Para parar uma tarefa do Dataflow, use a Google Cloud consola, o Cloud Shell, um terminal local instalado com a Google Cloud CLI ou a API REST do Dataflow.
Pode parar uma tarefa do Dataflow de uma das seguintes três formas:
Cancele uma tarefa. Este método aplica-se a pipelines de streaming e pipelines de processamento em lote. O cancelamento de uma tarefa impede que o serviço Dataflow processe quaisquer dados, incluindo dados em buffer. Para mais informações, consulte o artigo Cancele uma tarefa.
Drenar um trabalho. Este método aplica-se apenas a pipelines de streaming. A drenagem de uma tarefa permite que o serviço Dataflow termine o processamento dos dados em buffer, ao mesmo tempo que cessa a ingestão de novos dados. Para mais informações, consulte o artigo Desativar uma tarefa.
Forçar o cancelamento de uma tarefa. Este método aplica-se a pipelines de streaming e pipelines de processamento em lote. A anulação forçada de uma tarefa impede imediatamente o serviço Dataflow de processar quaisquer dados, incluindo dados em buffer. Antes de forçar o cancelamento, tem de tentar primeiro um cancelamento normal. O cancelamento forçado destina-se apenas a tarefas que ficaram bloqueadas no processo de cancelamento normal. Para mais informações, consulte o artigo Force o cancelamento de uma tarefa.
Quando cancela uma tarefa, não a pode reiniciar. Se não estiver a usar modelos flexíveis, pode clonar o pipeline cancelado e iniciar uma nova tarefa a partir do pipeline clonado.
Antes de parar um pipeline de streaming, considere criar uma captura instantânea da tarefa. As imagens instantâneas do fluxo de dados guardam o estado de um pipeline de streaming, para que possa iniciar uma nova versão da tarefa do Dataflow sem perder o estado. Para saber mais, consulte o artigo Usar instantâneos do Dataflow.
Se tiver um pipeline complexo, pondere criar um modelo e executar a tarefa a partir do modelo.
Não pode eliminar tarefas do Dataflow, mas pode arquivar tarefas concluídas. Todos os trabalhos concluídos, incluindo os trabalhos na lista de trabalhos arquivados, são eliminados após um período de retenção de 30 dias.
Cancele uma tarefa do Dataflow
Quando cancela uma tarefa, o serviço Dataflow para a tarefa imediatamente.
As seguintes ações ocorrem quando cancela uma tarefa:
O serviço Dataflow interrompe todo o carregamento e processamento de dados.
O serviço Dataflow começa a limpar os recursos da Google Cloud Platform associados à sua tarefa.
Estes recursos podem incluir o encerramento de instâncias de trabalho do Compute Engine e o fecho de ligações ativas a origens ou destinos de E/S.
Informações importantes sobre o cancelamento de uma tarefa
O cancelamento de um trabalho interrompe imediatamente o processamento do pipeline.
Pode perder dados em curso quando cancela uma tarefa. Os dados em trânsito referem-se aos dados que já foram lidos, mas que ainda estão a ser processados pelo pipeline.
Os dados escritos do pipeline para um destino de saída antes de cancelar a tarefa podem continuar acessíveis no destino de saída.
Se a perda de dados não for um problema, o cancelamento do trabalho garante que os Google Cloud recursos associados ao trabalho são encerrados assim que possível.
Desative uma tarefa do Dataflow
Quando esgota uma tarefa, o serviço Dataflow termina a tarefa no estado atual. Se quiser evitar a perda de dados à medida que desativa os pipelines de streaming, a melhor opção é esvaziar a tarefa.
As seguintes ações ocorrem quando esgota um trabalho:
A tarefa deixa de carregar novos dados das origens de entrada pouco depois de receber o pedido de eliminação (normalmente, no prazo de alguns minutos).
O serviço Dataflow preserva todos os recursos existentes, como instâncias de trabalhadores, para concluir o processamento e a gravação de todos os dados em buffer no seu pipeline.
Quando todas as operações de processamento e escrita pendentes estiverem concluídas, o serviço Dataflow encerra os Google Cloud recursos Google Cloud associados à sua tarefa.
Para esgotar o seu trabalho, o Dataflow deixa de ler novas entradas, marca a origem com uma data/hora do evento no infinito e, em seguida, propaga as datas/horas no infinito através do pipeline. Por conseguinte, os pipelines em processo de esgotamento podem ter uma marca de água infinita.
Informações importantes sobre a anulação de um trabalho
A eliminação de uma tarefa não é suportada para pipelines em lote.
O pipeline continua a incorrer no custo de manutenção de todos os recursosGoogle Cloud associados até que todo o processamento e escrita estejam concluídos.
Pode atualizar um pipeline que esteja a ser esvaziado. Se o pipeline estiver bloqueado, a atualização do pipeline com código que corrige o erro que está a criar o problema permite uma drenagem bem-sucedida sem perda de dados.
Pode cancelar uma tarefa que esteja atualmente a consumir recursos.
A conclusão da anulação de um trabalho pode demorar bastante tempo, por exemplo, quando o pipeline tem uma grande quantidade de dados em buffer.
Se o pipeline de streaming incluir um Splittable DoFn, tem de truncar o resultado antes de executar a opção de esgotamento. Para mais informações sobre a truncagem de DoFns divisíveis, consulte a documentação do Apache Beam.
Em alguns casos, uma tarefa do Dataflow pode não conseguir concluir a operação de drenagem. Pode consultar os registos de tarefas para determinar a causa principal e tomar as medidas adequadas.
Retenção de dados
O streaming do Dataflow é tolerante ao reinício dos trabalhadores e não falha nas tarefas de streaming quando ocorrem erros. Em alternativa, o serviço Dataflow tenta novamente até que tome uma medida, como cancelar ou reiniciar a tarefa. Quando esgota o trabalho, o Dataflow continua a tentar novamente, o que pode levar a pipelines bloqueados. Nesta situação, para ativar uma drenagem bem-sucedida sem perda de dados, atualize o pipeline com código que corrija o erro que está a criar o problema.
O Dataflow não confirma as mensagens até que o serviço Dataflow as confirme de forma duradoura. Por exemplo, com o Kafka, pode ver este processo como uma transferência segura da propriedade da mensagem do Kafka para o Dataflow, eliminando o risco de perda de dados.
Tarefas bloqueadas
- A eliminação não corrige pipelines bloqueados. Se a movimentação de dados estiver bloqueada, o pipeline permanece bloqueado após o comando de esvaziamento. Para resolver um pipeline bloqueado, use o comando update para atualizar o pipeline com código que resolva o erro que está a criar o problema. Também pode cancelar trabalhos bloqueados, mas o cancelamento de trabalhos pode resultar na perda de dados.
Temporizadores
Se o código do pipeline de streaming incluir um temporizador de ciclo, a tarefa pode ser lenta ou não conseguir esgotar os dados. Uma vez que a anulação não termina até todos os temporizadores serem concluídos, os pipelines com temporizadores de ciclo infinito nunca terminam a anulação.
O Dataflow aguarda até que todos os temporizadores de tempo de processamento sejam concluídos, em vez de os acionar imediatamente, o que pode resultar em esgotamentos lentos.
Efeitos da eliminação de uma tarefa
Quando esgota um pipeline de streaming, o Dataflow fecha imediatamente todas as janelas em processamento e aciona todos os acionadores.
O sistema não aguarda que as janelas baseadas no tempo pendentes terminem numa operação de esgotamento.
Por exemplo, se o pipeline estiver a dez minutos de uma janela de duas horas quando esvazia a tarefa, o Dataflow não aguarda que o resto da janela termine. Fecha a janela imediatamente com resultados parciais. O fluxo de dados faz com que as janelas abertas sejam fechadas ao avançar a marca d'água de dados para o infinito. Esta funcionalidade também funciona com origens de dados personalizadas.
Quando esgota um pipeline que usa uma classe de origem de dados personalizada, o Dataflow deixa de emitir pedidos de novos dados, avança a marca
d'água de dados para o infinito e chama o método finalize() da sua origem no último
ponto de verificação.
O esvaziamento pode resultar em janelas parcialmente preenchidas. Nesse caso, se reiniciar o pipeline esgotado, a mesma janela pode ser acionada uma segunda vez, o que pode causar problemas com os seus dados. Por exemplo, no cenário seguinte, os ficheiros podem ter nomes em conflito e os dados podem ser substituídos:
Se esgotar um pipeline com janelas por hora às 12:34, a janela das 12:00 às 13:00 fecha-se apenas com os dados acionados nos primeiros 34 minutos da janela. O pipeline não lê novos dados após as 12:34.
Se, em seguida, reiniciar imediatamente o pipeline, a janela das 12:00 às 13:00 é acionada novamente, mas apenas com os dados que foram lidos das 12:35 às 13:00. Não são enviados duplicados, mas, se um nome de ficheiro for repetido, os dados são substituídos.
Na Google Cloud consola, pode ver os detalhes das transformações do seu pipeline. O diagrama seguinte mostra os efeitos de uma operação de esgotamento em curso. Tenha em atenção que a marca de água é avançada para o valor máximo.
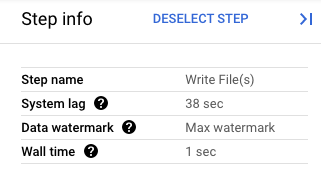
Figura 1. Uma vista de passos de uma operação de drenagem.
Force o cancelamento de uma tarefa do Dataflow
Use o cancelamento forçado apenas quando não conseguir cancelar a tarefa através de outros métodos. O cancelamento forçado termina a tarefa sem limpar todos os recursos. Se usar o cancelamento forçado repetidamente, os recursos com fugas podem acumular-se e usar a sua quota.
Quando força o cancelamento de uma tarefa, o serviço Dataflow para a tarefa imediatamente, o que provoca fugas de todas as VMs criadas pela tarefa do Dataflow. A anulação normal tem de ser tentada, pelo menos, 30 minutos antes da anulação forçada.
As seguintes ações ocorrem quando força o cancelamento de uma tarefa:
- O serviço Dataflow interrompe todo o carregamento e processamento de dados.
Informações importantes sobre o cancelamento forçado de uma tarefa
O cancelamento forçado de um trabalho interrompe imediatamente o processamento do pipeline.
O cancelamento forçado de um trabalho destina-se apenas a trabalhos que ficaram bloqueados no processo de cancelamento normal.
As instâncias de trabalho criadas pela tarefa do Dataflow não são necessariamente libertadas, o que pode resultar em instâncias de trabalho com fugas. As instâncias de trabalhadores com fugas não contribuem para os custos das tarefas, mas podem usar a sua quota. Após a conclusão do cancelamento da tarefa, pode eliminar estes recursos.
Para tarefas do Dataflow Prime, não pode ver nem eliminar as VMs com fugas. Na maioria dos casos, estas VMs não criam problemas. No entanto, se as VMs com fugas causarem problemas, como o consumo da sua quota de VMs, contacte o apoio técnico.
Pare uma tarefa do Dataflow
Antes de parar uma tarefa, tem de compreender os efeitos do cancelamento, da drenagem ou do cancelamento forçado de uma tarefa.
Consola
Aceda à página Tarefas do fluxo de dados.
Clique na tarefa que quer parar.
Para parar uma tarefa, o respetivo estado tem de ser em execução.
Na página de detalhes da tarefa, clique em Parar.
Efetue um dos seguintes passos:
Para um pipeline em lote, clique em Cancelar ou Forçar cancelamento.
Para um pipeline de streaming, clique em Cancelar, Drenar ou Forçar cancelamento.
Para confirmar a sua escolha, clique em Parar tarefa.
gcloud
Para esgotar ou cancelar uma tarefa do Dataflow,
pode usar o comando gcloud dataflow jobs
na Cloud Shell ou num terminal local instalado com a CLI gcloud.
Inicie sessão na shell.
Indique os IDs das tarefas do Dataflow que estão a ser executadas atualmente e, de seguida, anote o ID da tarefa que quer parar:
gcloud dataflow jobs listSe a flag
--regionnão estiver definida, são apresentados os trabalhos do Dataflow de todas as regiões disponíveis.Efetue um dos seguintes passos:
Para esgotar uma tarefa de streaming:
gcloud dataflow jobs drain JOB_IDSubstitua
JOB_IDpelo ID da tarefa que copiou anteriormente.Para cancelar uma tarefa de streaming ou em lote:
gcloud dataflow jobs cancel JOB_IDSubstitua
JOB_IDpelo ID da tarefa que copiou anteriormente.Para forçar o cancelamento de um trabalho em lote ou de streaming:
gcloud dataflow jobs cancel JOB_ID --forceSubstitua
JOB_IDpelo ID da tarefa que copiou anteriormente.
API
Para cancelar ou esgotar uma tarefa através da
API REST Dataflow,
pode escolher
projects.locations.jobs.update
ou projects.jobs.update.
No corpo do pedido,
transmita o estado da tarefa necessário
no campo requestedState da instância da tarefa da API escolhida.
Importante: é recomendável usar projects.locations.jobs.update, uma vez que projects.jobs.update só permite atualizar o estado das tarefas em execução no us-central1.
Para cancelar a tarefa, defina o estado da tarefa como
JOB_STATE_CANCELLED.Para esgotar a tarefa, defina o estado da tarefa como
JOB_STATE_DRAINED.Para forçar o cancelamento da tarefa, defina o estado da tarefa como
JOB_STATE_CANCELLEDcom a etiqueta"force_cancel_job": "true". O corpo do pedido é:{ "requestedState": "JOB_STATE_CANCELLED", "labels": { "force_cancel_job": "true" } }
Detete a conclusão de tarefas do Dataflow
Para detetar quando o cancelamento ou a drenagem da tarefa estiver concluído, use um dos seguintes métodos:
- Use um serviço de orquestração de fluxo de trabalho, como o Cloud Composer para monitorizar a tarefa do Dataflow.
- Execute o pipeline de forma síncrona para que as tarefas sejam bloqueadas até à conclusão do pipeline. Para mais informações, consulte Controlar os modos de execução em Definir opções de pipeline.
Use a ferramenta de linha de comandos na CLI Google Cloud para sondar o estado da tarefa. Para ver uma lista de todas as tarefas do Dataflow no seu projeto, execute o seguinte comando na shell ou no terminal:
gcloud dataflow jobs listO resultado mostra o ID, o nome, o estado (
STATE) e outras informações de cada tarefa. Para mais informações, consulte o artigo Use a CLI do Google Cloud para listar tarefas.
Arquive tarefas do Dataflow concluídas
Quando arquiva uma tarefa do Dataflow, esta é removida da lista de tarefas na página Tarefas do Dataflow na consola. O trabalho é movido para uma lista de trabalhos arquivados. Só pode arquivar tarefas concluídas, o que inclui tarefas nos seguintes estados:
JOB_STATE_CANCELLEDJOB_STATE_DRAINEDJOB_STATE_DONEJOB_STATE_FAILEDJOB_STATE_UPDATED
Para mais informações sobre a validação destes estados, consulte o artigo Detetar a conclusão da tarefa do Dataflow.
Para obter informações de resolução de problemas quando está a arquivar tarefas, consulte o artigo Erros de arquivo de tarefas em "Resolva problemas do Dataflow".
Todas as tarefas arquivadas são eliminadas após um período de retenção de 30 dias.
Arquive um trabalho
Siga estes passos para remover um trabalho concluído da lista de trabalhos principal na página Trabalhos do Dataflow.
Consola
Na Google Cloud consola, aceda à página Tarefas do Dataflow.
É apresentada uma lista de tarefas do Dataflow juntamente com o respetivo estado.
Selecione uma tarefa.
Na página Detalhes da tarefa, clique em Arquivar. Se o trabalho não tiver sido concluído, a opção Arquivar não está disponível.
REST
Para arquivar uma tarefa através da API, use o método
projects.locations.jobs.update.
Neste pedido, tem de especificar um objeto JobMetadata atualizado. No objeto JobMetadata.userDisplayProperties, use o par chave-valor "archived":"true".
Além do objeto JobMetadata atualizado, o seu pedido API também tem de incluir o parâmetro de consulta updateMask no URL do pedido:
https://dataflow.googleapis.com/v1b3/[...]/jobs/JOB_ID/?updateMask=job_metadata.user_display_properties.archived
Antes de usar qualquer um dos dados do pedido, faça as seguintes substituições:
- PROJECT_ID: o ID do seu projeto
- REGION: uma região do Dataflow
- JOB_ID: o ID da sua tarefa do Dataflow
Método HTTP e URL:
PUT https://dataflow.googleapis.com/v1b3/projects/PROJECT_ID/locations/REGION/jobs/JOB_ID/?updateMask=job_metadata.user_display_properties.archived
Corpo JSON do pedido:
{
"job_metadata": {
"userDisplayProperties": {
"archived": "true"
}
}
}
Para enviar o seu pedido, escolha uma destas opções:
curl
Guarde o corpo do pedido num ficheiro com o nome request.json,
e execute o seguinte comando:
curl -X PUT \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://dataflow.googleapis.com/v1b3/projects/PROJECT_ID/locations/REGION/jobs/JOB_ID/?updateMask=job_metadata.user_display_properties.archived"
PowerShell
Guarde o corpo do pedido num ficheiro com o nome request.json,
e execute o seguinte comando:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method PUT `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://dataflow.googleapis.com/v1b3/projects/PROJECT_ID/locations/REGION/jobs/JOB_ID/?updateMask=job_metadata.user_display_properties.archived" | Select-Object -Expand Content
Deve receber uma resposta JSON semelhante à seguinte:
{
"id": "JOB_ID",
"projectId": "PROJECT_ID",
"currentState": "JOB_STATE_DONE",
"currentStateTime": "2025-05-20T20:54:41.651442Z",
"createTime": "2025-05-20T20:51:06.031248Z",
"jobMetadata": {
"userDisplayProperties": {
"archived": "true"
}
},
"startTime": "2025-05-20T20:51:06.031248Z"
}
gcloud
Este comando arquiva uma única tarefa. A tarefa tem de estar num estado terminal para poder arquivá-la. Caso contrário, o pedido é rejeitado. Depois de enviar o comando, tem de confirmar que quer executá-lo.
Antes de usar qualquer um dos dados de comandos abaixo, faça as seguintes substituições:
JOB_ID: o ID da tarefa do Dataflow que quer arquivar.REGION: opcional. A região do Dataflow da sua tarefa.
Execute o seguinte comando:
Linux, macOS ou Cloud Shell
gcloud dataflow jobs archive JOB_ID --region=REGION_ID
Windows (PowerShell)
gcloud dataflow jobs archive JOB_ID --region=REGION_ID
Windows (cmd.exe)
gcloud dataflow jobs archive JOB_ID --region=REGION_ID
Deve receber uma resposta semelhante à seguinte:
Archived job [JOB_ID].
createTime: '2025-06-29T11:00:02.432552Z'
currentState: JOB_STATE_DONE
currentStateTime: '2025-06-29T11:04:25.125921Z'
id: JOB_ID
jobMetadata:
userDisplayProperties:
archived: 'true'
projectId: PROJECT_ID
startTime: '2025-06-29T11:00:02.432552Z'
Veja e restaure trabalhos arquivados
Siga estes passos para ver trabalhos arquivados ou restaurar trabalhos arquivados para a lista de trabalhos principal na página Trabalhos do Dataflow.
Consola
Na Google Cloud consola, aceda à página Tarefas do Dataflow.
Clique no botão ativar/desativar Arquivado. É apresentada uma lista de tarefas do Dataflow arquivadas.
Selecione uma tarefa.
Para restaurar a tarefa para a lista de tarefas principal na página Tarefas do Dataflow, na página Detalhes da tarefa, clique em Restaurar.
REST
Para restaurar uma tarefa arquivada através da API, use o método
projects.locations.jobs.update.
Neste pedido, tem de especificar um objeto JobMetadata atualizado. No objeto JobMetadata.userDisplayProperties, use o par de chave-valor "archived":"false".
Além do objeto JobMetadata atualizado, o seu pedido API também tem de incluir o parâmetro de consulta updateMask no URL do pedido:
https://dataflow.googleapis.com/v1b3/[...]/jobs/JOB_ID/?updateMask=job_metadata.user_display_properties.archived
Antes de usar qualquer um dos dados do pedido, faça as seguintes substituições:
- PROJECT_ID: o ID do seu projeto
- REGION: uma região do Dataflow
- JOB_ID: o ID da sua tarefa do Dataflow
Método HTTP e URL:
PUT https://dataflow.googleapis.com/v1b3/projects/PROJECT_ID/locations/REGION/jobs/JOB_ID/?updateMask=job_metadata.user_display_properties.archived
Corpo JSON do pedido:
{
"job_metadata": {
"userDisplayProperties": {
"archived": "false"
}
}
}
Para enviar o seu pedido, escolha uma destas opções:
curl
Guarde o corpo do pedido num ficheiro com o nome request.json,
e execute o seguinte comando:
curl -X PUT \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://dataflow.googleapis.com/v1b3/projects/PROJECT_ID/locations/REGION/jobs/JOB_ID/?updateMask=job_metadata.user_display_properties.archived"
PowerShell
Guarde o corpo do pedido num ficheiro com o nome request.json,
e execute o seguinte comando:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method PUT `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://dataflow.googleapis.com/v1b3/projects/PROJECT_ID/locations/REGION/jobs/JOB_ID/?updateMask=job_metadata.user_display_properties.archived" | Select-Object -Expand Content
Deve receber uma resposta JSON semelhante à seguinte:
{
"id": "JOB_ID",
"projectId": "PROJECT_ID",
"currentState": "JOB_STATE_DONE",
"currentStateTime": "2025-05-20T20:54:41.651442Z",
"createTime": "2025-05-20T20:51:06.031248Z",
"jobMetadata": {
"userDisplayProperties": {
"archived": "false"
}
},
"startTime": "2025-05-20T20:51:06.031248Z"
}
O que se segue?
- Explore a API REST do Dataflow.
- Explore a interface de monitorização do Dataflow na Google Cloud consola.
- Saiba como atualizar um pipeline.