某些實體需要比對的是模式,而非特定字詞,例如身分證字號、ID、車牌號碼等。只要使用規則運算式實體,您就能提供規則運算式來進行比對。
這項資料的所在位置
建構代理程式時,最常見的做法是使用 Dialogflow ES 主控台 (請參閱說明文件並開啟主控台)。以下操作說明重點介紹如何使用主控台。存取實體資料的方法如下:
- 前往 Dialogflow ES 主控台。
- 選取代理程式。
- 選取左側欄選單中的 [Entities] (實體)。
如果您是使用 API (而非主控台) 建構代理程式,請參閱 EntityType 參考資料。API 欄位名稱與主控台欄位名稱相似。以下操作說明會明確指出主控台與 API 之間的所有重要差異。
複合式規則運算式:
每個規則運算式實體都會對應至一個模式,不過如果這類實體都是某個模式的變化形式,您可以提供多個規則運算式。在代理程式訓練期間,單一實體的所有規則運算式都會與替換運算子 (|) 合併,形成一個複合式規則運算式。
舉例來說,如果您提供了下列電話號碼規則運算式:
^[2-9]\d{2}-\d{3}-\d{4}$^(1?(-?\d{3})-?)?(\d{3})(-?\d{4})$
複合式規則運算式會變為:
^[2-9]\d{2}-\d{3}-\d{4}$|^(1?(-?\d{3})-?)?(\d{3})(-?\d{4})$
規則運算式的順序會影響結果。系統會按照順序處理複合式規則運算式中的各個規則運算式,並在發現有效的比對項目後停止搜尋。舉例來說,如果使用者的運算式是「Seattle」:
Sea|Seattle與「Sea」相符Seattle|Sea與「Seattle」相符
語音辨識功能的特殊處理方式
如果您的代理程式會使用語音辨識功能 (也稱為「音訊輸入」、「語音轉文字」或「STT」),則系統在比對英文字母和數字時,必須以特殊的方式處理規則運算式。在比對實體之前,語音辨識器會先處理使用者的語音內容。如果語音內容中包含一系列的英文字母或數字,辨識器可能會為每個字元加上空格。另外,辨識器也會解讀以文字呈現的數字。舉例來說,系統可能會將使用者說出的「我的 ID 是 123」識別為以下任一形式:
- 「我的 ID 是 123」
- 「我的 ID 是 1、2、3」
- 「我的 ID 是一二三」
如要容納三個數字,您可以使用以下規則運算式:
\d{3}\d \d \d
(zero|one|two|three|four|five|six|seven|eight|nine) (zero|one|two|three|four|five|six|seven|eight|nine) (zero|one|two|three|four|five|six|seven|eight|nine)
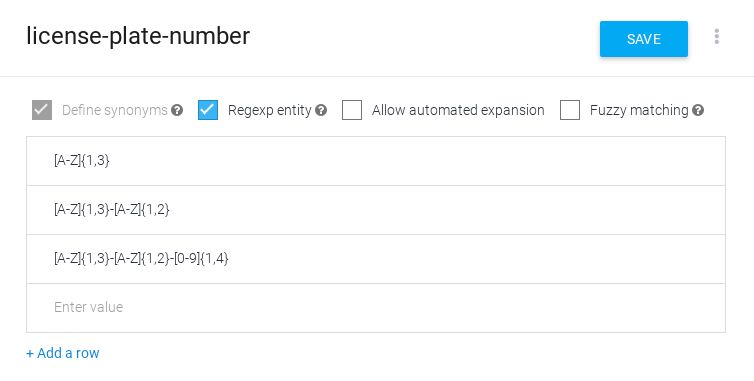
建立規則運算式實體
如要建立規則運算式實體,請按照下列指示操作:
- 開啟現有實體或建立新的實體。
- 查看規則運算式實體。
- 在項目資料表中輸入一或多個規則運算式。
- 按一下 [儲存]。
如果您是使用 API 來建立或更新實體,請在實體種類欄位中使用 KIND_REGEXP。
限制
限制如下: