Pode usar a infraestrutura de registo integrada do SDK Apache Beam para registar informações quando executar o seu pipeline. Pode usar a Google Cloud consola para monitorizar as informações de registo durante e após a execução do pipeline.
Adicione mensagens de registo ao seu pipeline
Java
O SDK do Apache Beam para Java recomenda que registe mensagens de trabalhadores através da biblioteca Simple Logging Facade for Java (SLF4J) de código aberto. O SDK Apache Beam para Java implementa a infraestrutura de registo necessária para que o seu código Java só precise de importar a API SLF4J. Em seguida, instancia um registador para ativar o registo de mensagens no código do pipeline.
Para código e/ou bibliotecas pré-existentes, o SDK do Apache Beam para Java configura uma infraestrutura de registo adicional. As mensagens de registo produzidas pelas seguintes bibliotecas de registo para Java são capturadas:
Python
O SDK Apache Beam para Python fornece o pacote de biblioteca logging, que permite que os trabalhadores do pipeline produzam mensagens de registo. Para usar as funções da biblioteca, tem de importar a biblioteca:
import logging
Go
O Apache Beam SDK para Go fornece o pacote de biblioteca log, que permite que os trabalhadores do pipeline produzam mensagens de registo. Para usar as funções da biblioteca, tem de importar a biblioteca:
import "github.com/apache/beam/sdks/v2/go/pkg/beam/log"
Exemplo de código de mensagem de registo do trabalhador
Java
O exemplo seguinte usa o SLF4J para o registo do Dataflow. Para saber como configurar o SLF4J para o registo do Dataflow, consulte o artigo Sugestões de Java.
O exemplo WordCount do Apache Beam pode ser modificado para gerar uma mensagem de registo quando a palavra "love" é encontrada numa linha do texto processado. O código adicionado está indicado a negrito no exemplo seguinte (o código circundante está incluído para contexto).
package org.apache.beam.examples; // Import SLF4J packages. import org.slf4j.Logger; import org.slf4j.LoggerFactory; ... public class WordCount { ... static class ExtractWordsFn extends DoFn<String, String> { // Instantiate Logger. // Suggestion: As shown, specify the class name of the containing class // (WordCount). private static final Logger LOG = LoggerFactory.getLogger(WordCount.class); ... @ProcessElement public void processElement(ProcessContext c) { ... // Output each word encountered into the output PCollection. for (String word : words) { if (!word.isEmpty()) { c.output(word); } // Log INFO messages when the word "love" is found. if(word.toLowerCase().equals("love")) { LOG.info("Found " + word.toLowerCase()); } } } } ... // Remaining WordCount example code ...
Python
O exemplo wordcount.py do Apache Beam pode ser modificado para gerar uma mensagem de registo quando a palavra "love" é encontrada numa linha do texto processado.
# import Python logging module. import logging class ExtractWordsFn(beam.DoFn): def process(self, element): words = re.findall(r'[A-Za-z\']+', element) for word in words: yield word if word.lower() == 'love': # Log using the root logger at info or higher levels logging.info('Found : %s', word.lower()) # Remaining WordCount example code ...
Go
O exemplo wordcount.go do Apache Beam pode ser modificado para gerar uma mensagem de registo quando a palavra "love" for encontrada numa linha do texto processado.
func (f *extractFn) ProcessElement(ctx context.Context, line string, emit func(string)) { for _, word := range wordRE.FindAllString(line, -1) { // increment the counter for small words if length of words is // less than small_word_length if strings.ToLower(word) == "love" { log.Infof(ctx, "Found : %s", strings.ToLower(word)) } emit(word) } } // Remaining Wordcount example
Java
Se o pipeline WordCount modificado for executado localmente com o DirectRunner predefinido
com a saída enviada para um ficheiro local (--output=./local-wordcounts), a saída da consola
inclui as mensagens de registo adicionadas:
INFO: Executing pipeline using the DirectRunner. ... Feb 11, 2015 1:13:22 PM org.apache.beam.examples.WordCount$ExtractWordsFn processElement INFO: Found love Feb 11, 2015 1:13:22 PM org.apache.beam.examples.WordCount$ExtractWordsFn processElement INFO: Found love Feb 11, 2015 1:13:22 PM org.apache.beam.examples.WordCount$ExtractWordsFn processElement INFO: Found love ... INFO: Pipeline execution complete.
Por predefinição, apenas as linhas de registo marcadas com INFO e superior são enviadas para o Cloud Logging. Para alterar este comportamento, consulte o artigo
Definir níveis de registo do trabalhador do pipeline.
Python
Se o pipeline WordCount modificado for executado localmente com o DirectRunner predefinido
com a saída enviada para um ficheiro local (--output=./local-wordcounts), a saída da consola
inclui as mensagens de registo adicionadas:
INFO:root:Found : love INFO:root:Found : love INFO:root:Found : love
Por predefinição, apenas as linhas de registo marcadas com INFO e superior são enviadas para o Cloud Logging. Para alterar este comportamento, consulte o artigo
Definir níveis de registo do trabalhador do pipeline.
Não substitua a configuração de registo com funções logging.config, uma vez que isto pode desativar os controladores de registo pré-configurados que transmitem os registos do pipeline para o Dataflow e o Cloud Logging.
Go
Se o pipeline WordCount modificado for executado localmente com o DirectRunner predefinido
com a saída enviada para um ficheiro local (--output=./local-wordcounts), a saída da consola
inclui as mensagens de registo adicionadas:
2022/05/26 11:36:44 Found : love 2022/05/26 11:36:44 Found : love 2022/05/26 11:36:44 Found : love
Por predefinição, apenas as linhas de registo marcadas com INFO e superior são enviadas para o Cloud Logging.
Controle o volume de registos
Também pode reduzir o volume dos registos gerados alterando os níveis de registo do pipeline. Se não quiser continuar a carregar alguns ou todos os seus registos do Dataflow, adicione uma exclusão de registo para excluir os registos do Dataflow. Em seguida, exporte os registos para um destino diferente, como o BigQuery, o Cloud Storage ou o Pub/Sub. Para mais informações, consulte o artigo Controlar o carregamento de registos do Dataflow.
Limite de registo e limitação
As mensagens de registo do trabalhador estão limitadas a 15 000 mensagens a cada 30 segundos, por trabalhador. Se este limite for atingido, é adicionada uma única mensagem de registo do trabalhador a indicar que o registo está limitado:
Throttling logger worker. It used up its 30s quota for logs in only 12.345s
Armazenamento e retenção de registos
Os registos operacionais são armazenados no contentor de registos _Default. O nome do serviço da API de registo é dataflow.googleapis.com. Para mais informações
acerca dos tipos de recursos monitorizados e dos serviços da Google Cloud Platform usados no
Cloud Logging, consulte o artigo Recursos monitorizados e
serviços.
Para ver detalhes sobre durante quanto tempo as entradas do registo são retidas pelo Logging, consulte as informações de retenção em Quotas e limites: períodos de retenção de registos.
Para ver informações sobre como ver registos operacionais, consulte o artigo Monitorize e veja registos de pipelines.
Monitorize e veja registos de pipelines
Quando executa o pipeline no serviço Dataflow, pode usar a interface de monitorização do Dataflow para ver os registos emitidos pelo pipeline.
Exemplo de registo de worker do Dataflow
O pipeline WordCount modificado pode ser executado na nuvem com as seguintes opções:
Java
--project=WordCountExample --output=gs://<bucket-name>/counts --runner=DataflowRunner --tempLocation=gs://<bucket-name>/temp --stagingLocation=gs://<bucket-name>/binaries
Python
--project=WordCountExample --output=gs://<bucket-name>/counts --runner=DataflowRunner --staging_location=gs://<bucket-name>/binaries
Go
--project=WordCountExample --output=gs://<bucket-name>/counts --runner=DataflowRunner --staging_location=gs://<bucket-name>/binaries
Ver registos
Uma vez que o pipeline na nuvem WordCount usa a execução de bloqueio, as mensagens da consola são apresentadas durante a execução do pipeline. Após o início da tarefa, é gerado um link para a Google Cloud página da consola, seguido do ID da tarefa do pipeline:
INFO: To access the Dataflow monitoring console, please navigate to https://console.developers.google.com/dataflow/job/2017-04-13_13_58_10-6217777367720337669 Submitted job: 2017-04-13_13_58_10-6217777367720337669
O URL da consola direciona para a interface de monitorização do Dataflow com uma página de resumo da tarefa enviada. Mostra um gráfico de execução dinâmico à esquerda, com informações de resumo à direita. Clique em keyboard_capslock no painel inferior para expandir o painel de registos.

Por predefinição, o painel de registos mostra os registos de tarefas que comunicam o estado da tarefa como um todo. Pode filtrar as mensagens que aparecem no painel de registos clicando em Informaçõesarrow_drop_down e filter_listFiltrar registos.
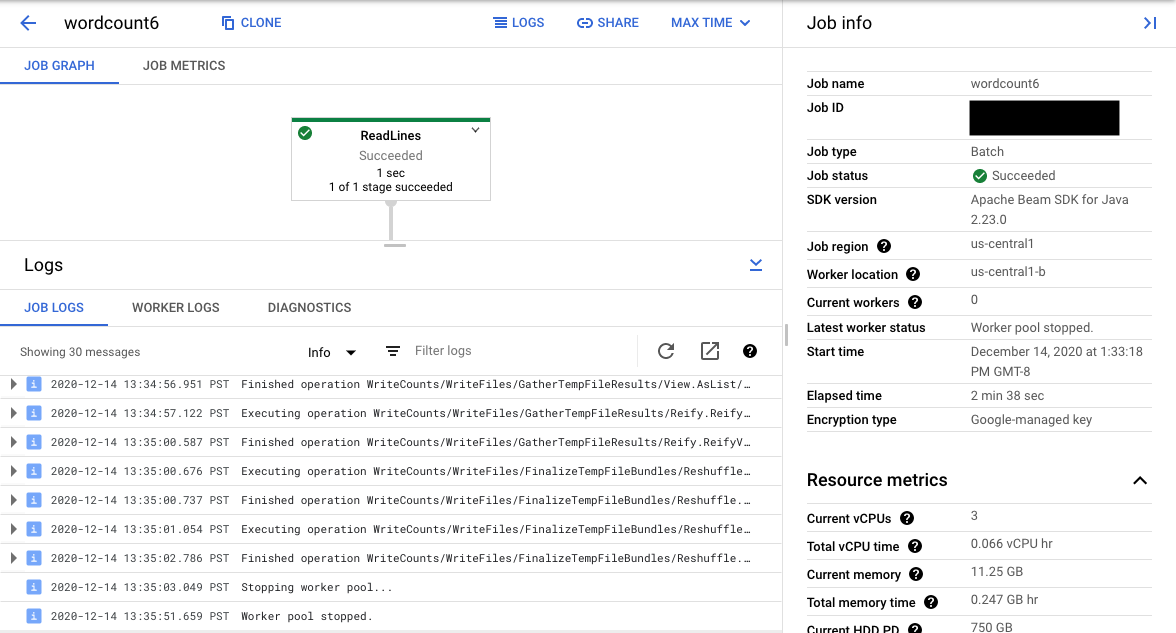
Selecionar um passo do pipeline no gráfico altera a vista para Registos de passos gerados pelo seu código e o código gerado em execução no passo do pipeline.

Para voltar a Registos de tarefas, limpe o passo clicando fora do gráfico ou usando o botão Desmarcar passo no painel lateral direito.
Navegue para o Explorador de registos
Para abrir o explorador de registos e selecionar diferentes tipos de registos, no painel de registos, clique em Ver no explorador de registos (o botão de link externo).
No Explorador de registos, para ver o painel com diferentes tipos de registos, clique no botão Campos de registo.
Na página Logs Explorer, a consulta pode filtrar os registos por passo da tarefa ou por tipo de registo. Para remover filtros, clique no botão Mostrar consulta e edite a consulta.
Para ver todos os registos disponíveis para uma tarefa, siga estes passos:
No campo Consulta, introduza a seguinte consulta:
resource.type="dataflow_step" resource.labels.job_id="JOB_ID"Substitua JOB_ID pelo ID da sua tarefa.
Clique em Executar consulta.
Se usar esta consulta e não vir registos para a sua tarefa, clique em Editar hora.
Ajuste a hora de início e a hora de fim e, de seguida, clique em Aplicar.
Tipos de registos
O Explorador de registos também inclui registos de infraestrutura para o seu pipeline. Use registos de erros e avisos para diagnosticar problemas observados no pipeline. Os erros e os avisos nos registos de infraestrutura que não estão correlacionados com um problema de pipeline não indicam necessariamente um problema.
Segue-se um resumo dos diferentes tipos de registos disponíveis para visualização na página Explorador de registos:
- Os registos job-message contêm mensagens ao nível da tarefa que vários componentes do Dataflow geram. Os exemplos incluem a configuração do ajuste de escala automático, quando os trabalhadores são iniciados ou terminados, o progresso no passo da tarefa e os erros da tarefa. Os erros ao nível do trabalhador que têm origem na falha do código do utilizador e que estão presentes nos registos do trabalhador também são propagados para os registos de mensagens de tarefas.
- Os registos worker são produzidos por trabalhadores do Dataflow. Os trabalhadores fazem a maioria do trabalho da pipeline (por exemplo, aplicar as suas
ParDoaos dados). Os registos do trabalhador contêm mensagens registadas pelo seu código e pelo Dataflow. - Os registos worker-startup estão presentes na maioria das tarefas do Dataflow e podem capturar mensagens relacionadas com o processo de arranque. O processo de arranque inclui a transferência dos ficheiros JAR da tarefa do Cloud Storage e, em seguida, o início dos trabalhadores. Se houver um problema ao iniciar os trabalhadores, estes registos são um bom local para procurar.
- Os registos harness contêm mensagens do Runner v2 runner harness.
- Os registos shuffler contêm mensagens de trabalhadores que consolidam os resultados das operações de pipeline paralelas.
- Os registos system contêm mensagens dos sistemas operativos anfitriões das VMs de trabalho. Em alguns cenários, podem capturar falhas de processamento ou eventos de falta de memória (OOM).
- Os registos do docker e do kubelet contêm mensagens relacionadas com estas tecnologias públicas, que são usadas nos trabalhadores do Dataflow.
- Os registos nvidia-mps contêm mensagens sobre as operações do serviço multiprocessos (MPS) da NVIDIA.
Defina os níveis de registo do trabalhador do pipeline
Java
O nível de registo SLF4J predefinido definido nos trabalhadores pelo SDK Apache Beam para Java é
INFO. Todas as mensagens de registo de INFO ou superior (INFO,
WARN, ERROR) são emitidas. Pode definir um nível de registo predefinido diferente
para suportar níveis de registo SLF4J inferiores (TRACE ou DEBUG) ou definir níveis de registo
diferentes para diferentes pacotes de classes no seu código.
As seguintes opções de pipeline são fornecidas para lhe permitir definir níveis de registo de trabalhadores a partir da linha de comandos ou programaticamente:
--defaultSdkHarnessLogLevel=<level>: use esta opção para definir todos os registadores no nível predefinido especificado. Por exemplo, a seguinte opção de linha de comandos substitui o nível de registoINFOpredefinido do Dataflow e define-o comoDEBUG:
--defaultSdkHarnessLogLevel=DEBUG--sdkHarnessLogLevelOverrides={"<package or class>":"<level>"}: use esta opção para definir o nível de registo para classes ou pacotes especificados. Por exemplo, para substituir o nível de registo do pipeline predefinido para o pacoteorg.apache.beam.runners.dataflowe defini-lo comoTRACE:
--sdkHarnessLogLevelOverrides='{"org.apache.beam.runners.dataflow":"TRACE"}'
Para fazer várias substituições, forneça um mapa JSON:
(--sdkHarnessLogLevelOverrides={"<package/class>":"<level>","<package/class>":"<level>",...}).- As opções de pipeline
defaultSdkHarnessLogLevelesdkHarnessLogLevelOverridesnão são suportadas com pipelines que usam as versões 2.50.0 e anteriores do SDK do Apache Beam sem o Runner v2. Nesse caso, use as opções de pipeline--defaultWorkerLogLevel=<level>e--workerLogLevelOverrides={"<package or class>":"<level>"}. Para fazer várias substituições, forneça um mapa JSON:
(--workerLogLevelOverrides={"<package/class>":"<level>","<package/class>":"<level>",...})
O exemplo seguinte define programaticamente as opções de registo do pipeline com valores predefinidos que podem ser substituídos a partir da linha de comandos:
PipelineOptions options = ... SdkHarnessOptions loggingOptions = options.as(SdkHarnessOptions.class); // Overrides the default log level on the worker to emit logs at TRACE or higher. loggingOptions.setDefaultSdkHarnessLogLevel(LogLevel.TRACE); // Overrides the Foo class and "org.apache.beam.runners.dataflow" package to emit logs at WARN or higher. loggingOptions.getSdkHarnessLogLevelOverrides() .addOverrideForClass(Foo.class, LogLevel.WARN) .addOverrideForPackage(Package.getPackage("org.apache.beam.runners.dataflow"), LogLevel.WARN);
Python
O nível de registo predefinido definido nos trabalhadores pelo SDK do Apache Beam para Python é
INFO. São emitidas todas as mensagens de registo de INFO ou superior (INFO,
WARNING, ERROR, CRITICAL).
Pode definir um nível de registo predefinido diferente para suportar níveis de registo mais baixos (DEBUG)
ou definir níveis de registo diferentes para diferentes módulos no seu código.
São disponibilizadas duas opções de pipeline para lhe permitir definir níveis de registo de trabalhadores a partir da linha de comandos ou programaticamente:
--default_sdk_harness_log_level=<level>: use esta opção para definir todos os registadores no nível predefinido especificado. Por exemplo, a seguinte opção de linha de comandos substitui o nível de registoINFOpredefinido do Dataflow e define-o comoDEBUG:
--default_sdk_harness_log_level=DEBUG--sdk_harness_log_level_overrides={\"<module>\":\"<level>\"}: use esta opção para definir o nível de registo para módulos especificados. Por exemplo, para substituir o nível de registo do pipeline predefinido para o móduloapache_beam.runners.dataflowe defini-lo comoDEBUG:
--sdk_harness_log_level_overrides={\"apache_beam.runners.dataflow\":\"DEBUG\"}
Para fazer várias substituições, forneça um mapa JSON:
(--sdk_harness_log_level_overrides={\"<module>\":\"<level>\",\"<module>\":\"<level>\",...}).
O exemplo seguinte usa a classe
WorkerOptions
para definir programaticamente as opções de registo do pipeline
que podem ser substituídas a partir da linha de comandos:
from apache_beam.options.pipeline_options import PipelineOptions, WorkerOptions pipeline_args = [ '--project=PROJECT_NAME', '--job_name=JOB_NAME', '--staging_location=gs://STORAGE_BUCKET/staging/', '--temp_location=gs://STORAGE_BUCKET/tmp/', '--region=DATAFLOW_REGION', '--runner=DataflowRunner' ] pipeline_options = PipelineOptions(pipeline_args) worker_options = pipeline_options.view_as(WorkerOptions) worker_options.default_sdk_harness_log_level = 'WARNING' # Note: In Apache Beam SDK 2.42.0 and earlier versions, use ['{"apache_beam.runners.dataflow":"WARNING"}'] worker_options.sdk_harness_log_level_overrides = {"apache_beam.runners.dataflow":"WARNING"} # Pass in pipeline options during pipeline creation. with beam.Pipeline(options=pipeline_options) as pipeline:
Substitua o seguinte:
PROJECT_NAME: o nome do projetoJOB_NAME: o nome da tarefaSTORAGE_BUCKET: o nome do Cloud StorageDATAFLOW_REGION: a região onde quer implementar a tarefa do DataflowA flag
--regionsubstitui a região predefinida definida no servidor de metadados, no cliente local ou nas variáveis de ambiente.
Go
Esta funcionalidade não está disponível no SDK Apache Beam para Go.
Veja o registo de tarefas do BigQuery iniciadas
Quando usa o BigQuery no seu pipeline do Dataflow, são iniciadas tarefas do BigQuery para realizar várias ações em seu nome. Estas ações podem incluir o carregamento de dados, a exportação de dados e outras tarefas semelhantes. Para fins de resolução de problemas e monitorização, a interface de monitorização do Dataflow tem informações adicionais sobre estas tarefas do BigQuery disponíveis no painel Registos.
As informações das tarefas do BigQuery apresentadas no painel Registos são armazenadas e carregadas a partir de uma tabela do sistema do BigQuery. É incorrido um custo de faturação quando a tabela do BigQuery subjacente é consultada.
Ver os detalhes da tarefa do BigQuery
Para ver as informações das tarefas do BigQuery, o pipeline tem de usar o Apache Beam 2.24.0 ou posterior.
Para listar as tarefas do BigQuery, abra o separador Tarefas do BigQuery e selecione a localização das tarefas do BigQuery. Em seguida, clique em Carregar tarefas do BigQuery e confirme a caixa de diálogo. Após a conclusão da consulta, é apresentada a lista de tarefas.
São fornecidas informações básicas sobre cada tarefa, incluindo o ID da tarefa, o tipo, a duração e outros detalhes.
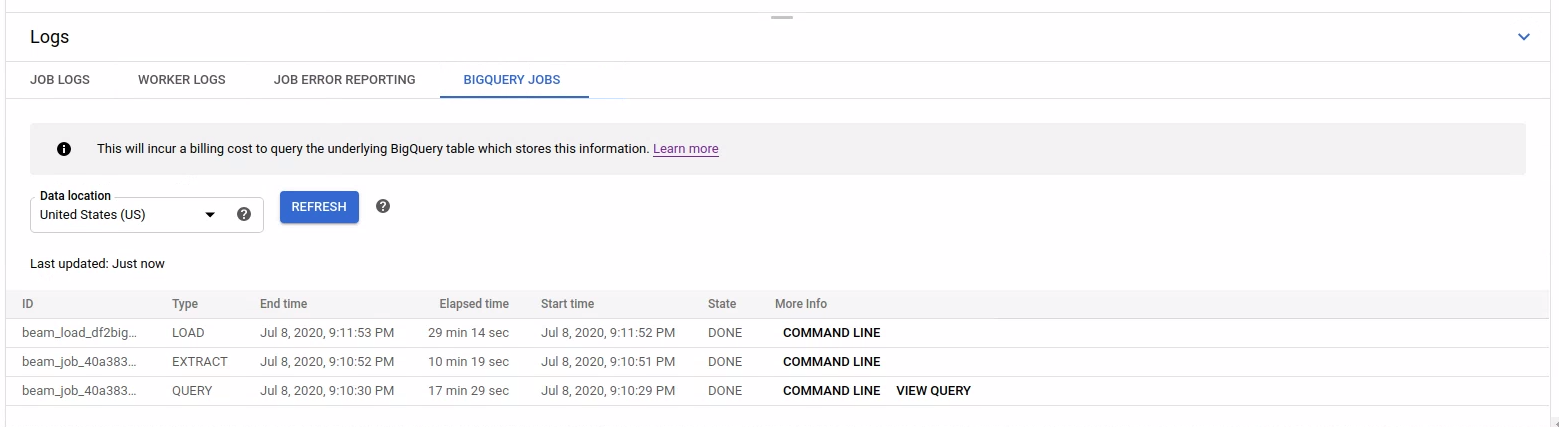
Para ver informações mais detalhadas sobre uma tarefa específica, clique em Linha de comandos na coluna Mais informações.
Na janela modal da linha de comandos, copie o comando bq jobs describe e execute-o localmente ou no Cloud Shell.
gcloud alpha bq jobs describe BIGQUERY_JOB_ID
O comando bq jobs describe produz
JobStatistics,
que fornecem mais detalhes úteis para diagnosticar uma tarefa do BigQuery lenta ou bloqueada.
Em alternativa, quando usa o BigQueryIO com uma consulta SQL, é emitido um trabalho de consulta. Para ver a consulta SQL usada pela tarefa, clique em Ver consulta na coluna Mais informações.
Ver diagnósticos
O separador Diagnósticos do painel Registos recolhe e apresenta determinadas entradas de registo produzidas nos seus pipelines. Estas entradas incluem mensagens que indicam um problema provável com o pipeline e mensagens de erro com rastreios de pilha. As entradas de registo recolhidas são desduplicadas e combinadas em grupos de erros.
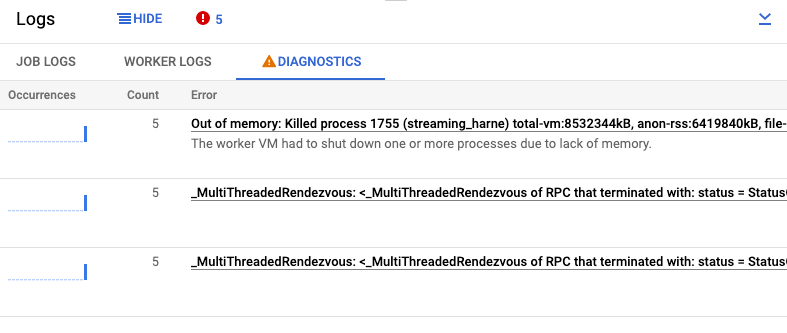
O relatório de erros inclui as seguintes informações:
- Uma lista de erros com mensagens de erro
- O número de vezes que cada erro ocorreu
- Um histograma que indica quando ocorreu cada erro
- A hora em que o erro ocorreu mais recentemente
- A hora em que o erro ocorreu pela primeira vez
- O estado do erro
Para ver o relatório de erros de um erro específico, clique na descrição na coluna Erros. É apresentada a página Relatório de erros. Se o erro for um erro de serviço, é apresentado um link para um guia de resolução de problemas.
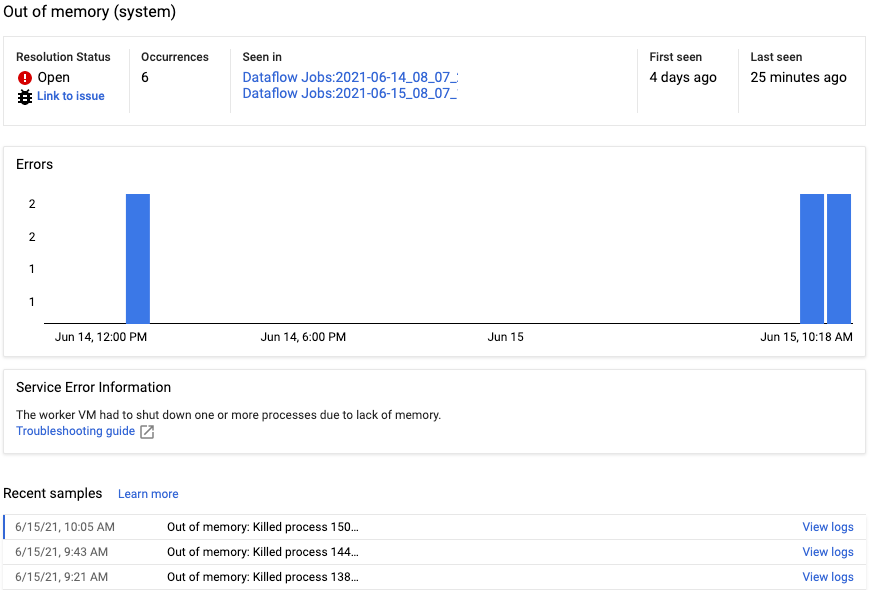
Para saber mais sobre a página, consulte o artigo Veja e filtre erros.
Desative o som de um erro
Para ignorar uma mensagem de erro, siga estes passos:
- Abra o separador Diagnósticos.
- Clique no erro que quer desativar o som.
- Abra o menu de estado de resolução. Os estados têm as seguintes etiquetas: Aberto, Confirmado, Resolvido ou Ignorado.
- Selecione Sem som.