Esta página fornece uma vista geral do ciclo de vida do pipeline, desde o código do pipeline até uma tarefa do Dataflow.
Esta página explica os seguintes conceitos:
- O que é um gráfico de execução e como um pipeline do Apache Beam se torna uma tarefa do Dataflow
- Como o Dataflow processa erros
- Como o Dataflow paraleliza e distribui automaticamente a lógica de processamento no seu pipeline para os trabalhadores que executam a sua tarefa
- Otimizações de tarefas que o Dataflow pode fazer
Gráfico de execução
Quando executa o pipeline do Dataflow, o Dataflow cria um gráfico de execução a partir do código que cria o objeto Pipeline, incluindo todas as transformações e as respetivas funções de processamento associadas, como objetos DoFn. Este é o gráfico de execução do pipeline e a fase chama-se
tempo de construção do gráfico.
Durante a construção do gráfico, o Apache Beam executa localmente o código do ponto de entrada principal do código do pipeline, parando nas chamadas a uma origem, um destino ou um passo de transformação e transformando estas chamadas em nós do gráfico.
Consequentemente, um fragmento de código no ponto de entrada de um pipeline (método Java e Go main
ou o nível superior de um script Python) é executado localmente na máquina que
executa o pipeline. O mesmo código declarado num método de um objeto DoFn é executado nos trabalhadores do Dataflow.
Por exemplo, o exemplo WordCount incluído nos SDKs do Apache Beam contém uma série de transformações para ler, extrair, contar, formatar e escrever as palavras individuais numa coleção de texto, juntamente com uma contagem de ocorrências para cada palavra. O diagrama seguinte mostra como as transformações no pipeline WordCount são expandidas num gráfico de execução:
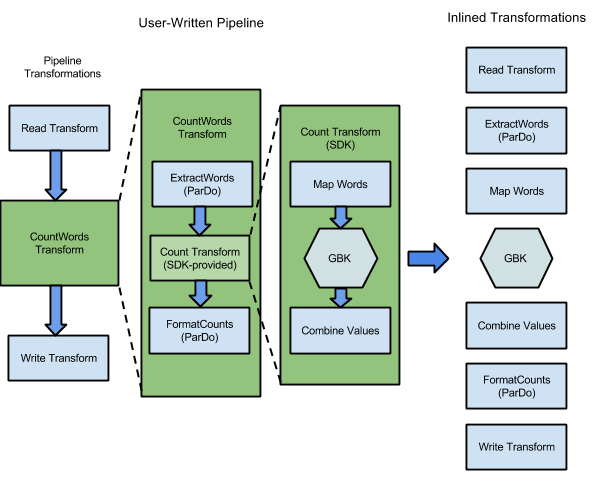
Figura 1: gráfico de execução do exemplo WordCount
O gráfico de execução difere frequentemente da ordem em que especificou as transformações quando construiu o pipeline. Esta diferença existe porque o serviço Dataflow executa várias otimizações e fusões no gráfico de execução antes de ser executado em recursos de nuvem geridos. O serviço Dataflow respeita as dependências de dados quando executa o seu pipeline. No entanto, os passos sem dependências de dados entre si podem ser executados em qualquer ordem.
Para ver o gráfico de execução não otimizado que o Dataflow gerou para o seu pipeline, selecione a tarefa na interface de monitorização do Dataflow. Para mais informações sobre a visualização de tarefas, consulte o artigo Use a interface de monitorização do Dataflow.
Durante a construção do gráfico, o Apache Beam valida se os recursos referenciados pelo pipeline, como contentores do Cloud Storage, tabelas do BigQuery e tópicos ou subscrições do Pub/Sub, existem efetivamente e são acessíveis. A validação é feita através de chamadas API padrão aos respetivos serviços, pelo que é fundamental que a conta de utilizador usada para executar um pipeline tenha a conetividade adequada aos serviços necessários e esteja autorizada a chamar as APIs dos serviços. Antes de enviar o pipeline para o serviço Dataflow, o Apache Beam também verifica a existência de outros erros e garante que o gráfico do pipeline não contém operações ilegais.
Em seguida, o gráfico de execução é traduzido para o formato JSON e o gráfico de execução JSON é transmitido para o ponto final do serviço Dataflow.
Em seguida, o serviço Dataflow valida o gráfico de execução JSON. Quando o gráfico é validado, torna-se uma tarefa no serviço Dataflow. Pode ver a tarefa, o respetivo gráfico de execução, o estado e as informações de registo através da interface de monitorização do Dataflow.
Java
O serviço Dataflow envia uma resposta para a máquina onde executa o seu programa Dataflow. Esta resposta está encapsulada no objeto
DataflowPipelineJob, que contém o jobId da sua tarefa do Dataflow.
Use a jobId para monitorizar, acompanhar e resolver problemas da tarefa através da
interface de monitorização do Dataflow
e da interface de linhas de comando do Dataflow.
Para mais informações, consulte a
referência da API para DataflowPipelineJob.
Python
O serviço Dataflow envia uma resposta para a máquina onde executa o seu programa Dataflow. Esta resposta está encapsulada no objeto
DataflowPipelineResult, que contém o job_id da sua tarefa do Dataflow.
Use o job_id para monitorizar, acompanhar e resolver problemas da tarefa
através da
interface de monitorização do Dataflow
e da
interface de linhas de comando do Dataflow.
Go
O serviço Dataflow envia uma resposta para a máquina onde executa o seu programa Dataflow. Esta resposta está encapsulada no objeto
dataflowPipelineResult, que contém o jobID da sua tarefa do Dataflow.
Use o jobID para monitorizar, acompanhar e resolver problemas da tarefa
através da
interface de monitorização do Dataflow
e da
interface de linhas de comando do Dataflow.
A construção do gráfico também ocorre quando executa o pipeline localmente, mas o gráfico não é traduzido para JSON nem transmitido para o serviço. Em alternativa, o gráfico é executado localmente na mesma máquina onde iniciou o seu programa do Dataflow. Para mais informações, consulte o artigo Configurar PipelineOptions para execução local.
Processamento de erros e exceções
O seu pipeline pode gerar exceções durante o processamento de dados. Alguns destes erros são temporários, como uma dificuldade temporária em aceder a um serviço externo. Outros erros são permanentes, como erros causados por dados de entrada danificados ou não analisáveis, ou ponteiros nulos durante o cálculo.
O Dataflow processa elementos em pacotes arbitrários e tenta novamente o pacote completo quando é gerado um erro para qualquer elemento nesse pacote. Quando executados no modo de lote, os pacotes que incluem um item com falha são repetidos quatro vezes. O pipeline falha completamente quando um único pacote falha quatro vezes. Quando é executado no modo de streaming, um pacote que inclui um item com falhas é repetido indefinidamente, o que pode fazer com que o seu pipeline fique permanentemente parado.
Quando o processamento é feito no modo de lote, pode ver um grande número de falhas individuais antes de uma tarefa de pipeline falhar completamente, o que acontece quando um determinado pacote falha após quatro tentativas. Por exemplo, se o seu pipeline tentar processar 100 pacotes, o Dataflow pode gerar várias centenas de falhas individuais até que um único pacote atinja a condição de quatro falhas para sair.
Os erros do trabalhador de arranque, como a falha na instalação de pacotes nos trabalhadores, são transitórios. Este cenário resulta em novas tentativas indefinidas e pode fazer com que o seu pipeline fique permanentemente parado.
Paralelização e distribuição
O serviço Dataflow paraleliza e distribui automaticamente a lógica de processamento no seu pipeline para os trabalhadores que atribui para executar a sua tarefa. O Dataflow usa as abstrações no modelo de programação para representar funções de processamento paralelo. Por exemplo, as ParDo transformações num pipeline fazem com que o Dataflow distribua automaticamente o código de processamento, representado por objetos DoFn, por vários trabalhadores para serem executados em paralelo.
Existem dois tipos de paralelismo de tarefas:
O paralelismo horizontal ocorre quando os dados do pipeline são divididos e processados em vários trabalhadores ao mesmo tempo. O ambiente de tempo de execução do Dataflow é suportado por um conjunto de trabalhadores distribuídos. Um pipeline tem um paralelismo potencialmente mais elevado quando o conjunto contém mais trabalhadores, mas essa configuração também tem um custo mais elevado. Teoricamente, o paralelismo horizontal não tem um limite superior. No entanto, o Dataflow limita o conjunto de trabalhadores a 4000 trabalhadores para otimizar a utilização de recursos em toda a frota.
O paralelismo vertical ocorre quando os dados do pipeline são divididos e processados por vários núcleos da CPU no mesmo trabalhador. Cada trabalhador é alimentado por uma VM do Compute Engine. Uma VM pode executar vários processos para saturar todos os respetivos núcleos do CPU. Uma VM com mais núcleos tem um potencial de paralelismo vertical mais elevado, mas esta configuração resulta em custos mais elevados. Um número mais elevado de núcleos resulta frequentemente num aumento da utilização de memória, pelo que o número de núcleos é normalmente dimensionado juntamente com o tamanho da memória. Dado o limite físico das arquiteturas de computador, o limite superior do paralelismo vertical é muito inferior ao limite superior do paralelismo horizontal.
Paralelismo gerido
Por predefinição, o Dataflow gere automaticamente o paralelismo das tarefas. O Dataflow monitoriza as estatísticas de tempo de execução da tarefa, como a utilização da CPU e da memória, para determinar como dimensionar a tarefa. Consoante as definições do trabalho, o Dataflow pode dimensionar os trabalhos horizontalmente, o que se denomina escala automática horizontal, ou verticalmente, o que se denomina escala vertical. A escalabilidade automática para paralelismo otimiza o custo da tarefa e o desempenho da tarefa.
Para melhorar o desempenho das tarefas, o Dataflow também otimiza os pipelines internamente. As otimizações típicas são a otimização de fusão e a otimização de combinação. Ao fundir passos do pipeline, o Dataflow elimina os custos desnecessários associados à coordenação de passos num sistema distribuído e à execução de cada passo individual separadamente.
Fatores que afetam o paralelismo
Os seguintes fatores afetam o desempenho do paralelismo nos trabalhos do Dataflow.
Origem de entrada
Quando uma origem de entrada não permite o paralelismo, o passo de carregamento da origem de entrada pode tornar-se um gargalo numa tarefa do Dataflow. Por exemplo, quando ingere dados de um único ficheiro de texto comprimido, o Dataflow não consegue paralelizar os dados de entrada. Uma vez que a maioria dos formatos de compressão não pode ser dividida arbitrariamente em fragmentos durante o carregamento, o Dataflow tem de ler os dados sequencialmente a partir do início do ficheiro. O débito geral do pipeline é reduzido pela parte não paralela do pipeline. A solução para este problema é usar uma origem de entrada mais escalável.
Em alguns casos, a união de passos também reduz o paralelismo. Quando a origem de entrada não permite o paralelismo, se o Dataflow fundir o passo de ingestão de dados com os passos subsequentes e atribuir este passo fundido a um único segmento, toda a pipeline pode ser executada mais lentamente.
Para evitar este cenário, insira um passo Redistribute após o passo de carregamento da fonte de entrada. Para mais informações, consulte a secção
Impedir a união deste documento.
Fanout e formato de dados predefinidos
A ramificação predefinida de um único passo de transformação pode tornar-se um gargalo e limitar o paralelismo. Por exemplo, a transformação "high fan-out" ParDo pode fazer com que a união limite a capacidade do Dataflow de otimizar a utilização de trabalhadores. Nessa operação, pode ter uma coleção de entrada com relativamente poucos elementos, mas o ParDo produz uma saída com centenas ou milhares de vezes mais elementos, seguida de outro ParDo. Se o serviço Dataflow fundir estas operações ParDo, o paralelismo neste passo fica limitado, no máximo, ao número de itens na coleção de entrada, mesmo que o PCollection intermédio contenha muito mais elementos.
Para ver potenciais soluções, consulte a secção Impedir a união deste documento.
Formato dos dados
A forma dos dados, quer sejam dados de entrada ou dados intermédios, pode limitar o paralelismo.
Por exemplo, quando um passo GroupByKey numa chave natural, como uma cidade, é seguido de um passo map ou Combine, o Dataflow funde os dois passos. Quando o espaço de chaves é pequeno, por exemplo, cinco cidades, e uma chave é muito
popular, por exemplo, uma cidade grande, a maioria dos itens no resultado do passo GroupByKey
é distribuída a um processo. Este processo torna-se um gargalo e abranda a tarefa.
Neste exemplo, pode redistribuir os resultados do passo GroupByKey num espaço de chaves artificiais maior em vez de usar as chaves naturais. Inserir um passo Redistribute entre o passo GroupByKey e o passo map ou Combine. No passo Redistribute, crie o espaço de chaves artificiais, por exemplo, usando uma função hash, para superar o paralelismo limitado causado pelo formato dos dados.
Para mais informações, consulte a secção Impedir a união deste documento.
Destino de saída
Um destino é uma transformação que escreve num sistema de armazenamento de dados externo, como um ficheiro ou uma base de dados. Na prática, os sinks são modelados e implementados como objetos DoFn padrão e são usados para materializar um PCollection para sistemas externos.
Neste caso, o elemento PCollection contém os resultados finais do pipeline. Os threads que chamam APIs de destino podem ser executados em paralelo para escrever dados nos sistemas externos. Por predefinição, não ocorre coordenação entre as linhas de execução. Sem uma camada intermédia para armazenar em buffer os pedidos de escrita e controlar o fluxo, o sistema externo pode ficar sobrecarregado e reduzir o débito de escrita. Aumentar os recursos adicionando mais paralelismo pode abrandar ainda mais o pipeline.
A solução para este problema é reduzir o paralelismo no passo de escrita.
Pode adicionar um passo GroupByKey imediatamente antes do passo de escrita. O GroupByKey
passo agrupa os dados de saída num conjunto mais pequeno de lotes para reduzir o total de chamadas RPC
e ligações a sistemas externos. Por exemplo, use um GroupByKey para criar um espaço de hash de 50 em 1 milhão de pontos de dados.
A desvantagem desta abordagem é que introduz um limite codificado para o paralelismo. Outra opção é implementar a retirada exponencial no destino quando escrever dados. Esta opção pode fornecer uma limitação mínima do cliente.
Monitorize o paralelismo
Para monitorizar o paralelismo, pode usar a Google Cloud consola para ver os elementos atrasados detetados. Para mais informações, consulte os artigos Resolva problemas de tarefas em atraso em trabalhos em lote e Resolva problemas de tarefas em atraso em trabalhos de streaming.
Otimização da união
Depois de o formulário JSON do gráfico de execução do pipeline ser validado, o serviço Dataflow pode modificar o gráfico para fazer otimizações.
As otimizações podem incluir a fusão de vários passos ou transformações no gráfico de execução do pipeline em passos únicos. A união de passos impede que o serviço Dataflow tenha de materializar todos os dados intermédios PCollection no seu pipeline, o que pode ser dispendioso em termos de memória e sobrecarga de processamento.
Embora todas as transformações especificadas na construção do pipeline sejam executadas no serviço, para garantir a execução mais eficiente do pipeline, as transformações podem ser executadas numa ordem diferente ou como parte de uma transformação unida maior. O serviço Dataflow respeita as dependências de dados entre os passos no gráfico de execução, mas, caso contrário, os passos podem ser executados em qualquer ordem.
Exemplo de fusão
O diagrama seguinte mostra como o gráfico de execução do exemplo WordCount incluído no SDK do Apache Beam para Java pode ser otimizado e fundido pelo serviço Dataflow para uma execução eficiente:
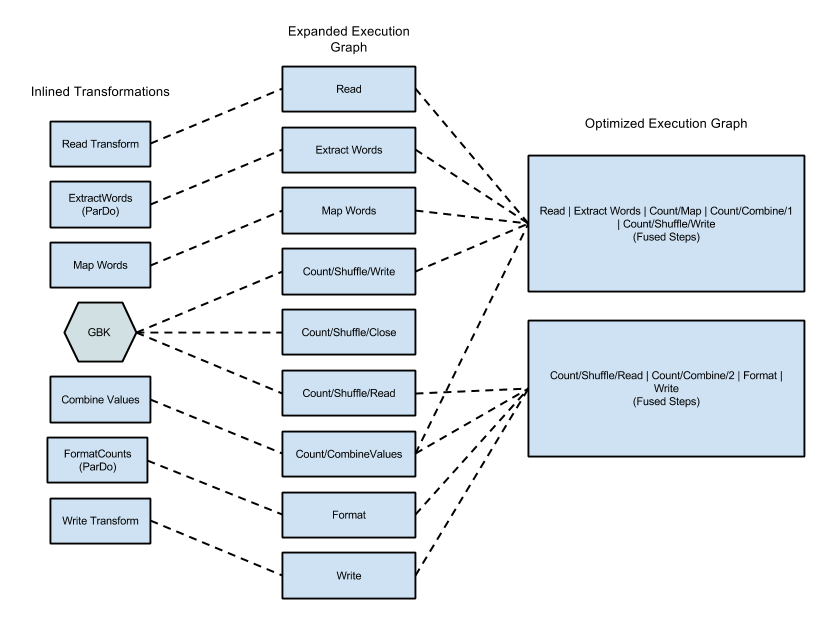
Figura 2: exemplo de WordCount com gráfico de execução otimizado
Evite a união
Em alguns casos, o Dataflow pode adivinhar incorretamente a forma ideal de fundir operações no pipeline, o que pode limitar a capacidade do Dataflow de usar todos os trabalhadores disponíveis. Nestes casos,
pode dar uma sugestão ao Dataflow para redistribuir os dados através de uma transformação Redistribute.
Para adicionar uma transformação Redistribute, chame um dos seguintes métodos:
Redistribute.arbitrarily: indica que é provável que os dados estejam desequilibrados. O Dataflow escolhe o melhor algoritmo para redistribuir os dados.Redistribute.byKey: indica que é provável que umPCollectionde pares chave-valor esteja desequilibrado e deve ser redistribuído com base nas chaves. Normalmente, o Dataflow localiza todos os elementos de uma única chave no mesmo segmento de processamento. No entanto, a colocação conjunta de chaves não é garantida e os elementos são processados de forma independente.
Se o seu pipeline contiver uma transformação Redistribute, o Dataflow impede normalmente a união dos passos antes e depois da transformação Redistribute e baralha os dados para que os passos a jusante da transformação Redistribute tenham um paralelismo mais otimizado.
Fusão de monitores
Pode aceder ao seu gráfico otimizado e fases unidas na Google Cloud consola, através da CLI gcloud ou da API.
Consola
Para ver as fases e os passos fundidos do gráfico na consola, no separador Detalhes da execução do seu trabalho do Dataflow, abra a vista do gráfico Fluxo de trabalho de fases.
Para ver os passos dos componentes que estão fundidos para uma fase, no gráfico, clique na fase fundida. No painel Informações da fase, a linha Etapas do componente apresenta as fases unidas. Por vezes, partes de uma única transformação composta são fundidas em várias fases.
gcloud
Para aceder ao seu gráfico otimizado e fases unidas através da CLI gcloud, execute o seguinte comando gcloud:
gcloud dataflow jobs describe --full JOB_ID --format json
Substitua JOB_ID pelo ID da sua tarefa do Dataflow.
Para extrair os bits relevantes, encaminhe o resultado do comando gcloud para jq:
gcloud dataflow jobs describe --full JOB_ID --format json | jq '.pipelineDescription.executionPipelineStage\[\] | {"stage_id": .id, "stage_name": .name, "fused_steps": .componentTransform }'
Para ver a descrição das fases unidas no ficheiro de resposta de saída, na matriz
ComponentTransform, consulte o objeto
ExecutionStageSummary.
API
Para aceder ao seu gráfico otimizado e estágios fundidos através da API, chame
project.locations.jobs.get.
Para ver a descrição das fases unidas no ficheiro de resposta de saída, na matriz
ComponentTransform, consulte o objeto
ExecutionStageSummary.
Combine a otimização
As operações de agregação são um conceito importante no processamento de dados em grande escala.
A agregação reúne dados que estão conceptualmente muito distantes, o que a torna extremamente útil para a correlação. O modelo de programação do Dataflow representa as operações de agregação como as transformações GroupByKey, CoGroupByKey e Combine.
As operações de agregação do Dataflow combinam dados em todo o conjunto de dados, incluindo dados que podem estar distribuídos por vários trabalhadores. Durante estas operações de agregação, é frequentemente mais eficiente combinar o máximo de dados possível localmente antes de combinar dados em várias instâncias. Quando aplica uma transformação de agregação GroupByKey ou outra, o serviço Dataflow realiza automaticamente a combinação parcial localmente antes da operação de agrupamento principal.
Quando realiza a combinação parcial ou de vários níveis, o serviço Dataflow toma decisões diferentes com base no facto de o seu pipeline estar a trabalhar com dados em lote ou em streaming. Para dados delimitados, o serviço privilegia a eficiência e realiza a maior combinação local possível. Para dados ilimitados, o serviço privilegia uma latência mais baixa e pode não realizar a combinação parcial, porque pode aumentar a latência.