Neste documento, descrevemos como atualizar um job de streaming em andamento. É possível atualizar o job atual do Dataflow pelos seguintes motivos:
- Ajustar ou melhorar o código do pipeline
- corrigir bugs no código do pipeline;
- Atualizar o canal para lidar com alterações no formato de dados, bem como para considerar outras mudanças na fonte de dados ou na versão
- Você quer corrigir uma vulnerabilidade de segurança relacionada ao SO otimizado para contêineres para todos os workers do Dataflow.
- Você quer escalonar um pipeline de streaming do Apache Beam para usar um número diferente de workers.
É possível atualizar jobs de duas maneiras:
- Atualização de jobs em andamento: para jobs de streaming que usam o
Streaming Engine, é possível atualizar as opções de job
min-num-workersemax-num-workerssem interromper o job ou alterar o ID dele. - Job de substituição: para executar o código do pipeline atualizado ou atualizar as opções de job sem suporte em atualizações de jobs em andamento, inicie um novo job que substitua o atual. Para verificar se um job de substituição é válido, antes de iniciá-lo, valide o gráfico de jobs dele.
Quando você atualiza o job, o serviço do Dataflow realiza uma verificação de compatibilidade entre o job em execução e o possível substituto. A verificação de compatibilidade garante que as informações do estado intermediário e os dados armazenados em buffer possam ser transferidos do job anterior para o job de substituição.
Você também pode usar a infraestrutura de geração de registros integrada do SDK do Apache Beam para registrar informações ao atualizar o job. Para mais informações, consulte Trabalhar com registros de canal.
Para identificar problemas com o código do pipeline, use o nível de geração de registros DEBUG.
- Para instruções sobre como atualizar jobs de streaming que usam modelos clássicos, consulte Atualizar um job de streaming de modelo personalizado.
- Para instruções sobre como atualizar jobs de streaming que usam modelos Flex, siga as instruções da gcloud CLI nesta página ou consulte Atualizar um job de modelo Flex.
Atualização da opção de job em trânsito
Para um job de streaming que usa o Streaming Engine, atualize as seguintes opções sem interromper o job ou alterar o código dele:
min-num-workers: o número mínimo de instâncias do Compute Engine.max-num-workers: o número máximo de instâncias do Compute Engine.worker-utilization-hint: a meta de uso da CPU, no intervalo [0,1, 0,9]
Para outras atualizações de jobs, é necessário substituir o job atual pelo atualizado. Para mais informações, consulte Iniciar um job de substituição.
Executar uma atualização em trânsito
Para atualizar uma opção de job em trânsito, siga as etapas abaixo.
gcloud
Use o comando gcloud dataflow jobs update-options:
gcloud dataflow jobs update-options \ --region=REGION \ --min-num-workers=MINIMUM_WORKERS \ --max-num-workers=MAXIMUM_WORKERS \ --worker-utilization-hint=TARGET_UTILIZATION \ JOB_ID
Substitua:
- REGION: o ID da região do job.
- MINIMUM_WORKERS: o número mínimo de instâncias do Compute Engine
- MAXIMUM_WORKERS: o número máximo de instâncias do Compute Engine
- TARGET_UTILIZATION: um valor no intervalo [0,1, 0,9].
- JOB_ID: o ID do job a ser atualizado
Também é possível atualizar --min-num-workers, --max-num-workers e worker-utilization-hint
individualmente.
REST
Use o
método
projects.locations.jobs.update:
PUT https://dataflow.googleapis.com/v1b3/projects/PROJECT_ID/locations/REGION/jobs/JOB_ID?updateMask=MASK { "runtime_updatable_params": { "min_num_workers": MINIMUM_WORKERS, "max_num_workers": MAXIMUM_WORKERS, "worker_utilization_hint": TARGET_UTILIZATION } }
Substitua:
- MASK: uma lista separada por vírgulas de parâmetros a serem atualizados dos
seguintes:
runtime_updatable_params.max_num_workersruntime_updatable_params.min_num_workersruntime_updatable_params.worker_utilization_hint
- PROJECT_ID: o ID do projeto do Google Cloud do job do Dataflow
- REGION: o ID da região do job.
- JOB_ID: o ID do job a ser atualizado
- MINIMUM_WORKERS: o número mínimo de instâncias do Compute Engine
- MAXIMUM_WORKERS: o número máximo de instâncias do Compute Engine
- TARGET_UTILIZATION: um valor no intervalo [0,1, 0,9].
Também é possível atualizar min_num_workers, max_num_workers e worker_utilization_hint
individualmente.
Especifique quais parâmetros atualizar no parâmetro de consulta updateMask e
inclua os valores atualizados no campo runtimeUpdatableParams do
corpo da solicitação. O exemplo a seguir atualiza min_num_workers:
PUT https://dataflow.googleapis.com/v1b3/projects/my_project/locations/us-central1/jobs/job1?updateMask=runtime_updatable_params.min_num_workers { "runtime_updatable_params": { "min_num_workers": 5 } }
Um job precisa estar em estado de execução para se qualificar para atualizações em trânsito. Ocorre um erro se o job não foi iniciado ou já está cancelado. Da mesma forma, se você iniciar um job de substituição, aguarde até que ele comece a ser executado antes de enviar atualizações em trânsito para o novo job.
Depois de enviar uma solicitação de atualização, recomendamos aguardar a conclusão da solicitação antes de enviar outra. Confira os registros do job para saber quando a solicitação é concluída.
Validar um job de substituição
Para verificar se um job de substituição é válido, antes de iniciá-lo, valide o gráfico de jobs dele. No Dataflow, um gráfico de jobs é uma representação gráfica de um pipeline. Ao validar o gráfico de jobs, você reduz o risco de o pipeline encontrar erros ou falhas após a atualização. Além disso, é possível validar as atualizações sem precisar interromper o job original, para que ele não fique inativo.
Para validar o gráfico de jobs, siga as etapas para
iniciar um job de substituição. Inclua a
opção de serviço do Dataflow graph_validate_only no comando de atualização.
Java
- Transmita a opção
--update. - Defina a opção
--jobNameemPipelineOptionscom o mesmo nome que o job a ser atualizado. - Defina a opção
--regionpara a mesma região do job que você quer atualizar. - Inclua a opção de serviço
--dataflowServiceOptions=graph_validate_only. - Em caso de alteração de qualquer nome de transformação do pipeline, será preciso fornecer um
mapeamento de transformação e transmiti-lo usando a
opção
--transformNameMapping. - Se você estiver enviando um job de substituição que usa uma versão mais recente do SDK do Apache Beam, defina
--updateCompatibilityVersioncomo a versão dele usada no job original.
Python
- Transmita a opção
--update. - Defina a opção
--job_nameemPipelineOptionscom o mesmo nome que o job a ser atualizado. - Defina a opção
--regionpara a mesma região do job que você quer atualizar. - Inclua a opção de serviço
--dataflow_service_options=graph_validate_only. - Em caso de alteração de qualquer nome de transformação do pipeline, será preciso fornecer um
mapeamento de transformação e transmiti-lo usando a
opção
--transform_name_mapping. - Se você estiver enviando um job de substituição que usa uma versão mais recente do SDK do Apache Beam, defina
--updateCompatibilityVersioncomo a versão dele usada no job original.
Go
- Transmita a opção
--update. - Defina a opção
--job_namecom o mesmo nome do job que você quer atualizar. - Defina a opção
--regionpara a mesma região do job que você quer atualizar. - Inclua a opção de serviço
--dataflow_service_options=graph_validate_only. - Em caso de alteração de qualquer nome de transformação do pipeline, será preciso fornecer um
mapeamento de transformação e transmiti-lo usando a
opção
--transform_name_mapping.
gcloud
Para validar o gráfico de jobs no caso de um job de modelo Flex, use o comando gcloud dataflow flex-template run com a opção additional-experiments:
- Transmita a opção
--update. - Defina JOB_NAME com o mesmo nome do job que você quer atualizar.
- Defina a opção
--regionpara a mesma região do job que você quer atualizar. - Inclua a opção
--additional-experiments=graph_validate_only. - Em caso de alteração de qualquer nome de transformação do pipeline, será preciso fornecer um
mapeamento de transformação e transmiti-lo usando a
opção
--transform-name-mappings.
Por exemplo:
gcloud dataflow flex-template run JOB_NAME --additional-experiments=graph_validate_only
Substitua JOB_NAME pelo nome do job que você quer atualizar.
REST
Use o campo additionalExperiments no objeto FlexTemplateRuntimeEnvironment (modelos Flex) ou RuntimeEnvironment.
{
additionalExperiments : ["graph_validate_only"]
...
}
A opção de serviço graph_validate_only
valida apenas as atualizações do pipeline. Não use essa opção ao criar ou
iniciar pipelines. Para atualizar o pipeline,
inicie um job de substituição sem a
opção de serviço graph_validate_only.
Quando a validação do gráfico de jobs é bem-sucedida, o estado e os registros do job mostram os seguintes status:
- O estado do job é
JOB_STATE_DONE. - No console do Google Cloud, o Status do job
é
Succeeded. A seguinte mensagem aparece nos registros do job:
Workflow job: JOB_ID succeeded validation. Marking graph_validate_only job as Done.
Quando há falha na validação do gráfico de jobs, o estado e os registros do job mostram os seguintes status:
- O estado do job é
JOB_STATE_FAILED. - No console do Google Cloud, o Status do job
é
Failed. - Uma mensagem é exibida nos registros do job descrevendo o erro de incompatibilidade. O conteúdo da mensagem depende do erro.
Iniciar um job de substituição
É possível substituir um job atual pelos seguintes motivos:
- Para executar o código atualizado do pipeline.
- Para atualizar opções de job que não têm suporte em atualizações em andamento.
Para verificar se um job de substituição é válido, antes de iniciá-lo, valide o gráfico de jobs dele.
Ao iniciar o job de substituição, defina as seguintes opções de pipeline para realizar o processo de atualização, além das opções regulares do job:
Java
- Transmita a opção
--update. - Defina a opção
--jobNameemPipelineOptionscom o mesmo nome que o job a ser atualizado. - Defina a opção
--regionpara a mesma região do job que você quer atualizar. - Em caso de alteração de qualquer nome de transformação do pipeline, será preciso fornecer um
mapeamento de transformação e transmiti-lo usando a
opção
--transformNameMapping. - Se você estiver enviando um job de substituição que usa uma versão mais recente do SDK do Apache Beam, defina
--updateCompatibilityVersioncomo a versão dele usada no job original.
Python
- Transmita a opção
--update. - Defina a opção
--job_nameemPipelineOptionscom o mesmo nome que o job a ser atualizado. - Defina a opção
--regionpara a mesma região do job que você quer atualizar. - Em caso de alteração de qualquer nome de transformação do pipeline, será preciso fornecer um
mapeamento de transformação e transmiti-lo usando a
opção
--transform_name_mapping. - Se você estiver enviando um job de substituição que usa uma versão mais recente do SDK do Apache Beam, defina
--updateCompatibilityVersioncomo a versão dele usada no job original.
Go
- Transmita a opção
--update. - Defina a opção
--job_namecom o mesmo nome do job que você quer atualizar. - Defina a opção
--regionpara a mesma região do job que você quer atualizar. - Em caso de alteração de qualquer nome de transformação do pipeline, será preciso fornecer um
mapeamento de transformação e transmiti-lo usando a
opção
--transform_name_mapping.
gcloud
Para atualizar um job de modelo flexível pela gcloud CLI, use o
comando
gcloud dataflow flex-template run. Não é possível atualizar outros jobs usando a gcloud CLI.
- Transmita a opção
--update. - Defina JOB_NAME com o mesmo nome do job que você quer atualizar.
- Defina a opção
--regionpara a mesma região do job que você quer atualizar. - Em caso de alteração de qualquer nome de transformação do pipeline, será preciso fornecer um
mapeamento de transformação e transmiti-lo usando a
opção
--transform-name-mappings.
REST
Estas instruções mostram como atualizar jobs não relacionados a modelo usando a API REST. Para usar a API REST na atualização de um job de modelo clássico, consulte Atualizar um job de streaming de modelo personalizado. Para usar a API REST na atualização de um job de modelo Flex, consulte Atualizar um job de modelo Flex.
Busque o recurso
jobdo job que você quer substituir usando o métodoprojects.locations.jobs.get. Inclua o parâmetro de consultaviewcom o valorJOB_VIEW_DESCRIPTION. IncluirJOB_VIEW_DESCRIPTIONlimita a quantidade de dados na resposta para que a solicitação seguinte não exceda os limites de tamanho. Se você precisar de informações mais detalhadas sobre o job, use o valorJOB_VIEW_ALL.GET https://dataflow.googleapis.com/v1b3/projects/PROJECT_ID/locations/REGION/jobs/JOB_ID?view=JOB_VIEW_DESCRIPTIONSubstitua os seguintes valores:
- PROJECT_ID: o ID do projeto do Google Cloud do job do Dataflow
- REGION: a região do job que você quer atualizar
- JOB_ID: o ID do job que você quer atualizar
Para atualizar o job, use o método
projects.locations.jobs.create. No corpo da solicitação, use o recursojobque você buscou.POST https://dataflow.googleapis.com/v1b3/projects/PROJECT_ID/locations/REGION/jobs { "id": JOB_ID, "replaceJobId": JOB_ID, "name": JOB_NAME, "type": "JOB_TYPE_STREAMING", "transformNameMapping": { string: string, ... }, }Substitua:
- JOB_ID: o mesmo ID do job que você quer atualizar.
- JOB_NAME: o mesmo nome do job que você quer atualizar.
Em caso de alteração de qualquer nome de transformação do pipeline, será preciso fornecer um mapeamento de transformação e transmiti-lo usando o campo
transformNameMapping.Opcional: para enviar sua solicitação usando curl (Linux, macOS ou Cloud Shell), salve a solicitação em um arquivo JSON e execute o seguinte comando:
curl -X POST -d "@FILE_PATH" -H "Content-Type: application/json" -H "Authorization: Bearer $(gcloud auth print-access-token)" https://dataflow.googleapis.com/v1b3/projects/PROJECT_ID/locations/REGION/jobsSubstitua FILE_PATH pelo caminho para o arquivo JSON que contém o corpo da solicitação.
Especificar o nome do job de substituição
Java
Ao iniciar o job substituto, o valor transmitido para a opção --jobName precisa corresponder exatamente ao nome do job a ser substituído.
Python
Ao iniciar o job de substituição, o valor transmitido à opção --job_name
precisa corresponder exatamente ao nome do job a ser substituído.
Go
Ao iniciar o job de substituição, o valor transmitido à opção --job_name
precisa corresponder exatamente ao nome do job a ser substituído.
gcloud
Quando você inicia o job de substituição, JOB_NAME precisa corresponder exatamente ao nome do job a ser substituído.
REST
Defina o valor do campo replaceJobId como o mesmo ID do job que você quer atualizar. Para encontrar o valor correto do nome do job, selecione o job anterior na Interface de monitoramento do Dataflow.
Em seguida, no painel lateral Informações do job, encontre o campo ID do job.
Para encontrar o valor correto do nome do job, selecione o job anterior na Interface de monitoramento do Dataflow. Em seguida, no painel lateral Informações do job, localize o campo Nome do job:
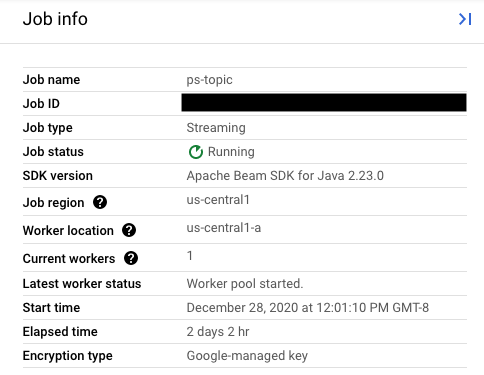
Como alternativa, consulte uma lista de jobs atuais usando a interface de linha de comando do Dataflow.
Digite o comando gcloud dataflow jobs list no shell ou na janela do terminal para acessar uma lista de jobs do Dataflow no projeto do Google Cloud e encontre o campo NAME para o job que você quer substituir:
JOB_ID NAME TYPE CREATION_TIME STATE REGION 2020-12-28_12_01_09-yourdataflowjobid ps-topic Streaming 2020-12-28 20:01:10 Running us-central1
Criar um mapeamento de transformação
Se o pipeline substituto tiver alterado qualquer nome de transformação do pipeline anterior, o serviço do Dataflow exigirá um mapeamento de transformação. Esse mapeamento correlaciona as transformações nomeadas no código do pipeline anterior com os nomes no código do pipeline substituto.
Java
Transmita o mapeamento usando a opção de linha de comando --transformNameMapping,
usando o seguinte formato geral:
--transformNameMapping= .
{"oldTransform1":"newTransform1","oldTransform2":"newTransform2",...}
Só é preciso fornecer entradas de mapeamento em --transformNameMapping para nomes de transformação que foram alterados entre o pipeline anterior e o pipeline substituto.
Ao executar com --transformNameMapping, talvez seja necessário inserir caracteres de escape para aspas conforme apropriado no seu shell. Por exemplo, em Bash:
--transformNameMapping='{"oldTransform1":"newTransform1",...}'
Python
Transmita o mapeamento usando a opção de linha de comando --transform_name_mapping,
usando o seguinte formato geral:
--transform_name_mapping= .
{"oldTransform1":"newTransform1","oldTransform2":"newTransform2",...}
Só é preciso fornecer entradas de mapeamento em --transform_name_mapping para nomes de transformação que foram alterados entre o pipeline anterior e o pipeline substituto.
Ao executar com --transform_name_mapping, talvez seja necessário inserir caracteres de escape para aspas conforme apropriado no seu shell. Por exemplo, em Bash:
--transform_name_mapping='{"oldTransform1":"newTransform1",...}'
Go
Transmita o mapeamento usando a opção de linha de comando --transform_name_mapping,
usando o seguinte formato geral:
--transform_name_mapping= .
{"oldTransform1":"newTransform1","oldTransform2":"newTransform2",...}
Só é preciso fornecer entradas de mapeamento em --transform_name_mapping para nomes de transformação que foram alterados entre o pipeline anterior e o pipeline substituto.
Ao executar com --transform_name_mapping, talvez seja necessário inserir caracteres de escape para aspas conforme apropriado no seu shell. Por exemplo, em Bash:
--transform_name_mapping='{"oldTransform1":"newTransform1",...}'
gcloud
Transmita o mapeamento usando a opção --transform-name-mappings com o seguinte formato geral:
--transform-name-mappings= .
{"oldTransform1":"newTransform1","oldTransform2":"newTransform2",...}
Só é preciso fornecer entradas de mapeamento em --transform-name-mappings para nomes de transformação que foram alterados entre o pipeline anterior e o pipeline substituto.
Ao executar com --transform-name-mappings, talvez seja necessário inserir caracteres de escape para aspas conforme apropriado no seu shell. Por exemplo,
em Bash:
--transform-name-mappings='{"oldTransform1":"newTransform1",...}'
REST
Transmita o mapeamento usando o campo transformNameMapping com o seguinte formato geral:
"transformNameMapping": {
oldTransform1: newTransform1,
oldTransform2: newTransform2,
...
}
Só é preciso fornecer entradas de mapeamento em transformNameMapping para nomes de transformação que foram alterados entre o pipeline anterior e o pipeline substituto.
Determinar nomes de transformação
O nome da transformação em cada instância no mapa é o que você forneceu ao aplicar a transformação no pipeline. Por exemplo:
Java
.apply("FormatResults", ParDo
.of(new DoFn<KV<String, Long>>, String>() {
...
}
}))
Python
| 'FormatResults' >> beam.ParDo(MyDoFn())
Go
// In Go, this is always the package-qualified name of the DoFn itself.
// For example, if the FormatResults DoFn is in the main package, its name
// is "main.FormatResults".
beam.ParDo(s, FormatResults, results)
Você também pode acessar os nomes de transformação do job anterior ao examinar o gráfico de execução do job na Interface de monitoramento do Dataflow:
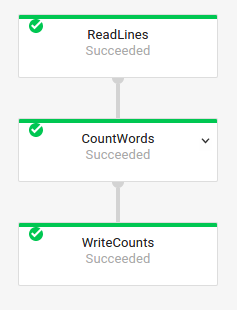
Nomenclatura de transformação composta
Os nomes de transformação são hierárquicos e têm como base a hierarquia de transformação do canal. Se o pipeline tem uma transformação composta, as transformações aninhadas são nomeadas com base nas transformações que as contêm. Por exemplo, suponha que o pipeline contenha uma transformação composta chamada CountWidgets, que contém uma transformação interna chamada Parse. O nome completo da transformação é CountWidgets/Parse, e você precisa especificar esse nome no mapeamento de transformação.
Se seu novo canal mapear uma transformação composta para um nome diferente, todas as transformações aninhadas também serão renomeadas automaticamente. Especifique os nomes alterados para as transformações internas no mapeamento de transformação.
Refatorar a hierarquia de transformação
Se o pipeline substituto usa uma hierarquia de transformação diferente do pipeline anterior, é preciso declarar explicitamente o mapeamento. Você pode ter uma hierarquia de transformação diferente porque refatorou as transformações compostas ou o pipeline depende de uma transformação composta de uma biblioteca que mudou.
Por exemplo, o pipeline anterior aplicou uma transformação composta, CountWidgets, que continha uma transformação interna chamada Parse. O pipeline substituto refatora CountWidgets e aninha Parse dentro de outra transformação chamada Scan. Para que a atualização funcione, mapeie explicitamente o nome completo da transformação no pipeline anterior (CountWidgets/Parse) para o nome da transformação no novo pipeline (CountWidgets/Scan/Parse):
Java
--transformNameMapping={"CountWidgets/Parse":"CountWidgets/Scan/Parse"}
Se você excluir completamente uma transformação no pipeline de substituição, forneça
um mapeamento nulo. Suponha que o pipeline de substituição remova a
transformação CountWidgets/Parse inteiramente:
--transformNameMapping={"CountWidgets/Parse":""}
Python
--transform_name_mapping={"CountWidgets/Parse":"CountWidgets/Scan/Parse"}
Se você excluir completamente uma transformação no pipeline de substituição, forneça
um mapeamento nulo. Suponha que o pipeline de substituição remova a
transformação CountWidgets/Parse inteiramente:
--transform_name_mapping={"CountWidgets/Parse":""}
Go
--transform_name_mapping={"CountWidgets/main.Parse":"CountWidgets/Scan/main.Parse"}
Se você excluir completamente uma transformação no pipeline de substituição, forneça
um mapeamento nulo. Suponha que o pipeline de substituição remova a
transformação CountWidgets/Parse inteiramente:
--transform_name_mapping={"CountWidgets/main.Parse":""}
gcloud
--transform-name-mappings={"CountWidgets/Parse":"CountWidgets/Scan/Parse"}
Se você excluir completamente uma transformação no pipeline de substituição, forneça
um mapeamento nulo. Suponha que o pipeline de substituição remova a
transformação CountWidgets/Parse inteiramente:
--transform-name-mappings={"CountWidgets/main.Parse":""}
REST
"transformNameMapping": {
CountWidgets/Parse: CountWidgets/Scan/Parse
}
Se você excluir completamente uma transformação no pipeline de substituição, forneça
um mapeamento nulo. Suponha que o pipeline de substituição remova a
transformação CountWidgets/Parse inteiramente:
"transformNameMapping": {
CountWidgets/main.Parse: null
}
Os efeitos da substituição de um job
Quando você substitui um job atual, um novo job executa o código atualizado do pipeline. O serviço do Dataflow retém o nome do job, mas executa o substituto com um ID do job atualizado. Esse processo pode causar inatividade enquanto o job atual é interrompido, a verificação de compatibilidade é executada e o novo job é iniciado.
O job substituto preserva os seguintes itens:
- Os dados do estado intermediário do job anterior. Os caches na memória não são salvos.
- Registros de dados em buffer ou metadados atualmente "em trânsito" provenientes do job anterior. Por exemplo, alguns registros no pipeline podem entrar em buffer enquanto aguardam a resolução de uma janela.
- As atualizações de opções de jobs em trânsito aplicadas ao job anterior.
Dados do estado intermediário
Os dados do estado intermediário do job anterior são preservados. Os dados de estado não incluem caches na memória. Se você quiser preservar dados de cache na memória ao atualizar o pipeline, como solução alternativa, refatore o pipeline para converter caches em dados de estado ou entradas secundárias. Para mais informações sobre o uso de entradas secundárias, consulte Padrões de entrada secundária na documentação do Apache Beam.
Os pipelines de streaming têm limites de tamanho para ValueState e para entradas secundárias.
Como resultado, se você tiver caches grandes que queira preservar, talvez seja necessário usar o armazenamento externo, como o Memorystore ou o Bigtable.
Dados em trânsito
Os dados "em trânsito" ainda são processados pelas transformações em seu novo canal. No entanto, transformações adicionais adicionadas ao seu código de canal de substituição podem ou não ter efeito, dependendo de onde os registros são armazenados em buffer. Neste exemplo, o pipeline atual tem as seguintes transformações:
Java
p.apply("Read", ReadStrings())
.apply("Format", FormatStrings());
Python
p | 'Read' >> beam.io.ReadFromPubSub(subscription=known_args.input_subscription)
| 'Format' >> FormatStrings()
Go
beam.ParDo(s, ReadStrings) beam.ParDo(s, FormatStrings)
Para substituir o job por um novo código de pipeline:
Java
p.apply("Read", ReadStrings())
.apply("Remove", RemoveStringsStartingWithA())
.apply("Format", FormatStrings());
Python
p | 'Read' >> beam.io.ReadFromPubSub(subscription=known_args.input_subscription)
| 'Remove' >> RemoveStringsStartingWithA()
| 'Format' >> FormatStrings()
Go
beam.ParDo(s, ReadStrings) beam.ParDo(s, RemoveStringsStartingWithA) beam.ParDo(s, FormatStrings)
Mesmo com a inclusão de uma transformação para filtrar as strings que começam com a
letra "A", é possível que a transformação seguinte (FormatStrings) ainda detecte
strings em buffer ou em trânsito começando com "A", transferidas do job
anterior.
Alterar janelamento
É possível alterar as janelas e acionar estratégias para os elementos PCollection no pipeline substituto, mas tenha cuidado.
Alterar as estratégias de acionador ou de uso de janelas não afeta os dados que já estão em buffer ou em trânsito.
Recomendamos que você tente fazer apenas alterações menores nas janelas do canal, como uma mudança na duração das janelas de tempo fixo ou variável. Grandes mudanças em janelas ou acionamentos, como a alteração de algoritmos, podem surtir resultados imprevisíveis na saída do canal.
Verificação de compatibilidade do job
Quando você inicia o job substituto, o serviço Dataflow faz uma verificação de compatibilidade entre esse job e o anterior. Se a verificação de compatibilidade for aprovada, o job anterior será interrompido. Seu job de substituição é iniciado no serviço do Dataflow, mantendo o mesmo nome de job. Se a verificação de compatibilidade falhar, o job anterior continuará em execução no serviço do Dataflow e o substituto gerará um erro.
Java
Devido a uma limitação, é necessário usar a execução de bloqueio para ver erros de tentativa de atualização com falha no console ou no terminal. A solução alternativa atual consiste nos passos a seguir:
- Use pipeline.run().waitUntilFinish() no código do seu pipeline.
- Execute o programa do pipeline substituto com a opção
--update. - Aguarde a aprovação do job substituto na verificação de compatibilidade.
- Saia do processo de bloqueio do executor digitando
Ctrl+C.
Como alternativa, monitore o estado do job substituto na interface de monitoramento do Dataflow. Se o job foi iniciado com sucesso, ele também passou na verificação de compatibilidade.
Python
Devido a uma limitação, é necessário usar a execução de bloqueio para ver erros de tentativa de atualização com falha no console ou no terminal. A solução alternativa atual consiste nos passos a seguir:
- Use pipeline.run().wait_until_finish() no código do seu pipeline.
- Execute o programa do pipeline substituto com a opção
--update. - Aguarde a aprovação do job substituto na verificação de compatibilidade.
- Saia do processo de bloqueio do executor digitando
Ctrl+C.
Como alternativa, monitore o estado do job substituto na interface de monitoramento do Dataflow. Se o job foi iniciado com sucesso, ele também passou na verificação de compatibilidade.
Go
Devido a uma limitação, é necessário usar a execução de bloqueio para ver erros de tentativa de atualização com falha no console ou no terminal.
Especificamente, é preciso definir a execução sem bloqueio usando as flags --execute_async ou --async. A solução alternativa atual consiste nos passos a seguir:
- Execute o programa de pipeline substituto com a opção
--updatee sem as sinalizações--execute_asyncou--async. - Aguarde a aprovação do job substituto na verificação de compatibilidade.
- Saia do processo de bloqueio do executor digitando
Ctrl+C.
gcloud
Devido a uma limitação, é necessário usar a execução de bloqueio para ver erros de tentativa de atualização com falha no console ou no terminal. A solução alternativa atual consiste nos passos a seguir:
- Para pipelines em Java, use pipeline.run().waitUntilFinish() no código do seu pipeline. Para pipelines do Python, use pipeline.run().wait_until_finish() no código do seu pipeline. Para pipelines em Go, siga as etapas na guia "Go".
- Execute o programa do pipeline substituto com a opção
--update. - Aguarde a aprovação do job substituto na verificação de compatibilidade.
- Saia do processo de bloqueio do executor digitando
Ctrl+C.
REST
Devido a uma limitação, é necessário usar a execução de bloqueio para ver erros de tentativa de atualização com falha no console ou no terminal. A solução alternativa atual consiste nos passos a seguir:
- Para pipelines em Java, use pipeline.run().waitUntilFinish() no código do seu pipeline. Para pipelines do Python, use pipeline.run().wait_until_finish() no código do seu pipeline. Para pipelines em Go, siga as etapas na guia "Go".
- Execute o programa do pipeline substituto com o campo
replaceJobId. - Aguarde a aprovação do job substituto na verificação de compatibilidade.
- Saia do processo de bloqueio do executor digitando
Ctrl+C.
A verificação de compatibilidade usa o mapeamento de transformação fornecido para garantir que o Dataflow possa transferir dados do estado intermediário das etapas do job anterior para o substituto. A verificação de compatibilidade também garante que os PCollections no pipeline usem os mesmos codificadores.
A alteração de um Coder pode gerar falhas na verificação de compatibilidade, porque talvez não seja possível serializar corretamente os dados em trânsito ou os registros em buffer no pipeline substituto.
Evitar falhas de compatibilidade
Certas diferenças entre o canal anterior e o substituto podem gerar falhas na verificação de compatibilidade. Essas diferenças incluem:
- Alteração do gráfico do pipeline sem fornecer um mapeamento. Quando você atualiza um job, o Dataflow tenta corresponder as transformações do job anterior com as do substituto. Esse processo de correspondência ajuda o Dataflow a transferir dados de estado intermediário para cada etapa. Se você renomear ou remover etapas, precisará fornecer um mapeamento de transformação para que o Dataflow possa corresponder dados de estado adequadamente.
- Alteração de entradas secundárias de um passo. A inclusão ou remoção de entradas secundárias em uma transformação no pipeline substituto pode gerar falhas na verificação de compatibilidade.
- Alteração do codificador de um passo. Quando você atualiza um job, o Dataflow preserva os registros de dados atualmente em buffer e os trata no substituto. Por exemplo, dados armazenados em buffer podem ocorrer enquanto a gestão de janelas é resolvida. Se o job substituto usa uma codificação de dados diferente ou incompatível, o serviço Dataflow não consegue serializar ou desserializar esses registros.
Remover uma operação com estado do seu pipeline. Se você remover as operações com estado do pipeline, o job substituto poderá falhar na verificação de compatibilidade. O Dataflow pode fundir várias etapas para eficiência. Se você remover uma operação dependente do estado de uma etapa com fusível, a verificação falhará. Veja alguns exemplos de operações com monitoramento de estado:
- Transformações que produzem ou consomem entradas secundárias
- Leituras de E/S
- Transformações que usam estado com chave
- Transformações com mesclagem de janelas
Como mudar variáveis
DoFncom estado. Para jobs de streaming em andamento, se o pipeline incluirDoFns com estado, alterar as variáveisDoFncom estado pode causar falha no pipeline.Tentativa de executar o job substituto em uma zona geográfica diferente. Execute o job substituto na mesma zona do anterior.
Como atualizar esquemas
O Apache Beam permite que as PCollections tenham esquemas com campos nomeados. Nesse caso, os codificadores
explícitos não são necessários. Se os nomes e tipos de campos de um determinado esquema não forem alterados (incluindo campos aninhados), esse esquema não causará falha na verificação de atualização. No entanto, a atualização ainda poderá ser bloqueada se outros segmentos do novo pipeline forem incompatíveis.
Evoluir esquemas
Muitas vezes, é necessário evoluir o esquema de PCollection devido à evolução dos requisitos de negócios. Ao atualizar o pipeline, o serviço Dataflow permite fazer as seguintes
mudanças em um esquema:
- Adicionar um ou mais campos novos a um esquema, incluindo campos aninhados.
- Fazer um tipo de campo obrigatório (não anulável) virar opcional (anulável).
Não é permitido remover campos, alterar nomes ou tipos de campo durante a atualização.
Transmitir dados extras para uma operação ParDo existente
É possível transmitir dados extras (fora de banda) para uma operação ParDo existente usando um dos métodos a seguir, dependendo do seu caso de uso:
- Serializando informações como campos na subclasse
DoFn. - Todas as variáveis referenciadas pelos métodos em uma
DoFnanônima são serializadas automaticamente. - Calculando dados dentro de
DoFn.startBundle(). - Transmitindo os dados usando
ParDo.withSideInputs.
Para mais informações, consulte as seguintes páginas:
- Guia de programação do Apache Beam: ParDo, em especial as seções sobre como criar uma DoFn e entradas secundárias.
- Referência do SDK do Apache Beam para Java: ParDo