본 페이지에서는 Dataflow 파이프라인을 구축 및 실행에 문제가 있는 경우 유용한 문제 해결 팁과 디버깅 전략을 제공합니다. 이 정보는 파이프라인 오류를 감지하고 파이프라인 실행 오류의 원인을 확인하며 문제 해결 조치를 취하는 데 유용할 수 있습니다.
아래 다이어그램은 이 페이지에서 설명하는 Dataflow 문제 해결 워크플로를 보여줍니다.

Dataflow는 작업에 대한 실시간 피드백을 제공하는데 오류 메시지, 로깅, 설치 작업 진행 상황 등의 상태를 확인하는 데 사용할 수 있는 기본 단계가 있습니다.
Dataflow 작업을 실행할 때 발생할 수 있는 일반적인 오류에 대한 안내는 Dataflow 오류 문제 해결을 참조하세요. 파이프라인 성능을 모니터링하고 문제를 해결하려면 파이프라인 성능 모니터링을 참조하세요.
파이프라인 권장사항
다음은 자바, Python, Go 파이프라인의 권장사항입니다.
자바
Python
임시 위치와 스테이징 위치에는 모두 <job_name>.<time> 프리픽스가 있습니다.
Go
파이프라인 상태 확인
Dataflow 모니터링 인터페이스를 사용하면 파이프라인 실행의 모든 오류를 감지할 수 있습니다.
- Google Cloud 콘솔로 이동합니다.
- 프로젝트 목록에서 Google Cloud 프로젝트를 선택합니다.
- 탐색 메뉴의 빅데이터에서 Dataflow를 클릭합니다. 오른쪽 창에 실행 중인 작업 목록이 나타납니다.
- 확인할 파이프라인 작업을 선택합니다. 상태 필드에서 작업 상태('실행 중', '성공' 또는 '실패')를 한눈에 확인할 수 있습니다.
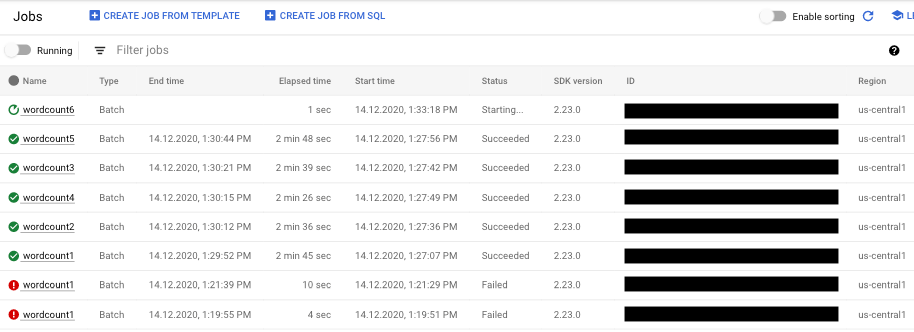
파이프라인 오류에 대한 정보 찾기
파이프라인 작업 중 하나가 실패하면 작업을 선택하여 오류와 실행 결과의 세부정보를 확인할 수 있습니다. 작업을 선택하면 파이프라인의 키 차트, 실행 그래프, 작업 정보 패널, 작업 로그가 포함된 작업 패널, 작업자 로그, , 진단, 권장사항 탭을 볼 수 있습니다.
작업 오류 메시지 확인
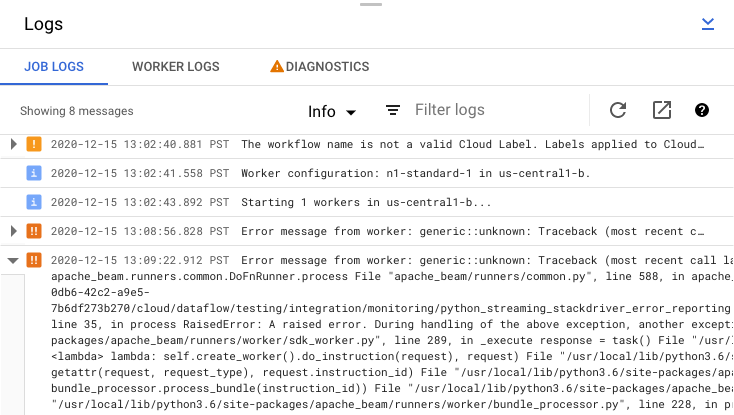
파이프라인 코드 및 Dataflow 서비스에 의해 생성된 작업 로그를 보려면 로그 패널에서 segment보기를 클릭하세요.
정보arrow_drop_down 및 filter_list필터를 클릭하여 작업 로그에 표시되는 메시지를 필터링할 수 있습니다. 오류 메시지만 표시하려면 정보arrow_drop_down를 클릭하고 오류를 선택합니다.
오류 메시지를 펼치려면 확장 가능 섹션 arrow_right를 클릭하세요.
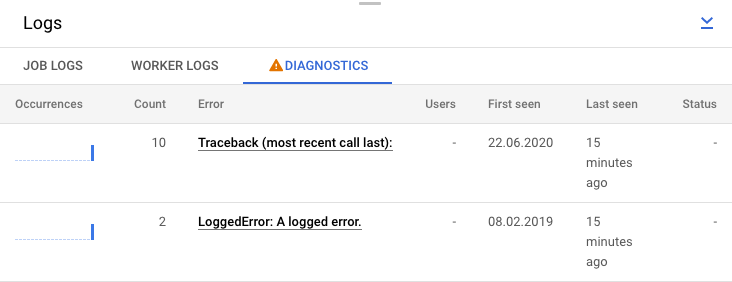
또는 진단 탭을 클릭해도 됩니다. 이 탭에는 선택한 타임라인에서 오류가 발생한 위치, 로깅된 모든 오류 수, 파이프라인에 대한 가능한 권장사항이 표시됩니다.
작업의 단계 로그 보기
파이프라인 그래프에서 단계를 선택하면 로그 패널이 Dataflow 서비스에서 생성한 작업 로그를 표시하다가 파이프라인 단계를 실행하는 Compute Engine 인스턴스의 로그를 표시하도록 전환됩니다.
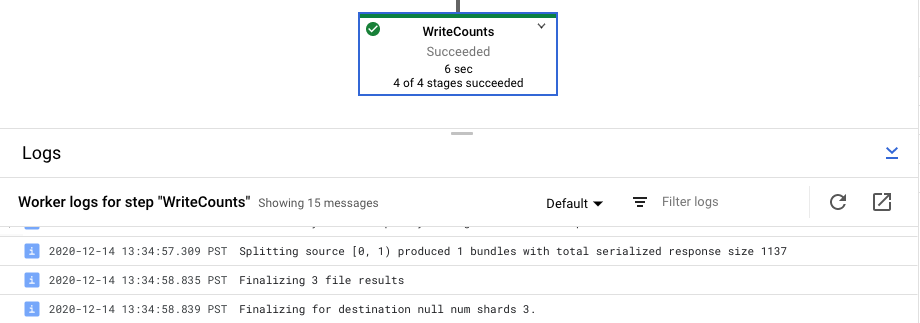
Cloud Logging은 프로젝트의 Compute Engine 인스턴스에서 수집된 모든 로그를 한곳으로 모읍니다. Dataflow의 다양한 로깅 기능 사용에 대한 자세한 내용은 로깅 파이프라인 메시지를 참조하세요.
자동 파이프라인 거부 처리
경우에 따라 Dataflow 서비스는 알려진 SDK 문제를 트리거할 가능성이 있는 파이프라인을 파악합니다. 문제가 발생할 가능성이 높은 파이프라인이 제출되지 않도록 하기 위해 Dataflow는 파이프라인을 자동으로 거부하고 다음 메시지를 표시합니다.
The workflow was automatically rejected by the service because it might trigger an identified bug in the SDK (details below). If you think this identification is in error, and would like to override this automated rejection, please re-submit this workflow with the following override flag: [OVERRIDE FLAG]. Bug details: [BUG DETAILS]. Contact Google Cloud Support for further help. Please use this identifier in your communication: [BUG ID].
연결된 버그 세부정보의 주의 사항을 읽은 후 파이프라인을 실행하려면 자동 거부를 재정의하면 됩니다. --experiments=<override-flag> 플래그를 추가하고 파이프라인을 다시 제출합니다.
파이프라인 오류 원인 확인
일반적으로 Apache Beam 파이프라인 실행은 다음 원인 중 하나로 인해 실패할 수 있습니다.
- 그래프 또는 파이프라인 구성 오류. Apache Beam 파이프라인에서 설명한 대로 파이프라인을 구성하는 단계 그래프를 빌드하는 과정에서 Dataflow에 문제가 생기는 경우에 이 오류가 발생합니다.
- 작업 유효성 검사 오류. Dataflow 서비스는 실행되는 파이프라인 작업의 유효성을 검사합니다. 유효성 검사 프로세스에서 오류가 발견되면 작업이 성공적으로 생성되거나 실행되지 않을 수 있습니다. 검증 오류에는 Google Cloud 프로젝트의 Cloud Storage 버킷 또는 프로젝트 권한 문제 등이 포함될 수 있습니다.
- 작업자 코드의 예외.
ParDo변환의DoFn인스턴스와 같이 Dataflow가 병렬 작업자로 배포하는 사용자 제공 코드에 오류나 버그가 있으면 이 오류가 발생합니다. - 다른 Google Cloud 서비스의 일시적인 장애로 인해 발생한 오류 Compute Engine 또는 Cloud Storage 등 Dataflow가 종속된Google Cloud 서비스의 일시적 중단 또는 기타 문제로 인해 파이프라인이 실패할 수 있습니다.
그래프 또는 파이프라인 구성 오류 감지
Dataflow가 Dataflow 프로그램 코드에서 파이프라인의 실행 그래프를 빌드할 때 그래프 구성 오류가 발생할 수 있습니다. 그래프 구성되는 동안 Dataflow는 잘못된 작업이 있는지 확인합니다.
Dataflow가 그래프 구성에서 오류를 감지하면 Dataflow 서비스에서 어떤 작업도 생성되지 않습니다. 따라서 Dataflow 모니터링 인터페이스에 아무런 피드백도 표시되지 않습니다. 대신 Apache Beam 파이프라인을 실행한 콘솔이나 터미널 창에 다음과 유사한 오류 메시지가 표시됩니다.
자바
예를 들어, 파이프라인에서 전역 기간이 지정되고 트리거되지 않으며 제한 없는 PCollection에서 GroupByKey와 같은 집계를 수행하려 하면 다음과 유사한 오류 메시지가 표시됩니다.
... ... Exception in thread "main" java.lang.IllegalStateException: ... GroupByKey cannot be applied to non-bounded PCollection in the GlobalWindow without a trigger. ... Use a Window.into or Window.triggering transform prior to GroupByKey ...
Python
예를 들어, 파이프라인이 형식 힌트를 사용하고, 변환 중 하나에 있는 인수 형식이 예상과 다르면 다음과 유사한 오류 메시지가 표시됩니다.
... in <module> run()
... in run | beam.Map('count', lambda (word, ones): (word, sum(ones))))
... in __or__ return self.pipeline.apply(ptransform, self)
... in apply transform.type_check_inputs(pvalueish)
... in type_check_inputs self.type_check_inputs_or_outputs(pvalueish, 'input')
... in type_check_inputs_or_outputs pvalue_.element_type))
google.cloud.dataflow.typehints.decorators.TypeCheckError: Input type hint violation at group: expected Tuple[TypeVariable[K], TypeVariable[V]], got <type 'str'>
Go
예를 들어 파이프라인에서 입력을 사용하지 않는 `DoFn`을 사용하는 경우 다음과 유사한 오류 메시지가 표시됩니다.
... panic: Method ProcessElement in DoFn main.extractFn is missing all inputs. A main input is required. ... Full error: ... inserting ParDo in scope root/CountWords ... graph.AsDoFn: for Fn named main.extractFn ... ProcessElement method has no main inputs ... goroutine 1 [running]: ... github.com/apache/beam/sdks/v2/go/pkg/beam.MustN(...) ... (more stacktrace)
이러한 오류가 발생하면 파이프라인 코드를 확인하여 파이프라인 작업이 정상적인지 확인합니다.
Dataflow 작업 유효성 검사에서 오류 감지
Dataflow 서비스가 파이프라인의 그래프를 수신하면 서비스가 작업의 유효성 검사를 시도합니다. 이 유효성 검사에는 다음이 포함됩니다.
- 서비스가 파일 스테이징과 임시 출력을 위해 작업 관련 Cloud Storage 버킷에 액세스할 수 있는지 확인
- Google Cloud 프로젝트에 필요한 권한 확인
- 서비스가 입력과 출력 소스(파일 등)에 액세스할 수 있는지 확인
작업이 유효성 검사 프로세스에 실패하면 실행 차단을 사용하는 경우 콘솔이나 터미널 윈도우뿐만 아니라 Dataflow 모니터링 인터페이스에도 오류 메시지가 표시됩니다. 오류 메시지는 다음과 유사합니다.
자바
INFO: To access the Dataflow monitoring console, please navigate to
https://console.developers.google.com/project/google.com%3Aclouddfe/dataflow/job/2016-03-08_18_59_25-16868399470801620798
Submitted job: 2016-03-08_18_59_25-16868399470801620798
...
... Starting 3 workers...
... Executing operation BigQuery-Read+AnonymousParDo+BigQuery-Write
... Executing BigQuery import job "dataflow_job_16868399470801619475".
... Stopping worker pool...
... Workflow failed. Causes: ...BigQuery-Read+AnonymousParDo+BigQuery-Write failed.
Causes: ... BigQuery getting table "non_existent_table" from dataset "cws_demo" in project "my_project" failed.
Message: Not found: Table x:cws_demo.non_existent_table HTTP Code: 404
... Worker pool stopped.
... com.google.cloud.dataflow.sdk.runners.BlockingDataflowPipelineRunner run
INFO: Job finished with status FAILED
Exception in thread "main" com.google.cloud.dataflow.sdk.runners.DataflowJobExecutionException:
Job 2016-03-08_18_59_25-16868399470801620798 failed with status FAILED
at com.google.cloud.dataflow.sdk.runners.DataflowRunner.run(DataflowRunner.java:155)
at com.google.cloud.dataflow.sdk.runners.DataflowRunner.run(DataflowRunner.java:56)
at com.google.cloud.dataflow.sdk.Pipeline.run(Pipeline.java:180)
at com.google.cloud.dataflow.integration.BigQueryCopyTableExample.main(BigQueryCopyTableExample.java:74)
Python
INFO:root:Created job with id: [2016-03-08_14_12_01-2117248033993412477] ... Checking required Cloud APIs are enabled. ... Job 2016-03-08_14_12_01-2117248033993412477 is in state JOB_STATE_RUNNING. ... Combiner lifting skipped for step group: GroupByKey not followed by a combiner. ... Expanding GroupByKey operations into optimizable parts. ... Lifting ValueCombiningMappingFns into MergeBucketsMappingFns ... Annotating graph with Autotuner information. ... Fusing adjacent ParDo, Read, Write, and Flatten operations ... Fusing consumer split into read ... ... Starting 1 workers... ... ... Executing operation read+split+pair_with_one+group/Reify+group/Write ... Executing failure step failure14 ... Workflow failed. Causes: ... read+split+pair_with_one+group/Reify+group/Write failed. Causes: ... Unable to view metadata for files: gs://dataflow-samples/shakespeare/missing.txt. ... Cleaning up. ... Tearing down pending resources... INFO:root:Job 2016-03-08_14_12_01-2117248033993412477 is in state JOB_STATE_FAILED.
Go
이 섹션에서 설명하는 작업 유효성 검사는 현재 Go에서 지원되지 않습니다. 이러한 문제로 인한 오류는 작업자 예외로 표시됩니다.
작업자 코드에서 예외 감지
작업을 실행하는 중에 작업자 코드에서 오류나 예외가 발생할 수 있습니다. 이러한 오류는 일반적으로 파이프라인 코드의 DoFn이 처리되지 않은 예외를 발생시켜 작업이 Dataflow 작업에서 실패했음을 나타냅니다.
사용자 코드(예: DoFn 인스턴스) 예외는 Dataflow 모니터링 인터페이스에 보고됩니다.
차단 실행으로 파이프라인을 실행하면 다음과 같이 콘솔이나 터미널 창에 오류 메시지가 출력됩니다.
자바
INFO: To access the Dataflow monitoring console, please navigate to https://console.developers.google.com/project/example_project/dataflow/job/2017-05-23_14_02_46-1117850763061203461
Submitted job: 2017-05-23_14_02_46-1117850763061203461
...
... To cancel the job using the 'gcloud' tool, run: gcloud beta dataflow jobs --project=example_project cancel 2017-05-23_14_02_46-1117850763061203461
... Autoscaling is enabled for job 2017-05-23_14_02_46-1117850763061203461.
... The number of workers will be between 1 and 15.
... Autoscaling was automatically enabled for job 2017-05-23_14_02_46-1117850763061203461.
...
... Executing operation BigQueryIO.Write/BatchLoads/Create/Read(CreateSource)+BigQueryIO.Write/BatchLoads/GetTempFilePrefix+BigQueryIO.Write/BatchLoads/TempFilePrefixView/BatchViewOverrides.GroupByWindowHashAsKeyAndWindowAsSortKey/ParDo(UseWindowHashAsKeyAndWindowAsSortKey)+BigQueryIO.Write/BatchLoads/TempFilePrefixView/Combine.GloballyAsSingletonView/Combine.globally(Singleton)/WithKeys/AddKeys/Map/ParMultiDo(Anonymous)+BigQueryIO.Write/BatchLoads/TempFilePrefixView/Combine.GloballyAsSingletonView/Combine.globally(Singleton)/Combine.perKey(Singleton)/GroupByKey/Reify+BigQueryIO.Write/BatchLoads/TempFilePrefixView/Combine.GloballyAsSingletonView/Combine.globally(Singleton)/Combine.perKey(Singleton)/GroupByKey/Write+BigQueryIO.Write/BatchLoads/TempFilePrefixView/BatchViewOverrides.GroupByWindowHashAsKeyAndWindowAsSortKey/BatchViewOverrides.GroupByKeyAndSortValuesOnly/Write
... Workers have started successfully.
...
... org.apache.beam.runners.dataflow.util.MonitoringUtil$LoggingHandler process SEVERE: 2017-05-23T21:06:33.711Z: (c14bab21d699a182): java.lang.RuntimeException: org.apache.beam.sdk.util.UserCodeException: java.lang.ArithmeticException: / by zero
at com.google.cloud.dataflow.worker.runners.worker.GroupAlsoByWindowsParDoFn$1.output(GroupAlsoByWindowsParDoFn.java:146)
at com.google.cloud.dataflow.worker.runners.worker.GroupAlsoByWindowFnRunner$1.outputWindowedValue(GroupAlsoByWindowFnRunner.java:104)
at com.google.cloud.dataflow.worker.util.BatchGroupAlsoByWindowAndCombineFn.closeWindow(BatchGroupAlsoByWindowAndCombineFn.java:191)
...
... Cleaning up.
... Stopping worker pool...
... Worker pool stopped.
Python
INFO:root:Job 2016-03-08_14_21_32-8974754969325215880 is in state JOB_STATE_RUNNING. ... INFO:root:... Expanding GroupByKey operations into optimizable parts. INFO:root:... Lifting ValueCombiningMappingFns into MergeBucketsMappingFns INFO:root:... Annotating graph with Autotuner information. INFO:root:... Fusing adjacent ParDo, Read, Write, and Flatten operations ... INFO:root:...: Starting 1 workers... INFO:root:...: Executing operation group/Create INFO:root:...: Value "group/Session" materialized. INFO:root:...: Executing operation read+split+pair_with_one+group/Reify+group/Write INFO:root:Job 2016-03-08_14_21_32-8974754969325215880 is in state JOB_STATE_RUNNING. INFO:root:...: ...: Workers have started successfully. INFO:root:Job 2016-03-08_14_21_32-8974754969325215880 is in state JOB_STATE_RUNNING. INFO:root:...: Traceback (most recent call last): File ".../dataflow_worker/batchworker.py", line 384, in do_work self.current_executor.execute(work_item.map_task) ... File ".../apache_beam/examples/wordcount.runfiles/py/apache_beam/examples/wordcount.py", line 73, in <lambda> ValueError: invalid literal for int() with base 10: 'www'
Go
... 2022-05-26T18:32:52.752315397Zprocess bundle failed for instruction ... process_bundle-4031463614776698457-2 using plan s02-6 : while executing ... Process for Plan[s02-6] failed: Oh no! This is an error message!
예외 핸들러를 추가하여 코드에서의 오류를 방지할 수 있습니다. 예를 들어, ParDo에서 수행된 일부 커스텀 입력 유효성 검사를 실패한 요소를 삭제하려면 DoFn 내의 예외를 처리하고 요소를 삭제합니다.
또한 몇 가지 다른 방법으로 실패한 요소를 추적할 수 있습니다.
- Cloud Logging을 사용하여 실패한 요소를 로깅하고 출력을 확인할 수 있습니다.
- 로그 보기의 안내에 따라 Dataflow 작업자 및 작업자 시작 로그에서 경고 또는 오류를 확인할 수 있습니다.
- 나중에 검사하기 위해
ParDo가 실패한 요소를 추가 출력에 쓰도록 할 수 있습니다.
다음 예시와 같이 Metrics 클래스를 사용하여 실행 중인 파이프라인의 속성을 추적할 수 있습니다.
자바
final Counter counter = Metrics.counter("stats", "even-items"); PCollection<Integer> input = pipeline.apply(...); ... input.apply(ParDo.of(new DoFn<Integer, Integer>() { @ProcessElement public void processElement(ProcessContext c) { if (c.element() % 2 == 0) { counter.inc(); } });
Python
class FilterTextFn(beam.DoFn): """A DoFn that filters for a specific key based on a regex.""" def __init__(self, pattern): self.pattern = pattern # A custom metric can track values in your pipeline as it runs. Create # custom metrics to count unmatched words, and know the distribution of # word lengths in the input PCollection. self.word_len_dist = Metrics.distribution(self.__class__, 'word_len_dist') self.unmatched_words = Metrics.counter(self.__class__, 'unmatched_words') def process(self, element): word = element self.word_len_dist.update(len(word)) if re.match(self.pattern, word): yield element else: self.unmatched_words.inc() filtered_words = ( words | 'FilterText' >> beam.ParDo(FilterTextFn('s.*')))
Go
func addMetricDoFnToPipeline(s beam.Scope, input beam.PCollection) beam.PCollection { return beam.ParDo(s, &MyMetricsDoFn{}, input) } func executePipelineAndGetMetrics(ctx context.Context, p *beam.Pipeline) (metrics.QueryResults, error) { pr, err := beam.Run(ctx, runner, p) if err != nil { return metrics.QueryResults{}, err } // Request the metric called "counter1" in namespace called "namespace" ms := pr.Metrics().Query(func(r beam.MetricResult) bool { return r.Namespace() == "namespace" && r.Name() == "counter1" }) // Print the metric value - there should be only one line because there is // only one metric called "counter1" in the namespace called "namespace" for _, c := range ms.Counters() { fmt.Println(c.Namespace(), "-", c.Name(), ":", c.Committed) } return ms, nil } type MyMetricsDoFn struct { counter beam.Counter } func init() { beam.RegisterType(reflect.TypeOf((*MyMetricsDoFn)(nil))) } func (fn *MyMetricsDoFn) Setup() { // While metrics can be defined in package scope or dynamically // it's most efficient to include them in the DoFn. fn.counter = beam.NewCounter("namespace", "counter1") } func (fn *MyMetricsDoFn) ProcessElement(ctx context.Context, v beam.V, emit func(beam.V)) { // count the elements fn.counter.Inc(ctx, 1) emit(v) }
느리게 실행되는 파이프라인 또는 출력 없음 문제 해결
느린 작업과 중단된 작업 문제 해결을 참조하세요.
일반적인 오류와 조치 방법
파이프라인 오류의 원인이 되는 오류를 알고 있는 경우 Dataflow 오류 문제 해결 페이지에서 오류 문제 해결 안내를 참조하세요.