Esta página explica os principais conceitos e funcionalidades do Inference Gateway do Google Kubernetes Engine (GKE), uma extensão do GKE Gateway para a publicação otimizada de aplicações de IA generativa.
Esta página pressupõe que tem conhecimentos sobre o seguinte:
- Orquestração de IA/ML no GKE
- Terminologia da IA generativa
- Conceitos de rede do GKE, incluindo Serviços e a API GKE Gateway
- Balanceamento de carga no Google Cloud, especialmente como os balanceadores de carga interagem com o GKE
Esta página destina-se às seguintes personas:
- Engenheiros de aprendizagem automática (AA), administradores e operadores de plataformas, e especialistas em dados e IA que tenham interesse em usar capacidades de orquestração de contentores do Kubernetes para apresentar cargas de trabalho de IA/AA.
- Arquitetos da nuvem e especialistas em redes que interagem com as redes do Kubernetes.
Vista geral
O GKE Inference Gateway é uma extensão do GKE Gateway que oferece encaminhamento e equilíbrio de carga otimizados para a publicação de cargas de trabalho de inteligência artificial (IA) generativa. Simplifica a implementação, a gestão e a observabilidade das cargas de trabalho de inferência de IA.
Para escolher a estratégia de balanceamento de carga ideal para as suas cargas de trabalho de IA/ML, consulte o artigo Escolha uma estratégia de balanceamento de carga para a inferência de IA no GKE.
Funcionalidades e vantagens
O GKE Inference Gateway oferece as seguintes capacidades principais para publicar de forma eficiente modelos de IA generativa para aplicações de IA generativa no GKE:
- Métricas suportadas:
KV cache hits: o número de pesquisas bem-sucedidas na cache de chave-valor (KV).- Utilização da GPU ou da TPU: a percentagem de tempo em que a GPU ou a TPU está a processar ativamente.
- Comprimento da fila de pedidos: o número de pedidos a aguardar processamento.
- Equilíbrio de carga otimizado para inferência: distribui pedidos para otimizar o desempenho da publicação de modelos de IA. Usa métricas de servidores de modelos, como
KV cache hitse oqueue length of pending requests, para consumir aceleradores (como GPUs e TPUs) de forma mais eficiente para cargas de trabalho de IA generativa. Isto ativa o encaminhamento com reconhecimento de prefixos de cache, uma funcionalidade essencial que envia pedidos com contexto partilhado, identificados através da análise do corpo do pedido, para a mesma réplica do modelo, maximizando os resultados da cache. Esta abordagem reduz drasticamente os cálculos redundantes e melhora o tempo até ao primeiro token, tornando-a altamente eficaz para IA conversacional, geração aumentada de recuperação (RAG) e outras cargas de trabalho de IA generativa baseadas em modelos. - Serviço de modelos otimizados com LoRA dinâmicos: suporta o serviço de modelos otimizados com LoRA dinâmicos num acelerador comum. Isto reduz o número de GPUs e TPUs necessários para publicar modelos através da multiplexagem de vários modelos com ajuste fino de LoRA num modelo base comum e num acelerador.
- Escala automática otimizada para inferência: o GKE Horizontal Pod Autoscaler (HPA) usa métricas do servidor de modelos para escala automática, o que ajuda a garantir a utilização eficiente dos recursos de computação e o desempenho de inferência otimizado.
- Encaminhamento com reconhecimento de modelos: encaminha pedidos de inferência com base nos nomes dos modelos definidos nas
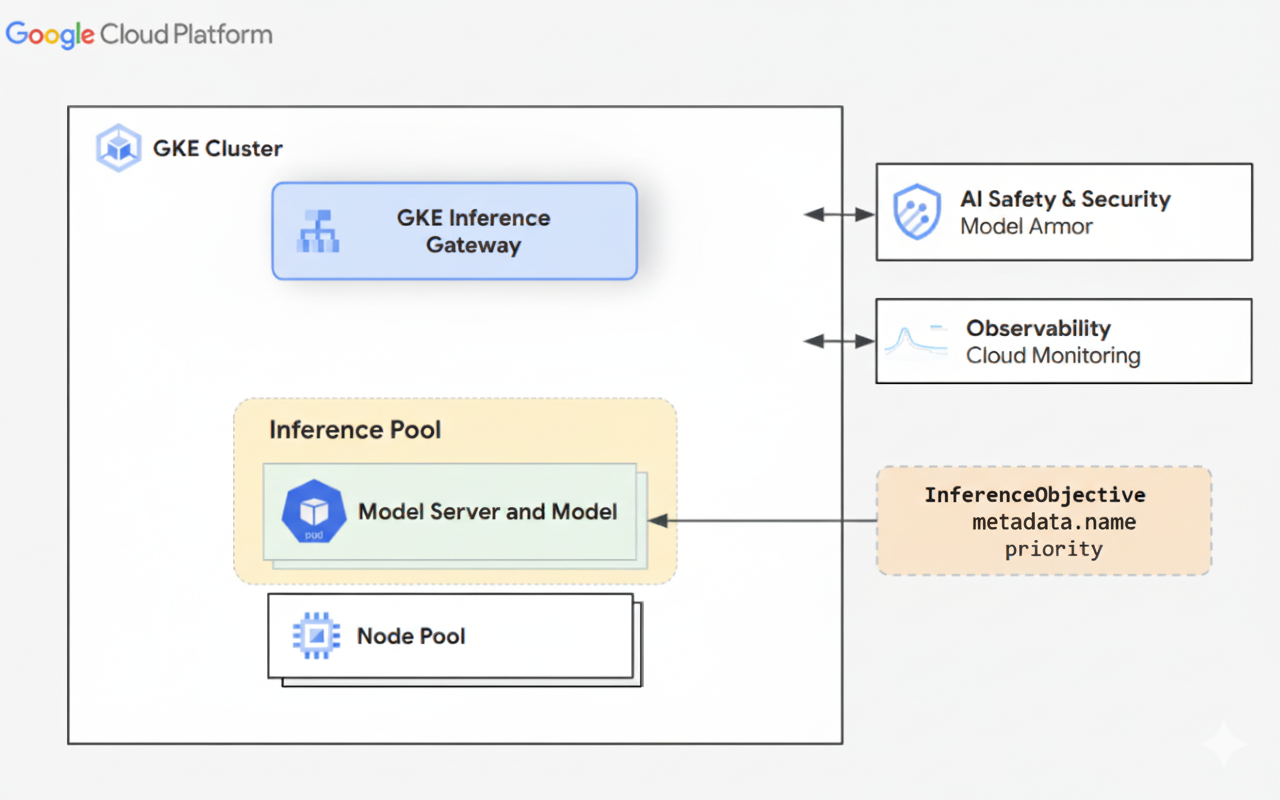
OpenAI APIespecificações no seu cluster do GKE. Pode definir políticas de encaminhamento de gateway, como a divisão de tráfego e a replicação de pedidos, para gerir diferentes versões de modelos e simplificar as implementações de modelos. Por exemplo, pode encaminhar pedidos de um nome de modelo específico para diferentesInferencePoolobjetos, cada um a publicar uma versão diferente do modelo. Para mais informações sobre como configurar esta opção, consulte o artigo Configure o encaminhamento baseado no corpo. - Segurança da IA e filtragem de conteúdo integradas: o GKE Inference Gateway integra-se com o Google Cloud Model Armor para aplicar verificações de segurança da IA e filtragem de conteúdo a comandos e respostas no gateway. O Model Armor fornece registos de pedidos, respostas e processamento para análise e otimização retrospetivas. As interfaces abertas do GKE Inference Gateway permitem que os fornecedores e os programadores de terceiros integrem serviços personalizados no processo de pedido de inferência.
- Apresentação específica do modelo
Priority: permite especificar a apresentaçãoPriorityde modelos de IA. Priorize os pedidos sensíveis à latência em relação às tarefas de inferência em lote tolerantes à latência. Por exemplo, pode dar prioridade a pedidos de aplicações sensíveis à latência e ignorar tarefas menos sensíveis ao tempo quando os recursos são limitados. - Observabilidade da inferência: fornece métricas de observabilidade para pedidos de inferência, como a taxa de pedidos, a latência, os erros e a saturação. Monitorize o desempenho e o comportamento dos seus serviços de inferência através do Cloud Monitoring e do Cloud Logging, tirando partido de painéis de controlo pré-criados especializados para obter estatísticas detalhadas. Para mais informações, consulte o artigo Veja o painel de controlo do GKE Inference Gateway.
- Gestão avançada de APIs com o Apigee: integra-se com o Apigee para melhorar a sua gateway de inferência com funcionalidades como segurança de APIs, limites de taxa e quotas. Para ver instruções detalhadas, consulte o artigo Configure o Apigee para autenticação e gestão de APIs.
- Extensibilidade: criada com base numa extensão de inferência da API Kubernetes Gateway de código aberto e extensível que suporta um algoritmo de seleção de pontos finais gerido pelo utilizador.
Compreenda os conceitos principais
O GKE Inference Gateway melhora o GKE
Gateway existente que usa objetos GatewayClass. O GKE Inference Gateway introduz as seguintes novas
Definições de recursos personalizados (CRDs) da API Gateway, alinhadas com a extensão da API Gateway do Kubernetes OSS para
inferência:
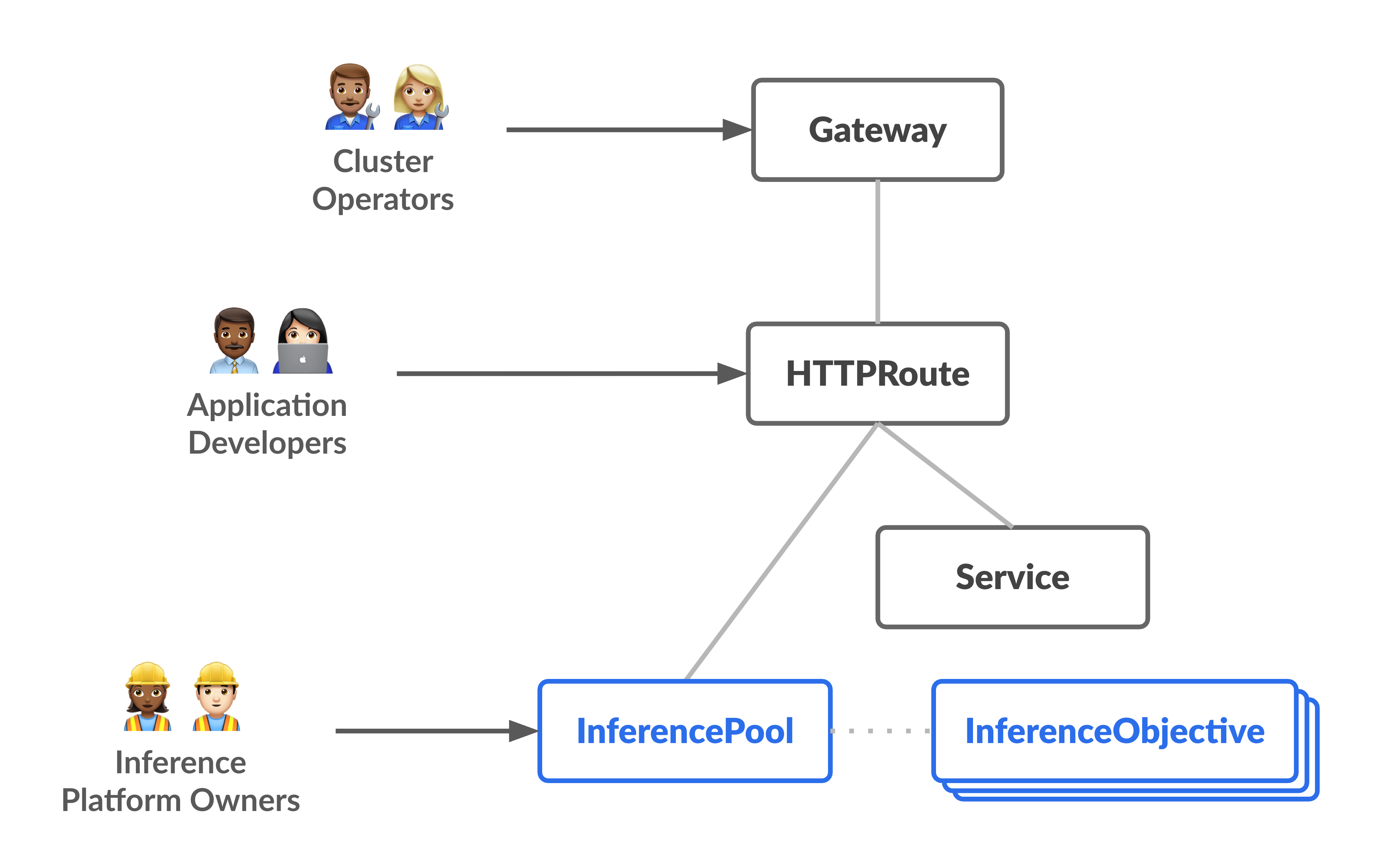
- Objeto
InferencePool: representa um grupo de pods (contentores) que partilham a mesma configuração de computação, tipo de acelerador, modelo de linguagem base e servidor de modelos. Isto agrupa e gere logicamente os recursos de publicação do modelo de IA. Um único objetoInferencePoolpode abranger vários pods em diferentes nós do GKE e oferece escalabilidade e alta disponibilidade. InferenceObjectiveobject: especifica o nome do modelo de publicação a partir doInferencePoolde acordo com a especificaçãoOpenAI API. O objetoInferenceObjectivetambém especifica as propriedades de publicação do modelo, como oPrioritydo modelo de IA. O GKE Inference Gateway dá preferência a cargas de trabalho com um valor de prioridade mais elevado. Isto permite-lhe multiplexar cargas de trabalho de IA sensíveis à latência e tolerantes à latência num cluster do GKE. Também pode configurar o objetoInferenceObjectivepara publicar modelos com ajuste preciso de LoRA.
O diagrama seguinte ilustra o GKE Inference Gateway e a respetiva integração com a segurança, a observabilidade e o serviço de modelos de IA num cluster do GKE.
O diagrama seguinte ilustra o modelo de recursos que se foca em duas personagens centradas na inferência e nos recursos que gerem.
Como funciona o GKE Inference Gateway
O GKE Inference Gateway usa extensões da API Gateway e lógica de encaminhamento específica do modelo para processar pedidos de clientes a um modelo de IA. Os passos seguintes descrevem o fluxo de pedidos.
Como funciona o fluxo de pedidos
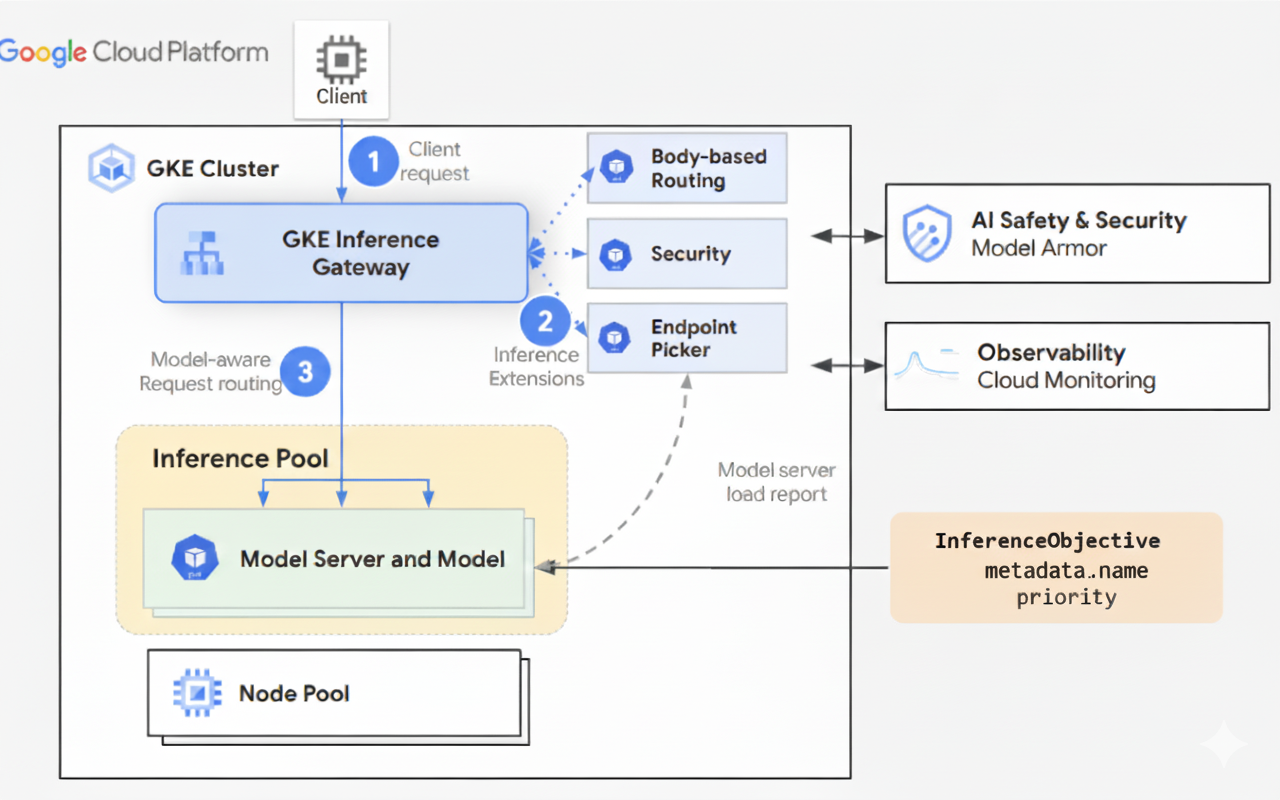
O GKE Inference Gateway encaminha os pedidos do cliente do pedido inicial para uma instância do modelo. Esta secção descreve como o GKE Inference Gateway processa os pedidos. Este fluxo de pedidos é comum a todos os clientes.
- O cliente envia um pedido, formatado conforme descrito na especificação da API OpenAI, para o modelo em execução no GKE.
- O GKE Inference Gateway processa o pedido através das seguintes
extensões de inferência:
- Extensão de encaminhamento baseado no corpo: extrai o identificador do modelo do corpo do pedido do cliente e envia-o para o GKE Inference Gateway.
Em seguida, o GKE Inference Gateway usa este identificador para encaminhar o pedido com base nas regras definidas no objeto
HTTPRouteda API Gateway. O encaminhamento do corpo do pedido é semelhante ao encaminhamento com base no caminho do URL. A diferença é que o encaminhamento do corpo do pedido usa dados do corpo do pedido. - Extensão de segurança: usa o Model Armor ou soluções de terceiros suportadas para aplicar políticas de segurança específicas do modelo, que incluem filtragem de conteúdo, deteção de ameaças, saneamento e registo. A extensão de segurança aplica estas políticas aos caminhos de processamento de pedidos e respostas.
- Extensão do selecionador de pontos finais: monitoriza as principais métricas dos servidores de modelos
no
InferencePool. Monitoriza a utilização da cache de chave-valor (KV-cache), o comprimento da fila de pedidos pendentes, os índices da cache de prefixos e os adaptadores LoRA ativos em cada servidor de modelos. Em seguida, encaminha o pedido para a réplica do modelo ideal com base nestas métricas para minimizar a latência e maximizar o débito para a inferência de IA.
- Extensão de encaminhamento baseado no corpo: extrai o identificador do modelo do corpo do pedido do cliente e envia-o para o GKE Inference Gateway.
Em seguida, o GKE Inference Gateway usa este identificador para encaminhar o pedido com base nas regras definidas no objeto
- O GKE Inference Gateway encaminha o pedido para a réplica do modelo devolvida pela extensão do selecionador de pontos finais.
O diagrama seguinte ilustra o fluxo de pedidos de um cliente para uma instância de modelo através do GKE Inference Gateway.
Como funciona a distribuição de tráfego
O GKE Inference Gateway distribui dinamicamente os pedidos de inferência para servidores de modelos no objeto InferencePool. Isto ajuda a otimizar a utilização de recursos e mantém o desempenho em condições de carga variáveis.
O GKE Inference Gateway usa os dois mecanismos seguintes para gerir a distribuição de tráfego:
Escolha do ponto final: seleciona dinamicamente o servidor de modelos mais adequado para processar um pedido de inferência. Monitoriza a carga e a disponibilidade do servidor e, em seguida, toma decisões de encaminhamento ideais calculando um
scorepara cada servidor, combinando várias heurísticas de otimização:- Encaminhamento com reconhecimento da cache de prefixos: o GKE Inference Gateway monitoriza os índices da cache de prefixos disponíveis em cada servidor de modelos e atribui uma pontuação mais elevada a um servidor com uma correspondência da cache de prefixos mais longa.
- Encaminhamento com reconhecimento da carga: o GKE Inference Gateway monitoriza a carga do servidor (utilização da cache KV e profundidade da fila pendente) e atribui uma pontuação mais elevada a um servidor com uma carga inferior.
- Encaminhamento com reconhecimento de LoRA: quando a publicação dinâmica de LoRA está ativada, o GKE Inference Gateway monitoriza os adaptadores LoRA ativos por servidor e atribui uma pontuação mais elevada a um servidor com o adaptador LoRA pedido ativo ou espaço adicional para carregar dinamicamente o adaptador LoRA pedido. É selecionado um servidor com a pontuação total mais elevada de todos os itens anteriores.
Colocação em fila e eliminação: gere o fluxo de pedidos e evita a sobrecarga de tráfego. O GKE Inference Gateway armazena os pedidos recebidos numa fila e prioriza os pedidos com base na prioridade definida.
O GKE Inference Gateway usa um sistema numérico Priority, também conhecido como Criticality, para gerir o fluxo de pedidos e evitar a sobrecarga. Este Priority é um campo de número inteiro opcional definido pelo utilizador para cada InferenceObjective. Um valor mais elevado significa um pedido mais importante. Quando o sistema está sob pressão, os pedidos com um Priority inferior a 0 são considerados de prioridade inferior e são rejeitados primeiro, devolvendo um erro 429 para proteger cargas de trabalho mais críticas. Por predefinição, o valor de Priority é 0. Os pedidos só são ignorados devido à prioridade se o respetivo Priority estiver explicitamente definido para um valor inferior a 0. Este sistema permite-lhe dar prioridade ao tráfego de inferência online sensível à latência em detrimento de tarefas em lote menos sensíveis ao tempo.
O GKE Inference Gateway suporta a inferência de streaming para aplicações como chatbots e tradução em direto, que requerem atualizações contínuas ou quase em tempo real. A inferência de streaming envia respostas em partes ou segmentos incrementais, em vez de um único resultado completo. Se ocorrer um erro durante uma resposta de streaming, a stream termina e o cliente recebe uma mensagem de erro. O GKE Inference Gateway não tenta novamente as respostas de streaming.
Explore exemplos de aplicações
Esta secção fornece exemplos de utilização do GKE Inference Gateway para abordar vários cenários de aplicação de IA generativa.
Exemplo 1: disponibilize vários modelos de IA generativa num cluster do GKE
Uma empresa quer implementar vários modelos de linguagem (conteúdo extenso) (MDIs/CEs) para servir diferentes cargas de trabalho. Por exemplo, podem querer implementar um modelo Gemma3 para uma interface de chatbot e um modelo Deepseek para uma aplicação de recomendações. A empresa tem de garantir um desempenho de publicação ideal para estes MDIs.
Com o GKE Inference Gateway, pode implementar estes MDIs no seu cluster do GKE com a configuração do acelerador escolhida num InferencePool. Em seguida, pode encaminhar pedidos com base no nome do modelo (como chatbot e recommender) e na propriedade Priority.
O diagrama seguinte ilustra como o GKE Inference Gateway encaminha pedidos para diferentes modelos com base no nome do modelo e no Priority.
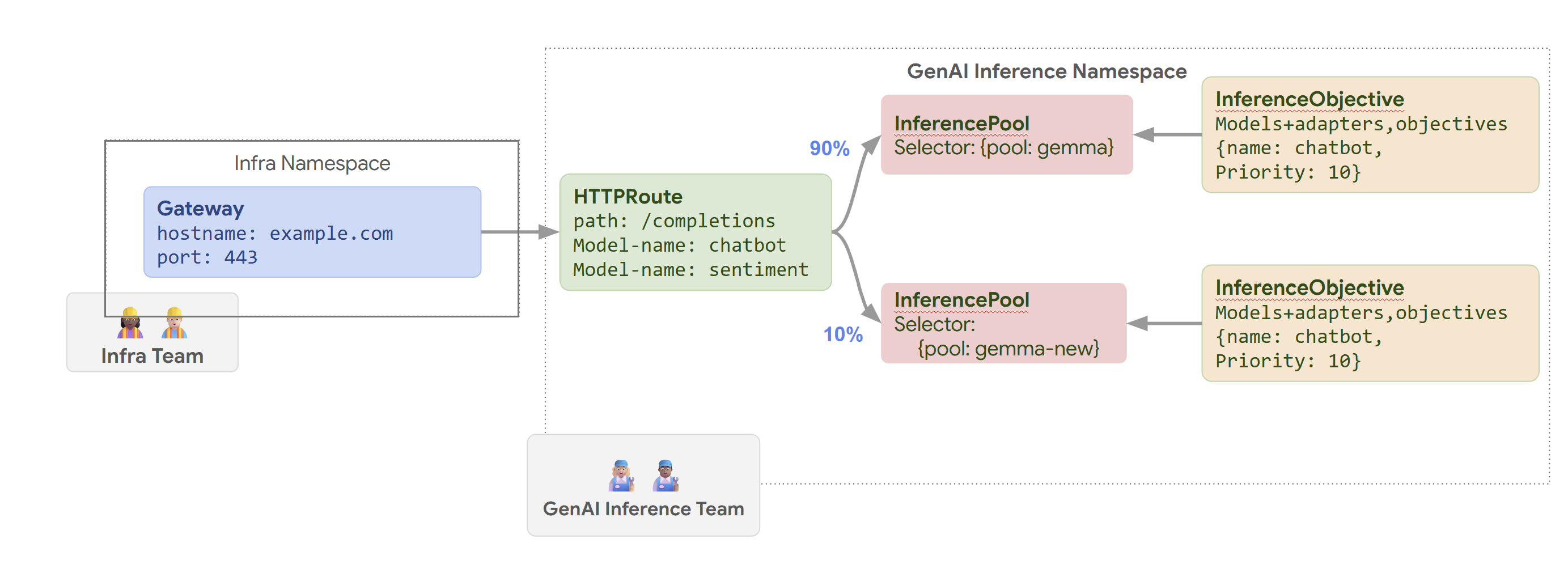
Este diagrama ilustra como um pedido a um serviço de IA gen em example.com/completions é processado pelo GKE Inference Gateway. O pedido
chega primeiro a um Gateway no espaço de nomes Infra. Este Gateway encaminha o pedido para um HTTPRoute no espaço de nomes GenAI Inference, que está configurado para processar pedidos de modelos de chatbot e de análise de sentimentos. Para o modelo de chatbot, o HTTPRoute divide o tráfego: 90% é direcionado para um InferencePool que executa a versão do modelo atual (selecionada por {pool: gemma}) e 10% é direcionado para um conjunto com uma versão mais recente ({pool: gemma-new}), normalmente para testes canary.
Ambos os conjuntos estão associados a um InferenceObjective que atribui uma Priority de 10 a pedidos para o modelo de chatbot, garantindo que estes pedidos são tratados como de alta prioridade.
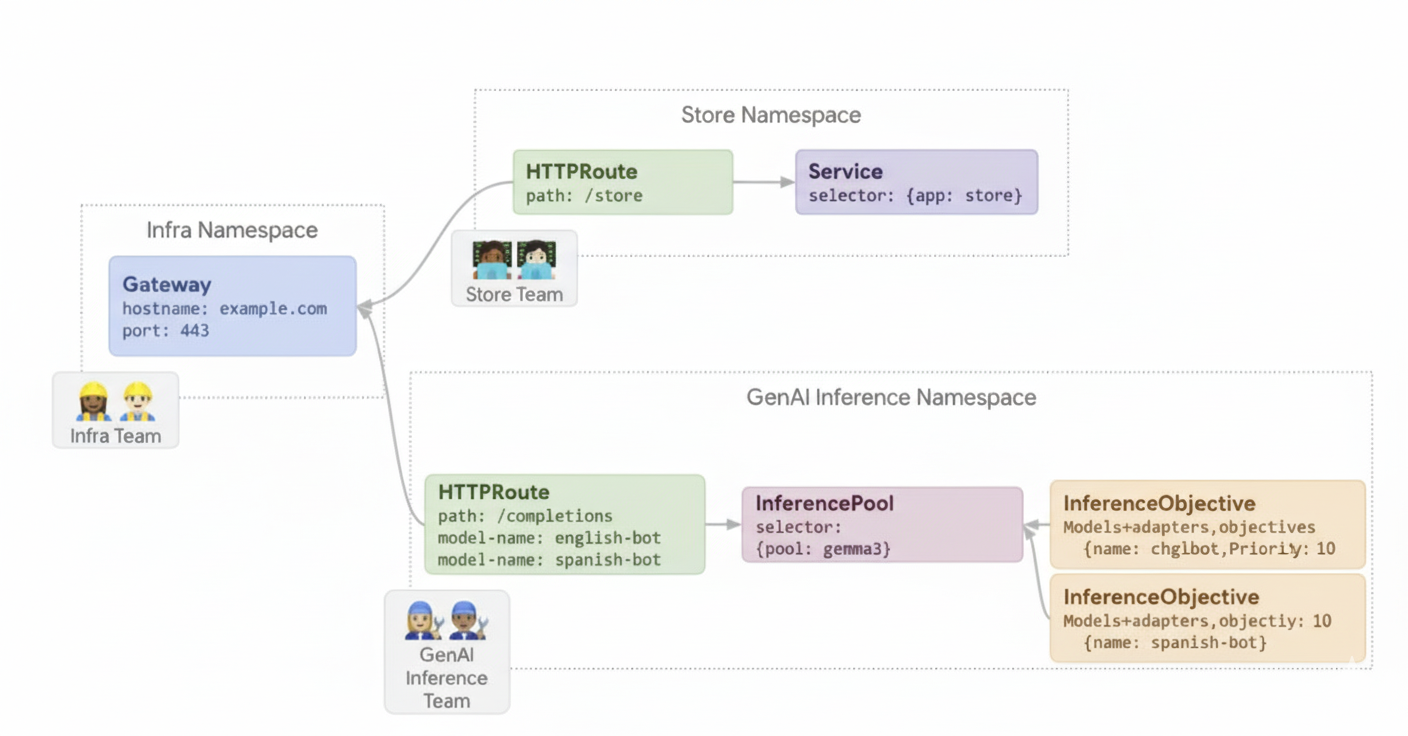
Exemplo 2: disponibilize adaptadores LoRA num acelerador partilhado
Uma empresa quer publicar MDIs para análise de documentos e foca-se em públicos-alvo em vários idiomas, como inglês e espanhol. Têm modelos otimizados para cada idioma, mas precisam de usar de forma eficiente a capacidade da GPU e da TPU. Pode usar o GKE Inference Gateway para implementar adaptadores de ajuste fino LoRA dinâmicos para cada idioma (por exemplo, english-bot e spanish-bot) num modelo base comum (por exemplo, llm-base) e acelerador. Isto permite-lhe reduzir o número de aceleradores necessários ao agrupar vários modelos num acelerador comum.
O diagrama seguinte ilustra como o GKE Inference Gateway publica vários adaptadores LoRA num acelerador partilhado.
O que se segue?
- Implemente o GKE Inference Gateway
- Personalize a configuração do GKE Inference Gateway
- Publique um MDG com o GKE Inference Gateway