Zum Beenden eines Dataflow-Jobs können Sie entweder die Google Cloud Console, Cloud Shell, ein lokales Terminal, das mit der Google Cloud CLI installiert wurde, oder die Dataflow REST API verwenden.
Sie haben drei Möglichkeiten, einen Dataflow-Job anzuhalten:
Job abbrechen. Diese Methode gilt sowohl für Streaming- als auch für Batchpipelines. Das Abbrechen eines Jobs hindert den Dataflow-Dienst an der Verarbeitung von Daten, einschließlich zwischengespeicherter Daten. Weitere Informationen finden Sie unter Job abbrechen.
Job per Drain beenden. Diese Methode gilt nur für Streamingpipelines. Durch das Beenden des Jobs per Drain kann der Dataflow-Dienst die Verarbeitung der zwischengespeicherten Daten abschließen und gleichzeitig die Aufnahme neuer Daten einstellen. Weitere Informationen finden Sie unter Job per Drain beenden.
Abbrechen eines Jobs erzwingen. Diese Methode gilt sowohl für Streaming- als auch für Batchpipelines. Durch das erzwungene Abbrechen eines Jobs wird die Verarbeitung von Daten, einschließlich der zwischengespeicherten Daten, durch den Dataflow-Dienst sofort gestoppt. Bevor Sie das Abbrechen erzwingen, müssen Sie zuerst einen regulären Abbruch durchführen. Das erzwungene Abbrechen ist nur für Jobs vorgesehen, die beim regulären Abbruchvorgang hängen geblieben sind. Weitere Informationen erhalten Sie auch unter Abbrechen von Job erzwingen.
Wenn Sie einen Job abbrechen, können Sie ihn nicht neu starten. Wenn Sie keine flexiblen Vorlagen verwenden, können Sie die abgebrochene Pipeline klonen und einen neuen Job aus der geklonten Pipeline starten.
Bevor Sie eine Streamingpipeline beenden, sollten Sie einen Snapshot des Jobs erstellen. Dataflow-Snapshots speichern den Status einer Streamingpipeline, sodass Sie eine neue Version Ihres Dataflow-Jobs starten können, ohne den Status zu verlieren. Weitere Informationen finden Sie unter Dataflow-Snapshots verwenden.
Wenn Sie eine komplexe Pipeline haben, können Sie eine Vorlage erstellen und den Job aus der Vorlage ausführen.
Sie können keine Dataflow-Jobs löschen, aber abgeschlossene Jobs archivieren. Alle abgeschlossenen Jobs, einschließlich der Jobs in der Liste der archivierten Jobs, werden nach einer Aufbewahrungsdauer von 30 Tagen gelöscht.
Dataflow-Job abbrechen
Wenn Sie einen Job abbrechen, beendet der Dataflow-Dienst den Job sofort.
Die folgenden Aktionen werden ausgeführt, wenn Sie einen Job abbrechen:
Der Dataflow-Dienst hält die gesamte Datenaufnahme und -verarbeitung an.
Der Dataflow-Dienst beginnt mit der Bereinigung der Google Cloud-Ressourcen, die mit dem Job verknüpft sind.
Dies kann auch beinhalten, dass Compute Engine-Worker-Instanzen heruntergefahren und aktive Verbindungen zu E/A-Quellen oder -Senken getrennt werden.
Wichtige Informationen zum Abbrechen eines Jobs
Das Abbrechen eines Jobs stoppt die Verarbeitung der Pipeline sofort.
Sie können In-Flight-Daten verlieren, wenn Sie einen Job abbrechen. In-Flight-Daten beziehen sich auf Daten, die bereits gelesen wurden, aber noch von der Pipeline verarbeitet werden.
Daten, die von der Pipeline in eine Ausgabesenke geschrieben werden, bevor Sie den Job abgebrochen haben, können dort gegebenenfalls noch zugänglich sein.
Wenn der Datenverlust kein Problem darstellt, wird durch das Abbrechen des Jobs sichergestellt, dass die mit Ihrem Job verknüpften Google Cloud-Ressourcen so schnell wie möglich heruntergefahren werden.
Dataflow-Job per Drain beenden
Wenn Sie einen Job per Drain beenden, beendet der Dataflow-Dienst den Job in seinem aktuellen Zustand. Wenn Sie Datenverluste beim Herunterfahren Ihrer Streamingpipelines vermeiden möchten, empfiehlt es sich, den Job per Drain zu beenden.
Die folgenden Aktionen werden ausgeführt, wenn Sie einen Job per Drain beenden:
Ihr Job beendet die Aufnahme neuer Daten aus den Eingabequellen, kurz nachdem die Anfrage für einen Drain eingegangen ist. Dies geschieht in der Regel innerhalb weniger Minuten.
Sämtliche vorhandenen Ressourcen, z. B. Worker-Instanzen, werden vom Dataflow-Dienst aufrechterhalten, damit die Verarbeitung und das Schreiben von zwischengespeicherten Daten in der Pipeline abgeschlossen werden können.
Wenn alle ausstehenden Verarbeitungs- und Schreibvorgänge abgeschlossen sind, fährt der Dataflow-Dienst Google Cloud-Ressourcen herunter, die Ihrem Job zugeordnet sind.
Um den Job per Drain zu beenden, beendet Dataflow das Lesen neuer Eingaben, markiert die Quelle mit einem Ereignis-Zeitstempel im Unendlichen und leitet dann unendliche Zeitstempel über die Pipeline weiter. Daher kann der Verbindungsausgleich bei Pipelines unendlich viele Wasserzeichen haben.
Wichtige Informationen zum Beenden eines Jobs per Drain
Das Beenden eines Jobs per Drain wird für Batchpipelines nicht unterstützt.
Für Ihre Pipeline fallen weiterhin Kosten für die Aufrechterhaltung aller zugehörigen Google Cloud-Ressourcen an, bis alle Verarbeitungs- und Schreibvorgänge abgeschlossen sind.
Sie können eine Pipeline, die per Drain beendet wird, aktualisieren. Wenn Ihre Pipeline hängen bleibt, aktiviert die Aktualisierung der Pipeline mit dem Code, der den Fehler behebt, der das Problem verursacht, eine erfolgreiche Beendigung per Drain ohne Datenverlust.
Sie können einen Job abbrechen, der gerade per Drain beendet wird.
Das Beenden eines Jobs per Drain kann einige Zeit in Anspruch nehmen, etwa wenn in der Pipeline viele zwischengespeicherte Daten enthalten sind.
Wenn Ihre Streaming-Pipeline eine Splittable DoFn enthält, müssen Sie das Ergebnis kürzen, bevor Sie die Drain-Option ausführen. Weitere Informationen zum Kürzen von Splittable DoFns finden Sie in der Apache Beam-Dokumentation.
In einigen Fällen kann ein Dataflow-Job den Drain-Vorgang möglicherweise nicht abschließen. In den Joblogs können Sie die Ursache ermitteln und entsprechende Maßnahmen ergreifen.
Datenaufbewahrung
Dataflow-Streaming ist tolerant gegenüber Worker-Neustarts und schlägt bei Streaming-Jobs nicht fehl. Stattdessen wird der Dataflow-Dienst den Vorgang wiederholen, bis Sie eine Maßnahme wie das Abbrechen oder Neustarten des Jobs ergreifen. Wenn Sie den Job per Drain beenden, setzt Dataflow den Vorgang fort, was zu hängen gebliebenen Pipelines führen kann. Aktualisieren Sie die Pipeline in diesem Fall mit Code, der den Fehler behebt, der das Problem verursacht, um eine erfolgreiche Beendigung per Drain ohne Datenverlust zu ermöglichen.
Dataflow bestätigt Nachrichten erst, wenn der Dataflow-Dienst sie dauerhaft festschreibt. Mit Kafka können Sie beispielsweise diesen Prozess als sichere Übergabe der Inhaberschaft an der Nachricht von Kafka an Dataflow ansehen, wodurch das Risiko eines Datenverlusts ausgeschlossen wird.
Festhängende Jobs
- Durch Draining werden hängende Pipelines nicht behoben. Wenn die Datenverschiebung blockiert wird, bleibt die Pipeline nach dem Drain-Befehl hängen. Verwenden Sie zum Beheben einer hängenden Pipeline den Befehl update, um die Pipeline mit Code zu aktualisieren, der den Fehler behebt, der das Problem verursacht. Sie können hängende Jobs auch abbrechen. Allerdings kann das Abbrechen von Daten zu Datenverlust führen.
Timer
Wenn Ihr Streaming-Pipelinecode einen Looping-Timer enthält, wird der Job möglicherweise langsam oder nicht per Drain beendet. Da das Draining nicht beendet wird, bevor alle Timer abgeschlossen sind, beenden Pipelines mit Endlosschleifen-Timern nie das Draining.
Dataflow wartet, bis alle Verarbeitungszeit-Timer abgeschlossen sind, anstatt sie sofort zu auslösen. Dies kann zu langsamen Drains führen.
Auswirkungen des Drain-Befehls auf einen Job
Wenn Sie eine Streaming-Pipeline per Drain beenden, schließt Dataflow sofort alle Fenster, die sich in der Verarbeitung befinden, und löst alle Trigger aus.
Das System wartet nicht, bis ausstehende zeitbasierte Fenster in einem Drain-Vorgang beendet werden.
Wenn Ihre Pipeline z. B. zehn Minuten in einem zweistündigen Fenster liegt, wenn Sie den Job per Drain beenden, wartet Dataflow nicht, bis der Rest des Fensters durchlaufen wurde. Das Fenster wird sofort mit Teilergebnissen geschlossen. Dataflow veranlasst, dass offene Fenster geschlossen werden, indem es das Datenwasserzeichen ins Unendliche verschiebt. Diese Funktion kann auch auf benutzerdefinierte Datenquellen angewendet werden.
Wenn Sie eine Pipeline mit einer benutzerdefinierten Datenquellklasse per Drain beenden, stoppt Dataflow das Senden von Anfragen für neue Daten, verschiebt das Datenwasserzeichen ins Unendliche und ruft die Methode finalize() Ihrer Quelle am letzten Prüfpunkt auf.
Das Draining kann zu teilweise gefüllten Fenstern führen. Wenn Sie die geleerte Pipeline in diesem Fall neu starten, wird möglicherweise dasselbe Fenster ein zweites Mal ausgelöst, was zu Problemen mit Ihren Daten führen kann. Im folgenden Szenario können die Dateien beispielsweise widersprüchliche Namen haben und Daten können überschrieben werden:
Wenn Sie eine Pipeline mit stündlichem Windowing um 12:34 Uhr per Drain beenden, wird das Fenster von 12:00 Uhr bis 13:00 Uhr nur mit den Daten geschlossen, die innerhalb der ersten 34 Minuten des Fensters ausgelöst wurden. Die Pipeline liest nach 12:34 Uhr keine neuen Daten mehr.
Wenn Sie die Pipeline dann sofort neu starten, wird das Fenster von 12:00 Uhr bis 13:00 Uhr noch einmal ausgelöst. Dabei werden nur die Daten von 12:35 Uhr bis 13:00 Uhr angezeigt. Es werden keine Duplikate gesendet, aber wenn ein Dateiname wiederholt wird, werden die Daten überschrieben.
In der Google Cloud Console können Sie sich Details zu den Transformationen Ihrer Pipeline ansehen. Das folgende Diagramm zeigt die Auswirkungen eines Prozess-Drain-Vorgangs. Beachten Sie, dass das Wasserzeichen auf den Höchstwert gesetzt wird.
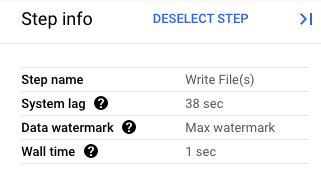
Abbildung 1. Eine Schrittansicht eines Drain-Vorgangs
Abbrechen eines Dataflow-Jobs erzwingen
Verwenden Sie das erzwungene Abbrechen nur, wenn Sie den Job nicht mit anderen Methoden abbrechen können. Durch das erzwungene Abbrechen wird der Job beendet, ohne alle Ressourcen zu bereinigen. Wenn Sie „Abbrechen“ wiederholt anwenden, können sich gehackte Ressourcen ansammeln, und gehackte Ressourcen verbrauchen Ihr Kontingent.
Wenn Sie das Abbrechen eines Jobs erzwingen, stoppt der Dataflow-Dienst den Job sofort und leakt alle vom Dataflow-Job erstellten VMs. Der reguläre Abbruch muss mindestens 30 Minuten vor dem erzwungenen Abbruch erfolgen.
Die folgenden Aktionen werden ausgeführt, wenn Sie das Abbrechen eines Jobs erzwingen:
- Der Dataflow-Dienst hält die gesamte Datenaufnahme und -verarbeitung an.
Wichtige Informationen zum erzwungenen Abbrechen eines Jobs
Das erzwungene Abbrechen eines Jobs stoppt die Verarbeitung der Pipeline sofort.
Das erzwungene Abbrechen eines Jobs ist nur für Jobs gedacht, die beim regulären Abbruchprozess hängen geblieben sind.
Alle vom Dataflow-Job erstellten Worker-Instanzen werden nicht unbedingt freigegeben, was zu geleakten Worker-Instanzen führen kann. Gehackte Worker-Instanzen tragen nicht zu den Jobkosten bei, verwenden aber möglicherweise Ihr Kontingent. Nachdem der Job abgebrochen wurde, können Sie diese Ressourcen löschen.
Bei Dataflow Prime-Jobs können Sie die gehackten VMs nicht sehen oder löschen. In den meisten Fällen verursachen diese VMs keine Probleme. Wenn die gehackten VMs jedoch Probleme verursachen, z. B. die Nutzung Ihres VM-Kontingents, wenden Sie sich an den Support.
Dataflow-Job beenden
Bevor Sie einen Job anhalten, müssen Sie sich mit den Auswirkungen des Abbrechens, Drainings oder erzwungenen Abbrechens eines Jobs vertraut machen.
Console
Rufen Sie die Dataflow-Seite Jobs auf.
Klicken Sie auf den Job, den Sie beenden möchten.
Zum Beeinden eines Jobs muss der Status des Jobs Wird ausgeführt sein.
Klicken Sie auf der Seite mit den Jobdetails auf Beenden.
Führen Sie einen der folgenden Schritte aus:
Klicken Sie für eine Batchpipeline auf Abbrechen oder Abbrechen erzwingen.
Klicken Sie für eine Streaming-Pipeline entweder auf Abbrechen, Per Drain beenden oder Abbrechen erzwingen.
Klicken Sie auf Job anhalten, um die Auswahl zu bestätigen.
gcloud
Um einen Dataflow-Job entweder per Drain zu beenden oder abzubrechen, können Sie den Befehl gcloud dataflow jobs in Cloud Shell oder dem lokalen Terminal, das mit der gcloud CLI installiert wird, verwenden.
Melden Sie sich in der Shell an.
Listen Sie die Job-IDs der Dataflow-Jobs auf, die derzeit ausgeführt werden, und notieren Sie sich die Job-ID des Jobs, den Sie beenden möchten:
gcloud dataflow jobs listWenn das Flag
--regionnicht gesetzt ist, werden Dataflow-Jobs aus allen verfügbaren Regionen angezeigt.Führen Sie einen der folgenden Schritte aus:
So beenden Sie einen Streamingjob per Drain:
gcloud dataflow jobs drain JOB_IDErsetzen Sie
JOB_IDdurch die zuvor kopierte Job-ID.So brechen Sie einen Batch- oder Streamingjob ab:
gcloud dataflow jobs cancel JOB_IDErsetzen Sie
JOB_IDdurch die zuvor kopierte Job-ID.So brechen Sie einen Batch- oder Streamingjob ab:
gcloud dataflow jobs cancel JOB_ID --forceErsetzen Sie
JOB_IDdurch die zuvor kopierte Job-ID.
API
Zum Abbrechen eines Jobs oder Beenden eines Jobs per Drain mit der Dataflow REST API können Sie entweder projects.locations.jobs.update oder projects.jobs.update auswählen.
Übergeben Sie im Anfragetext den erforderlichen Jobstatus im Feld requestedState der Jobinstanz der ausgewählten API.
Wichtig: Das Verwenden von projects.locations.jobs.update wird empfohlen, da projects.jobs.update nur die Aktualisierung des Status von Jobs zulässt, die in us-central1 ausgeführt werden.
Wenn Sie den Job abbrechen möchten, setzen Sie den Jobstatus auf
JOB_STATE_CANCELLED.Wenn Sie den Job per Drain beenden möchten, setzen Sie den Jobstatus auf
JOB_STATE_DRAINED.Wenn Sie das Abbrechen des Jobs erzwingen möchten, legen Sie den Jobzustand auf
JOB_STATE_CANCELLEDmit dem Label"force_cancel_job": "true"fest. Der Anfragetext lautet:{ "requestedState": "JOB_STATE_CANCELLED", "labels": { "force_cancel_job": "true" } }
Abschluss eines Dataflow-Jobs erkennen
Mit einer der folgenden Methoden können Sie erkennen, wenn der Job abgebrochen oder per Drain beendet wurde:
- Verwenden Sie einen Workflow-Orchestrierungsdienst wie Cloud Composer, um Ihren Dataflow-Job zu überwachen,
- Führen Sie die Pipeline synchron aus, damit Aufgaben bis zum Abschluss der Pipeline blockiert werden. Weitere Informationen finden Sie unter Ausführungsmodi steuern in „Pipelineoptionen festlegen”.
Verwenden Sie das Befehlszeilentool in der Google Cloud CLI, um den Jobstatus abzufragen. Führen Sie folgenden Befehl in der Shell oder im Terminal aus, um eine Liste aller Dataflow-Jobs in Ihrem Projekt abzurufen:
gcloud dataflow jobs listDie Ausgabe zeigt die Job-ID, den Namen, den Status (
STATE) und andere Informationen zu jedem Job. Weitere Informationen finden Sie unter Dataflow-Befehlszeile verwenden.
Dataflow-Jobs archivieren
Wenn Sie einen Dataflow-Job archivieren, wird der Job aus der Liste der Jobs auf der Dataflow-Seite Jobs in der Console entfernt. Der Job wird in eine archivierte Jobliste verschoben. Sie können nur abgeschlossene Jobs archivieren, einschließlich der Jobs in den folgenden Status:
JOB_STATE_CANCELLEDJOB_STATE_DRAINEDJOB_STATE_DONEJOB_STATE_FAILEDJOB_STATE_UPDATED
Weitere Informationen finden Sie unter Abschluss des Dataflow-Jobs in diesem Dokument. Informationen zur Fehlerbehebung finden Sie unter Fehler in Dataflow archivieren unter „Fehlerbehebung bei Dataflow-Fehlern”.
Alle archivierten Jobs werden nach einer Aufbewahrungsdauer von 30 Tagen gelöscht.
Job archivieren
Führen Sie die folgenden Schritte aus, um einen abgeschlossenen Job aus der Hauptjobliste auf der Dataflow-Seite Jobs zu entfernen.
Console
Rufen Sie in der Google Cloud Console die Dataflow-Seite Jobs auf.
Eine Liste der Dataflow-Jobs mit ihrem Status wird angezeigt.
Wählen Sie einen Job aus.
Klicken Sie auf der Seite Jobdetails auf Archivieren. Wenn der Job nicht abgeschlossen wurde, ist die Option Archivieren nicht verfügbar.
API
Verwenden Sie das Feld JobMetadata, um Jobs mit der API zu archivieren. Verwenden Sie im Feld JobMetadata für userDisplayProperties das Schlüssel/Wert-Paar "archived":"true".
Ihre API-Anfrage muss auch den Abfrageparameter updateMask enthalten.
curl --request PUT \
"https://dataflow.googleapis.com/v1b3/projects/PROJECT_ID/locations/REGION/jobs/JOB_ID/?updateMask=job_metadata.user_display_properties.archived" \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Accept: application/json" \
-H "Content-Type: application/json" \
--data
'{"job_metadata":{"userDisplayProperties":{"archived":"true"}}}' \
--compressed
Ersetzen Sie Folgendes:
PROJECT_ID: Ihre Projekt-ID.REGION: eine Dataflow-RegionJOB_ID: die ID Ihres Dataflow-Jobs.
Archivierte Jobs ansehen und wiederherstellen
Führen Sie die folgenden Schritte aus, um archivierte Jobs aufzurufen oder archivierte Jobs in der Hauptjobliste auf der Dataflow-Seite Jobs wiederherzustellen.
Console
Rufen Sie in der Google Cloud Console die Dataflow-Seite Jobs auf.
Klicken Sie auf den Schalter Archiviert. Eine Liste archivierter Dataflow-Jobs wird angezeigt.
Wählen Sie einen Job aus.
Klicken Sie auf der Seite Jobdetails auf Wiederherstellen, um den Job in der Hauptliste der Jobs auf der Dataflow-Seite Jobs wiederherzustellen.
API
Verwenden Sie das Feld JobMetadata, um Jobs mithilfe der API wiederherzustellen. Verwenden Sie im Feld JobMetadata für userDisplayProperties das Schlüssel/Wert-Paar "archived":"false".
Ihre API-Anfrage muss auch den Abfrageparameter updateMask enthalten.
curl --request PUT \
"https://dataflow.googleapis.com/v1b3/projects/PROJECT_ID/locations/REGION/jobs/JOB_ID/?updateMask=job_metadata.user_display_properties.archived" \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Accept: application/json" \
-H "Content-Type: application/json" \
--data
'{"job_metadata":{"userDisplayProperties":{"archived":"false"}}}' \
--compressed
Ersetzen Sie Folgendes:
PROJECT_ID: Ihre Projekt-ID.REGION: eine Dataflow-RegionJOB_ID: die ID Ihres Dataflow-Jobs.
Nächste Schritte
- Dataflow-Befehlszeile ansehen
- Dataflow REST API ansehen
- Dataflow-Monitoring-Oberfläche in der Google Cloud Console ansehen
- Pipeline aktualisieren