Bei einigen Entitäten müssen Muster anstelle von bestimmten Begriffen zugeordnet werden. Dies ist zum Beispiel bei nationalen Identifikationsnummern, IDs, Kfz-Kennzeichen usw. der Fall. Mit RegExp-Entitäten können Sie reguläre Ausdrücke für den Abgleich bereitstellen.
Wo finde ich diese Daten?
In der Regel erstellen Sie Agents mit der Dialogflow ES-Konsole (Dokumentation ansehen, Konsole öffnen). Die folgende Anleitung bezieht sich auf die Konsole. So greifen Sie auf Entitätsdaten zu:
- Rufen Sie die Dialogflow ES-Konsole auf.
- Wählen Sie einen Agent aus.
- Wählen Sie im Menü der linken Seitenleiste Entities aus.
Wenn Sie statt der Konsole die API zur Erstellung eines Agents verwenden, finden Sie Informationen dazu in der EntityTypes-Referenz. Die Bezeichnungen der API-Felder und der Felder in der Konsole sind weitgehend gleich. In der folgenden Anleitung werden alle wichtigen Unterschiede zwischen der Konsole und der API hervorgehoben.
Komplexe reguläre Ausdrücke
Jede RegExp-Entität entspricht einem einfachen Muster. Sie können jedoch mehrere reguläre Ausdrücke angeben, wenn diese alle Variationen eines einfachen Musters darstellen.
Während des Agenttrainings werden alle regulären Ausdrücke einer einzigen Entität mit dem Alternationsoperator (|) kombiniert, um einen komplexen regulären Ausdruck zu erstellen.
Angenommen, Sie geben die folgenden regulären Ausdrücke für eine Telefonnummer an:
^[2-9]\d{2}-\d{3}-\d{4}$^(1?(-?\d{3})-?)?(\d{3})(-?\d{4})$
Der komplexe reguläre Ausdruck wird zu:
^[2-9]\d{2}-\d{3}-\d{4}$|^(1?(-?\d{3})-?)?(\d{3})(-?\d{4})$
Die Reihenfolge der regulären Ausdrücke ist wichtig. Alle regulären Ausdrücke im komplexen regulären Ausdruck werden nacheinander verarbeitet. Die Suche wird beendet, sobald eine gültige Zuordnung gefunden wird. So gilt beispielsweise für den Endnutzerausdruck "Seattle" Folgendes:
Sea|Seattlestimmt mit "Sea" überein.Seattle|Seastimmt mit "Seattle" überein.
Besondere Verarbeitungsvorgänge bei der Spracherkennung
Wenn der Agent die Spracherkennung (auch als Audioeingabe, Sprache-in-Text oder STT bezeichnet) verwendet, müssen die regulären Ausdrücke bei der Zuordnung von Buchstaben und Ziffern besonders verarbeitet werden. Eine gesprochene Endnutzeräußerung wird erst vom Erkennungsmodul verarbeitet, erst dann werden die Entitäten zugeordnet. Wenn eine Äußerung eine Reihe von Buchstaben oder Zahlen enthält, kann das Erkennungsmodul die Zeichen durch Leerzeichen trennen. Außerdem kann das Erkennungsmodul Ziffern in Wortform interpretieren. So kann die Endnutzeräußerung "Meine ID lautet 123" auf folgende Weise erkannt werden:
- "Meine ID lautet 123"
- "Meine ID lautet 1 2 3"
- "Meine ID lautet eins, zwei, drei"
Zur Verarbeitung von dreistelligen Zahlen können Sie die folgenden regulären Ausdrücke verwenden:
\d{3}\d \d \d
(zero|one|two|three|four|five|six|seven|eight|nine) (zero|one|two|three|four|five|six|seven|eight|nine) (zero|one|two|three|four|five|six|seven|eight|nine)
RegExp-Entität erstellen
So erstellen Sie eine RegExp-Entität:
- Öffnen Sie eine vorhandene Entität oder erstellen Sie eine neue Entität.
- Aktivieren Sie die RegExp-Entität.
- Geben Sie einen oder mehrere reguläre Ausdrücke in die Tabelle der Einträge ein.
- Klicken Sie auf Speichern.
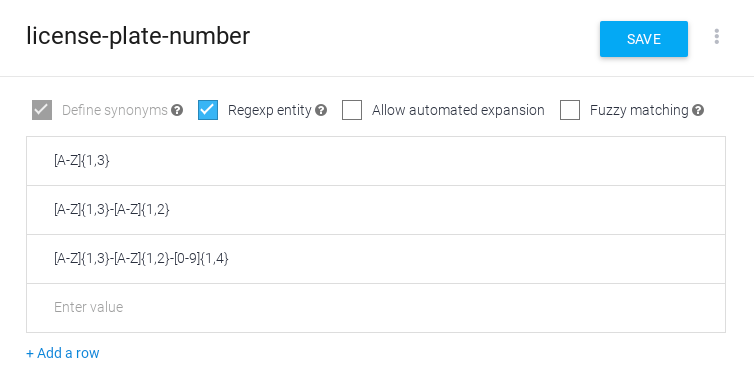
Wenn Sie Entitäten mit der API erstellen oder aktualisieren, verwenden Sie KIND_REGEXP für das Typfeld der Entität.
Einschränkungen
Es gelten folgende Einschränkungen:
- Ungenaue Übereinstimmung kann für RegExp-Entitäten nicht aktiviert werden. Diese Funktionen schließen sich gegenseitig aus.
- Jeder Agent kann maximal 50 RegExp-Entitäten enthalten.
- Der komplexe reguläre Ausdruck einer Entität ist maximal 2.000 Zeichen lang.