本教程使用 Dataproc Metastore 提出双区域灾难恢复和业务连续性策略。本教程使用双区域存储桶来存储 Hive 数据集和 Hive 元数据导出。
Dataproc Metastore 是一项全代管式高可用性 OSS 原生 Metastore 服务,具有自动扩缩和自动修复功能,可显著简化技术元数据管理。我们的代管式服务基于 Apache Hive Metastore,并充当企业数据湖的关键组件。
本教程适用于 Google Cloud 需要 Hive 数据和元数据高可用性的客户。该教程使用 Cloud Storage 进行存储,使用 Dataproc 进行计算,并使用 Dataproc Metastore (DPMS),这是 Google Cloud上的一项全代管式 Hive Metastore 服务。本教程还提供了两种不同的故障切换编排方法:一种使用 Cloud Run 和 Cloud Scheduler,另一种使用 Cloud Composer。
本教程中使用的双区域方法具有以下优点和缺点:
优势
- 双区域存储桶具有地理位置冗余性。
- 双区域存储桶的服务等级协议 (SLA) 承诺的可用性为 99.95%,而单区域存储桶的服务等级协议 (SLA) 承诺的可用性为 99.9%。
- 双区域存储桶在两个区域中均优化了性能,相比之下,单区域存储桶在处理位于其他区域中的资源时则表现为性能不佳。
缺点
- 双区域存储桶写入内容不会立即复制到这两个区域。
- 双区域存储桶的存储费用高于单区域存储桶。
参考架构
以下架构图展示了您在本教程中使用的组件。在这两个图表中,红色的大号 X 表示主要区域发生故障:
 图 1:使用 Cloud Run 和 Cloud Scheduler
图 1:使用 Cloud Run 和 Cloud Scheduler
 图 2:使用 Cloud Composer
图 2:使用 Cloud Composer
该解决方案的组件及其关系包括:
- 两个 Cloud Storage 双区域存储桶:为 Hive 数据创建一个存储桶,并为 Hive 元数据的定期备份创建一个存储桶。创建两个双区域存储桶,使其使用与访问数据的 Hadoop 集群相同的区域。
- 使用 DPMS 的 Hive Metastore:您可以在主要区域(区域 A)中创建此 Hive Metastore。Metastore 配置指向 Hive 数据存储分区。使用 Dataproc 的 Hadoop 集群必须与它附加到的 DPMS 实例位于同一区域。
- 第二个 DPMS 实例:在备用区域(区域 B)中创建第二个 DPMS 实例,以便为发生区域范围故障做好准备。然后,将最新的
hive.sql导出文件从导出存储桶导入备用 DPMS。您还可以在备用区域中创建 Dataproc 集群,并将其关联到备用 DPMS 实例。最后,在灾难恢复场景中,将客户端应用从区域 A 中的 Dataproc 集群重定向到区域 B 中的 Dataproc 集群。 Cloud Run 部署:您可以在区域 A 中创建 Cloud Run 部署,该部署使用 Cloud Scheduler 定期将 DPMS 元数据导出到元数据备份存储分区(如图 1 所示)。导出采用 SQL 文件的形式,其中包含 DPMS 元数据的完整转储。
如果您已有 Cloud Composer 环境,则可以通过在该环境中运行 Airflow DAG 来编排 DPMS 元数据导出和导入(如图 2 所示)。可以使用 Airflow DAG 来代替之前提到的 Cloud Run 方法。
目标
- 为 Hive 数据和 Hive Metastore 备份设置双区域存储空间。
- 在区域 A 和区域 B 中部署 Dataproc Metastore 和 Dataproc 集群。
- 将部署故障切换到区域 B。
- 将部署故障恢复到区域 A。
- 创建自动 Hive Metastore 备份。
- 通过 Cloud Run 编排元数据导出和导入。
- 通过 Cloud Composer 编排元数据导出和导入。
费用
在本文档中,您将使用 Google Cloud的以下收费组件:
如需根据您的预计使用量来估算费用,请使用价格计算器。
准备工作
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Dataproc, and Dataproc Metastore APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Create a service account:
-
Ensure that you have the Create Service Accounts IAM role
(
roles/iam.serviceAccountCreator). Learn how to grant roles. -
In the Google Cloud console, go to the Create service account page.
Go to Create service account - Select your project.
-
In the Service account name field, enter a name. The Google Cloud console fills in the Service account ID field based on this name.
In the Service account description field, enter a description. For example,
Service account for quickstart. - Click Create and continue.
-
Grant the Project > Owner role to the service account.
To grant the role, find the Select a role list, then select Project > Owner.
- Click Continue.
-
Click Done to finish creating the service account.
Do not close your browser window. You will use it in the next step.
-
Ensure that you have the Create Service Accounts IAM role
(
-
Create a service account key:
- In the Google Cloud console, click the email address for the service account that you created.
- Click Keys.
- Click Add key, and then click Create new key.
- Click Create. A JSON key file is downloaded to your computer.
- Click Close.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Dataproc, and Dataproc Metastore APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Create a service account:
-
Ensure that you have the Create Service Accounts IAM role
(
roles/iam.serviceAccountCreator). Learn how to grant roles. -
In the Google Cloud console, go to the Create service account page.
Go to Create service account - Select your project.
-
In the Service account name field, enter a name. The Google Cloud console fills in the Service account ID field based on this name.
In the Service account description field, enter a description. For example,
Service account for quickstart. - Click Create and continue.
-
Grant the Project > Owner role to the service account.
To grant the role, find the Select a role list, then select Project > Owner.
- Click Continue.
-
Click Done to finish creating the service account.
Do not close your browser window. You will use it in the next step.
-
Ensure that you have the Create Service Accounts IAM role
(
-
Create a service account key:
- In the Google Cloud console, click the email address for the service account that you created.
- Click Keys.
- Click Add key, and then click Create new key.
- Click Create. A JSON key file is downloaded to your computer.
- Click Close.
- 在 Cloud Shell 中,启动 Cloud Shell 实例。
克隆教程的 GitHub 代码库:
git clone https://github.com/GoogleCloudPlatform/metastore-disaster-recovery.git启用以下 Google Cloud API:
gcloud services enable dataproc.googleapis.com metastore.googleapis.com设置一些环境变量:
export PROJECT=$(gcloud info --format='value(config.project)') export WAREHOUSE_BUCKET=${PROJECT}-warehouse export BACKUP_BUCKET=${PROJECT}-dpms-backups export DPMS_PRIMARY_REGION=us-central1 export DPMS_STANDBY_REGION=us-east1 export DPMS_PRIMARY_INSTANCE=dpms1 export DPMS_STANDBY_INSTANCE=dpms2 export HADOOP_PRIMARY=dataproc-cluster1 export HADOOP_STANDBY=dataproc-cluster2
初始化环境
为 Hive 数据和 Hive Metastore 备份创建存储空间
在本部分,您将创建 Cloud Storage 存储桶来托管 Hive 数据和 Hive Metastore 备份。
创建 Hive 数据存储空间
在 Cloud Shell 中,创建一个双区域存储桶来托管 Hive 数据:
gcloud storage buckets create gs://${WAREHOUSE_BUCKET} --location=NAM4将一些示例数据复制到 Hive 数据存储桶:
gcloud storage cp gs://retail_csv gs://${WAREHOUSE_BUCKET}/retail --recursive
为元数据备份创建存储空间
在 Cloud Shell 中,创建一个双区域存储桶来托管 DPMS 元数据备份:
gcloud storage buckets create gs://${BACKUP_BUCKET} --location=NAM4
在主要区域中部署计算资源
在本部分中,您将在主要区域中部署所有计算资源,包括 DPMS 实例和 Dataproc 集群。您还可以使用示例元数据填充 Dataproc Metastore。
创建 DPMS 实例
在 Cloud Shell 中,创建 DPMS 实例:
gcloud metastore services create ${DPMS_PRIMARY_INSTANCE} \ --location=${DPMS_PRIMARY_REGION} \ --hive-metastore-version=3.1.2此命令可能需要几分钟才能完成。
将 Hive 数据存储桶设置为默认仓库目录:
gcloud metastore services update ${DPMS_PRIMARY_INSTANCE} \ --location=${DPMS_PRIMARY_REGION} \ --update-hive-metastore-configs="hive.metastore.warehouse.dir=gs://${PROJECT}- warehouse"此命令可能需要几分钟才能完成。
创建 Dataproc 集群
在 Cloud Shell 中,创建一个 Dataproc 集群并将其关联到 DPMS 实例:
gcloud dataproc clusters create ${HADOOP_PRIMARY} \ --dataproc-metastore=projects/${PROJECT}/locations/${DPMS_PRIMARY_REGION}/services/${DPMS_PRIMARY_INSTANCE} \ --region=${DPMS_PRIMARY_REGION} \ --image-version=2.0请将集群映像指定为 2.0 版(这是 2021 年 6 月以来发布的最新版本)。此版本也是第一个支持 DPMS 的版本。
填充 Metastore
在 Cloud Shell 中,使用 Hive 数据存储桶的名称更新本教程的代码库中提供的示例
retail.hql:sed -i -- 's/${WAREHOUSE_BUCKET}/'"$WAREHOUSE_BUCKET"'/g' retail.hql运行
retail.hql文件中包含的查询,以在 Metastore 中创建表定义:gcloud dataproc jobs submit hive \ --cluster=${HADOOP_PRIMARY} \ --region=${DPMS_PRIMARY_REGION} \ --file=retail.hql验证是否已正确创建表定义:
gcloud dataproc jobs submit hive \ --cluster=${HADOOP_PRIMARY} \ --region=${DPMS_PRIMARY_REGION} \ --execute=" desc departments; desc categories; desc products; desc order_items; desc orders; desc customers; select count(*) as num_departments from departments; select count(*) as num_categories from categories; select count(*) as num_products from products; select count(*) as num_order_items from order_items; select count(*) as num_orders from orders; select count(*) as num_customers from customers; "输出类似以下内容:
+------------------+------------+----------+ | col_name | data_type | comment | +------------------+------------+----------+ | department_id | int | | | department_name | string | | +------------------+------------+----------+
输出还包含每个表中的元素数量,例如:
+----------------+ | num_customers | +----------------+ | 12435 | +----------------+
故障切换到备用区域
本部分介绍了从主要区域(区域 A)故障切换到备用区域(区域 B)的步骤。
在 Cloud Shell 中,将 DPMS 主实例的元数据导出到备份存储桶:
gcloud metastore services export gcs ${DPMS_PRIMARY_INSTANCE} \ --location=${DPMS_PRIMARY_REGION} \ --destination-folder=gs://${BACKUP_BUCKET}输出类似以下内容:
metadataManagementActivity: metadataExports: ‐ databaseDumpType: MYSQL destinationGcsUri: gs://qa01-300915-dpms-backups/hive-export-2021-05-04T22:21:53.288Z endTime: '2021-05-04T22:23:35.982214Z' startTime: '2021-05-04T22:21:53.308534Z' state: SUCCEEDED请记下
destinationGcsUri属性中的值。此属性可存储您创建的备份。在备用区域中创建新的 DPMS 实例:
gcloud metastore services create ${DPMS_STANDBY_INSTANCE} \ --location=${DPMS_STANDBY_REGION} \ --hive-metastore-version=3.1.2将 Hive 数据存储桶设置为默认仓库目录:
gcloud metastore services update ${DPMS_STANDBY_INSTANCE} \ --location=${DPMS_STANDBY_REGION} \ --update-hive-metastore-configs="hive.metastore.warehouse.dir=gs://${PROJECT}-warehouse"检索最新元数据备份的路径:
IMPORT_DIR=`gcloud storage ls gs://${BACKUP_BUCKET} | sort -k 1 | tail -1` IMPORT_SQL="${IMPORT_DIR}hive.sql" echo ${IMPORT_SQL}将备份的元数据导入新的 Dataproc Metastore 实例:
gcloud metastore services import gcs ${DPMS_STANDBY_INSTANCE} \ --location=${DPMS_STANDBY_REGION} \ --dump-type=mysql \ --database-dump=${IMPORT_SQL} \ --import-id=import-$(date +"%Y-%m-%d-%H-%M-%S")在备用区域(区域 B)中创建 Dataproc 集群:
gcloud dataproc clusters create ${HADOOP_STANDBY} \ --dataproc-metastore=projects/${PROJECT}/locations/${DPMS_STANDBY_REGION}/services/${DPMS_STANDBY_INSTANCE} \ --region=${DPMS_STANDBY_REGION} \ --image-version=2.0验证是否已正确导入元数据:
gcloud dataproc jobs submit hive \ --cluster ${HADOOP_STANDBY} \ --region ${DPMS_STANDBY_REGION} \ --execute "select count(*) as num_orders from orders;"num_orders输出对本教程最为重要。它类似于以下内容:+-------------+ | num_orders | +-------------+ | 68883 | +-------------+主要 Dataproc Metastore 已成为新的备用 Metastore,备用 Dataproc Metastore 已成为新的主要 Metastore。
根据这些新角色更新环境变量:
export DPMS_PRIMARY_REGION=us-east1 export DPMS_STANDBY_REGION=us-central1] export DPMS_PRIMARY_INSTANCE=dpms2 export DPMS_STANDBY_INSTANCE=dpms1 export HADOOP_PRIMARY=dataproc-cluster2 export HADOOP_STANDBY=dataproc-cluster1验证您是否可以写入区域 B 中新的主要 Dataproc Metastore:
gcloud dataproc jobs submit hive \ --cluster ${DPMS_PRIMARY_INSTANCE} \ --region ${DPMS_PRIMARY_REGION} \ --execute "create view completed_orders as select * from orders where order_status = 'COMPLETE';" gcloud dataproc jobs submit hive \ --cluster ${HADOOP_PRIMARY} \ --region ${DPMS_PRIMARY_REGION} \ --execute "select * from completed_orders limit 5;"输出包含以下内容:
+----------------------------+------------------------------+-------------------------------------+--------------------------------+ | completed_orders.order_id | completed_orders.order_date | completed_orders.order_customer_id | completed_orders.order_status | +----------------------------+------------------------------+-------------------------------------+--------------------------------+ | 3 | 2013-07-25 00:00:00.0 | 12111 | COMPLETE | | 5 | 2013-07-25 00:00:00.0 | 11318 | COMPLETE | | 6 | 2013-07-25 00:00:00.0 | 7130 | COMPLETE | | 7 | 2013-07-25 00:00:00.0 | 4530 | COMPLETE | | 15 | 2013-07-25 00:00:00.0 | 2568 | COMPLETE | +----------------------------+------------------------------+-------------------------------------+--------------------------------+
故障切换现已完成。现在,您应该通过更新 Hadoop 客户端配置文件,将客户端应用重定向到区域 B 中新的主要 Dataproc 集群。
故障恢复至原始区域
本部分介绍了故障恢复至原始区域(区域 A)的步骤。
在 Cloud Shell 中,从 DPMS 实例中导出元数据:
gcloud metastore services export gcs ${DPMS_PRIMARY_INSTANCE} \ --location=${DPMS_PRIMARY_REGION} \ --destination-folder=gs://${BACKUP_BUCKET}检索最新元数据备份的路径:
IMPORT_DIR=`gcloud storage ls gs://${BACKUP_BUCKET} | sort -k 1 | tail -1` IMPORT_SQL="${IMPORT_DIR}hive.sql" echo ${IMPORT_SQL}将元数据导入原始区域(区域 A)中的备用 DPMS 实例:
gcloud metastore services import gcs ${DPMS_STANDBY_INSTANCE} \ --location=${DPMS_STANDBY_REGION} \ --dump-type=mysql \ --database-dump=${IMPORT_SQL} \ --import-id=import-$(date +"%Y-%m-%d-%H-%M-%S")验证是否已正确导入元数据:
gcloud dataproc jobs submit hive \ --cluster ${HADOOP_STANDBY} \ --region ${DPMS_STANDBY_REGION} \ --execute "select * from completed_orders limit 5;"输出包括以下内容:
+----------------------------+------------------------------+-------------------------------------+--------------------------------+ | completed_orders.order_id | completed_orders.order_date | completed_orders.order_customer_id | completed_orders.order_status | +----------------------------+------------------------------+-------------------------------------+--------------------------------+ | 3 | 2013-07-25 00:00:00.0 | 12111 | COMPLETE | | 5 | 2013-07-25 00:00:00.0 | 11318 | COMPLETE | | 6 | 2013-07-25 00:00:00.0 | 7130 | COMPLETE | | 7 | 2013-07-25 00:00:00.0 | 4530 | COMPLETE | | 15 | 2013-07-25 00:00:00.0 | 2568 | COMPLETE | +----------------------------+------------------------------+-------------------------------------+--------------------------------+
主要 Dataproc Metastore 和备用 Dataproc Metastore 再次交换了角色。
将环境变量更新为这些新角色:
export DPMS_PRIMARY_REGION=us-central1 export DPMS_STANDBY_REGION=us-east1 export DPMS_PRIMARY_INSTANCE=dpms1 export DPMS_STANDBY_INSTANCE=dpms12 export HADOOP_PRIMARY=dataproc-cluster1 export HADOOP_STANDBY=dataproc-cluster2
故障恢复现已完成。现在,您应该通过更新 Hadoop 客户端配置文件,将客户端应用重定向到区域 A 中新的主要 Dataproc 集群。
创建自动元数据备份
本部分简要介绍了两种不同的自动执行元数据备份导出和导入的方法。第一种方法(选项 1:Cloud Run 和 Cloud Scheduler)使用 Cloud Run 和 Cloud Scheduler。第二种方法选项 2:Cloud Composer 使用 Cloud Composer。在这两个示例中,导出作业都通过区域 A 中的主要 DPMS 创建元数据备份。导入作业使用备份填充区域 B 中的备用 DPMS。
如果您已有 Cloud Composer 集群,则应考虑选项 2:Cloud Composer(假设您的集群具有足够的计算容量)。否则,请使用选项 1:Cloud Run 和 Cloud Scheduler。此选项采用随用随付价格模式,比 Cloud Composer 更经济实惠,后者需要使用永久性计算资源。
选项 1:Cloud Run 和 Cloud Scheduler
本部分介绍了如何使用 Cloud Run 和 Cloud Scheduler 自动导出和导入 DPMS 元数据。
Cloud Run 服务
本部分介绍了如何构建两项 Cloud Run 服务来执行元数据导出和导入作业。
在 Cloud Shell 中,启用 Cloud Run、Cloud Scheduler、Cloud Build 和 App Engine API:
gcloud services enable run.googleapis.com cloudscheduler.googleapis.com cloudbuild.googleapis.com appengine.googleapis.com启用 App Engine API,因为 Cloud Scheduler 服务需要 App Engine。
使用提供的 Dockerfile 构建 Docker 映像:
cd metastore-disaster-recovery gcloud builds submit --tag gcr.io/$PROJECT/dpms_dr将容器映像部署到主要区域(区域 A)中的 Cloud Run 服务。此部署负责从主 Metastore 创建元数据备份:
gcloud run deploy dpms-export \ --image gcr.io/${PROJECT}/dpms_dr \ --region ${DPMS_PRIMARY_REGION} \ --platform managed \ --update-env-vars DPMS_STANDBY_REGION=${DPMS_STANDBY_REGION},BACKUP_BUCKET=${BACKUP_BUCKET},DPMS_STANDBY_INSTANCE=${DPMS_STANDBY_INSTANCE},DPMS_PRIMARY_INSTANCE=${DPMS_PRIMARY_INSTANCE},DPMS_PRIMARY_REGION=${DPMS_PRIMARY_REGION} \ --allow-unauthenticated \ --timeout=10m默认情况下,Cloud Run 服务请求会在 5 分钟后超时。为了帮助确保所有请求都有足够的时间来成功完成,上一个代码示例会将超时值延长到至少 10 分钟。
检索 Cloud Run 服务的部署网址:
EXPORT_RUN_URL=$(gcloud run services describe dpms-export --platform managed --region ${DPMS_PRIMARY_REGION} --format ` "value(status.address.url)") echo ${EXPORT_RUN_URL}在备用区域(区域 B)中创建第二个 Cloud Run 服务。此服务负责将元数据备份从
BACKUP_BUCKET导入备用 Metastore:gcloud run deploy dpms-import \ --image gcr.io/${PROJECT}/dpms_dr \ --region ${DPMS_STANDBY_REGION} \ --platform managed \ --update-env-vars DPMS_STANDBY_REGION=${DPMS_STANDBY_REGION},BACKUP_BUCKET=${BACKUP_BUCKET},DPMS_STANDBY_INSTANCE=${DPMS_STANDBY_INSTANCE} \ --allow-unauthenticated \ --timeout=10m检索第二项 Cloud Run 服务的部署网址:
IMPORT_RUN_URL=$(gcloud run services describe dpms-import --platform managed --region ${REGION_B} --format "value(status.address.url)") echo ${IMPORT_RUN_URL}
作业调度
本部分介绍如何使用 Cloud Scheduler 触发这两项 Cloud Run 服务。
在 Cloud Shell 中,创建 App Engine 应用,这是 Cloud Scheduler 所需的应用:
gcloud app create --region=${REGION_A}创建 Cloud Scheduler 作业以安排从主要 Metastore 导出元数据:
gcloud scheduler jobs create http dpms-export \ --schedule "*/15 * * * *" \ --http-method=post \ --uri=${EXPORT_RUN_URL}/export\
Cloud Scheduler 作业每 15 分钟向 Cloud Run 服务发出一次 http 请求。Cloud Run 服务会运行具有导出和导入函数的容器化 Flask 应用。导出函数触发后,它会使用 gcloud metastore services export 命令将元数据导出到 Cloud Storage。
通常,如果您的 Hadoop 作业频繁写入 Hive Metastore,我们建议您经常备份 Metastore。理想的备份计划范围介于每 15 分钟到 60 分钟之间。
触发 Cloud Run 服务的测试运行:
gcloud scheduler jobs run dpms-export验证 Cloud Scheduler 是否已正确触发 DPMS 导出操作:
gcloud metastore operations list --location ${REGION_A}输出类似以下内容:
OPERATION_NAME LOCATION TYPE TARGET DONE CREATE_TIME DURATION ... operation-a520936204508-5v23bx4y23f60-920f0a0f-9c2b56b5 us-central1 update dpms1 True 2021-05-13T20:05:04 2M23S
如果
DONE的值为False,则表示导出仍在进行中。如需确认操作是否已完成,请重新运行gcloud metastore operations list --location ${REGION_A}命令,直到值变为True。如需详细了解
gcloud metastore operations命令,请参阅参考文档。(可选)创建 Cloud Scheduler 作业以安排导入到备用 Metastore:
gcloud scheduler jobs create http dpms-import \ --schedule "*/15 * * * *" \ --http-method=post \ --uri=${IMPORT_RUN_URL}/import
此步骤取决于您的恢复时间目标 (RTO) 要求。
如果您希望使用热备用以最大限度地缩短故障切换时间,则应安排此导入作业。该作业每 15 分钟刷新一次备用 DPMS。
如果冷备用足以满足您的 RTO 需求,则可以跳过此步骤,同时删除备用 DPMS 和 Dataproc 集群以进一步降低总体月度费用。故障切换到备用区域(区域 B)时,请预配备用 DPMS 和 Dataproc 集群,同时运行导入作业。由于备份文件存储在双区域存储桶中,因此即使您的主要区域(区域 A)发生故障,备份文件也可以访问。
处理故障切换
故障切换到区域 B 后,您必须应用以下步骤来保持灾难恢复要求并保护您的基础架构免受区域 B 中可能发生的故障的影响:
- 暂停现有的 Cloud Scheduler 作业。
- 将主实例的 DPMS 区域更新为区域 B (
us-east1)。 - 将备用实例的 DPMS 区域更新为区域 A (
us-central1)。 - 将 DPMS 主实例更新为
dpms2。 - 将 DPMS 备用实例更新为
dpms1。 - 根据更新后的变量重新部署 Cloud Run 服务。
- 创建新的 Cloud Scheduler 作业以指向新的 Cloud Run 服务。
上述列表所需的步骤重复了前面部分的多个步骤,只进行了细微调整(如替换区域名称)。使用“选项 1:Cloud Run 和 Cloud Scheduler”中的信息完成此必需的操作。
选项 2:Cloud Composer
本部分介绍了如何使用 Cloud Composer 在单个 Airflow 有向无环图 (DAG) 中运行导出和导入作业。
在 Cloud Shell 中,启用 Cloud Composer API:
gcloud services enable composer.googleapis.com创建一个 Cloud Composer 环境。
export COMPOSER_ENV=comp-env gcloud beta composer environments create ${COMPOSER_ENV} \ --location ${DPMS_PRIMARY_REGION} \ --image-version composer-1.17.0-preview.1-airflow-2.0.1 \ --python-version 3使用以下环境变量配置 Cloud Composer 环境:
gcloud composer environments update ${COMPOSER_ENV} \ --location ${DPMS_PRIMARY_REGION} \ --update-env-variables=DPMS_PRIMARY_REGION=${DPMS_PRIMARY_REGION},DPMS_STANDBY_REGION=${DPMS_STANDBY_REGION},BACKUP_BUCKET=${BACKUP_BUCKET},DPMS_PRIMARY_INSTANCE=${DPMS_PRIMARY_INSTANCE},DPMS_STANDBY_INSTANCE=${DPMS_STANDBY_INSTANCE}将 DAG 文件上传到 Composer 环境:
gcloud composer environments storage dags import \ --environment ${COMPOSER_ENV} \ --location ${DPMS_PRIMARY_REGION} \ --source dpms_dag.py检索 Airflow 网址:
gcloud composer environments describe ${COMPOSER_ENV} \ --location ${DPMS_PRIMARY_REGION} \ --format "value(config.airflowUri)"在浏览器中,打开通过上一个命令返回的网址。
您应该会看到一个名为
dpms_dag的新 DAG 条目。单次运行中,DAG 会执行导出,然后执行导入。DAG 假定备用 DPMS 始终正常运行。如果您不需要热备用,而只想运行导出任务,则应在代码 (find_backup, wait_for_ready_status, current_ts,dpms_import)) 中注释掉所有与导入相关的任务。点击箭头图标以触发 DAG 执行测试:
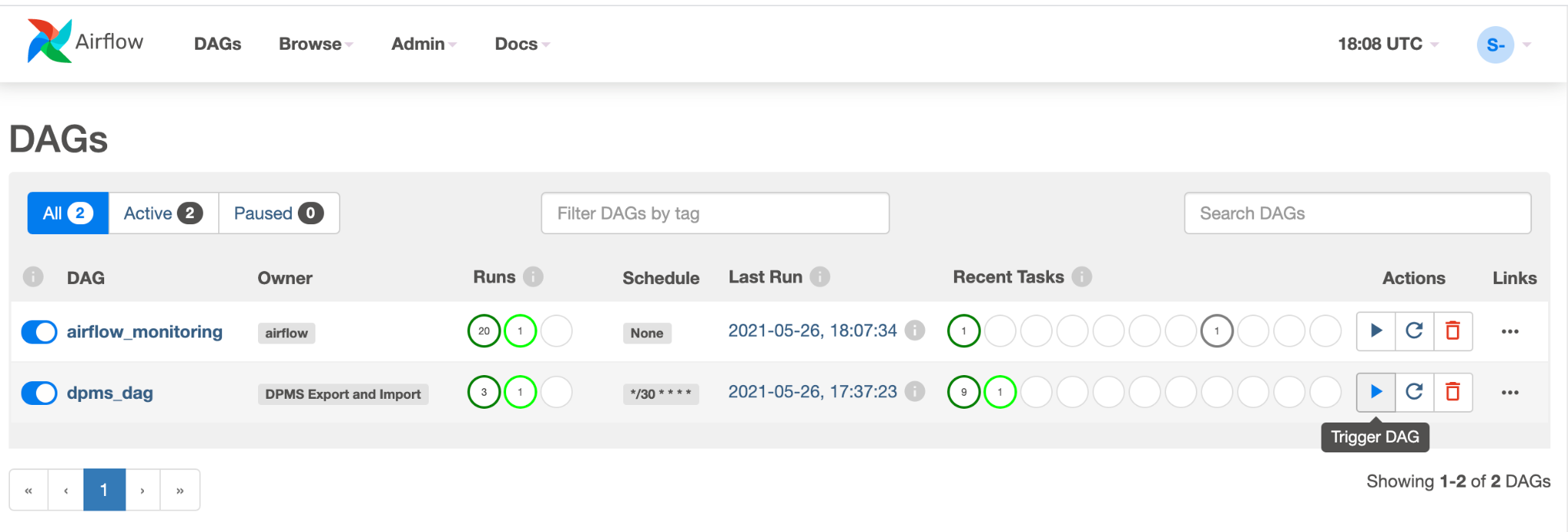
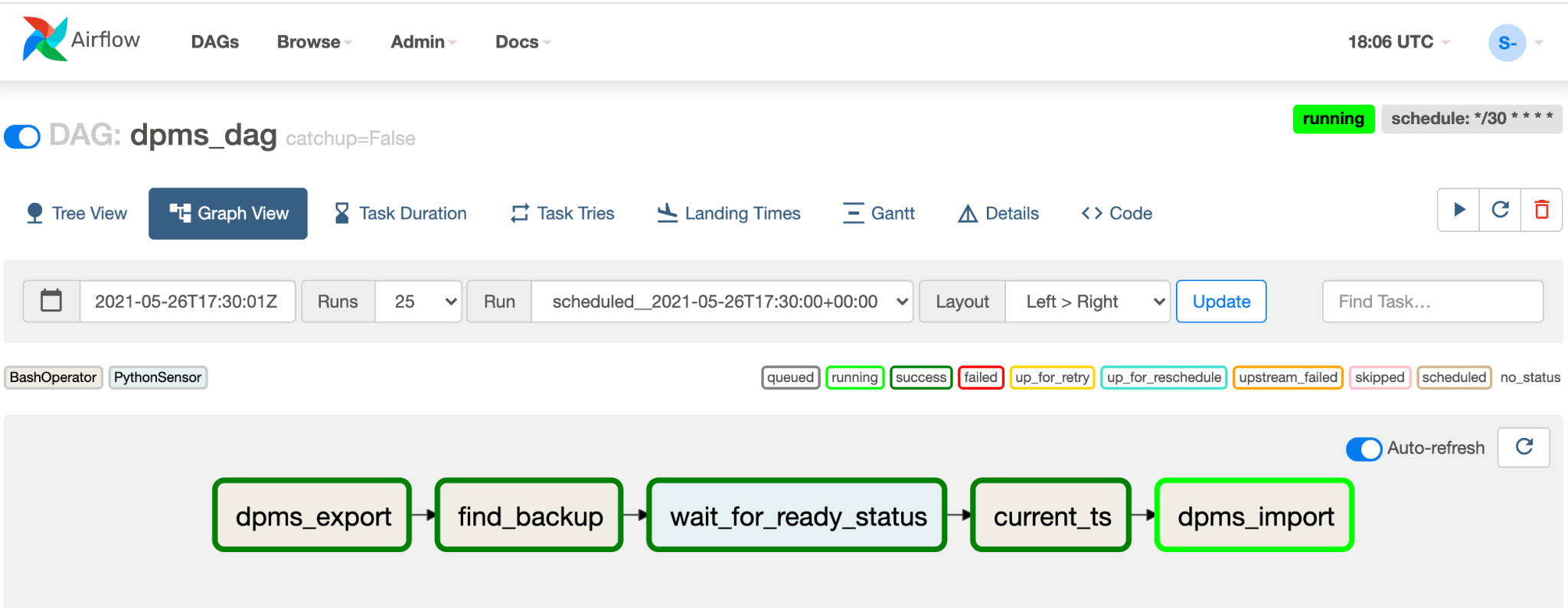
点击正在运行的 DAG 的图表视图,以检查每个任务的状态:
验证 DAG 后,请让 Airflow 定期运行 DAG。时间表设置为以 30 分钟为时间间隔,但您可以通过更改代码中的
schedule_interval参数来进行调整,以满足您的时间要求。
处理故障切换
故障切换到区域 B 后,您必须应用以下步骤来保持灾难恢复要求并保护您的基础架构免受区域 B 中可能发生的故障的影响:
- 将主实例的 DPMS 区域更新为区域 B (
us-east1)。 - 将备用实例的 DPMS 区域更新为区域 A (
us-central1)。 - 将 DPMS 主实例更新为
dpms2。 - 将 DPMS 备用实例更新为
dpms1。 - 在区域 B (
us-east1) 中创建新的 Cloud Composer 环境。 - 使用更新的环境变量配置 Cloud Composer 环境。
- 按上文所述将相同的
dpms_dagAirflow DAG 导入新的 Cloud Composer 环境。
上述列表所需的步骤重复了前面部分的多个步骤,只进行了细微调整(如替换区域名称)。使用“选项 2:Cloud Composer”中的信息完成此所需的操作。
清理
为避免因本教程中使用的资源导致您的 Google Cloud 账号产生费用,请删除包含这些资源的项目,或者保留项目但删除各个资源。
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
后续步骤
- 了解如何监控 Dataproc Metastore 实例
- 了解如何将 Hive Metastore 与 Data Catalog 同步
- 详细了解如何开发 Cloud Run 服务
- 如需查看更多参考架构、图表和最佳实践,请浏览 Cloud 架构中心。