Esta página descreve como personalizar a implementação do GKE Inference Gateway.
Esta página destina-se a especialistas em redes responsáveis pela gestão da infraestrutura do GKE e a administradores da plataforma que gerem cargas de trabalho de IA.
Para gerir e otimizar cargas de trabalho de inferência, configure funcionalidades avançadas do GKE Inference Gateway.
Compreenda e configure as seguintes funcionalidades avançadas:
- Para usar a integração do Model Armor, configure verificações de segurança e proteção da IA.
- Para melhorar o GKE Inference Gateway com funcionalidades como segurança da API, limitação de taxa e estatísticas, configure o Apigee para autenticação e gestão de APIs.
- Para encaminhar pedidos com base no nome do modelo no corpo do pedido, configure o encaminhamento com base no corpo.
- Para ver métricas e painéis de controlo para o GKE Inference Gateway e os servidores de modelos, e para ativar o registo de acesso HTTP, configure a observabilidade.
- Para dimensionar automaticamente as implementações do GKE Inference Gateway, configure a escala automática.
Configure verificações de segurança e proteção de IA
O GKE Inference Gateway integra-se com o Model Armor para realizar verificações de segurança em comandos e respostas para aplicações que usam grandes modelos de linguagem (GMLs). Esta integração oferece uma camada adicional de aplicação de segurança ao nível da infraestrutura que complementa as medidas de segurança ao nível da aplicação. Isto permite a aplicação de políticas centralizada em todo o tráfego de MDIs.
O diagrama seguinte ilustra a integração do Model Armor com o GKE Inference Gateway num cluster do GKE:
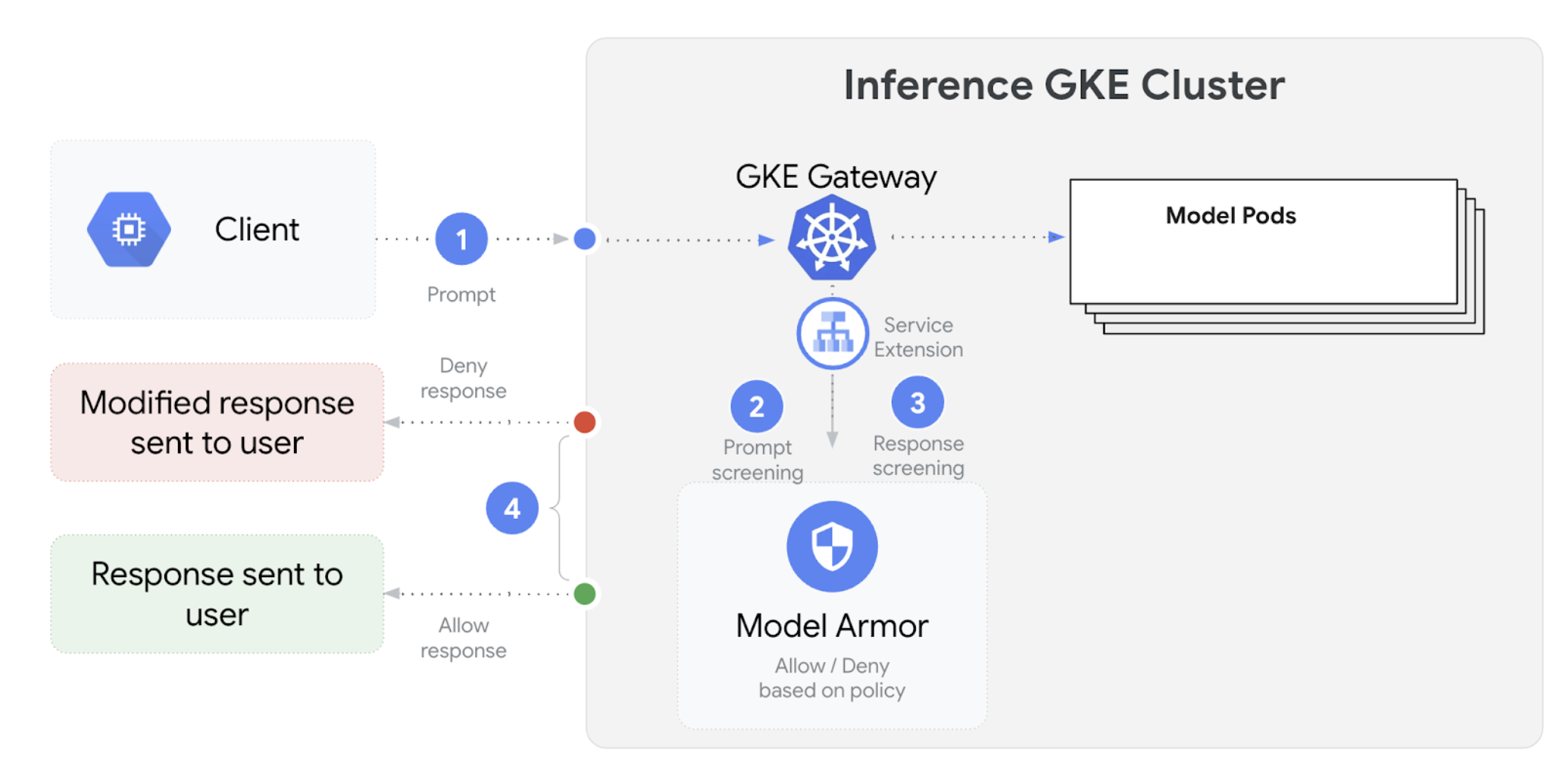
Para configurar as verificações de segurança da IA, siga estes passos:
Pré-requisitos
- Ative o serviço Model Armor no seu Google Cloud projeto.
Crie os modelos do Model Armor através da consola do Model Armor, da CLI gcloud ou da API. O comando seguinte cria um modelo denominado
llmque regista operações e filtra conteúdo prejudicial.# Set environment variables PROJECT_ID=$(gcloud config get-value project) # Replace <var>CLUSTER_LOCATION<var> with the location of your GKE cluster. For example, `us-central1`. LOCATION="CLUSTER_LOCATION" MODEL_ARMOR_TEMPLATE_NAME=llm # Set the regional API endpoint gcloud config set api_endpoint_overrides/modelarmor \ "https://modelarmor.$LOCATION.rep.googleapis.com/" # Create the template gcloud model-armor templates create $MODEL_ARMOR_TEMPLATE_NAME \ --location $LOCATION \ --pi-and-jailbreak-filter-settings-enforcement=enabled \ --pi-and-jailbreak-filter-settings-confidence-level=MEDIUM_AND_ABOVE \ --rai-settings-filters='[{ "filterType": "HATE_SPEECH", "confidenceLevel": "MEDIUM_AND_ABOVE" },{ "filterType": "DANGEROUS", "confidenceLevel": "MEDIUM_AND_ABOVE" },{ "filterType": "HARASSMENT", "confidenceLevel": "MEDIUM_AND_ABOVE" },{ "filterType": "SEXUALLY_EXPLICIT", "confidenceLevel": "MEDIUM_AND_ABOVE" }]' \ --template-metadata-log-sanitize-operations \ --template-metadata-log-operations
Conceda autorizações de IAM
A conta de serviço das extensões de serviços requer autorizações para aceder aos recursos necessários. Conceda as funções necessárias executando os seguintes comandos:
PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format 'get(projectNumber)') gcloud projects add-iam-policy-binding $PROJECT_ID \ --member=serviceAccount:service-$PROJECT_NUMBER@gcp-sa-dep.iam.gserviceaccount.com \ --role=roles/container.admin gcloud projects add-iam-policy-binding $PROJECT_ID \ --member=serviceAccount:service-$PROJECT_NUMBER@gcp-sa-dep.iam.gserviceaccount.com \ --role=roles/modelarmor.calloutUser gcloud projects add-iam-policy-binding $PROJECT_ID \ --member=serviceAccount:service-$PROJECT_NUMBER@gcp-sa-dep.iam.gserviceaccount.com \ --role=roles/serviceusage.serviceUsageConsumer gcloud projects add-iam-policy-binding $PROJECT_ID \ --member=serviceAccount:service-$PROJECT_NUMBER@gcp-sa-dep.iam.gserviceaccount.com \ --role=roles/modelarmor.userConfigure o
GCPTrafficExtensionPara aplicar as políticas do Model Armor ao seu Gateway, crie um recurso
GCPTrafficExtensioncom o formato de metadados correto.Guarde o seguinte manifesto de exemplo como
gcp-traffic-extension.yaml:kind: GCPTrafficExtension apiVersion: networking.gke.io/v1 metadata: name: my-model-armor-extension spec: targetRefs: - group: "gateway.networking.k8s.io" kind: Gateway name: GATEWAY_NAME extensionChains: - name: my-model-armor-chain1 matchCondition: celExpressions: - celMatcher: request.path.startsWith("/") extensions: - name: my-model-armor-service supportedEvents: - RequestHeaders - RequestBody - RequestTrailers - ResponseHeaders - ResponseBody - ResponseTrailers timeout: 1s failOpen: false googleAPIServiceName: "modelarmor.${LOCATION}.rep.googleapis.com" metadata: model_armor_settings: '[{"model": "${MODEL}","model_response_template_id": "projects/${PROJECT_ID}/locations/${LOCATION}/templates/${MODEL_ARMOR_TEMPLATE_NAME}","user_prompt_template_id": "projects/${PROJECT_ID}/locations/${LOCATION}/templates/${MODEL_ARMOR_TEMPLATE_NAME}"}]'Substitua o seguinte:
GATEWAY_NAME: o nome do gateway.MODEL_ARMOR_TEMPLATE_NAME: o nome do seu modelo do Model Armor.
O ficheiro
gcp-traffic-extension.yamlinclui as seguintes definições:targetRefs: especifica o gateway ao qual esta extensão se aplica.extensionChains: define uma cadeia de extensões a aplicar ao tráfego.matchCondition: define as condições em que as extensões são aplicadas.extensions: define as extensões a aplicar.supportedEvents: especifica os eventos durante os quais a extensão é invocada.timeout: especifica o limite de tempo para a extensão.googleAPIServiceName: especifica o nome do serviço para a extensão.metadata: especifica os metadados da extensão, incluindo oextensionPolicye as definições de higienização de comandos ou respostas.
Aplique o manifesto de exemplo ao seu cluster:
export GATEWAY_NAME="your-gateway-name" export MODEL="google/gemma-3-1b-it" # Or your specific model envsubst < gcp-traffic-extension.yaml | kubectl apply -f -
Depois de configurar as verificações de segurança da IA e integrá-las na sua Gateway, o Model Armor filtra automaticamente os comandos e as respostas com base nas regras definidas.
Configure o Apigee para autenticação e gestão de APIs
O GKE Inference Gateway integra-se com o Apigee para fornecer autenticação, autorização e gestão de APIs para as suas cargas de trabalho de inferência. Para saber mais sobre as vantagens de usar o Apigee, consulte o artigo Principais vantagens de usar o Apigee.
Pode integrar o GKE Inference Gateway com o Apigee para melhorar o GKE Inference Gateway com funcionalidades como segurança da API, limites de taxa, quotas, estatísticas e rentabilização.
Pré-requisitos
Antes de começar, certifique-se de que tem o seguinte:
- Um cluster do GKE com a versão 1.34.* ou posterior.
- Um cluster do GKE com o GKE Inference Gateway implementado.
- Uma instância do Apigee criada na mesma região que o cluster do GKE.
- O operador da APIM da Apigee e os respetivos CRDs instalados no seu cluster do GKE. Para ver instruções, consulte o artigo Instale o operador da APIM da Apigee.
kubectlconfigurado para estabelecer ligação ao seu cluster do GKE.Google Cloud CLIinstalada e autenticada.
Crie um ApigeeBackendService
Primeiro, crie um recurso ApigeeBackendService. O GKE Inference Gateway usa isto para criar um Apigee Extension Processor.
Guarde o seguinte manifesto como
my-apigee-backend-service.yaml:apiVersion: apim.googleapis.com/v1 kind: ApigeeBackendService metadata: name: my-apigee-backend-service spec: apigeeEnv: "APIGEE_ENVIRONMENT_NAME" # optional field defaultSecurityEnabled: true # optional field locations: name: "LOCATION" network: "CLUSTER_NETWORK" subnetwork: "CLUSTER_SUBNETWORK"Substitua o seguinte:
APIGEE_ENVIRONMENT_NAME: o nome do seu ambiente do Apigee. Nota: não tem de definir este campo se oapigee-apim-operatorestiver instalado com a flaggenerateEnv=TRUE. Caso contrário, crie um ambiente do Apigee seguindo as instruções em Criar um ambiente.LOCATION: a localização da sua instância do Apigee.CLUSTER_NETWORK: a rede do seu cluster do GKE.CLUSTER_SUBNETWORK: a sub-rede do seu cluster do GKE.
Aplique o manifesto ao cluster:
kubectl apply -f my-apigee-backend-service.yamlVerifique se o estado passou a ser
CREATED:kubectl wait --for=jsonpath='{.status.currentState}'="CREATED" -f my-apigee-backend-service.yaml --timeout=5m
Configure o GKE Inference Gateway
Configure o GKE Inference Gateway para ativar o Apigee Extension Processor como uma extensão de tráfego do balanceador de carga.
Guarde o seguinte manifesto como
my-apigee-traffic-extension.yaml:kind: GCPTrafficExtension apiVersion: networking.gke.io/v1 metadata: name: my-apigee-traffic-extension spec: targetRefs: - group: "gateway.networking.k8s.io" kind: Gateway name: GATEWAY_NAME extensionChains: - name: my-traffic-extension-chain matchCondition: celExpressions: - celMatcher: request.path.startsWith("/") extensions: - name: my-apigee-extension metadata: # The value for `apigee-extension-processor` must match the name of the `ApigeeBackendService` resource that was applied earlier. apigee-extension-processor: my-apigee-backend-service failOpen: false timeout: 1s supportedEvents: - RequestHeaders - ResponseHeaders - ResponseBody backendRef: group: apim.googleapis.com kind: ApigeeBackendService name: my-apigee-backend-service port: 443Substitua
GATEWAY_NAMEpelo nome da sua gateway.Aplique o manifesto ao cluster:
kubectl apply -f my-apigee-traffic-extension.yamlAguarde até que o estado do
GCPTrafficExtensionsejaProgrammed:kubectl wait --for=jsonpath='{.status.ancestors[0].conditions[?(@.type=="Programmed")].status}'=True -f my-apigee-traffic-extension.yaml --timeout=5m
Envie pedidos autenticados através de chaves de API
Para encontrar o endereço IP da GKE Inference Gateway, inspecione o estado da gateway:
GW_IP=$(kubectl get gateway/GATEWAY_NAME -o jsonpath='{.status.addresses[0].value}')Substitua
GATEWAY_NAMEpelo nome da sua gateway.Testar um pedido sem autenticação. Este pedido deve ser rejeitado:
curl -i ${GW_IP}/v1/completions -H 'Content-Type: application/json' -d '{ "model": "food-review", "prompt": "Write as if you were a critic: San Francisco", "max_tokens": 100, "temperature": 0 }'Vai ver uma resposta semelhante à seguinte, que indica que a extensão do Apigee está a funcionar:
{"fault":{"faultstring":"Raising fault. Fault name : RF-insufficient-request-raise-fault","detail":{"errorcode":"steps.raisefault.RaiseFault"}}}Aceda à IU do Apigee e crie uma chave da API. Para ver instruções, consulte o artigo Crie uma chave de API.
Envie a chave da API no cabeçalho do pedido HTTP:
curl -i ${GW_IP}/v1/completions -H 'Content-Type: application/json' -H 'x-api-key: API_KEY' -d '{ "model": "food-review", "prompt": "Write as if you were a critic: San Francisco", "max_tokens": 100, "temperature": 0 }'Substitua
API_KEYpela sua chave da API.
Para obter informações mais detalhadas sobre a configuração de políticas do Apigee, consulte o artigo Use políticas de gestão de APIs com o operador Apigee APIM para Kubernetes.
Configure a observabilidade
O GKE Inference Gateway fornece estatísticas sobre o estado, o desempenho e o comportamento das suas cargas de trabalho de inferência. Isto ajuda a identificar e resolver problemas, otimizar a utilização de recursos e garantir a fiabilidade das suas aplicações.
OGoogle Cloud fornece os seguintes painéis de controlo do Cloud Monitoring que oferecem observabilidade de inferência para o GKE Inference Gateway:
- Painel de controlo do GKE Inference Gateway:
fornece métricas de ouro para o serviço de MDIs/CEs, como o débito de pedidos
e tokens, a latência, os erros e a utilização da cache para o
InferencePool. Para ver a lista completa de métricas do GKE Inference Gateway disponíveis, consulte Métricas expostas. - Painéis de controlo de observabilidade de IA/AA: fornece painéis de controlo para a utilização da infraestrutura, métricas DCGM e métricas de desempenho do modelo vLLM.
- Painel de controlo do servidor de modelos: oferece um painel de controlo para os sinais de ouro do servidor de modelos. Isto permite-lhe monitorizar a carga e o desempenho dos servidores de modelos, como
KVCache UtilizationeQueue length. - Painel de controlo do balanceador de carga: comunica métricas do balanceador de carga, como pedidos por segundo, latência de publicação de pedidos ponto a ponto e códigos de estado de pedido-resposta. Estas métricas ajudam a compreender o desempenho do serviço de pedidos ponto a ponto e a identificar erros.
- Métricas do Data Center GPU Manager (DCGM): fornece métricas do DCGM, como o desempenho e a utilização das GPUs NVIDIA. Pode configurar as métricas do DCGM no Cloud Monitoring. Para mais informações, consulte Recolha e veja métricas do DCGM.
Veja o painel de controlo do GKE Inference Gateway
Para ver o painel de controlo do GKE Inference Gateway, siga estes passos:
Na Google Cloud consola, aceda à página Monitorização.
No painel de navegação, selecione Painéis de controlo.
Na secção Integrações, selecione GMP.
Na página Modelos de painéis de controlo do Cloud Monitoring, pesquise "Gateway".
Veja o painel de controlo do GKE Inference Gateway.
Em alternativa, pode seguir as instruções no artigo Painel de controlo de monitorização.
Veja painéis de controlo de observabilidade de modelos de IA/ML
Para ver os modelos implementados e os painéis de controlo das métricas de observabilidade de um modelo, siga estes passos:
Na Google Cloud consola, aceda à página Modelos implementados.
Para ver detalhes sobre uma implementação específica, incluindo as respetivas métricas, registos e painéis de controlo, clique no nome do modelo na lista.
Na página de detalhes do modelo, clique no separador Observabilidade para ver os seguintes painéis de controlo. Se lhe for pedido, clique em Ativar para ativar o painel de controlo.
- O painel de controlo Utilização da infraestrutura apresenta métricas de utilização.
- O painel de controlo do DCGM apresenta métricas do DCGM.
- Se estiver a usar o vLLM, o painel de controlo Desempenho do modelo está disponível e apresenta métricas para o desempenho do modelo vLLM.
Configure o painel de controlo de observabilidade do servidor de modelos
Para recolher sinais de ouro de cada servidor de modelos e compreender o que contribui para o desempenho do GKE Inference Gateway, pode configurar a monitorização automática para os seus servidores de modelos. Isto inclui servidores de modelos como os seguintes:
Para ver os painéis de controlo de integração, certifique-se primeiro de que está a recolher métricas do servidor do modelo. Depois, siga estes passos:
Na Google Cloud consola, aceda à página Monitorização.
No painel de navegação, selecione Painéis de controlo.
Em Integrações, selecione GMP. São apresentados os painéis de controlo de integração correspondentes.
Figura: Painéis de controlo de integração
Para mais informações, consulte o artigo Personalize a monitorização de aplicações.
Configure os alertas do Cloud Monitoring
Para configurar alertas do Cloud Monitoring para o GKE Inference Gateway, siga os passos seguintes:
Guarde o seguinte manifesto de exemplo como
alerts.yamle modifique os limites conforme necessário:groups: - name: gateway-api-inference-extension rules: - alert: HighInferenceRequestLatencyP99 annotations: title: 'High latency (P99) for model {{ $labels.model_name }}' description: 'The 99th percentile request duration for model {{ $labels.model_name }} and target model {{ $labels.target_model_name }} has been consistently above 10.0 seconds for 5 minutes.' expr: histogram_quantile(0.99, rate(inference_model_request_duration_seconds_bucket[5m])) > 10.0 for: 5m labels: severity: 'warning' - alert: HighInferenceErrorRate annotations: title: 'High error rate for model {{ $labels.model_name }}' description: 'The error rate for model {{ $labels.model_name }} and target model {{ $labels.target_model_name }} has been consistently above 5% for 5 minutes.' expr: sum by (model_name) (rate(inference_model_request_error_total[5m])) / sum by (model_name) (rate(inference_model_request_total[5m])) > 0.05 for: 5m labels: severity: 'critical' impact: 'availability' - alert: HighInferencePoolAvgQueueSize annotations: title: 'High average queue size for inference pool {{ $labels.name }}' description: 'The average number of requests pending in the queue for inference pool {{ $labels.name }} has been consistently above 50 for 5 minutes.' expr: inference_pool_average_queue_size > 50 for: 5m labels: severity: 'critical' impact: 'performance' - alert: HighInferencePoolAvgKVCacheUtilization annotations: title: 'High KV cache utilization for inference pool {{ $labels.name }}' description: 'The average KV cache utilization for inference pool {{ $labels.name }} has been consistently above 90% for 5 minutes, indicating potential resource exhaustion.' expr: inference_pool_average_kv_cache_utilization > 0.9 for: 5m labels: severity: 'critical' impact: 'resource_exhaustion'Para criar políticas de alerta, execute o seguinte comando:
gcloud alpha monitoring policies migrate --policies-from-prometheus-alert-rules-yaml=alerts.yamlVê novas políticas de alerta na página de alertas.
Modifique os alertas
Pode encontrar a lista completa das métricas mais recentes disponíveis no repositório GitHub kubernetes-sigs/gateway-api-inference-extension e pode anexar novos alertas ao manifesto usando outras métricas.
Para modificar os alertas de exemplo, considere o seguinte exemplo:
- alert: HighInferenceRequestLatencyP99
annotations:
title: 'High latency (P99) for model {{ $labels.model_name }}'
description: 'The 99th percentile request duration for model {{ $labels.model_name }} and target model {{ $labels.target_model_name }} has been consistently above 10.0 seconds for 5 minutes.'
expr: histogram_quantile(0.99, rate(inference_model_request_duration_seconds_bucket[5m])) > 10.0
for: 5m
labels:
severity: 'warning'
Este alerta é acionado se o percentil 99 da duração do pedido durante 5 minutos exceder 10 segundos. Pode modificar a secção expr do alerta para ajustar o limite com base nos seus requisitos.
Configure o registo para o GKE Inference Gateway
A configuração do registo para o GKE Inference Gateway fornece informações detalhadas sobre pedidos e respostas, o que é útil para a resolução de problemas, a auditoria e a análise de desempenho. Os registos de acesso HTTP registam todos os pedidos e respostas, incluindo cabeçalhos, códigos de estado e datas/horas. Este nível de detalhe pode ajudar a identificar problemas, encontrar erros e compreender o comportamento das suas cargas de trabalho de inferência.
Para configurar o registo para o GKE Inference Gateway, ative o registo de acesso HTTP para cada um dos seus objetos InferencePool.
Guarde o seguinte manifesto de exemplo como
logging-backend-policy.yaml:apiVersion: networking.gke.io/v1 kind: GCPBackendPolicy metadata: name: logging-backend-policy namespace: NAMESPACE_NAME spec: default: logging: enabled: true sampleRate: 500000 targetRef: group: inference.networking.x-k8s.io kind: InferencePool name: INFERENCE_POOL_NAMESubstitua o seguinte:
NAMESPACE_NAME: o nome do espaço de nomes onde o seuInferencePoolestá implementado.INFERENCE_POOL_NAME: o nome doInferencePool.
Aplique o manifesto de exemplo ao seu cluster:
kubectl apply -f logging-backend-policy.yaml
Depois de aplicar este manifesto, o GKE Inference Gateway ativa os registos de acesso HTTP para o InferencePool especificado. Pode ver estes registos no
Cloud Logging. Os registos incluem informações detalhadas sobre cada pedido e resposta, como o URL do pedido, os cabeçalhos, o código de estado da resposta e a latência.
Crie métricas baseadas em registos para ver detalhes dos erros
Pode usar métricas baseadas em registos para analisar os registos de equilíbrio de carga e extrair detalhes de erros. Cada classe de gateway do GKE, como as classes de gateway gke-l7-global-external-managed e gke-l7-regional-internal-managed, é suportada por um equilibrador de carga diferente. Para mais
informações, consulte as capacidades da GatewayClass.
Cada equilibrador de carga tem um recurso monitorizado diferente que tem de usar quando cria uma métrica baseada em registos. Para mais informações acerca do recurso monitorizado para cada equilibrador de carga, consulte o seguinte:
- Para balanceadores de carga externos regionais: métricas baseadas em registos para balanceadores de carga HTTP(S) externos
- Para balanceadores de carga internos: métricas baseadas em registos para balanceadores de carga HTTP(S) internos
Para criar uma métrica baseada em registos para ver os detalhes dos erros, faça o seguinte:
Crie um ficheiro JSON denominado
error_detail_metric.jsoncom a seguinte definiçãoLogMetric. Esta configuração cria uma métrica que extrai o campoproxyStatusdos registos do equilibrador de carga.{ "description": "Metric to extract error details from load balancer logs.", "filter": "resource.type=\"MONITORED_RESOURCE\"", "metricDescriptor": { "metricKind": "DELTA", "valueType": "INT64", "labels": [ { "key": "error_detail", "valueType": "STRING", "description": "The detailed error string from the load balancer." } ] }, "labelExtractors": { "error_detail": "EXTRACT(jsonPayload.proxyStatus)" } }Substitua
MONITORED_RESOURCEpelo recurso monitorizado do seu balanceador de carga.Abra o Cloud Shell ou o terminal local onde a CLI gcloud está instalada.
Para criar a métrica, execute o comando
gcloud logging metrics createcom a flag--config-from-file:gcloud logging metrics create error_detail_metric \ --config-from-file=error_detail_metric.json
Depois de criar a métrica, pode usá-la no Cloud Monitoring para ver a distribuição de erros comunicados pelo balanceador de carga. Para mais informações, consulte o artigo Crie uma métrica baseada em registos.
Para mais informações sobre a criação de alertas a partir de métricas baseadas em registos, consulte o artigo Crie uma política de alertas numa métrica de contador.
Configure a escala automática
A criação de uma escala automática ajusta a atribuição de recursos em resposta às variações de carga,
mantendo o desempenho e a eficiência dos recursos através da adição ou
remoção dinâmica de pods com base na procura. Para o GKE Inference Gateway, isto envolve a
escala automática horizontal de pods em cada InferencePool. O redimensionador automático horizontal de pods (HPA) do GKE redimensiona automaticamente os pods com base nas métricas do servidor de modelos, como KVCache Utilization. Isto garante que o serviço de inferência processa diferentes cargas de trabalho e volumes de consultas, ao mesmo tempo que gere de forma eficiente a utilização de recursos.
Para configurar instâncias InferencePool para que tenham uma escala automática com base nas métricas produzidas pelo GKE Inference Gateway, siga estes passos:
Implemente um objeto
PodMonitoringno cluster para recolher métricas produzidas pelo GKE Inference Gateway. Para mais informações, consulte o artigo Configure a observabilidade.Implemente o adaptador do Stackdriver de métricas personalizadas para conceder ao HPA acesso às métricas:
Guarde o seguinte manifesto de exemplo como
adapter_new_resource_model.yaml:apiVersion: v1 kind: Namespace metadata: name: custom-metrics --- apiVersion: v1 kind: ServiceAccount metadata: name: custom-metrics-stackdriver-adapter namespace: custom-metrics --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: custom-metrics:system:auth-delegator roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: system:auth-delegator subjects: - kind: ServiceAccount name: custom-metrics-stackdriver-adapter namespace: custom-metrics --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: custom-metrics-auth-reader namespace: kube-system roleRef: apiGroup: rbac.authorization.k8s.io kind: Role name: extension-apiserver-authentication-reader subjects: - kind: ServiceAccount name: custom-metrics-stackdriver-adapter namespace: custom-metrics --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: custom-metrics-resource-reader namespace: custom-metrics rules: - apiGroups: - "" resources: - pods - nodes - nodes/stats verbs: - get - list - watch --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: custom-metrics-resource-reader roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: custom-metrics-resource-reader subjects: - kind: ServiceAccount name: custom-metrics-stackdriver-adapter namespace: custom-metrics --- apiVersion: apps/v1 kind: Deployment metadata: run: custom-metrics-stackdriver-adapter k8s-app: custom-metrics-stackdriver-adapter spec: replicas: 1 selector: matchLabels: run: custom-metrics-stackdriver-adapter k8s-app: custom-metrics-stackdriver-adapter template: metadata: labels: run: custom-metrics-stackdriver-adapter k8s-app: custom-metrics-stackdriver-adapter kubernetes.io/cluster-service: "true" spec: serviceAccountName: custom-metrics-stackdriver-adapter containers: - image: gcr.io/gke-release/custom-metrics-stackdriver-adapter:v0.15.2-gke.1 imagePullPolicy: Always name: pod-custom-metrics-stackdriver-adapter command: - /adapter - --use-new-resource-model=true - --fallback-for-container-metrics=true resources: limits: cpu: 250m memory: 200Mi requests: cpu: 250m memory: 200Mi --- apiVersion: v1 kind: Service metadata: labels: run: custom-metrics-stackdriver-adapter k8s-app: custom-metrics-stackdriver-adapter kubernetes.io/cluster-service: 'true' kubernetes.io/name: Adapter name: custom-metrics-stackdriver-adapter namespace: custom-metrics spec: ports: - port: 443 protocol: TCP targetPort: 443 selector: run: custom-metrics-stackdriver-adapter k8s-app: custom-metrics-stackdriver-adapter type: ClusterIP --- apiVersion: apiregistration.k8s.io/v1 kind: APIService metadata: name: v1beta1.custom.metrics.k8s.io spec: insecureSkipTLSVerify: true group: custom.metrics.k8s.io groupPriorityMinimum: 100 versionPriority: 100 service: name: custom-metrics-stackdriver-adapter namespace: custom-metrics version: v1beta1 --- apiVersion: apiregistration.k8s.io/v1 kind: APIService metadata: name: v1beta2.custom.metrics.k8s.io spec: insecureSkipTLSVerify: true group: custom.metrics.k8s.io groupPriorityMinimum: 100 versionPriority: 200 service: name: custom-metrics-stackdriver-adapter namespace: custom-metrics version: v1beta2 --- apiVersion: apiregistration.k8s.io/v1 kind: APIService metadata: name: v1beta1.external.metrics.k8s.io spec: insecureSkipTLSVerify: true group: external.metrics.k8s.io groupPriorityMinimum: 100 versionPriority: 100 service: name: custom-metrics-stackdriver-adapter namespace: custom-metrics version: v1beta1 --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: external-metrics-reader rules: - apiGroups: - "external.metrics.k8s.io" resources: - "*" verbs: - list - get - watch --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: external-metrics-reader roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: external-metrics-reader subjects: - kind: ServiceAccount name: horizontal-pod-autoscaler namespace: kube-systemAplique o manifesto de exemplo ao seu cluster:
kubectl apply -f adapter_new_resource_model.yaml
Para conceder autorizações ao adaptador para ler métricas do projeto, execute o seguinte comando:
$ PROJECT_ID=PROJECT_ID $ PROJECT_NUMBER=$(gcloud projects describe PROJECT_ID --format="value(projectNumber)") $ gcloud projects add-iam-policy-binding projects/PROJECT_ID \ --role roles/monitoring.viewer \ --member=principal://iam.googleapis.com/projects/PROJECT_NUMBER/locations/global/workloadIdentityPools/$PROJECT_ID.svc.id.goog/subject/ns/custom-metrics/sa/custom-metrics-stackdriver-adapterSubstitua
PROJECT_IDpelo ID do seu Google Cloud projeto.Para cada
InferencePool, implemente um HPA semelhante ao seguinte:apiVersion: autoscaling/v2 kind: HorizontalPodAutoscaler metadata: name: INFERENCE_POOL_NAME namespace: INFERENCE_POOL_NAMESPACE spec: scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: INFERENCE_POOL_NAME minReplicas: MIN_REPLICAS maxReplicas: MAX_REPLICAS metrics: - type: External external: metric: name: prometheus.googleapis.com|inference_pool_average_kv_cache_utilization|gauge selector: matchLabels: metric.labels.name: INFERENCE_POOL_NAME resource.labels.cluster: CLUSTER_NAME resource.labels.namespace: INFERENCE_POOL_NAMESPACE target: type: AverageValue averageValue: TARGET_VALUESubstitua o seguinte:
INFERENCE_POOL_NAME: o nome doInferencePool.INFERENCE_POOL_NAMESPACE: o espaço de nomes do elementoInferencePool.CLUSTER_NAME: o nome do cluster.MIN_REPLICAS: a disponibilidade mínima doInferencePool(capacidade de base). O HPA mantém este número de réplicas quando a utilização está abaixo do limite do objetivo do HPA. As cargas de trabalho de elevada disponibilidade têm de definir este valor como superior a1para garantir a disponibilidade contínua durante as interrupções de pods.MAX_REPLICAS: o valor que restringe o número de aceleradores que têm de ser atribuídos às cargas de trabalho alojadas noInferencePool. O HPA não aumenta o número de réplicas além deste valor. Durante os períodos de pico de tráfego, monitorize o número de réplicas para garantir que o valor do campoMAX_REPLICASoferece espaço suficiente para que a carga de trabalho possa ser dimensionada para manter as caraterísticas de desempenho da carga de trabalho escolhidas.TARGET_VALUE: o valor que representa o objetivo escolhidoKV-Cache Utilizationpor servidor de modelos. Este é um número entre 0 e 100 e depende muito do servidor de modelos, do modelo, do acelerador e das características do tráfego recebido. Pode determinar este valor alvo experimentalmente através de testes de carga e traçando um gráfico de débito versus latência. Selecione uma combinação de débito e latência escolhida no gráfico e use o valorKV-Cache Utilizationcorrespondente como o alvo do HPA. Tem de ajustar e monitorizar atentamente este valor para alcançar os resultados de desempenho/preço escolhidos. Pode usar o Início rápido da inferência do GKE para determinar este valor automaticamente.
O que se segue?
- Saiba mais sobre o GKE Inference Gateway.
- Implemente o GKE Inference Gateway.
- Faça a gestão das operações de implementação do GKE Inference Gateway.
- Faça a publicação com o GKE Inference Gateway.