En esta página se describe cómo personalizar la implementación de GKE Inference Gateway.
Esta página está dirigida a especialistas en redes responsables de gestionar la infraestructura de GKE y a administradores de plataformas que gestionan cargas de trabajo de IA.
Para gestionar y optimizar las cargas de trabajo de inferencia, configura las funciones avanzadas de GKE Inference Gateway.
Conocer y configurar las siguientes funciones avanzadas:
- Para usar la integración de Model Armor, configura comprobaciones de seguridad de la IA.
- Para ver las métricas y los paneles de control de GKE Inference Gateway y del servidor de modelos, y para habilitar el registro de acceso HTTP para obtener información detallada sobre las solicitudes y las respuestas, configura la observabilidad.
- Para escalar automáticamente tus implementaciones de GKE Inference Gateway, configura el autoescalado.
Configurar comprobaciones de seguridad de la IA
GKE Inference Gateway se integra con Model Armor para realizar comprobaciones de seguridad en las peticiones y respuestas de las aplicaciones que usan modelos de lenguaje extensos (LLMs). Esta integración proporciona una capa adicional de seguridad a nivel de infraestructura que complementa las medidas de seguridad a nivel de aplicación. De esta forma, se puede aplicar una política centralizada a todo el tráfico de LLMs.
En el siguiente diagrama se muestra la integración de Model Armor con GKE Inference Gateway en un clúster de GKE:
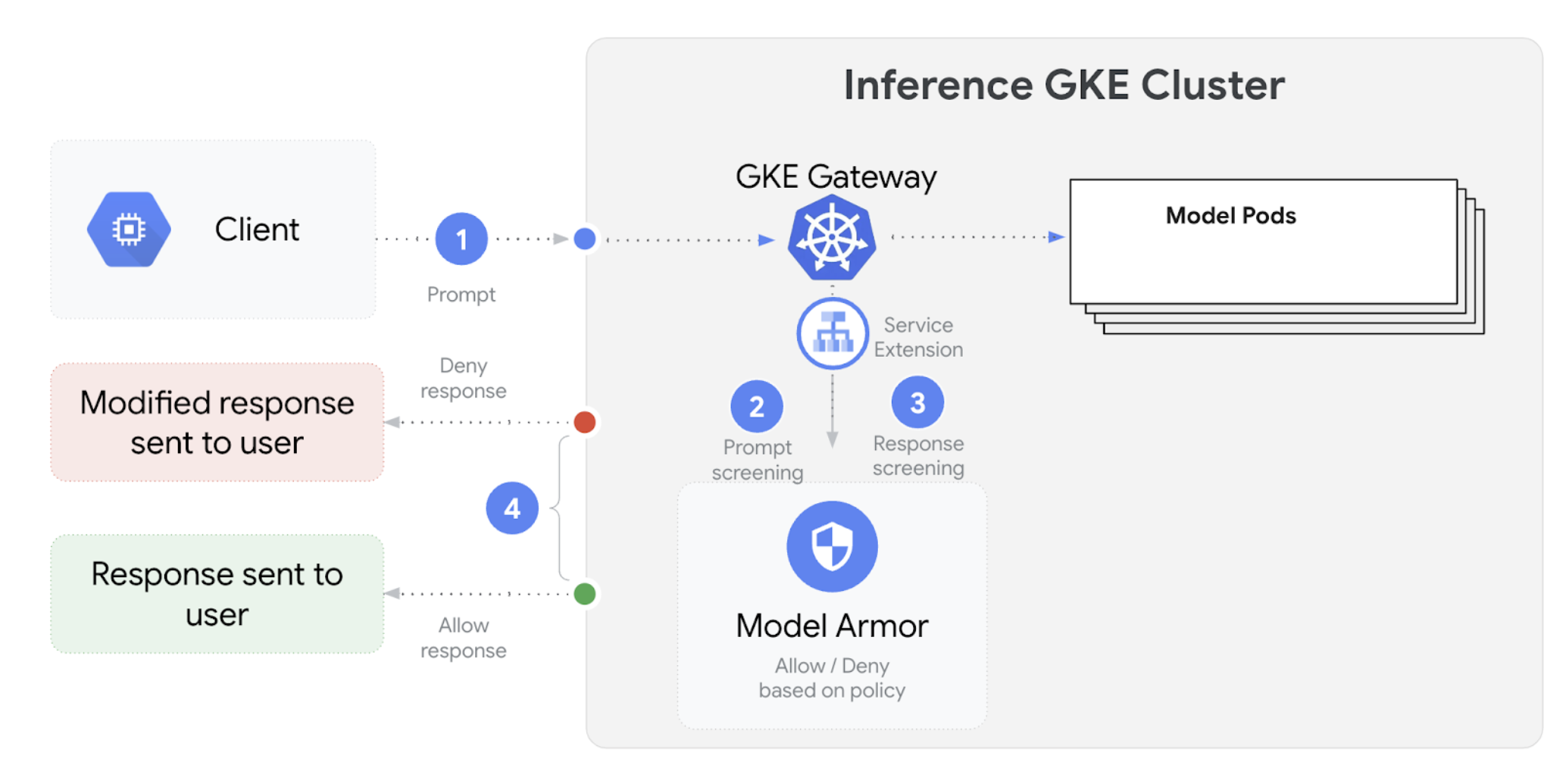
Para configurar las comprobaciones de seguridad de la IA, sigue estos pasos:
Asegúrate de que se cumplen los siguientes requisitos previos:
- Habilita el servicio Model Armor en tu Google Cloud proyecto.
- Crea las plantillas de Model Armor con la consola de Model Armor, Google Cloud CLI o la API.
Asegúrate de que ya has creado una plantilla de Model Armor llamada
my-model-armor-template-name-id.Para configurar el
GCPTrafficExtension, sigue estos pasos:Guarda el siguiente archivo de manifiesto de ejemplo como
gcp-traffic-extension.yaml:kind: GCPTrafficExtension apiVersion: networking.gke.io/v1 metadata: name: my-model-armor-extension spec: targetRefs: - group: "gateway.networking.k8s.io" kind: Gateway name: GATEWAY_NAME extensionChains: - name: my-model-armor-chain1 matchCondition: celExpressions: - celMatcher: request.path.startsWith("/") extensions: - name: my-model-armor-service supportedEvents: - RequestHeaders timeout: 1s googleAPIServiceName: "modelarmor.us-central1.rep.googleapis.com" metadata: 'extensionPolicy': MODEL_ARMOR_TEMPLATE_NAME 'sanitizeUserPrompt': 'true' 'sanitizeUserResponse': 'true'Haz los cambios siguientes:
GATEWAY_NAME: el nombre de la pasarela.MODEL_ARMOR_TEMPLATE_NAME: el nombre de tu plantilla de Model Armor.
El archivo
gcp-traffic-extension.yamlincluye los siguientes ajustes:targetRefs: especifica la pasarela a la que se aplica esta extensión.extensionChains: define una cadena de extensiones que se aplicará al tráfico.matchCondition: define las condiciones en las que se aplican las extensiones.extensions: define las extensiones que se van a aplicar.supportedEvents: especifica los eventos durante los cuales se invoca la extensión.timeout: especifica el tiempo de espera de la extensión.googleAPIServiceName: especifica el nombre del servicio de la extensión.metadata: especifica los metadatos de la extensión, incluidos los ajustes deextensionPolicyy de saneamiento de la petición o la respuesta.
Aplica el manifiesto de ejemplo a tu clúster:
kubectl apply -f `gcp-traffic-extension.yaml`
Una vez que hayas configurado las comprobaciones de seguridad de la IA y las hayas integrado con tu pasarela, Model Armor filtrará automáticamente las peticiones y las respuestas en función de las reglas definidas.
Configurar la observabilidad
GKE Inference Gateway proporciona información valiosa sobre el estado, el rendimiento y el comportamiento de tus cargas de trabajo de inferencia. De esta forma, puede identificar y resolver problemas, optimizar el uso de los recursos y asegurar la fiabilidad de sus aplicaciones.
Google Cloud proporciona los siguientes paneles de Cloud Monitoring, que ofrecen observabilidad de inferencia para GKE Inference Gateway:
- Panel de control de GKE Inference Gateway:
proporciona métricas de oro para el servicio de LLMs, como el rendimiento de las solicitudes y los tokens, la latencia, los errores y la utilización de la caché de
InferencePool. Para ver la lista completa de métricas de GKE Inference Gateway disponibles, consulte Métricas expuestas. - Panel de control del servidor de modelos: proporciona un panel de control con las señales de oro del servidor de modelos. Esto le permite monitorizar la carga y el rendimiento de los servidores de modelos, como
KVCache UtilizationyQueue length. De esta forma, puede monitorizar la carga y el rendimiento de los servidores de modelos. - Panel de control del balanceador de carga: muestra métricas del balanceador de carga, como las solicitudes por segundo, la latencia de servicio de las solicitudes de extremo a extremo y los códigos de estado de las solicitudes y respuestas. Estas métricas le ayudan a comprender el rendimiento del servicio de solicitudes de extremo a extremo e identificar errores.
- Métricas de Data Center GPU Manager (DCGM): proporciona métricas de las GPUs de NVIDIA, como el rendimiento y la utilización de las GPUs de NVIDIA. Puede configurar las métricas de NVIDIA Data Center GPU Manager (DCGM) en Cloud Monitoring. Para obtener más información, consulta Recoger y ver métricas de DCGM.
Ver el panel de control de GKE Inference Gateway
Para ver el panel de control de GKE Inference Gateway, sigue estos pasos:
En la Google Cloud consola, ve a la página Monitorización.
En el panel de navegación, selecciona Paneles.
En la sección Integraciones, selecciona GMP.
En la página Plantillas de panel de control de Cloud Monitoring, busca "Gateway".
Consulta el panel de control de GKE Inference Gateway.
También puedes seguir las instrucciones que se indican en el artículo Panel de control de monitorización.
Configurar el panel de control de observabilidad del servidor de modelos
Para recoger señales de oro de cada servidor de modelos y saber qué contribuye al rendimiento de GKE Inference Gateway, puedes configurar la monitorización automática de tus servidores de modelos. Esto incluye servidores de modelos como los siguientes:
Para ver los paneles de control de integración, sigue estos pasos:
- Recopila las métricas de tu servidor de modelos.
En la Google Cloud consola, ve a la página Monitorización.
En el panel de navegación, selecciona Paneles.
En Integrations (Integraciones), selecciona GMP. Se muestran los paneles de control de integración correspondientes.
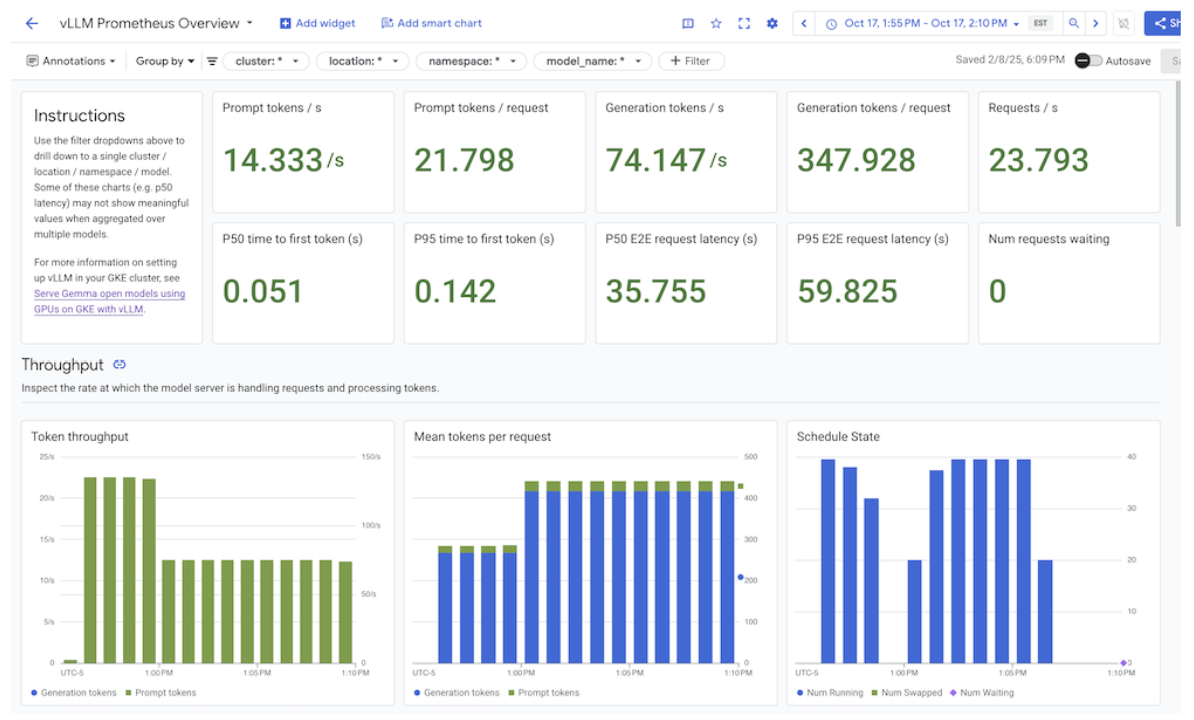
Imagen: Paneles de control de integraciones
Para obtener más información, consulta Personalizar la monitorización de aplicaciones.
Configurar las alertas de Cloud Monitoring
Para configurar alertas de Cloud Monitoring para GKE Inference Gateway, sigue estos pasos:
Modifica el umbral de las alertas. Guarda el siguiente archivo de manifiesto de ejemplo como
alerts.yaml:groups: - name: gateway-api-inference-extension rules: - alert: HighInferenceRequestLatencyP99 annotations: title: 'High latency (P99) for model {{ $labels.model_name }}' description: 'The 99th percentile request duration for model {{ $labels.model_name }} and target model {{ $labels.target_model_name }} has been consistently above 10.0 seconds for 5 minutes.' expr: histogram_quantile(0.99, rate(inference_model_request_duration_seconds_bucket[5m])) > 10.0 for: 5m labels: severity: 'warning' - alert: HighInferenceErrorRate annotations: title: 'High error rate for model {{ $labels.model_name }}' description: 'The error rate for model {{ $labels.model_name }} and target model {{ $labels.target_model_name }} has been consistently above 5% for 5 minutes.' expr: sum by (model_name) (rate(inference_model_request_error_total[5m])) / sum by (model_name) (rate(inference_model_request_total[5m])) > 0.05 for: 5m labels: severity: 'critical' impact: 'availability' - alert: HighInferencePoolAvgQueueSize annotations: title: 'High average queue size for inference pool {{ $labels.name }}' description: 'The average number of requests pending in the queue for inference pool {{ $labels.name }} has been consistently above 50 for 5 minutes.' expr: inference_pool_average_queue_size > 50 for: 5m labels: severity: 'critical' impact: 'performance' - alert: HighInferencePoolAvgKVCacheUtilization annotations: title: 'High KV cache utilization for inference pool {{ $labels.name }}' description: 'The average KV cache utilization for inference pool {{ $labels.name }} has been consistently above 90% for 5 minutes, indicating potential resource exhaustion.' expr: inference_pool_average_kv_cache_utilization > 0.9 for: 5m labels: severity: 'critical' impact: 'resource_exhaustion'Para crear políticas de alertas, ejecuta el siguiente comando:
gcloud alpha monitoring policies migrate --policies-from-prometheus-alert-rules-yaml=alerts.yamlVerás las nuevas políticas de alertas en la página Alertas.
Modificar alertas
Puedes consultar la lista completa de las métricas más recientes disponibles en el repositorio de GitHub kubernetes-sigs/gateway-api-inference-extension y añadir nuevas alertas al manifiesto usando otras métricas.
Para cambiar las alertas de muestra, toma como ejemplo la siguiente alerta:
- alert: HighInferenceRequestLatencyP99
annotations:
title: 'High latency (P99) for model {{ $labels.model_name }}'
description: 'The 99th percentile request duration for model {{ $labels.model_name }} and target model {{ $labels.target_model_name }} has been consistently above 10.0 seconds for 5 minutes.'
expr: histogram_quantile(0.99, rate(inference_model_request_duration_seconds_bucket[5m])) > 10.0
for: 5m
labels:
severity: 'warning'
La alerta se activará si el percentil 99 de la duración de las solicitudes en 5 minutos supera los 10 segundos. Puedes modificar la sección expr de la alerta para ajustar el umbral según tus requisitos.
Configurar el registro de GKE Inference Gateway
Configurar el registro de GKE Inference Gateway proporciona información detallada sobre las solicitudes y las respuestas, lo que resulta útil para solucionar problemas, auditar y analizar el rendimiento. Los registros de acceso HTTP registran todas las solicitudes y respuestas, incluidos los encabezados, los códigos de estado y las marcas de tiempo. Este nivel de detalle puede ayudarte a identificar problemas, encontrar errores y comprender el comportamiento de tus cargas de trabajo de inferencia.
Para configurar el registro de GKE Inference Gateway, habilita el registro de acceso HTTP para cada uno de tus objetos InferencePool.
Guarda el siguiente archivo de manifiesto de ejemplo como
logging-backend-policy.yaml:apiVersion: networking.gke.io/v1 kind: GCPBackendPolicy metadata: name: logging-backend-policy namespace: NAMESPACE_NAME spec: default: logging: enabled: true sampleRate: 500000 targetRef: group: inference.networking.x-k8s.io kind: InferencePool name: INFERENCE_POOL_NAMEHaz los cambios siguientes:
NAMESPACE_NAME: el nombre del espacio de nombres en el que se ha implementado tuInferencePool.INFERENCE_POOL_NAME: el nombre delInferencePool.
Aplica el manifiesto de ejemplo a tu clúster:
kubectl apply -f logging-backend-policy.yaml
Después de aplicar este manifiesto, GKE Inference Gateway habilita los registros de acceso HTTP para el InferencePool especificado. Puedes ver estos registros en Cloud Logging. Los registros incluyen información detallada sobre cada solicitud y respuesta, como la URL de la solicitud, los encabezados, el código de estado de la respuesta y la latencia.
Crear métricas basadas en registros para ver los detalles de los errores
Puede usar métricas basadas en registros para analizar los registros de balanceo de carga y extraer detalles de los errores. Cada clase de Gateway de GKE, como las clases gke-l7-global-external-managed y gke-l7-regional-internal-managed de Gateway, se basa en un balanceador de carga diferente. Para obtener más información, consulta las funciones de GatewayClass.
Cada balanceador de carga tiene un recurso monitorizado diferente que debe usar al crear una métrica basada en registros. Para obtener más información sobre el recurso monitorizado de cada balanceador de carga, consulte lo siguiente:
- En el caso de los balanceadores de carga externos regionales: métricas basadas en registros de balanceadores de carga HTTP(S) externos
- Balanceadores de carga internos: métricas basadas en registros de balanceadores de carga HTTP(S) internos
Para crear una métrica basada en registros que muestre los detalles de los errores, haz lo siguiente:
Crea un archivo JSON llamado
error_detail_metric.jsoncon la siguiente definición:LogMetricEsta configuración crea una métrica que extrae el campoproxyStatusde los registros del balanceador de carga.{ "description": "Metric to extract error details from load balancer logs.", "filter": "resource.type=\"MONITORED_RESOURCE\"", "metricDescriptor": { "metricKind": "DELTA", "valueType": "INT64", "labels": [ { "key": "error_detail", "valueType": "STRING", "description": "The detailed error string from the load balancer." } ] }, "labelExtractors": { "error_detail": "EXTRACT(jsonPayload.proxyStatus)" } }Sustituye
MONITORED_RESOURCEpor el recurso monitorizado de tu balanceador de carga.Abre Cloud Shell o tu terminal local donde esté instalada la CLI de gcloud.
Para crear la métrica, ejecuta el comando
gcloud logging metrics createcon la marca--config-from-file:gcloud logging metrics create error_detail_metric \ --config-from-file=error_detail_metric.json
Una vez creada la métrica, puedes usarla en Cloud Monitoring para ver la distribución de los errores que ha notificado el balanceador de carga. Para obtener más información, consulta Crear una métrica basada en registros.
Para obtener más información sobre cómo crear alertas a partir de métricas basadas en registros, consulta Crear una política de alertas en una métrica de contador.
.Configurar autoescalado
El autoescalado ajusta la asignación de recursos en respuesta a las variaciones de carga, lo que mantiene el rendimiento y la eficiencia de los recursos añadiendo o eliminando pods de forma dinámica en función de la demanda. En el caso de GKE Inference Gateway, esto implica el autoescalado horizontal de los pods de cada InferencePool. La herramienta de autoescalado horizontal de pods (HPA) de GKE autoescala los pods en función de las métricas del servidor de modelos, como KVCache Utilization. De esta forma, el servicio de inferencia puede gestionar diferentes cargas de trabajo y volúmenes de consultas, al tiempo que gestiona de forma eficiente el uso de los recursos.
Para configurar instancias InferencePool de forma que se escalen automáticamente en función de las métricas producidas por GKE Inference Gateway, sigue estos pasos:
Despliega un objeto
PodMonitoringen el clúster para recoger las métricas generadas por GKE Inference Gateway. Para obtener más información, consulta Configurar la observabilidad.Implementa el adaptador de Stackdriver de métricas personalizadas para que HPA pueda acceder a las métricas:
Guarda el siguiente archivo de manifiesto de ejemplo como
adapter_new_resource_model.yaml:apiVersion: v1 kind: Namespace metadata: name: custom-metrics --- apiVersion: v1 kind: ServiceAccount metadata: name: custom-metrics-stackdriver-adapter namespace: custom-metrics --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: custom-metrics:system:auth-delegator roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: system:auth-delegator subjects: - kind: ServiceAccount name: custom-metrics-stackdriver-adapter namespace: custom-metrics --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: custom-metrics-auth-reader namespace: kube-system roleRef: apiGroup: rbac.authorization.k8s.io kind: Role name: extension-apiserver-authentication-reader subjects: - kind: ServiceAccount name: custom-metrics-stackdriver-adapter namespace: custom-metrics --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: custom-metrics-resource-reader namespace: custom-metrics rules: - apiGroups: - "" resources: - pods - nodes - nodes/stats verbs: - get - list - watch --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: custom-metrics-resource-reader roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: custom-metrics-resource-reader subjects: - kind: ServiceAccount name: custom-metrics-stackdriver-adapter namespace: custom-metrics --- apiVersion: apps/v1 kind: Deployment metadata: run: custom-metrics-stackdriver-adapter k8s-app: custom-metrics-stackdriver-adapter spec: replicas: 1 selector: matchLabels: run: custom-metrics-stackdriver-adapter k8s-app: custom-metrics-stackdriver-adapter template: metadata: labels: run: custom-metrics-stackdriver-adapter k8s-app: custom-metrics-stackdriver-adapter kubernetes.io/cluster-service: "true" spec: serviceAccountName: custom-metrics-stackdriver-adapter containers: - image: gcr.io/gke-release/custom-metrics-stackdriver-adapter:v0.15.2-gke.1 imagePullPolicy: Always name: pod-custom-metrics-stackdriver-adapter command: - /adapter - --use-new-resource-model=true - --fallback-for-container-metrics=true resources: limits: cpu: 250m memory: 200Mi requests: cpu: 250m memory: 200Mi --- apiVersion: v1 kind: Service metadata: labels: run: custom-metrics-stackdriver-adapter k8s-app: custom-metrics-stackdriver-adapter kubernetes.io/cluster-service: 'true' kubernetes.io/name: Adapter name: custom-metrics-stackdriver-adapter namespace: custom-metrics spec: ports: - port: 443 protocol: TCP targetPort: 443 selector: run: custom-metrics-stackdriver-adapter k8s-app: custom-metrics-stackdriver-adapter type: ClusterIP --- apiVersion: apiregistration.k8s.io/v1 kind: APIService metadata: name: v1beta1.custom.metrics.k8s.io spec: insecureSkipTLSVerify: true group: custom.metrics.k8s.io groupPriorityMinimum: 100 versionPriority: 100 service: name: custom-metrics-stackdriver-adapter namespace: custom-metrics version: v1beta1 --- apiVersion: apiregistration.k8s.io/v1 kind: APIService metadata: name: v1beta2.custom.metrics.k8s.io spec: insecureSkipTLSVerify: true group: custom.metrics.k8s.io groupPriorityMinimum: 100 versionPriority: 200 service: name: custom-metrics-stackdriver-adapter namespace: custom-metrics version: v1beta2 --- apiVersion: apiregistration.k8s.io/v1 kind: APIService metadata: name: v1beta1.external.metrics.k8s.io spec: insecureSkipTLSVerify: true group: external.metrics.k8s.io groupPriorityMinimum: 100 versionPriority: 100 service: name: custom-metrics-stackdriver-adapter namespace: custom-metrics version: v1beta1 --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: external-metrics-reader rules: - apiGroups: - "external.metrics.k8s.io" resources: - "*" verbs: - list - get - watch --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: external-metrics-reader roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: external-metrics-reader subjects: - kind: ServiceAccount name: horizontal-pod-autoscaler namespace: kube-systemAplica el manifiesto de ejemplo a tu clúster:
kubectl apply -f adapter_new_resource_model.yaml
Para dar permisos al adaptador para leer métricas del proyecto, ejecuta el siguiente comando:
$ PROJECT_ID=PROJECT_ID $ PROJECT_NUMBER=$(gcloud projects describe PROJECT_ID --format="value(projectNumber)") $ gcloud projects add-iam-policy-binding projects/PROJECT_ID \ --role roles/monitoring.viewer \ --member=principal://iam.googleapis.com/projects/PROJECT_NUMBER/locations/global/workloadIdentityPools/$PROJECT_ID.svc.id.goog/subject/ns/custom-metrics/sa/custom-metrics-stackdriver-adapterSustituye
PROJECT_IDpor el ID de tu proyecto. Google CloudPor cada
InferencePool, implementa un HPA similar al siguiente:apiVersion: autoscaling/v2 kind: HorizontalPodAutoscaler metadata: name: INFERENCE_POOL_NAME namespace: INFERENCE_POOL_NAMESPACE spec: scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: INFERENCE_POOL_NAME minReplicas: MIN_REPLICAS maxReplicas: MAX_REPLICAS metrics: - type: External external: metric: name: prometheus.googleapis.com|inference_pool_average_kv_cache_utilization|gauge selector: matchLabels: metric.labels.name: INFERENCE_POOL_NAME resource.labels.cluster: CLUSTER_NAME resource.labels.namespace: INFERENCE_POOL_NAMESPACE target: type: AverageValue averageValue: TARGET_VALUEHaz los cambios siguientes:
INFERENCE_POOL_NAME: el nombre delInferencePool.INFERENCE_POOL_NAMESPACE: el espacio de nombres deInferencePool.CLUSTER_NAME: el nombre del clúster.MIN_REPLICAS: la disponibilidad mínima delInferencePool(capacidad de referencia). HPA mantiene este número de réplicas cuando el uso está por debajo del umbral objetivo de HPA. Las cargas de trabajo de alta disponibilidad deben asignar a este campo un valor superior a1para asegurar que la disponibilidad se mantenga durante las interrupciones de los pods.MAX_REPLICAS: el valor que limita el número de aceleradores que se deben asignar a las cargas de trabajo alojadas enInferencePool. HPA no aumentará el número de réplicas más allá de este valor. Durante las horas de mayor tráfico, monitoriza el número de réplicas para asegurarte de que el valor del campoMAX_REPLICASproporcione suficiente margen para que la carga de trabajo pueda aumentar y mantener las características de rendimiento elegidas.TARGET_VALUE: el valor que representa el objetivo elegidoKV-Cache Utilizationpor servidor de modelo. Es un número entre 0 y 100, y depende en gran medida del servidor del modelo, el modelo, el acelerador y las características del tráfico entrante. Puedes determinar este valor objetivo de forma experimental mediante pruebas de carga y trazando un gráfico de rendimiento frente a latencia. Selecciona una combinación de latencia y rendimiento del gráfico y usa el valorKV-Cache Utilizationcorrespondiente como destino del HPA. Debes ajustar y monitorizar este valor con atención para conseguir los resultados de rendimiento y precio que hayas elegido. Puedes usar GKE Inference Quickstart para determinar este valor automáticamente.
Siguientes pasos
- Consulta información sobre GKE Inference Gateway.
- Consulta información sobre cómo desplegar GKE Inference Gateway.
- Consulta información sobre las operaciones de lanzamiento de GKE Inference Gateway.
- Consulta información sobre el servicio con GKE Inference Gateway.