Dataflow collecte des métriques pour vos jobs, ce qui peut vous aider à déboguer les erreurs, à résoudre les problèmes de performances ou à optimiser votre pipeline. L'interface de surveillance Dataflow affiche des visualisations pour ces métriques. Vous pouvez également utiliser Cloud Monitoring pour créer des alertes ou des requêtes dans l'explorateur de métriques.
Accéder aux métriques de job
Pour afficher les métriques d'un job, procédez comme suit :
Dans la console Google Cloud , accédez à la page Dataflow > Tâches.
Sélectionnez une tâche.
Cliquez sur l'onglet Job metrics (Métriques de job).
Sélectionnez une métrique à afficher.
Pour accéder à des informations supplémentaires dans les graphiques de métriques de job, cliquez sur Explorer les données.
Chaque métrique est organisée dans les tableaux de bord suivants :
- Métriques d'autoscaling
- Métriques "Vue d'ensemble"
- Métriques de streaming
- Métriques sur les ressources
- Métriques d'entrée/de sortie
Compatibilité et limites
Assurez-vous de tenir compte des détails suivants lorsque vous utilisez les métriques Dataflow.
Les données des jobs sont parfois indisponibles par intermittence. Lorsque des données sont manquantes, des écarts apparaissent dans les graphiques de surveillance des jobs.
Certains de ces graphiques sont spécifiques aux pipelines de traitement en flux continu.
Pour écrire des données de métriques, un compte de service géré par l'utilisateur doit disposer de l'autorisation IAM
monitoring.timeSeries.createsur l'API. Cette autorisation est incluse dans le rôle "Nœud de calcul Dataflow".Le service Dataflow signale le temps CPU réservé une fois les jobs terminés. Pour les jobs illimités (en streaming), le temps CPU réservé n'est indiqué qu'après l'annulation ou l'échec des jobs. Par conséquent, les métriques de job n'incluent pas le temps CPU réservé pour les jobs traités par flux.
Métriques d'autoscaling
L'autoscaling horizontal permet à Dataflow de choisir le nombre approprié d'instances de nœuds de calcul pour votre job, en ajoutant ou en supprimant des nœuds de calcul selon les besoins.
La section Autoscaling de l'onglet Métriques du job indique le nombre de nœuds de calcul et le nombre cible de nœuds de calcul au fil du temps. Si votre job utilise Streaming Engine, le nombre minimal et maximal de nœuds de calcul s'affiche également.
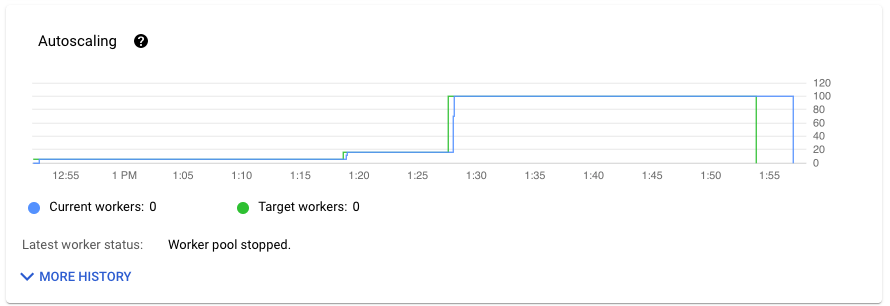
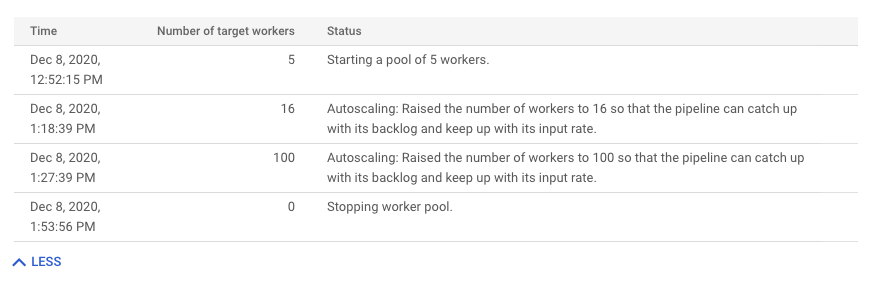
Pour afficher l'historique des modifications de l'autoscaling, cliquez sur Plus d'entrées d'historique. Un tableau s'affiche, qui contient des informations sur l'historique des nœuds de calcul de votre job.
Pour afficher des informations supplémentaires sur l'autoscaling pour les jobs de streaming, cliquez sur l'onglet Autoscaling. Pour en savoir plus, consultez Surveiller l'autoscaling Dataflow.
Métriques générales
Les métriques suivantes s'affichent sous Métriques "Vue d'ensemble".
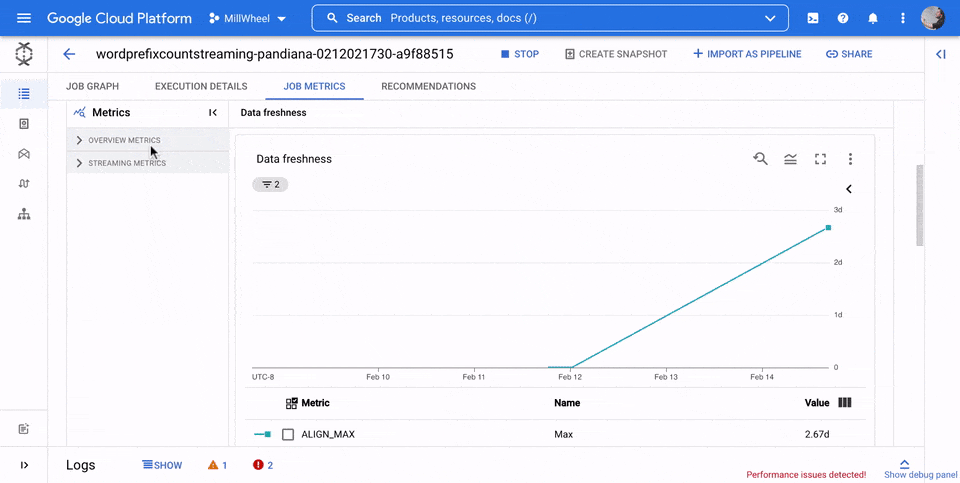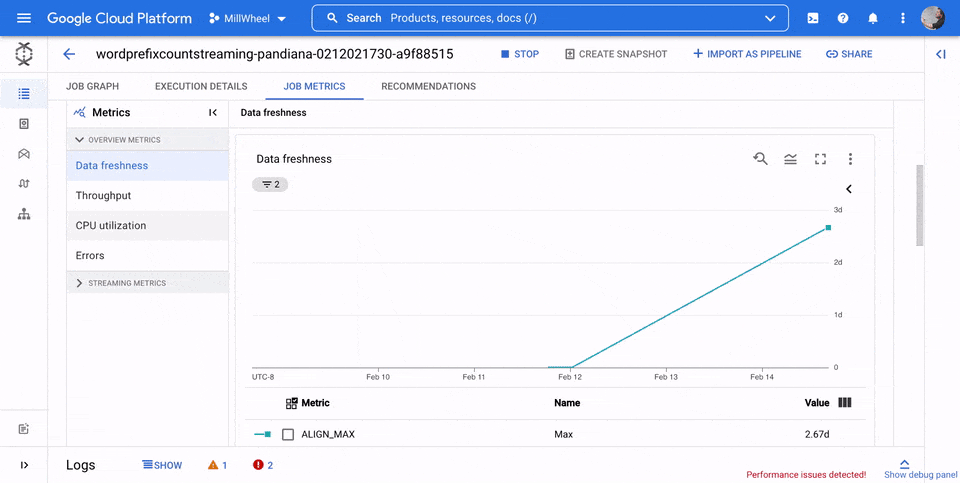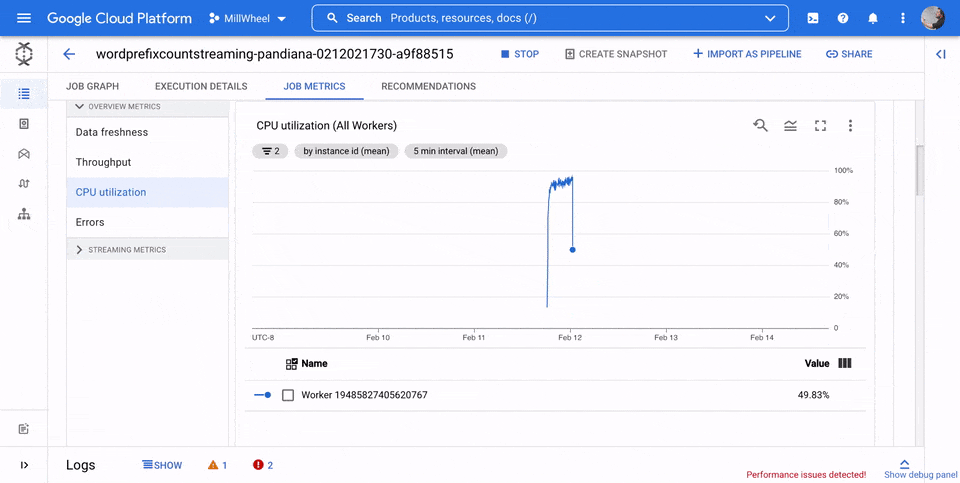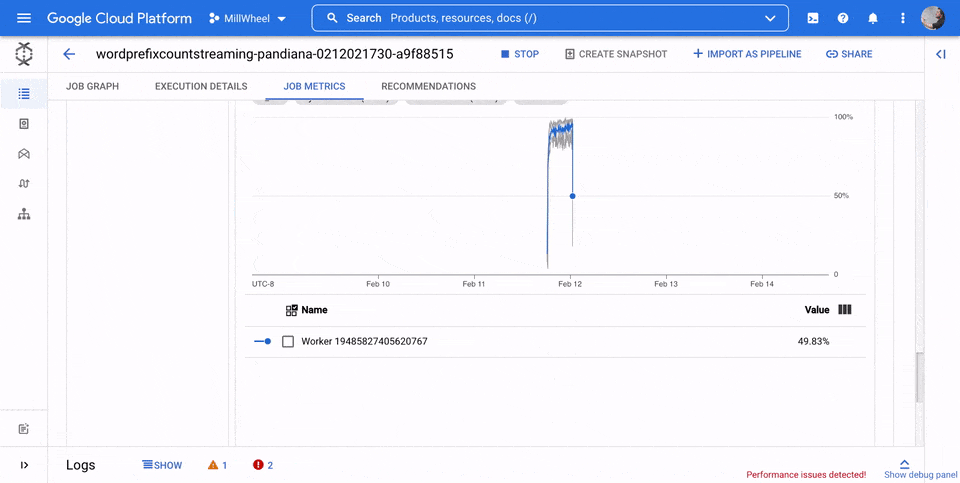
Fraîcheur des données
Cette métrique ne s'applique qu'aux jobs par flux.
La fraîcheur des données correspond à la différence entre le moment où un élément de données est traité (temps de traitement) et l'horodatage de l'élément de données (heure de l'événement). Plus les valeurs sont élevées, plus le délai entre l'heure de l'événement et l'heure de traitement est long.
Le graphique de fraîcheur des données indique la valeur maximale de fraîcheur des données à tout moment. Dataflow traite plusieurs éléments en parallèle. Le graphique reflète donc l'élément avec le délai le plus long par rapport à l'heure de son événement.
Si certaines données d'entrée n'ont pas encore été traitées, le filigrane de sortie peut être retardé, ce qui affecte la fraîcheur des données. Une différence significative entre l'heure du filigrane et l'heure de l'événement peut indiquer une opération lente ou bloquée. Pour en savoir plus, consultez la section Filigranes et données en retard dans la documentation Apache Beam.
Le tableau de bord comprend les deux graphiques suivants :
- Fraîcheur des données par étapes
- Fraîcheur des données
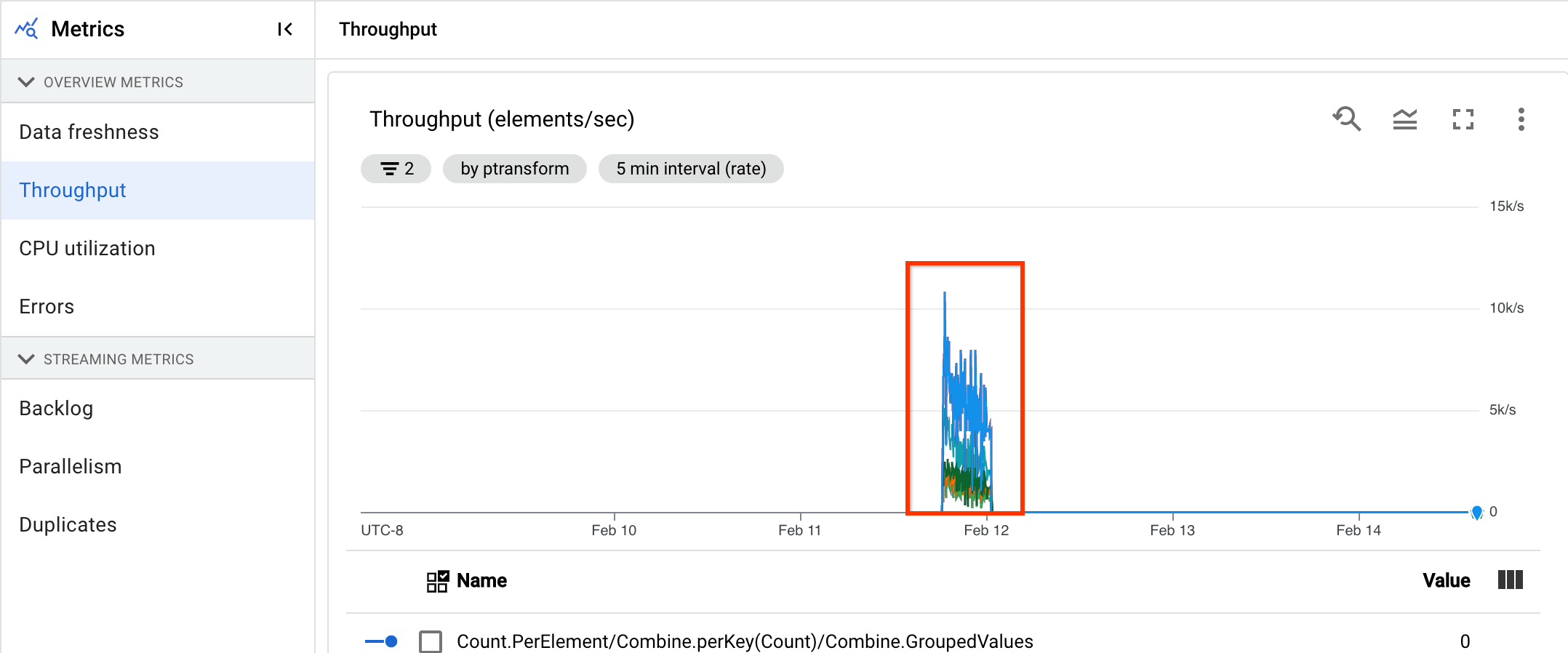
Dans l'image suivante, la zone en surbrillance montre une grande différence entre l'heure de l'événement et l'heure du filigrane de sortie, indiquant une opération lente.
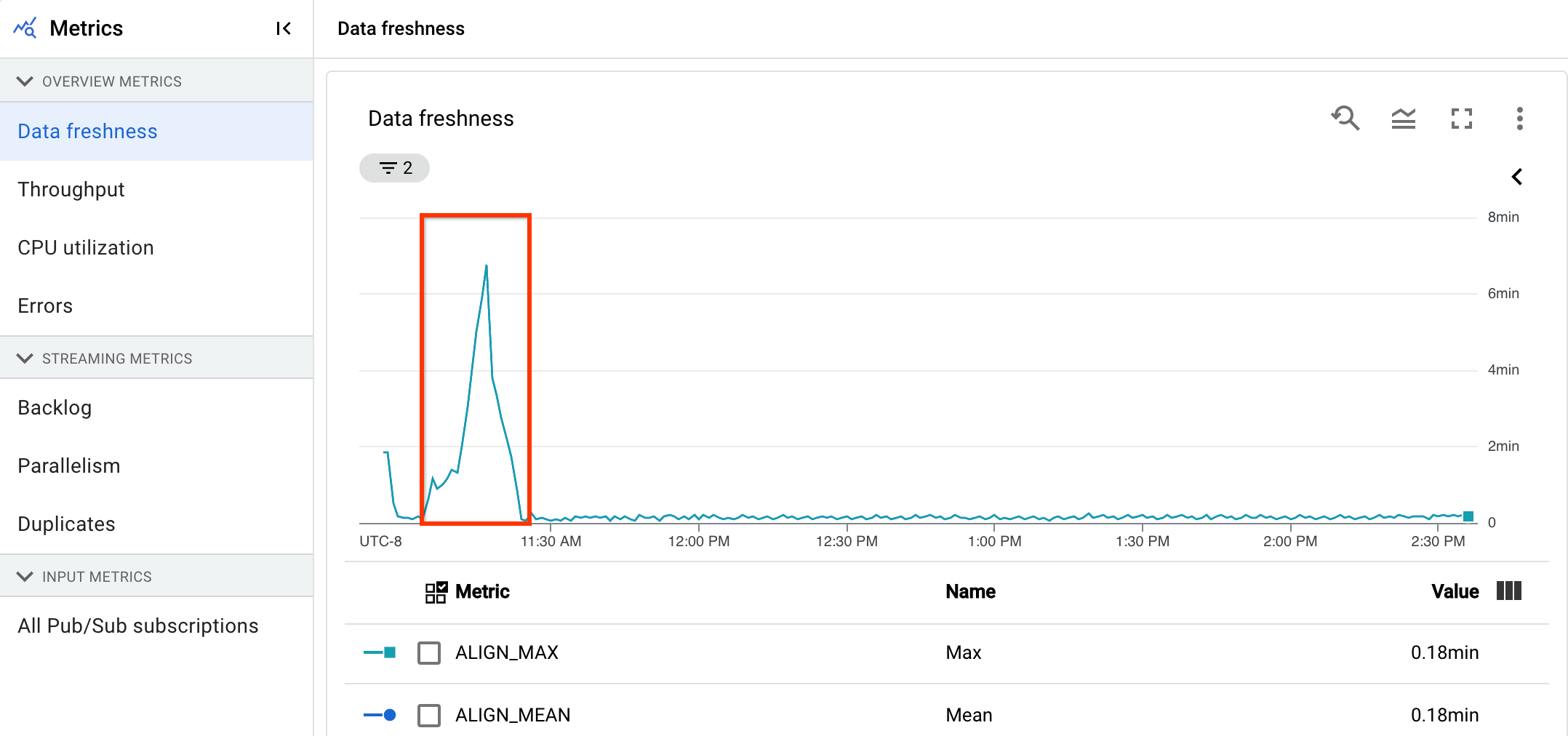
Les problèmes suivants peuvent entraîner des valeurs élevées pour cette métrique :
- Goulots d'étranglement des performances : si votre pipeline comporte des étapes présentant une latence système élevée ou des journaux indiquant des transformations bloquées, le pipeline peut rencontrer des problèmes de performances susceptibles d'améliorer la fraîcheur des données. Pour en savoir plus, consultez Résoudre les problèmes liés aux jobs de traitement en flux continu lents ou bloqués.
- Des goulots d'étranglement des sources de données : si les sources de données présentent des tâches en attente de traitement, les horodatages d'événements de vos éléments peuvent diverger par rapport au filigrane au moment du traitement. Une quantité élevée de tâches en attente est souvent causée par des goulots d'étranglement des performances ou par des problèmes liés aux sources de données, que vous pouvez identifier au mieux en surveillant les sources utilisées par votre pipeline.
- Les sources non ordonnées, telles que Pub/Sub, peuvent produire des filigranes bloqués même en sortie à un taux élevé. Cela est dû au fait que les éléments ne sont pas générés dans l'ordre des codes temporels, et le filigrane est basé sur la valeur minimale du code temporel non traité.
- Nouvelles tentatives : si vous obtenez des erreurs indiquant que les éléments ne peuvent pas être traités et que de nouvelles tentatives sont déclenchées, cela signifie que des horodatages plus anciens d'éléments faisant l'objet de nouvelles tentatives sont en train d'améliorer la fraîcheur des données. La liste des erreurs Dataflow courantes peut vous aider à résoudre les problèmes.
Pour les tâches traitées par flux récemment mises à jour, les informations sur l'état et le filigrane des tâches peuvent être indisponibles. L'opération de mise à jour apporte plusieurs modifications qui mettent quelques minutes à se propager sur l'interface de surveillance de Dataflow. Essayez d'actualiser l'interface de surveillance cinq minutes après la mise à jour de votre job.
Latence du système
Cette métrique ne s'applique qu'aux jobs par flux.
La latence du système correspond au nombre maximal de secondes pendant lequel un élément de données est en cours de traitement ou en attente. Cette métrique indique le délai d'attente des éléments dans une source. Par exemple, si une destination de sortie cesse d'accepter les requêtes d'écriture pendant un certain temps, des données peuvent s'accumuler au niveau de la source, ce qui augmente la latence du système. Si les opérations d'écriture reprennent et que le pipeline peut rattraper son retard, la latence du système revient à son niveau de référence.
Les cas suivants sont également à prendre en considération :
- S'il existe plusieurs sources et récepteurs, la latence du système correspond au délai d'attente maximum d'un élément dans une source avant qu'il ne soit écrit dans tous les récepteurs.
- Parfois, une source ne fournit pas de valeur pour la période pendant laquelle un élément est en attente dans la source. En outre, l'élément peut ne pas avoir de métadonnées permettant de définir son heure d'événement. Dans ce scénario, la latence du système est calculée à partir du moment où le pipeline reçoit l'élément.
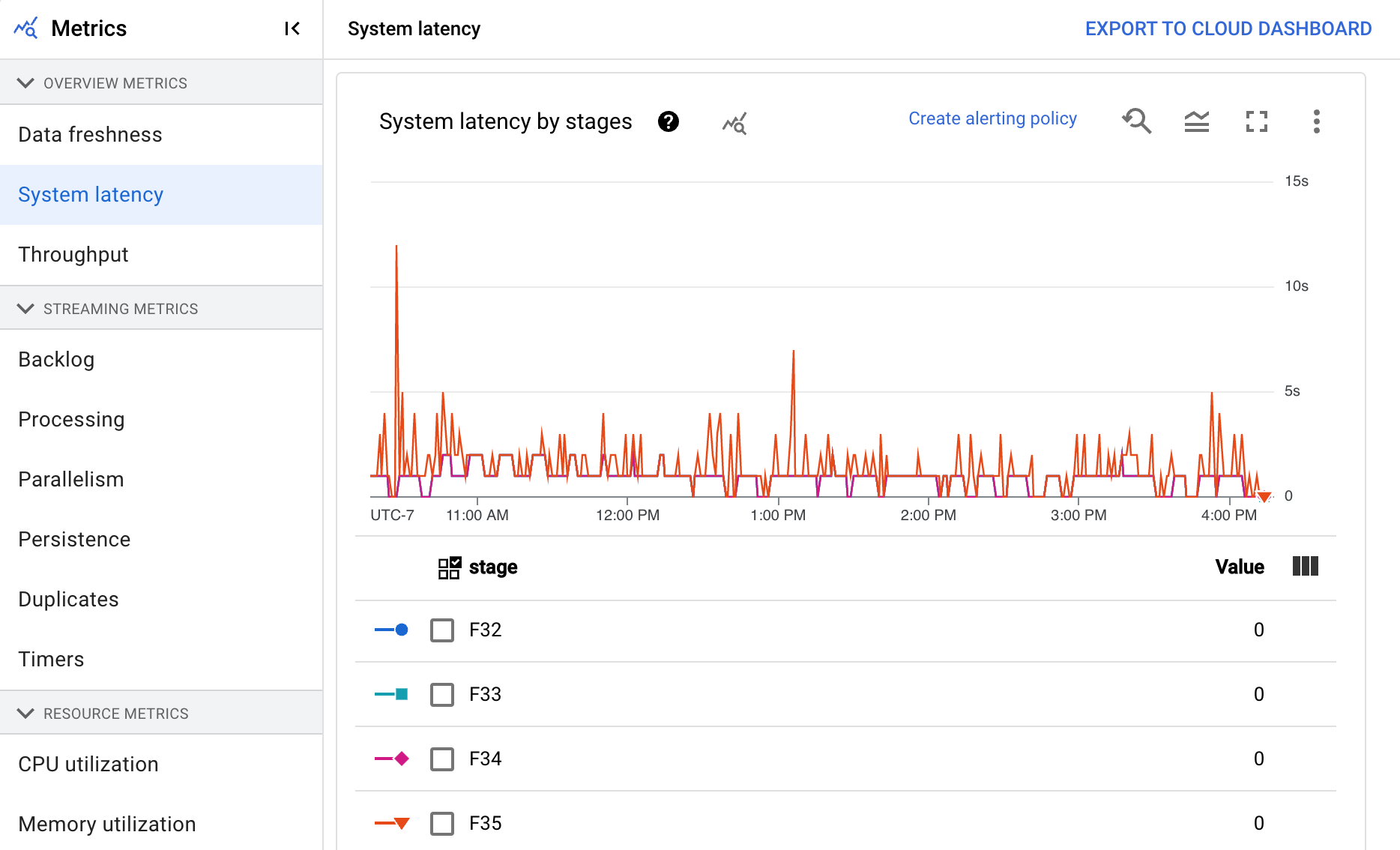
Le tableau de bord comprend les deux graphiques suivants :
- Latence du système par étapes
- Latence du système
Débit
Le débit correspond au volume de données traitées à tout moment. Le tableau de bord comprend les graphiques suivants :
- Débit par étape en éléments par seconde
- Débit par étape en octets par seconde
Décompte de journal d'erreur de nœud de calcul
Le volet Worker error log count (Décompte de journal d'erreur de nœud de calcul) indique le taux d'erreurs observées sur tous les nœuds de calcul à tout moment.

Métriques de flux continu
Les métriques suivantes s'affichent sous Métriques de streaming.
En attente
Cette métrique ne s'applique qu'aux jobs par flux.
Le tableau de bord En attente fournit des informations sur les éléments en attente de traitement. Le tableau de bord comprend les deux graphiques suivants :
- Secondes en attente (Streaming Engine uniquement)
- Octets en attente (avec et sans Streaming Engine)
Le graphique secondes en attente fournit une estimation du temps en secondes nécessaire pour absorber les tâches en attente actuelles si aucune nouvelle donnée n'arrive, et que le débit ne change pas. Le temps d'attente estimé est calculé à partir du débit et des octets en attente de la source d'entrée à traiter. Cette métrique est utilisée par la fonctionnalité d'autoscaling de flux pour déterminer quand effectuer un scaling à la hausse ou à la baisse.
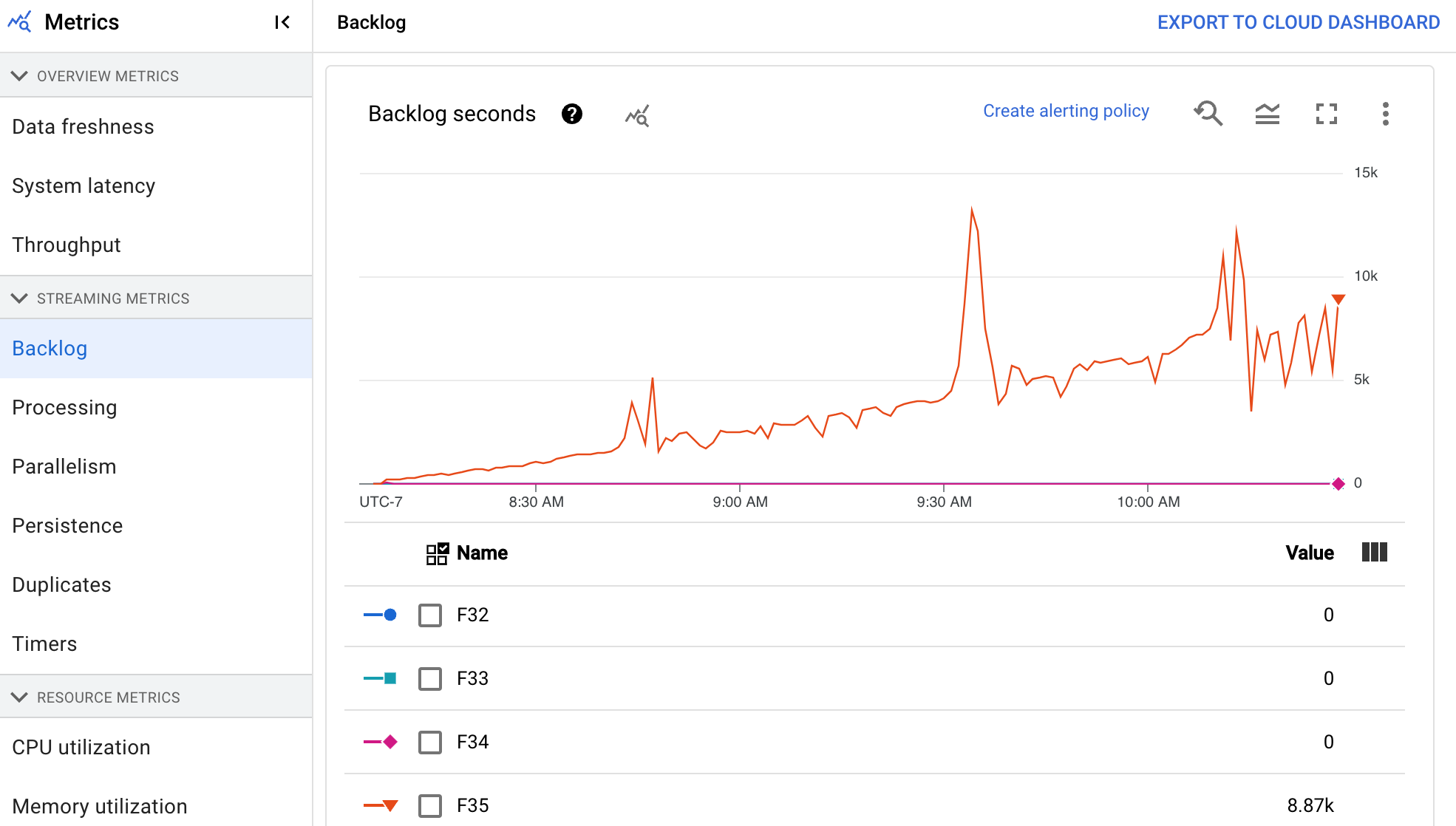
Le graphique Octets en attente indique la quantité d'entrées non traitées connues pour une étape en octets. Cette métrique compare les octets restants à utiliser par chaque étape par rapport aux étapes en amont. Pour que cette métrique soit signalée avec précision, chaque source ingérée par le pipeline doit être configurée correctement. Les sources natives telles que Pub/Sub et BigQuery sont déjà compatibles directement. Cependant, les sources personnalisées nécessitent une mise en œuvre supplémentaire. Pour en savoir plus, consultez la section Autoscaling des sources illimitées personnalisées.
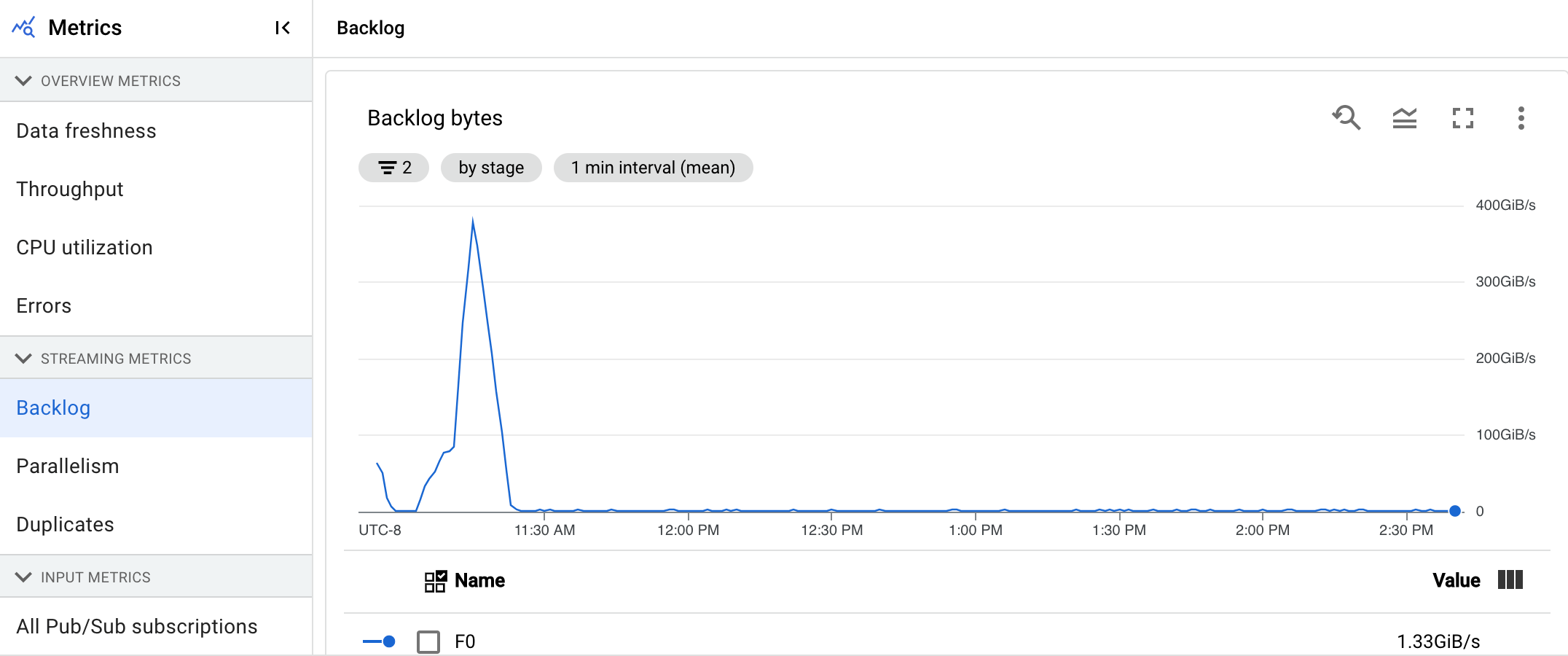
Traitement
Cette métrique ne s'applique qu'aux jobs par flux.
Lorsque vous exécutez un pipeline Apache Beam sur le service Dataflow, les tâches de pipeline sont exécutées sur des VM de nœud de calcul. Le tableau de bord Traitement fournit des informations sur la durée pendant laquelle les tâches ont été traitées sur les VM de nœud de calcul. Le tableau de bord comprend les deux graphiques suivants :
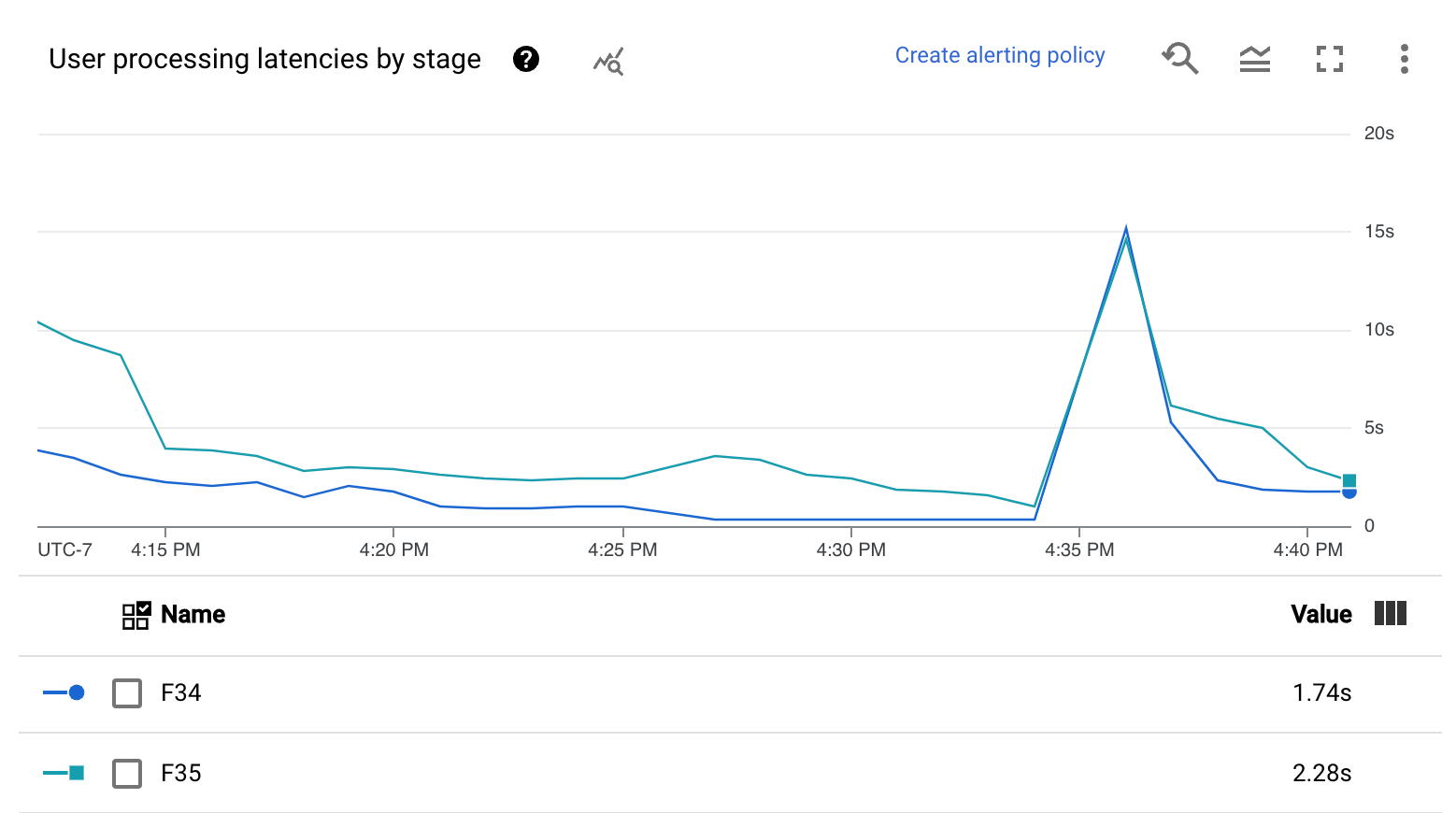
- Carte de densité des latences de traitement des utilisateurs
- Latences de traitement des utilisateurs par étape
La carte de densité des latences de traitement des utilisateurs indique les latences maximales des opérations sur les distributions des 50e, 95e et 99e centiles. utilisez la carte de densité pour voir si des opérations à longue traîne entraînent une latence globale du système élevée ou ont un impact négatif sur la fraîcheur globale des données.
Pour résoudre un problème en amont avant qu'il ne devienne un problème en aval, définissez une règle d'alerte pour les latences élevées au 50e centile.
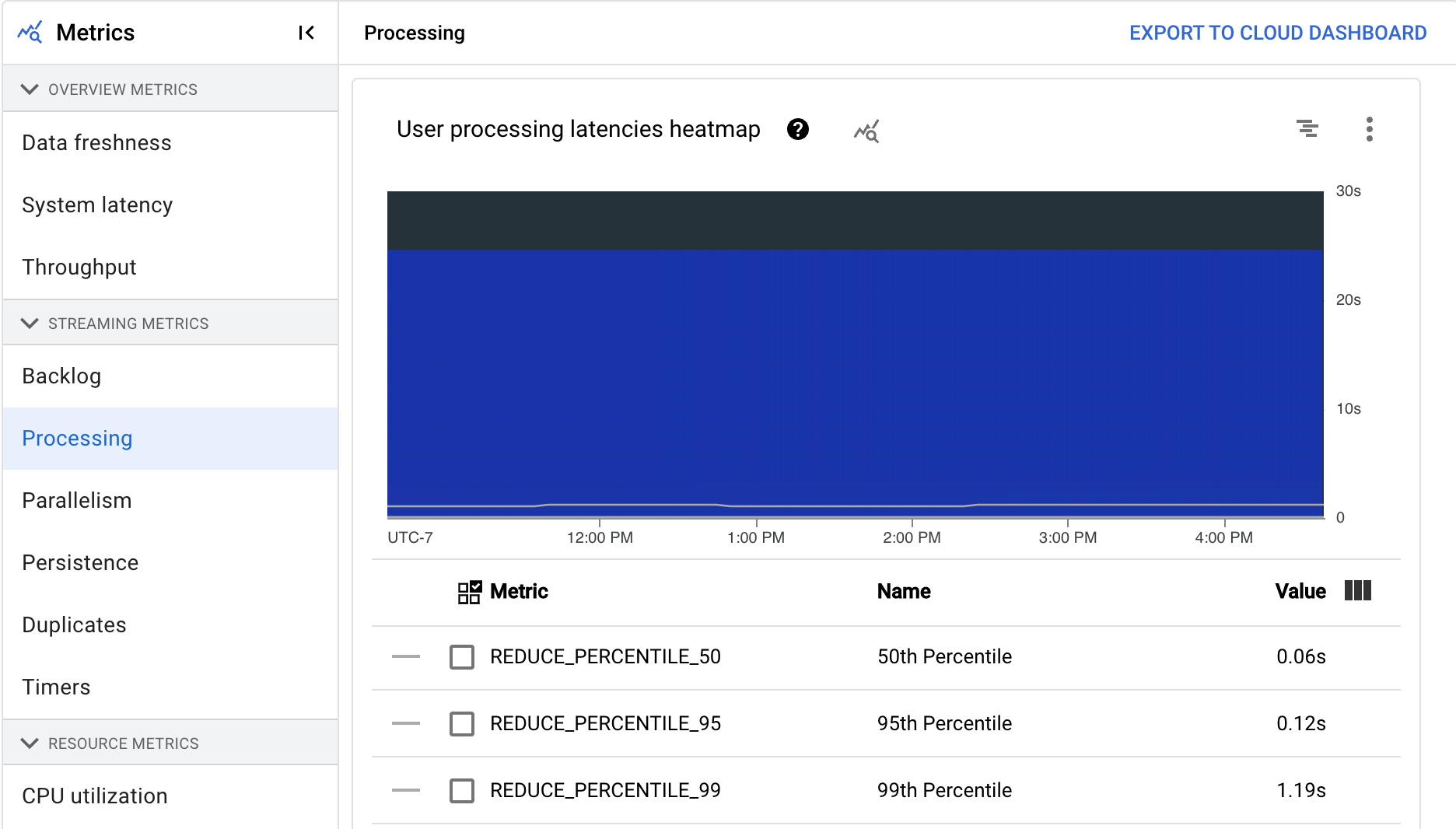
Le graphique Latences de traitement des utilisateurs par étape indique le 99e centile pour toutes les tâches traitées par les nœuds de calcul réparties par étape. Si le code utilisateur est à l'origine d'un goulot d'étranglement, ce graphique indique l'étape qui contient le goulot d'étranglement. Vous pouvez suivre les étapes ci-dessous pour déboguer le pipeline :
Utilisez le graphique pour identifier une étape présentant une latence inhabituellement élevée.
Sur la page des détails de la tâche, dans l'onglet Détails d'exécution, pour Vue graphique, sélectionnez Workflow des étapes. Dans le graphique Workflow des étapes, identifiez la phase présentant une latence inhabituellement élevée.
Pour trouver les opérations utilisateur associées, cliquez sur le nœud de cette étape dans le graphique.
Pour obtenir des informations supplémentaires, accédez à Cloud Profiler, puis utilisez Cloud Profiler pour déboguer la trace de la pile à la bonne période. Recherchez les opérations utilisateur que vous avez identifiées à l'étape précédente.
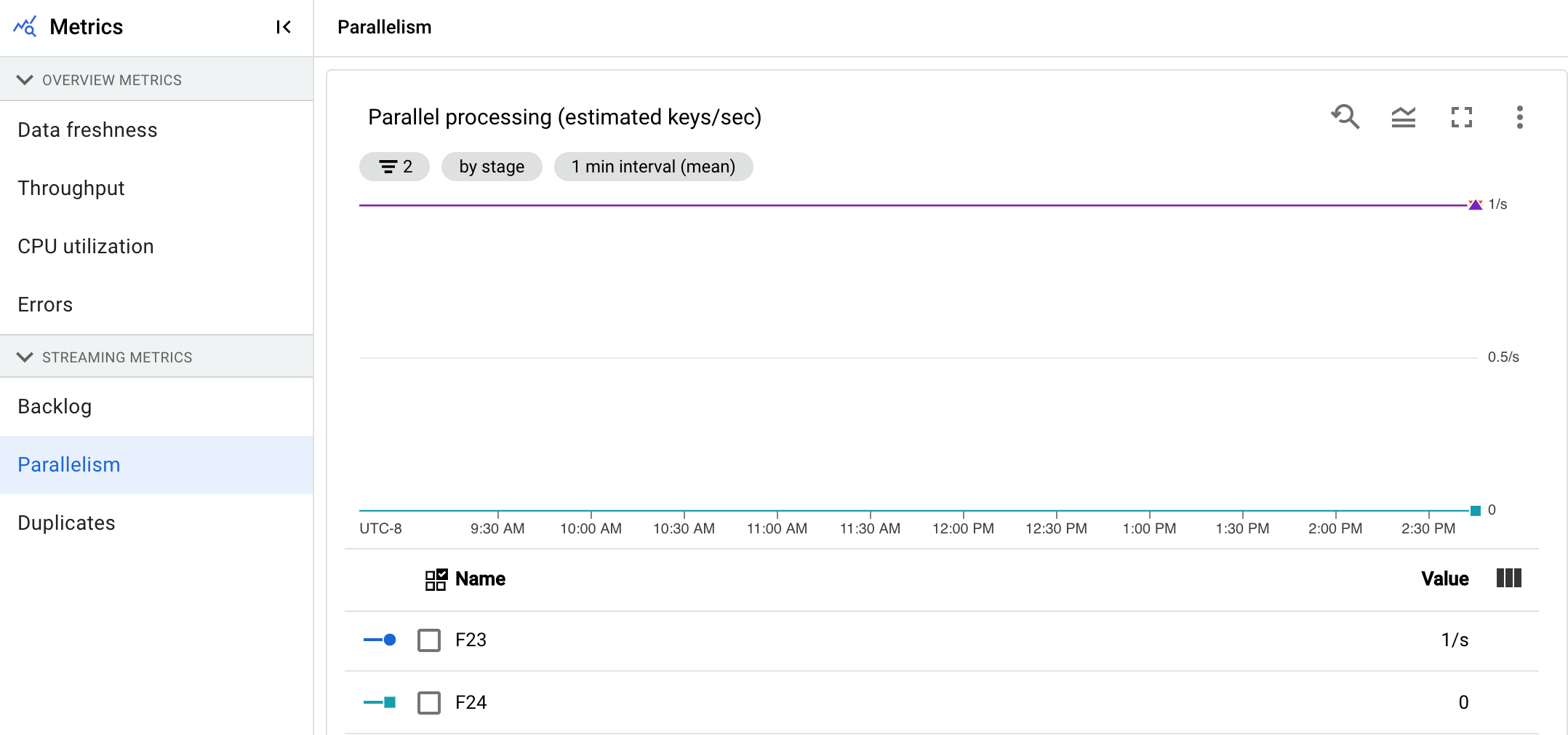
Parallélisme
Cette métrique ne s'applique qu'aux jobs Streaming Engine.
Le graphique de Traitement en parallèle indique le nombre approximatif de clés utilisées pour le traitement des données pour chaque étape. Dataflow effectue le scaling en fonction du parallélisme d'un pipeline.
Lorsque Dataflow exécute un pipeline, le traitement est réparti sur plusieurs machines virtuelles (VM) Compute Engine, également appelées nœuds de calcul. Le service Dataflow parallélise la logique de traitement de votre pipeline et la distribue automatiquement aux nœuds de calcul. Le traitement d'une clé donnée est sérialisé. Le nombre total de clés pour une phase représente donc le parallélisme disponible maximal à cette étape.
Les métriques de parallélisme peuvent être utiles pour rechercher des clés en zone chaude ou des goulots d'étranglement pour des pipelines lents ou bloqués.
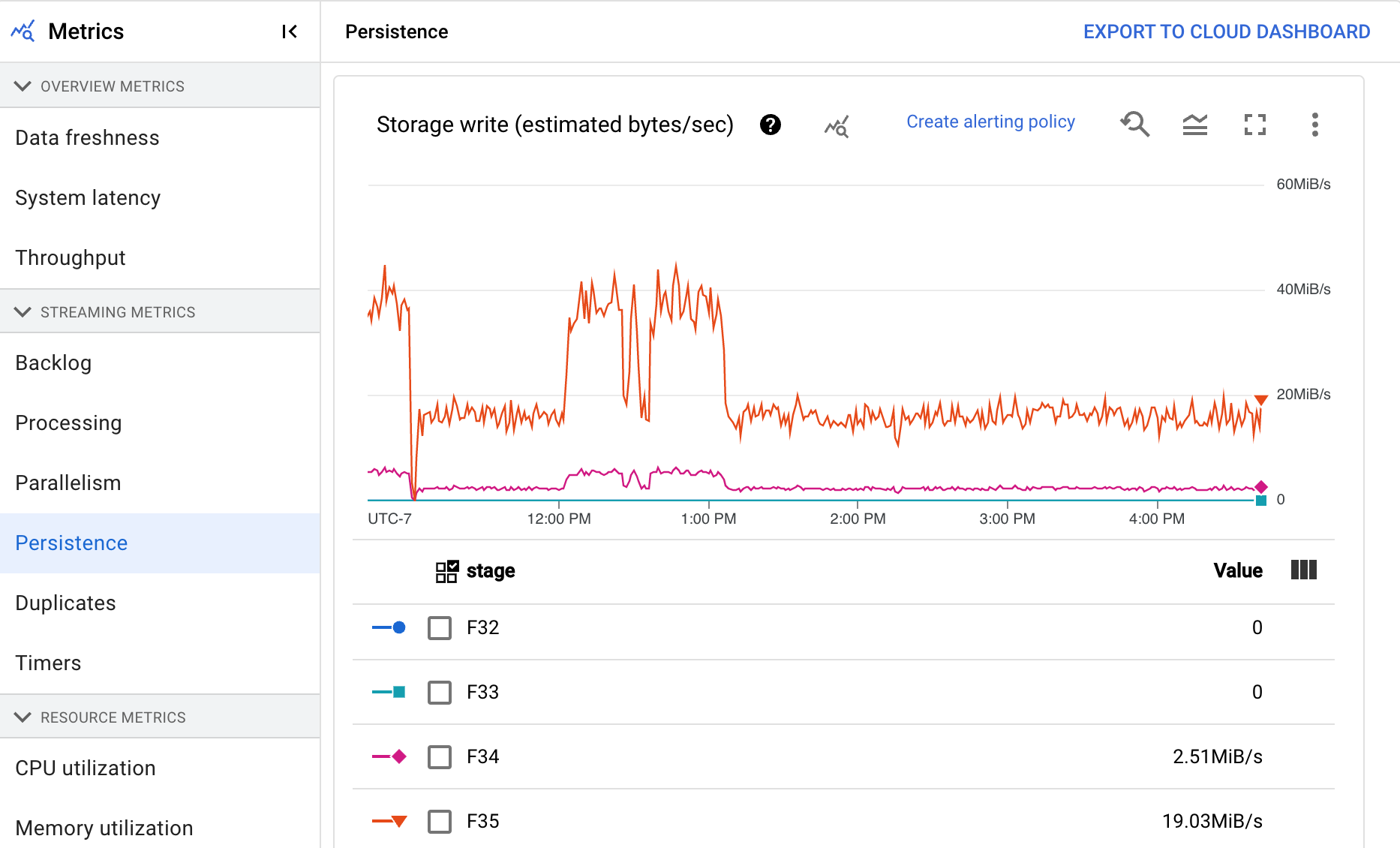
Persistance
Cette métrique ne s'applique qu'aux jobs par flux.
Le tableau de bord Persistance fournit des informations sur la vitesse de lecture et d'écriture (en octets par seconde) sur le stockage persistant, par une étape de pipeline spécifique. Les octets lus et écrits incluent les opérations sur l'état de l'utilisateur et l'état des mélanges persistants, la suppression des doublons, les entrées secondaires et le suivi des filigranes. Les codeurs de pipeline et la mise en cache ont une influence sur les octets lus et écrits. Les octets de stockage peuvent différer des octets traités en raison de l'utilisation du stockage interne et de la mise en cache.
Le tableau de bord comprend les deux graphiques suivants :
- Écriture du stockage
- Lecture du stockage
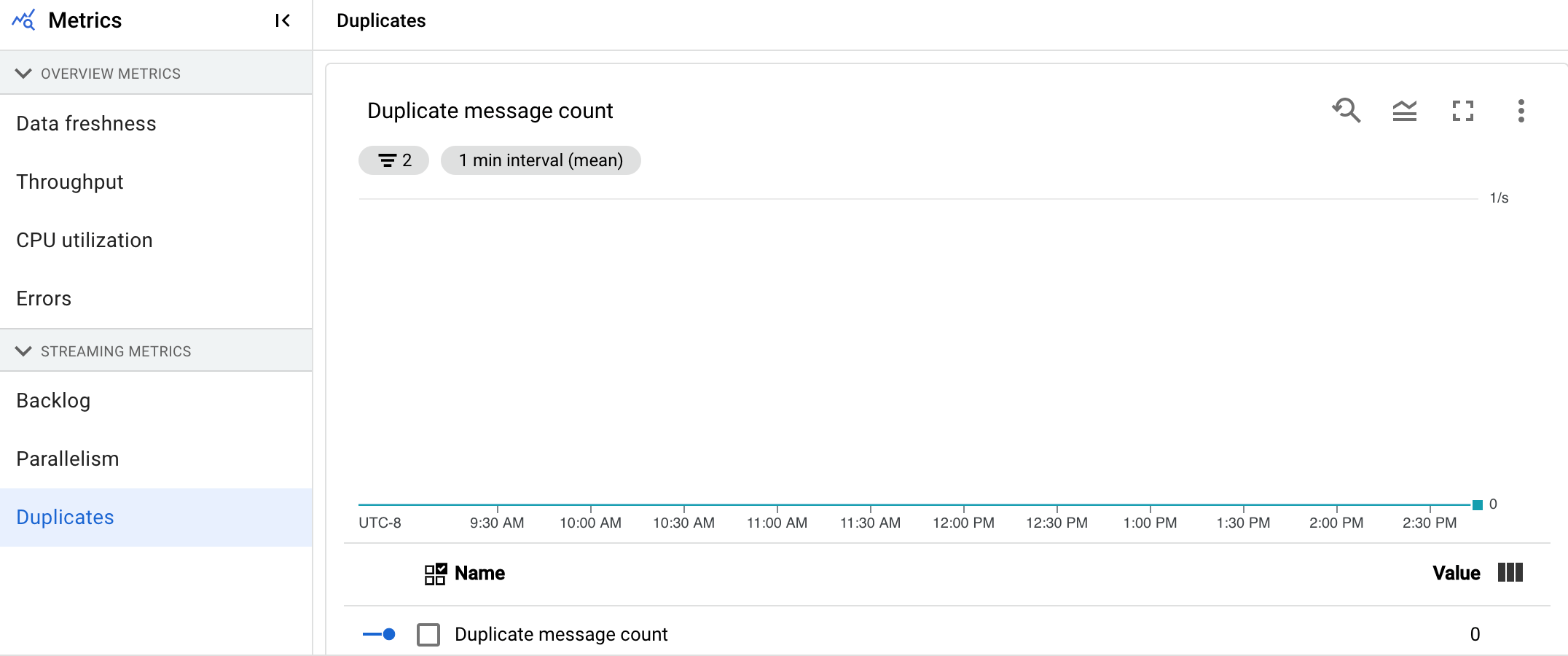
Doublons
Cette métrique ne s'applique qu'aux jobs par flux.
Le graphique Dupliquer indique le nombre de messages traités par une étape spécifique qui ont été filtrés en tant que doublons.
Dataflow est compatible avec de nombreuses sources et récepteurs qui garantissent la distribution de at least once. L'inconvénient de la distribution de at least once est qu'elle peut entraîner des doublons.
Dataflow garantit la distribution de exactly once, ce qui signifie que les doublons sont automatiquement filtrés.
Les étapes en aval sont sauvegardées lors du retraitement des mêmes éléments, ce qui garantit que l'état et les sorties ne sont pas affectés.
Vous pouvez optimiser le pipeline pour optimiser les ressources et les performances en réduisant le nombre de doublons générés à chaque étape.
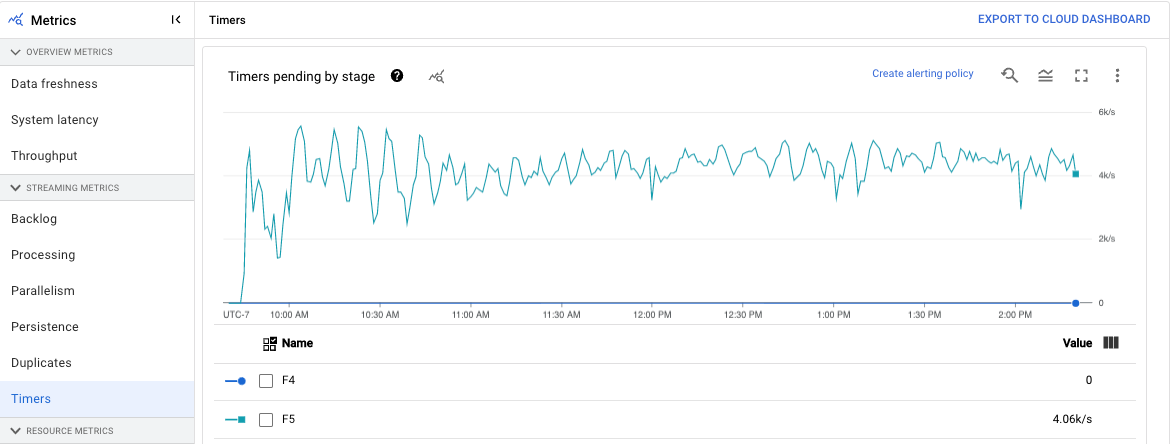
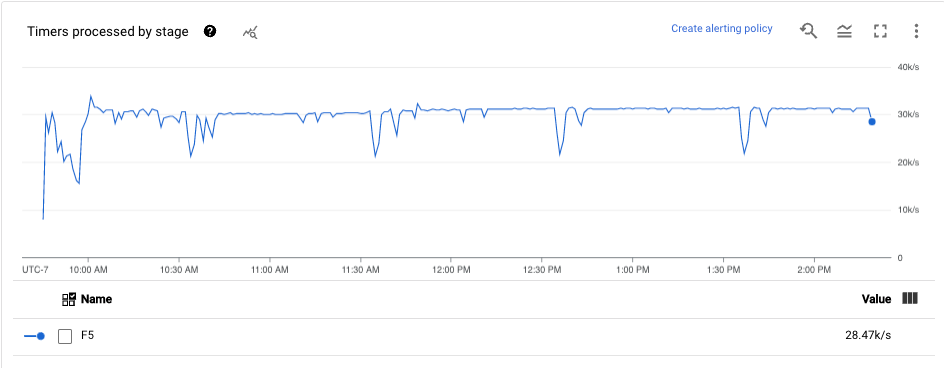
Minuteurs
Cette métrique ne s'applique qu'aux jobs par flux.
Le tableau de bord Minuteurs fournit des informations sur le nombre de minuteurs en attente et sur le nombre de minuteurs déjà traités dans une étape spécifique du pipeline. Cette métrique vous permet de suivre la progression des périodes, étant donné que celles-ci reposent sur des minuteurs.
Le tableau de bord comprend les deux graphiques suivants :
- Minuteurs en attente par étape
- Traitement des minuteurs par étape
Ces graphiques indiquent la fréquence à laquelle les périodes sont en attente ou en cours de traitement à un moment précis. Le graphique Timers pending by stage (Minuteurs en attente par étape) indique le nombre de périodes retardées en raison de goulots d'étranglement. Le graphique Timers processing by stage (Traitement des minuteurs par étape) indique le nombre de périodes en cours de collecte d'éléments.
Ces graphiques affichent tous les minuteurs de tâche. Par conséquent, si des minuteurs sont utilisés ailleurs dans votre code, ces minuteurs apparaissent également dans ces graphiques.
Métriques sur les ressources
Les métriques suivantes s'affichent sous Métriques sur les ressources.
Utilisation du processeur
L'utilisation du processeur correspond à la quantité de processeur utilisée, divisée par la quantité de processeur disponible pour le traitement. Cette métrique par nœud de calcul est affichée sous forme de pourcentage. Le tableau de bord comprend les quatre graphiques suivants :
- Utilisation du processeur (tous les nœuds de calcul)
- Utilisation du processeur (statistiques)
- Utilisation du processeur (les quatre plus élevés)
- Utilisation du processeur (les quatre plus faibles)
Utilisation de la mémoire
L'utilisation de la mémoire correspond à la quantité estimée de mémoire utilisée par les nœuds de calcul en octets par seconde. Le tableau de bord comprend les deux graphiques suivants :
- Utilisation maximale de la mémoire des nœuds de calcul (estimation en octets par seconde)
- Utilisation de la mémoire (estimation en octets par seconde)
Le graphique Utilisation maximale de la mémoire des nœuds de calcul fournit des informations sur les nœuds de calcul qui utilisent le plus de mémoire dans la tâche Dataflow à chaque instant. Si, à différents moments d'un job, le nœud de calcul utilisant la quantité maximale de mémoire change, une même ligne de graphique va afficher les données de plusieurs nœuds de calcul. Chaque point de données de la ligne affiche les données du nœud de calcul utilisant la quantité maximale de mémoire à ce moment-là. Le graphique compare l'estimation de la mémoire utilisée par le nœud de calcul à la limite de mémoire en octets.
Vous pouvez utiliser ce graphique pour résoudre les problèmes de mémoire saturée (OOM, Out Of Memory). Les plantages des nœuds de calcul dus à la mémoire saturée ne sont pas affichés dans ce graphique.
Le graphique Utilisation de la mémoire indique une estimation de la mémoire utilisée par tous les nœuds de calcul de la tâche Dataflow par rapport à la limite de mémoire en octets.
Métriques d'entrée et de sortie
Si votre job Dataflow de traitement en flux continu lit ou écrit des enregistrements à l'aide de Pub/Sub, l'onglet Métriques de job affiche les métriques pour les lectures ou les écritures Pub/Sub.
Toutes les métriques d'entrée du même type sont combinées, et toutes les métriques de sortie. Par exemple, toutes les métriques Pub/Sub sont regroupées dans une section. Chaque type de métrique est organisé en une section distincte. Pour modifier les métriques affichées, sélectionnez la section à gauche qui correspond le mieux aux métriques que vous recherchez. Les images suivantes montrent toutes les sections disponibles.
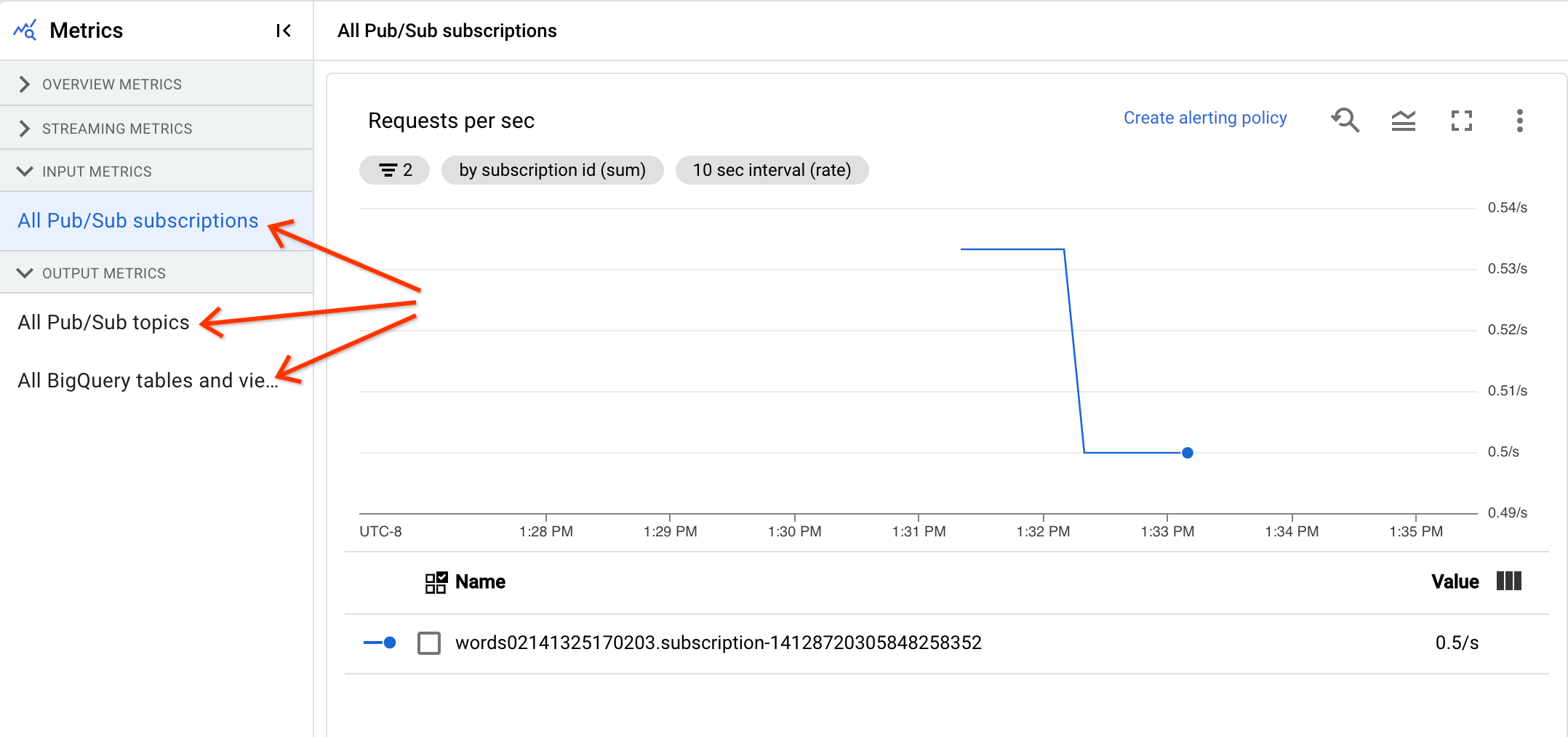
Les deux graphiques suivants sont affichés à la fois dans les sections Métriques d'entrée et Métriques de sortie.
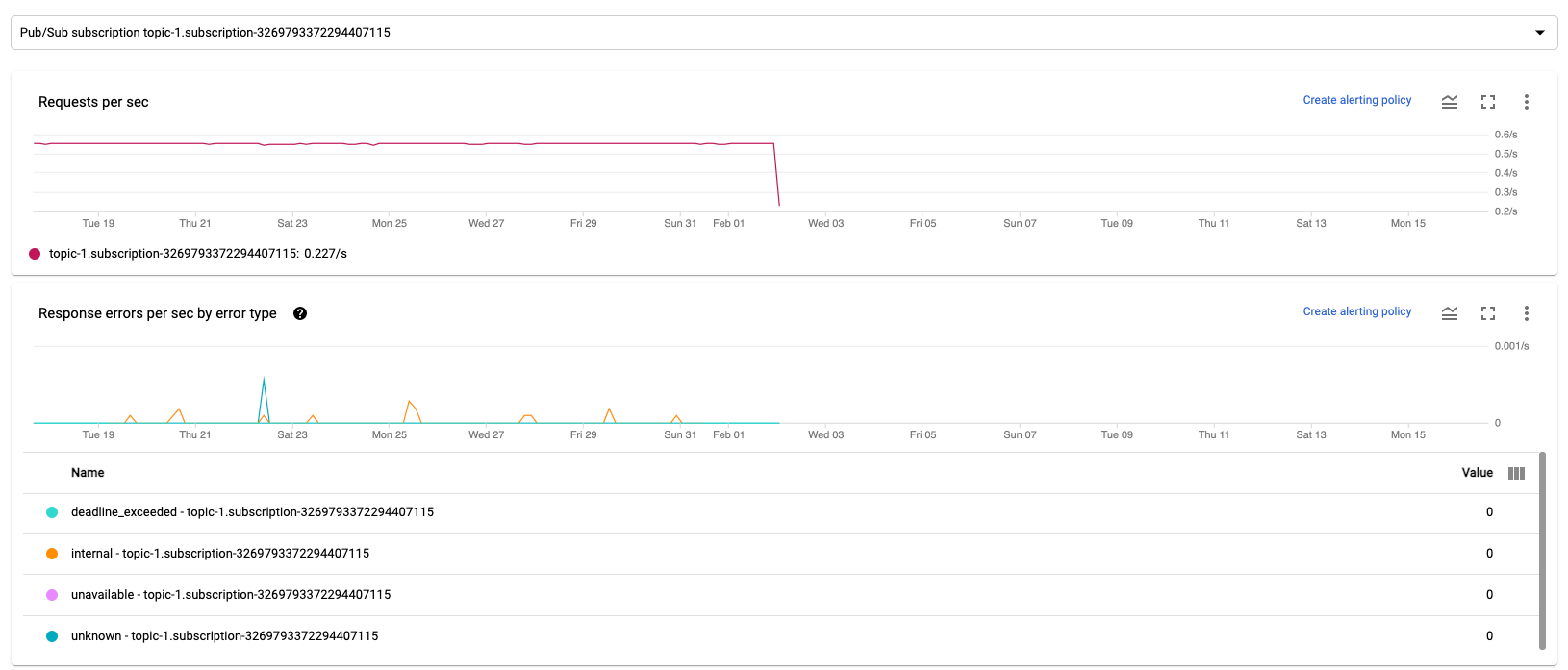
Requêtes par seconde
Le nombre de requêtes par seconde correspond au taux des requêtes API de lecture ou d'écriture de données de la source ou du récepteur au fil du temps. Si ce taux est égal à zéro ou diminue de manière significative pendant une période prolongée par rapport au comportement attendu, le pipeline risque d'être bloqué pour exécuter certaines opérations. Il est également possible qu'il n'y ait aucune donnée à lire. Dans ce cas, nous vous recommandons d'examiner les étapes comportant un filigrane système élevé. Examinez également les journaux du nœud de calcul pour identifier les erreurs ou les éléments indiquant que le traitement est lent.

Erreurs de réponse par seconde et par type
Le nombre d'erreurs de réponse par seconde et par type d'erreur correspond au taux d'échec des requêtes API de lecture ou d'écriture de données de la source ou du récepteur au fil du temps. Si de telles erreurs se produisent fréquemment, ces requêtes API peuvent ralentir le traitement. Ces requêtes API en échec doivent être examinées. Pour résoudre ces problèmes, consultez les codes d'erreur d'entrée et de sortie. Consultez également la documentation spécifique sur les codes d'erreur utilisés par la source ou le récepteur, tels que les codes d'erreur Pub/Sub.

Pour en savoir plus sur les scénarios dans lesquels vous pouvez utiliser ces métriques pour le débogage, consultez la section Outils de débogage dans "Résoudre les problèmes liés aux jobs lents ou bloqués".
Utilisez Cloud Monitoring
Dataflow est entièrement intégré à Cloud Monitoring. Utilisez Cloud Monitoring pour les tâches suivantes :
- Créer des alertes lorsque votre job dépasse un seuil défini par l'utilisateur.
- Utiliser l'Explorateur de métriques pour créer des requêtes, et ajuster la période des métriques.
- Affichez les métriques qui n'apparaissent pas dans l'interface de surveillance Dataflow.
Pour obtenir des instructions sur la création d'alertes et l'utilisation de l'Explorateur de métriques, consultez la page Utiliser Cloud Monitoring pour les pipelines Dataflow.
Pour obtenir la liste complète des métriques Dataflow, consultez la documentation sur les métriques Google Cloud Platform.
Créer des alertes Cloud Monitoring
Cloud Monitoring vous permet de créer des alertes lorsque votre job Dataflow dépasse un seuil défini par l'utilisateur. Pour créer une alerte Cloud Monitoring à partir d'un graphique de métriques, cliquez sur Créer une règle d'alerte.
Si vous ne parvenez pas à afficher les graphiques de surveillance ou à créer des alertes, vous avez peut-être besoin d'autorisations Monitoring supplémentaires.
Afficher dans l'Explorateur de métriques
Vous pouvez afficher les graphiques des métriques Dataflow dans l'Explorateur de métriques, dans lequel vous pouvez aussi créer des requêtes et ajuster la période des métriques.
Pour afficher les graphiques Dataflow dans l'explorateur de métriques, dans la vue Métriques de job, ouvrez Autres options des graphiques et cliquez sur Afficher dans l'Explorateur de métriques.
Lorsque vous ajustez la période des métriques, vous pouvez sélectionner une durée prédéfinie ou un intervalle de temps personnalisé pour analyser votre job.
Par défaut, pour les jobs par flux et les jobs par lot en cours, l'affichage affiche les six heures précédentes de métriques pour ce job. Pour les jobs par flux arrêtés ou terminés, l'affichage par défaut affiche l'intégralité de l'environnement d'exécution de la durée du job.
Métriques d'E/S Dataflow
Vous pouvez afficher les métriques d'E/S Dataflow suivantes dans l'explorateur de métriques :
job/pubsub/write_count: requêtes de publication Pub/Sub provenant de PubsubIO.Write dans les tâches Dataflow.job/pubsub/read_count: requêtes d'extraction Pub/Sub provenant de Pubsub.IO.Read dans les tâches Dataflow.job/bigquery/write_count: requêtes de publication BigQuery provenant de BigQueryIO.Write dans les tâches Dataflow. Les métriquesjob/bigquery/write_countsont disponibles dans les pipelines Python à l'aide de la transformation WriteToBigQuery avecmethod='STREAMING_INSERTS'activé sur Apache Beam v2.28.0 ou version ultérieure. Cette métrique est disponible pour les pipelines de traitement par lot et par flux.- Si votre pipeline utilise une source ou un récepteur BigQuery, vous pouvez utiliser les métriques de l'API BigQuery Storage pour résoudre les problèmes de quota.
Métriques DoFn
Pour les jobs de traitement en flux continu qui utilisent Streaming Engine et non Runner v2, vous pouvez afficher les métriques suivantes pour chaque DoFns défini par l'utilisateur :
job/dofn_latency_average: temps de traitement moyen d'un seulDoFnau cours de la période de trois minutes précédente, en millisecondes.job/dofn_latency_max: durée maximale de traitement d'un seulDoFnau cours de la période de trois minutes précédente, en millisecondes.job/dofn_latency_min: temps de traitement minimal d'un seulDoFnau cours de la période de trois minutes précédente, en millisecondes.job/dofn_latency_num_messages: nombre de messages traités par un seulDoFnau cours des trois dernières minutes.job/dofn_latency_total: temps de traitement total des messages pour tous les messages d'un mêmeDoFnau cours de la fenêtre de trois minutes précédente, en millisecondes.job/oldest_active_message_age: durée de traitement du message actif le plus ancien dans unDoFn, en millisecondes.
Ces métriques nécessitent le SDK Apache Beam version 2.53.0 ou ultérieure. Pour afficher ces métriques, utilisez l'explorateur de métriques.
Vous pouvez utiliser ces métriques pour identifier les DoFns qui contribuent le plus à la latence de traitement de vos jobs. Par exemple, si un job est bloqué, utilisez la métrique job/oldest_active_message_age pour trouver le DoFn avec le message actif le plus ancien. L'image suivante montre un DoFn avec un pic important dans cette métrique :
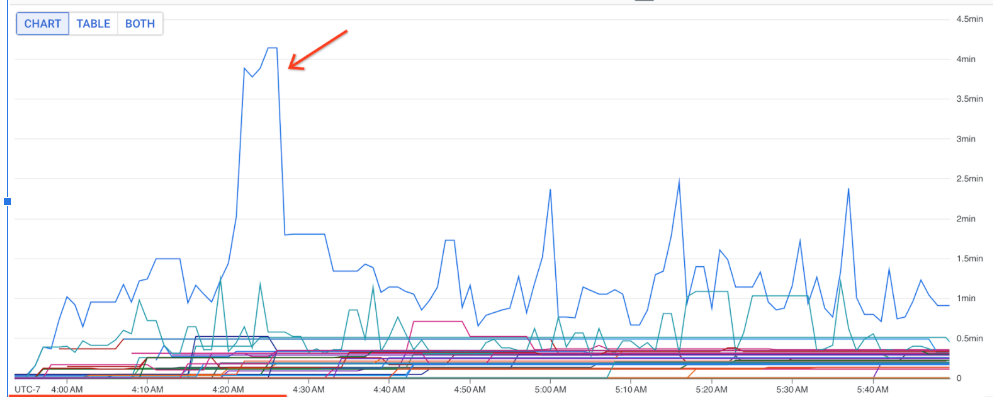
Pour afficher le nom de DoFn, pointez sur la ligne du graphique.
Étapes suivantes
- Résolvez les problèmes liés aux jobs de traitement en flux continu lents ou bloqués.
- Résolvez les problèmes liés aux jobs par lot lents ou bloqués.
- Ajuster l'autoscaling horizontal pour les pipelines de traitement en flux continu
- Optimiser les coûts