Trainieren und bewerten
Mit Document AI können Sie neue Prozessorversionen mit Ihren eigenen Trainingsdaten trainieren und die Qualität Ihrer Prozessorversion anhand Ihrer eigenen Testdaten bewerten.
Das ist nützlich, wenn Sie einen benutzerdefinierten Prozessor verwenden möchten. Es gibt einen Document AI-Prozessor für Ihren Dokumenttyp, aber Sie können eine benutzerdefinierte Version davon trainieren, um Ihren Anforderungen gerecht zu werden.
Training und Bewertung werden in der Regel gemeinsam durchgeführt, um eine hochwertige, nutzbare Prozessorversion zu erhalten.
Document AI
Mit Document AI können Sie einen eigenen benutzerdefinierten Extraktor erstellen, mit dem Entitäten aus Dokumenten eines bestimmten Typs extrahiert werden, z. B. die Elemente in einem Menü oder der Name und die Kontaktdaten aus einem Lebenslauf.
Im Gegensatz zu anderen Prozessoren sind für benutzerdefinierte Prozessoren keine vortrainierten Prozessorversionen verfügbar. Daher können keine Dokumente verarbeitet werden, bis Sie eine Version von Grund auf trainieren.
Prozessor weiter trainieren
Sie können neue Prozessorversionen trainieren, um die Genauigkeit Ihrer Daten zu verbessern, zusätzliche benutzerdefinierte Felder aus Ihren Dokumenten zu extrahieren und Unterstützung für neue Sprachen hinzuzufügen.
Beim Up-Training wird Transfer Learning auf vortrainierte Google-Prozessorversionen angewendet. Im Allgemeinen sind dafür weniger Daten als beim Training von Grund auf erforderlich.
Weitere Informationen finden Sie unter Vortrainierten Prozessor weiter trainieren.
Unterstützte Prozessoren
Nicht alle spezialisierten Prozessoren unterstützen das Up-Training. Dies sind die Prozessoren, die das Upscaling unterstützen.
Überlegungen und Empfehlungen zu Daten
Die Qualität und Menge Ihrer Daten bestimmen die Qualität des Trainings, des UPTraining und der Evaluierung.
Das Beschaffen einer Reihe repräsentativer, realer Dokumente und das Bereitstellen einer ausreichenden Anzahl hochwertiger Labels sind oft der zeitaufwendigste und ressourcenintensivste Teil des Prozesses.
Anzahl der Dokumente
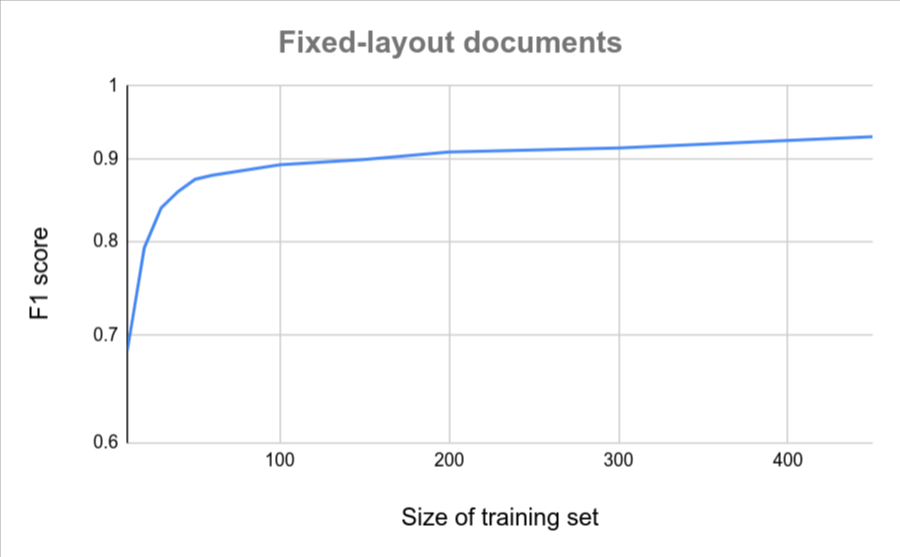
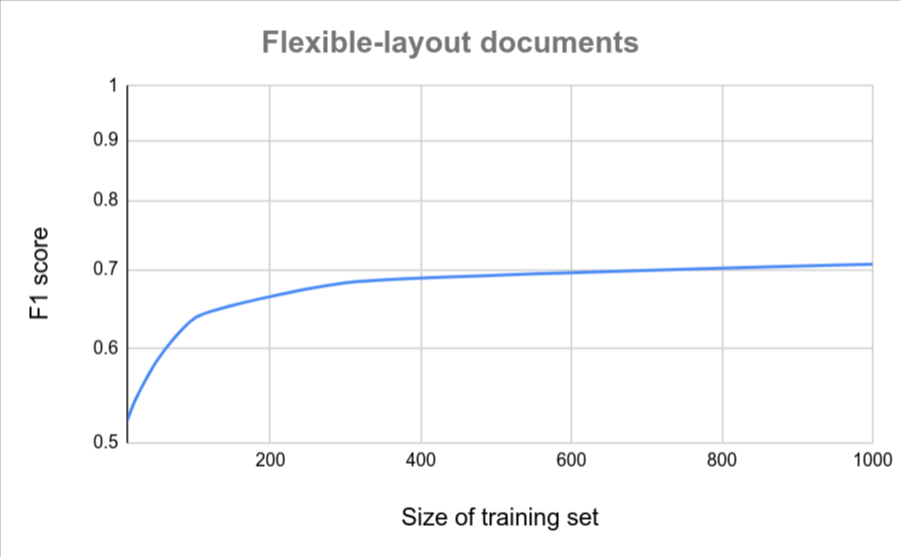
Wenn alle Ihre Dokumente ein ähnliches Format haben (z. B. ein festes Formular mit sehr geringen Abweichungen), sind weniger Dokumente erforderlich, um eine hohe Genauigkeit zu erzielen. Je größer die Variation, desto mehr Dokumente sind erforderlich.
Die folgenden Diagramme bieten eine grobe Schätzung der Anzahl der Dokumente, die für einen benutzerdefinierten Dokument-Extractor erforderlich sind, um einen bestimmten Qualitätswert zu erreichen.
| Geringe Abweichung | Hohe Variation |
|---|---|
 |
 |
Daten-Labeling
Sehen Sie sich Ihre Optionen zum Labeln von Dokumenten an und sorgen Sie dafür, dass Sie genügend Ressourcen haben, um die Dokumente in Ihrem Datensatz zu annotieren.
Modelle trainieren
Für benutzerdefinierte Extraktorprozessoren können je nach Anwendungsfall und verfügbaren Trainingsdaten verschiedene Modelltypen verwendet werden.
- Benutzerdefiniertes Modell: Modell, das mit gelabelten Trainingsdaten trainiert wird.
- Vorlagenbasiert: Dokumente mit einem festen Layout.
- Modellbasiert: Dokumente mit einigen Layoutabweichungen.
- Generatives KI-Modell: basiert auf vortrainierten Foundation Models, die nur minimales zusätzliches Training erfordern.
In der folgenden Tabelle sehen Sie, welche Anwendungsfälle den einzelnen Modelltypen entsprechen.
| Benutzerdefiniertes Modell | Generative AI | ||
|---|---|---|---|
| Vorlagenbasiert | Modellbasiert | ||
| Layout-Variante | Keine | Niedrig bis mittel | Hoch |
| Menge an Freiformtext (z. B. Absätze in einem Vertrag) | Niedrig | Niedrig | Hoch |
| Erforderliche Menge an Trainingsdaten | Niedrig | Hoch | Niedrig |
| Genauigkeit bei begrenzten Trainingsdaten | Höher | Niedrigere | Höher |
Informationen zum Feinabstimmen eines Prozessors mit Attributbeschreibungen
Wann sollte ein anderer Prozessor verwendet werden?
Hier sind einige Fälle, in denen Sie möglicherweise andere Optionen als Document AI Workbench in Betracht ziehen oder Ihren Workflow anpassen sollten.
- Bestimmte textbasierte Eingabeformate (.txt, .html, .docx, .md usw.) werden von Document AI Workbench nicht unterstützt. Erwägen Sie andere vorgefertigte oder benutzerdefinierte Angebote für die Sprachverarbeitung in Google Cloud, z. B. die Cloud Natural Language API.
- Das Schema für den benutzerdefinierten Dokumentextraktor unterstützt bis zu 150 Entitätslabels. Wenn für Ihre Geschäftslogik mehr als 150 Einheiten in der Schemadefinition erforderlich sind, sollten Sie mehrere Prozessoren trainieren, die jeweils auf eine Teilmenge von Einheiten ausgerichtet sind.
Prozessor trainieren
Angenommen, Sie haben bereits einen Prozessor erstellt, der das Trainieren oder Aktualisieren unterstützt, und Ihr Dataset mit Labels versehen, können Sie eine neue Prozessorversion von Grund auf trainieren. Sie können auch ein Aufbautraining einer bestehenden Prozessorversion durchführen, um eine neue Version zu erhalten.
Prozessorversion trainieren
Web-UI
Rufen Sie in der Google Cloud Console den Tab Trainieren Ihres Prozessors auf.
Klicken Sie auf Schema bearbeiten, um die Seite Labels verwalten zu öffnen. Prüfen Sie die Labels des Prozessors.
Die Labels, die zum Zeitpunkt des Trainings aktiviert sind, bestimmen die Entitäten, die von der neuen Prozessorversion extrahiert werden. Wenn ein Label im Schema inaktiv ist, wird es von der Prozessorversion nicht extrahiert, auch wenn die Dokumente entsprechend gekennzeichnet sind.
Klicken Sie auf dem Tab Trainieren auf Label-Statistiken ansehen und überprüfen Sie Ihren Test- und Trainingssatz. Dokumente, die automatisch mit Labels versehen, ohne Labels oder nicht zugewiesen sind, werden vom Training und von der Evaluierung ausgeschlossen.
Klicken Sie auf Neue Version trainieren.
Der Versionsname definiert das Feld
namedesprocessorVersion.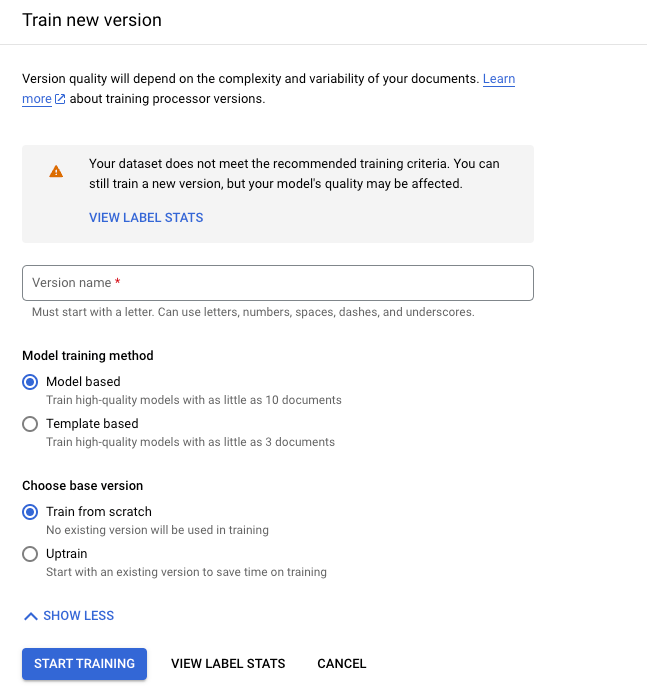
Klicken Sie auf Training starten und warten Sie, bis die neue Prozessorversion trainiert und bewertet wurde.
Sie können den Trainingsfortschritt auf dem Tab Versionen verwalten verfolgen:
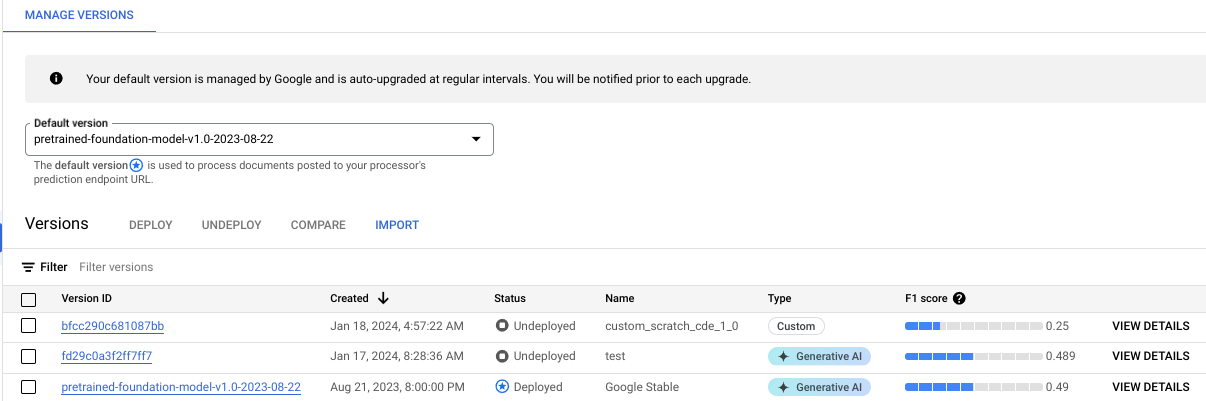
Klicken Sie auf den Tab Bewerten und Testen, um zu sehen, wie gut Ihre neue Prozessorversion im Test-Dataset abgeschnitten hat. Weitere Informationen finden Sie unter Prozessorversion bewerten.
Python
Weitere Informationen finden Sie in der Referenzdokumentation zur Document AI Python API.
Richten Sie zur Authentifizierung bei Document AI Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Prozessorversion bereitstellen und verwenden
Sie können Ihre Prozessorversionen wie jede andere Prozessorversion bereitstellen und verwalten. Weitere Informationen finden Sie unter Prozessorversionen verwalten.
Nach der Bereitstellung können Sie eine Verarbeitungsanfrage an Ihren benutzerdefinierten Prozessor senden.
Prozessor deaktivieren oder löschen
Wenn Sie einen Prozessor nicht mehr verwenden möchten, können Sie ihn deaktivieren oder löschen. Wenn Sie einen Prozessor deaktivieren, können Sie ihn wieder aktivieren. Wenn Sie einen Prozessor löschen, können Sie ihn nicht wiederherstellen.
Klicken Sie im Bereich Document AI auf der linken Seite auf Meine Prozessoren.
Klicken Sie rechts neben dem Namen des Prozessors auf das Dreipunkt-Menü. Klicken Sie auf Prozessor deaktivieren oder Prozessor löschen.
Weitere Informationen finden Sie unter Prozessorversionen verwalten.
Verschlüsselung von Trainingsdaten
Document AI-Trainingsdaten werden in Cloud Storage gespeichert und können bei Bedarf mit vom Kunden verwalteten Verschlüsselungsschlüsseln verschlüsselt werden.
Löschen von Trainingsdaten
Nach Abschluss eines Document AI-Trainingsjobs laufen alle in Cloud Storage gespeicherten Trainingsdaten nach einer Aufbewahrungsdauer von zwei Tagen ab. Bei nachfolgenden Aktivitäten zum Löschen von Daten wird der in Datenlöschung auf Google Cloud beschriebene Prozess berücksichtigt.
Preise
Für das Training oder das erneute Training fallen keine Kosten an. Sie bezahlen für das Hosting und die Vorhersage. Weitere Informationen finden Sie unter Document AI-Preise.