本頁說明如何執行漸進式推出作業,逐步部署 GKE Inference Gateway 的新版推論基礎架構。這個閘道可讓您安全地控制推論基礎架構的更新作業。您可以更新節點、基礎模型和 LoRA 配接器,盡量減少服務中斷。本頁面也提供流量分配和回溯的指南,確保部署作業穩定可靠。
本頁適用於 GKE 身分和帳戶管理員,以及想要為 GKE Inference Gateway 執行推出作業的開發人員。
支援的用途如下:
更新節點推出作業
節點更新會安全地將推論工作負載遷移至新的節點硬體或加速器設定。這個程序會以受控方式進行,不會中斷模型服務。在硬體升級、驅動程式更新或解決安全性問題時,使用節點更新功能,盡量減少服務中斷時間。
建立新的
InferencePool:部署以更新節點或硬體規格設定的InferencePool。使用
HTTPRoute分配流量:設定HTTPRoute,在現有和新的InferencePool資源之間分配流量。使用backendRefs中的weight欄位,管理導向新節點的流量百分比。維持一致的
InferenceObjective:保留現有的InferenceObjective設定,確保兩個節點設定的模型行為一致。保留原始資源:在推出期間保持原始
InferencePool和節點處於啟用狀態,以便在需要時進行回溯。
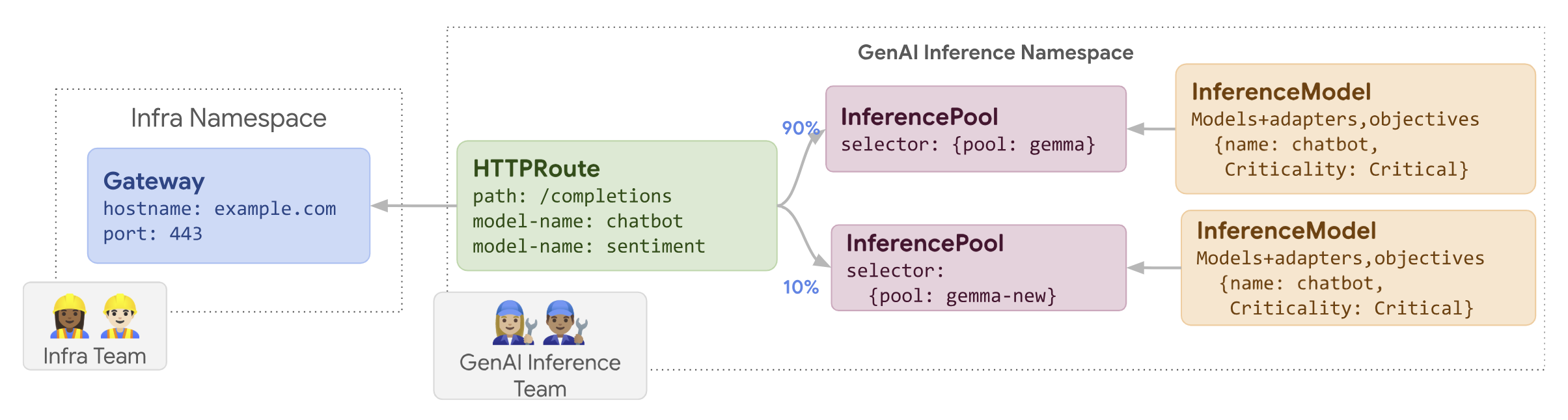
舉例來說,您可以建立名為 llm-new 的新 InferencePool。設定這個集區時,請使用與現有 llm
InferencePool 相同的模型設定。在叢集內的新節點集區上部署集區。使用 HTTPRoute 物件在原始 llm 和新 llm-new InferencePool 之間分配流量。這項技術可讓您逐步更新模型節點。
下圖說明 GKE Inference Gateway 如何執行節點更新推出作業。
如要推出節點更新,請按照下列步驟操作:
將下列範例資訊清單儲存為
routes-to-llm.yaml:apiVersion: gateway.networking.k8s.io/v1 kind: HTTPRoute metadata: name: routes-to-llm spec: parentRefs: - name: my-inference-gateway group: inference.networking.k8s.io kind: InferenceGateway rules: backendRefs: - name: llm group: inference.networking.k8s.io kind: InferencePool weight: 90 - name: llm-new group: inference.networking.k8s.io kind: InferencePool weight: 10將範例資訊清單套用至叢集:
kubectl apply -f routes-to-llm.yaml
原始 llm InferencePool 獲得大部分流量,其餘流量則會導向 llm-new InferencePool。逐步增加 llm-new InferencePool 的流量權重,完成節點更新發布作業。
推出基礎模型
基礎模型更新會分階段推出,採用新的基礎 LLM,同時保留與現有 LoRA 轉接程式的相容性。您可以透過推出基礎模型更新,升級至改良的模型架構,或解決模型專屬問題。
如要推出基礎模型更新:
- 部署新基礎架構:建立新節點和新
InferencePool,並使用您選擇的新基礎模型進行設定。 - 設定流量分配:使用
HTTPRoute在現有InferencePool(使用舊基礎模型) 和新InferencePool(使用新基礎模型) 之間分配流量。backendRefs weight欄位可控制分配給每個集區的流量百分比。 - 維持
InferenceObjective完整性:保持InferenceObjective設定不變。這可確保系統在兩個基礎模型版本中,都一致套用相同的 LoRA 配接器。 - 保留回溯功能:在推出期間保留原始節點和
InferencePool,以便在必要時回溯。
您建立名為 llm-pool-version-2 的新 InferencePool。這個集區會在新的節點集上部署新版基礎模型。如提供的範例所示,設定 HTTPRoute 後,您就能逐步將流量分配給原始 llm-pool 和 llm-pool-version-2。這可讓您控管叢集中的基礎模型更新。
如要推出基礎模型更新,請按照下列步驟操作:
將下列範例資訊清單儲存為
routes-to-llm.yaml:apiVersion: gateway.networking.k8s.io/v1 kind: HTTPRoute metadata: name: routes-to-llm spec: parentRefs: - name: my-inference-gateway group: inference.networking.k8s.io kind: InferenceGateway rules: backendRefs: - name: llm-pool group: inference.networking.k8s.io kind: InferencePool weight: 90 - name: llm-pool-version-2 group: inference.networking.k8s.io kind: InferencePool weight: 10將範例資訊清單套用至叢集:
kubectl apply -f routes-to-llm.yaml
原始 llm-pool InferencePool 獲得大部分流量,其餘流量則會導向 llm-pool-version-2 InferencePool。逐步增加 llm-pool-version-2 InferencePool 的流量權重,完成基礎模型更新推出作業。