Ce document explique comment mettre à jour un job de streaming en cours. Vous pouvez mettre à jour votre tâche Dataflow existante pour les raisons suivantes :
- Vous souhaitez retoucher ou améliorer le code de votre pipeline.
- Vous voulez corriger des bugs dans le code de votre pipeline.
- Vous souhaitez mettre à jour votre pipeline pour gérer des modifications au niveau du format des données, ou pour tenir compte d'une nouvelle version ou d'autres modifications au niveau de votre source de données.
- Vous souhaitez corriger une faille de sécurité liée à Container-Optimized OS pour l'ensemble des nœuds de calcul Dataflow.
- Vous souhaitez mettre à l'échelle un pipeline Apache Beam en mode de flux continu et lui faire utiliser un nombre différent de nœuds de calcul.
Vous pouvez mettre à jour des jobs de deux manières :
- Mise à jour des jobs en cours de transfert : pour les jobs de traitement par flux qui utilisent Streaming Engine, vous pouvez mettre à jour les options de jobs
min-num-workersetmax-num-workerssans arrêter ou modifier l'ID de job. - Job de remplacement : pour exécuter un code de pipeline mis à jour ou pour mettre à jour les options de job qui ne sont pas compatibles avec les mises à jour de job en cours, lancez un nouveau job qui remplace le job existant. Pour vérifier si un job de remplacement est valide, validez le graphique du job avant de lancer le nouveau job.
Lorsque vous mettez à jour votre tâche, le service Dataflow effectue une vérification de compatibilité entre votre tâche en cours d'exécution et la tâche potentiellement amenée à la remplacer. La vérification de compatibilité garantit que des éléments tels que les informations d'état intermédiaires et les données en mémoire tampon peuvent être transférés de votre tâche précédente vers la tâche de remplacement.
Vous pouvez également utiliser l'infrastructure de journalisation intégrée du SDK Apache Beam pour enregistrer des informations lorsque vous mettez à jour votre job. Pour en savoir plus, consultez la section Utiliser les journaux de pipeline.
Pour identifier les problèmes liés au code du pipeline, utilisez le niveau de journalisation DEBUG.
- Pour obtenir des instructions concernant la mise à jour des jobs de traitement par flux utilisant des modèles classiques, consultez la section Mettre à jour un job par flux à partir d'un modèle personnalisé.
- Pour obtenir des instructions concernant la mise à jour des jobs de traitement par flux utilisant des modèles Flex, suivez les instructions de gcloud CLI présentées sur cette page, ou consultez la section Mettre à jour un job de modèle Flex.
Mise à jour des options de job en cours de transfert
Pour une tâche de streaming qui utilise Streaming Engine, vous pouvez mettre à jour les options de tâche suivantes sans arrêter la tâche ou modifier son ID :
min-num-workers: nombre minimal d'instances Compute Engine.max-num-workers: nombre maximal d'instances Compute Engine.worker-utilization-hint: utilisation du processeur cible, dans la plage [0,1 - 0,9]
Pour les autres mises à jour de job, vous devez remplacer le job actuel par le job mis à jour. Pour en savoir plus, consultez la section Lancer un job de remplacement.
Effectuer une mise à jour en cours
Pour effectuer une mise à jour des options de job en cours, procédez comme suit.
gcloud
Exécutez la commande gcloud dataflow jobs update-options :
gcloud dataflow jobs update-options \ --region=REGION \ --min-num-workers=MINIMUM_WORKERS \ --max-num-workers=MAXIMUM_WORKERS \ --worker-utilization-hint=TARGET_UTILIZATION \ JOB_ID
Remplacez les éléments suivants :
- REGION : ID de la région de la tâche
- MINIMUM_WORKERS : nombre minimal d'instances Compute Engine.
- MAXIMUM_WORKERS : nombre maximal d'instances Compute Engine.
- TARGET_UTILIZATION : valeur comprise dans la plage [0,1 - 0,9].
- JOB_ID : ID de la tâche à mettre à jour.
Vous pouvez également mettre à jour --min-num-workers, --max-num-workers et worker-utilization-hint individuellement.
REST
Utilisez la méthode projects.locations.jobs.update :
PUT https://dataflow.googleapis.com/v1b3/projects/PROJECT_ID/locations/REGION/jobs/JOB_ID?updateMask=MASK { "runtime_updatable_params": { "min_num_workers": MINIMUM_WORKERS, "max_num_workers": MAXIMUM_WORKERS, "worker_utilization_hint": TARGET_UTILIZATION } }
Remplacez les éléments suivants :
- MASK : liste de paramètres à mettre à jour, séparés par une virgule, à partir des éléments suivants :
runtime_updatable_params.max_num_workersruntime_updatable_params.min_num_workersruntime_updatable_params.worker_utilization_hint
- PROJECT_ID : ID de projet Google Cloud du job Dataflow
- REGION : ID de la région de la tâche
- JOB_ID : ID de la tâche à mettre à jour.
- MINIMUM_WORKERS : nombre minimal d'instances Compute Engine.
- MAXIMUM_WORKERS : nombre maximal d'instances Compute Engine.
- TARGET_UTILIZATION : valeur comprise dans la plage [0,1 - 0,9].
Vous pouvez également mettre à jour min_num_workers, max_num_workers et worker_utilization_hint individuellement.
Spécifiez les paramètres à mettre à jour dans le paramètre de requête updateMask et incluez les valeurs mises à jour dans le champ runtimeUpdatableParams du corps de la requête. L'exemple suivant met à jour min_num_workers :
PUT https://dataflow.googleapis.com/v1b3/projects/my_project/locations/us-central1/jobs/job1?updateMask=runtime_updatable_params.min_num_workers { "runtime_updatable_params": { "min_num_workers": 5 } }
Un job doit être en cours d'exécution pour pouvoir recevoir les mises à jour en cours de transfert. Une erreur se produit si le job n'a pas démarré ou est déjà annulé. De même, si vous lancez un job de remplacement, attendez qu'il commence à s'exécuter avant d'envoyer les mises à jour en cours de transfert au nouveau job.
Une fois votre requête de mise à jour envoyée, nous vous recommandons d'attendre sa fin avant d'envoyer une autre mise à jour. Consultez les journaux des jobs pour savoir quand la requête est terminée.
Valider un job de remplacement
Pour vérifier si un job de remplacement est valide, validez son graphique avant de lancer le nouveau job. Dans Dataflow, un graphique de job est une représentation graphique d'un pipeline. En validant le graphique de job, vous réduisez le risque que le pipeline rencontre des erreurs ou des échecs de pipeline après la mise à jour. En outre, vous pouvez valider les mises à jour sans avoir à arrêter le job d'origine, afin que celui-ci ne subisse aucun temps d'arrêt.
Pour valider votre graphique de job, suivez les étapes pour lancer un job de remplacement. Incluez l'option de service Dataflow graph_validate_only dans la commande de mise à jour.
Java
- Transmettez l'option
--update. - Définissez l'option
--jobNamedansPipelineOptionspour qu'elle porte le même nom que le job devant être mis à jour. - Définissez l'option
--regionsur la même région que celle du job que vous souhaitez mettre à jour. - Incluez l'option de service
--dataflowServiceOptions=graph_validate_only. - Si les noms de certaines transformations de votre pipeline ont changé, vous devez fournir un mappage des transformations par le biais de l'option
--transformNameMapping. - Si vous envoyez un job de remplacement qui utilise une version ultérieure du SDK Apache Beam, définissez
--updateCompatibilityVersionsur la version du SDK Apache Beam utilisée dans le job d'origine.
Python
- Transmettez l'option
--update. - Définissez l'option
--job_namedansPipelineOptionspour qu'elle porte le même nom que le job devant être mis à jour. - Définissez l'option
--regionsur la même région que celle du job que vous souhaitez mettre à jour. - Incluez l'option de service
--dataflow_service_options=graph_validate_only. - Si les noms de certaines transformations de votre pipeline ont changé, vous devez fournir un mappage des transformations par le biais de l'option
--transform_name_mapping. - Si vous envoyez un job de remplacement qui utilise une version ultérieure du SDK Apache Beam, définissez
--updateCompatibilityVersionsur la version du SDK Apache Beam utilisée dans le job d'origine.
Go
- Transmettez l'option
--update. - Définissez le champ
--job_namesur le même nom que celui du job à mettre à jour. - Définissez l'option
--regionsur la même région que celle du job que vous souhaitez mettre à jour. - Incluez l'option de service
--dataflow_service_options=graph_validate_only. - Si les noms de certaines transformations de votre pipeline ont changé, vous devez fournir un mappage des transformations par le biais de l'option
--transform_name_mapping.
gcloud
Pour valider le graphique de job d'un job de modèle Flex, exécutez la commande gcloud dataflow flex-template run avec l'option additional-experiments :
- Transmettez l'option
--update. - Définissez le champ JOB_NAME sur le même nom que celui du job à mettre à jour.
- Définissez l'option
--regionsur la même région que celle du job que vous souhaitez mettre à jour. - Incluez l'option
--additional-experiments=graph_validate_only. - Si les noms de certaines transformations de votre pipeline ont changé, vous devez fournir un mappage des transformations par le biais de l'option
--transform-name-mappings.
Exemple :
gcloud dataflow flex-template run JOB_NAME --additional-experiments=graph_validate_only
Remplacez JOB_NAME par le nom du job que vous souhaitez mettre à jour.
REST
Utilisez le champ additionalExperiments dans l'objet FlexTemplateRuntimeEnvironment (modèles Flex) ou RuntimeEnvironment.
{
additionalExperiments : ["graph_validate_only"]
...
}
L'option de service graph_validate_only valide uniquement les mises à jour du pipeline. N'utilisez pas cette option lors de la création ou du lancement de pipelines. Pour mettre à jour votre pipeline, lancez un job de remplacement sans l'option de service graph_validate_only.
Une fois la validation du graphique de job réussie, l'état du job et les journaux du job affichent les états suivants :
- L'état du job est
JOB_STATE_DONE. - Dans la console Google Cloud, l'état du job est
Succeeded. Le message suivant apparaît dans les journaux des jobs :
Workflow job: JOB_ID succeeded validation. Marking graph_validate_only job as Done.
Lorsque la validation du graphique de job échoue, l'état du job et les journaux du job affichent les états suivants :
- L'état du job est
JOB_STATE_FAILED. - Dans la console Google Cloud, l'état du job est
Failed. - Un message décrivant les erreurs d'incompatibilité apparaît dans les journaux des jobs. Le contenu du message dépend de l'erreur.
Lancer un job de remplacement
Vous pouvez remplacer une tâche existante pour les raisons suivantes :
- Pour exécuter le code de pipeline mis à jour.
- Pour mettre à jour des options de tâches non compatibles avec les mises à jour en cours.
Pour vérifier si un job de remplacement est valide, validez le graphique de job avant de lancer le nouveau job.
Lorsque vous lancez votre tâche de remplacement, définissez les options de pipeline suivantes pour exécuter le processus de mise à jour en plus des options habituelles de la tâche :
Java
- Transmettez l'option
--update. - Définissez l'option
--jobNamedansPipelineOptionspour qu'elle porte le même nom que le job devant être mis à jour. - Définissez l'option
--regionsur la même région que celle du job que vous souhaitez mettre à jour. - Si les noms de certaines transformations de votre pipeline ont changé, vous devez fournir un mappage des transformations par le biais de l'option
--transformNameMapping. - Si vous envoyez un job de remplacement qui utilise une version ultérieure du SDK Apache Beam, définissez
--updateCompatibilityVersionsur la version du SDK Apache Beam utilisée dans le job d'origine.
Python
- Transmettez l'option
--update. - Définissez l'option
--job_namedansPipelineOptionspour qu'elle porte le même nom que le job devant être mis à jour. - Définissez l'option
--regionsur la même région que celle du job que vous souhaitez mettre à jour. - Si les noms de certaines transformations de votre pipeline ont changé, vous devez fournir un mappage des transformations par le biais de l'option
--transform_name_mapping. - Si vous envoyez un job de remplacement qui utilise une version ultérieure du SDK Apache Beam, définissez
--updateCompatibilityVersionsur la version du SDK Apache Beam utilisée dans le job d'origine.
Go
- Transmettez l'option
--update. - Définissez le champ
--job_namesur le même nom que celui du job à mettre à jour. - Définissez l'option
--regionsur la même région que celle du job que vous souhaitez mettre à jour. - Si les noms de certaines transformations de votre pipeline ont changé, vous devez fournir un mappage des transformations par le biais de l'option
--transform_name_mapping.
gcloud
Pour mettre à jour un job de modèle Flex à l'aide de gcloud CLI, exécutez la commande gcloud dataflow flex-template run. La mise à jour d'autres tâches à l'aide de la CLI gcloud n'est pas prise en charge.
- Transmettez l'option
--update. - Définissez le champ JOB_NAME sur le même nom que celui du job à mettre à jour.
- Définissez l'option
--regionsur la même région que celle du job que vous souhaitez mettre à jour. - Si les noms de certaines transformations de votre pipeline ont changé, vous devez fournir un mappage des transformations par le biais de l'option
--transform-name-mappings.
REST
Ces instructions montrent comment mettre à jour des jobs sans modèle à l'aide de l'API REST. Pour utiliser l'API REST afin de mettre à jour un job de modèle classique, consultez la section Mettre à jour un job par flux à partir d'un modèle personnalisé. Pour utiliser l'API REST afin de mettre à jour un job de modèle Flex, consultez la section Mettre à jour un job de modèle Flex.
Récupérez la ressource
jobpour le job que vous souhaitez remplacer à l'aide de la méthodeprojects.locations.jobs.get. Incluez le paramètre de requêteviewavec la valeurJOB_VIEW_DESCRIPTION. L'inclusion deJOB_VIEW_DESCRIPTIONlimite la quantité de données dans la réponse afin que votre requête ultérieure ne dépasse pas les limites de taille. Si vous avez besoin d'informations plus détaillées sur le job, utilisez la valeurJOB_VIEW_ALL.GET https://dataflow.googleapis.com/v1b3/projects/PROJECT_ID/locations/REGION/jobs/JOB_ID?view=JOB_VIEW_DESCRIPTIONRemplacez les valeurs suivantes :
- PROJECT_ID : ID de projet Google Cloud du job Dataflow
- REGION : région du job que vous souhaitez mettre à jour
- JOB_ID : Job ID du job que vous souhaitez mettre à jour
Pour mettre à jour le job, utilisez la méthode
projects.locations.jobs.create. Dans le corps de la requête, utilisez la ressourcejobque vous avez récupérée.POST https://dataflow.googleapis.com/v1b3/projects/PROJECT_ID/locations/REGION/jobs { "id": JOB_ID, "replaceJobId": JOB_ID, "name": JOB_NAME, "type": "JOB_TYPE_STREAMING", "transformNameMapping": { string: string, ... }, }Remplacez les éléments suivants :
- JOB_ID : le même Job ID que l'ID du job que vous souhaitez mettre à jour.
- JOB_NAME : le même nom de job que le nom du job que vous souhaitez mettre à jour.
Si les noms de certaines transformations de votre pipeline ont changé, vous devez fournir un mappage des transformations par le biais du champ
transformNameMapping.Facultatif : Pour envoyer votre requête à l'aide de curl (Linux, macOS ou Cloud Shell), enregistrez la requête dans un fichier JSON, puis exécutez la commande suivante :
curl -X POST -d "@FILE_PATH" -H "Content-Type: application/json" -H "Authorization: Bearer $(gcloud auth print-access-token)" https://dataflow.googleapis.com/v1b3/projects/PROJECT_ID/locations/REGION/jobsRemplacez FILE_PATH par le chemin d'accès au fichier JSON contenant le corps de la requête.
Indiquez le nom de votre job de remplacement
Java
Lorsque vous lancez une tâche de remplacement, la valeur que vous transmettez pour l'option --jobName doit correspondre exactement au nom de la tâche que vous souhaitez remplacer.
Python
Lorsque vous lancez une tâche de remplacement, la valeur que vous transmettez pour l'option --job_name doit correspondre exactement au nom de la tâche que vous souhaitez remplacer.
Go
Lorsque vous lancez une tâche de remplacement, la valeur que vous transmettez pour l'option --job_name doit correspondre exactement au nom de la tâche que vous souhaitez remplacer.
gcloud
Lorsque vous lancez un job de remplacement, l'élément JOB_NAME doit correspondre exactement au nom du job que vous souhaitez remplacer.
REST
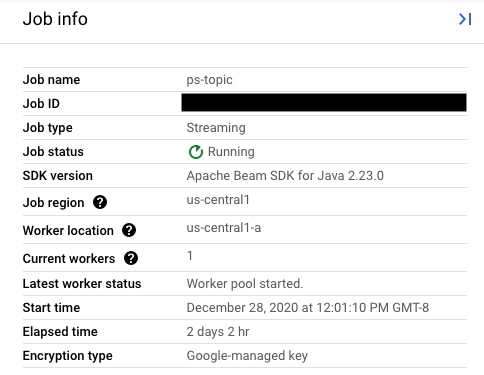
Définissez la valeur du champ replaceJobId sur le même Job ID que le job à mettre à jour. Pour trouver la valeur du nom de job correcte, sélectionnez votre job précédent dans l'interface de surveillance de Dataflow.
Ensuite, dans le panneau latéral Job info (Informations sur le job), recherchez le champ Job ID.
Pour trouver la valeur du nom de job correcte, sélectionnez votre job précédent dans l'interface de surveillance de Dataflow. Ensuite, dans le panneau latéral Job info (Informations sur le job), recherchez le champ Job name (Nom du job) :
Vous pouvez également vérifier la liste des jobs existants à l'aide de l'interface de ligne de commande de Dataflow.
Saisissez la commande gcloud dataflow jobs list dans votre fenêtre d'interface système ou de terminal pour obtenir la liste des tâches Dataflow de votre projet Google Cloud. Ensuite, recherchez le champ NAME de la tâche que vous souhaitez remplacer :
JOB_ID NAME TYPE CREATION_TIME STATE REGION 2020-12-28_12_01_09-yourdataflowjobid ps-topic Streaming 2020-12-28 20:01:10 Running us-central1
Créer un mappage de transformation
Si votre pipeline de remplacement a modifié le nom de certaines transformations par rapport aux noms figurant dans le pipeline précédent, le service Dataflow nécessite un mappage des transformations. Le mappage des transformations crée une correspondance entre les noms des transformations dans le code de votre pipeline précédent et les noms figurant dans le code de votre pipeline de remplacement.
Java
Transmettez le mappage à l'aide de l'option de ligne de commande --transformNameMapping, en utilisant le format général suivant :
--transformNameMapping= .
{"oldTransform1":"newTransform1","oldTransform2":"newTransform2",...}
Dans l'option --transformNameMapping, vous devez uniquement fournir les entrées de mappage pour les noms de transformations qui ont changé entre votre pipeline précédent et votre pipeline de remplacement.
Lorsque vous exécutez la commande avec --transformNameMapping, votre shell peut nécessiter d'échapper les guillemets. Par exemple, en Bash :
--transformNameMapping='{"oldTransform1":"newTransform1",...}'
Python
Transmettez le mappage à l'aide de l'option de ligne de commande --transform_name_mapping, en utilisant le format général suivant :
--transform_name_mapping= .
{"oldTransform1":"newTransform1","oldTransform2":"newTransform2",...}
Dans l'option --transform_name_mapping, vous devez uniquement fournir les entrées de mappage pour les noms de transformations qui ont changé entre votre pipeline précédent et votre pipeline de remplacement.
Lorsque vous exécutez la commande avec --transform_name_mapping, votre shell peut nécessiter d'échapper les guillemets. Par exemple, en Bash :
--transform_name_mapping='{"oldTransform1":"newTransform1",...}'
Go
Transmettez le mappage à l'aide de l'option de ligne de commande --transform_name_mapping, en utilisant le format général suivant :
--transform_name_mapping= .
{"oldTransform1":"newTransform1","oldTransform2":"newTransform2",...}
Dans l'option --transform_name_mapping, vous devez uniquement fournir les entrées de mappage pour les noms de transformations qui ont changé entre votre pipeline précédent et votre pipeline de remplacement.
Lorsque vous exécutez la commande avec --transform_name_mapping, votre shell peut nécessiter d'échapper les guillemets. Par exemple, en Bash :
--transform_name_mapping='{"oldTransform1":"newTransform1",...}'
gcloud
Transmettez le mappage à l'aide de l'option --transform-name-mappings, en utilisant le format général suivant :
--transform-name-mappings= .
{"oldTransform1":"newTransform1","oldTransform2":"newTransform2",...}
Dans l'option --transform-name-mappings, vous devez uniquement fournir les entrées de mappage pour les noms de transformations qui ont changé entre votre pipeline précédent et votre pipeline de remplacement.
Lorsque vous exécutez la commande avec --transform-name-mappings, votre shell peut nécessiter d'échapper les guillemets. Par exemple, en Bash :
--transform-name-mappings='{"oldTransform1":"newTransform1",...}'
REST
Transmettez le mappage à l'aide du champ transformNameMapping, en utilisant le format général suivant :
"transformNameMapping": {
oldTransform1: newTransform1,
oldTransform2: newTransform2,
...
}
Dans l'option transformNameMapping, vous devez uniquement fournir les entrées de mappage pour les noms de transformations qui ont changé entre votre pipeline précédent et votre pipeline de remplacement.
Déterminer les noms de transformation
Le nom de la transformation dans chaque instance du mappage est le nom que vous avez fourni lorsque vous avez appliqué la transformation dans votre pipeline. Exemple :
Java
.apply("FormatResults", ParDo
.of(new DoFn<KV<String, Long>>, String>() {
...
}
}))
Python
| 'FormatResults' >> beam.ParDo(MyDoFn())
Go
// In Go, this is always the package-qualified name of the DoFn itself.
// For example, if the FormatResults DoFn is in the main package, its name
// is "main.FormatResults".
beam.ParDo(s, FormatResults, results)
Vous pouvez également obtenir les noms de transformations de votre tâche précédente en examinant le graphique d'exécution de la tâche dans l'interface de surveillance de Dataflow :
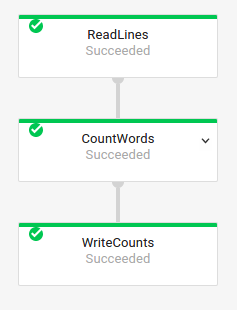
Nommer les transformations composites
Les noms des transformations sont hiérarchiques et basés sur la hiérarchie des transformations de votre pipeline. Si votre pipeline comporte une transformation composite, les transformations imbriquées sont nommées en fonction de la transformation qui les contient. Par exemple, supposons que votre pipeline contient une transformation composite nommée CountWidgets, qui contient elle-même une transformation nommée Parse. Le nom complet de votre transformation est CountWidgets/Parse. Vous devez spécifier ce nom complet dans votre mappage de transformations.
Si votre nouveau pipeline mappe une transformation composite vers un nom différent, toutes les transformations imbriquées sont automatiquement renommées. Vous devez spécifier les noms modifiés pour les transformations internes dans votre mappage des transformations.
Refactoriser la hiérarchie des transformations
Si votre pipeline de remplacement utilise une hiérarchie de transformations différente de celle de votre pipeline précédent, vous devez déclarer explicitement le mappage. Vous pouvez disposer d'une hiérarchie de transformations différente, car vous avez refactorisé vos transformations composites ou car votre pipeline dépend d'une transformation composite provenant d'une bibliothèque qui a été modifiée.
Par exemple, votre pipeline précédent a appliqué une transformation composite, CountWidgets, qui contenait une transformation interne nommée Parse. Le pipeline de remplacement refactorise CountWidgets et imbrique Parse dans une autre transformation appelée Scan. Pour que votre mise à jour réussisse, vous devez mapper explicitement le nom complet de la transformation dans le pipeline précédent (CountWidgets/Parse) sur le nom de la transformation dans le nouveau pipeline (CountWidgets/Scan/Parse) :
Java
--transformNameMapping={"CountWidgets/Parse":"CountWidgets/Scan/Parse"}
Si vous supprimez entièrement une transformation dans votre pipeline de remplacement, vous devez fournir un mappage null. Supposons que notre pipeline de remplacement supprime entièrement la transformation CountWidgets/Parse :
--transformNameMapping={"CountWidgets/Parse":""}
Python
--transform_name_mapping={"CountWidgets/Parse":"CountWidgets/Scan/Parse"}
Si vous supprimez entièrement une transformation dans votre pipeline de remplacement, vous devez fournir un mappage null. Supposons que notre pipeline de remplacement supprime entièrement la transformation CountWidgets/Parse :
--transform_name_mapping={"CountWidgets/Parse":""}
Go
--transform_name_mapping={"CountWidgets/main.Parse":"CountWidgets/Scan/main.Parse"}
Si vous supprimez entièrement une transformation dans votre pipeline de remplacement, vous devez fournir un mappage null. Supposons que notre pipeline de remplacement supprime entièrement la transformation CountWidgets/Parse :
--transform_name_mapping={"CountWidgets/main.Parse":""}
gcloud
--transform-name-mappings={"CountWidgets/Parse":"CountWidgets/Scan/Parse"}
Si vous supprimez entièrement une transformation dans votre pipeline de remplacement, vous devez fournir un mappage null. Supposons que notre pipeline de remplacement supprime entièrement la transformation CountWidgets/Parse :
--transform-name-mappings={"CountWidgets/main.Parse":""}
REST
"transformNameMapping": {
CountWidgets/Parse: CountWidgets/Scan/Parse
}
Si vous supprimez entièrement une transformation dans votre pipeline de remplacement, vous devez fournir un mappage null. Supposons que notre pipeline de remplacement supprime entièrement la transformation CountWidgets/Parse :
"transformNameMapping": {
CountWidgets/main.Parse: null
}
Effets du remplacement d'un job
Lorsque vous remplacez un job existant, un nouveau job exécute le code de votre pipeline mis à jour. Le service Dataflow conserve le nom du job, mais exécute le job de remplacement avec un ID de job mis à jour. Ce processus peut entraîner des temps d'arrêt pendant l'arrêt de la tâche existante, l'exécution de la vérification de compatibilité et le démarrage de la nouvelle tâche.
La tâche de remplacement conserve les éléments suivants :
- Données d'état intermédiaires du job précédent. Les caches en mémoire ne sont pas enregistrés.
- Enregistrements de données en mémoire tampon ou métadonnées actuellement en cours de transfert depuis le job précédent. Par exemple, certains enregistrements de votre pipeline peuvent être mis en mémoire tampon en attendant la résolution d'une fenêtre.
- Les mises à jour des options de job en cours que vous avez appliquées au job précédent.
Données d'état intermédiaires
Les données d'état intermédiaires du job précédent sont conservées. Les données d'état n'incluent pas les caches en mémoire. Si vous souhaitez conserver les données du cache en mémoire lors de la mise à jour de votre pipeline, pour contourner ce problème, refactorisez votre pipeline pour convertir les caches en données d'état ou en entrées secondaires. Pour en savoir plus sur l'utilisation des entrées secondaires, consultez la section Modèles d'entrées secondaires dans la documentation Apache Beam.
Les pipelines de traitement par flux comportent des limites de taille pour ValueState et pour les entrées secondaires.
Par conséquent, si vous souhaitez conserver de grands volumes de caches, vous devrez peut-être utiliser un stockage externe, tel que Memorystore ou Bigtable.
Données en cours de transfert
Les données en cours de transfert sont toujours traitées par les transformations dans votre nouveau pipeline. Toutefois, les transformations supplémentaires que vous intégrez au code de votre pipeline de remplacement peuvent être appliquées ou non, suivant l'endroit où les enregistrements sont mis en mémoire tampon. Dans cet exemple, votre pipeline existant comporte les transformations suivantes :
Java
p.apply("Read", ReadStrings())
.apply("Format", FormatStrings());
Python
p | 'Read' >> beam.io.ReadFromPubSub(subscription=known_args.input_subscription)
| 'Format' >> FormatStrings()
Go
beam.ParDo(s, ReadStrings) beam.ParDo(s, FormatStrings)
Vous pouvez remplacer votre tâche par un code de pipeline mis à jour, comme ci-dessous :
Java
p.apply("Read", ReadStrings())
.apply("Remove", RemoveStringsStartingWithA())
.apply("Format", FormatStrings());
Python
p | 'Read' >> beam.io.ReadFromPubSub(subscription=known_args.input_subscription)
| 'Remove' >> RemoveStringsStartingWithA()
| 'Format' >> FormatStrings()
Go
beam.ParDo(s, ReadStrings) beam.ParDo(s, RemoveStringsStartingWithA) beam.ParDo(s, FormatStrings)
Même si vous avez ajouté une transformation pour filtrer les chaînes commençant par la lettre "A", la transformation suivante (FormatStrings) peut toujours voir des chaînes en mémoire tampon ou en cours de transfert qui commencent par la lettre "A" et qui proviennent de la tâche précédente.
Modifier le fenêtrage
Vous pouvez modifier les stratégies de fenêtrage et de déclenchement des éléments PCollection dans votre pipeline de remplacement, mais restez prudent.
La modification des stratégies de fenêtrage ou de déclenchement n'affecte pas les données déjà mises en mémoire tampon ou en cours de transfert.
Nous vous recommandons de ne tenter que des modifications mineures sur le fenêtrage de votre pipeline, par exemple changer la durée des fenêtres à durée fixe ou flexible. Des changements majeurs sur le fenêtrage ou les déclencheurs (par exemple des modifications de l'algorithme de fenêtrage) peuvent avoir des résultats imprévisibles sur la sortie de votre pipeline.
Vérifier la compatibilité des tâches
Lorsque vous lancez votre tâche de remplacement, le service Dataflow effectue une vérification de compatibilité entre votre tâche de remplacement et la tâche précédente. Si la vérification de compatibilité réussit, la tâche précédente est arrêtée. Votre tâche de remplacement est alors lancée sur le service Dataflow avec le même nom de tâche. Si la vérification de compatibilité échoue, l'exécution de la tâche précédente continue sur le service Dataflow, et la tâche de remplacement renvoie une erreur.
Java
En raison d'une limitation, vous devez utiliser l'exécution bloquante pour voir les erreurs de tentative de mise à jour ayant échoué dans votre console ou terminal. La solution de contournement actuelle est constituée des étapes suivantes :
- Utilisez pipeline.run().waitUntilFinish() dans le code de votre pipeline.
- Exécutez le code de votre pipeline de remplacement avec l'option
--update. - Attendez que la tâche de remplacement réussisse la vérification de compatibilité.
- Quittez le processus du gestionnaire d'exécution en mode blocage en tapant
Ctrl+C.
Vous pouvez également surveiller l'état du job de remplacement dans l'interface de surveillance de Dataflow. Si la tâche a démarré, elle a réussi la vérification de compatibilité.
Python
En raison d'une limitation, vous devez utiliser l'exécution bloquante pour voir les erreurs de tentative de mise à jour ayant échoué dans votre console ou terminal. La solution de contournement actuelle est constituée des étapes suivantes :
- Utilisez pipeline.run().wait_until_finish() dans le code de votre pipeline.
- Exécutez le code de votre pipeline de remplacement avec l'option
--update. - Attendez que la tâche de remplacement réussisse la vérification de compatibilité.
- Quittez le processus du gestionnaire d'exécution en mode blocage en tapant
Ctrl+C.
Vous pouvez également surveiller l'état du job de remplacement dans l'interface de surveillance de Dataflow. Si la tâche a démarré, elle a réussi la vérification de compatibilité.
Go
En raison d'une limitation, vous devez utiliser l'exécution bloquante pour voir les erreurs de tentative de mise à jour ayant échoué dans votre console ou terminal.
Plus précisément, vous devez spécifier une exécution non bloquante à l'aide des options --execute_async ou --async. La solution de contournement actuelle est constituée des étapes suivantes :
- Exécutez le code de votre pipeline de remplacement avec l'option
--updateet sans les options--execute_asyncou--async. - Attendez que la tâche de remplacement réussisse la vérification de compatibilité.
- Quittez le processus du gestionnaire d'exécution en mode blocage en tapant
Ctrl+C.
gcloud
En raison d'une limitation, vous devez utiliser l'exécution bloquante pour voir les erreurs de tentative de mise à jour ayant échoué dans votre console ou terminal. La solution de contournement actuelle est constituée des étapes suivantes :
- Pour les pipelines Java, utilisez pipeline.run().waitUntilFinish() dans le code de votre pipeline. Pour les pipelines Python, utilisez pipeline.run().wait_until_finish() dans le code de votre pipeline. Pour les pipelines Go, suivez les étapes décrites dans l'onglet Go.
- Exécutez le code de votre pipeline de remplacement avec l'option
--update. - Attendez que la tâche de remplacement réussisse la vérification de compatibilité.
- Quittez le processus du gestionnaire d'exécution en mode blocage en tapant
Ctrl+C.
REST
En raison d'une limitation, vous devez utiliser l'exécution bloquante pour voir les erreurs de tentative de mise à jour ayant échoué dans votre console ou terminal. La solution de contournement actuelle est constituée des étapes suivantes :
- Pour les pipelines Java, utilisez pipeline.run().waitUntilFinish() dans le code de votre pipeline. Pour les pipelines Python, utilisez pipeline.run().wait_until_finish() dans le code de votre pipeline. Pour les pipelines Go, suivez les étapes décrites dans l'onglet Go.
- Exécutez le programme de votre pipeline de remplacement avec le champ
replaceJobId. - Attendez que la tâche de remplacement réussisse la vérification de compatibilité.
- Quittez le processus du gestionnaire d'exécution en mode blocage en tapant
Ctrl+C.
La vérification de compatibilité utilise le mappage de transformation fourni pour s'assurer que Dataflow peut transférer des données d'état intermédiaires depuis les étapes de votre job précédent vers votre job de remplacement. La vérification de compatibilité garantit également que les collections PCollection de votre pipeline utilisent les mêmes codeurs.
Changer un Coder peut entraîner l'échec de la vérification de compatibilité, car les données en cours de transfert ou les enregistrements en mémoire tampon risquent de ne pas être sérialisés correctement dans le pipeline de remplacement.
Prévenir les ruptures de compatibilité
Certaines différences entre votre pipeline précédent et votre pipeline de remplacement peuvent entraîner l'échec de la vérification de compatibilité. Ces différences incluent les suivantes :
- Changer le graphique du pipeline sans fournir de mappage. Lorsque vous mettez à jour un job, Dataflow tente de mettre en correspondance les transformations de votre job précédent avec celles du job de remplacement. Ce processus de mise en correspondance permet à Dataflow de transférer des données d'état intermédiaires pour chaque étape. Si vous renommez ou supprimez des étapes, vous devez fournir un mappage des transformations pour que Dataflow puisse établir la correspondance avec les données d'état.
- Changer les entrées secondaires d'une étape. L'ajout ou la suppression d'entrées secondaires pour une transformation dans votre pipeline de remplacement entraîne l'échec de la vérification de compatibilité.
- Changer le codeur pour une étape. Lorsque vous mettez à jour un job, Dataflow conserve tous les enregistrements de données actuellement en mémoire tampon et les gère dans le job de remplacement. Par exemple, des données mises en mémoire tampon peuvent se produire pendant la résolution du fenêtrage. Si la tâche de remplacement utilise un encodage de données différent ou incompatible, le service Dataflow ne peut pas sérialiser ou désérialiser ces enregistrements.
Supprimer une opération "avec état" de votre pipeline. Si vous supprimez les opérations avec état de votre pipeline, la vérification de compatibilité de votre job de remplacement peut échouer. Dataflow peut fusionner plusieurs étapes pour plus d'efficacité. Si vous supprimez une opération dépendante de l'état au sein d'une étape fusionnée, la vérification échoue. Les opérations avec état comprennent :
- les transformations qui produisent ou consomment des entrées secondaires ;
- les lectures d'E/S ;
- les transformations utilisant des états à clés ;
- les transformations avec fusion de fenêtres.
Modifier des variables
DoFnavec état. Pour les tâches de traitement par flux en cours, si votre pipeline inclut des variablesDoFnavec état, la modification de ces variablesDoFnavec état peut entraîner l'échec du pipeline.Essayer d'exécuter votre tâche de remplacement dans une zone géographique différente. Exécutez votre job de remplacement dans la même zone que votre job précédent.
Mettre à jour des schémas
Apache Beam permet aux éléments PCollection d'avoir des schémas comportant des champs nommés, auquel cas les codeurs explicites ne sont pas nécessaires. Si les noms et types des champs d'un schéma donné ne sont pas modifiés (y compris les champs imbriqués), ce schéma n'entraîne pas l'échec de la vérification d'une mise à jour. Il est cependant possible que la mise à jour soit bloquée si d'autres segments du nouveau pipeline sont incompatibles.
Faire évoluer des schémas
Il est souvent nécessaire de faire évoluer le schéma d'un élément PCollection en raison de l'évolution des exigences métier. Le service Dataflow permet d'apporter les modifications suivantes à un schéma lors de la mise à jour du pipeline :
- Ajouter un ou plusieurs nouveaux champs à un schéma, y compris des champs imbriqués.
- Passer un type de champ d'obligatoire (ne pouvant être nul) à facultatif (pouvant être nul).
La suppression de champs ou la modification de noms ou de types de champs ne sont pas autorisées lors d'une mise à jour.
Transmettre des données supplémentaires à une opération ParDo existante
Vous pouvez transmettre des données supplémentaires (hors bande) à une opération ParDo existante en utilisant l'une des méthodes suivantes, en fonction de votre cas d'utilisation :
- Sérialisez les informations sous forme de champs dans votre sous-classe
DoFn. - Toutes les variables référencées par les méthodes dans une fonction
DoFnanonyme sont automatiquement sérialisées. - Calculez les données dans
DoFn.startBundle(). - Transmettez des données à l'aide de
ParDo.withSideInputs.
Pour en savoir plus, consultez les pages suivantes :
- Guide de programmation d'Apache Beam : ParDo, en particulier les sections sur la création d'un objet DoFn et d'entrées secondaires.
- SDK Apache Beam pour Java : ParDo