Questa pagina fornisce suggerimenti per la risoluzione dei problemi e strategie di debug che potrebbero esserti utili se hai difficoltà a creare o eseguire la pipeline Dataflow. Queste informazioni possono aiutarti a rilevare un errore della pipeline, determinare il motivo di un'esecuzione della pipeline non riuscita e suggerire alcune azioni per correggere il problema.
Il seguente diagramma mostra il flusso di lavoro per la risoluzione dei problemi di Dataflow descritto in questa pagina.

Dataflow fornisce feedback in tempo reale sul job ed esiste un insieme di passaggi di base che puoi utilizzare per controllare i messaggi di errore, i log e le condizioni, ad esempio l'avanzamento del job è bloccato.
Per indicazioni sugli errori comuni che potresti riscontrare durante l'esecuzione del job Dataflow, vedi Risolvere i problemi relativi agli errori di Dataflow. Per monitorare e risolvere i problemi relativi alle prestazioni della pipeline, consulta Monitorare le prestazioni della pipeline.
Best practice per le pipeline
Di seguito sono riportate le best practice per le pipeline Java, Python e Go.
Java
Per i job batch, ti consigliamo di impostare un time to live (TTL) per la posizione temporanea.
Prima di configurare il TTL e come best practice generale, assicurati di impostare la posizione di staging e la posizione temporanea su posizioni diverse.
Non eliminare gli oggetti nella posizione di staging, in quanto vengono riutilizzati.
Se un job viene completato o interrotto e gli oggetti temporanei non vengono puliti, rimuovi manualmente questi file dal bucket Cloud Storage utilizzato come posizione temporanea.
Python
Sia le posizioni temporanee sia quelle di gestione temporanea hanno il prefisso <job_name>.<time>.
Assicurati di impostare sia la posizione di staging sia la posizione temporanea su località diverse.
Se necessario, elimina gli oggetti nella posizione di staging dopo il completamento o l'interruzione di un job. Inoltre, gli oggetti di staging non vengono riutilizzati nelle pipeline Python.
Se un job termina e gli oggetti temporanei non vengono puliti, rimuovi manualmente questi file dal bucket Cloud Storage utilizzato come posizione temporanea.
Per i job batch, ti consigliamo di impostare un time to live (TTL) sia per le posizioni temporanee sia per quelle di staging.
Vai
Sia le posizioni temporanee sia quelle di gestione temporanea hanno il prefisso
<job_name>.<time>.Assicurati di impostare sia la posizione di staging sia la posizione temporanea su località diverse.
Se necessario, elimina gli oggetti nella posizione di staging dopo il completamento o l'interruzione di un job. Inoltre, gli oggetti di staging non vengono riutilizzati nelle pipeline Go.
Se un job termina e gli oggetti temporanei non vengono puliti, rimuovi manualmente questi file dal bucket Cloud Storage utilizzato come posizione temporanea.
Per i job batch, ti consigliamo di impostare un time to live (TTL) sia per le posizioni temporanee sia per quelle di staging.
Controllare lo stato della pipeline
Puoi rilevare eventuali errori nelle esecuzioni della pipeline utilizzando l'interfaccia di monitoraggio di Dataflow.
- Vai alla consoleGoogle Cloud .
- Seleziona il tuo progetto Google Cloud dall'elenco dei progetti.
- Nel menu di navigazione, in Big Data, fai clic su Dataflow. Nel riquadro a destra viene visualizzato un elenco di job in esecuzione.
- Seleziona il job di pipeline che vuoi visualizzare. Puoi visualizzare lo stato dei job a colpo d'occhio nel campo Stato: "In esecuzione", "Riuscito" o "Non riuscito".
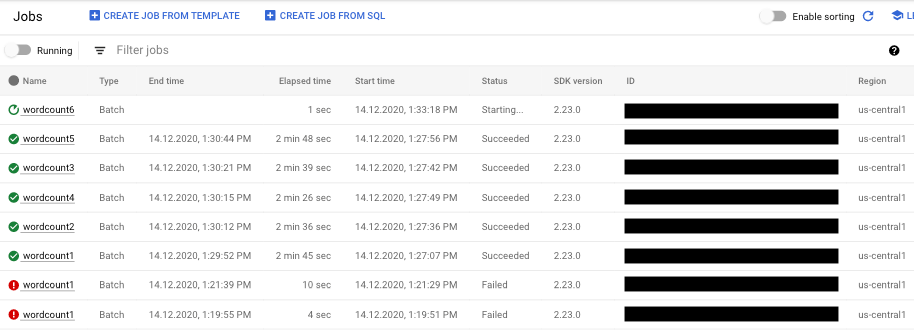
Trovare informazioni sugli errori della pipeline
Se uno dei job della pipeline non va a buon fine, puoi selezionarlo per visualizzare informazioni più dettagliate sugli errori e sui risultati dell'esecuzione. Quando selezioni un job, puoi visualizzare i grafici chiave per la pipeline, il grafico di esecuzione, il riquadro Informazioni job e il riquadro Log con le schede Log job, Log worker, Diagnostica e Consigli.
Controllare i messaggi di errore del job
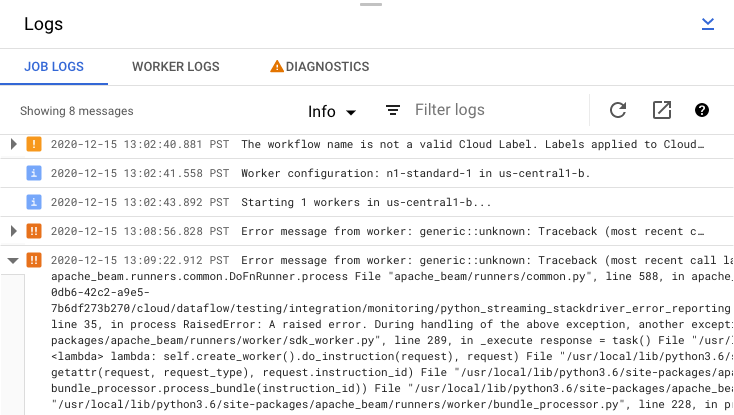
Per visualizzare i log dei job generati dal codice della pipeline e dal servizio Dataflow, fai clic su segmentMostra nel riquadro Log.
Puoi filtrare i messaggi visualizzati in Log dei job facendo clic su Informazioniarrow_drop_down e filter_listFiltra. Per visualizzare solo i messaggi di errore, fai clic su Informazioniarrow_drop_down e seleziona Errore.
Per espandere un messaggio di errore, fai clic sulla sezione espandibile arrow_right.
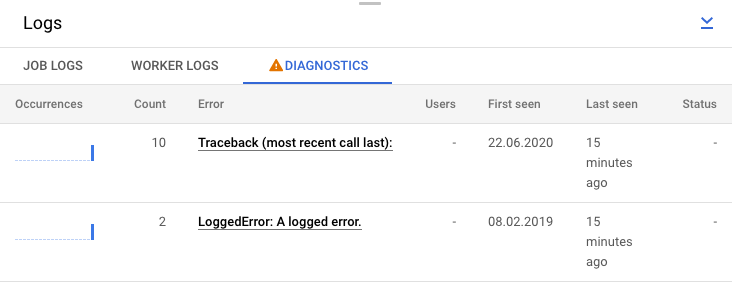
In alternativa, puoi fare clic sulla scheda Diagnostica. Questa scheda mostra dove si sono verificati errori lungo la sequenza temporale scelta, un conteggio di tutti gli errori registrati e possibili consigli per la tua pipeline.
Visualizzare i log dei passaggi per il job
Quando selezioni un passaggio nel grafico della pipeline, il riquadro dei log passa dalla visualizzazione dei log dei job generati dal servizio Dataflow alla visualizzazione dei log delle istanze di Compute Engine che eseguono il passaggio della pipeline.
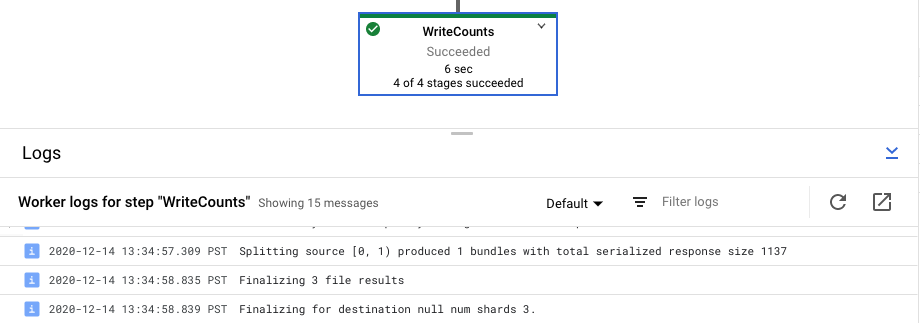
Cloud Logging combina tutti i log raccolti dalle istanze Compute Engine del tuo progetto in un'unica posizione. Per ulteriori informazioni sull'utilizzo delle varie funzionalità di logging di Dataflow, consulta Messaggi della pipeline di logging.
Gestire il rifiuto della pipeline automatizzata
In alcuni casi, il servizio Dataflow identifica che la pipeline potrebbe attivare problemi noti dell'SDK. Per impedire l'invio di pipeline che potrebbero riscontrare problemi, Dataflow rifiuta automaticamente la pipeline e mostra il seguente messaggio:
The workflow was automatically rejected by the service because it might trigger an identified bug in the SDK (details below). If you think this identification is in error, and would like to override this automated rejection, please re-submit this workflow with the following override flag: [OVERRIDE FLAG]. Bug details: [BUG DETAILS]. Contact Google Cloud Support for further help. Please use this identifier in your communication: [BUG ID].
Dopo aver letto gli avvisi nei dettagli del bug collegato, se vuoi provare a eseguire
la pipeline comunque, puoi ignorare il rifiuto automatico. Aggiungi il flag
--experiments=<override-flag> e invia di nuovo la pipeline.
Determinare la causa di un errore della pipeline
In genere, l'esecuzione di una pipeline Apache Beam non riuscita può essere attribuita a una delle seguenti cause:
- Errori di costruzione del grafico o della pipeline. Questi errori si verificano quando Dataflow riscontra un problema durante la creazione del grafico dei passaggi che compongono la pipeline, come descritto dalla pipeline Apache Beam.
- Errori nella convalida del job. Il servizio Dataflow convalida qualsiasi job della pipeline che avvii. Gli errori nel processo di convalida possono impedire la creazione o l'esecuzione corretta del job. Gli errori di convalida possono includere problemi con il bucket Cloud Storage del tuo progetto Google Cloud o con le autorizzazioni del progetto.
- Eccezioni nel codice del worker. Questi errori si verificano quando nel codice fornito dall'utente che Dataflow distribuisce ai worker paralleli, ad esempio le istanze
DoFndi una trasformazioneParDo, sono presenti errori o bug. - Errori causati da errori temporanei in altri servizi Google Cloud . La pipeline potrebbe non riuscire a causa di un'interruzione temporanea o di un altro problema nei serviziGoogle Cloud da cui dipende Dataflow, ad esempio Compute Engine o Cloud Storage.
Rilevare errori di costruzione di grafici o pipeline
Un errore di costruzione del grafico può verificarsi quando Dataflow crea il grafico di esecuzione della pipeline dal codice del programma Dataflow. Durante la creazione del grafico, Dataflow verifica la presenza di operazioni non consentite.
Se Dataflow rileva un errore nella costruzione del grafico, tieni presente che non viene creato alcun job nel servizio Dataflow. Pertanto, non vedi alcun feedback nell'interfaccia di monitoraggio di Dataflow. Nella console o nella finestra del terminale in cui hai eseguito la pipeline Apache Beam viene visualizzato un messaggio di errore simile al seguente:
Java
Ad esempio, se la pipeline tenta di eseguire un'aggregazione come
GroupByKey su un PCollection senza limiti, non attivato e con finestra globale, viene visualizzato un messaggio di errore simile al seguente:
... ... Exception in thread "main" java.lang.IllegalStateException: ... GroupByKey cannot be applied to non-bounded PCollection in the GlobalWindow without a trigger. ... Use a Window.into or Window.triggering transform prior to GroupByKey ...
Python
Ad esempio, se la tua pipeline utilizza suggerimenti sul tipo e il tipo di argomento in una delle trasformazioni non è quello previsto, viene visualizzato un messaggio di errore simile al seguente:
... in <module> run()
... in run | beam.Map('count', lambda (word, ones): (word, sum(ones))))
... in __or__ return self.pipeline.apply(ptransform, self)
... in apply transform.type_check_inputs(pvalueish)
... in type_check_inputs self.type_check_inputs_or_outputs(pvalueish, 'input')
... in type_check_inputs_or_outputs pvalue_.element_type))
google.cloud.dataflow.typehints.decorators.TypeCheckError: Input type hint violation at group: expected Tuple[TypeVariable[K], TypeVariable[V]], got <type 'str'>
Vai
Ad esempio, se la pipeline utilizza una `DoFn` che non accetta input, viene visualizzato un messaggio di errore simile al seguente:
... panic: Method ProcessElement in DoFn main.extractFn is missing all inputs. A main input is required. ... Full error: ... inserting ParDo in scope root/CountWords ... graph.AsDoFn: for Fn named main.extractFn ... ProcessElement method has no main inputs ... goroutine 1 [running]: ... github.com/apache/beam/sdks/v2/go/pkg/beam.MustN(...) ... (more stacktrace)
Se si verifica un errore di questo tipo, controlla il codice della pipeline per assicurarti che le operazioni della pipeline siano legali.
Rilevare errori nella convalida dei job Dataflow
Una volta che il servizio Dataflow ha ricevuto il grafico della pipeline, tenta di convalidare il job. Questa convalida include quanto segue:
- Assicurarsi che il servizio possa accedere ai bucket Cloud Storage associati al job per l'area di staging dei file e l'output gestione temporanea.
- Verifica delle autorizzazioni richieste nel progetto Google Cloud .
- Assicurarsi che il servizio possa accedere alle origini di input e output, ad esempio i file.
Se il job non supera il processo di convalida, viene visualizzato un messaggio di errore nell'interfaccia di monitoraggio Dataflow, nonché nella finestra della console o del terminale se utilizzi l'esecuzione bloccante. Il messaggio di errore è simile al seguente:
Java
INFO: To access the Dataflow monitoring console, please navigate to
https://console.developers.google.com/project/google.com%3Aclouddfe/dataflow/job/2016-03-08_18_59_25-16868399470801620798
Submitted job: 2016-03-08_18_59_25-16868399470801620798
...
... Starting 3 workers...
... Executing operation BigQuery-Read+AnonymousParDo+BigQuery-Write
... Executing BigQuery import job "dataflow_job_16868399470801619475".
... Stopping worker pool...
... Workflow failed. Causes: ...BigQuery-Read+AnonymousParDo+BigQuery-Write failed.
Causes: ... BigQuery getting table "non_existent_table" from dataset "cws_demo" in project "my_project" failed.
Message: Not found: Table x:cws_demo.non_existent_table HTTP Code: 404
... Worker pool stopped.
... com.google.cloud.dataflow.sdk.runners.BlockingDataflowPipelineRunner run
INFO: Job finished with status FAILED
Exception in thread "main" com.google.cloud.dataflow.sdk.runners.DataflowJobExecutionException:
Job 2016-03-08_18_59_25-16868399470801620798 failed with status FAILED
at com.google.cloud.dataflow.sdk.runners.DataflowRunner.run(DataflowRunner.java:155)
at com.google.cloud.dataflow.sdk.runners.DataflowRunner.run(DataflowRunner.java:56)
at com.google.cloud.dataflow.sdk.Pipeline.run(Pipeline.java:180)
at com.google.cloud.dataflow.integration.BigQueryCopyTableExample.main(BigQueryCopyTableExample.java:74)
Python
INFO:root:Created job with id: [2016-03-08_14_12_01-2117248033993412477] ... Checking required Cloud APIs are enabled. ... Job 2016-03-08_14_12_01-2117248033993412477 is in state JOB_STATE_RUNNING. ... Combiner lifting skipped for step group: GroupByKey not followed by a combiner. ... Expanding GroupByKey operations into optimizable parts. ... Lifting ValueCombiningMappingFns into MergeBucketsMappingFns ... Annotating graph with Autotuner information. ... Fusing adjacent ParDo, Read, Write, and Flatten operations ... Fusing consumer split into read ... ... Starting 1 workers... ... ... Executing operation read+split+pair_with_one+group/Reify+group/Write ... Executing failure step failure14 ... Workflow failed. Causes: ... read+split+pair_with_one+group/Reify+group/Write failed. Causes: ... Unable to view metadata for files: gs://dataflow-samples/shakespeare/missing.txt. ... Cleaning up. ... Tearing down pending resources... INFO:root:Job 2016-03-08_14_12_01-2117248033993412477 is in state JOB_STATE_FAILED.
Vai
La convalida del job descritta in questa sezione non è attualmente supportata per Go. Gli errori dovuti a questi problemi vengono visualizzati come eccezioni del worker.
Rilevare un'eccezione nel codice worker
Durante l'esecuzione del job, potresti riscontrare errori o eccezioni nel codice
del worker. Questi errori in genere indicano che i DoFn nel codice della pipeline
hanno generato eccezioni non gestite, che comportano l'esito negativo delle attività nel
job Dataflow.
Le eccezioni nel codice utente (ad esempio le istanze DoFn) vengono segnalate nell'interfaccia di monitoraggio Dataflow.
Se esegui la pipeline con l'esecuzione bloccante, i messaggi di errore vengono
stampati nella finestra della console o del terminale, ad esempio:
Java
INFO: To access the Dataflow monitoring console, please navigate to https://console.developers.google.com/project/example_project/dataflow/job/2017-05-23_14_02_46-1117850763061203461
Submitted job: 2017-05-23_14_02_46-1117850763061203461
...
... To cancel the job using the 'gcloud' tool, run: gcloud beta dataflow jobs --project=example_project cancel 2017-05-23_14_02_46-1117850763061203461
... Autoscaling is enabled for job 2017-05-23_14_02_46-1117850763061203461.
... The number of workers will be between 1 and 15.
... Autoscaling was automatically enabled for job 2017-05-23_14_02_46-1117850763061203461.
...
... Executing operation BigQueryIO.Write/BatchLoads/Create/Read(CreateSource)+BigQueryIO.Write/BatchLoads/GetTempFilePrefix+BigQueryIO.Write/BatchLoads/TempFilePrefixView/BatchViewOverrides.GroupByWindowHashAsKeyAndWindowAsSortKey/ParDo(UseWindowHashAsKeyAndWindowAsSortKey)+BigQueryIO.Write/BatchLoads/TempFilePrefixView/Combine.GloballyAsSingletonView/Combine.globally(Singleton)/WithKeys/AddKeys/Map/ParMultiDo(Anonymous)+BigQueryIO.Write/BatchLoads/TempFilePrefixView/Combine.GloballyAsSingletonView/Combine.globally(Singleton)/Combine.perKey(Singleton)/GroupByKey/Reify+BigQueryIO.Write/BatchLoads/TempFilePrefixView/Combine.GloballyAsSingletonView/Combine.globally(Singleton)/Combine.perKey(Singleton)/GroupByKey/Write+BigQueryIO.Write/BatchLoads/TempFilePrefixView/BatchViewOverrides.GroupByWindowHashAsKeyAndWindowAsSortKey/BatchViewOverrides.GroupByKeyAndSortValuesOnly/Write
... Workers have started successfully.
...
... org.apache.beam.runners.dataflow.util.MonitoringUtil$LoggingHandler process SEVERE: 2017-05-23T21:06:33.711Z: (c14bab21d699a182): java.lang.RuntimeException: org.apache.beam.sdk.util.UserCodeException: java.lang.ArithmeticException: / by zero
at com.google.cloud.dataflow.worker.runners.worker.GroupAlsoByWindowsParDoFn$1.output(GroupAlsoByWindowsParDoFn.java:146)
at com.google.cloud.dataflow.worker.runners.worker.GroupAlsoByWindowFnRunner$1.outputWindowedValue(GroupAlsoByWindowFnRunner.java:104)
at com.google.cloud.dataflow.worker.util.BatchGroupAlsoByWindowAndCombineFn.closeWindow(BatchGroupAlsoByWindowAndCombineFn.java:191)
...
... Cleaning up.
... Stopping worker pool...
... Worker pool stopped.
Python
INFO:root:Job 2016-03-08_14_21_32-8974754969325215880 is in state JOB_STATE_RUNNING. ... INFO:root:... Expanding GroupByKey operations into optimizable parts. INFO:root:... Lifting ValueCombiningMappingFns into MergeBucketsMappingFns INFO:root:... Annotating graph with Autotuner information. INFO:root:... Fusing adjacent ParDo, Read, Write, and Flatten operations ... INFO:root:...: Starting 1 workers... INFO:root:...: Executing operation group/Create INFO:root:...: Value "group/Session" materialized. INFO:root:...: Executing operation read+split+pair_with_one+group/Reify+group/Write INFO:root:Job 2016-03-08_14_21_32-8974754969325215880 is in state JOB_STATE_RUNNING. INFO:root:...: ...: Workers have started successfully. INFO:root:Job 2016-03-08_14_21_32-8974754969325215880 is in state JOB_STATE_RUNNING. INFO:root:...: Traceback (most recent call last): File ".../dataflow_worker/batchworker.py", line 384, in do_work self.current_executor.execute(work_item.map_task) ... File ".../apache_beam/examples/wordcount.runfiles/py/apache_beam/examples/wordcount.py", line 73, in <lambda> ValueError: invalid literal for int() with base 10: 'www'
Vai
... 2022-05-26T18:32:52.752315397Zprocess bundle failed for instruction ... process_bundle-4031463614776698457-2 using plan s02-6 : while executing ... Process for Plan[s02-6] failed: Oh no! This is an error message!
Valuta la possibilità di proteggerti dagli errori nel codice aggiungendo gestori di eccezioni. Ad esempio, se vuoi eliminare gli elementi che non superano una convalida personalizzata dell'input
eseguita in un ParDo, gestisci l'eccezione all'interno di DoFn ed elimina l'elemento.
Puoi anche monitorare gli elementi non riusciti in diversi modi:
- Puoi registrare gli elementi non riusciti e controllare l'output utilizzando Cloud Logging.
- Puoi controllare i log di avvio dei worker Dataflow e dei worker per verificare la presenza di avvisi o errori seguendo le istruzioni riportate in Visualizzazione dei log.
- Puoi chiedere a
ParDodi scrivere gli elementi non riusciti in un output aggiuntivo per un'ispezione successiva.
Per monitorare le proprietà di una pipeline in esecuzione, puoi utilizzare la classe Metrics,
come mostrato nell'esempio seguente:
Java
final Counter counter = Metrics.counter("stats", "even-items"); PCollection<Integer> input = pipeline.apply(...); ... input.apply(ParDo.of(new DoFn<Integer, Integer>() { @ProcessElement public void processElement(ProcessContext c) { if (c.element() % 2 == 0) { counter.inc(); } });
Python
class FilterTextFn(beam.DoFn): """A DoFn that filters for a specific key based on a regex.""" def __init__(self, pattern): self.pattern = pattern # A custom metric can track values in your pipeline as it runs. Create # custom metrics to count unmatched words, and know the distribution of # word lengths in the input PCollection. self.word_len_dist = Metrics.distribution(self.__class__, 'word_len_dist') self.unmatched_words = Metrics.counter(self.__class__, 'unmatched_words') def process(self, element): word = element self.word_len_dist.update(len(word)) if re.match(self.pattern, word): yield element else: self.unmatched_words.inc() filtered_words = ( words | 'FilterText' >> beam.ParDo(FilterTextFn('s.*')))
Vai
func addMetricDoFnToPipeline(s beam.Scope, input beam.PCollection) beam.PCollection { return beam.ParDo(s, &MyMetricsDoFn{}, input) } func executePipelineAndGetMetrics(ctx context.Context, p *beam.Pipeline) (metrics.QueryResults, error) { pr, err := beam.Run(ctx, runner, p) if err != nil { return metrics.QueryResults{}, err } // Request the metric called "counter1" in namespace called "namespace" ms := pr.Metrics().Query(func(r beam.MetricResult) bool { return r.Namespace() == "namespace" && r.Name() == "counter1" }) // Print the metric value - there should be only one line because there is // only one metric called "counter1" in the namespace called "namespace" for _, c := range ms.Counters() { fmt.Println(c.Namespace(), "-", c.Name(), ":", c.Committed) } return ms, nil } type MyMetricsDoFn struct { counter beam.Counter } func init() { beam.RegisterType(reflect.TypeOf((*MyMetricsDoFn)(nil))) } func (fn *MyMetricsDoFn) Setup() { // While metrics can be defined in package scope or dynamically // it's most efficient to include them in the DoFn. fn.counter = beam.NewCounter("namespace", "counter1") } func (fn *MyMetricsDoFn) ProcessElement(ctx context.Context, v beam.V, emit func(beam.V)) { // count the elements fn.counter.Inc(ctx, 1) emit(v) }
Risolvere i problemi relativi a pipeline lente o alla mancanza di output
Consulta le seguenti pagine:
- Risolvi i problemi relativi ai job di streaming lenti o bloccati.
- Risolvi i problemi relativi ai job batch lenti o bloccati.
Errori comuni e azioni da intraprendere
Quando conosci l'errore che ha causato l'interruzione della pipeline, consulta la pagina Risolvere i problemi relativi agli errori di Dataflow per indicazioni sulla risoluzione dei problemi relativi agli errori.