Comprendre les lectures et les écritures à grande échelle
Lisez ce document pour prendre des décisions éclairées sur l'architecture de vos applications afin d'optimiser leurs performances et leur fiabilité. Ce document aborde des sujets avancés concernant Firestore. Si vous débutez avec Firestore, consultez plutôt le guide de démarrage rapide.
Créé par Firebase et Google Cloud, Firestore est une base de données flexible et évolutive conçue pour le développement d'appareil mobile, Web et serveur. Il est très facile de se lancer avec Firestore et d'écrire des applications riches et performantes.
Pour vous assurer que vos applications continuent de fonctionner correctement à mesure que la taille et le trafic de votre base de données augmentent, il est utile de comprendre le fonctionnement des lectures et des écritures dans le backend Firestore. Vous devez également comprendre l'interaction de vos lectures et écritures avec la couche de stockage, ainsi que les contraintes sous-jacentes qui peuvent affecter les performances.
Consultez les sections suivantes pour connaître les bonnes pratiques avant de concevoir votre application.
Comprendre les composants de haut niveau
Le diagramme suivant présente les composants de haut niveau impliqués dans une requête API Firestore.
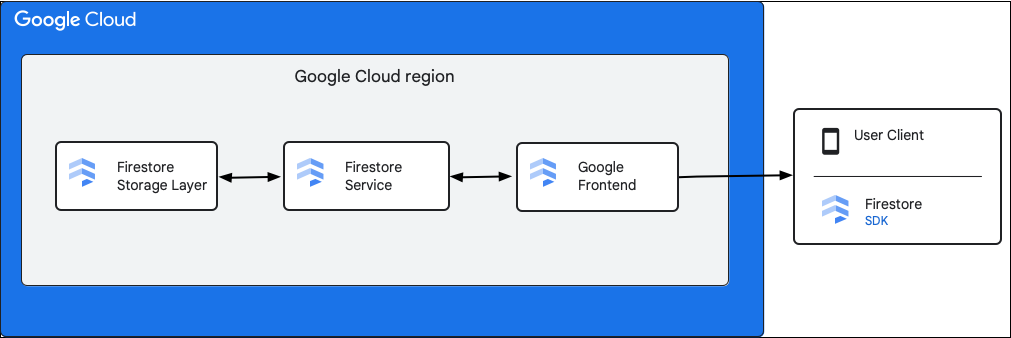
SDK et bibliothèques clientes Firestore
Firestore est compatible avec les SDK et les bibliothèques clientes pour différentes plates-formes. Bien qu'une application puisse effectuer des appels HTTP et RPC directs à l'API Firestore, les bibliothèques clientes fournissent une couche d'abstraction pour simplifier l'utilisation de l'API et implémenter les bonnes pratiques. Ils peuvent également fournir des fonctionnalités supplémentaires telles que l'accès hors connexion, les caches, etc.
Google Front End (GFE)
Il s'agit d'un service d'infrastructure commun à tous les services Google Cloud. Le GFE accepte les requêtes entrantes et les transmet au service Google concerné (service Firestore dans ce contexte). Il offre également d'autres fonctionnalités importantes, y compris la protection contre les attaques par déni de service.
Service Firestore
Le service Firestore effectue des vérifications sur la requête API, y compris l'authentification, l'autorisation, les vérifications de quota et les règles de sécurité, et gère également les transactions. Ce service Firestore inclut un client de stockage qui interagit avec la couche de stockage pour les lectures et les écritures de données.
Couche de stockage Firestore
La couche de stockage Firestore est responsable du stockage des données et des métadonnées, ainsi que des fonctionnalités de base de données associées fournies par Firestore. Les sections suivantes décrivent comment les données sont organisées dans la couche de stockage Firestore et comment le système évolue. En découvrant comment les données sont organisées, vous pouvez concevoir un modèle de données évolutif et mieux comprendre les bonnes pratiques dans Firestore.
Plages de clés et fractionnements
Firestore est une base de données NoSQL orientée documents. Vous stockez les données dans des documents, qui sont organisés en hiérarchies de collections. La hiérarchie des collections et l'ID du document sont traduits en une seule clé pour chaque document. Les documents sont stockés de manière logique et triés par ordre lexicographique selon cette clé unique. Nous utilisons le terme "plage de clés" pour désigner une plage de clés contiguë sur le plan lexicographique.
Une base de données Firestore typique est trop volumineuse pour tenir sur une seule machine physique. Il se peut également que la charge de travail sur les données soit trop lourde à traiter pour une machine. Pour gérer les charges de travail importantes, Firestore partitionne les données en plusieurs parties qui peuvent être stockées et diffusées à partir de plusieurs machines ou serveurs de stockage. Ces partitions sont créées dans les tables de base de données en blocs de plages de clés appelés "splits".
Réplication synchrone
Il est important de noter que la base de données est toujours répliquée automatiquement et de manière synchrone. Les fractions de données comportent des répliques dans différentes zones pour qu'elles restent disponibles même lorsqu'une zone devient inaccessible. L'algorithme de consensus Paxos est chargé de faire en sorte que la réplication soit cohérente sur les différentes copies de la partition. Une instance répliquée de chaque fraction est élue pour agir en tant qu'instance principale Paxos, qui est responsable de la gestion des écritures dans cette fraction. La réplication synchrone vous permet de toujours pouvoir lire la dernière version des données de Firestore.
Le résultat global est un système évolutif et à disponibilité élevée qui offre de faibles latences pour les lectures et les écritures, quelles que soient les charges de travail importantes et à très grande échelle.
Disposition des données
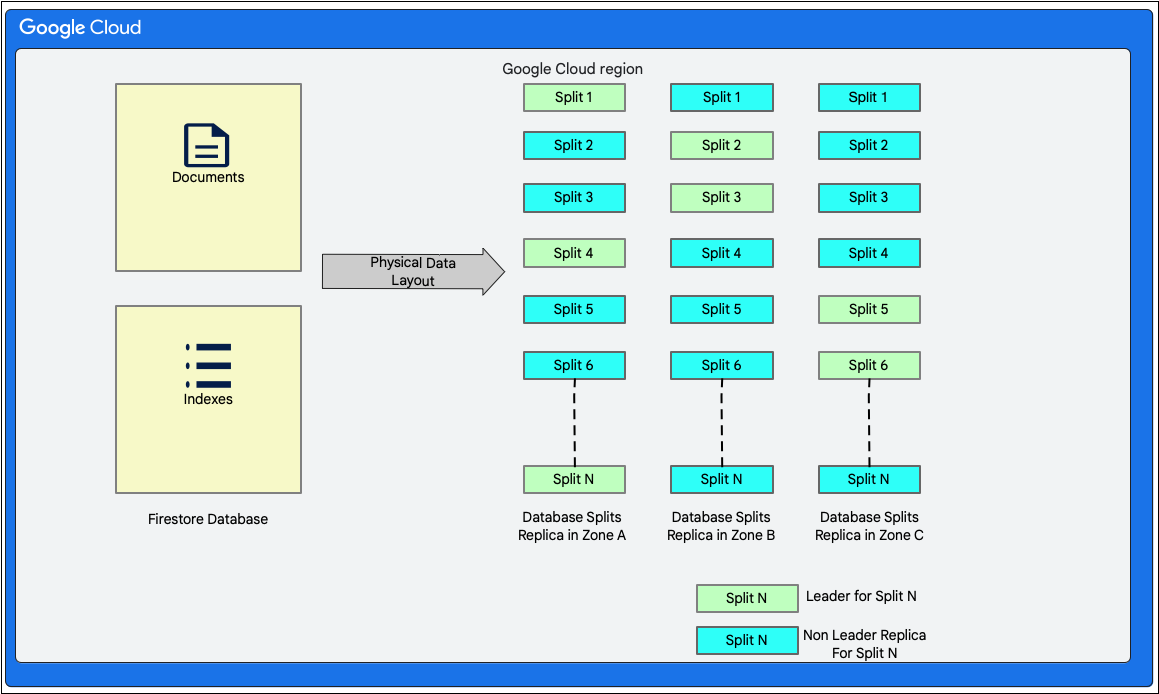
Firestore est une base de données de documents sans schéma. Toutefois, en interne, il organise les données principalement dans deux tableaux de type base de données relationnelle dans sa couche de stockage, comme suit :
- Table Documents : les documents sont stockés dans cette table.
- Tableau Indexes : les entrées d'index qui permettent d'obtenir des résultats de manière efficace et triés par valeur d'index sont stockées dans ce tableau.
Le diagramme suivant montre à quoi pourraient ressembler les tables d'une base de données Firestore avec les fractionnements. Les partitions sont répliquées dans trois zones différentes et chaque partition est associée à une variante optimale Paxos.
Région unique ou multirégionale
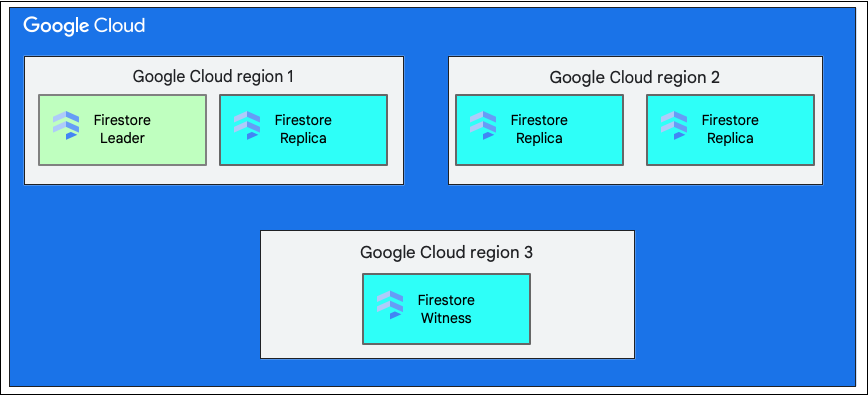
Lorsque vous créez une base de données, vous devez sélectionner une région ou une multirégion.
Un emplacement régional unique est un emplacement géographique spécifique, comme us-west1. Comme expliqué précédemment, les fractions de données d'une base de données Firestore comportent des répliques dans différentes zones de la région sélectionnée.
Un emplacement multirégional se compose d'un ensemble défini de régions dans lesquelles les réplicas de la base de données sont stockés. Dans un déploiement multirégional de Firestore, deux régions disposent de répliques complètes de l'ensemble des données de la base de données. Une troisième région dispose d'une instance répliquée témoin qui ne conserve pas un ensemble complet de données, mais participe à la réplication. En répliquant les données entre plusieurs régions, il est possible de les écrire et de les lire même en cas de perte d'une région entière.
Pour en savoir plus sur les emplacements d'une région, consultez Emplacements Firestore.
Comprendre le cycle de vie d'une écriture dans Firestore
Un client Firestore peut écrire des données en créant, en mettant à jour ou en supprimant un seul document. Une écriture dans un seul document nécessite la mise à jour atomique du document et de ses entrées d'index associées dans la couche de stockage. Firestore accepte également les opérations atomiques qui consistent en plusieurs lectures et/ou écritures sur un ou plusieurs documents.
Pour tous les types d'écritures, Firestore fournit les propriétés ACID (atomicité, cohérence, isolation et durabilité) des bases de données relationnelles. Firestore fournit également la sérialisabilité, ce qui signifie que toutes les transactions apparaissent comme si elles étaient exécutées dans un ordre sériel.
Étapes générales d'une transaction d'écriture
Lorsque le client Firestore émet une écriture ou valide une transaction à l'aide de l'une des méthodes mentionnées précédemment, cela est exécuté en interne en tant que transaction de lecture/écriture de base de données dans la couche de stockage. La transaction permet à Firestore de fournir les propriétés ACID mentionnées précédemment.
Lors de la première étape d'une transaction, Firestore lit le document existant et détermine les mutations à apporter aux données dans la table "Documents".
Cela inclut également d'apporter les modifications nécessaires au tableau "Indexes" (Index) comme suit :
- Les champs ajoutés aux documents doivent avoir des insertions correspondantes dans la table "Indexes".
- Les champs supprimés des documents doivent être supprimés de la table "Indexes".
- Les champs modifiés dans les documents doivent comporter à la fois des suppressions (pour les anciennes valeurs) et des insertions (pour les nouvelles valeurs) dans le tableau "Indexes" (Index).
Pour calculer les mutations mentionnées précédemment, Firestore lit la configuration d'indexation du projet. La configuration d'indexation stocke des informations sur les index d'un projet. Firestore utilise deux types d'index : à champ unique et composites. Pour comprendre en détail les index créés dans Firestore, consultez Types d'index dans Firestore.
Une fois les mutations calculées, Firestore les collecte dans une transaction, puis les valide.
Comprendre une transaction d'écriture dans la couche de stockage
Comme indiqué précédemment, une écriture dans Firestore implique une transaction en lecture-écriture dans la couche de stockage. Selon la mise en page des données, une écriture peut impliquer une ou plusieurs divisions, comme indiqué dans la mise en page des données.
Dans le schéma suivant, la base de données Firestore comporte huit divisions (numérotées de 1 à 8) hébergées sur trois serveurs de stockage différents dans une même zone. Chaque division est répliquée dans trois zones différentes(ou plus). Chaque partition possède une variante optimale Paxos, qui peut se trouver dans une zone différente pour chaque partition.
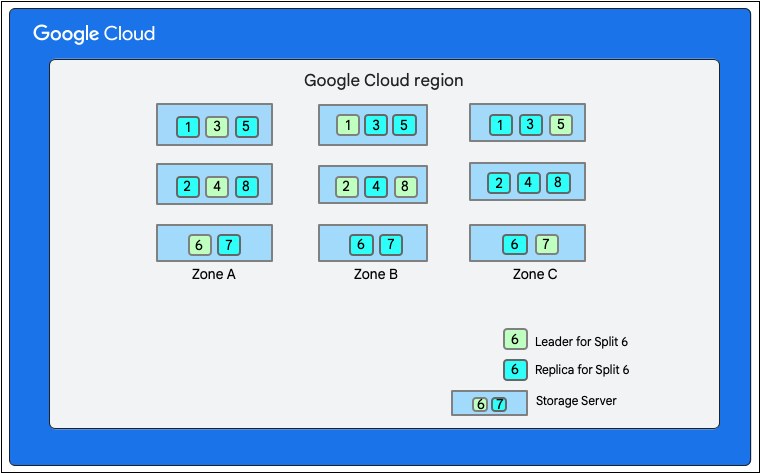
Prenons l'exemple d'une base de données Firestore dont la collection Restaurants se présente comme suit :
Le client Firestore demande la modification suivante d'un document dans la collection Restaurant en mettant à jour la valeur du champ priceCategory.
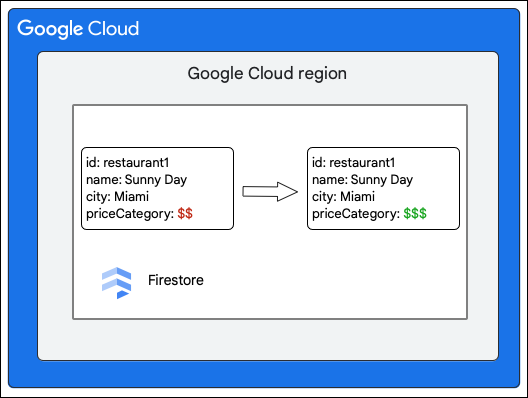
Les étapes générales suivantes décrivent ce qui se passe lors de l'écriture :
- Créez une transaction en lecture/écriture.
- Lire le document
restaurant1dans la collectionRestaurantsà partir de la table Documents de la couche de stockage. - Lisez les index du document dans le tableau Index.
- Calculer les mutations à apporter aux données. Dans ce cas, il y a cinq mutations :
- M1 : Mettez à jour la ligne de
restaurant1dans le tableau Documents pour refléter la modification de la valeur du champpriceCategory. - M2 et M3 : supprimez les lignes correspondant à l'ancienne valeur de
priceCategorydans le tableau Indexes pour les index ascendants et descendants. - M4 et M5 : insérez les lignes pour la nouvelle valeur de
priceCategorydans le tableau Indexes pour les index décroissants et croissants.
- M1 : Mettez à jour la ligne de
- Effectuez un commit sur ces mutations.
Le client de stockage du service Firestore recherche les divisions qui possèdent les clés des lignes à modifier. Prenons l'exemple où la partition 3 diffuse M1 et la partition 6 diffuse M2 à M5. Il existe une transaction distribuée impliquant toutes ces divisions en tant que participants. Les fractionnements des participants peuvent également inclure tout autre fractionnement à partir duquel des données ont été lues précédemment dans le cadre de la transaction en lecture/écriture.
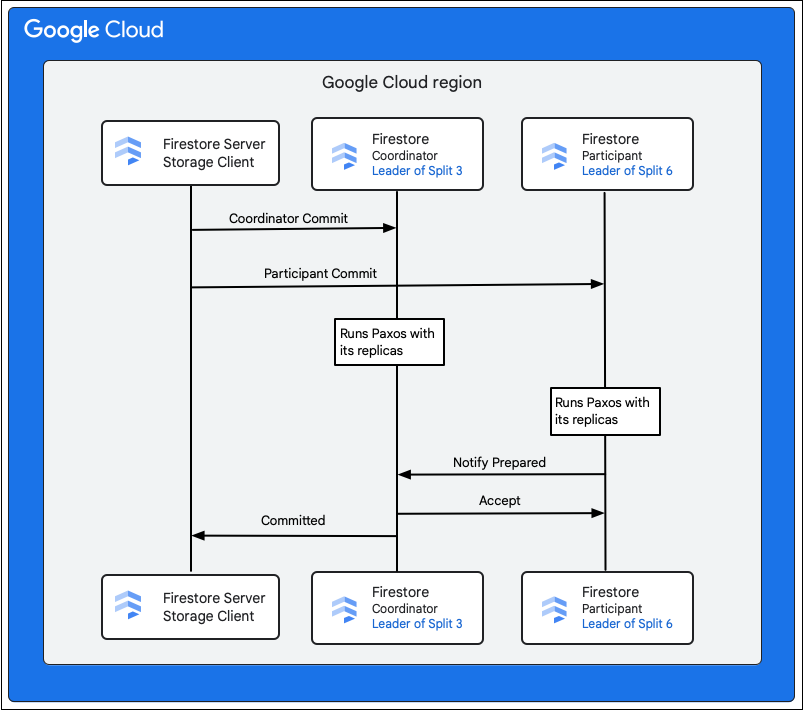
Les étapes suivantes décrivent ce qui se passe lors de l'opération d'envoi :
- Le client de stockage émet une validation. Le commit contient les mutations M1 à M5.
- Les partitions 3 et 6 sont les participants à cette transaction. L'un des participants est choisi comme coordinateur, par exemple Split 3. Celui-ci a pour tâche de s'assurer que la transaction est validée ou annulée de manière atomique pour tous les participants.
- Les instances répliquées maîtres de ces partitions sont responsables du travail effectué par les participants et les coordinateurs.
- Chaque participant et coordinateur exécute un algorithme Paxos avec ses répliques respectives.
- Le leader exécute un algorithme Paxos avec les réplicas. Le quorum est atteint si la plupart des répliques répondent au leader avec une réponse
ok to commit. - Chaque participant notifie ensuite au coordinateur qu'il est prêt (première phase de validation en deux phases). Si l'un des participants ne peut pas valider la transaction, toute la transaction
aborts.
- Le leader exécute un algorithme Paxos avec les réplicas. Le quorum est atteint si la plupart des répliques répondent au leader avec une réponse
- Une fois que le coordinateur sait que tous les participants, y compris lui-même, sont prêts, il communique le résultat de la transaction
acceptà tous les participants (deuxième phase de la validation en deux phases). Au cours de cette phase, chaque participant enregistre la décision de validation dans un stockage stable et la transaction est validée. - Le coordinateur répond au client de stockage dans Firestore que la transaction a été validée. Parallèlement, le coordinateur et tous les participants appliquent les mutations aux données.
Lorsque la base de données Firestore est petite, il peut arriver qu'une seule division possède toutes les clés des mutations M1 à M5. Dans ce cas, il n'y a qu'un seul participant à la transaction et le commit en deux phases mentionné précédemment n'est pas nécessaire, ce qui accélère les écritures.
Écritures dans plusieurs régions
Dans un déploiement multirégional, la répartition des réplicas entre les régions augmente la disponibilité, mais au détriment des performances. La communication entre les réplicas de différentes régions prend plus de temps. Par conséquent, la latence de référence pour les opérations Firestore est légèrement plus élevée que pour les déploiements dans une seule région.
Nous configurons les réplicas de sorte que le leadership des fractionnements reste toujours dans la région principale. La région principale est celle à partir de laquelle le trafic arrive au serveur Firestore. Cette décision de leadership réduit le délai aller-retour de communication entre le client de stockage dans Firestore et le leader du réplica (ou le coordinateur pour les transactions multisplit).
Chaque écriture dans Firestore implique également une interaction avec le moteur en temps réel de Firestore. Pour en savoir plus sur les requêtes en temps réel, consultez Comprendre les requêtes en temps réel à grande échelle.
Comprendre le cycle de vie d'une lecture dans Firestore
Cette section traite des lectures autonomes et non en temps réel dans Firestore. En interne, le serveur Firestore gère la plupart de ces requêtes en deux étapes principales :
- Une seule analyse de plage sur la table Indexes
- Recherches ponctuelles dans la table Documents en fonction du résultat de l'analyse précédente
Les lectures de données à partir de la couche de stockage sont effectuées en interne à l'aide d'une transaction de base de données pour garantir la cohérence des lectures. Toutefois, contrairement aux transactions utilisées pour les écritures, ces transactions ne prennent pas de verrous. Au lieu de cela, elles choisissent un code temporel, puis exécutent toutes les lectures à ce code temporel. Comme elles n'acquièrent pas de verrous, elles ne bloquent pas les transactions en lecture-écriture simultanées. Pour exécuter cette transaction, le client de stockage dans Firestore spécifie une limite d'horodatage, qui indique à la couche de stockage comment choisir un horodatage de lecture. Le type de limite d'horodatage choisi par le client de stockage dans Firestore est déterminé par les options de lecture de la requête de lecture.
Comprendre une transaction de lecture dans la couche de stockage
Cette section décrit les types de lectures et la façon dont elles sont traitées dans la couche de stockage de Firestore.
Lectures fortes
Par défaut, les lectures Firestore sont fortement cohérentes. Cette forte cohérence signifie qu'une lecture Firestore renvoie la dernière version des données, qui reflète toutes les écritures qui ont été validées jusqu'au début de la lecture.
Lecture de fractionnement unique
Le client de stockage dans Firestore recherche les divisions qui possèdent les clés des lignes à lire. Supposons qu'il doive effectuer une lecture à partir de la fraction 3 de la section précédente. Le client envoie la requête de lecture à l'instance répliquée la plus proche pour réduire la latence aller-retour.
À ce stade, les cas suivants peuvent se produire en fonction de la réplique choisie :
- La demande de lecture est envoyée à une instance dupliquée principale (zone A).
- Cette dernière étant toujours à jour, la lecture peut se dérouler directement.
- Une requête de lecture est envoyée à une instance répliquée non principale (par exemple, la zone B).
- Le split 3 peut savoir, grâce à son état interne, qu'il dispose de suffisamment d'informations pour diffuser la lecture, et il le fait.
- Le split 3 n'est pas sûr d'avoir connaissance des données les plus récentes. Elle envoie un message à la variante optimale pour lui demander l'horodatage de la dernière transaction à appliquer pour pouvoir diffuser la lecture. Une fois que cette transaction est appliquée, la lecture peut avoir lieu.
Firestore renvoie ensuite la réponse à son client.
Lecture sur plusieurs partitions
Dans le cas où les lectures doivent être effectuées à partir de plusieurs fractionnements, le même mécanisme se produit dans tous les fractionnements. Une fois les données renvoyées par toutes les divisions, le client de stockage dans Firestore combine les résultats. Firestore répond ensuite à son client avec ces données.
Lectures non actualisées
Les lectures fortes sont le mode par défaut dans Firestore. Toutefois, cela peut entraîner une latence plus élevée en raison de la communication qui peut être nécessaire avec le leader. Souvent, votre application Firestore n'a pas besoin de lire la dernière version des données, et la fonctionnalité fonctionne bien avec des données qui peuvent être obsolètes de quelques secondes.
Dans ce cas, le client peut choisir de recevoir des lectures obsolètes en utilisant les options de lecture read_time. Dans ce cas, les lectures sont effectuées telles que les données étaient à read_time, et l'instance répliquée la plus proche a très probablement déjà vérifié qu'elle disposait de données à l'horodatage read_time spécifié.
Pour obtenir des performances nettement meilleures, 15 secondes est une valeur d'obsolescence raisonnable. Même pour les lectures non actualisées, les lignes générées sont cohérentes entre elles.
Éviter les zones cliquables
Dans Firestore, les splits sont automatiquement divisés en plus petits morceaux pour répartir le travail de diffusion du trafic sur plusieurs serveurs de stockage si nécessaire ou lorsque l'espace de clés s'étend. Les fractionnements créés pour gérer le trafic excédentaire sont conservés pendant environ 24 heures, même si le trafic disparaît. Ainsi, en cas de pics de trafic récurrents, les fractionnements sont conservés et d'autres sont introduits si nécessaire. Ces mécanismes aident les bases de données Firestore à évoluer automatiquement en fonction de l'augmentation de la charge de trafic ou de la taille de la base de données. Toutefois, certaines limites s'appliquent, comme expliqué ci-dessous.
La répartition du stockage et de la charge prend du temps. Si vous augmentez le trafic trop rapidement, cela peut entraîner une latence élevée ou des erreurs de dépassement du délai (communément appelées points chauds) pendant que le service s'ajuste. La bonne pratique consiste à répartir les opérations sur la plage de clés, tout en augmentant le trafic sur une collection dans une base de données avec 500 opérations par seconde. Après cette augmentation progressive, augmentez le trafic de 50 % toutes les cinq minutes. Ce processus est appelé règle 500/50/5 et permet à la base de données de s'adapter de manière optimale à votre charge de travail.
Bien que les fractionnements soient créés automatiquement lorsque la charge augmente, Firestore ne peut fractionner une plage de clés que jusqu'à ce qu'elle diffuse un seul document à l'aide d'un ensemble dédié de serveurs de stockage répliqués. Par conséquent, des volumes élevés et soutenus d'opérations simultanées sur un même document peuvent entraîner un point chaud sur ce document. Si vous rencontrez des latences élevées et prolongées sur un seul document, envisagez de modifier votre modèle de données pour répartir ou répliquer les données sur plusieurs documents.
Les erreurs de contention se produisent lorsque plusieurs opérations tentent de lire et/ou d'écrire simultanément le même document.
Un autre cas particulier de hotspotting se produit lorsqu'une clé séquentielle croissante/décroissante est utilisée comme ID de document dans Firestore et qu'il existe un nombre considérablement élevé d'opérations par seconde. Créer d'autres divisions ne vous aidera pas, car le pic de trafic se déplacera simplement vers la nouvelle division. Étant donné que Firestore indexe automatiquement tous les champs du document par défaut, de tels hotspots mobiles peuvent également être créés dans l'espace d'index pour un champ de document contenant une valeur qui augmente ou diminue de façon séquentielle, comme un code temporel.
Notez qu'en suivant les pratiques décrites ci-dessus, Firestore peut évoluer pour traiter des charges de travail de n'importe quelle taille sans que vous ayez à ajuster la configuration.
Dépannage
Firestore fournit Key Visualizer, un outil de diagnostic conçu pour analyser les schémas d'utilisation et résoudre les problèmes de hotspotting.
Étape suivante
- En savoir plus sur les bonnes pratiques
- En savoir plus sur les requêtes en temps réel à grande échelle