Dataflow snapshots save the state of a streaming pipeline, which lets you start a new version of your Dataflow job without losing state. Snapshots are useful for backup and recovery, testing and rolling back updates to streaming pipelines, and other similar scenarios.
You can create a Dataflow snapshot of any running streaming job. Note that any new job you create from a snapshot uses Streaming Engine. You can also use a Dataflow snapshot to migrate your existing pipeline over to the more efficient and scalable Streaming Engine with minimal downtime.
This guide explains how to create snapshots, manage snapshots, and create jobs from snapshots.
Before you begin
- Sign in to your Google Cloud Platform account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Dataflow, Compute Engine, Cloud Logging, Cloud Storage, Google Cloud Storage JSON, BigQuery, Cloud Pub/Sub, Cloud Datastore, and Cloud Resource Manager APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Dataflow, Compute Engine, Cloud Logging, Cloud Storage, Google Cloud Storage JSON, BigQuery, Cloud Pub/Sub, Cloud Datastore, and Cloud Resource Manager APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.
Create a snapshot
Console
- In the Google Cloud console, go to the Dataflow
Jobs page.
A list of Dataflow jobs appears along with their status. If you don't see any streaming jobs, you need to run a new streaming job. For an example of a streaming job, see the Using Templates quickstart.
- Select a job.
- In the menu bar on the Job details page, click Create snapshot.
- In the Create a snapshot dialog, select one of the following
options:
- Without data sources: select this option to create a snapshot of your Dataflow job state only.
- With data sources: select this option to create a snapshot of both your Dataflow job state along with a snapshot of your Pub/Sub source.
- Click Create.
gcloud
Create a snapshot:
gcloud dataflow snapshots create \
--job-id=JOB_ID \
--snapshot-ttl=DURATION \
--snapshot-sources=true \
--region=REGIONReplace the following:
JOB_ID: your streaming job IDDURATION: the amount of time (in days) before the snapshot expires, after which no more jobs can be created from the snapshot. Thesnapshot-ttlflag is optional, so if it is not specified, the snapshot expires in 7 days. Specify the value in the following format:5d. The maximum duration you can specify is 30 days (30d).REGION: the region where your streaming job is running
The snapshot-sources flag specifies whether to snapshot the
Pub/Sub sources along with the Dataflow
snapshot. If true, Pub/Sub sources are
automatically snapshotted and the Pub/Sub snapshot IDs are
shown in the output response. After running the
create
command, check on the snapshot status by running either the
list
or the
describe
command.
The following apply when creating Dataflow snapshots:
- Dataflow snapshots incur a charge on disk usage.
- Snapshots are created in the same region as the job.
- If the job's worker location is different from the job's region, snapshot creation fails. See the Dataflow regions guide.
- You can only take snapshots of non-Streaming Engine jobs if the jobs were started or updated after February 1, 2021.
- Pub/Sub snapshots created with Dataflow snapshots are managed by the Pub/Sub service and incur a charge.
- A Pub/Sub snapshot expires no later than 7 days from the time
of its creation. Its exact lifetime is determined at creation by the
existing backlog in the source subscription. Specifically, the lifetime of
the Pub/Sub snapshot is
7 days - (age of oldest unacked message in the subscription). For example, consider a subscription whose oldest unacknowledged message is 3 days old. If a Pub/Sub snapshot is created from this subscription, the snapshot, which always captures this 3-day-old backlog as long as the snapshot exists, expires in 4 days. See Pub/Sub snapshot reference. - During the snapshot operation, your Dataflow job pauses and resumes after the snapshot is ready. The time needed depends on the size of the pipeline state. For example, the time needed to take snapshots on Streaming Engine jobs are generally shorter than non-Streaming Engine jobs.
- You can cancel the job while a snapshot is in progress, which then cancels the snapshot.
- You cannot update or drain the job while a snapshot is in progress. You must wait until the job has resumed from the snapshot process before you can update or drain the job.
Use the snapshots page
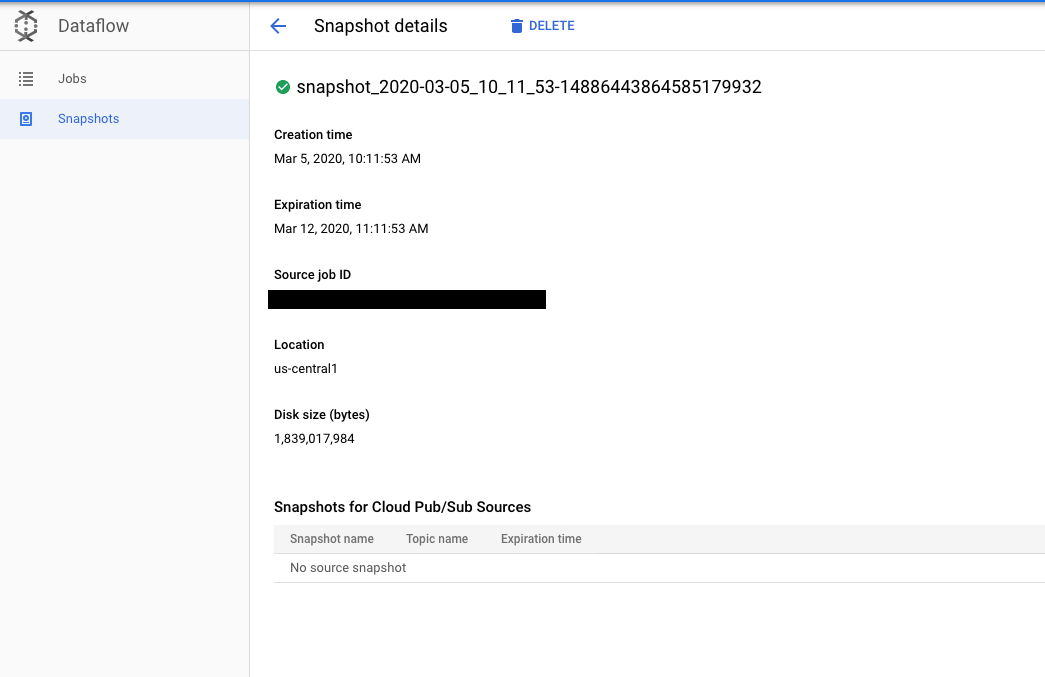
After you create a snapshot, you can use the Snapshots page in the Google Cloud console to view and manage the snapshots for your project.
Clicking on a snapshot opens the Snapshot details page. You can view additional metadata about the snapshot as well as a link to the source job and any Pub/Sub snapshots.
Delete a snapshot
Deleting a snapshot is a way you can stop the snapshot process and resume the job. Also, deleting Dataflow snapshots does not automatically delete the associated Pub/Sub snapshots.
Console
- In the Google Cloud console, go to the Dataflow Snapshots page.
- Select the snapshot and click Delete.
- In the Delete snapshot dialog, click Delete to confirm.
gcloud
Delete a snapshot:
gcloud dataflow snapshots delete SNAPSHOT_ID \
--region=REGIONReplace the following:
SNAPSHOT_ID: your snapshot IDREGION: the region where your snapshot exists
For more information, see the
delete
command reference.
Create a job from a snapshot
After you create a snapshot, you can restore your Dataflow job's state by creating a new job from that snapshot.
Java
To create a new job from a snapshot, use both the
--createFromSnapshot and --enableStreamingEngine
flags.
- In your shell or terminal, create a new job from a snapshot. For
example:
mvn -Pdataflow-runner compile exec:java \ -Dexec.mainClass=MAIN_CLASS \ -Dexec.args="--project=PROJECT_ID \ --stagingLocation=gs://STORAGE_BUCKET/staging/ \ --inputFile=gs://apache-beam-samples/shakespeare/* \ --output=gs://STORAGE_BUCKET/output \ --runner=DataflowRunner \ --enableStreamingEngine \ --createFromSnapshot=SNAPSHOT_ID \ --region=REGION"
Replace the following:
MAIN_CLASSorMODULE: For Java pipelines, the location of the main class that contains your pipeline code. For Python pipelines, the location of the module that contains your pipeline code. For example, when using the Wordcount example, the value isorg.apache.beam.examples.WordCount.PROJECT_ID: your Google Cloud project IDSTORAGE_BUCKET: the Cloud Storage bucket you use for temporary job assets and the final outputSNAPSHOT_ID: the snapshot ID of the snapshot from which you want to create a new jobREGION: the location where you want to run the new Dataflow job
Python
Dataflow snapshots require the Apache Beam SDK for Python, version 2.29.0 or later.
To create a new job from a snapshot, use both the
--createFromSnapshot and --enableStreamingEngine
flags.
- In your shell or terminal, create a new job from a snapshot. For
example:
python -m MODULE \ --project PROJECT_ID \ --temp_location gs://STORAGE_BUCKET/tmp/ \ --input gs://apache-beam-samples/shakespeare/* \ --output gs://STORAGE_BUCKET/output \ --runner DataflowRunner \ --enable_streaming_engine \ --create_from_snapshot=SNAPSHOT_ID \ --region REGION \ --streaming
Replace the following:
MAIN_CLASSorMODULE: For Java pipelines, the location of the main class that contains your pipeline code. For Python pipelines, the location of the module that contains your pipeline code. For example, when using the Wordcount example, the value isorg.apache.beam.examples.WordCount.PROJECT_ID: your Google Cloud project IDSTORAGE_BUCKET: the Cloud Storage bucket you use for temporary job assets and the final outputSNAPSHOT_ID: the snapshot ID of the snapshot from which you want to create a new jobREGION: the location where you want to run the new Dataflow job
The following apply when creating jobs from Dataflow snapshots:
- Jobs created from snapshots must run in the same region where the snapshot is stored.
If a Dataflow snapshot includes snapshots of Pub/Sub sources, jobs created from a Dataflow snapshot automatically
seekto those Pub/Sub snapshots as sources. You must specify the same Pub/Sub topics used by the source job when creating jobs from that Dataflow snapshot.If a Dataflow snapshot doesn't include snapshots of Pub/Sub sources and the source job uses a Pub/Sub source, you must specify a Pub/Sub topic when creating jobs from that Dataflow snapshot.
New jobs created from a snapshot are still subjected to an update compatibility check.
Known limitations
The following limitations apply to Dataflow snapshots:
- You can't create jobs from snapshots using templates or the Dataflow SQL editor.
- You can't update or drain a job while a snapshot is in progress. You must wait until the job has resumed from the snapshot process before you can update or drain the job.
- The snapshot expiration timeframe can only be set through the Google Cloud CLI.
- Sink snapshots are not supported. For example, you cannot create a BigQuery snapshot when creating a Dataflow snapshot.
Troubleshooting
This section provides instructions for troubleshooting common issues found when interacting with Dataflow snapshots.
Before reaching out for support, ensure that you have ruled out problems related to the known limitations and in the following troubleshooting sections.
Snapshot creation request is rejected
After a snapshot creation request is submitted, either from the Google Cloud console or the gcloud CLI, Dataflow service performs a precondition check and returns any error messages. The snapshot creation request can be rejected for various reasons that are specified in the error messages—for example, if a job type is unsupported or a region is unavailable.
If the request is rejected because the job is too old, you must update your job before you request a snapshot.
Snapshot creation failed
Snapshot creation might fail for several reasons. For example, the source job was canceled or the project does not have the correct permissions to create Pub/Sub snapshots. The job-message logs of the job contains error messages from the snapshot creation. If the snapshot creation fails, then the source job resumes.
Create a job from snapshot failed
When you create a job from a snapshot, ensure that the snapshot exists and is not expired. The new job must run on Streaming Engine.
For common job creation issues, refer to Dataflow troubleshooting guide. In particular, new jobs created from snapshots are subjected to an update compatibility check where the new job is required to be compatible with the snapshotted source job.
Job created from snapshot makes little progress
The job-message logs of the job contains error messages for job creation. For example, you might see that the job can't find the Pub/Sub snapshots. In this case, verify that the Pub/Sub snapshots exist and are not expired. Pub/Sub snapshots expire as soon as the oldest message in a snapshot is older than seven days. Expired Pub/Sub snapshots might be removed by Pub/Sub service automatically.
For jobs created from Dataflow snapshots that include Pub/Sub source snapshots, the new job might have large Pub/Sub backlogs to process. Streaming autoscaling might help the new job to clear the backlog faster.
The snapshotted source job might already be in an unhealthy state before the snapshot was taken. Understanding why the source job is unhealthy might help resolve issues of the new job. For common job debugging tips, refer to Dataflow troubleshooting guide.