Visão geral do Config Sync
O Config Sync é um serviço do GitOps oferecido como parte do Google Kubernetes Engine (GKE) Enterprise. O Config Sync é baseado em um núcleo de código aberto e permite que operadores de cluster e administradores de plataforma implantem configurações de uma fonte de verdade. O serviço tem flexibilidade para ser compatível com um ou vários clusters e qualquer número de repositórios por cluster ou namespace. Os clusters podem estar em um ambiente híbrido ou de várias nuvens.
O Config Sync está disponível com uma licença do Google Kubernetes Engine (GKE) Enterprise.
Benefícios do Config Sync
A metodologia GitOps é considerada uma prática recomendada universal para organizações que gerenciam a configuração do Kubernetes em escala. Os benefícios da melhoria da estabilidade, da legibilidade, da consistência, da auditoria e da segurança são comuns a todas as ferramentas do GitOps. O Config Sync faz parte do Google Kubernetes Engine (GKE) Enterprise, que oferece um conjunto de vantagens exclusivas:
- Integrado com a edição Google Kubernetes Engine (GKE) Enterprise: os administradores da plataforma podem instalar o Config Sync com alguns cliques no console do Google Cloud, usando o Terraform ou a Google Cloud CLI em qualquer cluster conectado à sua frota. O serviço está pré-configurado para funcionar com outras edições do Google Kubernetes Engine (GKE) Enterprise e serviços do Google Cloud, como o Policy Controller, a Identidade da carga de trabalho e o Cloud Monitoring.
- Observabilidade integrada: o Config Sync tem um painel de observabilidade integrado ao console do Google Cloud, que não requer nenhuma configuração adicional. Os administradores da plataforma podem ver o estado da sincronização e reconciliação acessando o console do Google Cloud ou usando a Google Cloud CLI.
- Suporte a várias nuvens e nuvens híbridas: o Config Sync foi testado em vários provedores de nuvem e em ambientes híbridos antes de cada versão de disponibilidade geral. Para visualizar a matriz de suporte, consulte Versão do Google Kubernetes Engine (GKE) Enterprise e upgrade do suporte.
Noções básicas do Config Sync
O diagrama a seguir mostra uma visão geral de como as equipes podem sincronizar os clusters com um único repositório raiz (gerenciado por um administrador) e vários repositórios de namespace (gerenciados pelos operadores do aplicativo):
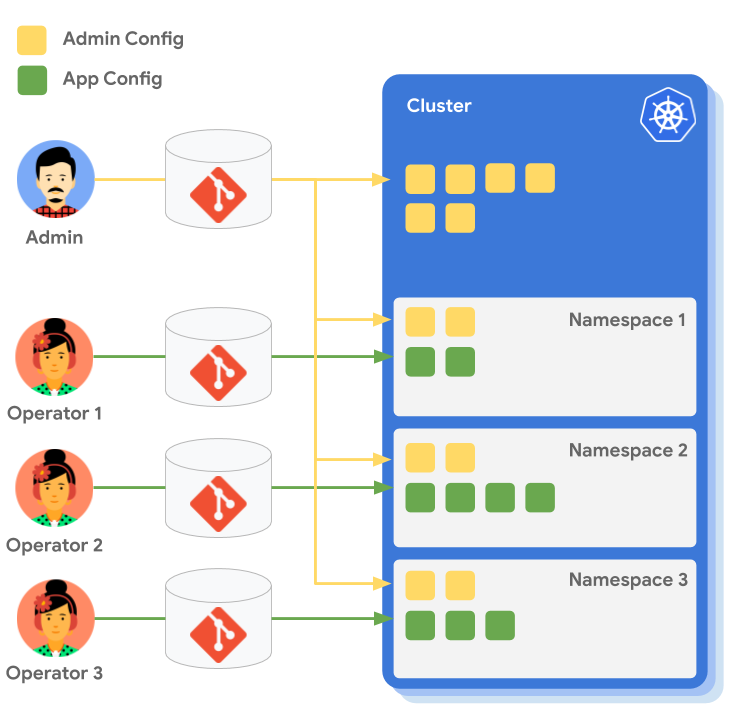
Um administrador central gerencia a infraestrutura centralizada da organização e aplica políticas no cluster e em todos os namespaces na organização. Os operadores do aplicativo, que são responsáveis por gerenciar implantações ativas, aplicam configurações aos aplicativos nos namespaces em que trabalham.
Configurar clusters
O Config Sync permite criar um conjunto comum de configurações e políticas, como restrições do Policy Controller, e aplicá-las de forma consistente em clusters registrados e conectados de uma única fonte de verdade.
Em vez de executar repetidamente o comando kubectl apply manualmente, é possível orquestrar a implantação de mudanças de configuração nas frotas de clusters usando ferramentas no estilo GitOps. Para mais informações, consulte
Lançamentos seguros com o Config Sync.
Embora este e outros tutoriais usem um repositório Git como fonte da verdade, também é possível usar uma imagem OCI ou um gráfico do Helm.
Como configurar namespaces
A configuração de namespaces com o Config Sync fornece os seguintes recursos:
- É possível provisionar namespaces do Kubernetes de maneira consistente com políticas com escopo de namespace, como papéis do RBAC, entre clusters registrados e conectados. Com as políticas com escopo de namespace, é mais fácil implementar e gerenciar a multilocação nos seus clusters.
- Aplicar políticas a vários namespaces relacionados, sem duplicar configurações, e com a capacidade de substituir ou estender um config para um determinado namespace ou conjunto de namespaces, facilitando a aplicação de políticas consistentes em locatários.