Questa pagina mostra come eseguire operazioni di implementazione incrementale, che distribuiscono gradualmente nuove versioni dell'infrastruttura di inferenza per GKE Inference Gateway. Questo gateway ti consente di eseguire aggiornamenti sicuri e controllati alla tua infrastruttura di inferenza. Puoi aggiornare nodi, modelli di base e adattatori LoRA con interruzioni minime del servizio. Questa pagina fornisce anche indicazioni sulla suddivisione del traffico e sui rollback per garantire implementazioni affidabili.
Questa pagina è rivolta agli amministratori di identità e account GKE e agli sviluppatori che vogliono eseguire operazioni di implementazione per GKE Inference Gateway.
Sono supportati i seguenti casi d'uso:
- Implementazione dell'aggiornamento dei nodi (di calcolo, acceleratore)
- Implementazione dell'aggiornamento del modello di base
Aggiorna l'implementazione di un nodo
Gli aggiornamenti dei nodi eseguono la migrazione sicura dei carichi di lavoro di inferenza a nuove configurazioni hardware dei nodi o degli acceleratori. Questo processo avviene in modo controllato senza interrompere il servizio del modello. Utilizza gli aggiornamenti dei nodi per ridurre al minimo l'interruzione del servizio durante gli upgrade hardware, gli aggiornamenti dei driver o la risoluzione dei problemi di sicurezza.
Crea un nuovo
InferencePool: esegui il deployment di unInferencePoolconfigurato con le specifiche aggiornate del nodo o dell'hardware.Dividi il traffico utilizzando un
HTTPRoute: configura unHTTPRouteper distribuire il traffico tra le risorseInferencePoolesistenti e quelle nuove. Utilizza il campoweightinbackendRefsper gestire la percentuale di traffico indirizzata ai nuovi nodi.Mantieni un
InferenceObjectivecoerente: conserva la configurazioneInferenceObjectiveesistente per garantire un comportamento uniforme del modello in entrambe le configurazioni dei nodi.Mantieni le risorse originali: mantieni attivi i nodi e
InferencePooloriginali durante l'implementazione per consentire i rollback, se necessario.
Ad esempio, puoi creare un nuovo InferencePool denominato llm-new. Configura
questo pool con la stessa configurazione del modello del tuo llm
InferencePool esistente. Esegui il deployment del pool su un nuovo insieme di nodi all'interno del cluster. Utilizza
un oggetto HTTPRoute per dividere il traffico tra l'llm originale e il nuovo
llm-new InferencePool. Questa tecnica ti consente di aggiornare in modo incrementale i nodi del modello.
Il seguente diagramma illustra come GKE Inference Gateway esegue il roll-out di un aggiornamento dei nodi.
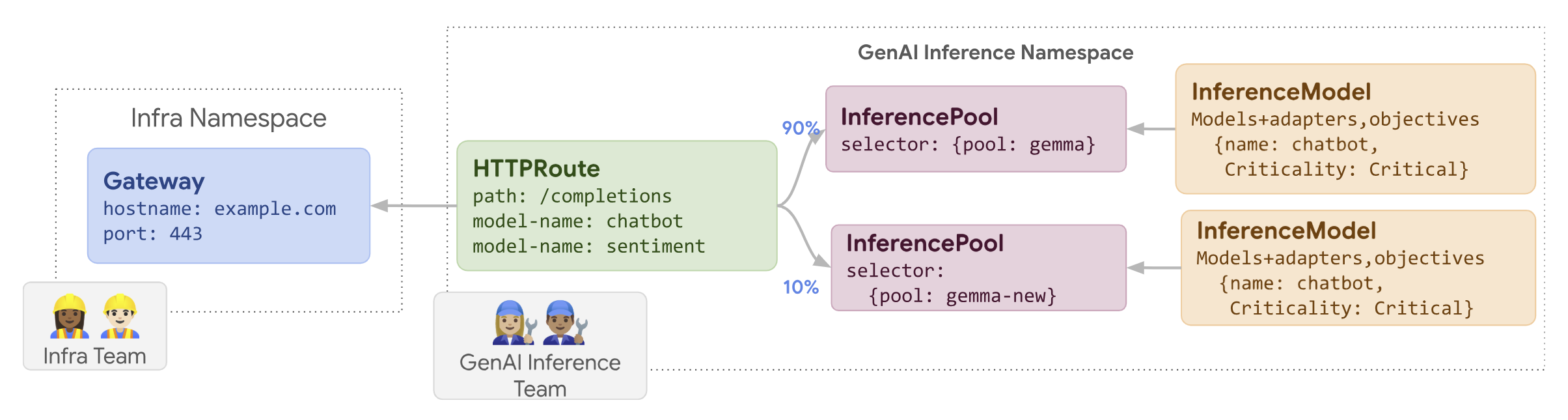
Per eseguire l'implementazione di un aggiornamento dei nodi:
Salva il seguente manifest di esempio come
routes-to-llm.yaml:apiVersion: gateway.networking.k8s.io/v1 kind: HTTPRoute metadata: name: routes-to-llm spec: parentRefs: - name: my-inference-gateway group: inference.networking.k8s.io kind: InferenceGateway rules: backendRefs: - name: llm group: inference.networking.k8s.io kind: InferencePool weight: 90 - name: llm-new group: inference.networking.k8s.io kind: InferencePool weight: 10Applica il manifest di esempio al cluster:
kubectl apply -f routes-to-llm.yaml
L'llm originale InferencePool riceve la maggior parte del traffico, mentre
l'llm-new InferencePool riceve il resto. Aumenta gradualmente il peso del traffico
per llm-new InferencePool per completare l'implementazione dell'aggiornamento del nodo.
Implementare un modello di base
Gli aggiornamenti del modello di base vengono implementati in fasi in un nuovo LLM di base, mantenendo la compatibilità con gli adattatori LoRA esistenti. Puoi utilizzare i rollout degli aggiornamenti del modello di base per eseguire l'upgrade a architetture di modelli migliorate o per risolvere problemi specifici del modello.
Per implementare un aggiornamento del modello di base:
- Deploy new infrastructure (Esegui il deployment di una nuova infrastruttura): crea nuovi nodi e un nuovo
InferencePoolconfigurato con il nuovo modello di base che hai scelto. - Configura la distribuzione del traffico: utilizza un
HTTPRouteper dividere il traffico tra l'InferencePoolesistente (che utilizza il vecchio modello di base) e il nuovoInferencePool(che utilizza il nuovo modello di base). Il campobackendRefs weightcontrolla la percentuale di traffico allocata a ogni pool. - Mantenere l'integrità di
InferenceObjective: mantieni invariata la configurazione diInferenceObjective. In questo modo, il sistema applica gli stessi adattatori LoRA in modo coerente in entrambe le versioni del modello di base. - Preserva la funzionalità di rollback: mantieni i nodi originali e
InferencePooldurante l'implementazione per facilitare un rollback, se necessario.
Crea un nuovo InferencePool denominato llm-pool-version-2. Questo pool esegue il deployment
di una nuova versione del modello di base su un nuovo insieme di nodi. Configurando un HTTPRoute, come mostrato nell'esempio fornito, puoi dividere gradualmente il traffico tra l'llm-pool originale e llm-pool-version-2. In questo modo puoi controllare gli aggiornamenti del modello di base nel tuo
cluster.
Per eseguire l'implementazione di un aggiornamento del modello di base:
Salva il seguente manifest di esempio come
routes-to-llm.yaml:apiVersion: gateway.networking.k8s.io/v1 kind: HTTPRoute metadata: name: routes-to-llm spec: parentRefs: - name: my-inference-gateway group: inference.networking.k8s.io kind: InferenceGateway rules: backendRefs: - name: llm-pool group: inference.networking.k8s.io kind: InferencePool weight: 90 - name: llm-pool-version-2 group: inference.networking.k8s.io kind: InferencePool weight: 10Applica il manifest di esempio al cluster:
kubectl apply -f routes-to-llm.yaml
L'llm-pool originale InferencePool riceve la maggior parte del traffico, mentre
l'llm-pool-version-2 InferencePool riceve il resto. Aumenta gradualmente il peso del traffico per llm-pool-version-2 InferencePool per completare l'implementazione dell'aggiornamento del modello di base.