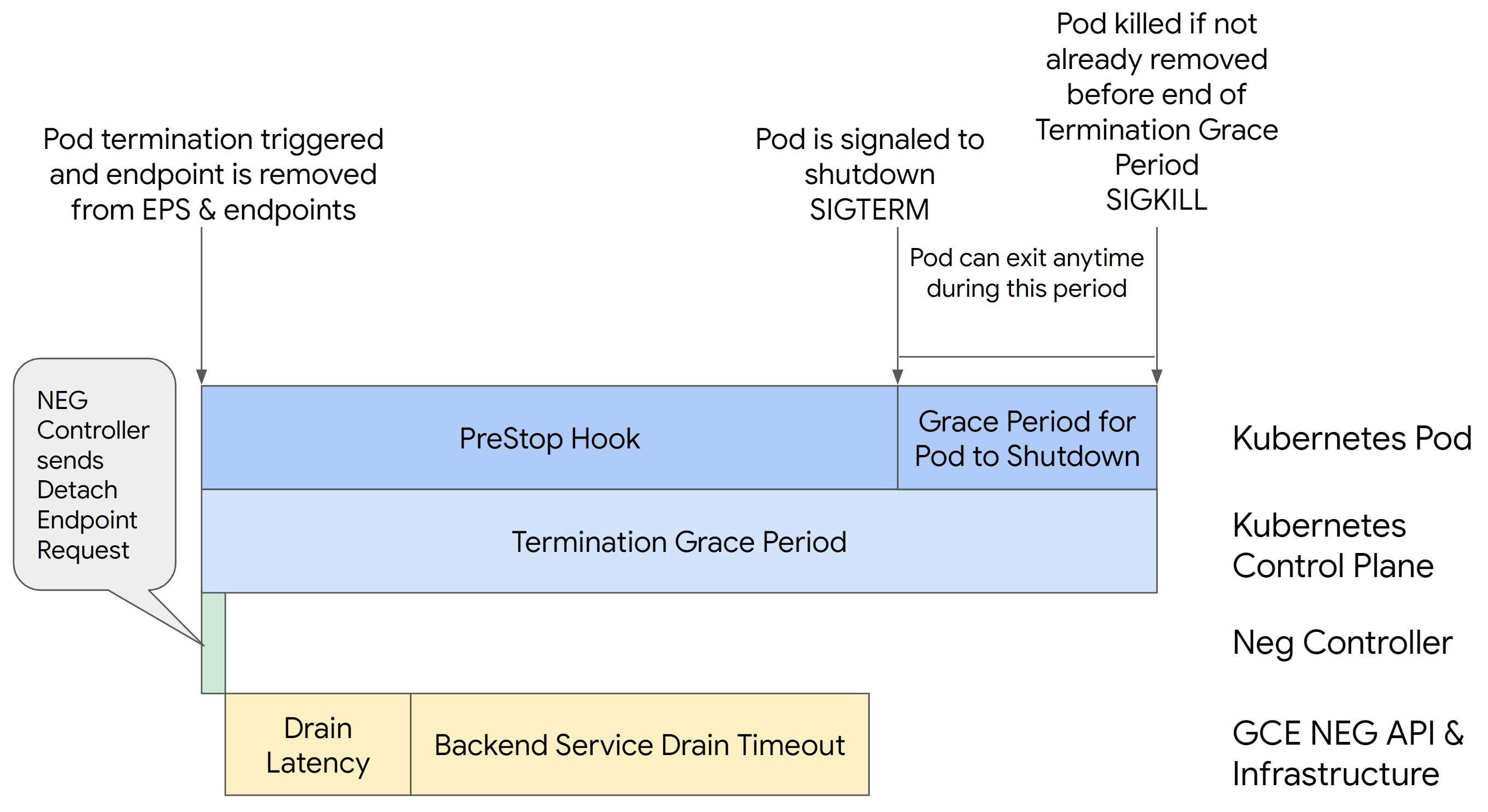
To avoid 500 series errors, perform the following steps:
Set the
BackendService Drain Timeoutfor your service to 1 minute.For Ingress Users, see set the timeout on the BackendConfig.
For Gateway Users, see configure the timeout on the GCPBackendPolicy.
For those managing their BackendServices directly when using Standalone NEGs, see set the timeout directly on the Backend Service.
Extend the
terminationGracePeriodon the Pod.Set the
terminationGracePeriodSecondson the Pod to 3.5 minutes. When combined with the recommended settings, this allows your Pods a 30 to 45 second window for a graceful shutdown after the Pod's endpoint has been removed from the NEG. If you require more time for the graceful shutdown, you can extend the grace period or follow the instructions mentioned in the Customize timeouts section.The following Pod manifest specifies a connection draining timeout of 210 seconds (3.5 minutes):
spec: terminationGracePeriodSeconds: 210 containers: - name: my-app ... ...Apply a
preStophook to all containers.Apply a
preStophook that will ensure the Pod is alive for 120 seconds longer while the Pod's endpoint is drained in the load balancer and the endpoint is removed from the NEG.spec: containers: - name: my-app ... lifecycle: preStop: exec: command: ["/bin/sh", "-c", "sleep 120s"] ...
Customize timeouts
To ensure Pod continuity and prevent 500 series errors, the Pod must be alive
until the endpoint is removed from the NEG. Specifically to prevent 502 and 503
errors, consider implementing a combination of timeouts and a preStop hook.
To keep the Pod alive longer during the shutdown process, add a preStop hook
to the Pod. Run the preStop hook before a Pod is signaled to exit, so the
preStop hook can be used to keep the Pod alive until its corresponding
endpoint is removed from the NEG.
To extend the duration that a Pod remains active during the shutdown process,
insert a preStop hook into the Pod configuration as follows:
spec:
containers:
- name: my-app
...
lifecycle:
preStop:
exec:
command: ["/bin/sh", "-c", "sleep <latency time>"]
You can configure timeouts and related settings to manage the graceful shutdown
of Pods during workload scale downs. You can adjust timeouts based on specific
use cases. We recommend that you start with longer timeouts and reduce the
duration as necessary. You can customize the timeouts by configuring
timeout-related parameters and the preStop hook in the following ways:
Backend Service Drain Timeout
The Backend Service Drain Timeout parameter is unset by default and has no
effect. If you set the Backend Service Drain Timeout parameter and activate
it, the load balancer stops routing new requests to the endpoint and waits
the timeout before terminating existing connections.
You can set the Backend Service Drain Timeout parameter by using the
BackendConfig with Ingress, the GCPBackendPolicy with Gateway or manually on
the BackendService with standalone NEGs. The timeout should be 1.5 to 2 times
longer than the time it takes to process a request. This ensures if a request
came in right before the drain was initiated, it will complete before the
timeout completes. Setting the Backend Service Drain Timeout parameter to a
value greater than 0 helps mitigate 503 errors because no new requests are sent
to endpoints scheduled for removal. For this timeout to be effective, you must
use it with the preStop hook to ensure that the Pod remains
active while the drain occurs. Without this combination, existing requests that
didn't complete will receive a 502 error.
preStop hook time
The preStop hook must delay Pod shut down sufficiently for both drain
latency and backend service drain timeout to complete, ensuring proper
connection drainage and endpoint removal from the NEG before the Pod is shut
down.
For optimal results, ensure your preStop hook execution time is greater than
or equal to the sum of the Backend Service Drain Timeout and drain latency.
Calculate your ideal preStop hook execution time with the following formula:
preStop hook execution time >= BACKEND_SERVICE_DRAIN_TIMEOUT + DRAIN_LATENCY
Replace the following:
BACKEND_SERVICE_DRAIN_TIMEOUT: the time that you configured for theBackend Service Drain Timeout.DRAIN_LATENCY: an estimated time for drain latency. We recommend that you use one minute as your estimate.
If 500 errors persist, estimate the total occurrence duration and add double that time to the estimated drain latency. This ensures that your Pod has enough time to drain gracefully before being removed from the service. You can adjust this value if it's too long for your specific use case.
Alternatively, you can estimate the timing by examining the deletion timestamp from the Pod and the timestamp when the endpoint was removed from the NEG in the Cloud Audit Logs.
Termination Grace Period parameter
You must configure the terminationGracePeriod parameter to allow sufficient
time for the preStop hook to finish and for the Pod to complete a graceful
shutdown.
By default, when not explicitly set, the terminationGracePeriod is 30 seconds.
You can calculate the optimal terminationGracePeriod using the formula:
terminationGracePeriod >= preStop hook time + Pod shutdown time
To define terminationGracePeriod within the Pod's configuration as follows:
spec:
terminationGracePeriodSeconds: <terminationGracePeriod>
containers:
- name: my-app
...
...
NEG not found when creating an Internal Ingress resource
The following error might occur when you create an internal Ingress in GKE:
Error syncing: error running backend syncing routine: googleapi: Error 404: The resource 'projects/PROJECT_ID/zones/ZONE/networkEndpointGroups/NEG' was not found, notFound
This error occurs because Ingress for internal Application Load Balancers requires Network Endpoint Groups (NEGs) as backends.
In Shared VPC environments or clusters with Network Policies enabled,
add the annotation cloud.google.com/neg: '{"ingress": true}' to the Service
manifest.
504 Gateway Timeout: upstream request timeout
The following error might occur when you access a Service from an internal Ingress in GKE:
HTTP/1.1 504 Gateway Timeout
content-length: 24
content-type: text/plain
upsteam request timeout
This error occurs because traffic sent to internal Application Load Balancers are proxied by envoy proxies in the proxy-only subnet range.
To allow traffic from the proxy-only subnet range,
create a firewall rule
on the targetPort of the Service.
Error 400: Invalid value for field 'resource.target'
The following error might occur when you access a Service from an internal Ingress in GKE:
Error syncing:LB_NAME does not exist: googleapi: Error 400: Invalid value for field 'resource.target': 'https://www.googleapis.com/compute/v1/projects/PROJECT_NAME/regions/REGION_NAME/targetHttpProxies/LB_NAME. A reserved and active subnetwork is required in the same region and VPC as the forwarding rule.
To resolve this issue, create a proxy-only subnet.
Error during sync: error running load balancer syncing routine: loadbalancer does not exist
One of the following errors might occur when the GKE control plane upgrades or when you modify an Ingress object:
"Error during sync: error running load balancer syncing routine: loadbalancer
INGRESS_NAME does not exist: invalid ingress frontend configuration, please
check your usage of the 'kubernetes.io/ingress.allow-http' annotation."
Or:
Error during sync: error running load balancer syncing routine: loadbalancer LOAD_BALANCER_NAME does not exist:
googleapi: Error 400: Invalid value for field 'resource.IPAddress':'INGRESS_VIP'. Specified IP address is in-use and would result in a conflict., invalid
To resolve these issues, try the following steps:
- Add the
hostsfield in thetlssection of the Ingress manifest, then delete the Ingress. Wait five minutes for GKE to delete the unused Ingress resources. Then, recreate the Ingress. For more information, see The hosts field of an Ingress object. - Revert the changes you made to the Ingress. Then, add a certificate using an annotation or Kubernetes Secret.
Known issues
Cannot enable HTTPS Redirects with the V1 Ingress naming scheme
You cannot enable HTTPS redirects on GKE Ingress resources created on GKE versions 1.16.8-gke.12 and earlier. You must recreate the Ingress before you can enable HTTPS redirects, or an error event is created and the Ingress does not sync.
The error event message is similar to the following:
Error syncing: error running load balancer syncing routine: loadbalancer lb-name does not exist: ensureRedirectUrlMap() = error: cannot enable HTTPS Redirects with the V1 Ingress naming scheme. Please recreate your ingress to use the newest naming scheme.
Google Cloud Armor security policy fields removed from BackendConfig
There is a known issue where updating a BackendConfig resource using the v1beta1
API removes an active Cloud Armor security policy from its Service.
This issue affects the following GKE versions:
- 1.18.19-gke.1400 to 1.18.20-gke.5099
- 1.19.10-gke.700 to 1.19.14-gke.299
- 1.20.6-gke.700 to 1.20.9-gke.899
If you do not configure Cloud Armor on your Ingress resources via the BackendConfig then this issue does not affect your clusters.
For GKE clusters which do configure Cloud Armor through
the BackendConfig, it is strongly recommended to only update BackendConfig resources using the
v1 API. Applying a BackendConfig to your cluster using v1beta1
BackendConfig resources will remove your Cloud Armor security policy
from the Service it is referencing.
To mitigate this issue, only make updates to your BackendConfig using the v1
BackendConfig API. The v1 BackendConfig supports all the same fields as v1beta1
and makes no breaking changes so the API field can be updated transparently.
Replace the apiVersion field of any active BackendConfig
manifests with cloud.google.com/v1 and do not use cloud.google.com/v1beta1.
The following sample manifest describes a BackendConfig resource that uses the v1
API:
apiVersion: cloud.google.com/v1
kind: BackendConfig
metadata:
name: my-backend-config
spec:
securityPolicy:
name: "ca-how-to-security-policy"
If you have CI/CD systems or tools which regularly update BackendConfig
resources, ensure that you are using the cloud.google.com/v1 API group in
those systems.
If your BackendConfig has already been updated with the v1beta1 API,
your Cloud Armor security policy might have been removed.
You can determine if this has happened by running the following command:
kubectl get backendconfigs -A -o json | jq -r '.items[] | select(.spec.securityPolicy == {}) | .metadata | "\(.namespace)/\(.name)"'
If the response returns output, then your cluster is impacted by the issue.
The output of this command returns a list of BackendConfig resources
(<namespace>/<name>) that are affected by the issue. If the output is empty,
then your BackendConfig has not been updated using the v1beta1 API since the
issue has been introduced. Any future updates to your BackendConfig should only
use v1.
If your Cloud Armor security policy was removed, you can determine when it was removed using the following Logging query:
resource.type="gce_backend_service"
protoPayload.methodName="v1.compute.backendServices.setSecurityPolicy"
protoPayload.authenticationInfo.principalEmail:"container-engine-robot.iam.gserviceaccount.com"
protoPayload.response.status = "RUNNING"
NOT protoPayload.authorizationInfo.permission:"compute.securityPolicies.use"
If any of your clusters have been impacted, then this can be corrected by pushing
an update to your BackendConfig resource that uses the v1 API.
Upgrade your GKE control plane
to one of the following updated versions that patches this issue and allows
v1beta1 BackendConfig resources to be used safely:
- 1.18.20-gke.5100 and later
- 1.19.14-gke.300 and later
- 1.20.9-gke.900 and later