Dopo aver creato e archiviato il modello Dataflow in un'area intermedia, esegui il modello con la console Google Cloud , l'API REST o Google Cloud CLI. Puoi eseguire il deployment dei job del modello Dataflow da molti ambienti, tra cui l'ambiente standard di App Engine, le funzioni Cloud Run e altri ambienti vincolati.
Utilizzare la console Google Cloud
Puoi utilizzare la console Google Cloud per eseguire modelli Dataflow forniti da Google e personalizzati.
Modelli forniti da Google
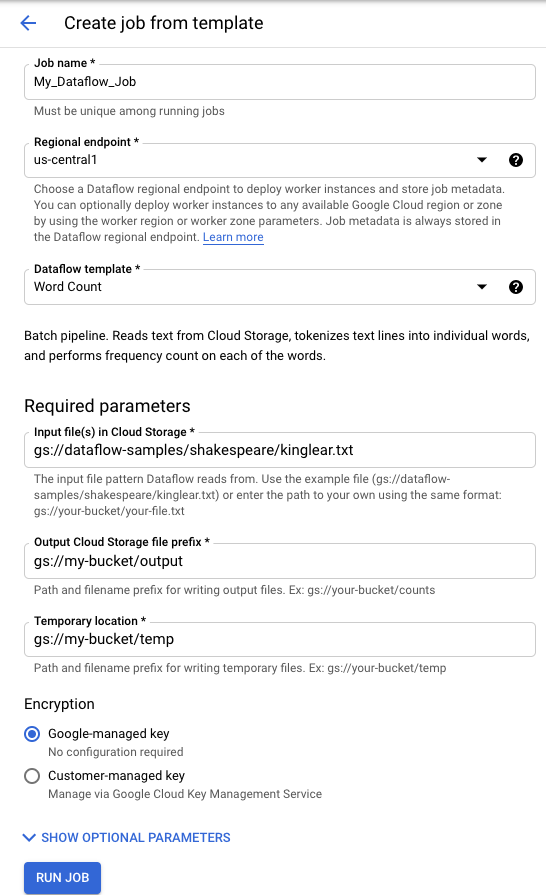
Per eseguire un modello fornito da Google:
- Vai alla pagina Dataflow nella console Google Cloud . Vai alla pagina Dataflow
- Fai clic su add_boxCREA JOB DA MODELLO.
- Seleziona il modello fornito da Google che vuoi eseguire dal menu a discesa Modello Dataflow.
- Inserisci un nome del job nel campo Nome job.
- Inserisci i valori dei parametri nei campi forniti. Non è necessaria la sezione Parametri aggiuntivi quando utilizzi un modello fornito da Google.
- Fai clic su Esegui job.

Modelli personalizzati
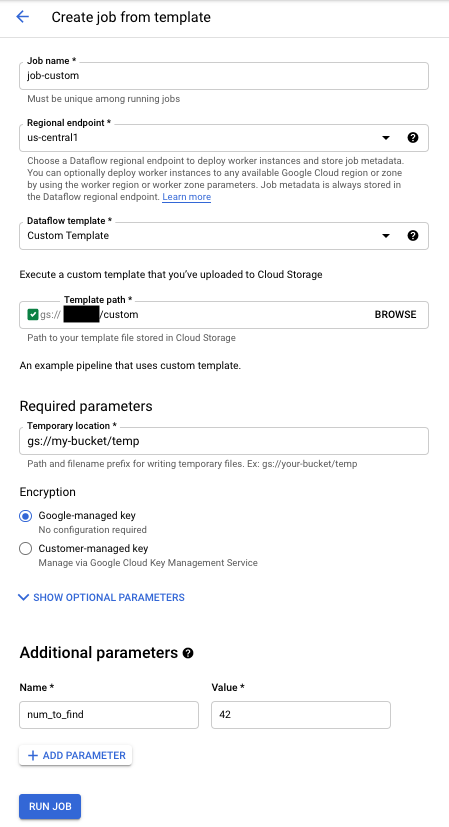
Per eseguire un modello personalizzato:
- Vai alla pagina Dataflow nella console Google Cloud . Vai alla pagina Dataflow
- Fai clic su CREA JOB DA MODELLO.
- Seleziona Modello personalizzato dal menu a discesa Modello Dataflow.
- Inserisci un nome del job nel campo Nome job.
- Inserisci il percorso Cloud Storage del file di modello nel campo Percorso Cloud Storage del modello.
- Se il modello richiede parametri, fai clic su addAGGIUNGI PARAMETRO nella sezione Parametri aggiuntivi. Inserisci il Nome e il Valore del parametro. Ripeti questo passaggio per ogni parametro necessario.
- Fai clic su Esegui job.
Utilizzo dell'API REST
Per eseguire un modello con una richiesta API REST, invia una richiesta HTTP POST con l'ID progetto. Questa richiesta richiede l'autorizzazione.
Consulta il riferimento dell'API REST per projects.locations.templates.launch per scoprire di più sui parametri disponibili.
Crea un job batch di modelli personalizzati
Questo esempio di richiesta projects.locations.templates.launch crea un job batch da un modello che legge un file di testo e scrive un file di testo di output. Se la richiesta ha esito positivo, il corpo della risposta contiene un'istanza di LaunchTemplateResponse.
Modifica i seguenti valori:
- Sostituisci
YOUR_PROJECT_IDcon l'ID progetto. - Sostituisci
LOCATIONcon la regione Dataflow che preferisci. - Sostituisci
JOB_NAMEcon un nome del job a tua scelta. - Sostituisci
YOUR_BUCKET_NAMEcon il nome del tuo bucket Cloud Storage. - Imposta
gcsPathsulla posizione Cloud Storage del file di modello. - Imposta
parameterssull'elenco di coppie chiave-valore. - Imposta
tempLocationsu una posizione in cui hai il permesso di scrittura. Questo valore è obbligatorio per eseguire i modelli forniti da Google.
POST https://dataflow.googleapis.com/v1b3/projects/YOUR_PROJECT_ID/locations/LOCATION/templates:launch?gcsPath=gs://YOUR_BUCKET_NAME/templates/TemplateName
{
"jobName": "JOB_NAME",
"parameters": {
"inputFile" : "gs://YOUR_BUCKET_NAME/input/my_input.txt",
"output": "gs://YOUR_BUCKET_NAME/output/my_output"
},
"environment": {
"tempLocation": "gs://YOUR_BUCKET_NAME/temp",
"zone": "us-central1-f"
}
}
Crea un job di streaming di modelli personalizzati
Questo esempio projects.locations.templates.launch richiede la creazione di un job di streaming da un modello classico che legge da una sottoscrizione Pub/Sub e scrive in una tabella BigQuery. Se vuoi avviare un modello flessibile, utilizza projects.locations.flexTemplates.launch in alternativa. Il modello di esempio è un modello fornito da Google. Puoi modificare il percorso nel modello in modo che punti a un modello personalizzato. La stessa logica viene utilizzata per avviare i modelli forniti da Google e quelli personalizzati. In questo esempio, la tabella BigQuery deve già esistere con lo schema appropriato. In caso di esito positivo, il corpo della risposta contiene un'istanza di LaunchTemplateResponse.
Modifica i seguenti valori:
- Sostituisci
YOUR_PROJECT_IDcon l'ID progetto. - Sostituisci
LOCATIONcon la regione Dataflow che preferisci. - Sostituisci
JOB_NAMEcon un nome del job a tua scelta. - Sostituisci
YOUR_BUCKET_NAMEcon il nome del tuo bucket Cloud Storage. - Sostituisci
GCS_PATHcon il percorso Cloud Storage del file modello. La posizione deve iniziare con gs:// - Imposta
parameterssull'elenco di coppie chiave-valore. I parametri elencati sono specifici di questo esempio di modello. Se utilizzi un modello personalizzato, modifica i parametri in base alle esigenze. Se utilizzi il modello di esempio, sostituisci le seguenti variabili.- Sostituisci
YOUR_SUBSCRIPTION_NAMEcon il nome della tua sottoscrizione Pub/Sub. - Sostituisci
YOUR_DATASETcon il tuo set di dati BigQuery e sostituisciYOUR_TABLE_NAMEcon il nome della tua tabella BigQuery.
- Sostituisci
- Imposta
tempLocationsu una posizione in cui hai il permesso di scrittura. Questo valore è obbligatorio per eseguire i modelli forniti da Google.
POST https://dataflow.googleapis.com/v1b3/projects/YOUR_PROJECT_ID/locations/LOCATION/templates:launch?gcsPath=GCS_PATH
{
"jobName": "JOB_NAME",
"parameters": {
"inputSubscription": "projects/YOUR_PROJECT_ID/subscriptions/YOUR_SUBSCRIPTION_NAME",
"outputTableSpec": "YOUR_PROJECT_ID:YOUR_DATASET.YOUR_TABLE_NAME"
},
"environment": {
"tempLocation": "gs://YOUR_BUCKET_NAME/temp",
"zone": "us-central1-f"
}
}
Aggiorna un job di streaming di modelli personalizzati
Questo esempio projects.locations.templates.launch mostra come aggiornare un job di streaming del modello. Se vuoi aggiornare un modello flessibile, utilizza projects.locations.flexTemplates.launch.
- Esegui Esempio 2: creazione di un job di streaming di modelli personalizzato per avviare un job di streaming di modelli.
- Invia la seguente richiesta HTTP POST con i seguenti valori modificati:
- Sostituisci
YOUR_PROJECT_IDcon l'ID progetto. - Sostituisci
LOCATIONcon la regione Dataflow del job che stai aggiornando. - Sostituisci
JOB_NAMEcon il nome esatto del job che vuoi aggiornare. - Sostituisci
GCS_PATHcon il percorso Cloud Storage del file modello. La posizione deve iniziare con gs:// - Imposta
parameterssull'elenco di coppie chiave-valore. I parametri elencati sono specifici di questo esempio di modello. Se utilizzi un modello personalizzato, modifica i parametri in base alle esigenze. Se utilizzi il modello di esempio, sostituisci le seguenti variabili.- Sostituisci
YOUR_SUBSCRIPTION_NAMEcon il nome della tua sottoscrizione Pub/Sub. - Sostituisci
YOUR_DATASETcon il tuo set di dati BigQuery e sostituisciYOUR_TABLE_NAMEcon il nome della tua tabella BigQuery.
- Sostituisci
- Utilizza il parametro
environmentper modificare le impostazioni dell'ambiente, ad esempio il tipo di macchina. Questo esempio utilizza il tipo di macchina n2-highmem-2, che ha più memoria e CPU per worker rispetto al tipo di macchina predefinito.
POST https://dataflow.googleapis.com/v1b3/projects/YOUR_PROJECT_ID/locations/LOCATION/templates:launch?gcsPath=GCS_PATH { "jobName": "JOB_NAME", "parameters": { "inputSubscription": "projects/YOUR_PROJECT_ID/subscriptions/YOUR_TOPIC_NAME", "outputTableSpec": "YOUR_PROJECT_ID:YOUR_DATASET.YOUR_TABLE_NAME" }, "environment": { "machineType": "n2-highmem-2" }, "update": true } - Sostituisci
- Accedi all'interfaccia di monitoraggio di Dataflow e verifica che sia stato creato un nuovo job con lo stesso nome. Questo job ha lo stato Aggiornato.
Utilizzare le librerie client delle API di Google
Valuta la possibilità di utilizzare le librerie client delle API di Google per effettuare facilmente chiamate alle API REST di Dataflow. Questo script di esempio utilizza la libreria client delle API di Google per Python.
In questo esempio, devi impostare le seguenti variabili:
project: impostalo sull'ID progetto.job: impostalo su un nome univoco del job a tua scelta.template: impostalo sulla posizione di Cloud Storage del file modello.parameters: impostato su un dizionario con i parametri del modello.
Per impostare la
regione,
includi il
parametro
location.
Per maggiori informazioni sulle opzioni disponibili, consulta il
metodo projects.locations.templates.launch
nel riferimento API REST di Dataflow.
Utilizza gcloud CLI
gcloud CLI può eseguire un modello personalizzato o
fornito da Google
utilizzando il comando gcloud dataflow jobs run. Gli esempi di esecuzione dei modelli forniti da Google sono documentati nella pagina Modelli forniti da Google.
Per i seguenti esempi di modelli personalizzati, imposta i seguenti valori:
- Sostituisci
JOB_NAMEcon un nome del job a tua scelta. - Sostituisci
YOUR_BUCKET_NAMEcon il nome del tuo bucket Cloud Storage. - Imposta
--gcs-locationsulla posizione Cloud Storage del file di modello. - Imposta
--parameterssull'elenco separato da virgole dei parametri da passare al job. Gli spazi tra virgole e valori non sono consentiti. - Per impedire alle VM di accettare le chiavi SSH archiviate nei metadati del progetto, utilizza il flag
additional-experimentscon l'opzione di servizioblock_project_ssh_keys:--additional-experiments=block_project_ssh_keys.
Crea un job batch di modelli personalizzati
Questo esempio crea un job batch da un modello che legge un file di testo e scrive un file di testo di output.
gcloud dataflow jobs run JOB_NAME \
--gcs-location gs://YOUR_BUCKET_NAME/templates/MyTemplate \
--parameters inputFile=gs://YOUR_BUCKET_NAME/input/my_input.txt,output=gs://YOUR_BUCKET_NAME/output/my_output
La richiesta restituisce una risposta con il seguente formato.
id: 2016-10-11_17_10_59-1234530157620696789
projectId: YOUR_PROJECT_ID
type: JOB_TYPE_BATCH
Crea un job di streaming di modelli personalizzati
Questo esempio crea un job di streaming da un modello che legge da un argomento Pub/Sub e scrive in una tabella BigQuery. La tabella BigQuery deve già esistere con lo schema appropriato.
gcloud dataflow jobs run JOB_NAME \
--gcs-location gs://YOUR_BUCKET_NAME/templates/MyTemplate \
--parameters topic=projects/project-identifier/topics/resource-name,table=my_project:my_dataset.my_table_name
La richiesta restituisce una risposta con il seguente formato.
id: 2016-10-11_17_10_59-1234530157620696789
projectId: YOUR_PROJECT_ID
type: JOB_TYPE_STREAMING
Per un elenco completo dei flag per il comando gcloud dataflow jobs run, consulta la documentazione di riferimento di gcloud CLI.
Monitoraggio e risoluzione dei problemi
L'interfaccia di monitoraggio di Dataflow ti consente di monitorare i tuoi job Dataflow. Se un job non va a buon fine, puoi trovare suggerimenti per la risoluzione dei problemi, strategie di debug e un catalogo di errori comuni nella guida Risoluzione dei problemi della pipeline.