概览
专用连接是 Virtual Private Cloud (VPC) 网络与 Datastream 的专用网络之间的连接,使 Datastream 能够使用内部 IP 地址与资源进行通信。使用专用连接会在 Datastream 网络上建立专属的连接,这意味着其他客户无法共享此连接。
您可以使用专用连接将 Datastream 连接到任何来源。但是,只有直接对等互连的 VPC 网络才能相互通信。
不支持传递性对等互连。如果 DataStream 与之对等互连的网络不是托管来源的网络,则需要使用反向代理。如果您的来源是 Cloud SQL,并且您的来源托管在另一个 VPC 中或不在 Google 网络内,您就需要反向代理。
在本页面中,您将了解如何使用代理在 Datastream 与 Cloud SQL 之间,或在 Datastream 与托管在其他 VPC 中或 Google 网络外部的来源之间建立专用连接。
为什么需要 Cloud SQL 的反向代理?
将 Cloud SQL for MySQL 或 Cloud SQL for PostgreSQL 实例配置为使用专用 IP 地址时,您需要使用您的 VPC 网络与 Cloud SQL 实例所在的底层 Google 服务的 VPC 网络之间的 VPC 对等互连连接。
由于 Datastream 的网络无法与 Cloud SQL 的专用服务网络直接对等互连,并且由于 VPC 对等互连不具有传递性,因此需要使用 Cloud SQL 的反向代理来桥接从 Datastream 到 Cloud SQL 实例的连接。
下图展示了如何使用反向代理在 Datastream 和 Cloud SQL 之间建立专用连接。
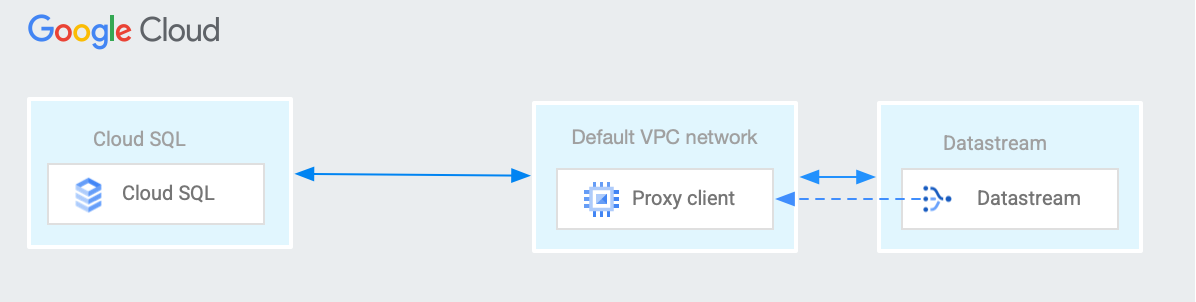
为什么您需要对托管在另一个 VPC 中的来源使用反向代理?
如果 Datastream 的 VPC 网络与您的 VPC 网络(“Network1”)对等互连,并且您的来源可从另一个 VPC 网络(“Network2”)访问,则 Datastream 不能仅使用 VPC 网络对等互连与来源进行通信。还需要使用反向代理来建立 Datastream 与来源之间的连接。
下图说明了如何使用反向代理在 Datastream 与托管在 Google 网络外部的来源之间建立专用连接。

设置反向代理
- 确定 Datastream 连接到来源的 VPC 网络。
- 在此 VPC 网络中,使用基本 Debian 或 Ubuntu 映像创建新的虚拟机 (VM)。此虚拟机将托管反向代理。
- 验证子网是否与 Datastream 位于同一区域,以及反向代理是否将流量转发到来源(而不是从来源转发流量)。
- 使用 SSH 连接到代理虚拟机。如需了解 SSH 连接,请参阅 SSH 连接简介。
- 通过从虚拟机到来源的内部 IP 地址和端口运行
ping或telnet命令,确认您的代理虚拟机是否可以与来源通信。 在代理虚拟机上,使用以下代码创建启动脚本。如需详细了解启动脚本,请参阅在 Linux 虚拟机上使用启动脚本。
#! /bin/bash export DB_ADDR=[IP] export DB_PORT=[PORT] export ETH_NAME=$(ip -o link show | awk -F': ' '{print $2}' | grep -v lo) export LOCAL_IP_ADDR=$(ip -4 addr show $ETH_NAME | grep -Po 'inet \K[\d.]+') echo 1 > /proc/sys/net/ipv4/ip_forward iptables -t nat -A PREROUTING -p tcp -m tcp --dport $DB_PORT -j DNAT \ --to-destination $DB_ADDR:$DB_PORT iptables -t nat -A POSTROUTING -j SNAT --to-source $LOCAL_IP_ADDR
每次虚拟机重新启动时,该脚本都会运行。
在 Datastream 中创建专用连接配置,以便在您的 VPC 与 Datastream 的 VPC 之间建立 VPC 对等互连。
验证您的防火墙规则是否允许来自为专用连接选择的 IP 地址范围的流量。
在 Datastream 中创建连接配置文件。
设置反向代理的最佳实践
本部分介绍了设置网关和代理虚拟机时应遵循的最佳实践。
机器类型
如需确定最适合您的机器类型,请先进行简单的设置,然后测量负载和吞吐量。如果使用量较低,且吞吐量峰值 处理时不会出现任何问题,不妨考虑减少 CPU 数量和 内存。例如,如果您的吞吐量上限为 2 Gbps,请选择 n1-standard-1 机器类型。如果您的吞吐量超过 2 GBps, 请选择 e2-standard-2 机器类型。e2-standard-2 类型是一种经济高效的配置,可提高效率。
架构类型
非高可用性 (非 HA) 实例
部署搭载您选择的操作系统的单个虚拟机。为了提高弹性 您可以在单个虚拟机中使用代管式实例组 (MIG)。如果您的虚拟机崩溃 MIG 会通过重新创建来自动修复失败的实例。如需了解详情,请参阅实例组。
高可用性 (HA) 实例
设置具有两个虚拟机的 MIG,每个虚拟机位于不同区域(如适用),或位于 另一个可用区如需创建 MIG,您必须拥有该实例组可以使用的实例模板。MIG 是在内部第 4 层负载均衡器后面使用内部下一个跃点 IP 地址创建的。