Datastream은 Oracle, MySQL, PostgreSQL 데이터베이스에서 BigQuery 데이터 세트로 직접 데이터를 스트리밍하도록 지원합니다. 그러나 데이터 변환 또는 논리적 기본 키에 대한 수동 설정과 같이 스트리밍 처리 논리를 세부적으로 제어해야 하는 경우에는 Datastream을 Dataflow 작업 템플릿에 통합할 수 있습니다.
이 튜토리얼에서는 분석용 BigQuery에서 최신 구체화된 뷰를 스트리밍하기 위해 Dataflow 작업 템플릿을 사용해서 Datastream을 Dataflow와 통합하는 방법을 보여줍니다.
데이터 소스가 여러 개로 격리된 조직의 경우에는 특히 실시간으로 조직 내 기업 데이터에 액세스하는 것이 제한적이고 느릴 수 있습니다. 그 결과 조직의 자체 조사 능력이 제한될 수 있습니다.
Datastream은 다양한 온프레미스 및 클라우드 기반 데이터 소스로부터 데이터를 변경할 수 있도록 거의 실시간 액세스를 제공합니다. Datastream은 사용자가 데이터 스트리밍을 위해 많은 구성을 수행할 필요가 없는 설정 환경을 제공하며, 사용자를 위해 이러한 작업을 자동으로 수행합니다. 조직은 Datastream의 통합 소비 API를 통해 대부분의 최신 기업 데이터에 민주적으로 액세스하고 통합 시나리오를 쉽게 생성할 수 있습니다.
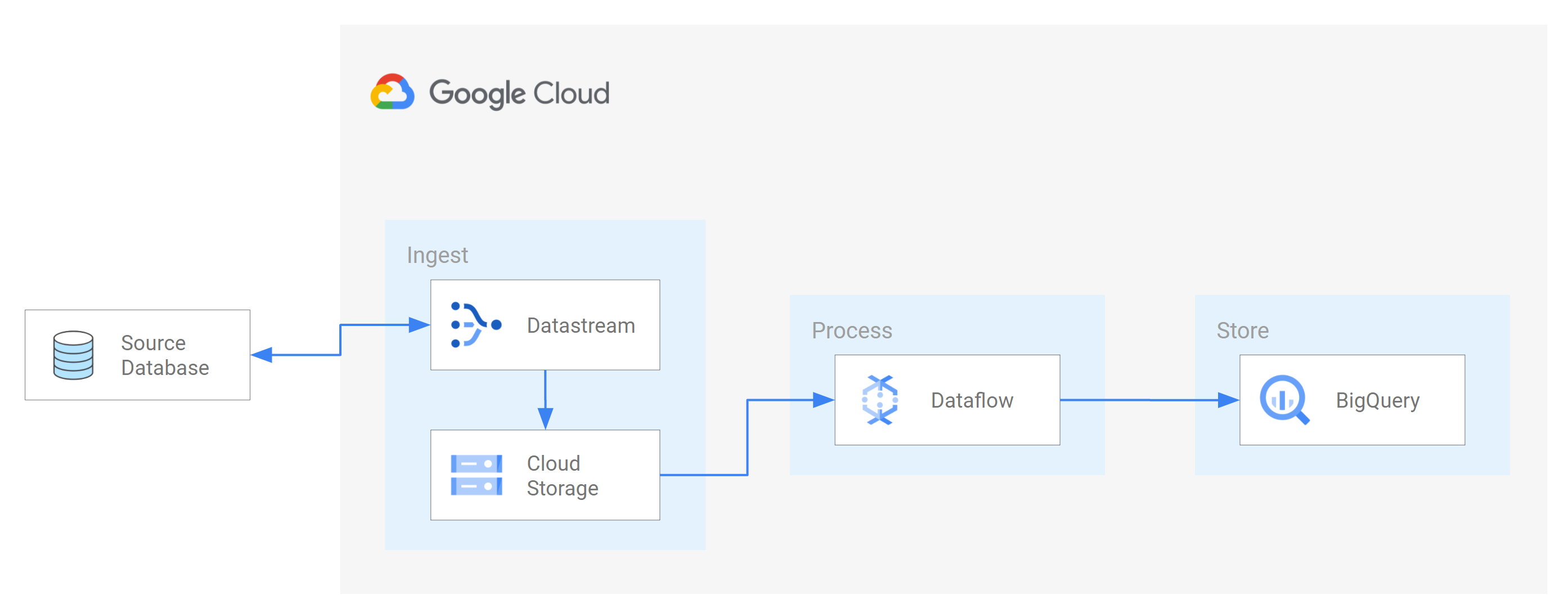
이러한 시나리오 중 하나는 소스 데이터베이스의 데이터를 클라우드 기반 스토리지 서비스 또는 메시지 큐로 전송하는 것입니다. Datastream이 데이터를 스트리밍한 후에는 다른 애플리케이션과 서비스가 읽을 수 있는 형식으로 데이터가 전송됩니다. 이 튜토리얼에서 Dataflow는 스토리지 서비스 또는 메시징 큐와 통신하여 Google Cloud에서 데이터를 캡처하고 처리하는 웹 서비스입니다.
Datastream을 사용하여 소스 MySQL 데이터베이스의 변경사항(삽입, 업데이트 또는 삭제된 데이터)을 Cloud Storage 버킷의 폴더로 스트리밍하는 방법을 알아봅니다. 그런 후 Datastream이 소스 데이터베이스로부터 스트리밍하는 데이터 변경사항을 포함하여 모든 새 파일을 확인하기 위해 Dataflow에 사용되는 알림을 전송하도록 Cloud Storage 버킷을 구성합니다. 그런 후 Dataflow 작업이 파일을 처리하고 변경사항을 BigQuery로 전송합니다.
목표
이 튜토리얼의 목표는 다음과 같습니다.- Cloud Storage에서 버킷을 만듭니다. 이것은 DataStream이 소스 MySQL 데이터베이스의 스키마, 테이블, 데이터를 스트리밍하는 대상 버킷입니다.
- Cloud Storage 버킷에 대해 Pub/Sub 알림을 사용 설정합니다. 이렇게 하면 Dataflow가 처리 준비된 새 파일을 확인하기 위해 사용하는 알림을 전송하도록 버킷이 구성됩니다. 이러한 파일에는 Datastream이 소스 데이터베이스에서 버킷으로 스트리밍하는 데이터 변경사항이 포함됩니다.
- BigQuery에서 데이터 세트를 만듭니다. BigQuery는 데이터 세트를 사용하여 Dataflow에서 수신하는 데이터를 포함합니다. 이 데이터는 Datastream이 Cloud Storage 버킷으로 스트림하는 소스 데이터베이스의 변경사항을 나타냅니다.
- 소스 데이터베이스와 Cloud Storage의 대상 버킷에 대한 연결 프로필을 만들고 관리합니다. Datastream의 스트림은 연결 프로필의 정보를 사용해서 소스 데이터베이스의 데이터를 버킷으로 전송합니다.
- 스트림을 만들고 시작합니다. 이 스트림은 소스 데이터베이스에서 버킷으로 데이터, 스키마, 테이블을 전송합니다.
- Datastream이 소스 데이터베이스의 스키마와 연결된 데이터와 테이블을 버킷으로 전송하는지 확인합니다.
- Dataflow에서 작업을 만듭니다. Datastream이 소스 데이터베이스에서 Cloud Storage 버킷으로 데이터 변경사항을 스트리밍한 후에는 변경사항이 포함된 새 파일에 대한 알림이 Dataflow로 전송됩니다. Dataflow 작업은 파일을 처리하고 변경사항을 BigQuery로 전송합니다.
- Dataflow가 이 데이터와 연관된 변경사항이 포함된 파일을 처리하고 변경사항을 BigQuery로 전송하는지 확인합니다. 그 결과 Datastream과 BigQuery 사이에 엔드 투 엔드 통합이 설정됩니다.
- 할당량을 차지하지 않고 이후에 비용이 청구되지 않도록 Datastream, Cloud Storage, Pub/Sub, Dataflow, BigQuery에서 만든 리소스를 삭제합니다.
비용
이 문서에서는 비용이 청구될 수 있는 다음과 같은 Google Cloud구성요소를 사용합니다.
- Datastream
- Cloud Storage
- Pub/Sub
- Dataflow
- BigQuery
프로젝트 사용량을 기준으로 예상 비용을 산출하려면 가격 계산기를 사용합니다.
시작하기 전에
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Verify that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Verify that billing is enabled for your Google Cloud project.
- Datastream API를 사용 설정합니다.
- Datastream 관리자 역할이 사용자 계정에 부여되었는지 확인합니다.
- Datastream이 액세스할 수 있는 소스 MySQL 데이터베이스가 있는지 확인합니다. 또한 데이터베이스에 데이터, 테이블, 스키마가 있는지 확인합니다.
- Datastream 공개 IP 주소의 수신 연결을 허용하도록 MySQL 데이터베이스를 구성합니다. 모든 Datastream 리전과 해당 연결된 공개 IP 주소 목록은 IP 허용 목록과 리전을 참조하세요.
- 소스 데이터베이스에 대한 변경 데이터 캡처(CDC)를 설정합니다. 자세한 내용은 소스 MySQL 데이터베이스 구성을 참조하세요.
Cloud Storage에 대해 Pub/Sub 알림을 사용 설정하도록 모든 기본 요건을 충족하는지 확인합니다.
이 튜토리얼에서는 Cloud Storage에 대상 버킷을 만들고 버킷에 대해 Pub/Sub 알림을 사용 설정합니다. 이렇게 하면 Dataflow는 Datastream이 버킷에 기록하는 새 파일에 대한 알림을 수신할 수 있습니다. 이러한 파일에는 Datastream이 소스 데이터베이스에서 버킷으로 스트리밍하는 데이터 변경사항이 포함됩니다.
요구사항
Datastream은 다양한 소스 옵션, 대상 옵션, 네트워킹 연결 방법을 제공합니다.
이 튜토리얼에서는 독립형 MySQL 데이터베이스와 대상 Cloud Storage 서비스를 사용한다고 가정합니다. 소스 데이터베이스의 경우 인바운드 방화벽 규칙을 추가하도록 네트워크를 구성할 수 있어야 합니다. 소스 데이터베이스는 온프레미스 또는 클라우드 제공업체에 있어야 합니다. Cloud Storage 대상의 경우에는 연결 구성이 필요하지 않습니다.
여기에서는 각 사용자 환경의 세부사항을 알 수 없기 때문에 네트워킹 구성과 관련해서 세부 단계를 제공할 수 없습니다.
이 튜토리얼에서는 IP 허용 목록을 네트워크 연결 방법으로 선택합니다. IP 허용 목록은 소스 데이터베이스의 데이터 액세스를 신뢰할 수 있는 사용자로 제한하고 제어하는 데 자주 사용되는 보안 기능입니다. IP 허용 목록을 사용하면 사용자 및 Datastream과 같은 다른 Google Cloud 서비스에서 이 데이터에 액세스할 수 있는 신뢰할 수 있는 IP 주소 또는 IP 범위의 목록을 만들 수 있습니다. IP를 허용 목록을 사용하려면 Datastream으로부터 수신되는 연결에 대해 소스 데이터베이스나 방화벽을 열어야 합니다.
Cloud Storage에서 버킷 만들기
Datastream이 소스 MySQL 데이터베이스에서 가져온 스키마, 테이블, 데이터를 스트리밍하는 Cloud Storage 내에서 대상 버킷을 생성합니다.
Google Cloud 콘솔에서 Cloud Storage에 대한 브라우저 페이지로 이동합니다.
버킷 만들기를 클릭합니다. 버킷 만들기 페이지가 나타납니다.
버킷 이름 지정 리전의 텍스트 필드에 버킷의 고유한 이름을 입력한 다음 계속을 클릭합니다.
페이지의 나머지 각 리전에 대해 기본 설정을 그대로 사용합니다. 각 리전의 끝에서 계속을 클릭합니다.
만들기를 클릭합니다.
Cloud Storage 버킷에 대해 Pub/Sub 알림을 사용 설정합니다.
이 섹션에서는 생성한 Cloud Storage 버킷에 대해 Pub/Sub 알림을 사용 설정합니다. 이렇게 하면 Datastream이 버킷에 기록하는 새 파일을 Dataflow에 알리도록 버킷을 구성합니다. 이러한 파일에는 Datastream이 소스 MySQL 데이터베이스에서 버킷으로 스트리밍하는 데이터 변경사항이 포함됩니다.
생성한 Cloud Storage 버킷에 액세스합니다. 버킷 세부정보 페이지가 나타납니다.
Cloud Shell 활성화를 클릭합니다.
프롬프트에서 다음 명령어를 입력합니다.
gcloud storage buckets notifications create gs://bucket-name --topic=my_integration_notifs --payload-format=json --object-prefix=integration/tutorial/선택사항: Cloud Shell 승인 창이 표시되면 승인을 클릭합니다.
다음 코드 줄이 표시되는지 확인합니다.
Created Cloud Pub/Sub topic projects/project-name/topics/my_integration_notifs Created notification config projects/_/buckets/bucket-name/notificationConfigs/1
Google Cloud 콘솔에서 Pub/Sub의 주제 페이지로 이동합니다.
생성한 my_integration_notifs 주제를 클릭합니다.
my_integration_notifs 페이지에서 페이지 하단으로 스크롤합니다. 구독 탭이 활성 상태이고 표시할 구독 없음 메시지가 표시되는지 확인합니다.
구독 만들기를 클릭합니다.
표시되는 메뉴에서 구독 만들기를 선택합니다.
주제에 구독 추가 대화상자에서 다음을 수행합니다.
- 구독 ID 필드에
my_integration_notifs_sub를 입력합니다. - 확인 기한 값을
120초로 설정합니다. 그러면 Dataflow가 처리된 파일을 시간 내에 충분히 확인할 수 있고 Dataflow 작업의 전체 성능이 향상됩니다. Pub/Sub 구독 속성에 대한 자세한 내용은 구독 속성을 참조하세요. - 페이지에서 다른 모든 값은 그대로 둡니다.
- 만들기를 클릭합니다.
- 구독 ID 필드에
이 튜토리얼의 뒷부분에서 Dataflow 작업을 생성합니다. 이 작업을 생성할 때는 my_integration_notifs_sub 구독의 구독자로 Dataflow를 할당합니다. 이렇게 하면 Datastream이 Cloud Storage에 기록하는 새 파일에 대한 알림을 Dataflow가 수신하고, 파일을 처리하고, 데이터 변경사항을 BigQuery로 전송할 수 있습니다.
BigQuery에서 데이터 세트 만들기
이 섹션에서는 BigQuery에서 데이터 세트를 만듭니다. BigQuery는 데이터 세트를 사용하여 Dataflow에서 수신하는 데이터를 포함합니다. 이 데이터는 Datastream이 Cloud Storage 버킷으로 스트림하는 소스 MySQL 데이터베이스의 변경사항을 나타냅니다.
Google Cloud 콘솔에서 BigQuery에 대한 SQL 작업공간 페이지로 이동합니다.
탐색기 창의 Google Cloud 프로젝트 이름 옆에서 작업 보기를 클릭합니다.
표시되는 메뉴에서 데이터 세트 만들기를 선택합니다.
데이터 세트 만들기 창에서 다음을 수행합니다.
- 데이터 세트 ID 필드에 데이터 세트의 ID를 입력합니다. 이 튜토리얼에서는 필드에
My_integration_dataset_log를 입력합니다. - 창에서 다른 모든 기본값은 그대로 둡니다.
- 데이터 세트 만들기를 클릭합니다.
- 데이터 세트 ID 필드에 데이터 세트의 ID를 입력합니다. 이 튜토리얼에서는 필드에
탐색기 창의 Google Cloud 프로젝트 이름 옆에서 노드 확장을 클릭한 후 생성한 데이터 세트가 보이는지 확인합니다.
이 절차의 단계에 따라 두 번째 데이터 세트 My_integration_dataset_final을 만듭니다.
각 데이터 세트 옆에서 노드 확장을 선택합니다.
각 데이터 세트가 비어 있는지 확인합니다.
Datastream이 소스 데이터베이스에서 Cloud Storage 버킷으로 데이터 변경사항을 스트리밍하면 Dataflow 작업이 변경사항이 포함된 파일을 처리하고 BigQuery 데이터 세트로 변경사항을 전송합니다.
Datastream에서 연결 프로필 만들기
이 섹션에서는 Datastream에서 소스 데이터베이스 및 대상에 대한 연결 프로필을 만듭니다. 연결 프로필을 만드는 동안 소스 연결 프로필의 프로필 유형으로 MySQL을 선택하고 대상 연결 프로필의 프로필 유형으로 Cloud Storage를 선택합니다.
Datastream은 연결 프로필에 정의된 정보를 사용하여 소스와 대상 모두에 연결하고 소스 데이터베이스의 데이터를 Cloud Storage의 대상 버킷으로 스트리밍합니다.
MySQL 데이터베이스에 대한 소스 연결 프로필 만들기
Google Cloud 콘솔에서 Datastream의 연결 프로필 페이지로 이동합니다.
프로필 만들기를 클릭합니다.
MySQL 데이터베이스에 대해 소스 연결 프로필을 만들려면 연결 프로필 만들기 페이지에서 MySQL 프로필 유형을 클릭합니다.
MySQL 프로필 만들기 페이지의 연결 설정 정의 섹션에서 다음 정보를 제공합니다.
- 연결 프로필 이름 필드에
My Source Connection Profile을 입력합니다. - 자동 생성된 연결 프로필 ID를 그대로 둡니다.
연결 프로필을 저장하려는 리전을 선택합니다.
연결 세부정보를 입력합니다.
- 호스트 이름 또는 IP 필드에 Datastream이 소스 데이터베이스에 연결하는 데 사용할 수 있는 호스트 이름 또는 공개 IP 주소를 입력합니다. 이 튜토리얼에 대한 네트워크 연결로 IP 허용 목록을 사용하기 때문에 공개 IP 주소를 제공합니다.
- 포트 필드에 소스 데이터베이스용으로 예약된 포트 번호를 입력합니다. MySQL 데이터베이스에서 기본 포트는 일반적으로
3306입니다. - 사용자 이름과 비밀번호를 입력하여 소스 데이터베이스에 인증을 수행합니다.
- 연결 프로필 이름 필드에
연결 설정 정의 섹션에서 계속을 클릭합니다. MySQL 프로필 만들기 페이지의 소스 연결 보호 섹션이 활성화됩니다.
암호화 유형 메뉴에서 없음을 선택합니다. 이 메뉴에 대한 자세한 내용은 MySQL 데이터베이스에 대한 연결 프로필 만들기를 참조하세요.
소스 연결 보호 섹션에서 계속을 클릭합니다. MySQL 프로필 만들기 페이지의 연결 방법 정의 섹션이 활성화됩니다.
연결 방법 드롭다운에서 Datastream과 소스 데이터베이스 사이에 연결을 설정하기 위해 사용하는 네트워킹 방법을 선택합니다. 이 튜토리얼에서는 연결 방법으로 IP 허용 목록을 선택합니다.
표시된 Datastream 공개 IP 주소의 수신 연결을 허용하도록 소스 데이터베이스를 구성합니다.
연결 방법 정의 섹션에서 계속을 클릭합니다. MySQL 프로필 만들기 페이지의 연결 프로필 테스트 섹션이 활성화됩니다.
테스트 실행을 클릭하여 소스 데이터베이스와 Datastream이 서로 통신할 수 있는지 확인합니다.
테스트 통과 상태가 표시되는지 확인합니다.
만들기를 클릭합니다.
Cloud Storage의 대상 연결 프로필 만들기
Google Cloud 콘솔에서 Datastream의 연결 프로필 페이지로 이동합니다.
프로필 만들기를 클릭합니다.
Cloud Storage에 대해 대상 연결 프로필을 만들려면 연결 프로필 만들기 페이지에서 Cloud Storage 프로필 유형을 클릭합니다.
Cloud Storage 프로필 만들기 페이지에서 다음 정보를 제공합니다.
- 연결 프로필 이름 필드에
My Destination Connection Profile을 입력합니다. - 자동 생성된 연결 프로필 ID를 그대로 둡니다.
- 연결 프로필을 저장하려는 리전을 선택합니다.
연결 세부정보 창에서 찾아보기를 클릭하여 이 튜토리얼의 앞부분에서 만든 Cloud Storage 버킷을 선택합니다. 이것은 Datastream이 소스 데이터베이스에서 데이터를 전송하는 버킷입니다. 항목을 선택한 후 선택을 클릭합니다.
연결 세부정보 창의 버킷 이름 필드에 버킷이 표시됩니다.
연결 프로필 경로 프리픽스 필드에 Datastream이 데이터를 대상으로 스트리밍할 때 버킷 이름에 추가하려는 경로의 프리픽스를 제공합니다. Datastream이 버킷 루트 폴더가 아닌 버킷 내내부의 경로로 데이터를 기록하는지 확인합니다. 이 튜토리얼에서는 Pub/Sub 알림을 구성할 때 정의한 경로를 사용합니다. 입력란에
/integration/tutorial을 입력합니다.
- 연결 프로필 이름 필드에
만들기를 클릭합니다.
MySQL 데이터베이스의 소스 연결 프로필과 Cloud Storage의 대상 연결 프로필을 만든 후 이를 사용하여 스트림을 만들 수 있습니다.
Datastream에서 스트림 만들기
이 섹션에서 스트림을 만듭니다. 이 스트림은 연결 프로필의 정보를 사용해서 소스 MySQL 데이터베이스에서 Cloud Storage의 대상 버킷으로 데이터를 전송합니다.
스트림 설정 정의
Google Cloud 콘솔에서 Datastream에 대한 스트림 페이지로 이동합니다.
스트림 만들기를 클릭합니다.
스트림 만들기 페이지의 스트림 세부정보 정의 패널에 다음 정보를 제공합니다.
- 스트림 이름 필드에
My Stream을 입력합니다. - 자동 생성된 스트림 ID를 그대로 둡니다.
- 리전 메뉴에서 소스 및 대상 연결 프로필을 만든 리전을 선택합니다.
- 소스 유형 메뉴에서 MySQL 프로필 유형을 선택합니다.
- 대상 유형 메뉴에서 Cloud Storage 프로필 유형을 선택합니다.
- 스트림 이름 필드에
스트림에 맞게 환경을 준비해야 하는 방법이 자동으로 반영되도록 생성된 필수 기본 요건을 검토합니다. 이러한 기본 요건에는 소스 데이터베이스 구성 방법과 Cloud Storage의 대상 버킷에 Datastream을 연결하는 방법이 포함될 수 있습니다.
계속을 클릭합니다. 스트림 만들기 페이지의 MySQL 연결 프로필 정의 패널이 표시됩니다.
소스 연결 프로필 정보 지정
이 섹션에서는 소스 데이터베이스에 대해 만든 연결 프로필(소스 연결 프로필)을 선택합니다. 이 튜토리얼에서는 내 소스 연결 프로필입니다.
소스 연결 프로필 메뉴에서 MySQL 데이터베이스에 대한 소스 연결 프로필을 선택합니다.
테스트 실행을 클릭하여 소스 데이터베이스와 Datastream이 서로 통신할 수 있는지 확인합니다.
테스트에 실패하면 연결 프로필과 관련된 문제가 표시됩니다. 문제 해결 단계는 문제 진단 페이지를 참조하세요. 문제 해결을 위해 필요한 항목을 변경한 후 다시 테스트합니다.
계속을 클릭합니다. 스트림 만들기 페이지의 스트림 소스 구성 패널이 표시됩니다.
스트림의 소스 데이터베이스에 대한 정보 구성
이 섹션에서는 스트림에 사용되는 소스 데이터베이스에 대한 구성 세부정보를 설정합니다. 여기에는 Datastream이 다음과 같은 특성을 갖는 소스 데이터베이스의 테이블 및 스키마 지정이 포함됩니다.
- 대상으로 데이터를 전송할 수 있습니다.
- 대상으로 전송이 제한됩니다.
또한 Datastream이 이전 데이터를 백필하고 계속해서 지속적인 변경 사항을 대상으로 스트리밍하거나 이전 데이터 백필 없이 데이터 변경사항만 스트리밍할지 결정할 수 있습니다.
포함할 객체 메뉴를 사용하여 Datastream이 Cloud Storage의 대상 버킷에 있는 폴더로 전송할 수 있는 소스 데이터베이스의 테이블과 스키마를 지정합니다. 데이터베이스에 최대 5,000개의 객체가 있는 경우에만 메뉴가 로드됩니다.
이 튜토리얼에서는 Datastream이 모든 테이블과 스키마를 전송하도록 합니다. 따라서 메뉴에서 모든 스키마의 모든 테이블을 선택합니다.
제외할 객체 선택 패널이 없음으로 설정되어 있는지 확인합니다. Datastream이 소스 데이터베이스의 테이블 및 스키마를 Cloud Storage로 전송하는 것을 제한하지 않으려고 합니다.
이전 데이터의 백필 모드 선택 패널이 자동으로 설정되어 있는지 확인합니다. Datastream이 데이터 변경사항은 물론 모든 기존 데이터를 소스에서 대상으로 스트리밍합니다.
계속을 클릭합니다. 스트림 만들기 페이지의 Cloud Storage 연결 프로필 정의 패널이 표시됩니다.
대상 연결 프로필 선택
이 섹션에서는 Cloud Storage에 대해 만든 연결 프로필(대상 연결 프로필)을 선택합니다. 이 튜토리얼에서는 내 대상 연결 프로필입니다.
대상 연결 프로필 메뉴에서 Cloud Storage의 대상 연결 프로필을 선택합니다.
계속을 클릭합니다. 스트림 만들기 페이지의 스트림 대상 구성 패널이 표시됩니다.
스트림의 대상 정보 구성
이 섹션에서는 스트림의 대상 버킷에 대한 정보를 구성합니다. 이러한 정보에는 다음이 포함됩니다.
- Cloud Storage에 기록된 파일의 출력 형식.
- Datastream이 소스 데이터베이스에서 스키마, 테이블, 데이터를 전송하는 대상 버킷의 폴더입니다.
출력 형식 필드에서 Cloud Storage에 기록된 파일 형식을 선택합니다. Datastream에서는 Avro 및 JSON의 두 가지 출력 형식만 지원됩니다. 이 튜토리얼에서 파일 형식은 Avro입니다.
계속을 클릭합니다. 스트림 만들기 페이지의 스트림 세부정보 검토 및 만들기 패널이 표시됩니다.
스트림 만들기
스트림은 물론 소스 MySQL 데이터베이스에서 Cloud Storage의 대상 버킷으로 데이터를 전송하기 위해 스트림에 사용되는 소스 및 대상 연결 프로필에 대한 세부정보를 확인합니다.
스트림을 검증하려면 검증 실행을 클릭합니다. Datastream은 스트림을 검증하여 소스가 올바르게 구성되었는지 확인하고, 스트림이 소스 및 대상 모두에 연결할 수 있는지 확인하고, 스트림의 엔드 투 엔드 구성을 확인합니다.
모든 검증 확인에 통과하면 만들기를 클릭합니다.
스트림 만들기 대화상자에서 만들기를 클릭합니다.
스트림 시작
이 튜토리얼에서는 스트림 생성 프로세스로 인해 소스 데이터베이스에서 부하가 증가하는 경우를 대비하여 스트림을 별도로 만들고 시작합니다. 이러한 부하를 막으려면 스트림을 만들 때 시작하지 않고 데이터베이스가 부하를 처리할 수 있을 때 스트림을 시작합니다.
스트림을 시작하면 Datastream이 소스 데이터베이스에서 대상으로 데이터, 스키마, 테이블을 전송할 수 있습니다.
Google Cloud 콘솔에서 Datastream에 대한 스트림 페이지로 이동합니다.
시작하려는 스트림 옆에 있는 체크박스를 선택합니다. 이 튜토리얼에서는 내 스트림입니다.
시작을 클릭합니다.
대화상자에서 시작을 클릭합니다. 스트림 상태가
Not started에서Starting,Running으로 변경됩니다.
스트림을 시작한 후 Datastream이 소스 데이터베이스에서 대상으로 데이터를 전송했는지 확인할 수 있습니다.
스트림 검증
이 섹션에서는 Datastream이 소스 MySQL 데이터베이스의 모든 테이블에서 Cloud Storage 대상 버킷의 /integration/tutorial 폴더로 데이터를 전송하는지 확인합니다.
Google Cloud 콘솔에서 Datastream에 대한 스트림 페이지로 이동합니다.
생성된 스트림을 클릭합니다. 이 튜토리얼에서는 내 스트림입니다.
스트림 세부정보 창에서 bucket-name/integration/tutorial 링크를 클릭합니다. 여기서 bucket-name은 Cloud Storage 버킷에 지정한 이름입니다. 이 링크는 대상 쓰기 경로 필드 다음에 표시됩니다. Cloud Storage의 버킷 세부정보 페이지가 개별 탭으로 열립니다.
소스 데이터베이스의 테이블을 나타내는 폴더가 표시되는지 확인합니다.
테이블 폴더 중 하나를 클릭한 후 테이블과 연결된 데이터가 표시될 때까지 각 하위 폴더를 클릭합니다.
Dataflow 작업 만들기
이 섹션에서는 Dataflow의 작업을 만듭니다. Datastream이 소스 MySQL 데이터베이스에서 Cloud Storage 버킷으로 데이터 변경사항을 스트리밍한 후 Pub/Sub는 변경사항이 포함된 새 파일에 대한 알림을 Dataflow로 전송합니다. Dataflow 작업은 파일을 처리하고 변경사항을 BigQuery로 전송합니다.
Google Cloud 콘솔에서 Dataflow의 작업 페이지로 이동합니다.
템플릿에서 작업 만들기를 클릭합니다.
템플릿에서 작업 만들기 페이지의 작업 이름 필드에 만들려는 Dataflow 작업의 이름을 입력합니다. 이 튜토리얼에서는 필드에
my-dataflow-integration-job을 입력합니다.리전별 엔드포인트 메뉴에서 작업을 저장하려는 리전을 선택합니다. 이 리전은 소스 연결 프로필, 대상 연결 프로필, 생성된 스트림에 선택한 리전과 같습니다.
Dataflow 템플릿 메뉴에서 작업을 만들기 위해 사용 중인 템플릿을 선택합니다. 이 튜토리얼에서는 Datastream에서 BigQuery로를 선택합니다.
이 항목을 선택하면 이 템플릿과 관련된 추가 필드가 표시됩니다.
Cloud Storage에서 Datastream 파일 출력을 위한 파일 위치 필드에
gs://bucket-name형식을 사용하여 Cloud Storage 버킷 이름을 입력합니다.Cloud Storage 알림 정책에 사용 중인 Pub/Sub 구독 필드에 Pub/Sub 구독 이름이 포함된 경로를 입력합니다. 이 튜토리얼에서는
projects/project-name/subscriptions/my_integration_notifs_sub를 입력합니다.이 튜토리얼에서는 Avro가 Datastream이 Cloud Storage에 쓰는 파일의 파일 형식이므로 Datastream 출력 파일 형식(avro/json) 필드에
avro를 입력합니다.스테이징 테이블을 포함할 데이터 세트의 이름 또는 템플릿 필드에
My_integration_dataset_log를 입력합니다. Dataflow는 이 데이터 세트를 사용하여 Datastream에서 수신하는 데이터 변경사항을 스테이징하기 때문입니다.복제본 테이블을 포함할 데이터 세트의 템플릿 필드에
My_integration_dataset_final을 입력합니다. 소스 데이터베이스에 있는 일대일 테이블 복제본을 만들기 위해 이 데이터 세트에서 My_integration_dataset_log 데이터 세트에 스테이징된 변경사항이 병합되기 때문입니다.데드 레터 큐 디렉터리 필드에 Cloud Storage 버킷의 이름이 포함된 경로 그리고 데드 레터 큐의 폴더를 입력합니다. 루트 폴더의 경로가 사용되지 않는지 확인하고 이 경로가 Datastream이 데이터를 기록하는 경로와 다른지 확인합니다. Dataflow가 BigQuery로 전송하지 못하는 모든 데이터 변경사항은 큐에 저장됩니다. Dataflow가 다시 처리할 수 있도록 큐에서 콘텐츠를 수정할 수 있습니다.
이 튜토리얼에서는 데드 레터 큐 디렉터리 필드에
gs://bucket-name/dlq를 입력합니다(여기서 bucket-name은 버킷의 이름이고 dlq는 데드 레터 큐의 폴더입니다).작업 실행을 클릭합니다.
통합 확인
이 튜토리얼의 스트림 확인 섹션에서 Datastream이 소스 MySQL 데이터베이스의 모든 테이블에서 Cloud Storage 대상 버킷의 /integration/tutorial 폴더로 데이터를 전송했음을 확인했습니다.
이 섹션에서는 Dataflow가 이 데이터와 연결된 변경사항이 포함된 파일을 처리하고 변경사항을 BigQuery로 전송하는지 확인합니다. 그 결과 Datastream과 BigQuery 사이에 엔드 투 엔드 통합이 설정됩니다.
Google Cloud 콘솔에서 BigQuery에 대한 SQL 작업공간으로 이동합니다.
탐색기 창에서 Google Cloud 프로젝트 이름 옆의 노드를 확장합니다.
My_integration_dataset_log 및 My_integration_dataset_final 데이터 세트 옆의 노드를 확장합니다.
이제 각 데이터 세트에 데이터가 포함되었는지 확인합니다. 그러면 Datastream이 Cloud Storage로 스트리밍한 데이터와 연결된 변경사항이 포함된 파일이 Dataflow에서 처리되었고 변경사항이 BigQuery로 전송된 것을 확인할 수 있습니다.
삭제
이 튜토리얼에서 사용된 리소스의 비용이 Google Cloud 계정에 청구되지 않도록 하려면 Google Cloud 콘솔을 사용해서 다음을 수행합니다.
- 프로젝트, Datastream 스트림, Datastream 연결 프로필을 삭제합니다.
- Dataflow 작업을 중지합니다.
- BigQuery 데이터 세트, Pub/Sub 주제와 구독, Cloud Storage 버킷을 삭제합니다.
Datastream, Dataflow, BigQuery, Pub/Sub, Cloud Storage에서 만든 리소스를 삭제하면 해당 리소스가 할당량을 차지하지 않고 이후 해당 비용이 청구되지 않습니다.
프로젝트 삭제
비용이 청구되지 않도록 하는 가장 쉬운 방법은 튜토리얼에서 만든 프로젝트를 삭제하는 것입니다.
Google Cloud 콘솔에서 리소스 관리 페이지로 이동합니다.
프로젝트 목록에서 삭제할 프로젝트를 선택하고 삭제를 클릭합니다.
프로젝트를 삭제하려면 대화상자에서 프로젝트 ID를 입력한 후 종료를 클릭합니다.
스트림 삭제
Google Cloud 콘솔에서 Datastream에 대한 스트림 페이지로 이동합니다.
삭제하려는 스트림을 클릭합니다. 이 튜토리얼에서는 내 스트림입니다.
일시중지를 클릭합니다.
대화상자에서 일시중지를 클릭합니다.
스트림 세부정보 페이지의 스트림 상태 창에서 스트림 상태가
Paused인지 확인합니다.삭제를 클릭합니다.
대화상자의 텍스트 필드에
Delete를 입력한 후 삭제를 클릭합니다.
연결 프로필 삭제
Google Cloud 콘솔에서 Datastream의 연결 프로필 페이지로 이동합니다.
내 소스 연결 프로필 및 내 대상 연결 프로필을 삭제하려는 각 연결 프로필의 체크박스를 선택합니다.
삭제를 클릭합니다.
대화상자에서 삭제를 클릭합니다.
Dataflow 작업 중지
Google Cloud 콘솔에서 Dataflow의 작업 페이지로 이동합니다.
중지할 작업을 클릭합니다. 이 튜토리얼에서는 my-dataflow-integration-job입니다.
중지를 클릭합니다.
작업 중지 대화상자에서 드레이닝 옵션을 선택한 후 작업 중지를 클릭합니다.
BigQuery 데이터 세트 삭제
Google Cloud 콘솔에서 BigQuery에 대한 SQL 작업공간으로 이동합니다.
탐색기 창에서 Google Cloud 프로젝트 이름 옆의 노드를 확장합니다.
BigQuery에서 데이터 세트 만들기에서 만든 데이터 세트 중 하나의 오른쪽에 있는 작업 보기 버튼을 클릭합니다. 이 버튼은 세로 생략 기호처럼 보입니다.
이 튜토리얼에서 My_integration_dataset_log 오른쪽에 있는 작업 보기 버튼을 클릭합니다.
표시되는 드롭다운 메뉴에서 삭제를 선택합니다.
데이터 세트를 삭제하시겠습니까? 대화상자의 텍스트 필드에
delete를 입력한 후 삭제를 클릭합니다.다음 절차의 단계를 반복해서 생성된 두 번째 데이터 세트인 My_integration_dataset_final을 삭제합니다.
Pub/Sub 구독 및 주제 삭제
Google Cloud 콘솔에서 Pub/Sub의 구독 페이지로 이동합니다.
삭제하려는 구독 옆의 체크박스를 클릭합니다. 이 튜토리얼에서는 my_integration_notifs_sub 구독 옆의 체크박스를 클릭합니다.
삭제를 클릭합니다.
구독 삭제 대화상자에서 삭제를 클릭합니다.
Google Cloud 콘솔에서 Pub/Sub의 주제 페이지로 이동합니다.
my_integration_notifs 주제 옆의 체크박스를 클릭합니다.
삭제를 클릭합니다.
주제 삭제 대화상자의 텍스트 필드에
delete를 입력한 후 삭제를 클릭합니다.
Cloud Storage 버킷 삭제
Google Cloud 콘솔에서 Cloud Storage에 대한 브라우저 페이지로 이동합니다.
버킷 옆에 있는 체크박스를 선택합니다.
삭제를 클릭합니다.
대화상자에서 텍스트 필드에
Delete를 입력한 후 삭제를 클릭합니다.
다음 단계
- Datastream에 대해 자세히 알아보기
- 기존 스트리밍 API를 사용해서 BigQuery에 데이터 스트리밍 고급 기능을 수행하기
- 다른 Google Cloud 기능을 직접 사용해 보기 가이드 참조