Nesta página, descrevemos como solucionar problemas de inacessibilidade do dispositivo após a inicialização. Você pode encontrar os seguintes problemas:
- Mensagens de erro, como
Unable to connect to the server: dial tcp 198.18.0.64:443: i/o timeout, ao tentar consultar usando kubectl. - Erro
Webpage not availableao tentar acessar a UI. - Os aplicativos implantados no dispositivo não estão funcionando ou não é possível implantar novos aplicativos.
Resolver problemas de inacessibilidade da interface
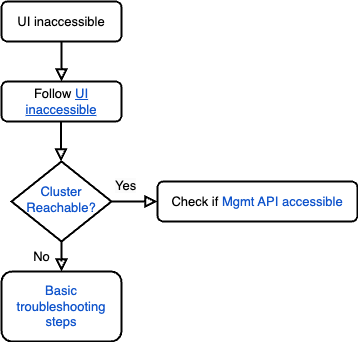
- Siga o runbook Interface inacessível para resolver o problema.
- Verifique se o cluster está acessível seguindo a seção Acessibilidade do cluster.
- Se o cluster estiver responsivo, verifique se a API de gerenciamento está acessível seguindo a seção API de gerenciamento acessível.
- Se o cluster não estiver acessível e retornar erros como
Connection timed outoui/o timeout error, consulte o guia de solução de problemas para mais etapas.
Etapas básicas de solução de problemas

Verifique a fonte de alimentação do chassi conferindo se as luzes indicadoras (verdes) em uma das duas fontes estão acesas, conforme indicado pelas setas na imagem.
Status da luz de LED Descrição Verde contínua Sistema ligado e operação normal Verde piscante Energia em espera presente (fonte de alimentação desligada) Âmbar sólido Falha na fonte de alimentação (sobretensão/subtensão, temperatura excessiva, sobrecarga, curto-circuito), falha no ventilador ou proteção contra sobretensão na entrada Âmbar piscando Erro na fonte de alimentação Desativado Não há energia ou a energia em espera falhou (sobretensão/ subtensão, superaquecimento, sobrecarga, curto-circuito, bloqueio do ventilador) Se as luzes indicadoras estiverem apagadas, primeiro verifique se o cabo de alimentação está recebendo energia. Se o cabo de alimentação estiver funcionando corretamente, provavelmente as fontes de alimentação estão com defeito e precisam ser substituídas. Para instruções de substituição, consulte o Guia de substituição da fonte de alimentação.
Se as fontes de alimentação estiverem funcionando, mas o dispositivo ainda não, verifique se há conexões soltas ou danificadas.
Verifique se os LEDs do switch e dos servidores estão acesos, conforme indicado pelas setas na imagem.
Se o LED de link do switch estiver verde constante, siga a seção Verificar se o switch está operacional.
Se a integridade e a configuração do switch estiverem corretas, faça login no iLO seguindo as etapas mencionadas em Etapas para fazer login no iLO e verifique a integridade do dispositivo.
- Se algum dos ventiladores for crítico, entre em contato com a equipe de suporte da HPE para receber um substituto e siga o Guia de substituição de ventiladores.
- Se alguma lâmina estiver desligada, navegue até a seção "Lâminas", selecione a lâmina e pressione o botão liga/desliga para ligá-la.
- Se alguma das placas estiver em estado crítico, navegue até a seção "Placas", selecione a placa crítica, acesse a seção "Energia" e inicie uma redefinição forçada do sistema.
- Se a integridade do chassi for crítica, tente redefini-lo acessando a guia Energia e temperatura. Selecione a seção Management Power e clique em Reset EL8000CM Button. Esse processo redefine o firmware do gerenciador de chassi e pode levar alguns minutos, durante os quais o chassi fica indisponível.
- Se o problema persistir, acesse a guia Informações, selecione Registros, escolha Registros de integridade no menu suspenso e faça o download deles como um arquivo CSV. Abra um tíquete com o Google e anexe os registros para solicitar a substituição do hardware.
Se os LEDs de energia nos módulos estiverem acesos, faça um teste de ping nos seguintes endereços IP de módulos em uma máquina conectada ao appliance:
ping 198.18.0.7 //BM01 ping 198.18.0.8 //BM02 ping 198.18.0.9 //BM03Se o teste de ping for bem-sucedido, isso indica que os nós estão operacionais.
Se todos os nós falharem no teste de ping, encaminhe para o suporte do Google.
Se o problema persistir depois de seguir todas as etapas descritas nesta seção, encaminhe o caso para o Suporte do Google para receber mais ajuda.
Conexões soltas ou danificadas
Verifique se todas as conexões estão seguras e encaixadas corretamente. Para orientações sobre como verificar e proteger as conexões de cabo no dispositivo, consulte verificar cabos.
Verifique se há danos visíveis nos cabos. Se algum cabo estiver danificado, substitua-o.
Verificar se a chave está operacional
Faça login no console serial do switch. Se o login for bem-sucedido, execute o seguinte comando para verificar a integridade da chave. Esse comando mostra o tempo de atividade e o consumo de recursos do switch.
show versionSe o console serial estiver responsivo, valide a configuração do BGP no switch consultando Validar resumo do BGP.
Se o LED de link estiver apagado ou o console serial não responder, talvez o switch esteja com defeito. Encaminhe o problema ao Suporte do Google para uma substituição.
Verificar a capacidade de acesso ao cluster
Faça login na sessão do gdcloud com as credenciais de E/S:
gdcloud auth loginSe não for possível fazer login, localize a credencial de emergência armazenada em backup durante a configuração do appliance para usar com o comando -: root-admin-kubeconfig.
Verifique se o cluster está acessível:
kubectl --kubeconfig root-admin-kubeconfig get servers -A
Verificar a acessibilidade da API Management
Faça login na sessão do gdcloud com as credenciais de E/S:
gdcloud auth loginSe o login falhar, faça login com as credenciais do plano de gerenciamento.
Às vezes, o banco de dados do AIS pode apresentar falhas ou estar mal configurado, causando falhas de login. Consulte IAM-R0009: banco de dados da AIS.
Se não for possível resolver os problemas de login, localize a credencial de emergência salva durante a configuração do appliance para usar com o comando -: root-admin-kubeconfig.
Extraia o kubeconfig do plano de gerenciamento:
kubectl --kubeconfig root-admin-kubeconfig -n management-kube-system get secret kube-admin-remote-kubeconfig -ojsonpath='{.data.value}' | base64 -d > kube-admin-remote-kubeconfigConfira o status de integridade do cluster:
kubectl --kubeconfig kube-admin-remote-kubeconfig get --raw='/readyz?verbose'