En esta página, se describe cómo personalizar la implementación de GKE Inference Gateway.
Esta página está dirigida a los especialistas en redes responsables de administrar la infraestructura de GKE y a los administradores de plataformas que administran cargas de trabajo de IA.
Para administrar y optimizar las cargas de trabajo de inferencia, debes configurar las funciones avanzadas de la puerta de enlace de inferencia de GKE.
Comprende y configura las siguientes funciones avanzadas:
- Para usar la integración de Model Armor, configura las verificaciones de seguridad de la IA.
- Para mejorar la puerta de enlace de inferencia de GKE con funciones como seguridad de la API, límite de frecuencia y estadísticas, configura Apigee para la autenticación y la administración de APIs.
- Para enrutar solicitudes según el nombre del modelo en el cuerpo de la solicitud, configura el enrutamiento basado en el cuerpo.
- Para ver las métricas y los paneles del Inference Gateway y los servidores de modelos de GKE, y para habilitar el registro de acceso HTTP, configura la observabilidad.
- Para escalar automáticamente tus implementaciones de GKE Inference Gateway, configura el ajuste de escala automático.
Configura las verificaciones de seguridad y protección de la IA
La puerta de enlace de inferencia de GKE se integra con Model Armor para realizar verificaciones de seguridad en las instrucciones y respuestas de las aplicaciones que usan modelos de lenguaje grandes (LLMs). Esta integración proporciona una capa adicional de aplicación de la seguridad a nivel de la infraestructura que complementa las medidas de seguridad a nivel de la aplicación. Esto permite la aplicación centralizada de políticas en todo el tráfico de LLM.
En el siguiente diagrama, se ilustra la integración de Model Armor con GKE Inference Gateway en un clúster de GKE:
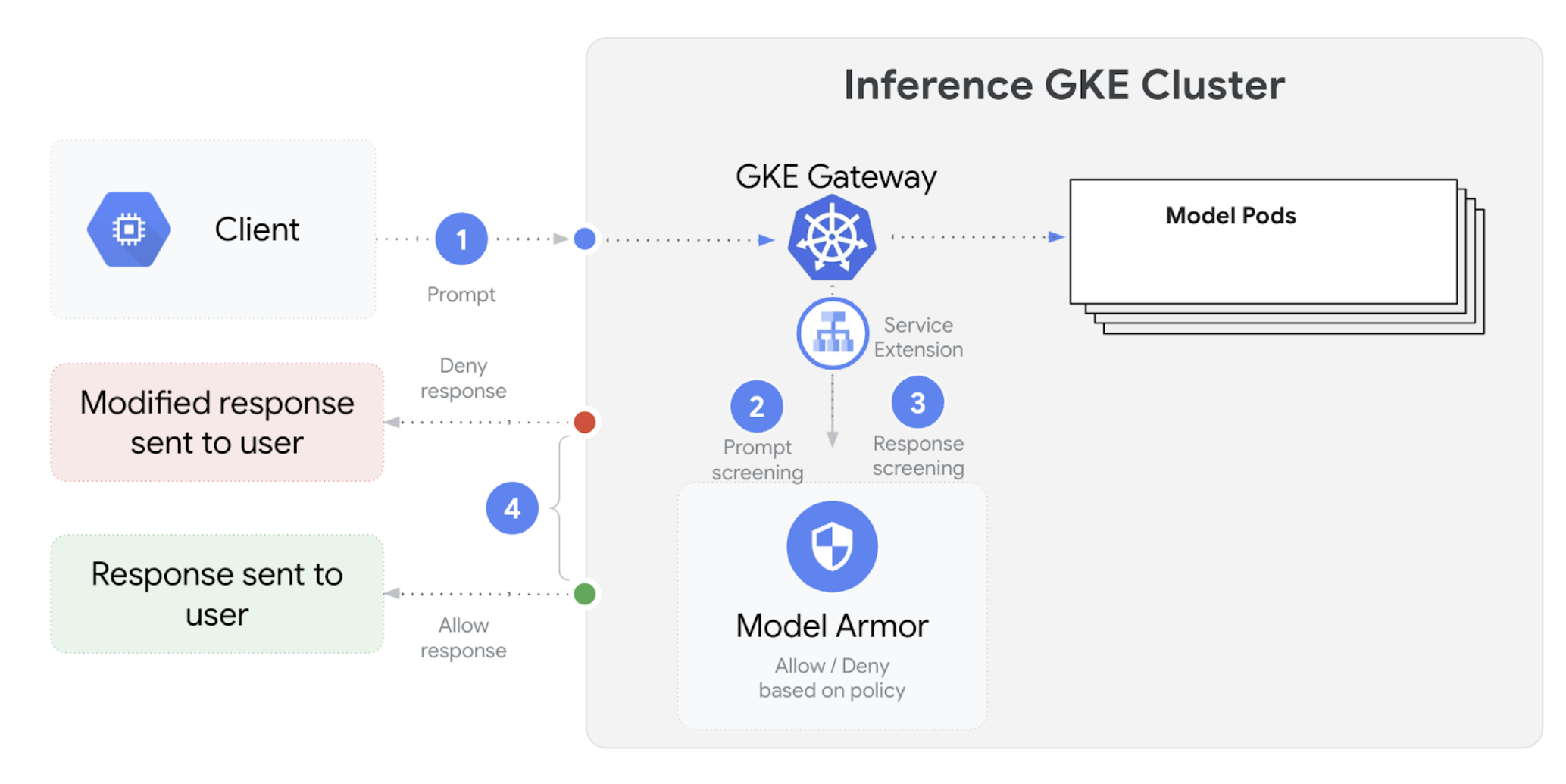
Para configurar las verificaciones de seguridad de la IA, sigue estos pasos:
Requisitos previos
- Habilita el servicio Model Armor en tu proyecto Google Cloud .
Crea las plantillas de Model Armor con la consola de Model Armor, Google Cloud CLI o la API. El siguiente comando crea una plantilla llamada
llmque registra las operaciones y filtra el contenido dañino.# Set environment variables PROJECT_ID=$(gcloud config get-value project) # Replace <var>CLUSTER_LOCATION<var> with the location of your GKE cluster. For example, `us-central1`. LOCATION="CLUSTER_LOCATION" MODEL_ARMOR_TEMPLATE_NAME=llm # Set the regional API endpoint gcloud config set api_endpoint_overrides/modelarmor \ "https://modelarmor.$LOCATION.rep.googleapis.com/" # Create the template gcloud model-armor templates create $MODEL_ARMOR_TEMPLATE_NAME \ --location $LOCATION \ --pi-and-jailbreak-filter-settings-enforcement=enabled \ --pi-and-jailbreak-filter-settings-confidence-level=MEDIUM_AND_ABOVE \ --rai-settings-filters='[{ "filterType": "HATE_SPEECH", "confidenceLevel": "MEDIUM_AND_ABOVE" },{ "filterType": "DANGEROUS", "confidenceLevel": "MEDIUM_AND_ABOVE" },{ "filterType": "HARASSMENT", "confidenceLevel": "MEDIUM_AND_ABOVE" },{ "filterType": "SEXUALLY_EXPLICIT", "confidenceLevel": "MEDIUM_AND_ABOVE" }]' \ --template-metadata-log-sanitize-operations \ --template-metadata-log-operations
Otorga permisos de IAM
La cuenta de servicio de las extensiones de servicio requiere permisos para acceder a los recursos necesarios. Otorga los roles necesarios ejecutando los siguientes comandos:
PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format 'get(projectNumber)') gcloud projects add-iam-policy-binding $PROJECT_ID \ --member=serviceAccount:service-$PROJECT_NUMBER@gcp-sa-dep.iam.gserviceaccount.com \ --role=roles/container.admin gcloud projects add-iam-policy-binding $PROJECT_ID \ --member=serviceAccount:service-$PROJECT_NUMBER@gcp-sa-dep.iam.gserviceaccount.com \ --role=roles/modelarmor.calloutUser gcloud projects add-iam-policy-binding $PROJECT_ID \ --member=serviceAccount:service-$PROJECT_NUMBER@gcp-sa-dep.iam.gserviceaccount.com \ --role=roles/serviceusage.serviceUsageConsumer gcloud projects add-iam-policy-binding $PROJECT_ID \ --member=serviceAccount:service-$PROJECT_NUMBER@gcp-sa-dep.iam.gserviceaccount.com \ --role=roles/modelarmor.userConfigura el
GCPTrafficExtensionPara aplicar las políticas de Model Armor a tu puerta de enlace, crea un recurso
GCPTrafficExtensioncon el formato de metadatos correcto.Guarda el siguiente manifiesto de muestra como
gcp-traffic-extension.yaml:kind: GCPTrafficExtension apiVersion: networking.gke.io/v1 metadata: name: my-model-armor-extension spec: targetRefs: - group: "gateway.networking.k8s.io" kind: Gateway name: GATEWAY_NAME extensionChains: - name: my-model-armor-chain1 matchCondition: celExpressions: - celMatcher: request.path.startsWith("/") extensions: - name: my-model-armor-service supportedEvents: - RequestHeaders - RequestBody - RequestTrailers - ResponseHeaders - ResponseBody - ResponseTrailers timeout: 1s failOpen: false googleAPIServiceName: "modelarmor.${LOCATION}.rep.googleapis.com" metadata: model_armor_settings: '[{"model": "${MODEL}","model_response_template_id": "projects/${PROJECT_ID}/locations/${LOCATION}/templates/${MODEL_ARMOR_TEMPLATE_NAME}","user_prompt_template_id": "projects/${PROJECT_ID}/locations/${LOCATION}/templates/${MODEL_ARMOR_TEMPLATE_NAME}"}]'Reemplaza lo siguiente:
GATEWAY_NAME: Es el nombre de la puerta de enlace.MODEL_ARMOR_TEMPLATE_NAME: El nombre de tu plantilla de Model Armor.
El archivo
gcp-traffic-extension.yamlincluye los siguientes parámetros de configuración:targetRefs: Especifica la puerta de enlace a la que se aplica esta extensión.extensionChains: Define una cadena de extensiones que se aplicará al tráfico.matchCondition: Define las condiciones en las que se aplican las extensiones.extensions: Define las extensiones que se aplicarán.supportedEvents: Especifica los eventos durante los cuales se invoca la extensión.timeout: Especifica el tiempo de espera de la extensión.googleAPIServiceName: Especifica el nombre del servicio para la extensión.metadata: Especifica los metadatos de la extensión, incluidos los parámetros de configuración deextensionPolicyy de limpieza de la respuesta o la instrucción.
Aplica el manifiesto de muestra a tu clúster:
export GATEWAY_NAME="your-gateway-name" export MODEL="google/gemma-3-1b-it" # Or your specific model envsubst < gcp-traffic-extension.yaml | kubectl apply -f -
Después de configurar las verificaciones de seguridad de la IA y de integrarlas en tu puerta de enlace, Model Armor filtra automáticamente las instrucciones y las respuestas según las reglas definidas.
Configura Apigee para la autenticación y la administración de APIs
GKE Inference Gateway se integra con Apigee para proporcionar autenticación, autorización y administración de API para tus cargas de trabajo de inferencia. Para obtener más información sobre los beneficios de usar Apigee, consulta Beneficios clave de usar Apigee.
Puedes integrar GKE Inference Gateway con Apigee para mejorar tu puerta de enlace de inferencia de GKE con funciones como seguridad de la API, límite de frecuencia, cuotas, estadísticas y monetización.
Requisitos previos
Antes de comenzar, asegúrate de tener lo siguiente:
- Un clúster de GKE que ejecute la versión 1.34.* o una posterior.
- Un clúster de GKE con la puerta de enlace de GKE Inference implementada.
- Una instancia de Apigee creada en la misma región que tu clúster de GKE
- El operador de APIM de Apigee y sus CRD instalados en tu clúster de GKE Para obtener instrucciones, consulta Instala el operador de APIM de Apigee.
kubectlconfigurado para conectarse a tu clúster de GKEGoogle Cloud CLIinstalado y autenticado
Crea un ApigeeBackendService
Primero, crea un recurso ApigeeBackendService. La puerta de enlace de inferencia de GKE usa esto para crear un procesador de extensiones de Apigee.
Guarda el siguiente manifiesto como
my-apigee-backend-service.yaml:apiVersion: apim.googleapis.com/v1 kind: ApigeeBackendService metadata: name: my-apigee-backend-service spec: apigeeEnv: "APIGEE_ENVIRONMENT_NAME" # optional field defaultSecurityEnabled: true # optional field locations: name: "LOCATION" network: "CLUSTER_NETWORK" subnetwork: "CLUSTER_SUBNETWORK"Reemplaza lo siguiente:
APIGEE_ENVIRONMENT_NAME: Es el nombre de tu entorno de Apigee. Nota: No es necesario que configures este campo siapigee-apim-operatorse instaló con la marcagenerateEnv=TRUE. De lo contrario, crea un entorno de Apigee siguiendo las instrucciones en Crea un entorno.LOCATION: Es la ubicación de tu instancia de Apigee.CLUSTER_NETWORK: Es la red de tu clúster de GKE.CLUSTER_SUBNETWORK: Es la subred de tu clúster de GKE.
Aplica el manifiesto al clúster:
kubectl apply -f my-apigee-backend-service.yamlVerifica que el estado haya cambiado a
CREATED:kubectl wait --for=jsonpath='{.status.currentState}'="CREATED" -f my-apigee-backend-service.yaml --timeout=5m
Configura la puerta de enlace de GKE Inference
Configura GKE Inference Gateway para habilitar el procesador de extensiones de Apigee como una extensión de tráfico del balanceador de cargas.
Guarda el siguiente manifiesto como
my-apigee-traffic-extension.yaml:kind: GCPTrafficExtension apiVersion: networking.gke.io/v1 metadata: name: my-apigee-traffic-extension spec: targetRefs: - group: "gateway.networking.k8s.io" kind: Gateway name: GATEWAY_NAME extensionChains: - name: my-traffic-extension-chain matchCondition: celExpressions: - celMatcher: request.path.startsWith("/") extensions: - name: my-apigee-extension metadata: # The value for `apigee-extension-processor` must match the name of the `ApigeeBackendService` resource that was applied earlier. apigee-extension-processor: my-apigee-backend-service failOpen: false timeout: 1s supportedEvents: - RequestHeaders - ResponseHeaders - ResponseBody backendRef: group: apim.googleapis.com kind: ApigeeBackendService name: my-apigee-backend-service port: 443Reemplaza
GATEWAY_NAMEpor el nombre de tu puerta de enlace.Aplica el manifiesto al clúster:
kubectl apply -f my-apigee-traffic-extension.yamlEspera a que el estado de
GCPTrafficExtensioncambie aProgrammed:kubectl wait --for=jsonpath='{.status.ancestors[0].conditions[?(@.type=="Programmed")].status}'=True -f my-apigee-traffic-extension.yaml --timeout=5m
Envía solicitudes autenticadas con claves de API
Para encontrar la dirección IP de tu puerta de enlace de GKE Inference, inspecciona el estado de la puerta de enlace:
GW_IP=$(kubectl get gateway/GATEWAY_NAME -o jsonpath='{.status.addresses[0].value}')Reemplaza
GATEWAY_NAMEpor el nombre de tu puerta de enlace.Probar una solicitud sin autenticación Se debe rechazar esta solicitud:
curl -i ${GW_IP}/v1/completions -H 'Content-Type: application/json' -d '{ "model": "food-review", "prompt": "Write as if you were a critic: San Francisco", "max_tokens": 100, "temperature": 0 }'Verás una respuesta similar a la siguiente, que indica que la extensión de Apigee funciona:
{"fault":{"faultstring":"Raising fault. Fault name : RF-insufficient-request-raise-fault","detail":{"errorcode":"steps.raisefault.RaiseFault"}}}Accede a la IU de Apigee y crea una clave de API. Para obtener instrucciones, consulta Crea una clave de API.
Envía la clave de API en el encabezado de la solicitud HTTP:
curl -i ${GW_IP}/v1/completions -H 'Content-Type: application/json' -H 'x-api-key: API_KEY' -d '{ "model": "food-review", "prompt": "Write as if you were a critic: San Francisco", "max_tokens": 100, "temperature": 0 }'Reemplaza
API_KEYpor tu clave de API.
Para obtener información más detallada sobre la configuración de políticas de Apigee, consulta Usa políticas de administración de APIs con el operador de APIM de Apigee para Kubernetes.
Configura la observabilidad
La puerta de enlace de inferencia de GKE proporciona estadísticas sobre el estado, el rendimiento y el comportamiento de tus cargas de trabajo de inferencia. Esto te ayuda a identificar y resolver problemas, optimizar el uso de recursos y garantizar la confiabilidad de tus aplicaciones.
Google Cloud proporciona los siguientes paneles de Cloud Monitoring que ofrecen observabilidad de la inferencia para la puerta de enlace de inferencia de GKE:
- Panel de la puerta de enlace de inferencia de GKE: Proporciona métricas clave para la entrega de LLM, como el rendimiento de solicitudes y tokens, la latencia, los errores y la utilización de la caché para
InferencePool. Para ver la lista completa de las métricas disponibles de GKE Inference Gateway, consulta Métricas expuestas. - Paneles de observabilidad de IA/AA: Proporciona paneles para el uso de la infraestructura, las métricas de DCGM y las métricas de rendimiento del modelo de vLLM.
- Panel del servidor de modelos: Proporciona un panel para los indicadores dorados del servidor de modelos. Esto te permite supervisar la carga y el rendimiento de los servidores de modelos, como
KVCache UtilizationyQueue length. - Panel del balanceador de cargas: Informa métricas del balanceador de cargas, como las solicitudes por segundo, la latencia de entrega de solicitudes de extremo a extremo y los códigos de estado de solicitud y respuesta. Estas métricas te ayudan a comprender el rendimiento de la publicación de solicitudes de extremo a extremo y a identificar errores.
- Métricas de Data Center GPU Manager (DCGM): Proporciona métricas de DCGM, como el rendimiento y el uso de las GPUs de NVIDIA. Puedes configurar las métricas de DCGM en Cloud Monitoring. Para obtener más información, consulta Recopila y visualiza métricas de DCGM.
Visualiza el panel de la puerta de enlace de inferencia de GKE
Para ver el panel de la puerta de enlace de inferencia de GKE, sigue estos pasos:
En la consola de Google Cloud , ve a la página Monitoring.
En el panel de navegación, selecciona Paneles.
En la sección Integraciones, selecciona GMP.
En la página Plantillas de paneles de Cloud Monitoring, busca "Puerta de enlace".
Visualiza el panel de GKE Inference Gateway.
Como alternativa, puedes seguir las instrucciones que se indican en Panel de supervisión.
Visualiza los paneles de observabilidad de los modelos de IA/AA
Para ver los modelos implementados y los paneles de las métricas de observabilidad de un modelo, sigue estos pasos:
En la consola de Google Cloud , ve a la página Modelos implementados.
Para ver detalles sobre una implementación específica, incluidas sus métricas, registros y paneles, haz clic en el nombre del modelo en la lista.
En la página de detalles del modelo, haz clic en la pestaña Observabilidad para ver los siguientes paneles. Si se te solicita, haz clic en Habilitar para habilitar el panel.
- En el panel Uso de la infraestructura, se muestran las métricas de utilización.
- En el panel DCGM, se muestran las métricas de DCGM.
- Si usas vLLM, el panel Rendimiento del modelo está disponible y muestra métricas sobre el rendimiento del modelo de vLLM.
Configura el panel de observabilidad del servidor de modelos
Para recopilar indicadores clave de rendimiento de cada servidor de modelos y comprender qué contribuye al rendimiento de la puerta de enlace de GKE Inference, puedes configurar la supervisión automática de tus servidores de modelos. Esto incluye servidores de modelos como los siguientes:
Para ver los paneles de integración, primero asegúrate de recopilar métricas de tu servidor de modelos. Luego, realiza los pasos a continuación:
En la consola de Google Cloud , ve a la página Monitoring.
En el panel de navegación, selecciona Paneles.
En Integraciones, selecciona GMP. Se muestran los paneles de integración correspondientes.
Figura: Paneles de integración
Para obtener más información, consulta Personaliza la supervisión de aplicaciones.
Configura las alertas de Cloud Monitoring
Para configurar alertas de Cloud Monitoring para GKE Inference Gateway, sigue estos pasos:
Guarda el siguiente manifiesto de muestra como
alerts.yamly modifica los umbrales según sea necesario:groups: - name: gateway-api-inference-extension rules: - alert: HighInferenceRequestLatencyP99 annotations: title: 'High latency (P99) for model {{ $labels.model_name }}' description: 'The 99th percentile request duration for model {{ $labels.model_name }} and target model {{ $labels.target_model_name }} has been consistently above 10.0 seconds for 5 minutes.' expr: histogram_quantile(0.99, rate(inference_model_request_duration_seconds_bucket[5m])) > 10.0 for: 5m labels: severity: 'warning' - alert: HighInferenceErrorRate annotations: title: 'High error rate for model {{ $labels.model_name }}' description: 'The error rate for model {{ $labels.model_name }} and target model {{ $labels.target_model_name }} has been consistently above 5% for 5 minutes.' expr: sum by (model_name) (rate(inference_model_request_error_total[5m])) / sum by (model_name) (rate(inference_model_request_total[5m])) > 0.05 for: 5m labels: severity: 'critical' impact: 'availability' - alert: HighInferencePoolAvgQueueSize annotations: title: 'High average queue size for inference pool {{ $labels.name }}' description: 'The average number of requests pending in the queue for inference pool {{ $labels.name }} has been consistently above 50 for 5 minutes.' expr: inference_pool_average_queue_size > 50 for: 5m labels: severity: 'critical' impact: 'performance' - alert: HighInferencePoolAvgKVCacheUtilization annotations: title: 'High KV cache utilization for inference pool {{ $labels.name }}' description: 'The average KV cache utilization for inference pool {{ $labels.name }} has been consistently above 90% for 5 minutes, indicating potential resource exhaustion.' expr: inference_pool_average_kv_cache_utilization > 0.9 for: 5m labels: severity: 'critical' impact: 'resource_exhaustion'Para crear políticas de alertas, ejecuta el siguiente comando:
gcloud alpha monitoring policies migrate --policies-from-prometheus-alert-rules-yaml=alerts.yamlVerás las nuevas políticas de alertas en la página Alertas.
Cómo modificar alertas
Puedes encontrar la lista completa de las métricas más recientes disponibles en el repositorio de GitHub de kubernetes-sigs/gateway-api-inference-extension y puedes agregar alertas nuevas al manifiesto con otras métricas.
Para modificar las alertas de muestra, considera el siguiente ejemplo:
- alert: HighInferenceRequestLatencyP99
annotations:
title: 'High latency (P99) for model {{ $labels.model_name }}'
description: 'The 99th percentile request duration for model {{ $labels.model_name }} and target model {{ $labels.target_model_name }} has been consistently above 10.0 seconds for 5 minutes.'
expr: histogram_quantile(0.99, rate(inference_model_request_duration_seconds_bucket[5m])) > 10.0
for: 5m
labels:
severity: 'warning'
Esta alerta se activa si el percentil 99 de la duración de la solicitud durante 5 minutos supera los 10 segundos. Puedes modificar la sección expr de la alerta para ajustar el umbral según tus requisitos.
Configura el registro para la puerta de enlace de inferencia de GKE
Configurar el registro para la puerta de enlace de inferencia de GKE proporciona información detallada sobre las solicitudes y las respuestas, lo que resulta útil para solucionar problemas, realizar auditorías y analizar el rendimiento. Los registros de acceso HTTP registran cada solicitud y respuesta, incluidos los encabezados, los códigos de estado y las marcas de tiempo. Este nivel de detalle puede ayudarte a identificar problemas, encontrar errores y comprender el comportamiento de tus cargas de trabajo de inferencia.
Para configurar el registro de Inference Gateway de GKE, habilita el registro de acceso HTTP para cada uno de tus objetos InferencePool.
Guarda el siguiente manifiesto de muestra como
logging-backend-policy.yaml:apiVersion: networking.gke.io/v1 kind: GCPBackendPolicy metadata: name: logging-backend-policy namespace: NAMESPACE_NAME spec: default: logging: enabled: true sampleRate: 500000 targetRef: group: inference.networking.x-k8s.io kind: InferencePool name: INFERENCE_POOL_NAMEReemplaza lo siguiente:
NAMESPACE_NAME: Es el nombre del espacio de nombres en el que se implementa tuInferencePool.INFERENCE_POOL_NAME: el nombre deInferencePool.
Aplica el manifiesto de muestra a tu clúster:
kubectl apply -f logging-backend-policy.yaml
Después de aplicar este manifiesto, la puerta de enlace de GKE Inference habilita los registros de acceso HTTP para el InferencePool especificado. Puedes ver estos registros en Cloud Logging. Los registros incluyen información detallada sobre cada solicitud y respuesta, como la URL de la solicitud, los encabezados, el código de estado de la respuesta y la latencia.
Crea métricas basadas en registros para ver los detalles de los errores
Puedes usar métricas basadas en registros para analizar tus registros de balanceo de cargas y extraer detalles de errores. Cada clase de Gateway de GKE, como las clases de Gateway gke-l7-global-external-managed y gke-l7-regional-internal-managed, está respaldada por un balanceador de cargas diferente. Para obtener más información, consulta Capacidades de GatewayClass.
Cada balanceador de cargas tiene un recurso supervisado diferente que debes usar cuando creas una métrica basada en registros. Para obtener más información sobre el recurso supervisado de cada balanceador de cargas, consulta los siguientes vínculos:
- Para los balanceadores de cargas regionales externos: Métricas basadas en registros para balanceadores de cargas HTTP(S) externos
- Para los balanceadores de cargas internos: Métricas basadas en registros para balanceadores de cargas HTTP(S) internos
Para crear una métrica basada en registros y ver los detalles de los errores, haz lo siguiente:
Crea un archivo JSON llamado
error_detail_metric.jsoncon la siguiente definición deLogMetric. Esta configuración crea una métrica que extrae el campoproxyStatusde los registros del balanceador de cargas.{ "description": "Metric to extract error details from load balancer logs.", "filter": "resource.type=\"MONITORED_RESOURCE\"", "metricDescriptor": { "metricKind": "DELTA", "valueType": "INT64", "labels": [ { "key": "error_detail", "valueType": "STRING", "description": "The detailed error string from the load balancer." } ] }, "labelExtractors": { "error_detail": "EXTRACT(jsonPayload.proxyStatus)" } }Reemplaza
MONITORED_RESOURCEpor el recurso supervisado de tu balanceador de cargas.Abre Cloud Shell o la terminal local en la que está instalada gcloud CLI.
Para crear la métrica, ejecuta el comando
gcloud logging metrics createcon la marca--config-from-file:gcloud logging metrics create error_detail_metric \ --config-from-file=error_detail_metric.json
Después de crear la métrica, puedes usarla en Cloud Monitoring para ver la distribución de los errores que informa el balanceador de cargas. Para obtener más información, consulta Crea una métrica basada en registros.
Para obtener más información sobre cómo crear alertas a partir de métricas basadas en registros, consulta Crea una política de alertas en una métrica de contador.
Configurar ajuste de escala automático
El ajuste de escala automático ajusta la asignación de recursos en respuesta a las variaciones de carga, lo que mantiene el rendimiento y la eficiencia de los recursos agregando o quitando Pods de forma dinámica según la demanda. En el caso de GKE Inference Gateway, esto implica el ajuste de escala automático horizontal de los Pods en cada InferencePool. El Horizontal Pod Autoscaler (HPA) de GKE ajusta automáticamente la escala de los Pods en función de las métricas del servidor de modelos, como KVCache Utilization. Esto garantiza que el servicio de inferencia controle diferentes cargas de trabajo y volúmenes de consultas, y que administre de manera eficiente el uso de recursos.
Para configurar instancias InferencePool de modo que se ajusten automáticamente según las métricas que produce GKE Inference Gateway, sigue estos pasos:
Implementa un objeto
PodMonitoringen el clúster para recopilar las métricas que produce GKE Inference Gateway. Para obtener más información, consulta Configura la observabilidad.Implementa el adaptador de métricas personalizadas de Stackdriver para otorgar acceso de HPA a las métricas:
Guarda el siguiente manifiesto de muestra como
adapter_new_resource_model.yaml:apiVersion: v1 kind: Namespace metadata: name: custom-metrics --- apiVersion: v1 kind: ServiceAccount metadata: name: custom-metrics-stackdriver-adapter namespace: custom-metrics --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: custom-metrics:system:auth-delegator roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: system:auth-delegator subjects: - kind: ServiceAccount name: custom-metrics-stackdriver-adapter namespace: custom-metrics --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: custom-metrics-auth-reader namespace: kube-system roleRef: apiGroup: rbac.authorization.k8s.io kind: Role name: extension-apiserver-authentication-reader subjects: - kind: ServiceAccount name: custom-metrics-stackdriver-adapter namespace: custom-metrics --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: custom-metrics-resource-reader rules: - apiGroups: - "" resources: - pods - nodes - nodes/stats verbs: - get - list - watch --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: custom-metrics-resource-reader roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: custom-metrics-resource-reader subjects: - kind: ServiceAccount name: custom-metrics-stackdriver-adapter namespace: custom-metrics --- apiVersion: apps/v1 kind: Deployment metadata: name: custom-metrics-stackdriver-adapter labels: run: custom-metrics-stackdriver-adapter k8s-app: custom-metrics-stackdriver-adapter spec: replicas: 1 selector: matchLabels: run: custom-metrics-stackdriver-adapter k8s-app: custom-metrics-stackdriver-adapter template: metadata: labels: run: custom-metrics-stackdriver-adapter k8s-app: custom-metrics-stackdriver-adapter kubernetes.io/cluster-service: "true" spec: serviceAccountName: custom-metrics-stackdriver-adapter containers: - image: gcr.io/gke-release/custom-metrics-stackdriver-adapter:v0.15.2-gke.1 imagePullPolicy: Always name: pod-custom-metrics-stackdriver-adapter command: - /adapter - --use-new-resource-model=true - --fallback-for-container-metrics=true resources: limits: cpu: 250m memory: 200Mi requests: cpu: 250m memory: 200Mi --- apiVersion: v1 kind: Service metadata: labels: run: custom-metrics-stackdriver-adapter k8s-app: custom-metrics-stackdriver-adapter kubernetes.io/cluster-service: 'true' kubernetes.io/name: Adapter name: custom-metrics-stackdriver-adapter namespace: custom-metrics spec: ports: - port: 443 protocol: TCP targetPort: 443 selector: run: custom-metrics-stackdriver-adapter k8s-app: custom-metrics-stackdriver-adapter type: ClusterIP --- apiVersion: apiregistration.k8s.io/v1 kind: APIService metadata: name: v1beta1.custom.metrics.k8s.io spec: insecureSkipTLSVerify: true group: custom.metrics.k8s.io groupPriorityMinimum: 100 versionPriority: 100 service: name: custom-metrics-stackdriver-adapter namespace: custom-metrics version: v1beta1 --- apiVersion: apiregistration.k8s.io/v1 kind: APIService metadata: name: v1beta2.custom.metrics.k8s.io spec: insecureSkipTLSVerify: true group: custom.metrics.k8s.io groupPriorityMinimum: 100 versionPriority: 200 service: name: custom-metrics-stackdriver-adapter namespace: custom-metrics version: v1beta2 --- apiVersion: apiregistration.k8s.io/v1 kind: APIService metadata: name: v1beta1.external.metrics.k8s.io spec: insecureSkipTLSVerify: true group: external.metrics.k8s.io groupPriorityMinimum: 100 versionPriority: 100 service: name: custom-metrics-stackdriver-adapter namespace: custom-metrics version: v1beta1 --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: external-metrics-reader rules: - apiGroups: - "external.metrics.k8s.io" resources: - "*" verbs: - list - get - watch --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: external-metrics-reader roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: external-metrics-reader subjects: - kind: ServiceAccount name: horizontal-pod-autoscaler namespace: kube-systemAplica el manifiesto de muestra a tu clúster:
kubectl apply -f adapter_new_resource_model.yaml
Para otorgar permisos al adaptador para leer métricas del proyecto, ejecuta el siguiente comando:
$ PROJECT_ID=PROJECT_ID $ PROJECT_NUMBER=$(gcloud projects describe PROJECT_ID --format="value(projectNumber)") $ gcloud projects add-iam-policy-binding projects/PROJECT_ID \ --role roles/monitoring.viewer \ --member=principal://iam.googleapis.com/projects/PROJECT_NUMBER/locations/global/workloadIdentityPools/$PROJECT_ID.svc.id.goog/subject/ns/custom-metrics/sa/custom-metrics-stackdriver-adapterReemplaza
PROJECT_IDpor el Google Cloud ID del proyecto.Para cada
InferencePool, implementa un HPA similar al siguiente:apiVersion: autoscaling/v2 kind: HorizontalPodAutoscaler metadata: name: INFERENCE_POOL_NAME namespace: INFERENCE_POOL_NAMESPACE spec: scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: INFERENCE_POOL_NAME minReplicas: MIN_REPLICAS maxReplicas: MAX_REPLICAS metrics: - type: External external: metric: name: prometheus.googleapis.com|inference_pool_average_kv_cache_utilization|gauge selector: matchLabels: metric.labels.name: INFERENCE_POOL_NAME resource.labels.cluster: CLUSTER_NAME resource.labels.namespace: INFERENCE_POOL_NAMESPACE target: type: AverageValue averageValue: TARGET_VALUEReemplaza lo siguiente:
INFERENCE_POOL_NAME: el nombre deInferencePool.INFERENCE_POOL_NAMESPACE: Es el espacio de nombres deInferencePool.CLUSTER_NAME: el nombre del clústerMIN_REPLICAS: Es la disponibilidad mínima delInferencePool(capacidad de referencia). El HPA mantiene esta cantidad de réplicas cuando el uso está por debajo del umbral objetivo del HPA. Las cargas de trabajo con alta disponibilidad deben establecer este valor en uno superior a1para garantizar la disponibilidad continua durante las interrupciones de Pods.MAX_REPLICAS: Es el valor que limita la cantidad de aceleradores que se deben asignar a las cargas de trabajo alojadas enInferencePool. El HPA no aumentará la cantidad de réplicas más allá de este valor. Durante los períodos de mayor tráfico, supervisa la cantidad de réplicas para asegurarte de que el valor del campoMAX_REPLICASproporcione suficiente margen para que la carga de trabajo pueda aumentar su escala y mantener las características de rendimiento de la carga de trabajo elegida.TARGET_VALUE: Es el valor que representa elKV-Cache Utilizationobjetivo elegido por servidor del modelo. Es un número entre 0 y 100, y depende en gran medida del servidor del modelo, el modelo, el acelerador y las características del tráfico entrante. Puedes determinar este valor objetivo de forma experimental a través de pruebas de carga y trazando un gráfico de capacidad de procesamiento versus latencia. Selecciona una combinación de capacidad de procesamiento y latencia del gráfico, y usa el valor deKV-Cache Utilizationcorrespondiente como objetivo del HPA. Debes ajustar y supervisar este valor de cerca para lograr los resultados de rendimiento y precio deseados. Puedes usar la Guía de inicio rápido de GKE Inference para determinar este valor automáticamente.
¿Qué sigue?
- Obtén más información sobre GKE Inference Gateway.
- Implementa la puerta de enlace de GKE Inference.
- Administra las operaciones de lanzamiento de GKE Inference Gateway.
- Entrega con GKE Inference Gateway.