Comprendere le letture e le scritture su larga scala
Leggi questo documento per prendere decisioni informate sulla progettazione delle tue applicazioni per ottenere prestazioni e affidabilità elevate. Questo documento include argomenti avanzati di Firestore. Se hai appena iniziato a utilizzare Firestore, consulta la guida rapida.
Firestore è un database flessibile e scalabile per lo sviluppo di app web, mobile e server di Firebase e Google Cloud. È molto facile iniziare a utilizzare Firestore e scrivere applicazioni ricche e potenti.
Per assicurarti che le tue applicazioni continuino a funzionare bene man mano che le dimensioni e il traffico del database aumentano, è utile comprendere il meccanismo di lettura e scrittura nel backend di Firestore. Devi anche comprendere l'interazione delle operazioni di lettura e scrittura con il livello di archiviazione e i vincoli sottostanti che potrebbero influire sulle prestazioni.
Prima di progettare l'applicazione, consulta le sezioni seguenti per le best practice.
Comprendere i componenti di alto livello
Il seguente diagramma mostra i componenti di alto livello coinvolti in una richiesta API Firestore.
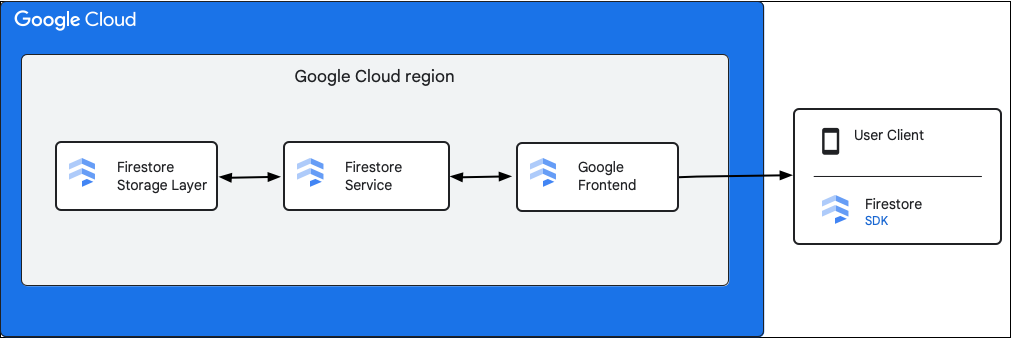
SDK e librerie client di Firestore
Firestore supporta SDK e librerie client per piattaforme diverse. Sebbene un'app possa effettuare chiamate HTTP e RPC dirette all'API Firestore, le librerie client forniscono un livello di astrazione per semplificare l'utilizzo dell'API e implementare le best practice. Potrebbero anche fornire funzionalità aggiuntive come l'accesso offline, le cache e così via.
Google Front End (GFE)
Si tratta di un servizio di infrastruttura comune a tutti i servizi cloud Google. Il GFE accetta le richieste in entrata e le inoltra al servizio Google pertinente (in questo contesto, il servizio Firestore). Fornisce inoltre altre importanti funzionalità, tra cui la protezione dagli attacchi Denial of Service.
Servizio Firestore
Il servizio Firestore esegue controlli sulla richiesta API, che includono autenticazione, autorizzazione, controlli delle quote e regole di sicurezza, e gestisce anche le transazioni. Questo servizio Firestore include un client di archiviazione che interagisce con il livello di archiviazione per le letture e le scritture dei dati.
Livello di archiviazione Firestore
Il livello di archiviazione Firestore è responsabile dell'archiviazione dei dati e dei metadati, nonché delle funzionalità del database associate fornite da Firestore. Le sezioni seguenti descrivono come vengono organizzati i dati nel livello di archiviazione Firestore e come viene scalato il sistema. Comprendere come sono organizzati i dati può aiutarti a progettare un modello dei dati scalabile e a comprendere meglio le best practice in Firestore.
Intervalli e divisioni delle chiavi
un database NoSQL orientato ai documenti. I dati vengono archiviati in documenti, organizzati in gerarchie di raccolte. La gerarchia delle raccolte e l'ID documento vengono tradotti in una singola chiave per ogni documento. I documenti vengono archiviati e ordinati in modo logico in ordine lessicografico in base a questa singola chiave. Utilizziamo il termine intervallo di chiavi per indicare un intervallo di chiavi contigue in ordine lessicografico.
Un tipico database Firestore è troppo grande per essere contenuto in una singola macchina fisica. Esistono anche scenari in cui il carico di lavoro sui dati è troppo pesante per una singola macchina. Per gestire carichi di lavoro di grandi dimensioni, Firestore partiziona i dati in parti separate che possono essere archiviate e gestite da più macchine o server di archiviazione. Queste partizioni vengono create nelle tabelle del database in blocchi di intervalli di chiavi chiamati suddivisioni.
Replica sincrona
È importante notare che il database viene sempre replicato automaticamente e in modo sincrono. Le suddivisioni dei dati hanno repliche in zone diverse per mantenerle disponibili anche quando una zona diventa inaccessibile. La replica coerente nelle diverse copie della suddivisione viene gestita dall'algoritmo Paxos per il consenso. Una replica di ogni split viene scelta per fungere da leader Paxos, responsabile della gestione delle scritture in quello split. La replica sincrona ti consente di leggere sempre l'ultima versione dei dati da Firestore.
Il risultato complessivo è un sistema scalabile e a disponibilità elevata che offre basse latenze sia per le letture che per le scritture, indipendentemente dai carichi di lavoro elevati e su larga scala.
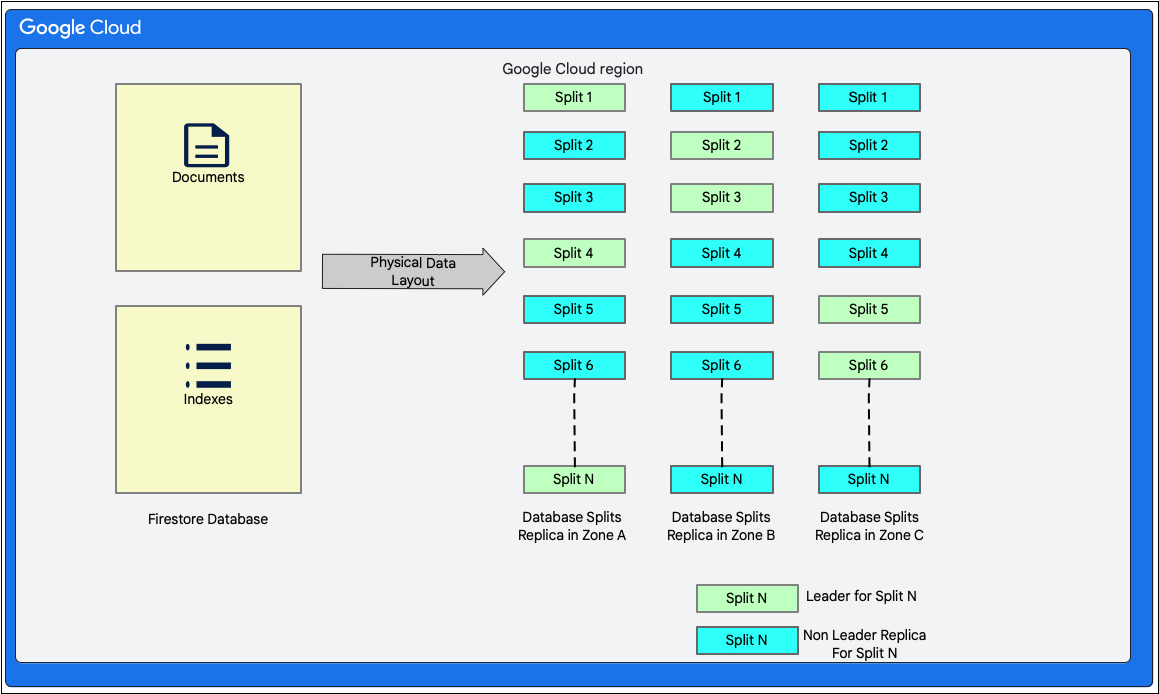
Layout dei dati
Firestore è un database di documenti senza schema. Tuttavia, internamente organizza i dati principalmente in due tabelle in stile database relazionale nel livello di archiviazione nel seguente modo:
- Tabella Documents: i documenti sono archiviati in questa tabella.
- Tabella Indici: in questa tabella vengono memorizzate le voci di indice che consentono di ottenere risultati in modo efficiente e ordinati per valore dell'indice.
Il seguente diagramma mostra come potrebbero apparire le tabelle di un database Firestore con le suddivisioni. Le suddivisioni vengono replicate in tre zone diverse e a ognuna viene assegnato un leader Paxos.
Regione singola e multiregionale
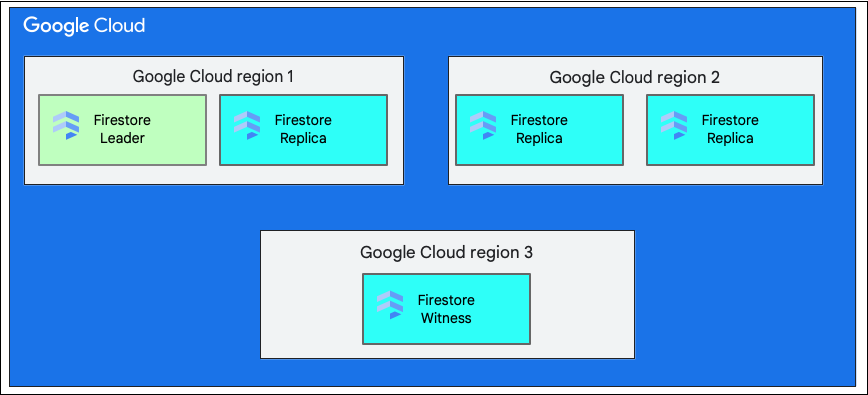
Quando crei un database, devi selezionare una regione o una multiregione.
Una singola località regionale è una posizione geografica specifica, ad esempio us-west1. Le suddivisioni dei dati di un database Firestore hanno repliche in zone diverse all'interno della regione selezionata, come spiegato in precedenza.
Una località multiregionale è costituita da un insieme definito di regioni in cui sono archiviate le repliche del database. In un deployment multiregionale di Firestore, due delle regioni hanno repliche complete di tutti i dati nel database. Una terza regione ha una replica di testimonianza che non mantiene un set completo di dati, ma partecipa alla replica. Replicando i dati tra più regioni, i dati sono disponibili per la scrittura e la lettura anche in caso di perdita di un'intera regione.
Per saperne di più sulle località di una regione, consulta Località Firestore.
Comprendere il ciclo di vita di una scrittura in Firestore
Un client Firestore può scrivere dati creando, aggiornando o eliminando un singolo documento. Una scrittura in un singolo documento richiede l'aggiornamento atomico sia del documento sia delle voci di indice associate nel livello di archiviazione. Firestore supporta anche operazioni atomiche costituite da più letture e/o scritture in uno o più documenti.
Per tutti i tipi di scrittura, Firestore fornisce le proprietà ACID (atomicità, coerenza, isolamento e durabilità) dei database relazionali. Firestore fornisce anche la serializzabilità, il che significa che tutte le transazioni vengono eseguite in ordine seriale.
Passaggi di alto livello in una transazione di scrittura
Quando il client Firestore esegue una scrittura o esegue il commit di una transazione utilizzando uno dei metodi menzionati in precedenza, internamente questa operazione viene eseguita come transazione di lettura/scrittura del database nel livello di archiviazione. La transazione consente a Firestore di fornire le proprietà ACID menzionate in precedenza.
Come primo passaggio di una transazione, Firestore legge il documento esistente e determina le mutazioni da apportare ai dati nella tabella Documents.
Ciò include anche l'apporto degli aggiornamenti necessari alla tabella Indici come segue:
- I campi che vengono aggiunti ai documenti devono avere inserimenti corrispondenti nella tabella Indici.
- I campi che vengono rimossi dai documenti devono essere eliminati anche nella tabella Indici.
- I campi che vengono modificati nei documenti richiedono sia eliminazioni (per i valori precedenti) sia inserimenti (per i nuovi valori) nella tabella Indici.
Per calcolare le mutazioni menzionate in precedenza, Firestore legge la configurazione dell'indicizzazione per il progetto. La configurazione dell'indicizzazione memorizza le informazioni sugli indici di un progetto. Firestore utilizza due tipi di indici: a campo singolo e composti. Per una comprensione dettagliata degli indici creati in Firestore, consulta la sezione Tipi di indice in Firestore.
Una volta calcolate le mutazioni, Firestore le raccoglie all'interno di una transazione e poi le esegue.
Comprendere una transazione di scrittura nel livello di archiviazione
Come spiegato in precedenza, una scrittura in Firestore comporta una transazione di lettura-scrittura nel livello di archiviazione. A seconda del layout dei dati, una scrittura potrebbe comportare una o più suddivisioni, come mostrato nel layout dei dati.
Nel seguente diagramma, il database Firestore ha otto suddivisioni (contrassegnate con i numeri 1-8) ospitate su tre diversi server di archiviazione in una singola zona e ogni suddivisione viene replicata in tre(o più) zone diverse. Ogni split ha un leader Paxos, che potrebbe trovarsi in una zona diversa per split diversi.
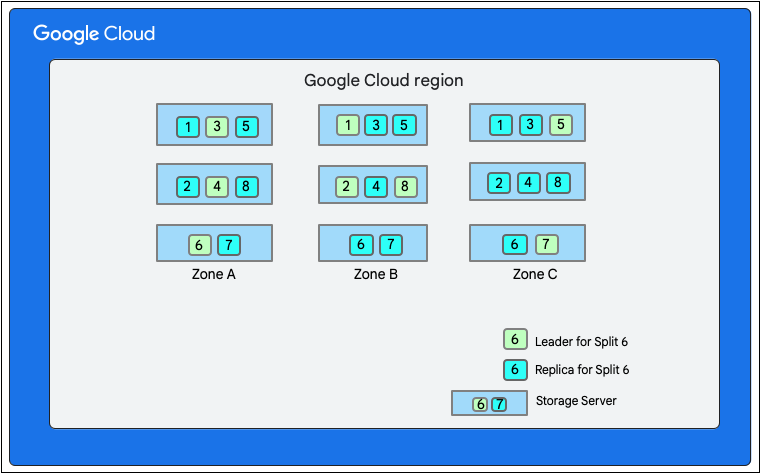
Considera un database Firestore con la raccolta Restaurants come segue:
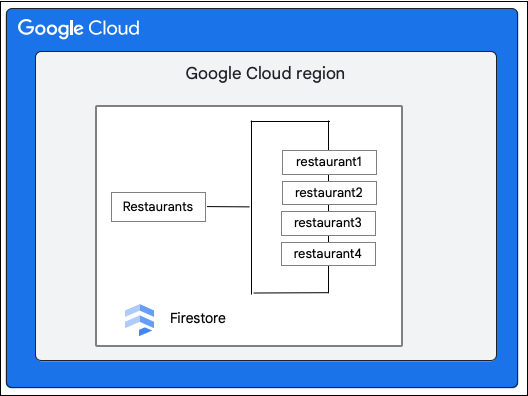
Il client Firestore richiede la seguente modifica a un documento nella raccolta Restaurant aggiornando il valore del campo priceCategory.
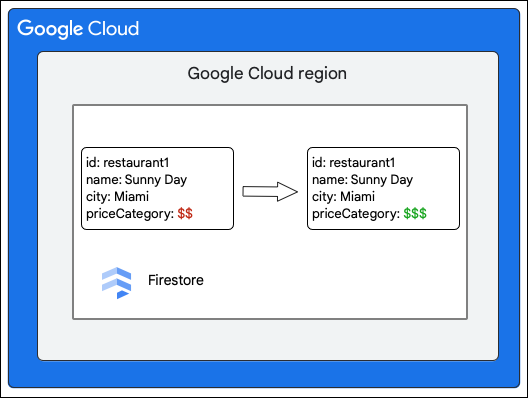
I seguenti passaggi di alto livello descrivono cosa succede durante la scrittura:
- Crea una transazione di lettura/scrittura.
- Leggi il documento
restaurant1nella raccoltaRestaurantsdalla tabella Documenti del livello di archiviazione. - Leggi gli indici del documento dalla tabella Indici.
- Calcola le modifiche da apportare ai dati. In questo caso, ci sono cinque mutazioni:
- M1: aggiorna la riga relativa a
restaurant1nella tabella Documenti in modo che rifletta la modifica del valore del campopriceCategory. - M2 e M3: elimina le righe per il vecchio valore di
priceCategorynella tabella Indici per gli indici decrescenti e crescenti. - M4 e M5: inserisci le righe per il nuovo valore di
priceCategorynella tabella Indici per gli indici decrescenti e crescenti.
- M1: aggiorna la riga relativa a
- Esegui il commit di queste mutazioni.
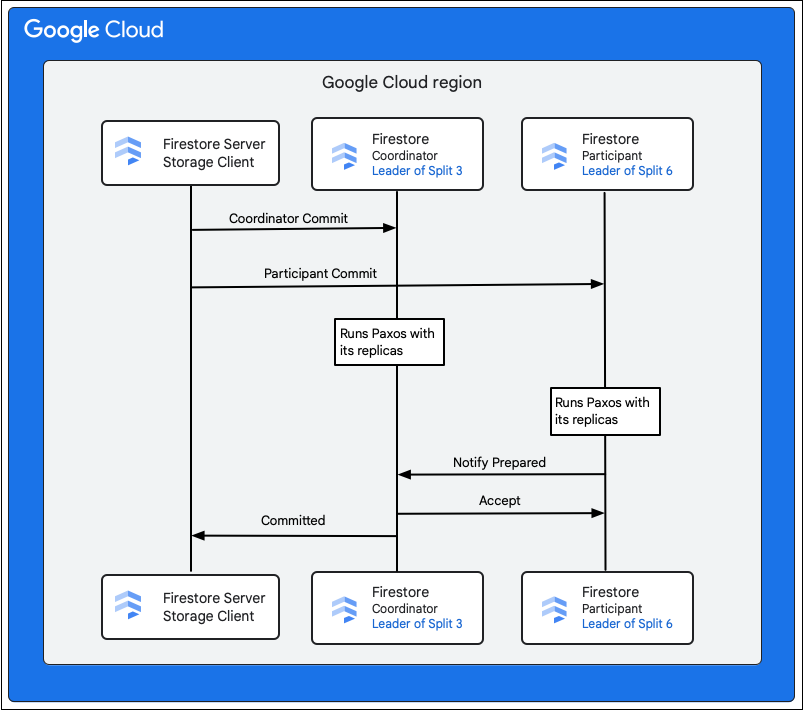
Il client di archiviazione nel servizio Firestore cerca le suddivisioni che possiedono le chiavi delle righe da modificare. Consideriamo un caso in cui Split 3 gestisce M1 e Split 6 gestisce M2-M5. Esiste una transazione distribuita, che coinvolge tutte queste suddivisioni come partecipanti. Le suddivisioni dei partecipanti possono includere anche qualsiasi altra suddivisione da cui sono stati letti i dati in precedenza nell'ambito della transazione di lettura/scrittura.
I seguenti passaggi descrivono cosa succede durante il commit:
- Il client di archiviazione emette un commit. Il commit contiene le mutazioni M1-M5.
- Le divisioni 3 e 6 sono i partecipanti a questa transazione. Uno dei partecipanti viene scelto come coordinatore, ad esempio Split 3. Il compito del coordinatore è assicurarsi che la transazione venga eseguita o interrotta in modo atomico per tutti i partecipanti.
- Le repliche leader di queste suddivisioni sono responsabili del lavoro svolto dai partecipanti e dai coordinatori.
- Ogni partecipante e coordinatore esegue un algoritmo Paxos con le rispettive repliche.
- Il leader esegue un algoritmo Paxos con le repliche. Il quorum viene raggiunto se la maggior parte delle repliche risponde al leader con una risposta
ok to commit. - Ogni partecipante comunica al coordinatore quando è pronto (prima fase del commit in due fasi). Se un partecipante non può eseguire il commit della transazione, l'intera transazione
aborts.
- Il leader esegue un algoritmo Paxos con le repliche. Il quorum viene raggiunto se la maggior parte delle repliche risponde al leader con una risposta
- Una volta che il coordinatore sa che tutti i partecipanti, incluso se stesso, sono pronti, comunica il risultato della transazione
accepta tutti i partecipanti (seconda fase del commit in due fasi). In questa fase, ogni partecipante registra la decisione di commit in una memoria stabile e la transazione viene eseguita. - Il coordinatore risponde al client di archiviazione in Firestore che la transazione è stata eseguita. Parallelamente, il coordinatore e tutti i partecipanti applicano le modifiche ai dati.
Quando il database Firestore è piccolo, può succedere che una singola suddivisione possieda tutte le chiavi nelle mutazioni M1-M5. In questo caso, nella transazione è presente un solo partecipante e non è necessario il commit in due fasi menzionato in precedenza, il che rende le scritture più veloci.
Scritture in più regioni
In un deployment multiregionale, la distribuzione delle repliche tra le regioni aumenta la disponibilità, ma comporta un costo in termini di prestazioni. La comunicazione tra le repliche in regioni diverse richiede tempi di andata e ritorno più lunghi. Pertanto, la latenza di base per le operazioni Firestore è leggermente superiore rispetto ai deployment in una singola regione.
Configuriamo le repliche in modo che la leadership per le suddivisioni rimanga sempre nella regione principale. La regione principale è quella da cui il traffico in entrata arriva al server Firestore. Questa decisione della leadership riduce il ritardo di round trip nella comunicazione tra il client di archiviazione in Firestore e il leader della replica (o il coordinatore per le transazioni multi-split).
Ogni scrittura in Firestore comporta anche un'interazione con il motore in tempo reale di Firestore. Per saperne di più sulle query in tempo reale, consulta Comprendere le query in tempo reale su larga scala.
Informazioni sul ciclo di vita di una lettura in Firestore
Questa sezione esamina le letture autonome e non in tempo reale in Firestore. A livello interno, il server Firestore gestisce la maggior parte di queste query in due fasi principali:
- Una singola scansione dell'intervallo nella tabella Indici
- Ricerca puntuale nella tabella Documenti in base al risultato della scansione precedente
Le letture dei dati dal livello di archiviazione vengono eseguite internamente utilizzando una transazione di database per garantire letture coerenti. Tuttavia, a differenza delle transazioni utilizzate per le scritture, queste transazioni non acquisiscono blocchi. Funzionano invece scegliendo un timestamp ed eseguendo tutte le letture in corrispondenza di quel timestamp. Poiché non acquisiscono blocchi, non bloccano le transazioni di lettura/scrittura simultanee. Per eseguire questa transazione, il client di archiviazione in Firestore specifica un limite di timestamp, che indica al livello di archiviazione come scegliere un timestamp di lettura. Il tipo di limite temporale scelto dal client di archiviazione in Firestore è determinato dalle opzioni di lettura per la richiesta di lettura.
Comprendere una transazione di lettura nel livello di archiviazione
Questa sezione descrive i tipi di letture e come vengono elaborati nel livello di archiviazione in Firestore.
Letture forti
Per impostazione predefinita, le letture di Firestore sono fortemente coerenti. Questa elevata coerenza significa che una lettura di Firestore restituisce l'ultima versione dei dati che riflette tutte le scritture di cui è stato eseguito il commit fino all'inizio della lettura.
Lettura di una singola divisione
Il client di archiviazione in Firestore cerca le suddivisioni che possiedono le chiavi delle righe da leggere. Supponiamo che debba leggere la divisione 3 dalla sezione precedente. Il client invia la richiesta di lettura alla replica più vicina per ridurre la latenza di andata e ritorno.
A questo punto, a seconda della replica scelta, potrebbero verificarsi i seguenti casi:
- La richiesta di lettura viene inviata a una replica leader (zona A).
- Poiché il leader è sempre aggiornato, la lettura può procedere direttamente.
- La richiesta di lettura viene inviata a una replica non leader (ad esempio, la zona B)
- La suddivisione 3 potrebbe sapere dal suo stato interno di avere informazioni sufficienti per pubblicare la lettura e lo fa.
- Il segmento 3 non è sicuro di aver visualizzato i dati più recenti. Invia un messaggio al leader per richiedere il timestamp dell'ultima transazione che deve applicare per eseguire la lettura. Una volta applicata la transazione, la lettura può procedere.
Firestore restituisce quindi la risposta al client.
Lettura multi-split
Nella situazione in cui le letture devono essere eseguite da più suddivisioni, lo stesso meccanismo si verifica in tutte le suddivisioni. Una volta restituiti i dati da tutte le suddivisioni, il client di archiviazione in Firestore combina i risultati. Firestore risponde quindi al client con questi dati.
Letture dati inattivi
Le letture coerenti sono la modalità predefinita in Firestore. Tuttavia, ciò comporta una latenza potenzialmente maggiore a causa della comunicazione che potrebbe essere necessaria con il leader. Spesso l'applicazione Firestore non ha bisogno di leggere l'ultima versione dei dati e la funzionalità funziona bene con i dati che potrebbero essere obsoleti di qualche secondo.
In questo caso, il client può scegliere di ricevere letture non aggiornate utilizzando le opzioni di lettura read_time. In questo caso, le letture vengono eseguite in base ai dati presenti alle ore read_time e la replica più vicina ha già verificato con alta probabilità di avere dati all'ora read_time specificata.
Per prestazioni notevolmente migliori, 15 secondi è un valore di obsolescenza ragionevole. Anche per le letture non aggiornate, le righe restituite sono coerenti tra loro.
Evita gli hotspot
Le divisioni in Firestore vengono suddivise automaticamente in parti più piccole per distribuire il lavoro di gestione del traffico a più server di archiviazione quando necessario o quando lo spazio delle chiavi si espande. Le suddivisioni create per gestire il traffico in eccesso vengono conservate per circa 24 ore anche se il traffico scompare. Pertanto, se si verificano picchi di traffico ricorrenti, le suddivisioni vengono mantenute e ne vengono introdotte altre quando necessario. Questi meccanismi aiutano i database Firestore a scalare automaticamente in base al carico di traffico o alle dimensioni del database. Tuttavia, ci sono alcune limitazioni di cui tenere conto, come spiegato di seguito.
La suddivisione dell'archiviazione e del carico richiede tempo e l'aumento troppo rapido del traffico può causare latenza elevata o errori di scadenza, comunemente denominati hotspot, mentre il servizio si adegua. La best practice consiste nel distribuire le operazioni nell'intervallo di chiavi, aumentando il traffico su una raccolta in un database con 500 operazioni al secondo. Dopo questo aumento graduale, aumenta il traffico fino al 50% ogni cinque minuti. Questo processo è chiamato regola 500/50/5 e posiziona il database in modo ottimale per scalare in base al carico di lavoro.
Sebbene le suddivisioni vengano create automaticamente con l'aumento del carico, Firestore può suddividere un intervallo di chiavi solo finché non gestisce un singolo documento utilizzando un insieme dedicato di server di archiviazione replicati. Di conseguenza, volumi elevati e sostenuti di operazioni simultanee su un singolo documento possono portare a un hotspot su quel documento. Se riscontri latenze elevate e prolungate su un singolo documento, ti consigliamo di modificare il modello dei dati per dividere o replicare i dati in più documenti.
Gli errori di contesa si verificano quando più operazioni tentano di leggere e/o scrivere contemporaneamente lo stesso documento.
Un altro caso speciale di hotspotting si verifica quando una chiave che aumenta/diminuisce in sequenza viene utilizzata come ID documento in Firestore e il numero di operazioni al secondo è notevolmente elevato. Creare più suddivisioni non è utile in questo caso, perché il picco di traffico si sposta semplicemente nella suddivisione appena creata. Poiché Firestore indicizza automaticamente tutti i campi del documento per impostazione predefinita, questi hotspot mobili possono essere creati anche nello spazio dell'indice per un campo del documento che contiene un valore che aumenta/diminuisce in sequenza, come un timestamp.
Tieni presente che, seguendo le pratiche descritte sopra, Firestore può scalare per gestire workload di dimensioni arbitrarie senza che tu debba modificare alcuna configurazione.
Risoluzione dei problemi
Firestore fornisce Key Visualizer come strumento di diagnostica progettato per analizzare i pattern di utilizzo e risolvere i problemi di hotspotting.
Passaggi successivi
- Scopri altre best practice
- Scopri di più sulle query in tempo reale su larga scala