Vous pouvez utiliser l'infrastructure de journalisation intégrée du SDK Apache Beam pour enregistrer des informations lors de l'exécution de votre pipeline. Vous pouvez exploiter Google Cloud Console pour surveiller les informations de journalisation pendant et après l'exécution de votre pipeline.
Ajouter des messages de journal à votre pipeline
Java
Le SDK Apache Beam pour Java vous recommande de journaliser les messages des nœuds de calcul via la bibliothèque Open Source SLF4J (Simple Logging Facade for Java). Le SDK Apache Beam pour Java met en œuvre l'infrastructure de journalisation requise, de sorte que votre code Java a simplement à importer l'API SLF4J. Il instancie ensuite un enregistreur pour activer la journalisation des messages dans le code de votre pipeline.
Pour le code et/ou les bibliothèques préexistants, le SDK Apache Beam pour Java configure une infrastructure de journalisation supplémentaire. Les messages de journal générés par les bibliothèques de journalisation suivantes pour Java sont capturés :
Python
Le SDK Apache Beam pour Python propose le package de bibliothèques logging, qui permet aux nœuds de calcul du pipeline de générer des messages de journal. Pour utiliser les fonctions de la bibliothèque, vous devez importer celle-ci :
import logging
Go
Le SDK Apache Beam pour Go propose le package de bibliothèques log, qui permet aux nœuds de calcul du pipeline de générer des messages de journal. Pour utiliser les fonctions de la bibliothèque, vous devez importer celle-ci :
import "github.com/apache/beam/sdks/v2/go/pkg/beam/log"
Exemple de code pour générer les messages de journal d'un nœud de calcul
Java
L'exemple suivant utilise SLF4J pour la journalisation de Dataflow. Pour en savoir plus sur la configuration de SLF4J pour la journalisation de Dataflow, consultez l'article Conseils Java.
L'exemple Apache Beam WordCount peut être modifié pour générer un message de journal lorsque le mot "love" est trouvé dans une ligne du texte traité. Le code ajouté est indiqué en gras dans l'exemple suivant (le code environnant est inclus pour situer le contexte).
package org.apache.beam.examples; // Import SLF4J packages. import org.slf4j.Logger; import org.slf4j.LoggerFactory; ... public class WordCount { ... static class ExtractWordsFn extends DoFn<String, String> { // Instantiate Logger. // Suggestion: As shown, specify the class name of the containing class // (WordCount). private static final Logger LOG = LoggerFactory.getLogger(WordCount.class); ... @ProcessElement public void processElement(ProcessContext c) { ... // Output each word encountered into the output PCollection. for (String word : words) { if (!word.isEmpty()) { c.output(word); } // Log INFO messages when the word "love" is found. if(word.toLowerCase().equals("love")) { LOG.info("Found " + word.toLowerCase()); } } } } ... // Remaining WordCount example code ...
Python
L'exemple Apache Beam wordcount.py peut être modifié pour générer un message de journal lorsque le mot "love" est détecté dans une ligne du texte traité.
# import Python logging module. import logging class ExtractWordsFn(beam.DoFn): def process(self, element): words = re.findall(r'[A-Za-z\']+', element) for word in words: yield word if word.lower() == 'love': # Log using the root logger at info or higher levels logging.info('Found : %s', word.lower()) # Remaining WordCount example code ...
Go
L'exemple Apache Beam wordcount.go peut être modifié pour générer un message de journal lorsque le mot "love" est détecté dans une ligne du texte traité.
func (f *extractFn) ProcessElement(ctx context.Context, line string, emit func(string)) { for _, word := range wordRE.FindAllString(line, -1) { // increment the counter for small words if length of words is // less than small_word_length if strings.ToLower(word) == "love" { log.Infof(ctx, "Found : %s", strings.ToLower(word)) } emit(word) } } // Remaining Wordcount example
Java
Si le pipeline WordCount modifié est exécuté en local à l'aide de l'exécuteur par défaut DirectRunner et que la sortie est envoyée dans un fichier local (--output=./local-wordcounts), la sortie de la console inclut les messages de journal ajoutés :
INFO: Executing pipeline using the DirectRunner. ... Feb 11, 2015 1:13:22 PM org.apache.beam.examples.WordCount$ExtractWordsFn processElement INFO: Found love Feb 11, 2015 1:13:22 PM org.apache.beam.examples.WordCount$ExtractWordsFn processElement INFO: Found love Feb 11, 2015 1:13:22 PM org.apache.beam.examples.WordCount$ExtractWordsFn processElement INFO: Found love ... INFO: Pipeline execution complete.
Par défaut, seules les lignes de journal de niveau INFO ou supérieur seront envoyées à Cloud Logging. Si vous souhaitez modifier ce comportement, consultez la section Définir les niveaux de journalisation des nœuds de calcul d'un pipeline.
Python
Si le pipeline WordCount modifié est exécuté en local à l'aide de l'exécuteur par défaut DirectRunner et que la sortie est envoyée dans un fichier local (--output=./local-wordcounts), la sortie de la console inclut les messages de journal ajoutés :
INFO:root:Found : love INFO:root:Found : love INFO:root:Found : love
Par défaut, seules les lignes de journal de niveau INFO ou supérieur seront envoyées à Cloud Logging.
Go
Si le pipeline WordCount modifié est exécuté en local à l'aide de l'exécuteur par défaut DirectRunner et que la sortie est envoyée dans un fichier local (--output=./local-wordcounts), la sortie de la console inclut les messages de journal ajoutés :
2022/05/26 11:36:44 Found : love 2022/05/26 11:36:44 Found : love 2022/05/26 11:36:44 Found : love
Par défaut, seules les lignes de journal de niveau INFO ou supérieur seront envoyées à Cloud Logging.
Contrôler le volume des journaux
Vous pouvez également réduire le volume des journaux générés en modifiant les niveaux de journalisation du pipeline. Si vous ne souhaitez plus ingérer tout ou partie des journaux Dataflow, ajoutez une exclusion Logging afin d'exclure les journaux Dataflow. Exportez ensuite les journaux vers une autre destination, telle que BigQuery, Cloud Storage ou Pub/Sub. Pour en savoir plus, consultez la page Contrôler l'ingestion de journaux Dataflow.
Limite et limitation de journalisation
Les messages de journal de nœud de calcul sont limités à 15 000 messages toutes les 30 secondes, par nœud de calcul. Si cette limite est atteinte, un seul message de journal de nœud de calcul est ajouté indiquant que la journalisation est limitée :
Throttling logger worker. It used up its 30s quota for logs in only 12.345s
Stockage et conservation des journaux
Les journaux opérationnels sont stockés dans le bucket de journaux _Default.
Le nom du service de l'API Logging est dataflow.googleapis.com. Pour en savoir plus sur les services et les types de ressources surveillées Google Cloud utilisés dans Cloud Logging, consultez la page Ressources et services surveillés.
Pour en savoir plus sur la durée de conservation des entrées de journal par Logging, consultez la section correspondante sur la page Quotas et limites : durée de conservation des journaux.
Pour en savoir plus sur l'affichage des journaux opérationnels, consultez la section Surveiller et afficher les journaux de pipeline.
Surveiller et afficher les journaux de pipeline
Lorsque vous exécutez votre pipeline sur le service Dataflow, l'interface de surveillance de Dataflow vous permet d'afficher les journaux émis par votre pipeline.
Exemple de journal de nœud de calcul Dataflow
Pour exécuter le pipeline WordCount modifié dans le Cloud, spécifiez les options suivantes :
Java
--project=WordCountExample --output=gs://<bucket-name>/counts --runner=DataflowRunner --tempLocation=gs://<bucket-name>/temp --stagingLocation=gs://<bucket-name>/binaries
Python
--project=WordCountExample --output=gs://<bucket-name>/counts --runner=DataflowRunner --staging_location=gs://<bucket-name>/binaries
Go
--project=WordCountExample --output=gs://<bucket-name>/counts --runner=DataflowRunner --staging_location=gs://<bucket-name>/binaries
Afficher les journaux
Étant donné que le pipeline cloud WordCount utilise l'exécution bloquante, des messages de la console sont générés pendant l'exécution du pipeline. Une fois la tâche démarrée, un lien vers la page de la console Google Cloud est généré dans la console, suivi de l'ID de la tâche du pipeline :
INFO: To access the Dataflow monitoring console, please navigate to https://console.developers.google.com/dataflow/job/2017-04-13_13_58_10-6217777367720337669 Submitted job: 2017-04-13_13_58_10-6217777367720337669
L'URL de la console mène à l'interface de surveillance de Dataflow, qui présente la page de résumé du job envoyé. Cette page affiche un graphique d'exécution dynamique sur la gauche et des informations récapitulatives sur la droite : Cliquez sur keyboard_capslock dans le panneau inférieur pour développer le panneau des journaux.
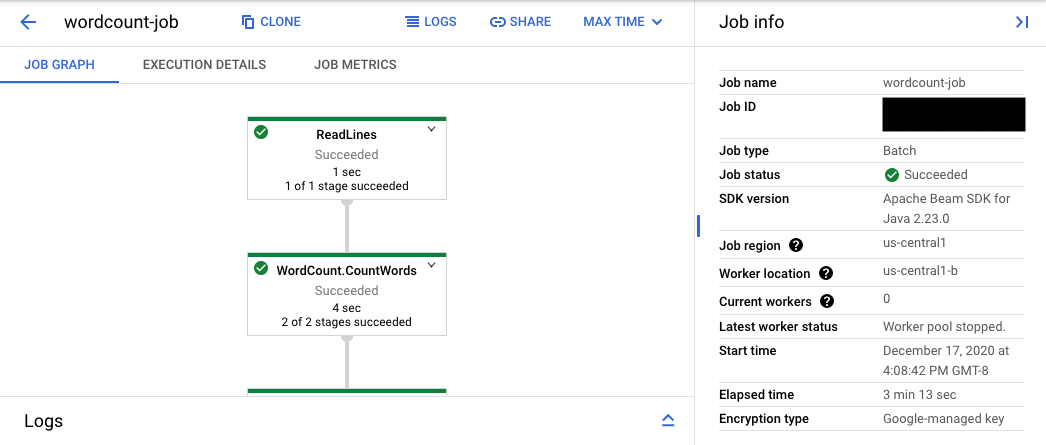
Par défaut, le panneau des journaux affiche les journaux des tâches indiquant l'état de la tâche dans son ensemble. Vous pouvez filtrer les messages qui apparaissent dans le panneau des journaux en cliquant sur Infoarrow_drop_down (Infos) et sur filter_listFilter logs (Filtrer les journaux).
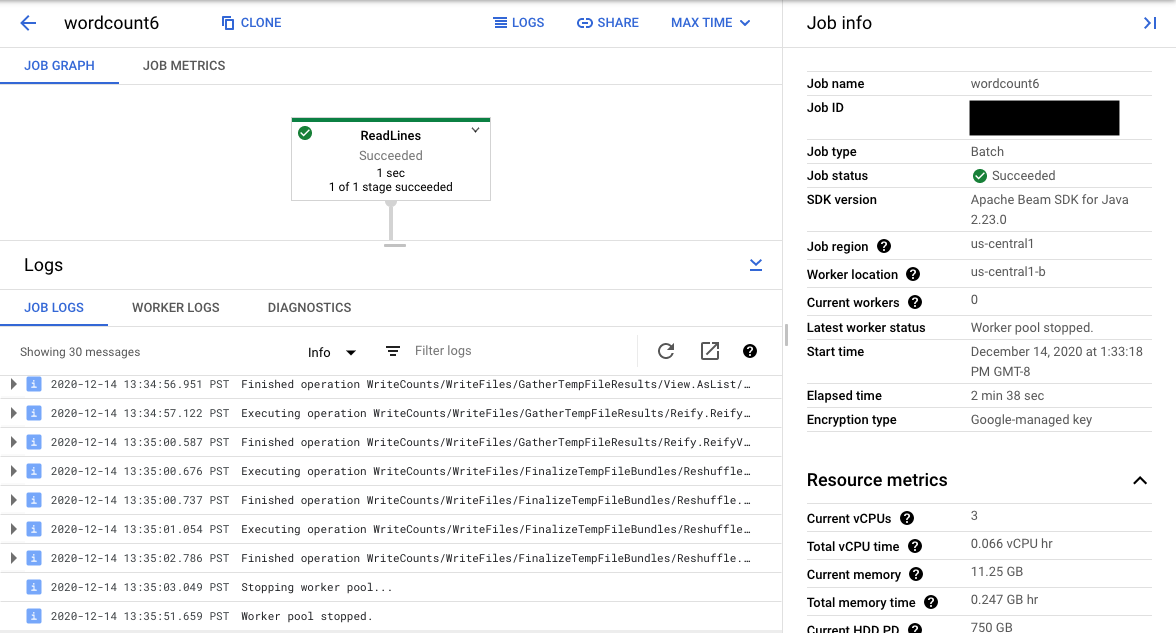
La sélection d'une étape du pipeline dans le graphique remplace la vue affichée par la vue Step Logs (Journaux des étapes), qui comprend les messages générés par votre code et le code généré s'exécutant dans le cadre de cette étape du pipeline.
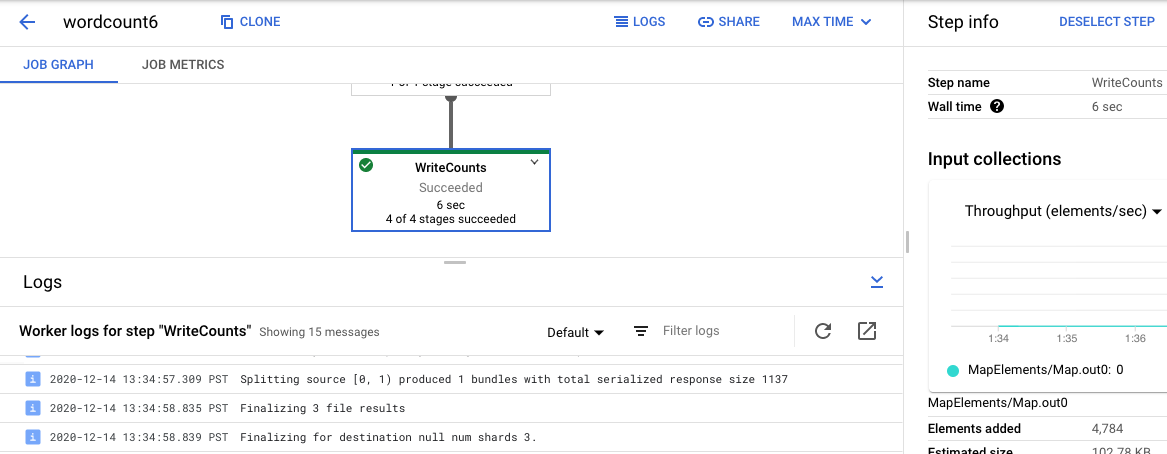
Pour revenir à la vue Journaux des tâches, désélectionnez l'étape en cliquant à l'extérieur du graphique ou en utilisant le bouton Désélectionner l'étape du panneau de droite.
Accédez à l'explorateur de journaux.
Pour ouvrir l'explorateur de journaux et sélectionner différents types de journaux, cliquez sur Afficher dans l'explorateur de journaux (bouton de lien externe) dans le panneau des journaux.
Dans l'explorateur de journaux, pour afficher le panneau avec différents types de journaux, cliquez sur le bouton Champs de journal.
Sur la page "Explorateur de journaux", la requête peut filtrer les journaux par étape de tâche ou par type de journal. Pour supprimer les filtres, cliquez sur le bouton Afficher la requête et modifiez la requête.
Pour afficher tous les journaux disponibles pour une tâche, procédez comme suit :
Dans le champ Requête, saisissez la requête suivante :
resource.type="dataflow_step" resource.labels.job_id="JOB_ID"Remplacez JOB_ID par l'ID de votre job.
Cliquez sur Exécuter la requête.
Si vous utilisez cette requête et que vous ne voyez pas de journaux pour votre tâche, cliquez sur Modifier l'heure.
Ajustez l'heure de début et l'heure de fin, puis cliquez sur Appliquer.
Types de journaux
L'explorateur de journaux inclut également les journaux d'infrastructure correspondant à votre pipeline. Utilisez les journaux d'erreurs et d'avertissements pour diagnostiquer les problèmes de pipeline observés. Les erreurs et les avertissements dans les journaux d'infrastructure qui ne sont pas corrélés à un problème de pipeline n'indiquent pas nécessairement un problème.
Voici un récapitulatif des différents types de journaux consultables à partir de la page Explorateur de journaux :
- Les journaux job-message contiennent des messages au niveau des tâches générés par plusieurs composants de Dataflow. Il peut s'agir de la configuration de l'autoscaling, du démarrage ou de l'arrêt des nœuds de calcul, de la progression d'une étape de la tâche et des erreurs concernant la tâche. Les erreurs au niveau des nœuds de calcul qui sont dues au plantage du code utilisateur et qui s'affichent dans les journaux worker se propagent également dans les journaux job-message.
- Les journaux worker sont produits par les nœuds de calcul Dataflow. Les nœuds de calcul effectuent la majeure partie du travail en pipeline (par exemple, en appliquant vos objets
ParDoaux données). Les journaux worker contiennent des messages enregistrés par votre code et par Dataflow. - Les journaux worker-startup sont présents sur la plupart des tâches Dataflow et peuvent capturer les messages liés au processus de démarrage. Le processus de démarrage comprend le téléchargement des fichiers JAR du job à partir de Cloud Storage, puis le démarrage des nœuds de calcul. Il est recommandé d'examiner ces journaux en cas de problème lié au démarrage des nœuds de calcul.
- Les journaux shuffler accueillent les messages des nœuds de calcul qui consolident les résultats des opérations de pipeline exécutées en parallèle.
- Les journaux system contiennent les messages des systèmes d'exploitation hôtes des VM de nœud de calcul. Dans certains scénarios, ils peuvent capturer des plantages de processus ou des événements de mémoire saturée (OOM, Out Of Memory).
- Les journaux docker et kubelet contiennent les messages liés à ces technologies publiques, qui sont utilisées sur les nœuds de calcul Dataflow.
- Les journaux nvidia-mps contiennent des messages concernant les opérations du service multi-processus (MPS) NVIDIA.
Définir les niveaux de journalisation des nœuds de calcul d'un pipeline
Java
Le niveau de journalisation SLF4J par défaut défini sur les nœuds de calcul par le SDK Apache Beam pour Java est INFO. Tous les messages de journal de niveau INFO ou supérieur (INFO, WARN, ERROR) sont émis. Vous pouvez redéfinir ce paramètre par défaut afin de prendre en charge des niveaux de journalisation SLF4J inférieurs (TRACE ou DEBUG) ou de définir des niveaux de journalisation distincts pour différents packages de classe de votre code.
Les options de pipeline suivantes vous permettent de définir des niveaux de journalisation pour les nœuds de calcul à partir de la ligne de commande ou de façon programmatique :
--defaultSdkHarnessLogLevel=<level>: cette option permet de définir tous les enregistreurs au niveau par défaut spécifié. Par exemple, l'option de ligne de commande suivante remplace le niveau de journalisation DataflowINFOpar défaut et le définit surDEBUG:--defaultSdkHarnessLogLevel=DEBUG--sdkHarnessLogLevelOverrides={"<package or class>":"<level>"}: cette option permet de définir le niveau de journalisation pour les packages ou classes spécifiés. Par exemple, pour ignorer le niveau de journalisation par défaut du pipeline pour le packageorg.apache.beam.runners.dataflowet le définir surTRACE:
--sdkHarnessLogLevelOverrides='{"org.apache.beam.runners.dataflow":"TRACE"}'
Pour effectuer plusieurs forçages, fournissez une carte JSON :
(--sdkHarnessLogLevelOverrides={"<package/class>":"<level>","<package/class>":"<level>",...}).- Les options de pipeline
defaultSdkHarnessLogLeveletsdkHarnessLogLevelOverridesne sont pas compatibles avec les pipelines qui utilisent les versions 2.50.0 ou antérieures du SDK Apache Beam sans l'exécuteur v2. Dans ce cas, utilisez les options de pipeline--defaultWorkerLogLevel=<level>et--workerLogLevelOverrides={"<package or class>":"<level>"}. Pour utiliser plusieurs forçages, fournissez une carte JSON :
(--workerLogLevelOverrides={"<package/class>":"<level>","<package/class>":"<level>",...})
L'exemple suivant définit de façon automatisée les options de journalisation du pipeline avec des valeurs par défaut pouvant être remplacées à partir de la ligne de commande :
PipelineOptions options = ... SdkHarnessOptions loggingOptions = options.as(SdkHarnessOptions.class); // Overrides the default log level on the worker to emit logs at TRACE or higher. loggingOptions.setDefaultSdkHarnessLogLevel(LogLevel.TRACE); // Overrides the Foo class and "org.apache.beam.runners.dataflow" package to emit logs at WARN or higher. loggingOptions.getSdkHarnessLogLevelOverrides() .addOverrideForClass(Foo.class, LogLevel.WARN) .addOverrideForPackage(Package.getPackage("org.apache.beam.runners.dataflow"), LogLevel.WARN);
Python
Le niveau de journalisation par défaut défini sur les nœuds de calcul par le SDK Apache Beam pour Python est INFO. Tous les messages de journal de niveau INFO ou supérieur (INFO, WARNING, ERROR, CRITICAL) sont émis.
Vous pouvez redéfinir ce paramètre par défaut afin de prendre en charge des niveaux de journalisation inférieurs (DEBUG) ou de définir des niveaux de journalisation distincts pour différents modules de votre code.
Vous disposez de deux options de pipeline permettant de définir les niveaux de journalisation des nœuds de calcul à partir de la ligne de commande ou de manière programmatique :
--default_sdk_harness_log_level=<level>: cette option permet de définir tous les enregistreurs au niveau par défaut spécifié. Par exemple, l'option de ligne de commande suivante remplace le niveau de journalisation DataflowINFOpar défaut et le définit surDEBUG:
--default_sdk_harness_log_level=DEBUG--sdk_harness_log_level_overrides={\"<module>\":\"<level>\"}: cette option permet de définir le niveau de journalisation pour les modules spécifiés. Par exemple, pour ignorer le niveau de journalisation par défaut du pipeline pour le moduleapache_beam.runners.dataflowet le définir surDEBUG:
--sdk_harness_log_level_overrides={\"apache_beam.runners.dataflow\":\"DEBUG\"}
Pour effectuer plusieurs forçages, fournissez une carte JSON :
(--sdk_harness_log_level_overrides={\"<module>\":\"<level>\",\"<module>\":\"<level>\",...}).
L'exemple suivant utilise la classe WorkerOptions pour définir de manière automatisée les options de journalisation de pipeline pouvant être remplacées à partir de la ligne de commande :
from apache_beam.options.pipeline_options import PipelineOptions, WorkerOptions pipeline_args = [ '--project=PROJECT_NAME', '--job_name=JOB_NAME', '--staging_location=gs://STORAGE_BUCKET/staging/', '--temp_location=gs://STORAGE_BUCKET/tmp/', '--region=DATAFLOW_REGION', '--runner=DataflowRunner' ] pipeline_options = PipelineOptions(pipeline_args) worker_options = pipeline_options.view_as(WorkerOptions) worker_options.default_sdk_harness_log_level = 'WARNING' # Note: In Apache Beam SDK 2.42.0 and earlier versions, use ['{"apache_beam.runners.dataflow":"WARNING"}'] worker_options.sdk_harness_log_level_overrides = {"apache_beam.runners.dataflow":"WARNING"} # Pass in pipeline options during pipeline creation. with beam.Pipeline(options=pipeline_options) as pipeline:
Remplacez les éléments suivants :
PROJECT_NAME: nom du projet.JOB_NAME: nom du job.STORAGE_BUCKET: nom Cloud Storage.DATAFLOW_REGION: région dans laquelle vous souhaitez déployer la tâche DataflowL'option
--regionremplace la région par défaut définie dans le serveur de métadonnées, sur votre client local ou dans les variables d'environnement.
Go
Cette fonctionnalité n'est pas disponible dans le SDK Apache Beam pour Go.
Afficher le journal des tâches BigQuery lancées
Lorsque vous utilisez BigQuery dans votre pipeline Dataflow, des jobs BigQuery sont lancés pour effectuer diverses actions en votre nom. Ces actions peuvent inclure le chargement de données, l'exportation de données, etc. À des fins de dépannage et de surveillance, l'interface de surveillance de Dataflow contient des informations supplémentaires sur ces jobs BigQuery, accessibles dans le panneau Journaux.
Les informations sur les jobs BigQuery affichées dans le panneau Journaux sont stockées et chargées à partir d'une table système BigQuery. Par conséquent, des coûts de facturation sont générés lorsque la table BigQuery sous-jacente est interrogée.
Afficher les détails d'une tâche BigQuery
Pour afficher les informations sur les tâches BigQuery, votre pipeline doit utiliser Apache Beam 2.24.0 ou version ultérieure.
Pour répertorier les tâches BigQuery, ouvrez l'onglet BigQuery Jobs (Tâches BigQuery) et sélectionnez l'emplacement des tâches BigQuery. Cliquez ensuite sur Load BigQuery Jobs (Charger les tâches BigQuery) et confirmez la boîte de dialogue. Une fois la requête terminée, la liste des tâches s'affiche.
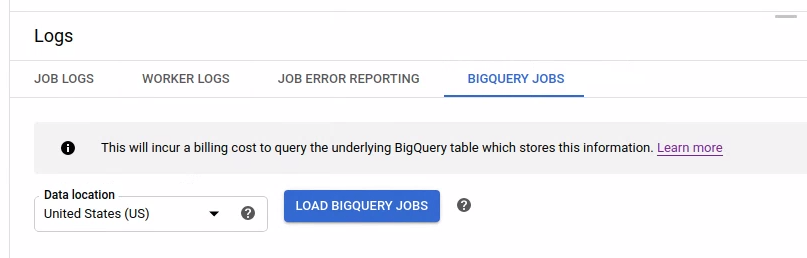
Des informations de base sur chaque job sont fournies, y compris l'ID du job, son type et sa durée.
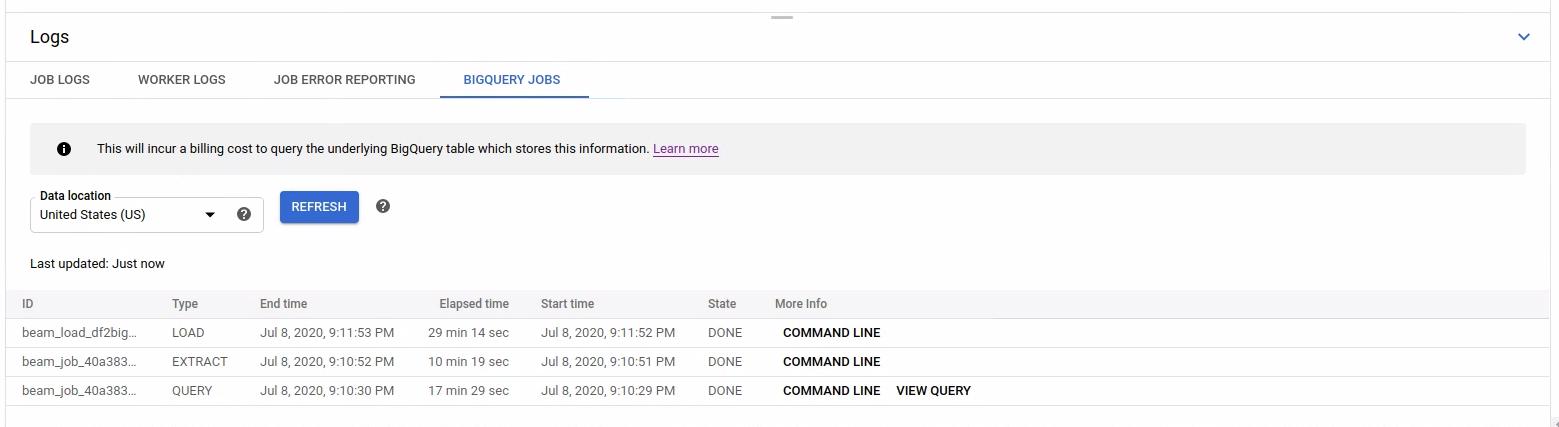
Pour obtenir des informations plus détaillées sur une tâche spécifique, cliquez sur Command line (Ligne de commande) dans la colonne More Info (Plus d'infos).
Dans la fenêtre modale de la ligne de commande, copiez la commande bq jobs describe et exécutez-la localement ou dans Cloud Shell.
gcloud alpha bq jobs describe BIGQUERY_JOB_ID
La commande bq jobs describe génère des statistiques JobStatistics, qui fournissent des informations supplémentaires utiles pour le diagnostic d'un job BigQuery lent ou bloqué.
Sinon, lorsque vous utilisez BigQueryIO avec une requête SQL, une tâche de requête est émise. Pour afficher la requête SQL utilisée par le job, cliquez sur Afficher la requête dans la colonne Plus d'infos.