Google Distributed Cloud air-gapped appliance (GDC) lets you manage your Kubernetes clusters after creation so you can adapt to your evolving container workload requirements.
Perform node maintenance
When you need to repair or maintain nodes, first put the nodes into maintenance mode. Putting nodes into maintenance mode safely drains their pods/workloads and excludes the nodes from pod scheduling. In maintenance mode, you can work on your nodes without a risk of disrupting pod traffic.
How it works
Maintenance mode for GDC is similar to running kubectl
cordon and kubectl drain for a specific node. Here are a few details that are
relevant to maintenance mode:
- Specified nodes are marked as unschedulable. This action is what
kubectl cordondoes. - Node taints are added to specified nodes to indicate that no pods can be
scheduled or executed on the nodes. This action is similar to
kubectl drain. - A 20-minute timeout is enforced to ensure that the nodes don't get stuck waiting for pods to terminate. Pods might not terminate if they are configured to tolerate all taints or they have finalizers. GDC clusters attempt to terminate all pods, but if the timeout is exceeded, the node is put into maintenance mode. This timeout prevents running pods from blocking upgrades.
- If you have a VM-based workload running on the node, GDC clusters apply a
NodeSelectorto the virtual machine instance (VMI) pod, then stop the pod. TheNodeSelectorensures that the VMI pod is restarted on the same node when the node is removed from maintenance mode.
Put a node into maintenance mode
Choose the nodes you want to put into maintenance mode by specifying IP address
ranges for the selected nodes in the maintenanceBlocks section of your cluster
configuration file. The nodes you choose must be in a Ready state, and
functioning in the cluster.
To put nodes into maintenance mode:
Edit the cluster configuration file to select the nodes you want to put into maintenance mode.
You can edit the configuration file with an editor of your choice, or you can edit the cluster custom resource directly by running the following command:
kubectl -n CLUSTER_NAMESPACE edit cluster CLUSTER_NAMEReplace the following:
- CLUSTER_NAMESPACE: the namespace of the cluster.
- CLUSTER_NAME: the name of the cluster.
Add the
maintenanceBlockssection to the cluster configuration file to specify either a single IP address, or an address range, for nodes you want to put into maintenance mode.The following sample shows how to select multiple nodes by specifying a range of IP addresses:
... metadata: name: my-cluster namespace: cluster-my-cluster spec: maintenanceBlocks: cidrBlocks: - 172.16.128.1-172.16.128.64 ...Save and apply the updated cluster configuration:
kubectl apply -f my-cluster.yamlAfter the cluster configuration is applied, the cluster puts the applicable nodes into maintenance mode.
Run the following command to get the status of the nodes in your cluster:
kubectl get nodes -n CLUSTER_NAMEThe response is something like the following:
NAME STATUS ROLES AGE VERSION user-gdch-01 Ready master 2d22h v1.23.5-gke.1502 user-gdch-04 Ready none 2d22h v1.23.5-gke.1502 user-gdch-05 Ready,SchedulingDisabled none 2d22h v1.23.5-gke.1502 user-gdch-06 Ready none 2d22h v1.23.5-gke.1502A status of
SchedulingDisabledindicates that a node is in maintenance mode.Run the following command to get the number of nodes in maintenance mode:
kubectl get nodepoolsThe response looks similar to the following output:
NAME READY RECONCILING STALLED UNDERMAINTENANCE UNKNOWN np1 3 0 0 1 0The
UNDERMAINTENANCEcolumn in this sample shows that one node is in maintenance mode.Clusters also add the following taints to nodes when they are put into maintenance mode:
baremetal.cluster.gke.io/maintenance:NoExecutebaremetal.cluster.gke.io/maintenance:NoSchedule
Resize node pools
Any user cluster in the GDC environment can have its
node pool resized to scale with workload changes. To manage node pools in a user
cluster, you must have the User Cluster Admin (user-cluster-admin) role.
To scale a node pool in an existing cluster, complete the following steps:
Console
- In the dashboard, select the project in which the cluster you intend to edit exists.
- In the navigation menu, select Clusters.
- Select the cluster name that the node pool is associated with. The Cluster details page is displayed.
- Click the Node pools tab.
- Select the edit Edit icon for the node pool you want to resize. The Edit node pool prompt is displayed.
Update the Number of nodes field to reflect the new amount of nodes required in the node pool. You can increase or decrease the number of nodes to fit your workload requirements.
Click Save.
Navigate back to the Node pools tab for your cluster and confirm the resized node pool has the
Readystatus and has the correct number of nodes. It can take a few minutes for the node pool to scale to your specification.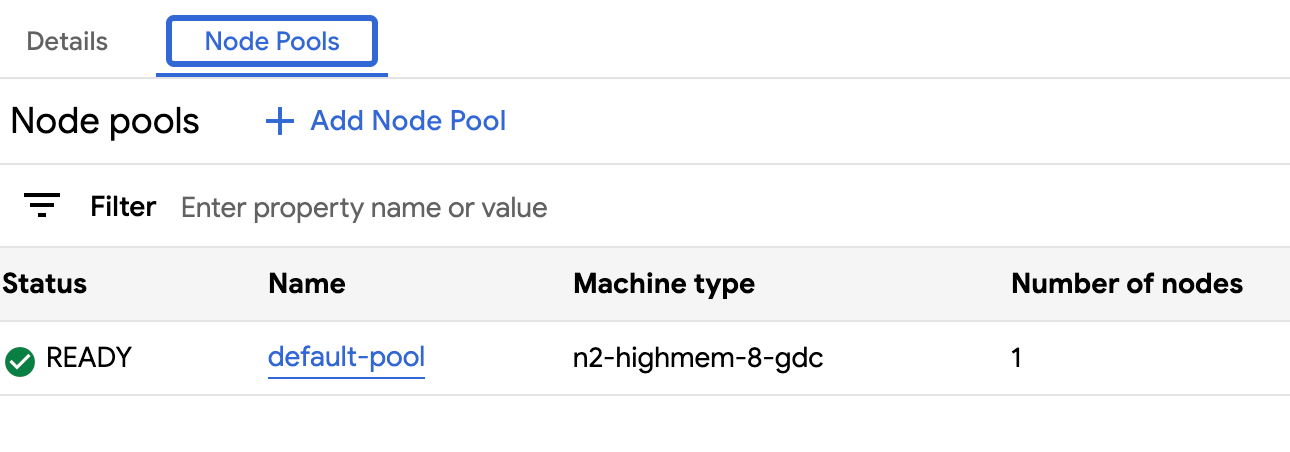
API
Open the
Clustercustom resource spec with thekubectlCLI using the interactive editor:kubectl edit clusters.cluster.gdc.goog/USER_CLUSTER_NAME -n platform \ --kubeconfig ORG_ADMIN_CLUSTER_KUBECONFIGUpdate the
nodeCountfield for the node pool to resize:nodePools: ... - machineTypeName: n2-standard-2-gdc name: nodepool-1 nodeCount: NUMBER_OF_WORKER_NODESReplace
NUMBER_OF_WORKER_NODESwith the updated number of worker nodes to provision in the node pool.Save the file and exit the editor.
Verify your node scaling is complete by checking the node pool's configuration:
kubectl get clusters.cluster.gdc.goog/USER_CLUSTER_NAME -n platform -o json \ --kubeconfig ADMIN_CLUSTER_KUBECONFIG | jq .status.workerNodePoolStatusesConfirm the
readyNodesnumber reflects the amount of nodes you set for the node pool. It can take a few minutes for the node pool to scale to your specification.
View all clusters in an organization
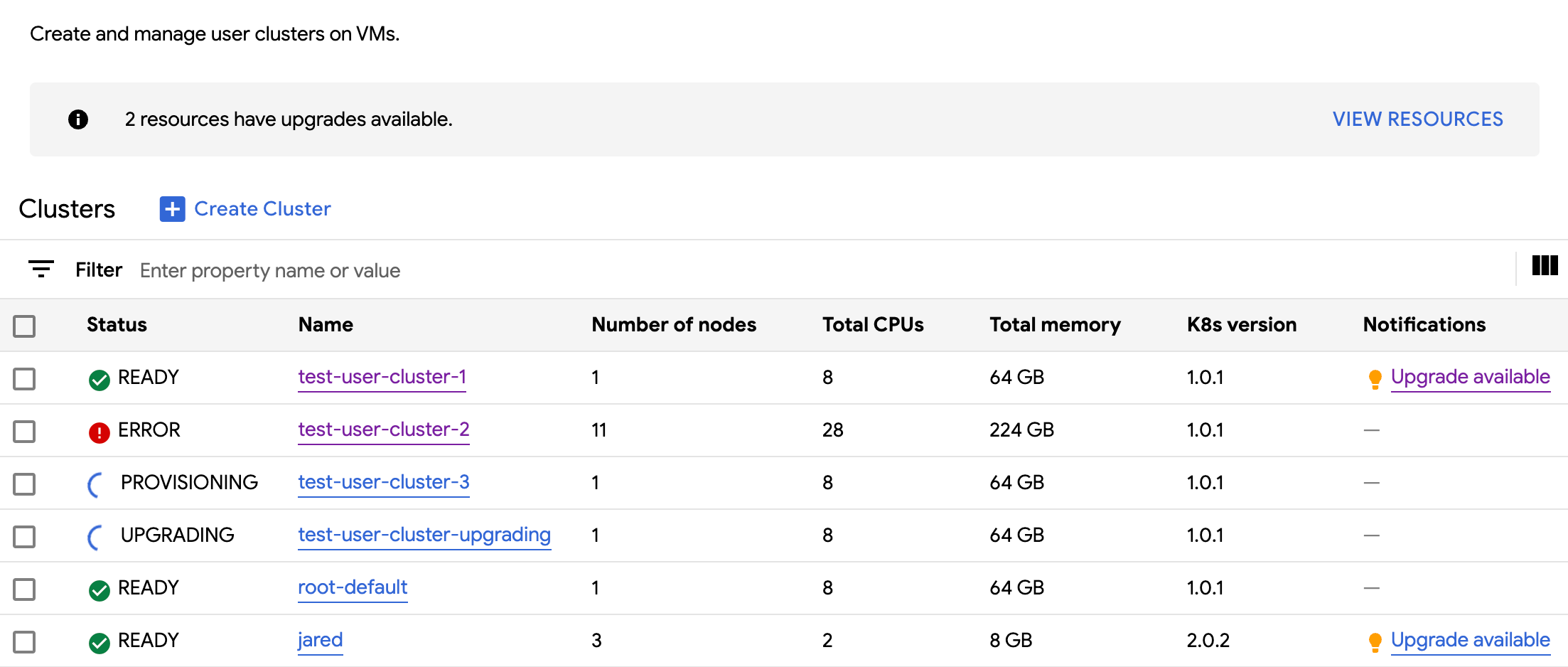
You can view all available user clusters in an organization, including their statuses, Kubernetes versions, and other details.
Console
In the navigation menu, select Clusters.
All available clusters in the organization with their statuses and other information are displayed:
kubectl
List the available user clusters in an organization:
kubectl get clusters.cluster.gdc.goog -n platform \ --kubeconfig ADMIN_CLUSTER_KUBECONFIGThe output is similar to the following:
NAME STATE K8S VERSION user-vm-1 Running 1.25.10-gke.2100 user-test Running 1.26.5-gke.2100
View updatable properties
For each user cluster, a set of properties are available to change after it is
created. You can only change the mutable properties that are in the spec of
the Cluster custom resource. Not all properties in the spec are eligible to
update after the cluster is provisioned. To view these updatable properties,
complete the following steps:
Console
In the navigation menu, select Clusters.
In the list of user clusters, click a cluster name to view its properties.
Editable properties have an edit Edit icon.
kubectl
View the list of properties for the
Clusterspec and the valid values corresponding to each property:kubectl explain clusters.cluster.gdc.goog.spec \ --kubeconfig ORG_ADMIN_CLUSTER_KUBECONFIGThe output is similar to the following:
KIND: Cluster VERSION: cluster.gdc.goog/v1 RESOURCE: spec <Object> DESCRIPTION: <empty> FIELDS: clusterNetwork <Object> The cluster network configuration. If unset, the default configurations with pod and service CIDR sizes are used. Optional. Mutable. initialVersion <Object> The GDCH version information of the user cluster during cluster creation. Optional. Default to use the latest applicable version. Immutable. loadBalancer <Object> The load balancer configuration. If unset, the default configuration with the ingress service IP address size is used. Optional. Mutable. nodePools <[]Object> The list of node pools for the cluster worker nodes. Optional. Mutable. releaseChannel <Object> The release channel a cluster is subscribed to. When a cluster is subscribed to a release channel, GDCH maintains the cluster versions for users. Optional. Mutable.Update these settings by using the GDC console or
kubectlCLI. For example, you can resize a node pool.
Scale ingress service IP address size
You can scale your ingress service IP address size after you create a user cluster.
Open the
Clustercustom resource spec with thekubectlCLI using the interactive editor:kubectl edit clusters.cluster.gdc.goog/USER_CLUSTER_NAME -n platform \ --kubeconfig ADMIN_CLUSTER_KUBECONFIGUpdate the
ingressServiceIPSizefield to the new IP address size:... spec: ... loadBalancer: ingressServiceIPSize: INGRESS_SERVICE_IP_SIZE ...Replace
INGRESS_SERVICE_IP_SIZEwith the updated ingress service IP address size.Save the file and exit the editor.
There is no set limit on the ingress service IP address size. The amount of IP addresses you request is fulfilled based on your organization. If the request cannot be fulfilled, the cluster reports an error.