En esta página se describe cómo encontrar y resolver errores de falta de memoria (OOM) en Dataflow.
Buscar errores de falta de memoria
Para determinar si tu flujo de procesamiento se está quedando sin memoria, usa uno de los siguientes métodos.
- En la página Detalles de la tarea, en el panel Registros, consulte la pestaña Diagnóstico. En esta pestaña se muestran los errores relacionados con problemas de memoria y la frecuencia con la que se producen.
- En la interfaz de monitorización de Dataflow, usa el gráfico Uso de la memoria para monitorizar la capacidad y el uso de la memoria de los trabajadores.
- En la página Detalles de la tarea, en el panel Registros, selecciona Registros de trabajador para ver los errores de falta de memoria en los registros de trabajador.
También pueden aparecer errores de falta de memoria en los registros del sistema. Para verlos, ve al Explorador de registros y usa la siguiente consulta:
resource.type="dataflow_step" resource.labels.job_id="JOB_ID" "out of memory" OR "OutOfMemory" OR "Shutting down JVM"Sustituye JOB_ID por el ID de tu trabajo.
En el caso de los trabajos de Java, el monitor de memoria de Java informa periódicamente de las métricas de recolección de elementos no utilizados. Si la fracción del tiempo de CPU utilizado para la recogida de elementos no utilizados supera un umbral del 50% durante un periodo prolongado, el arnés del SDK falla. Es posible que aparezca un error similar al siguiente ejemplo:
Shutting down JVM after 8 consecutive periods of measured GC thrashing. Memory is used/total/max = ...Este error puede producirse cuando aún hay memoria física disponible y suele indicar que el uso de memoria de la canalización es ineficiente. Para resolver este problema, optimiza tu flujo de procesamiento.
El monitor de memoria de Java se configura mediante la interfaz
MemoryMonitorOptions.
Si tu trabajo tiene un uso elevado de memoria o errores de falta de memoria, sigue las recomendaciones de esta página para optimizar el uso de memoria o aumentar la cantidad de memoria disponible.
Resolver errores de falta de memoria
Los cambios en tu canalización de Dataflow pueden resolver errores de falta de memoria o reducir el uso de memoria. Entre los cambios posibles se incluyen las siguientes acciones:
- Optimizar la cartera
- Reduce el número de conversaciones
- Usar un tipo de máquina con más memoria por vCPU
En el siguiente diagrama se muestra el flujo de trabajo para solucionar problemas de Dataflow que se describe en esta página.
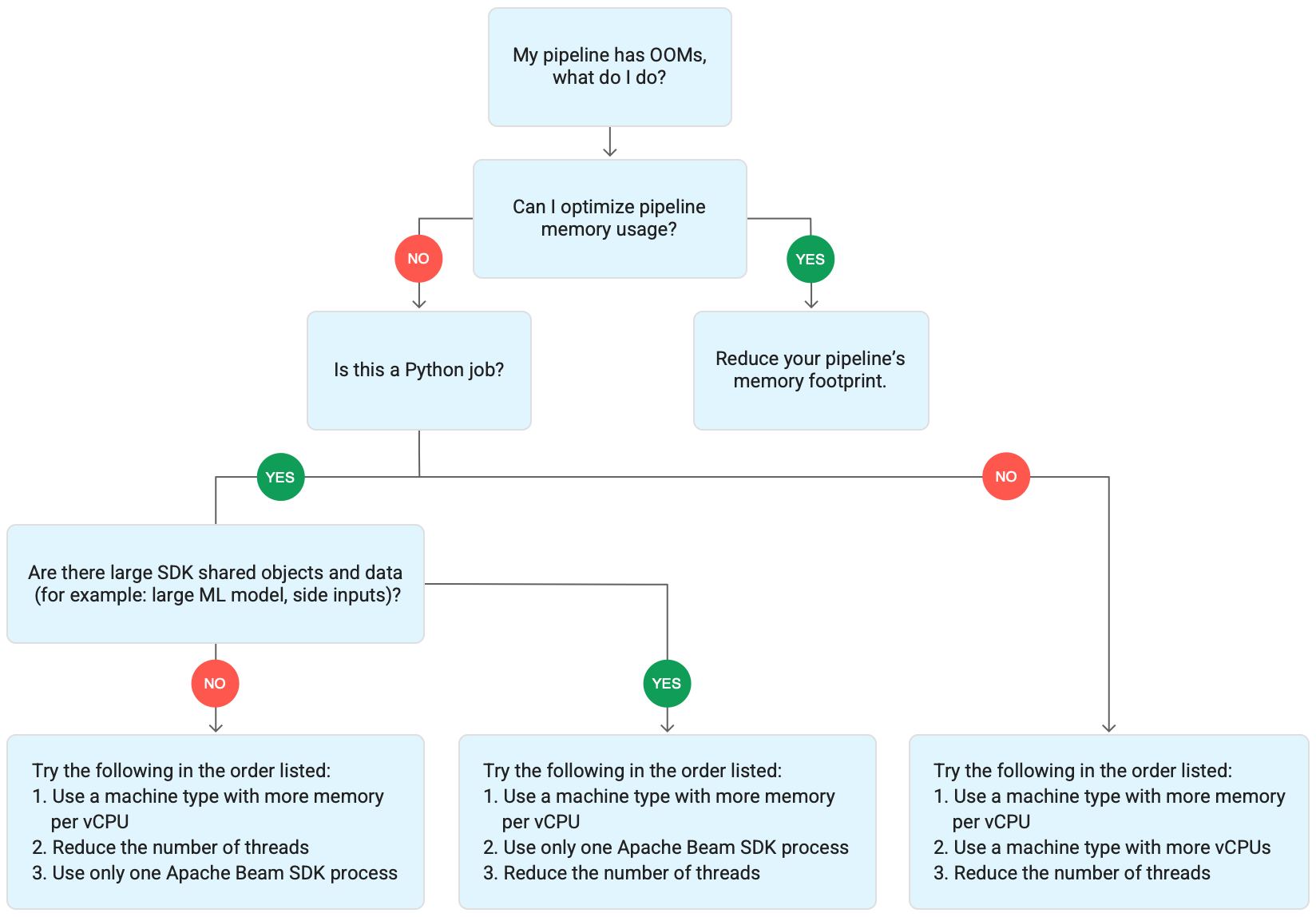
Prueba las siguientes medidas de mitigación:
- Si es posible, optimiza tu canalización para reducir el uso de memoria.
- Si el trabajo es un trabajo por lotes, prueba los siguientes pasos en el orden indicado:
- Usa un tipo de máquina con más memoria por vCPU.
- Reduce el número de hilos a un valor inferior al número de vCPUs por trabajador.
- Usa un tipo de máquina personalizado con más memoria por vCPU.
- Si la tarea es una tarea de streaming que usa Python, reduce el número de subprocesos a menos de 12.
- Si el trabajo es un trabajo de streaming que usa Java o Go, prueba lo siguiente:
- Reduce el número de subprocesos a menos de 500 en las tareas de Runner v2 o a menos de 300 en las tareas que no usen Runner v2.
- Usa un tipo de máquina con más memoria.
Optimizar tu flujo de trabajo
Varias operaciones de la canalización pueden provocar errores de falta de memoria. En esta sección se ofrecen opciones para reducir el uso de memoria de tu flujo de procesamiento. Para identificar las fases de la canalización que consumen más memoria, usa Cloud Profiler para monitorizar el rendimiento de la canalización.
Puede seguir estas prácticas recomendadas para optimizar su canal:
- Usar conectores de E/S integrados de Apache Beam para leer archivos
- Rediseñar las operaciones al usar
GroupByKeyPTransforms - Reducir los datos de entrada de fuentes externas
- Compartir objetos entre conversaciones
- Usar representaciones de elementos eficientes en cuanto a memoria
- Reducir el tamaño de las entradas laterales
- Usar DoFns divisibles de Apache Beam
Usar conectores de E/integrados de Apache Beam para leer archivos
No abras archivos grandes dentro de un DoFn. Para leer archivos, usa los conectores de E/S integrados de Apache Beam.
Los archivos abiertos en un DoFn deben caber en la memoria. Como se ejecutan varias instancias de DoFn simultáneamente, los archivos de gran tamaño que se abren en DoFn pueden provocar errores de falta de memoria.
Rediseñar operaciones al usar GroupByKey PTransforms
Cuando usas una GroupByKey PTransform en Dataflow, los valores por clave y por ventana resultantes se procesan en un solo subproceso. Como estos datos se transfieren como un flujo desde el servicio backend de Dataflow a los trabajadores, no es necesario que quepan en la memoria de los trabajadores. Sin embargo, si los valores se recogen en la memoria, la lógica de procesamiento puede provocar errores de falta de memoria.
Por ejemplo, si tiene una clave que contiene datos de una ventana y añade los valores de clave a un objeto en memoria, como una lista, pueden producirse errores de falta de memoria. En este caso, es posible que el trabajador no tenga suficiente capacidad de memoria para contener todos los objetos.
Para obtener más información sobre las GroupByKey PTransforms, consulta la documentación de Apache Beam sobre Python GroupByKey
y Java GroupByKey.
La siguiente lista contiene sugerencias para diseñar tu canalización de forma que se minimice el consumo de memoria al usar GroupByKey PTransforms.
- Para reducir la cantidad de datos por clave y por ventana, evita las claves con muchos valores, también conocidas como "claves activas".
- Para reducir la cantidad de datos recogidos por ventana, usa un tamaño de ventana más pequeño.
- Si vas a usar los valores de una clave en una ventana para calcular un número, usa una transformación
Combine. No hagas el cálculo en una sola instancia deDoFndespués de recoger los valores. - Filtrar valores o duplicados antes de procesarlos. Para obtener más información, consulta la documentación de las transformaciones de Python
Filtery JavaFilter.
Reducir los datos de entrada de fuentes externas
Si haces llamadas a una API externa o a una base de datos para enriquecer los datos, los datos devueltos deben caber en la memoria del trabajador.
Si vas a agrupar llamadas por lotes, te recomendamos que uses una transformación GroupIntoBatches.
Si se producen errores de falta de memoria, reduce el tamaño del lote. Para obtener más información sobre cómo agrupar en lotes, consulta la documentación de la transformación Python GroupIntoBatches
y Java GroupIntoBatches.
Compartir objetos entre subprocesos
Compartir un objeto de datos en memoria entre instancias de DoFn puede mejorar la eficiencia del espacio y del acceso. Los objetos de datos creados en cualquier método de DoFn, incluidos Setup, StartBundle, Process, FinishBundle y Teardown, se invocan para cada DoFn. En Dataflow, cada trabajador puede tener varias DoFn
instancias. Para usar la memoria de forma más eficiente, pasa un objeto de datos como singleton para compartirlo entre varios DoFns. Para obtener más información, consulta la entrada de blog Reutilización de la caché en DoFns.
Usar representaciones de elementos eficientes en cuanto a memoria
Evalúa si puedes usar representaciones para PCollection
elementos que usen menos memoria. Cuando uses codificadores en tu canalización, ten en cuenta no solo las representaciones de elementos PCollection codificadas, sino también las decodificadas. Las matrices dispersas a menudo se benefician de este tipo de optimización.
Reducir el tamaño de las entradas secundarias
Si tus DoFns usan entradas laterales, reduce el tamaño de la entrada lateral. En el caso de las entradas secundarias que son colecciones de elementos, te recomendamos que uses vistas iterables, como AsIterable o AsMultimap, en lugar de vistas que materialicen toda la entrada secundaria al mismo tiempo, como AsList.
Reduce el número de cadenas
Puedes aumentar la memoria disponible por hilo reduciendo el número máximo de hilos que ejecutan instancias de DoFn. Este cambio reduce el paralelismo, pero
hace que haya más memoria disponible para cada DoFn.
En la siguiente tabla se muestra el número predeterminado de subprocesos que crea Dataflow:
| Tipo de tarea | SDK de Python | SDKs de Java y Go |
|---|---|---|
| Lotes | 1 subproceso por vCPU | 1 subproceso por vCPU |
| Streaming con Runner v2 | 12 subprocesos por vCPU | 500 subprocesos por VM de trabajador |
| Streaming sin Runner v2 | 12 subprocesos por vCPU | 300 hilos por VM de trabajador |
Para reducir el número de subprocesos del SDK de Apache Beam, define la siguiente opción de canalización:
Java
Usa la opción de canalización --numberOfWorkerHarnessThreads.
Python
Usa la opción de canalización --number_of_worker_harness_threads.
Go
Usa la opción de canalización --number_of_worker_harness_threads.
En el caso de las tareas por lotes, asigna un valor inferior al número de vCPUs.
En el caso de las tareas de streaming, empieza por reducir el valor a la mitad del valor predeterminado. Si este paso no mitiga el problema, sigue reduciendo el valor a la mitad y observa los resultados en cada paso. Por ejemplo, si usas Python, prueba con los valores 6, 3 y 1.
Usar un tipo de máquina con más memoria por vCPU
Para seleccionar un trabajador con más memoria por vCPU, utilice uno de los siguientes métodos.
- Usa un tipo de máquina con alta capacidad de memoria de la familia de máquinas de uso general. Los tipos de máquinas con alta capacidad de memoria tienen más memoria por vCPU que los tipos de máquinas estándar. Si usas un tipo de máquina con mucha memoria, aumentará la memoria disponible para cada trabajador y la memoria disponible por subproceso, ya que el número de vCPUs seguirá siendo el mismo. Por lo tanto, usar un tipo de máquina con alta capacidad de memoria puede ser una forma rentable de seleccionar un trabajador con más memoria por vCPU.
- Para tener más flexibilidad a la hora de especificar el número de vCPUs y la cantidad de memoria, puedes usar un tipo de máquina personalizada. Con los tipos de máquinas personalizadas, puedes aumentar la memoria en incrementos de 256 MB. Estos tipos de máquinas tienen precios diferentes a los de los tipos de máquinas estándar.
- Algunas familias de máquinas te permiten usar tipos de máquinas personalizadas con memoria ampliada. La memoria ampliada permite una mayor proporción de memoria por vCPU. El coste es más alto.
Para definir los tipos de trabajador, usa la siguiente opción de la canalización. Para obtener más información, consulta Configurar opciones de la canalización y Opciones de la canalización.
Java
Usa la opción de canalización --workerMachineType.
Python
Usa la opción de canalización --machine_type.
Go
Usa la opción de canalización --worker_machine_type.
Usar solo un proceso del SDK de Apache Beam
En el caso de las canalizaciones de streaming de Python y las canalizaciones de Python que usan Runner v2, puedes forzar a Dataflow a iniciar solo un proceso del SDK de Apache Beam por trabajador. Antes de probar esta opción, intenta resolver el problema con los otros métodos. Para configurar las VMs de trabajador de Dataflow de forma que solo inicien un proceso de Python contenedorizado, usa la siguiente opción de canalización:
--experiments=no_use_multiple_sdk_containers
Con esta configuración, las canalizaciones de Python crean un proceso del SDK de Apache Beam por trabajador. Esta configuración evita que los objetos y los datos compartidos se repliquen varias veces en cada proceso del SDK de Apache Beam. Sin embargo, limita el uso eficiente de los recursos de computación disponibles en el trabajador.
Reducir el número de procesos del SDK de Apache Beam a uno no implica necesariamente que se reduzca el número total de hilos iniciados en el trabajador. Además, si todos los subprocesos se ejecutan en un único proceso del SDK de Apache Beam, el procesamiento puede ser lento o el flujo de trabajo puede quedarse bloqueado. Por lo tanto, es posible que también tengas que reducir el número de hilos, tal como se describe en la sección Reduce el número de hilos de esta página.
También puedes obligar a los trabajadores a usar solo un proceso del SDK de Apache Beam mediante un tipo de máquina con solo una vCPU.
Información sobre el uso de memoria de Dataflow
Para solucionar errores de falta de memoria, es útil saber cómo usan la memoria las canalizaciones de Dataflow.
Cuando Dataflow ejecuta una canalización, el procesamiento se distribuye entre varias máquinas virtuales de Compute Engine, a menudo denominadas "trabajadores".
Los trabajadores procesan elementos de trabajo del servicio Dataflow y los delegan en procesos del SDK de Apache Beam. Un proceso del SDK de Apache Beam crea instancias de DoFn. DoFn es una clase del SDK de Apache Beam que define una función de procesamiento distribuido.
Dataflow inicia varios subprocesos en cada trabajador y la memoria de cada trabajador se comparte entre todos los subprocesos. Un hilo es una sola tarea ejecutable que se ejecuta en un proceso más grande. El número predeterminado de hilos depende de varios factores y varía entre los trabajos por lotes y los de streaming.
Si tu flujo de trabajo necesita más memoria que la cantidad predeterminada disponible en los trabajadores, es posible que se produzcan errores de falta de memoria.
Las canalizaciones de Dataflow usan principalmente la memoria de los trabajadores de tres formas:
Memoria operativa del trabajador
Los trabajadores de Dataflow necesitan memoria para sus sistemas operativos y procesos del sistema. El uso de memoria de los trabajadores no suele superar 1 GB. El uso suele ser inferior a 1 GB.
- Varios procesos del trabajador usan memoria para asegurarse de que tu canalización funciona correctamente. Cada uno de estos procesos puede reservar una pequeña cantidad de memoria para su funcionamiento.
- Cuando tu flujo de procesamiento no usa Streaming Engine, los procesos de trabajo adicionales usan memoria.
Memoria de proceso del SDK
Los procesos del SDK de Apache Beam pueden crear objetos y datos que se comparten entre los subprocesos del proceso, a los que se hace referencia en esta página como objetos y datos compartidos del SDK. El uso de memoria de estos objetos y datos compartidos del SDK se denomina memoria de proceso del SDK. En la siguiente lista se incluyen ejemplos de objetos y datos compartidos del SDK:
- Entradas secundarias
- Modelos de aprendizaje automático
- Objetos singleton en memoria
- Objetos de Python creados con el módulo
apache_beam.utils.shared - Datos cargados desde fuentes externas, como Cloud Storage o BigQuery
Las tareas de streaming que no usan Streaming Engine almacenan las entradas laterales en la memoria. En las canalizaciones de Java y Go, cada trabajador tiene una copia de la entrada auxiliar. En el caso de las canalizaciones de Python, cada proceso del SDK de Apache Beam tiene una copia de la entrada auxiliar.
Las tareas de streaming que usan Streaming Engine tienen un límite de tamaño de entrada lateral de 80 MB. Las entradas secundarias se almacenan fuera de la memoria de los trabajadores.
El uso de memoria de los objetos y datos compartidos del SDK crece de forma lineal con el número de procesos del SDK de Apache Beam. En los flujos de procesamiento de Java y Go, se inicia un proceso del SDK de Apache Beam por cada trabajador. En las canalizaciones de Python, se inicia un proceso del SDK de Apache Beam por cada vCPU. Los objetos compartidos y los datos del SDK se reutilizan en los diferentes subprocesos del mismo proceso del SDK de Apache Beam.
Uso de memoria DoFn
DoFn es una clase del SDK de Apache Beam que define una función de procesamiento distribuido.
Cada trabajador puede ejecutar DoFn instancias simultáneas. Cada hilo ejecuta una DoFn
instancia. Al evaluar el uso total de memoria, puede ser útil calcular el tamaño del conjunto de trabajo o la cantidad de memoria necesaria para que una aplicación siga funcionando. Por ejemplo, si un DoFn individual usa un máximo de 5 MB de memoria y un trabajador tiene 300 hilos, el uso de memoria de DoFn podría alcanzar un máximo de 1,5 GB, o el número de bytes de memoria multiplicado por el número de hilos. En función de cómo usen la memoria los trabajadores, un pico en el uso de memoria podría provocar que se queden sin memoria.
Es difícil estimar cuántas instancias de un DoFn crea Dataflow. El número depende de varios factores, como el SDK y el tipo de máquina. Además, es posible que varios subprocesos utilicen el DoFn de forma sucesiva.
El servicio Dataflow no garantiza cuántas veces se invoca un DoFn ni el número exacto de instancias de DoFn que se crean a lo largo de una canalización.
Sin embargo, en la siguiente tabla se ofrece información sobre el nivel de paralelismo que puedes esperar y se estima un límite superior del número de instancias de DoFn.
SDK de Python de Beam
| Lotes | Streaming sin Streaming Engine | Streaming Engine | |
|---|---|---|---|
| Paralelismo |
1 proceso por vCPU 1 subproceso por proceso 1 subproceso por vCPU
|
1 proceso por vCPU 12 subprocesos por proceso 12 subprocesos por vCPU |
1 proceso por vCPU 12 subprocesos por proceso 12 subprocesos por vCPU
|
Número máximo de instancias simultáneas de DoFn (todos estos números están sujetos a cambios en cualquier momento). |
1 DoFn por conversación
1
|
1 DoFn por conversación
12
|
1 DoFn por conversación
12
|
SDK de Beam para Java o Go
| Lotes | Streaming Appliance y Streaming Engine sin runner v2 | Streaming Engine con runner v2 | |
|---|---|---|---|
| Paralelismo |
1 proceso por VM de trabajador 1 subproceso por vCPU
|
1 proceso por VM de trabajador 300 subprocesos por proceso 300 hilos por VM de trabajador
|
1 proceso por VM de trabajador 500 subprocesos por proceso 500 subprocesos por VM de trabajador
|
Número máximo de instancias simultáneas de DoFn (todos estos números están sujetos a cambios en cualquier momento). |
1 DoFn por conversación
1
|
1 DoFn por conversación
300
|
1 DoFn por conversación
500
|
Por ejemplo, cuando se usa el SDK de Python con un n1-standard-2trabajador de Dataflow, se aplican las siguientes condiciones:
- Tareas por lotes: Dataflow inicia un proceso por vCPU (dos en este caso). Cada proceso usa un hilo y cada hilo crea una instancia de
DoFn. - Tareas de streaming con Streaming Engine: Dataflow inicia un proceso por vCPU (dos en total). Sin embargo, cada proceso puede generar hasta 12 subprocesos, cada uno con su propia instancia de DoFn.
Cuando diseñas pipelines complejos, es importante que conozcas el DoFnciclo de vida.
Asegúrate de que tus funciones DoFn sean serializables y no modifiques el argumento element
directamente en ellas.
Si tienes una canalización multilingüe y se está ejecutando más de un SDK de Apache Beam en el trabajador, este usará el grado más bajo posible de paralelismo de un hilo por proceso.
Diferencias entre Java, Go y Python
Java, Go y Python gestionan los procesos y la memoria de forma diferente. Por lo tanto, el enfoque que debes adoptar para solucionar los errores de falta de memoria varía en función de si tu canalización usa Java, Go o Python.
Pipelines de Java y Go
En las canalizaciones de Java y Go:
- Cada trabajador inicia un proceso del SDK de Apache Beam.
- Los objetos y datos compartidos del SDK, como las entradas laterales y las cachés, se comparten entre todos los subprocesos del trabajador.
- La memoria que usan los objetos y los datos compartidos del SDK no suele escalarse en función del número de vCPUs del trabajador.
Pipelines de Python
En las canalizaciones de Python:
- Cada trabajador inicia un proceso del SDK de Apache Beam por vCPU.
- Los objetos y los datos compartidos del SDK, como las entradas secundarias y las cachés, se comparten entre todos los subprocesos de cada proceso del SDK de Apache Beam.
- El número total de hilos del trabajador se escala linealmente en función del número de vCPUs. Por lo tanto, la memoria que usan los objetos y los datos compartidos del SDK aumenta de forma lineal con el número de vCPUs.
- Los hilos que realizan el trabajo se distribuyen entre los procesos. Las nuevas unidades de trabajo se asignan a un proceso sin elementos de trabajo o al proceso con el menor número de elementos de trabajo asignados.