Nesta página, descrevemos como encontrar e resolver erros de falta de memória (OOM) no Dataflow.
Encontrar erros de memória insuficiente
Para determinar se o pipeline está ficando sem memória, use um dos métodos a seguir.
- Na página Detalhes do job, no painel Registros, consulte a guia Diagnóstico. Esta guia exibe erros relacionados a problemas de memória e com que frequência eles ocorrem.
- Na interface de monitoramento do Dataflow, use o gráfico de Utilização da memória para monitorar a capacidade e o uso da memória do worker.
- Na página Detalhes do job, no painel Registros, selecione Registros de worker para encontrar erros de memória insuficiente nos registros de worker.
Erros de falta de memória também podem aparecer nos registros do sistema. Para conferir esses dados, navegue até o Explorador de registros e use a seguinte consulta:
resource.type="dataflow_step" resource.labels.job_id="JOB_ID" "out of memory" OR "OutOfMemory" OR "Shutting down JVM"Substitua JOB_ID pelo ID do job.
No caso de jobs em Java, o monitor de memória Java gera relatórios periódicos de métricas de coleta de lixo. Se a fração do tempo de CPU usada para coleta de lixo exceder um limite de 50% por um longo período, o arcabouço do SDK vai falhar. Talvez você encontre um erro semelhante ao exemplo a seguir:
Shutting down JVM after 8 consecutive periods of measured GC thrashing. Memory is used/total/max = ...Esse erro pode ocorrer quando a memória física ainda está disponível e geralmente indica que o uso da memória do pipeline é ineficiente. Para resolver esse problema, otimize o pipeline.
O monitor de memória Java é configurado pela interface
MemoryMonitorOptions.
Se o job tiver alto uso de memória ou erros de falta de memória, siga as recomendações desta página para otimizar o uso da memória ou aumentar a quantidade de memória disponível.
Resolver erros de falta de memória
Fazer alterações no pipeline do Dataflow pode resolver erros de falta de memória ou reduzir o uso da memória. As possíveis alterações incluem as seguintes ações:
- Otimizar o pipeline
- Reduzir o número de linhas de execução
- Use um tipo de máquina com mais memória por vCPU
O diagrama a seguir mostra o fluxo de trabalho da solução de problemas do Dataflow descrito nesta página.
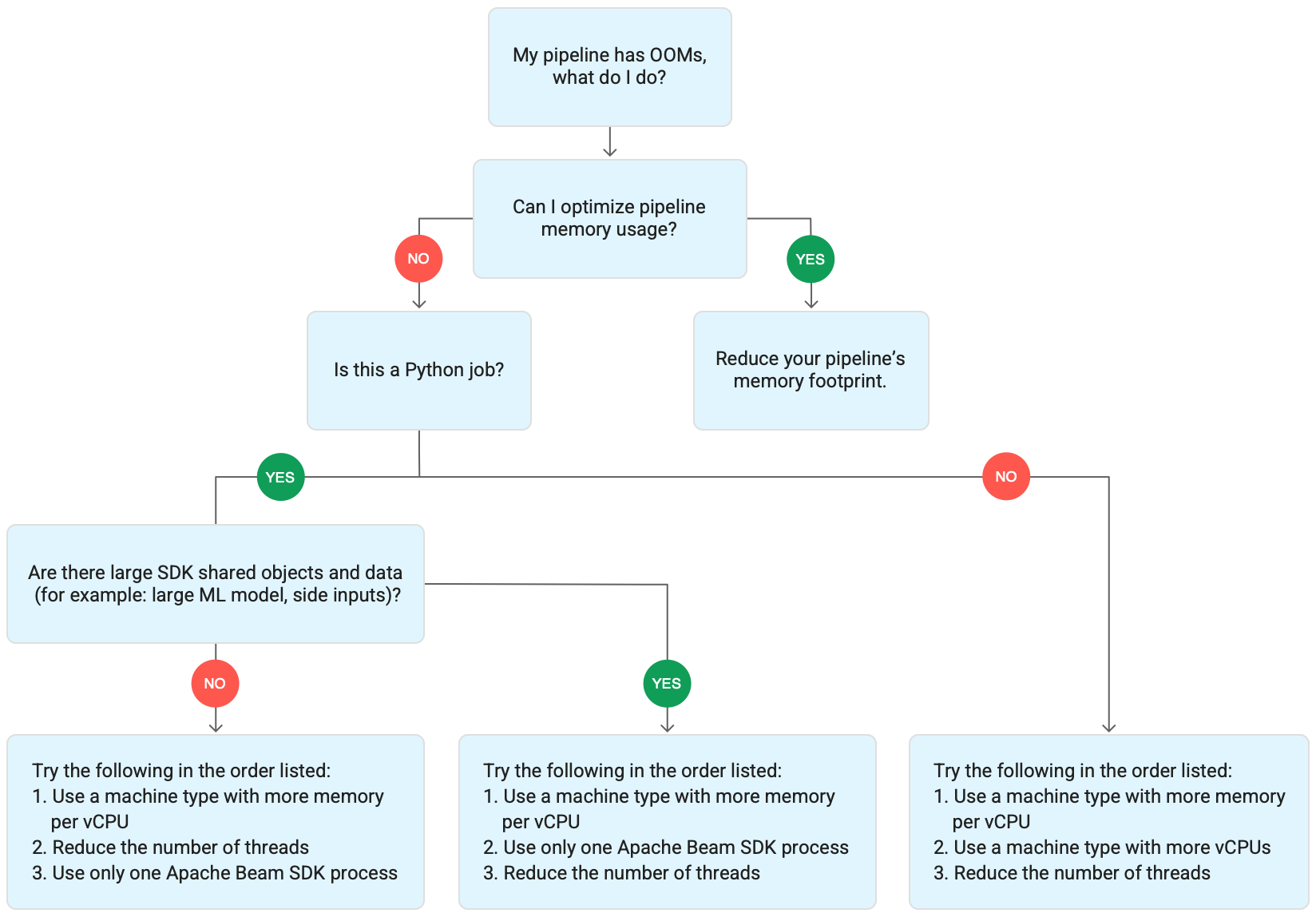
Tente as seguintes soluções:
- Se possível, otimize o pipeline para reduzir o uso de memória.
- Se o job for em job em lote, siga estas etapas na ordem listada:
- Use um tipo de máquina com mais memória por vCPU.
- Reduza o número de linhas de execução para menos do que a contagem de vCPUs por worker.
- Use um tipo de máquina personalizado com mais memória por vCPU.
- Se o job for de streaming e usar Python, reduza o número de linhas de execução para menos de 12.
- Se o job for de streaming e usar Java ou Go, tente o seguinte:
- Reduza o número de linhas de execução para menos de 500 em jobs do Runner v2 ou menos de 300 em jobs que não usam o Runner v2.
- Use um tipo de máquina com mais memória.
Otimizar o pipeline
Várias operações de pipeline podem causar erros de falta de memória. Nesta seção, apresentamos opções para reduzir o uso de memória do seu pipeline. Para identificar os estágios de pipeline que consomem mais memória, use o Cloud Profiler para monitorar o desempenho do pipeline.
Para otimizar seu pipeline, siga estas práticas recomendadas:
- Usar conectores de E/S integrados do Apache Beam para ler arquivos
- Reformular operações ao usar PTransforms do
GroupByKey - Reduzir os dados de entrada de fontes externas
- Compartilhar objetos em linhas de execução
- Usar representações de elementos com eficiência de memória
- Reduzir o tamanho das entradas secundárias
- Usar DoFns divisíveis do Apache Beam
Usar conectores de E/S integrados do Apache Beam para ler arquivos
Não abra arquivos grandes em uma DoFn. Para ler arquivos, use os conectores de E/S integrados ao Apache Beam.
Os arquivos abertos em uma DoFn precisam caber na memória. Como várias instâncias do DoFn são executadas
simultaneamente, arquivos grandes abertos em DoFns podem causar erros de falta de memória.
Reformular operações ao usar PTransforms do GroupByKey
Ao usar uma PTransform do GroupByKey no Dataflow, os valores resultantes
por chave e janela são processados em uma única linha de execução. Como esses dados são
transmitidos como um fluxo do serviço de back-end do Dataflow para os
workers, eles não precisam se ajustar à memória do worker. No entanto, se os valores forem
coletados na memória, a lógica de processamento pode causar erros de falta de memória.
Por exemplo, se você tiver uma chave que contém dados de uma janela e adicionar os valores de chave a um objeto na memória, como uma lista, poderão ocorrer erros de falta de memória. Nesse cenário, o worker pode não ter capacidade de memória suficiente para conter todos os objetos.
Para mais informações sobre PTransforms do GroupByKey, consulte a documentação de GroupByKey em Python e de GroupByKey em Java.
A lista a seguir contém sugestões para projetar o pipeline para minimizar
o consumo de memória ao usar PTransforms do GroupByKey.
- Para reduzir a quantidade de dados por chave e por janela, evite chaves com muitos valores, também conhecidas como chaves de atalho.
- Para reduzir a quantidade de dados coletados por janela, use uma janela menor.
- Se você estiver usando valores de uma chave em uma janela para calcular um número, use uma transformação
Combine. Não faça o cálculo em uma única instânciaDoFndepois de coletar os valores. - Filtre valores ou cópias antes do processamento. Para mais informações, consulte a documentação de transformação
Filterem Python eFilterem Java.
Reduzir os dados de entrada de fontes externas
Se você fizer chamadas a uma API externa ou a um banco de dados para aprimoramento de dados,
os dados retornados devem caber na memória do worker.
Se você estiver recebendo chamadas em lote, é recomendável usar uma transformação GroupIntoBatches.
Se você encontrar erros de memória insuficiente, reduza o tamanho do lote. Para mais informações
sobre como agrupar em lotes, consulte a
documentação de transformação
GroupIntoBatches em Python
e GroupIntoBatches em Java.
Compartilhar objetos em linhas de execução
O compartilhamento de um objeto de dados da memória em instâncias DoFn pode melhorar o espaço e
a eficiência de acesso. Os objetos de dados criados em qualquer método da DoFn, incluindo
Setup, StartBundle, Process, FinishBundle e Teardown, são invocados
para cada método DoFn. No Dataflow, cada worker pode ter várias instâncias
DoFn. Para um uso da memória mais eficiente, transmita um objeto de dados como um singleton para compartilhá-lo em várias DoFns. Para mais informações, consulte a postagem do blog
Reutilização de cache em DoFns (link em inglês).
Usar representações de elementos com eficiência de memória
Avalie se é possível usar representações para elementos PCollection
que usam menos memória. Ao usar codificadores no pipeline, considere não
apenas a codificação de elementos do elemento PCollection, mas também a decodificação. Geralmente, as matrizes esparsas
podem se beneficiar desse tipo de otimização.
Reduzir o tamanho das entradas secundárias
Se as DoFns usarem entradas secundárias, reduza o tamanho da entrada secundária. Para entradas
secundárias que são coleções de elementos, use visualizações iteráveis, como
AsIterable
ou AsMultimap, em vez de visualizações que materializam toda a entrada secundária ao mesmo tempo, como
AsList.
Reduzir o número de linhas de execução
É possível aumentar a memória disponível por linha de execução reduzindo o número máximo
de linhas de execução que executam instâncias de DoFn. Essa mudança reduz o paralelismo, mas disponibiliza mais memória para cada DoFn.
A tabela a seguir mostra o número padrão de linhas de execução que o Dataflow cria:
| Tipo de job | SDK do Python | SDKs do Java/Go |
|---|---|---|
| Lote | 1 linha de execução por vCPU | 1 linha de execução por vCPU |
| Streaming com o Runner v2 | 12 linhas de execução por vCPU | 500 linhas de execução por VM de worker |
| Streaming sem o Runner v2 | 12 linhas de execução por vCPU | 300 linhas de execução por VM de worker |
Para reduzir o número de linhas de execução do SDK do Apache Beam, defina a seguinte opção de pipeline:
Java
Usar a opção de pipeline --numberOfWorkerHarnessThreads.
Python
Usar a opção de pipeline --number_of_worker_harness_threads.
Go
Usar a opção de pipeline --number_of_worker_harness_threads.
Para jobs em lote, defina o valor como um número menor que o número de vCPUs.
Para jobs de streaming, comece reduzindo o valor para metade do padrão. Se essa etapa não resolver o problema, continue reduzindo o valor pela metade e observando os resultados em cada etapa. Por exemplo, ao usar Python, tente os valores 6, 3 e 1.
Usar um tipo de máquina com mais memória por vCPU
Para selecionar um worker com mais memória por vCPU, use um dos métodos a seguir.
- Use um tipo de máquina com alta memória na família de máquinas de uso geral. Os tipos de máquina com alta memória têm mais memória por vCPU do que os tipos de máquina padrão. Usar um tipo de máquina com grande quantidade de memória aumenta a memória disponível para cada worker e a memória disponível por linha de execução, porque o número de vCPUs permanece o mesmo. Como resultado, o uso de um tipo de máquina com grande quantidade de memória pode ser uma maneira econômica de selecionar um worker com mais memória por vCPU.
- Para ter mais flexibilidade ao especificar o número de vCPUs e o volume de memória, use um tipo de máquina personalizado. Com os tipos de máquina personalizados, é possível aumentar a memória em incrementos de 256 MB. Esses tipos de máquinas têm preços diferentes dos tipos padrão.
- Algumas famílias de máquinas permitem usar tipos de máquina personalizados de memória estendida. A memória estendida permite uma proporção maior de memória por vCPU. O custo é maior.
Para definir os tipos de workers, use a opção de pipeline a seguir. Para mais informações, consulte Como definir opções de pipeline e Opções de pipeline.
Java
Usar a opção de pipeline --workerMachineType.
Python
Usar a opção de pipeline --machine_type.
Go
Usar a opção de pipeline --worker_machine_type.
Usar apenas um processo do SDK do Apache Beam
Para pipelines de streaming do Python e pipelines do Python que usam o Runner v2, é possível forçar o Dataflow a iniciar apenas um processo do SDK do Apache Beam por worker. Antes de usar essa opção, tente resolver o problema usando os outros métodos. Para configurar as VMs de worker do Dataflow para iniciar somente um processo de Python conteinerizado, use a seguinte opção de pipeline:
--experiments=no_use_multiple_sdk_containers
Com essa configuração, os pipelines do Python criam um processo do SDK do Apache Beam por worker. Essa configuração impede que os objetos e dados compartilhados sejam replicados várias vezes para cada processo do SDK do Apache Beam. No entanto, isso limita o uso eficiente dos recursos de computação disponíveis no worker.
Reduzir o número de processos do SDK do Apache Beam para um não reduz necessariamente o número total de linhas de execução iniciadas no worker. Além disso, colocar todas as linhas de execução em um único processo do SDK do Apache Beam pode causar processamento lento ou fazer com que o pipeline fique travado. Portanto, você talvez precise reduzir o número de linhas de execução, conforme descrito na seção Reduzir o número de linhas de execução desta página.
Também é possível forçar os workers a usar somente um processo do SDK do Apache Beam com um tipo de máquina com apenas uma vCPU.
Entender o uso da memória do Dataflow
Para solucionar erros de falta de memória, é útil entender como os pipelines do Dataflow usam a memória.
Quando o Dataflow executa um pipeline, o processamento é distribuído
em várias máquinas virtuais (VMs) do Compute Engine, geralmente chamadas de workers.
Os workers processam itens de trabalho do serviço do Dataflow
e delegam os itens de trabalho aos processos do SDK do Apache Beam. Um processo do SDK
do Apache Beam cria instâncias
de DoFns. DoFn é uma classe do SDK do Apache Beam que define uma função
de processamento distribuído.
O Dataflow inicia várias linhas de execução em cada worker, e a memória de cada worker é compartilhada em todas as linhas de execução. Uma linha de execução é uma única tarefa executável em um processo maior. O número padrão de linhas de execução depende de vários fatores e varia entre os jobs em lote e de streaming.
Se o pipeline precisar de mais memória do que a quantidade padrão disponível nos workers, talvez ocorram erros de falta de memória.
Os pipelines do Dataflow usam principalmente a memória do worker de três maneiras:
Memória operacional do worker
Os workers do Dataflow precisam de memória para os sistemas operacionais e processos do sistema. O uso da memória do worker normalmente não é maior que 1 GB. O uso normalmente é menor que 1 GB.
- Vários processos do worker usam memória para garantir que o pipeline funcione. Cada um desses processos pode reservar uma pequena quantidade de memória para a operação.
- Quando o pipeline não usa o Streaming Engine, outros processos de worker usam a memória.
Memória do processo do SDK
Os processos do SDK do Apache Beam podem criar objetos e dados compartilhados entre linhas de execução dentro do processo, chamados de objetos e dados compartilhados do SDK nesta página. O uso da memória desses objetos e dados compartilhados do SDK é chamado de memória de processo do SDK. A lista a seguir inclui exemplos de objetos e dados compartilhados do SDK:
- Entradas secundárias
- Modelos de machine learning
- Objetos singleton na memória
- Objetos Python criados com o
módulo
apache_beam.utils.shared - Dados carregados de fontes externas, como o Cloud Storage ou o BigQuery;
Jobs de streaming que não usam entradas secundárias de armazenamento do Streaming Engine na memória. Nos pipelines de Java e Go, cada worker tem uma cópia da entrada secundária. Para pipelines de Python, cada processo do SDK do Apache Beam tem uma cópia da entrada secundária.
Os jobs de streaming que usam o Streaming Engine têm um limite de tamanho de entrada secundária de 80 MB. As entradas secundárias são armazenadas fora da memória do worker.
O uso da memória de objetos e dados compartilhados do SDK cresce de maneira linear com o número de processos do SDK do Apache Beam. Em pipelines de Java e Go, um processo do SDK do Apache Beam é iniciado por worker. Nos pipelines do Python, um processo do SDK do Apache Beam é iniciado por vCPU. Os objetos e dados compartilhados do SDK são reutilizados em linhas de execução no mesmo processo do SDK do Apache Beam.
DoFn Uso da memória
DoFn é uma classe do SDK do Apache Beam que define uma função
de processamento distribuído.
Cada worker pode executar instâncias DoFn simultâneas. Cada linha de execução executa uma instância
de DoFn. Ao avaliar o uso total da memória, calcular o tamanho do conjunto de trabalho ou
a quantidade de memória necessária para que um aplicativo continue funcionando pode ser
útil. Por exemplo, se uma DoFn individual usar
no máximo 5 MB de memória e um worker tiver 300 linhas de execução, o uso da memória de DoFn poderá atingir 1,5 MB ou o número de bytes de memória multiplicado pelo
número de linhas de execução. Dependendo de como os workers usam a memória, um pico no uso da memória pode fazer com que eles fiquem sem memória.
É difícil estimar quantas instâncias de um DoFn são criados. O número depende de vários fatores, como o SDK, o tipo de máquina e assim por diante. Além disso, o DoFn pode ser usado por vários threads sucessivamente.
O serviço do Dataflow não garante quantas vezes uma DoFn é invocada,
nem garante o número exato de instâncias de DoFn criadas durante um pipeline.
A tabela a seguir fornece alguns insights sobre o nível de paralelismo
esperado e estima um limite superior do
número de instâncias de DoFn.
SDK do Beam para Python
| Lote | Streaming sem o Streaming Engine | Streaming Engine | |
|---|---|---|---|
| Paralelismo |
1 processo por vCPU 1 linha de execução por processo 1 linha de execução por vCPU
|
1 processo por vCPU 12 linhas de execução por processo 12 linhas de execução por vCPU |
1 processo por vCPU 12 linhas de execução por processo 12 linhas de execução por vCPU
|
Número máximo de instâncias DoFn simultâneas (esses números estão sujeitos a alterações a qualquer momento). |
1 DoFn por linha de execução
1
|
1 DoFn por linha de execução
12
|
1 DoFn por linha de execução
12
|
SDK do Beam para Java/Go
| Lote | Streaming Appliance e Streaming Engine sem o runner v2 | Streaming Engine com o runner v2 | |
|---|---|---|---|
| Paralelismo |
1 processo por VM de worker 1 linha de execução por vCPU
|
1 processo por VM de worker 300 linhas de execução por processo 300 linhas de execução por VM de worker
|
1 processo por VM de worker 500 linhas de execução por processo 500 linhas de execução por VM de worker
|
Número máximo de instâncias DoFn simultâneas (esses números estão sujeitos a alterações a qualquer momento). |
1 DoFn por linha de execução
1
|
1 DoFn por linha de execução
300
|
1 DoFn por linha de execução
500
|
Por exemplo, ao usar o SDK Python com um worker do Dataflow n1-standard-2, o seguinte se aplica:
- Jobs em lote: o Dataflow inicia um processo por vCPU (dois neste caso). Cada processo usa uma linha de execução, e cada linha de execução cria uma instância
de
DoFn. - Jobs de streaming com o Streaming Engine: o Dataflow inicia um processo por vCPU (total de dois). No entanto, cada processo pode gerar até 12 threads, cada uma com sua própria instância DoFn.
Ao criar pipelines complexos, é importante entender o ciclo de vida do DoFn.
Verifique se as funções DoFn são serializáveis e evite modificar o argumento do elemento diretamente nelas.
Quando você tem um pipeline de várias linguagens e mais de um SDK do Apache Beam está em execução no worker, o worker usa o menor grau de paralelismo de linhas de execução por processo.
Diferenças de Java, Go e Python
Java, Go e Python gerenciam processos e memória de maneiras diferentes. Como resultado, a abordagem que você precisa seguir para resolver erros de falta de memória varia, se o pipeline usar Java, Go ou Python.
Pipelines Java e Go
Em pipelines de Java e Go:
- Cada worker inicia um processo do SDK do Apache Beam.
- Os objetos e dados compartilhados do SDK, como entradas laterais e caches, são compartilhados entre todas as linhas de execução no worker.
- A memória usada por dados e objetos compartilhados do SDK geralmente não é escalonada com base no número de vCPUs no worker.
Pipelines do Python
Nos pipelines de Python:
- Cada worker inicia um processo do SDK do Apache Beam por vCPU.
- Objetos e dados compartilhados do SDK, como entradas secundárias e caches, são compartilhados entre todas as linhas de execução de cada processo do SDK do Apache Beam.
- O número total de linhas de execução do worker é escalonado de maneira linear com base no número de vCPUs. Como resultado, a memória usada pelos objetos e dados compartilhados do SDK cresce de maneira linear com o número de vCPUs.
- As linhas de execução que executam o trabalho são distribuídas entre os processos. Novas unidades de trabalho são atribuídas a um processo sem itens de trabalho ou ao processo com o menor número de itens de trabalho atualmente atribuídos.